常用模型
机器学习的常用模型可分为如下几类
- 监督学习
- 分类
- kNN
- 贝叶斯
- 决策树和随机森林
- 逻辑回归
- 回归
- 线性回归
- 岭回归
- 分类
- 无监督学习
- 聚类
- KMeans
- 聚类
- 强化学习
不同的模型对于数据的要求也不一样。
其中监督学习要求数据拥有特征值和目标值,无监督学习只要求有特征值。
而在监督学习中,分类问题要求目标值是离散型数据,回归问题则要求目标是连续型数据。
关于强化学习,在《强化学习浅谈及其Python实现》中,有专门的一个系列进行讨论。
常用函数
在机器学习中,有两种函数。
- 假设函数
- 损失函数
我们举一个例子来讨论两种函数。
假设存在数据如下,我们要求寻找一个最能拟合所有点的模型。
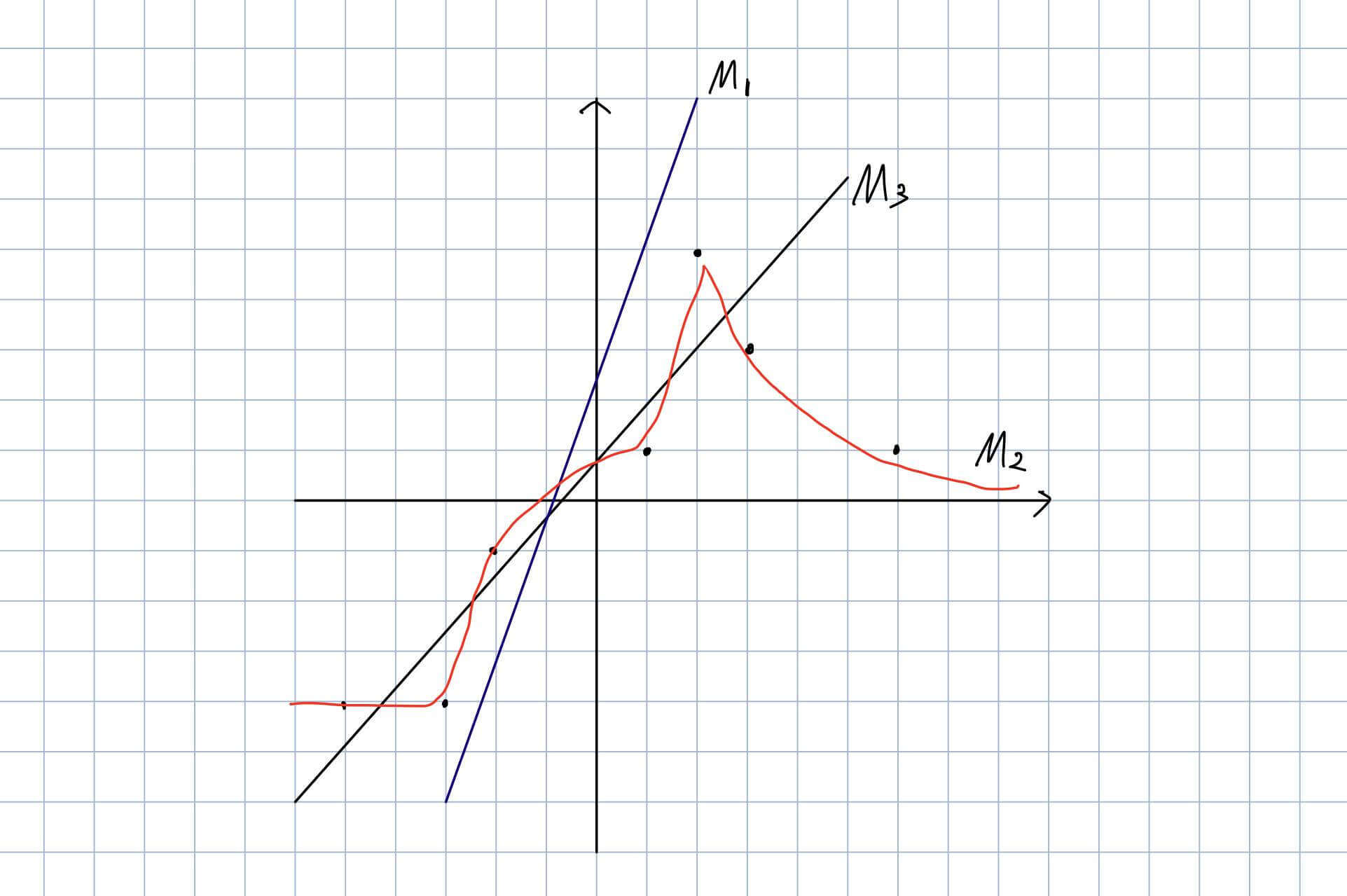
假设函数
假设函数通常记作,其中是需要传入的参数,当然这里的不一定代表一个数字,可以有多种形式,可能是一个向量、也可能是一个矩阵等。在传入参数之后,能够得到一个结果,这个结果便是我们模型的预测值。
损失函数
那么,我们怎么知道这个预测值与真实值到底有多么拟合呢?损失函数。
损失函数通常计作,代表。
在上面的例子,我们可以用每个点到模型的距离平方来评估。
但是,只有每个点到模型的距离的平方,还不够,这时候不足以评价模型的好与不好。
我们还需要对所有的距离进行平方再求和,这就是损失函数。
模型评估
分类模型评估
常用的分类模型评估方法有
- 准确率
- 精确率和召回率
- 平衡F分数
准确率
即:预测结果与事实相符的百分比
精确率和召回率
以二分类为例:预测结果与真实标记之间存在四种不同的组合
| 预测为正 | 预测为负 | |
|---|---|---|
| 真实为正 | 真正例 TP | 伪反例 FN |
| 真实为负 | 伪正例 FP | 真反例 TN |
TP:True Positive,预测结果为正,真实为正。这时候与事实相符。FP:False Positive,预测结果为正,真实为负。这时候与事实不符。FN:False Negative,预测结果为负,真实为正。这时候与事实不符。TN:True Negative,预测结果为负,真实为负。这时候与事实相符。
精确率与召回率
- 精确率:预测为正的样本中,真实为正的比例。(查的准)
- 比如100人进行新冠肺炎的核算检测,核酸检测认为其中10人感染了新冠,实际上这10人中只有9人感染了新冠。那么精确率为90%。
- 召回率:真实为正的样本中,预测为正的比例。(查的全)
- 比如100人进行新冠肺炎的核算检测,其中有15人是感染了新冠的,核酸检测这15人中只有10人感染了新冠。那么召回率为66.66%
精确率的公式
- :预测为正
- :真实为正
召回率的公式
- :真实为正
- :预测为正
平衡F分数
上面我们讲了精确率和召回率,而平衡F分数就是兼顾精确率和召回率的公式。
的公式
例如:
另外还有和。
- 认为
精确率和召回率同等重要。 - 认为
精确率比召回率重要。 - 认为
召回率比精确率重要。
分类模型评估的实现
1 | from sklearn.metrics import classification_report |
传入的参数有
- y_true:真实目标值
- y_pred:估计器预测目标值
- target_name:目标类别名称
返回每个类别的精确率和召回率
回归模型评估
常见的回归模型评估方法有
- 平均绝对误差
- 平均方差
- R平方
平均绝对误差
是预测值,是真实值,就是绝对误差,那么很多的平均就是平均绝对误差。
实现方式
1 | from sklearn.metrics import mean_absolute_error |
平均方差
与平均绝对误差类似,很多方差的平均就是平均方差。
实现方式
1 | from sklearn.metrics import mean_squared_error |
R平方
R平方定义
我们先定义这些符号。
- 是目标值的真实值
- 是目标值的真实值的预测值
- 是目标值的真实值的平均值
ESS(Explained Sum of Squares)是回归平方和
RSS(Residual Sum of Squares)是残差平方和
TSS(Toatl Sum of Squares of Deviations)是总离差平方和
R平方
ESS,RSS,TSS之间还存在关系,我们举例来说明。
假设是关于,,,的线性回归,且
| 方差来源 | 平方和 | 自由度 |
|---|---|---|
- ,即
- 的自由度是自变量的个数
-
- 是样本个数
- 是参数个数,在这里是。(因为回归模型中还有一个常数)
R平方缺陷
R平方的缺陷有
- 如果有更多的回归变量加入回归方程中,只会增大不会减少,容易误解。
- 对于时间序列回归,通常很大,此时难以判断模型的优劣。
所以有了有调整的,记作
其中
- 是样本个数
- 是参数个数
R平方的实现
1 | from sklearn.metrics import r2_score |
两个问题
一、为什么不把损失函数作为模型的评估方法?
因为损失函数并不能很好的作为从业务角度去评价模型。比如,在分类问题中,有时候我们需要的查的准,在预测为正的样本实际为正的比例要高,所以我们用精准率。但是有时候我们需要实际为正中预测为正的比例,召回率。此外,我们还可能会平衡F分数,兼顾准确率和召回率等。此外,在分类问题中,即使准确率也有交叉熵损失更利于从业务角度去评估模型。而在回归模型评估方法中,平均绝对误差和平均方差,其实和回归问题的损失函数均方误差非常相似。而R平方是决定系数,可以反应因变量的变化对自变量的影响力。
二、为什么不把模型评估方法做为目标函数?
因为大多数模型评估方法没法通过梯度进行优化,比如准确率、精准率和召回率等。