在《无间道》这部电影,有一个细节特别有意思,那就是卧底陈永仁和警司黄志诚的沟通方式,是一种类似于摩斯密码的编码方式。
而编码器和解码器,将会贯穿我们这一章。
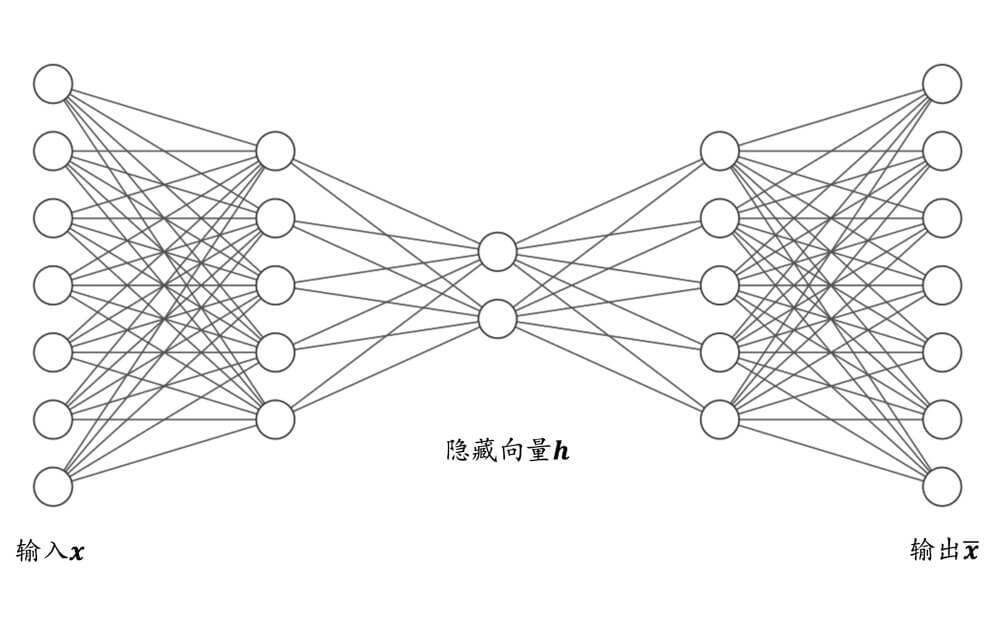
自编码器的原理
x \bold{x} x z \bold{z} z z \bold{z} z x ^ \bold{\widehat{x}} x x ^ \bold{\widehat{x}} x x \bold{x} x
我们对上面的过程,再进行数学抽象。
函数f ( ) f() f ( ) z = f ( x ) \bold{z} = f(\bold{x}) z = f ( x )
函数g ( ) g() g ( ) x ^ = g ( z ) = g ( f ( x ) ) \bold{\widehat{x}} = g(\bold{z}) = g(f(\bold{x})) x = g ( z ) = g ( f ( x ) )
损失函数l o s s = d i s t ( x , x ^ ) loss = dist(\bold{x},\bold{\widehat{x}}) l o s s = d i s t ( x , x )
通常,我们用欧式距离(两点间的距离)来度量x \bold{x} x x ^ \bold{\widehat{x}} x
那么现在,规则已经都清楚了,就差卧底陈永仁和警司黄志诚。
回想一下我们在《循环神经网络》这一章讨论的Word Embedding。这是不是就是一种编码方式?
( 1 0 0 0 0 0 0 1 0 0 0 0 ) ( w 11 w 12 w 13 w 21 w 22 w 23 w 31 w 32 w 33 w 41 w 42 w 43 w 51 w 52 w 53 w 61 w 62 w 63 ) = ( w 11 w 12 w 13 w 21 w 22 w 23 ) \begin{pmatrix}1 & 0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 0 & 0 \end{pmatrix}\begin{pmatrix}w_{11} & w_{12} & w_{13}\\
w_{21} & w_{22} & w_{23}\\
w_{31} & w_{32} & w_{33}\\
w_{41} & w_{42} & w_{43}\\
w_{51} & w_{52} & w_{53}\\
w_{61} & w_{62} & w_{63}\end{pmatrix}=\begin{pmatrix}w_{11} & w_{12} & w_{13}\\
w_{21} & w_{22} & w_{23}\end{pmatrix}
( 1 0 0 1 0 0 0 0 0 0 0 0 ) ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ w 1 1 w 2 1 w 3 1 w 4 1 w 5 1 w 6 1 w 1 2 w 2 2 w 3 2 w 4 2 w 5 2 w 6 2 w 1 3 w 2 3 w 3 3 w 4 3 w 5 3 w 6 3 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ( w 1 1 w 2 1 w 1 2 w 2 2 w 1 3 w 2 3 )
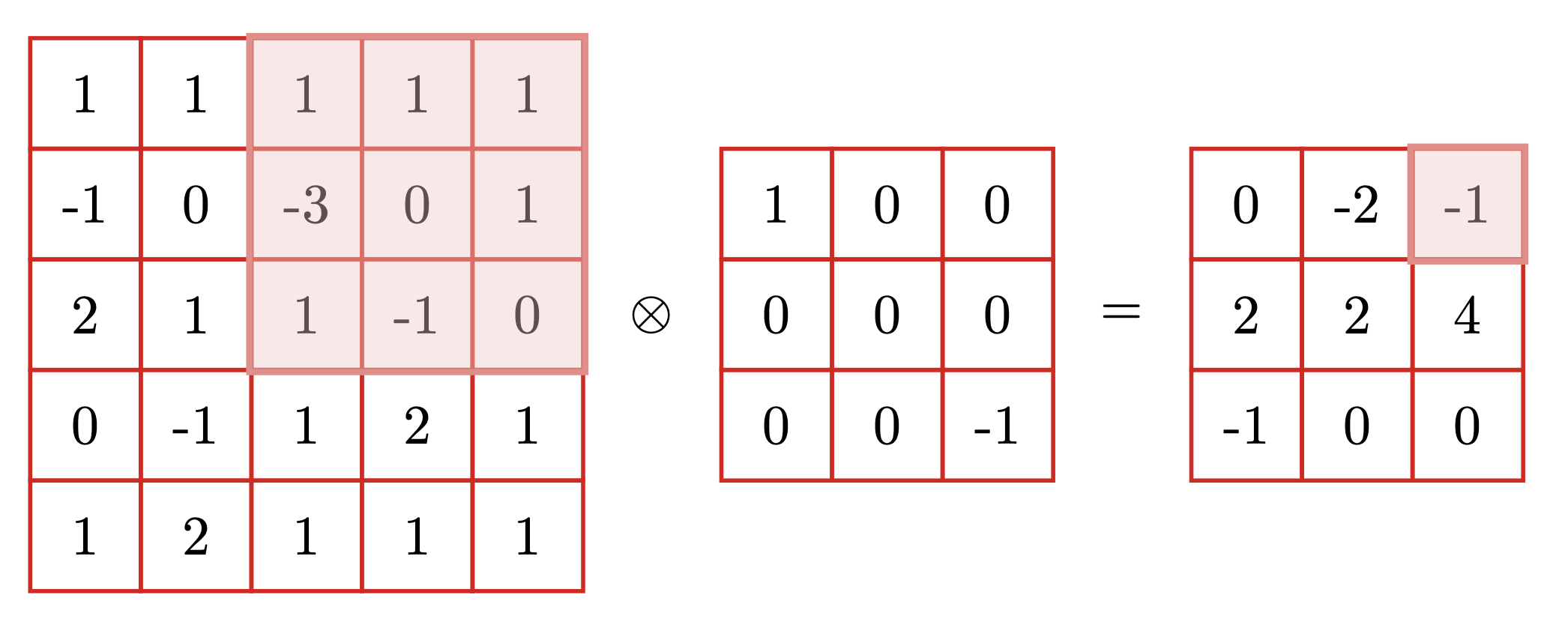
再比如,卷积神经网络中。我们的卷积运算。
又或者,我们的全连接层网络。
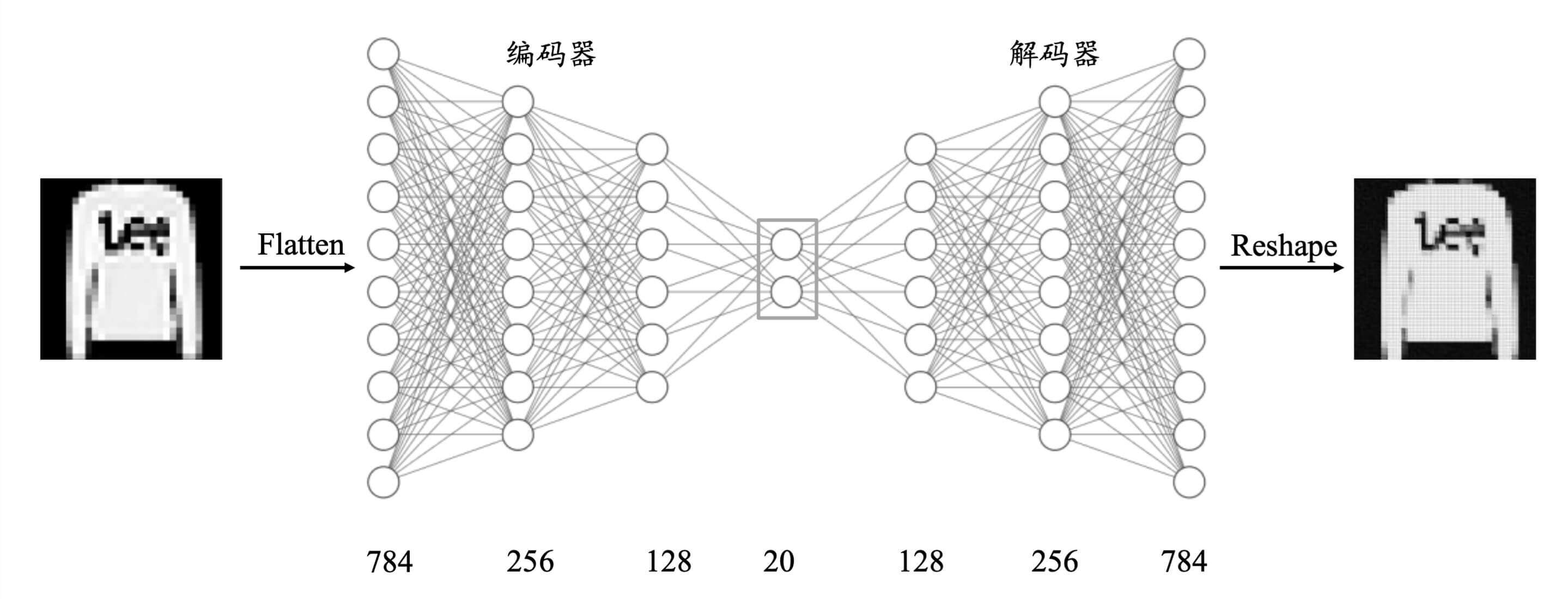
接下来,我们实现一个基于全连接神经网络的自编码器。
自编码器的实现
我们以Fashion MNIST的编码解码为例。
编码器
首先,我们需要编码器(卧底陈永仁)。
1 2 3 4 5 encoder = Sequential([ layers.Dense(256 ,activation=tf.nn.relu), layers.Dense(128 ,activation=tf.nn.relu), layers.Dense(20 ) ])
解码器
然后我们需要解码器(警司黄志诚)。
1 2 3 4 5 decoder = Sequential([ layers.Dense(128 ,activation=tf.nn.relu), layers.Dense(256 ,activation=tf.nn.relu), layers.Dense(784 ) ])
自编码器
编码器和解码器就合成了我们的自编码器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class AE (Model) : def __init__ (self) : super(AE, self).__init__() self.encoder = Sequential([ layers.Dense(256 , activation=tf.nn.relu), layers.Dense(128 , activation=tf.nn.relu), layers.Dense(h_dim) ]) self.decoder = Sequential([ layers.Dense(128 , activation=tf.nn.relu), layers.Dense(256 , activation=tf.nn.relu), layers.Dense(784 ) ]) def call (self, inputs, training=None) : h = self.encoder(inputs) x_hat = self.decoder(h) return x_hat
加载数据
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 (x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data() x_train, x_test = x_train.astype(np.float32) / 255. , x_test.astype(np.float32) / 255. train_db = tf.data.Dataset.from_tensor_slices(x_train) train_db = train_db.shuffle(128 * 5 ).batch(128 ) test_db = tf.data.Dataset.from_tensor_slices(x_test) test_db = test_db.batch(128 ) for step, x in enumerate(train_db): if step > 3 : break ; print(x.shape) print('\n' ) for step, x in enumerate(test_db): if step > 3 : break ; print(x.shape)
运行结果:
1 2 3 4 5 6 7 8 9 10 (128, 28, 28) (128, 28, 28) (128, 28, 28) (128, 28, 28) (128, 28, 28) (128, 28, 28) (128, 28, 28) (128, 28, 28)
网络训练
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 model = AE() model.build(input_shape=(None , 784 )) model.summary() optimizer = tf.optimizers.Adam(lr=0.01 ) for epoch in range(5 ): for step, x in enumerate(train_db): x = tf.reshape(x, [-1 , 784 ]) with tf.GradientTape() as tape: x_rec_logits = model(x) rec_loss = tf.losses.binary_crossentropy(x, x_rec_logits, from_logits=True ) rec_loss = tf.reduce_mean(rec_loss) grads = tape.gradient(rec_loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) if step % 100 == 0 : print(epoch, step, float(rec_loss))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Model: "ae" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= sequential (Sequential) (None, 20) 236436 _________________________________________________________________ sequential_1 (Sequential) (None, 784) 237200 ================================================================= Total params: 473,636 Trainable params: 473,636 Non-trainable params: 0 _________________________________________________________________ 0 0 0.6935020685195923 0 100 0.3264176845550537 0 200 0.30031147599220276 0 300 0.2973533570766449 0 400 0.29836705327033997 【部分运行结果略】 4 0 0.2900039553642273 4 100 0.26454201340675354 4 200 0.2719815671443939 4 300 0.28770673274993896 4 400 0.2869689464569092
模型评估
比如对于图片重建,一般依赖于人工主观评价图片生成的质量,或利用某些图片逼真度计算方法(如 Inception Score 和 Frechet Inception Distance)来辅助评估。
我们这里对图片进行重建,并进行主观评估。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 x = next(iter(test_db)) logits = model(tf.reshape(x, [-1 , 784 ])) x_hat = tf.sigmoid(logits) x_hat = tf.reshape(x_hat, [-1 , 28 , 28 ]) x_concat = tf.concat([x[:10 ], x_hat[:10 ]], axis=0 ) x_concat = x_concat.numpy() * 255. x_concat = x_concat.astype(np.uint8)
通过上面的代码,我们获得编码前的x \bold{x} x x ^ \bold{\widehat{x}} x
1 2 3 4 5 6 7 8 9 10 11 12 def printImage (images) : plt.figure(figsize=(10.0 , 8.0 )) for i in range(20 ): plt.subplot(4 , 5 , i + 1 ) plt.xticks([]) plt.yticks([]) plt.grid(False ) plt.imshow(images[i], cmap=plt.cm.binary) plt.show() printImage(x_concat)
运行结果:
上面两行是x \bold{x} x x ^ \bold{\widehat{x}} x
KL散度
刚刚我们已经体会到了,自编码器就是学习输入x \bold{x} x z \bold{z} z z \bold{z} z p ( z ) p(\bold{z}) p ( z ) p ( x ∣ z ) p(\bold{x}|\bold{z}) p ( x ∣ z ) p ( x , z ) = p ( x ∣ z ) p ( z ) p(\bold{x},\bold{z}) = p(\bold{x}|\bold{z})p(\bold{z}) p ( x , z ) = p ( x ∣ z ) p ( z )
如果这么做的话,我们需要有一个东西,来度量两个分布之间的距离,以此来做损失函数。KL散度 。
我们决定按照这个顺序讨论,把这几个串起来。
信息熵 ⟶ 交叉熵 ⟶ KL散度 \text{信息熵} \quad \longrightarrow \text{交叉熵} \quad \longrightarrow \text{KL散度}
信息熵 ⟶ 交叉熵 ⟶ KL 散度
信息熵
假设,现在有4个西瓜,而且4个西瓜中只有一个是好瓜。而我们对西瓜完全不了解,只能猜。这时候卖西瓜的和我们玩一个游戏,猜一次一块钱。
graph LR
1-2{在1-2中?}
1{1?}
3{3?}
g1(瓜-1)
g2(瓜-2)
g3(瓜-3)
g4(瓜-4)
1-2 -- 是 --> 1
1-2 -- 否 --> 3
1 -- 是 --> g1
1 -- 否 --> g2
3 -- 是 --> g3
3 -- 否 --> g4
按照这个策略,我们只需要猜两次,就可以选中最好的西瓜。
那么,我们还会发现。
log 2 4 = 2 比特 \log_2 4 = 2\text{比特}
log 2 4 = 2 比特
而这个2 比特 2\text{比特} 2 比特 − log 2 1 4 - \log_2 \frac{1}{4} − log 2 4 1
− ( ∑ i = 1 4 1 4 ∗ log 2 1 4 ) = 2 -\bigg (\sum_{i=1}^{4} \frac{1}{4} * \log_2 \frac{1}{4} \bigg ) = 2
− ( i = 1 ∑ 4 4 1 ∗ log 2 4 1 ) = 2
即确定一个有n n n log 2 n \log_2 n log 2 n 1 n \frac{1}{n} n 1
− ( ∑ i = 1 n 1 n ∗ log 2 1 n ) \quad -\bigg (\sum_{i=1}^{n} \frac{1}{n} * \log_2 \frac{1}{n} \bigg ) \quad
− ( i = 1 ∑ n n 1 ∗ log 2 n 1 )
现在改一下。我们对西瓜也略知一二。
那么,这时候,我们需要多少信息量去挑选好瓜呢?或者我们需要多少信息量去消除不确定呢?
( − 0.4 log 2 0.4 ) + ( − log 0.3 log 2 0.3 ) + ( − 0.2 log 2 0.2 ) + ( − 0.1 log 2 0.1 ) (-{0.4}\log_2{0.4}) + (-\log{0.3}\log_2{0.3}) + (-{0.2}\log_2{0.2}) + (-{0.1}\log_2{0.1})
( − 0 . 4 log 2 0 . 4 ) + ( − log 0 . 3 log 2 0 . 3 ) + ( − 0 . 2 log 2 0 . 2 ) + ( − 0 . 1 log 2 0 . 1 )
这就是我们的信息熵的公式:
H ( X ) = − ∑ i ∈ X p ( i ) ∗ log 2 p ( i ) H(X) = - \sum_{i\in X} p(i) * \log_2 p(i)
H ( X ) = − i ∈ X ∑ p ( i ) ∗ log 2 p ( i )
交叉熵
我们把信息熵的公式改一下。
H ( X ) = − ∑ i ∈ X p ( i ) ∗ log 2 q ( i ) H(X) = - \sum_{i\in X} p(i) * \log_2 q(i)
H ( X ) = − i ∈ X ∑ p ( i ) ∗ log 2 q ( i )
把log 2 p ( i ) \log_2 p(i) log 2 p ( i ) log 2 q ( i ) \log_2 q(i) log 2 q ( i )
这就是交叉熵的公式,用于度量两个概率分布间的差异性信息。
提起交叉熵,我们很容易会联想到一个损失函数:交叉熵损失。
H ( p ∣ ∣ q ) = − ∑ i p i log 2 q i H(\bold{p}||\bold{q}) = - \sum_i p_i \log_2 q_i
H ( p ∣ ∣ q ) = − i ∑ p i log 2 q i
KL散度
KL散度又被称为相对熵,那么既然是熵呢,肯定也和信息熵、交叉熵一样,是衡量混乱程度的。
D K L ( p ∣ ∣ q ) = H ( p ∣ ∣ q ) − H ( p ) = p和q的交叉熵 − p的熵 \begin{aligned}
D_{KL}(\bold{p}||\bold{q}) &= H(\bold{p}||\bold{q}) - H(\bold{p}) \\
&= \text{p和q的交叉熵} - \text{p的熵}
\end{aligned}
D K L ( p ∣ ∣ q ) = H ( p ∣ ∣ q ) − H ( p ) = p 和 q 的交叉熵 − p 的熵
特别需要注意的是:
D K L ( p ∣ ∣ q ) ≠ D K L ( q ∣ ∣ p ) D_{KL}(\bold{p}||\bold{q}) \neq D_{KL}(\bold{q}||\bold{p}) D K L ( p ∣ ∣ q ) = D K L ( q ∣ ∣ p ) H ( p ∣ ∣ q ) ≠ H ( q ∣ ∣ p ) H(\bold{p}||\bold{q}) \neq H(\bold{q}||\bold{p}) H ( p ∣ ∣ q ) = H ( q ∣ ∣ p )
这个被称为不对称性。
为什么是交叉熵损失
再讨论一个问题。为什么之前我们的损失函数都是交叉熵损失,不是KL散度?p \bold{p} p D K L ( p ∣ ∣ q ) D_{KL}(\bold{p}||\bold{q}) D K L ( p ∣ ∣ q ) H ( p ∣ ∣ q ) H(\bold{p}||\bold{q}) H ( p ∣ ∣ q )
D K L ( p ∣ ∣ q ) = H ( p ∣ ∣ q ) − H ( p ) D_{KL}(\bold{p}||\bold{q}) = H(\bold{p}||\bold{q}) - H(\bold{p})
D K L ( p ∣ ∣ q ) = H ( p ∣ ∣ q ) − H ( p )
p \bold{p} p D K L ( p ∣ ∣ q ) D_{KL}(\bold{p}||\bold{q}) D K L ( p ∣ ∣ q ) H ( p ∣ ∣ q ) H(\bold{p}||\bold{q}) H ( p ∣ ∣ q )
那么既然两者等价呢,我们何必再折腾去减个H ( p ) H(\bold{p}) H ( p )
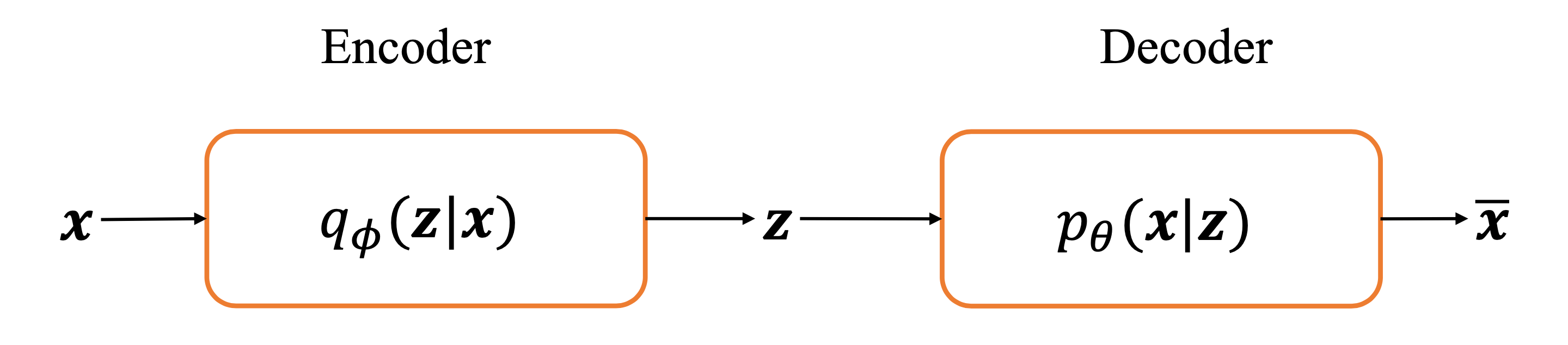
变分自编码器的原理
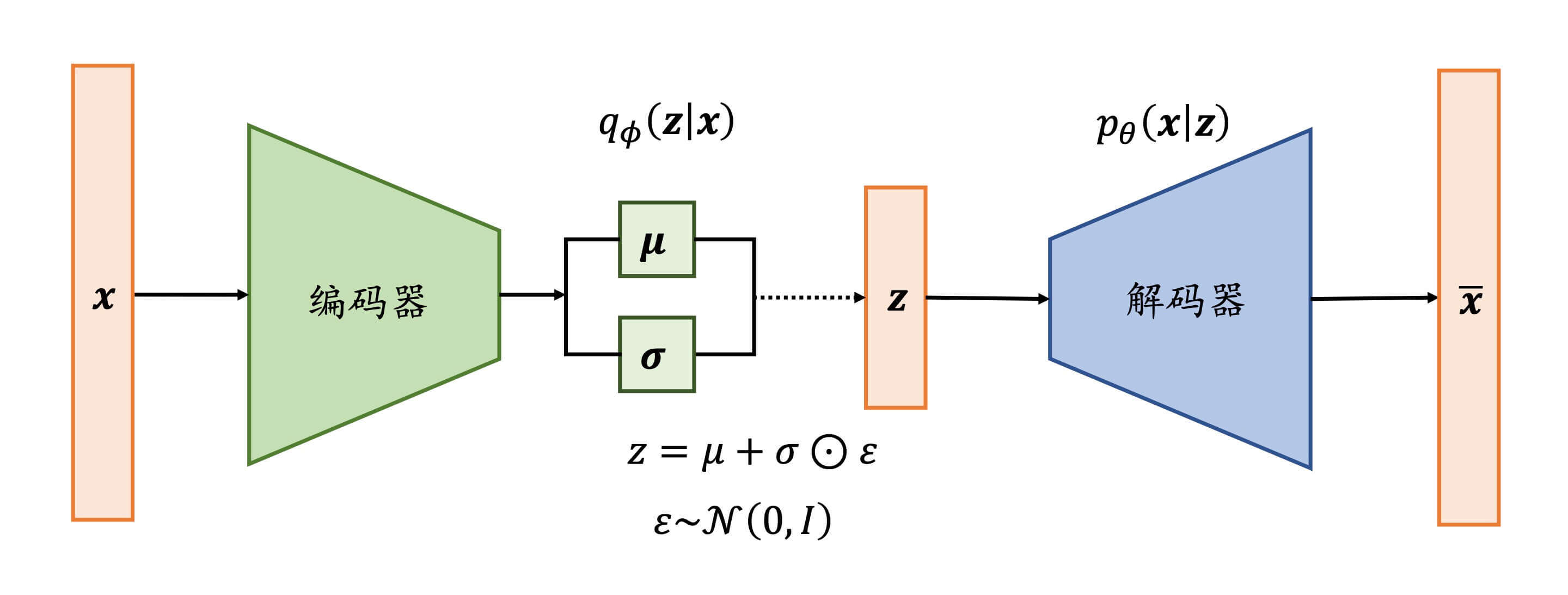
如图,是变分自编码起的网络结构。x \bold{x} x z \bold{z} z z \bold{z} z x ~ \bold{\widetilde{x}} x z \bold{z} z z \bold{z} z p ( z ) p(\bold{z}) p ( z ) z \bold{z} z p ( x ∣ z ) p(\bold{x}|\bold{z}) p ( x ∣ z )
那么,这时候我们需要一个分布q ϕ ( z ∣ x ) q_{\phi}(\bold{z}|\bold{x}) q ϕ ( z ∣ x ) p ( z ∣ x ) p(\bold{z}|\bold{x}) p ( z ∣ x )
损失函数
min ϕ D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) \min_{\phi} D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x}))
ϕ min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) )
这就是q ϕ ( z ∣ x ) q_{\phi}(\bold{z}|\bold{x}) q ϕ ( z ∣ x ) p ( z ∣ x ) p(\bold{z}|\bold{x}) p ( z ∣ x )
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = ∑ z q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( z ∣ x ) D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) = \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{q_{\phi}(\bold{z}|\bold{x})}{p(\bold{z}|\bold{x})}
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = z ∑ q ϕ ( z ∣ x ) log p ( z ∣ x ) q ϕ ( z ∣ x )
我们知道p ( z ∣ x ) ⋅ p ( x ) = p ( x , z ) p(\bold{z}|\bold{x}) \cdot p(\bold{x}) = p(\bold{x},\bold{z}) p ( z ∣ x ) ⋅ p ( x ) = p ( x , z )
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = ∑ z q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( x ) p ( x , z ) = ∑ z q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( x , z ) + ∑ z q ϕ ( z ∣ x ) log p ( x ) = − ( − ∑ z q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( x , z ) ) + log p ( x ) \begin{aligned}
D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) &= \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{q_{\phi}(\bold{z}|\bold{x}) p(\bold{x})}{p(\bold{x},\bold{z})} \\
&= \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{q_{\phi}(\bold{z}|\bold{x})}{p(\bold{x},\bold{z})} + \sum_z q_{\phi}(\bold{z}|\bold{x}) \log p(\bold{x}) \\
&= -\bigg( - \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{q_{\phi}(\bold{z}|\bold{x})}{p(\bold{x},\bold{z})} \bigg) + \log p(\bold{x})
\end{aligned}
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = z ∑ q ϕ ( z ∣ x ) log p ( x , z ) q ϕ ( z ∣ x ) p ( x ) = z ∑ q ϕ ( z ∣ x ) log p ( x , z ) q ϕ ( z ∣ x ) + z ∑ q ϕ ( z ∣ x ) log p ( x ) = − ( − z ∑ q ϕ ( z ∣ x ) log p ( x , z ) q ϕ ( z ∣ x ) ) + log p ( x )
我们把( − ∑ z q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p θ ( x , z ) ) \Big( - \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{q_{\phi}(\bold{z}|\bold{x})}{p_{\theta}(\bold{x},\bold{z})} \Big) ( − ∑ z q ϕ ( z ∣ x ) log p θ ( x , z ) q ϕ ( z ∣ x ) ) L ( ϕ , θ ) L(\phi,\theta) L ( ϕ , θ )
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = − L ( ϕ , θ ) + log p ( x ) D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) = - L(\phi,\theta) + \log p(\bold{x})
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = − L ( ϕ , θ ) + log p ( x )
我们知道D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ≥ 0 D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) \ge 0 D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ≥ 0 D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) L ( ϕ , θ ) L(\phi,\theta) L ( ϕ , θ )
所以:
损失函数从 min ϕ D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ⟶ max L ( ϕ , θ ) \text{损失函数从} \min_{\phi} D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) \quad \longrightarrow \quad \max L(\phi,\theta)
损失函数从 ϕ min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ⟶ max L ( ϕ , θ )
那么,如何使得L ( ϕ , θ ) L(\phi,\theta) L ( ϕ , θ ) L ( ϕ , θ ) L(\phi,\theta) L ( ϕ , θ )
L ( ϕ , θ ) = ∑ z q ϕ ( z ∣ x ) log p ( x , z ) q ϕ ( z ∣ x ) = ∑ z q ϕ ( z ∣ x ) log p ( z ) p θ ( x ∣ z ) q ϕ ( z ∣ x ) \begin{aligned}
L(\phi,\theta) &= \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{p(\bold{x},\bold{z})}{q_{\phi}(\bold{z}|\bold{x})} \\
&= \sum_z q_{\phi}(\bold{z}|\bold{x}) \log \frac{p(\bold{z})p_{\theta}(\bold{x}|\bold{z})}{q_{\phi}(\bold{z}|\bold{x})}
\end{aligned}
L ( ϕ , θ ) = z ∑ q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( x , z ) = z ∑ q ϕ ( z ∣ x ) log q ϕ ( z ∣ x ) p ( z ) p θ ( x ∣ z )
再进行变换操作,最后
L ( ϕ , θ ) = − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) + E z ∼ q [ log p θ ( x ∣ z ) ] L(\phi,\theta) = - D_{KL}\bigg(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z})\bigg) + \mathbf{E}_{z \sim q}\bigg[ \log p_{\theta}(\bold{x}|\bold{z})\bigg]
L ( ϕ , θ ) = − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) + E z ∼ q [ log p θ ( x ∣ z ) ]
所以:
损失函数从 max L ( ϕ , θ ) ⟶ { min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) max E z ∼ q [ log p θ ( x ∣ z ) ] \text{损失函数从} \max L(\phi,\theta) \quad \longrightarrow \quad \begin{cases}
\min D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z})) \\
\max \mathbf{E}_{z \sim q}[ \log p_{\theta}(\bold{x}|\bold{z})]
\end{cases}
损失函数从 max L ( ϕ , θ ) ⟶ { min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) max E z ∼ q [ log p θ ( x ∣ z ) ]
小结:
min ϕ D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ⟶ max L ( ϕ , θ ) ⟶ { min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) max E z ∼ q [ log p θ ( x ∣ z ) ] \min_{\phi} D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z}|\bold{x})) \ \longrightarrow \ \max L(\phi,\theta) \quad \longrightarrow \quad \begin{cases}
\min D_{KL}(q_{\phi}(\bold{z}|\bold{x})||p(\bold{z})) \\
\max \mathbf{E}_{z \sim q}[ \log p_{\theta}(\bold{x}|\bold{z})]
\end{cases}
ϕ min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) ⟶ max L ( ϕ , θ ) ⟶ { min D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) max E z ∼ q [ log p θ ( x ∣ z ) ]
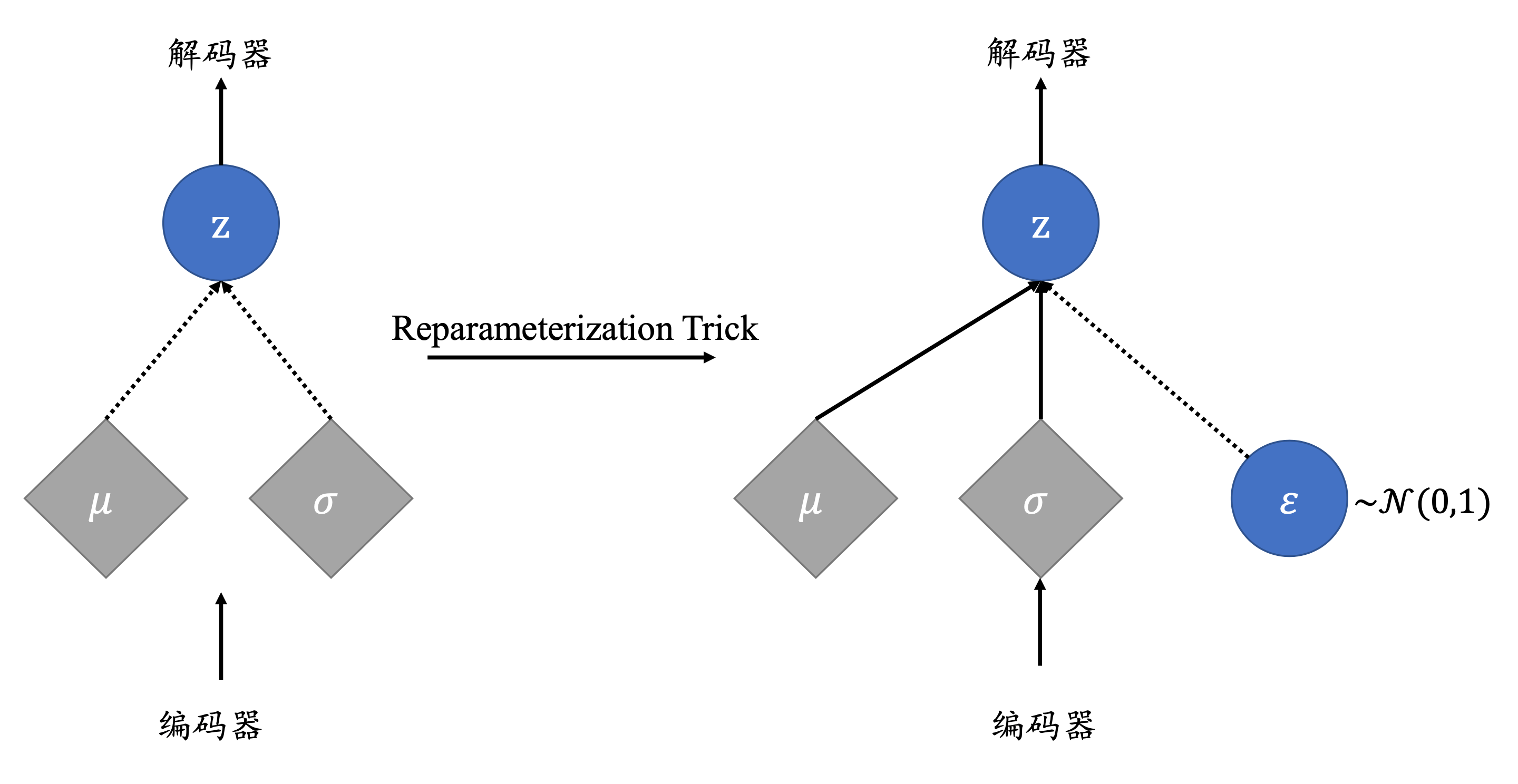
Reparameterization Trick
现在,再让我们看一下这个过程。我们预设z \bold{z} z p ( z ) p(\bold{z}) p ( z ) N ( μ , σ 2 ) \bold{N}(\mu,\sigma^2) N ( μ , σ 2 ) μ \mu μ σ 2 \sigma^2 σ 2 z = μ + σ ⊙ ε z = \mu + \sigma \odot \varepsilon z = μ + σ ⊙ ε ε ∼ N ( 0 , 1 ) \varepsilon \sim \bold{N}(0,1) ε ∼ N ( 0 , 1 ) z \bold{z} z N ( μ , σ 2 ) \bold{N}(\mu,\sigma^2) N ( μ , σ 2 ) ∂ z ∂ μ \frac{\partial z}{\partial \mu} ∂ μ ∂ z ∂ z ∂ σ \frac{\partial z}{\partial \sigma} ∂ σ ∂ z ∂ z ∂ ε \frac{\partial z}{\partial \varepsilon} ∂ ε ∂ z ε ∼ N ( 0 , 1 ) \varepsilon \sim \bold{N}(0,1) ε ∼ N ( 0 , 1 )
这个操作叫做Reparameterization Trick。
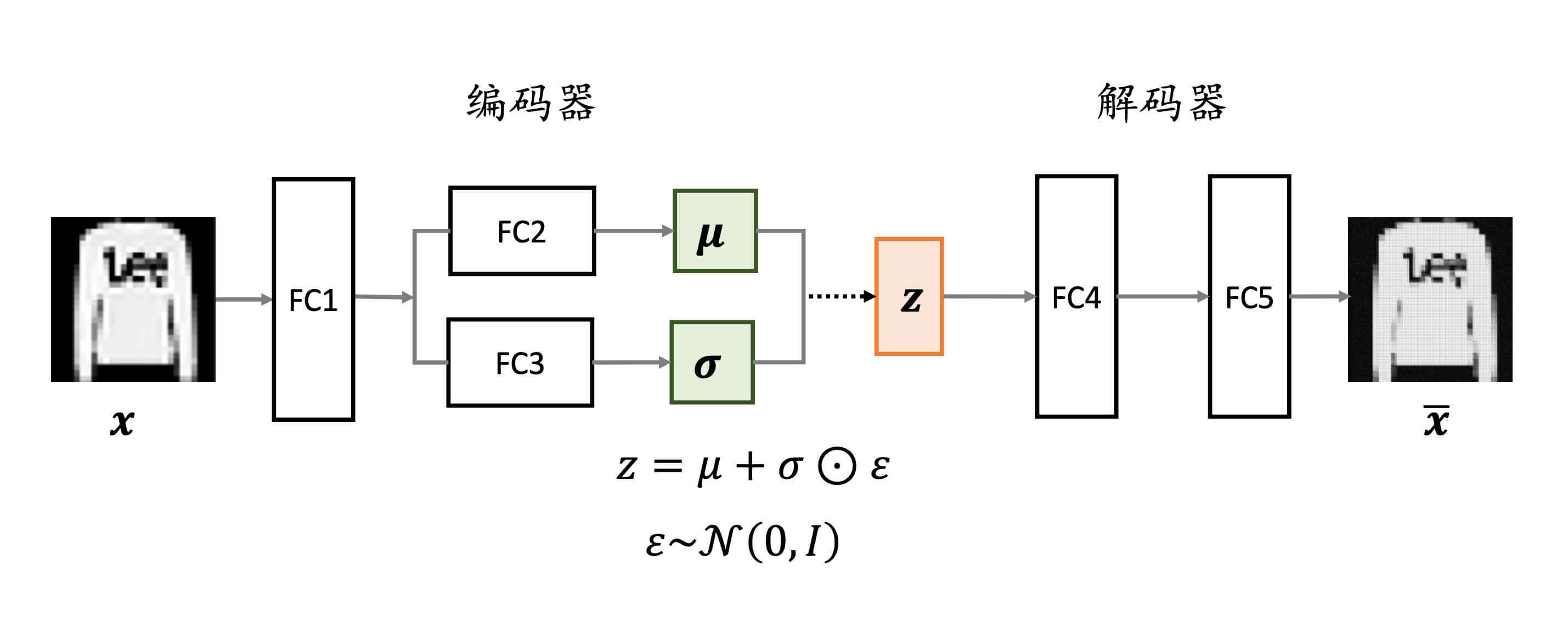
整个网络的结构如下:
通常解码器网络层输出的是log σ 2 \log \sigma^2 log σ 2 σ \sigma σ log σ 2 \log \sigma^2 log σ 2 ( − ∞ , + ∞ ) (-\infty,+\infty) ( − ∞ , + ∞ ) σ 2 \sigma^2 σ 2 [ 0 , + ∞ ) [0,+\infty) [ 0 , + ∞ ) log σ 2 \log \sigma^2 log σ 2 σ \sigma σ
变分自编码器的实现
我们继续以Fashion MNIST的编码解码为例。
初始化方法
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class VAE (Model) : def __init__ (self) : super(VAE, self).__init__() self.fc1 = layers.Dense(128 ) self.fc2 = layers.Dense(10 ) self.fc3 = layers.Dense(10 ) self.fc4 = layers.Dense(128 ) self.fc5 = layers.Dense(784 )
前向计算
接下来,我们来实现前向计算。
1、编码器的前向计算 log σ 2 \log \sigma^2 log σ 2 σ \sigma σ
1 2 3 4 5 6 7 8 9 def encoder (self, x) : h = tf.nn.relu(self.fc1(x)) mu = self.fc2(h) log_var = self.fc3(h) return mu, log_var
2、解码器的前向计算
1 2 3 4 5 6 def decoder (self, z) : out = tf.nn.relu(self.fc4(z)) out = self.fc5(out) return out
3、Reparameterization Trick log σ 2 \log \sigma^2 log σ 2 σ \sigma σ
1 2 3 4 5 6 7 def reparameterize (self, mu, log_var) : eps = tf.random.normal(log_var.shape) std = tf.exp(log_var)**0.5 z = mu + std * eps return z
4、call方法
1 2 3 4 5 6 7 8 9 10 def call (self, inputs, training=None) : mu, log_var = self.encoder(inputs) z = self.reparameterize(mu, log_var) x_hat = self.decoder(z) return x_hat, mu, log_var
模型训练
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 model = VAE() model.build(input_shape=(4 , 784 )) model.summary() optimizer = tf.optimizers.Adam(lr=0.01 ) for epoch in range(5 ): for step, x in enumerate(train_db): x = tf.reshape(x, [-1 , 784 ]) with tf.GradientTape() as tape: x_rec_logits, mu, log_var = model(x) rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits) rec_loss = tf.reduce_sum(rec_loss) / x.shape[0 ] kl_div = -0.5 * (log_var + 1 - mu ** 2 - tf.exp(log_var)) kl_div = tf.reduce_sum(kl_div) / x.shape[0 ] loss = rec_loss + 1. * kl_div grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) if step % 100 == 0 : print(epoch, step, 'kl div:' , float(kl_div), 'rec loss:' , float(rec_loss))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Model: "vae" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) multiple 100480 _________________________________________________________________ dense_1 (Dense) multiple 1290 _________________________________________________________________ dense_2 (Dense) multiple 1290 _________________________________________________________________ dense_3 (Dense) multiple 1408 _________________________________________________________________ dense_4 (Dense) multiple 101136 ================================================================= Total params: 205,604 Trainable params: 205,604 Non-trainable params: 0 _________________________________________________________________ 0 0 kl div: 2.082995891571045 rec loss: 545.6994018554688 0 100 kl div: 14.052530288696289 rec loss: 256.65277099609375 0 200 kl div: 14.115103721618652 rec loss: 253.49703979492188 0 300 kl div: 12.919075012207031 rec loss: 245.1560821533203 0 400 kl div: 12.998880386352539 rec loss: 243.81082153320312 【部分运行结果略】 4 0 kl div: 13.248461723327637 rec loss: 237.49778747558594 4 100 kl div: 12.899820327758789 rec loss: 232.00466918945312 4 200 kl div: 13.066536903381348 rec loss: 235.38673400878906 4 300 kl div: 13.595346450805664 rec loss: 234.9623260498047 4 400 kl div: 13.309326171875 rec loss: 240.35516357421875
评估模型
我们要发挥变分自编码器的优势,做点自编码器不能做的事情。比如:生成样本。
1 2 3 4 5 6 z = tf.random.normal((128 , 10 )) logits = model.decoder(z) x_hat = tf.sigmoid(logits) x_hat = tf.reshape(x_hat, [-1 , 28 , 28 ]).numpy() *255. x_hat = x_hat.astype(np.uint8) printImage(x_hat)
运行结果:
我们看到衣服和鞋子的模样已经画出来了。但这只是一个demo,我们的epoch设置得很低。如果想获得更好的效果,可以调整参数、学习率等。
如果想获得更好的效果,那需要新的模型。生成对抗网络
下一章,我们讨论生成对抗网络 。