概述
简介
- Filebeat,用于采集日志和其他数据的轻量型采集器。
- 官网:https://www.elastic.co/cn/beats/filebeat
- 官方文档:https://www.elastic.co/guide/en/beats/filebeat/current/index.html
Filebeat中还内置了多种模块(Apache、NGINX、MySQL等),可通过一个简单的命令,对常见应用的日志进行采集。
特点
- 轻量型日志采集器,占用资源更少,对机器配置要求极低。
- 操作简便,可将采集到的日志信息直接发送到Kafka、Logstash或者ElasticSearch等。
- 异常中断重启后会继续上次停止的位置。
(通过${filebeat_home}\data\registry文件来记录日志的偏移量。) - 使用压力敏感协议(backpressure-sensitive)来传输数据,当目标(例如
logstash)忙的时候,Filebeat会减慢读取传输速度,一旦目标(例如logstash)恢复,Filebeat也会恢复速度。 - Filebeat带有内部模块(Apache、Nginx、MySQL等),可通过一个简单的命令,对常见应用的日志进行采集。
和Logstash的对比
- Filebeat更轻量级,占用空间更小,使用的系统资源更少;当然功能更简单。
- Logstash会占用更大的资源;功能也更丰富,有大量的输入、过滤和输出插件,可以用于收集、转换来自各种来源的数据。
- 在实现语言上,Filebeat采用Golang编写;Logstach采用Java编写,插件采用jruby编写。
如果我们在部署业务系统的机器上,再部署一套Logstash进行日志收集,所占用的资源会比部署Filebeat更大。
安装
- 官网:
https://www.elastic.co/cn/products/beats/filebeat
Linux系统
在Linux系统上有很多中安装方式:.rpm、.deb以及.tar。
rpm和deb
通过.rpm或.deb的方式进行安装:
- 应用位于
/usr/share/filebeat/目录 - 配置文件位于
/etc/filebeat/目录 - 还会有一个快捷方式
/etc/bin/filebeat。
通过.deb的方式安装,可能会有如下的报错:
1 | N: Download is performed unsandboxed as root as file '/root/filebeat-8.6.1-amd64.deb' couldn't be accessed by user '_apt'. - pkgAcquire::Run (13: Permission denied) |
解决办法是把要安装包移动到/tmp目录下再进行安装。
tar
通过.tar包的话,直接解压即可,命令如下:
1 | tar -zxvf filebeat-8.6.1-linux-x86_64.tar.gz |
Windows系统
在Windows上,有两种安装方式,对应两种的安装包:
.msi,Windows MSI x86_64 (beta)。.zip,Windows ZIP x86_64。
通过.msi的方式进行安装:
- 应用位于
C:\ProgramData\Elastic\Beats\filebeat - 配置文件位于
C:\ProgramData\Elastic\Beats\filebeat
通过.zip的方式进行安装,和我们上文.tar方式,没有区别,直接解压即可。
快速开始
我们以《Linux操作系统使用入门:2.命令》的"后台运行"这一小节中的Java程序为例,将其日志再输出到File。
配置
filebeat.yml
配置文件filebeat.yml的地址:
1 | /usr/local/filebeat/filebeat-8.6.1-linux-x86_64/filebeat.yml |
我们重点关注filebeat.yml的这两部分:
Filebeat inputsOutputs
Filebeat inputs
1 | # ============================== Filebeat inputs =============================== |
我们修改两处:
-
把原本的
enabled: false设为enabled: true,即打开。 -
把
/var/log/*.log注释掉,改成我们需要监控的日志/root/f/f.log。 -
Filebeat所支持的输入,远不止这些,根据官方文档的记录,有:
AWS CloudWatch、AWS S3、Azure Event Hub、Azure Blob Storage、CEL、Cloud Foundry、CometD、Container、filestream、GCP Pub/Sub、HTTP Endpoint、HTTP JSON、journald、Kafka、Log (deprecated in 7.16.0, use filestream)、MQTT、NetFlow、Office 365 Management Activity API、Redis、Stdin、Syslog、TCP、UDP、Google Cloud Storage。
我们使用最多的是filestream。
Outputs
1 | # ================================== Outputs =================================== |
接下里,我们在Outputs部分新增如下内容:
1 | output.file: |
- 有一个属性
enabled,默认值是true。
我们需要注释掉默认开启的Elastisearch,或者为其新增一个属性enabled,设置为false。
1 | output.elasticsearch: |
在Outputs部分,官方的示例只有Elasticsearch Output和Logstash Output。
实际上,Filebeat支持的远不止这些,根据官方文档的记录,Filebeat支持的有:
Elasticsearch ServiceElasticsearchLogstashKafkaRedisFileConsoleChange the output codec
解释说明:
- 通常我们认为的几个消息队列中,Filebeat只支持Kafka。Redis,虽然也可以作为消息队列,但通常认为是一种缓存技术。
Elasticsearch Service,是一些云服务厂商以软件即服务模式(SaaS)提供托管Elasticsearch。
启动
执行filebeat-8.6.1-linux-x86_64目录下的filebeat:
1 | ./filebeat |
然后,我们会看到如下内容:
1 |
|
进行JSON格式化后,如下:
1 | { |
@timestamp:是当前时间戳,是Filebeat加上的字段。log.file.path:采集的日志文件的路径。log.offset:偏移量。agent:Beats的信息。- 日志信息位于
message字段。
对接Kafka
环境准备
- 有两个应用,一个应用在Linux机器上输出日志,一个应用在Windows机器上输出日志;然后Filebeat采集日志,并发送到Kafka。这是Kafka的生产者。
- 还有一个应用,接收Kakfa的消息,进行消费。这是Kafka的消费者。
在Linux机器上输出日志的应用,继续复用《Linux操作系统使用入门:2.命令》的"后台运行"这一小节中的Java程序,但有一处调整,输出的日志,在时间前面加上[Java]。
在Windows机器上输出日志的,是一个Python脚本:
1 | import logging |
消费者是是一个SpringBoot项目,其关键代码如下:
1 | package com.kakawanyifan.spbf; |
Filebeat配置
Filebeat配置的Filebeat inputs我们不赘述,设为指定的路径即可。主要关注Outputs:
1 | output.kafka: |
更详细的配置,可以参考官方文档。
地址:https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
测试
消费者打印的日志如下:
1 |
|
ELK
Filebeat更多的时候,会和ELK结合,架构如图所示:
x关于ELK的具体搭建和应用,我们不讨论。根据一些资料,一个需要注意的点是:ELK之间的版本要一致(包括Filebeat)。
还有Filebeat中的模块使用,虽然只需要简单的配置,但是只有和ELK配合,才能看到效果。
所以,关于该部分,我们也不讨论。
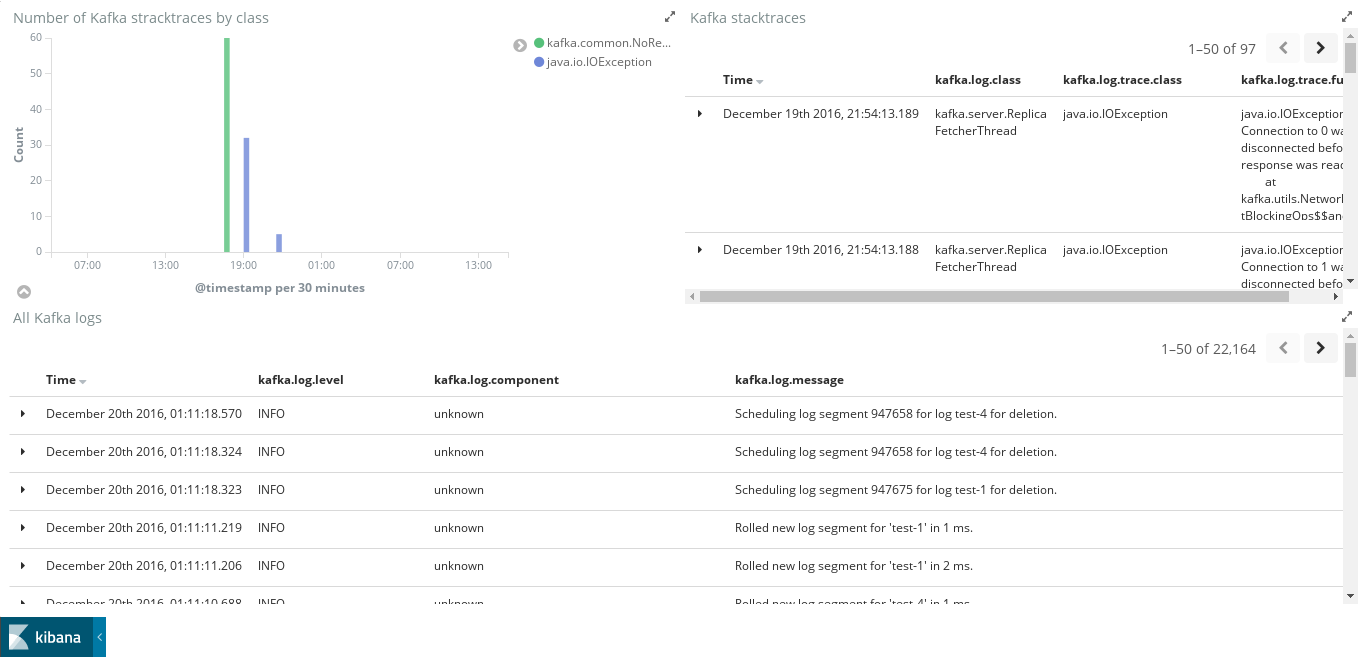
如图,是Kafka模块,在ELK中的效果:
- 关于ElasticSeach,可以参考《ElasticSearch实战入门(6.X)》。
- 关于Kibana,在《ElasticSearch实战入门(6.X)》,也有简单的讨论。
原理
采集日志
- Filebeat每采集一条日志文本,都会保存为JSON格式的对象,称为日志事件(event)。
- Filebeat的主要模块:
- input:输入端。
- output:输出端。
- harvester:收割机,负责采集日志。
- Filebeat会定期扫描(scan)日志文件,如果发现其最后修改时间改变,则创建harvester去采集日志。
- 对每个日志文件创建一个harvester,逐行读取文本,转换成日志事件,发送到输出端。
- 每行日志文本必须以换行符分隔,最后一行也要加上换行符才能视作一行。
- harvester开始读取时会打开文件描述符,读取结束时才关闭文件描述符。
- 默认会一直读取到文件末尾,如果文件未更新的时长超过
close_inactive,才关闭。
- 默认会一直读取到文件末尾,如果文件未更新的时长超过
- 对每个日志文件创建一个harvester,逐行读取文本,转换成日志事件,发送到输出端。
- 在Filebeat采集日志文件A时,如果发生了轮换日志文件,例如将文件A重命名为B的情况(例如
mv A B),Filebeat会按以下规则处理:- 如果没打开文件A,则以后会因为文件A不存在而采集不了。
- 如果打开了文件A,则会继续读取到文件末尾,然后每隔backoff时间检查一次文件:
- 如果在backoff时长之内又创建文件A(例如
touch A)。则Filebeat会认为文件被重命名。- 默认配置了
close_renamed: false,因此会既采集文件A,又采集文件B,直到因为close_inactive超时等原因才关闭文件B。
- 默认配置了
- 如果在backoff时长之后,依然没有创建文件A。则Filebeat会认为文件被删除。
- 默认配置了
close_removed: true,因此会立即关闭文件B而不采集,而文件A又因为不存在而采集不了。
- 默认配置了
- 如果在backoff时长之内又创建文件A(例如
注册表
- Filebeat会通过registry文件记录所有日志文件的当前状态信息(State)。
- 即使只有一个日志文件被修改了,也会在registry文件中写入一次所有日志文件的当前状态。
- registry保存在
data/registry/目录下,删除该目录就会重新采集所有日志文件。
data/registry/目录的结构:
1 | data/registry/filebeat/ |
log.json中的一个示例:
1 | {"op":"set", "id":237302} // 本次动作的编号 |
- 采集每个日志文件时,会记录已采集的字节偏移量(bytes offset)。
- 每次harvester读取日志文件时,会从offset处继续采集。
- 如果harvester发现文件体积小于已采集的offset,则认为文件被截断了,会从
offset 0处重新开始读取,这可能会导致重复采集。
发送日志
- Filebeat将采集的日志事件经过处理之后,会发送到输出端,该过程称为发布事件(publish event)。
- event保存在内存中,不会写入磁盘。
- 每个event只有成功发送到输出端,且收到确认接收的回复,才视作发送成功。
- 如果发送event到输出端失败,则会自动重试。直到发送成功,才更新记录。
- 因此,采集到的event至少会被发送一次。但如果在确认接收之前重启Filebeat,则可能重复发送。
event的具体内容,就是我们上文快速开始的案例中,写在文件中的内容。