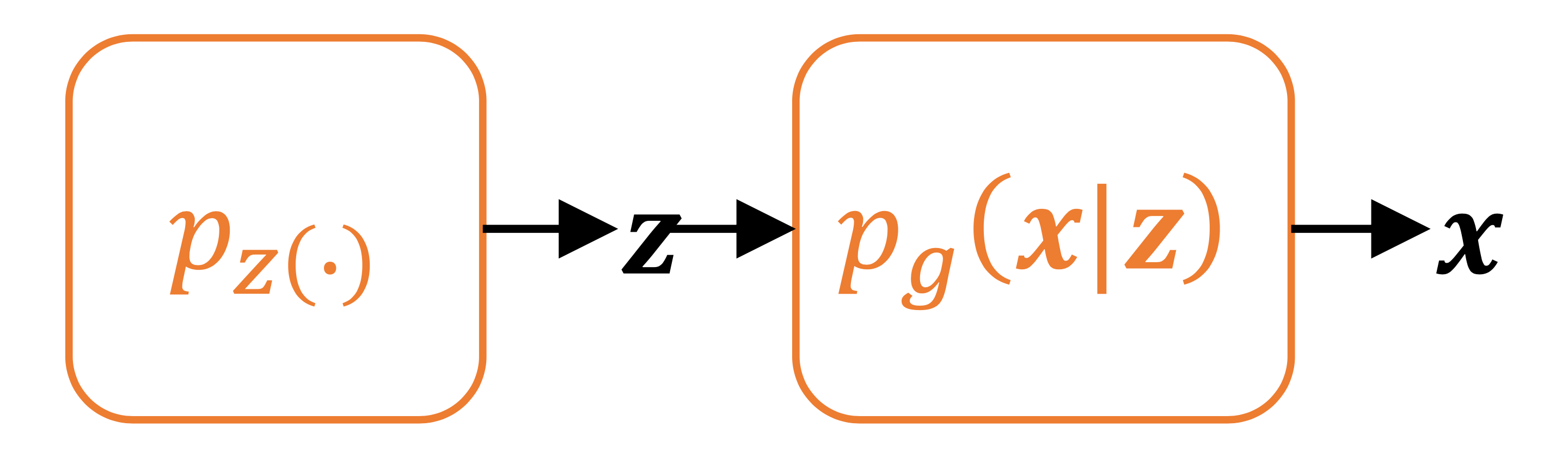这就涉及到我们这一章的主题:生成对抗网络 。
生成对抗网络的原理
网络模型介绍
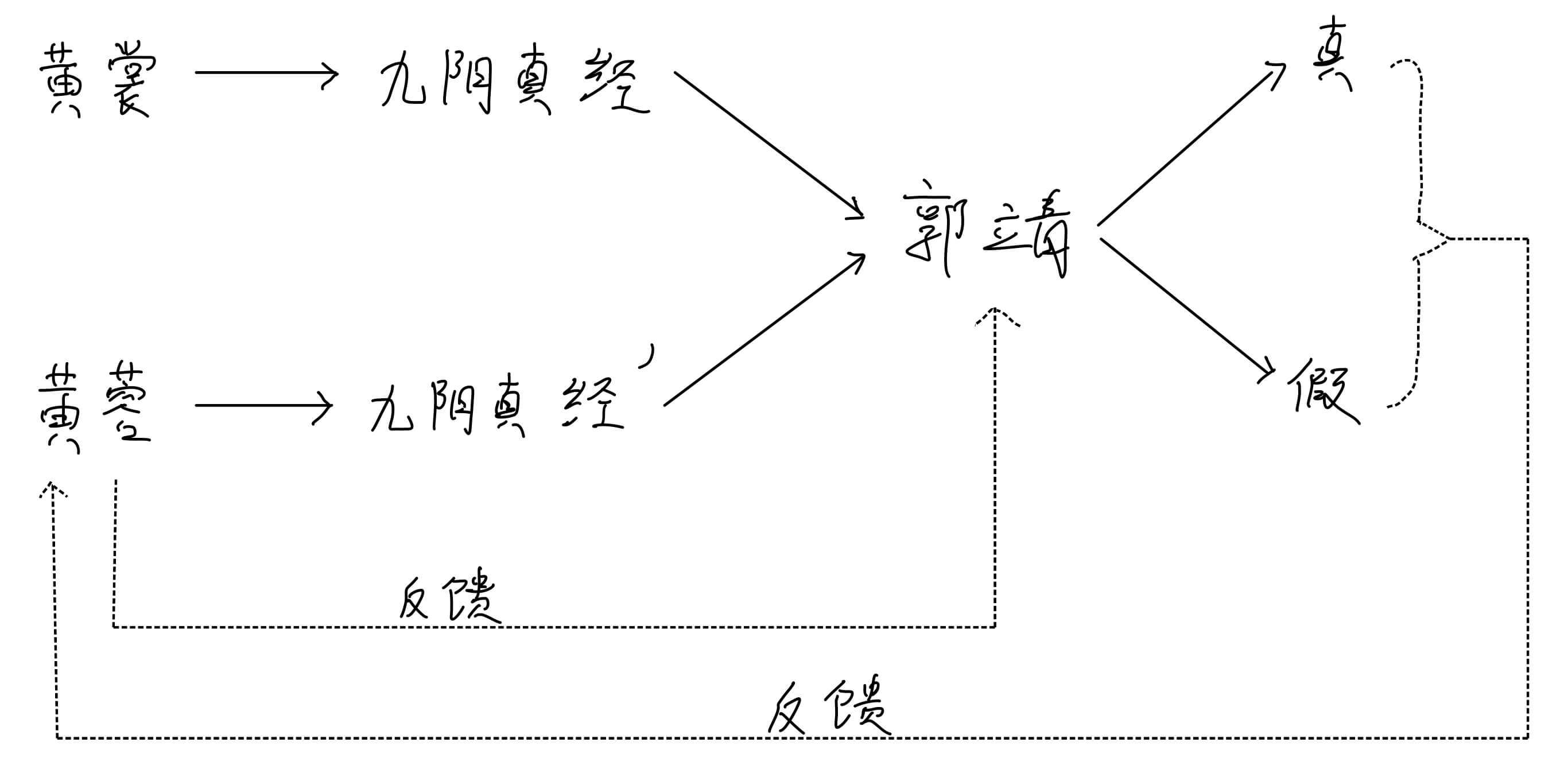
下图就是我们伪造《九阴真经》的方案。
九阴真经是北宋时期黄裳所著,小说的背景是南宋。所以在这个过程中,九阴真经是静态的,就像我们的样本数据 。
九阴真经′ \bold{'} ′
郭靖也是动态的,郭靖的鉴别水平是在不断提升的。
当然,我们的目标不是培养鉴别水平高超的郭靖,而是培养伪造水平高超的黄蓉。
图中还有两条虚线。真和假到黄蓉的这条虚线,含义是鉴别结果会反馈给黄蓉。
当然郭靖也要提高自己的水平,所以,黄蓉也会反馈信息给郭靖。
现在,我们把这个过程抽象出来。
1、样本数据
黄裳写的九阴真经是我们的样本数据,我们表示成{ x i } i = 1 n \{\bold{x_i}\}_{i=1}^{n} { x i } i = 1 n p d a t a p_{data} p d a t a
2、生成网络
黄蓉写的九阴真经′ \bold{'} ′ p g ( x ∣ z ) p_g(\bold{x}|\bold{z}) p g ( x ∣ z ) z ∼ p z \bold{z} \sim p_z z ∼ p z
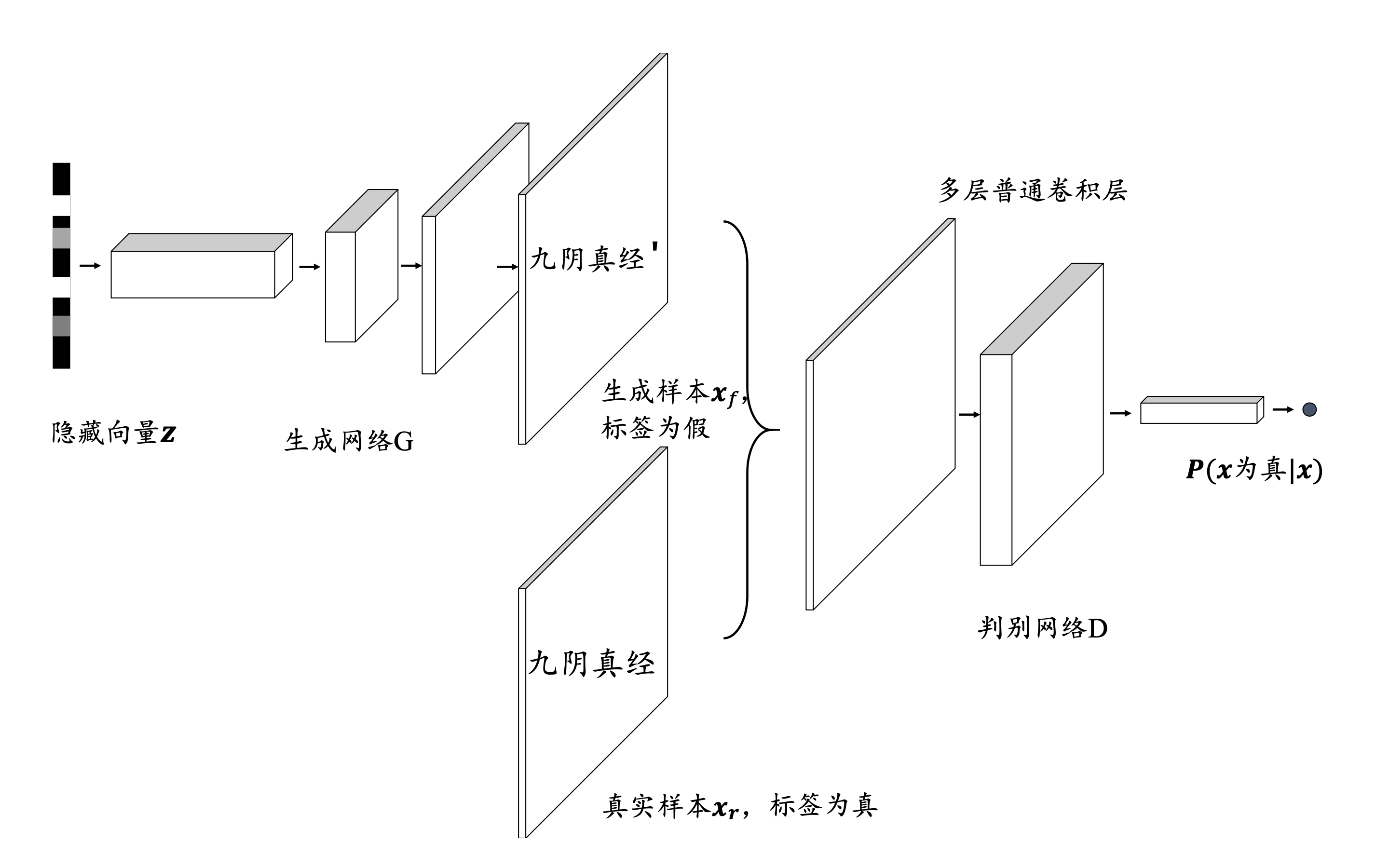
3、郭靖的鉴别
郭靖会对来自黄裳的九阴真经和来自黄蓉的九阴真经′ \bold{'} ′ x \bold{x} x p r p_r p r x r ∼ p r \bold{x_r} \sim p_r x r ∼ p r x f ∼ p g ( x ∣ z ) \bold{x}_f \sim p_g(\bold{x}|\bold{z}) x f ∼ p g ( x ∣ z )
最后,我们把上面的那个方案,抽象成如下。
目标函数
首先,我们的目标是培养伪造水平高超的黄蓉。那么,为了实现这个目标,我们需要:
鉴别水平高超的郭靖
伪造水平高超的黄蓉
鉴别水平高超的郭靖
那么郭靖的鉴别水平高,体现在什么地方?′ \bold{'} ′
即
如果x ∼ p d a t a \bold{x} \sim p_{data} x ∼ p d a t a D ( x ) D(\bold{x}) D ( x )
如果x ∼ p g ( x ) \bold{x} \sim p_g(x) x ∼ p g ( x ) 1 − D ( x ) 1 - D(\bold{\bold{x}}) 1 − D ( x ) z ∼ p z \bold{z} \sim p_z z ∼ p z 1 − D ( G ( z ) ) 1 - D(G(\bold{z})) 1 − D ( G ( z ) )
需要注意的是,为了计算方便,我们通常用log ( D ( x ) ) \log(D(\bold{x})) log ( D ( x ) ) log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(\bold{z}))) log ( 1 − D ( G ( z ) ) )
那么,我们的目标就是:
max D E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \max_D \ \mathbf{E}_{(x \sim p_data)}[\log(D(\bold{x}))] + \mathbf{E}_{\bold{z} \sim p_z}[\log(1 - D(G(\bold{z})))]
D max E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ]
伪造水平高超的黄蓉
那么?怎么体现黄蓉的伪造水平高超呢?如果编撰出来的九阴真经′ \bold{'} ′
min G E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \ \mathbf{E}_{\bold{z} \sim p_z}[\log(1 - D(G(\bold{z})))]
G min E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ]
总目标
先成就郭靖,再实现黄蓉。毕竟要先郭靖鉴别水平高超,然后看不出黄蓉的九阴真经′ \bold{'} ′ 先max \max max min \min min 。
min G max D E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D \ \mathbf{E}_{(x \sim p_data)}[\log(D(\bold{x}))] + \mathbf{E}_{\bold{z} \sim p_z}[\log(1 - D(G(\bold{z})))]
G min D max E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ]
其实,还有一个问题。我们在构造目标函数的时候,完全是类比推理了一个我们认为有道理的目标函数。p g p_g p g p d a t a p_{data} p d a t a p g = p d a t a p_g = p_{data} p g = p d a t a
算法流程
生成对抗网络的算法流程
随机初始化参数θ \theta θ ϕ \phi ϕ repeat for step = 1,2,…,N do z ∼ p z \bold{z} \sim p_z z ∼ p z x r ∼ p r \bold{x_r} \sim p_r x r ∼ p r
∇ θ E x r ∼ p r log D θ ( x r ) + E x f ∼ p g log ( 1 − D θ ( x f ) ) \nabla_{\theta}\ \mathbf{E}_{\bold{x_r} \sim p_r} \log D_{\theta}(\bold{x_r}) + \mathbf{E}_{\bold{x_f} \sim p_g} \log(1 - D_{\theta}(\bold{x}_f)) ∇ θ E x r ∼ p r log D θ ( x r ) + E x f ∼ p g log ( 1 − D θ ( x f ) )
随机采样隐向量z ∼ p z \bold{z} \sim p_z z ∼ p z
∇ ϕ E z ∼ p z log ( 1 − D θ ( G ϕ ( z ) ) ) \nabla_{\phi}\ \mathbf{E}_{\bold{z} \sim p_z} \log (1 - D_{\theta}(G_{\phi}(\bold{z}))) ∇ ϕ E z ∼ p z log ( 1 − D θ ( G ϕ ( z ) ) )
end until 训练达到最大回合数 Epoch 或者达到要求输出 :训练之后的生成器G ϕ G_{\phi} G ϕ
说明:
θ \theta θ ϕ \phi ϕ 对于鉴别器要梯度上升,因为目标是max \max max
对于生成器要梯度下降,因为目标是min \min min
DCGAN的实现
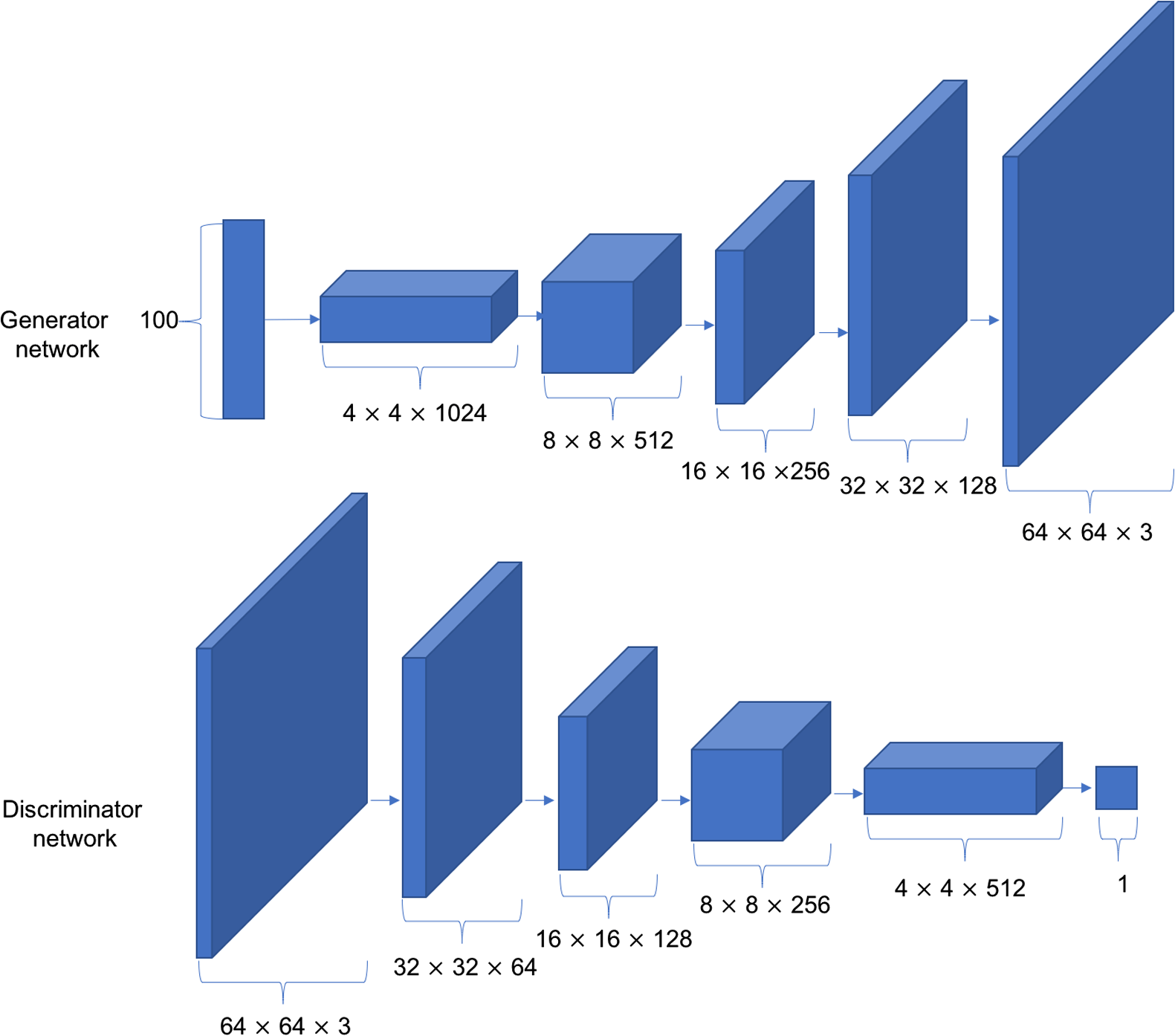
刚刚我们讨论生成对抗网络的时候,一直没有讨论生成器内部结构是什么,鉴别器内部结构是什么。其实这个可以多种多样,完全可以自定义的。其中,最经典的是深度卷积生成对抗网络 (Deep Convolution Generative Adversarial Networks,简称DCGAN)。
其网络结构如图:
接下来,我们来实现一个DCGAN,我们以动漫头像的生成为例。
生成器
生成生成器G由5个转置卷积层单元堆叠而成,实现特征图高宽的层层放大,特征图通道数的层层减少。每个卷积层中间插入BN层来提高训练稳定性。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Generator (Model) : def __init__ (self) : super(Generator, self).__init__() self.fc = layers.Dense(3 * 3 * 512 ) self.conv1 = layers.Conv2DTranspose(256 , 3 , 3 , 'valid' ) self.bn1 = layers.BatchNormalization() self.conv2 = layers.Conv2DTranspose(128 , 5 , 2 , 'valid' ) self.bn2 = layers.BatchNormalization() self.conv3 = layers.Conv2DTranspose(3 , 4 , 3 , 'valid' ) def call (self, inputs, training=None) : x = self.fc(inputs) x = tf.reshape(x, [-1 , 3 , 3 , 512 ]) x = tf.nn.leaky_relu(x) x = tf.nn.leaky_relu(self.bn1(self.conv1(x), training=training)) x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training)) x = self.conv3(x) x = tf.tanh(x) return x
x = tf.tanh(x),所以之后我们的图片数据都要从[0,255]缩小到[-1,1]。
我们还可以传一个z \bold{z} z
1 2 3 g = Generator() z = tf.random.normal([2 ,100 ]) print(g(z).shape)
运行结果:
鉴别器
鉴别器D与普通的分类网络相同,最后通过一个全连接层获得二分类任务的概率。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Discriminator (Model) : def __init__ (self) : super(Discriminator, self).__init__() self.conv1 = layers.Conv2D(64 , 5 , 3 , 'valid' ) self.conv2 = layers.Conv2D(128 , 5 , 3 , 'valid' ) self.bn2 = layers.BatchNormalization() self.conv3 = layers.Conv2D(256 , 5 , 3 , 'valid' ) self.bn3 = layers.BatchNormalization() self.flatten = layers.Flatten() self.fc = layers.Dense(1 ) def call (self, inputs, training=None) : x = tf.nn.leaky_relu(self.conv1(inputs)) x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training)) x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training)) x = self.flatten(x) logits = self.fc(x) return logits
我们还可以传一张图片x \bold{x} x
1 2 3 d = Discriminator() x = tf.random.normal([2 ,64 ,64 ,3 ]) print(d(x))
运行结果:
1 2 3 tf.Tensor( [[-0.11715111] [-0.02971719]], shape=(2, 1), dtype=float32)
损失函数
min G max D E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D \ \mathbf{E}_{(x \sim p_data)}[\log(D(\bold{x}))] + \mathbf{E}_{\bold{z} \sim p_z}[\log(1 - D(G(\bold{z})))]
G min D max E ( x ∼ p d a t a ) [ log ( D ( x ) ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ]
鉴别器的损失函数
对于鉴别器,我们的目标是最大化上面那个式子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def d_loss_fn (generator, discriminator, batch_z, batch_x, is_training) : fake_image = generator(batch_z, is_training) d_fake_logits = discriminator(fake_image, is_training) d_real_logits = discriminator(batch_x, is_training) d_loss_real = celoss_ones(d_real_logits) d_loss_fake = celoss_zeros(d_fake_logits) loss = d_loss_fake + d_loss_real return loss
celoss_ones计算当前预测概率与标签1之间的交叉熵损失。
1 2 3 4 def celoss_ones (logits) : y = tf.ones_like(logits) loss = losses.binary_crossentropy(y, logits, from_logits=True ) return tf.reduce_mean(loss)
celoss_zeros计算当前预测概率与标签0之间的交叉熵损失。
1 2 3 4 def celoss_zeros (logits) : y = tf.zeros_like(logits) loss = losses.binary_crossentropy(y, logits, from_logits=True ) return tf.reduce_mean(loss)
生成器的损失函数
对于生成器来说,真实样本与生成器没有关系。所以只需要最小化E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \mathbf{E}_{\bold{z} \sim p_z}[\log(1 - D(G(\bold{z})))] E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ]
1 2 3 4 5 6 7 8 9 10 def g_loss_fn (generator, discriminator, batch_z, is_training) : fake_image = generator(batch_z, is_training) d_fake_logits = discriminator(fake_image, is_training) loss = celoss_ones(d_fake_logits) return loss
加载数据集
与之前的章节不一样的是,不是来自keras.datasets,需要我们额外进行下载。
数据可以从这里下载:https://pan.baidu.com/s/1Kyk3_iCxL5Lt78m7tUocfA
我们先把数据下载解压之后,然后加载数据。
示例代码:
1 2 3 4 5 6 7 img_paths = glob.glob('./Ch11-Data/*.jpg' ) print(len(img_paths)) dataset, img_shape, len_dataset = Ch11Util.make_anime_dataset(img_paths=img_paths, batch_size=128 , resize=64 ) print(dataset, img_shape, len_dataset) sample = next(iter(dataset)) print(sample.shape)
运行结果:
1 2 3 51223 <PrefetchDataset shapes: (128, 64, 64, 3), types: tf.float32> (64, 64, 3) 400 (128, 64, 64, 3)
然后我们还可以把数据还原回图片。
1 2 3 4 5 6 for i in range(25 ): plt.subplot(5 , 5 , i + 1 ) x = (images[i] + 1.0 ) * 127.5 x = tf.cast(x=x, dtype=tf.int32) plt.imshow(x) plt.show()
运行结果:
另外,我还需要设置一个dataset.repeat(),让dataset的迭代无限。
1 2 dataset = dataset.repeat() db_iter = iter(dataset)
模型训练
实例化生成器和鉴别器
示例代码:
1 2 3 4 5 6 7 8 generator = Generator() generator.build(input_shape=(None , 100 )) discriminator = Discriminator() discriminator.build(input_shape=(None , 64 , 64 , 3 )) print(generator.summary()) print('\n' * 2 ) print(discriminator.summary())
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 Model: "generator_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_2 (Dense) multiple 465408 _________________________________________________________________ conv2d_transpose_3 (Conv2DTr multiple 1179904 _________________________________________________________________ batch_normalization_4 (Batch multiple 1024 _________________________________________________________________ conv2d_transpose_4 (Conv2DTr multiple 819328 _________________________________________________________________ batch_normalization_5 (Batch multiple 512 _________________________________________________________________ conv2d_transpose_5 (Conv2DTr multiple 6147 ================================================================= Total params: 2,472,323 Trainable params: 2,471,555 Non-trainable params: 768 _________________________________________________________________ None Model: "discriminator_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_3 (Conv2D) multiple 4864 _________________________________________________________________ conv2d_4 (Conv2D) multiple 204928 _________________________________________________________________ batch_normalization_6 (Batch multiple 512 _________________________________________________________________ conv2d_5 (Conv2D) multiple 819456 _________________________________________________________________ batch_normalization_7 (Batch multiple 1024 _________________________________________________________________ flatten_1 (Flatten) multiple 0 _________________________________________________________________ dense_3 (Dense) multiple 257 ================================================================= Total params: 1,031,041 Trainable params: 1,030,273 Non-trainable params: 768 _________________________________________________________________ None
创建两个优化器
示例代码:
1 2 g_optimizer = tf.optimizers.Adam(learning_rate=0.002, beta_1=0.5) d_optimizer = tf.optimizers.Adam(learning_rate=0.002, beta_1=0.5)
迭代更新,查看效果
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 for epoch in range(1000000 ): batch_z = tf.random.uniform([128 , 100 ], minval=-1.0 , maxval=1.0 ) batch_x = next(db_iter) with tf.GradientTape() as tape: d_loss = d_loss_fn(generator, discriminator, batch_z, batch_x, True ) grads = tape.gradient(d_loss, discriminator.trainable_variables) d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables)) with tf.GradientTape() as tape: g_loss = g_loss_fn(generator, discriminator, batch_z, True ) grads = tape.gradient(g_loss, generator.trainable_variables) g_optimizer.apply_gradients(zip(grads, generator.trainable_variables)) if epoch % 100 == 0 : print(epoch, 'd-loss:' , float(d_loss), 'g-loss:' , float(g_loss)) z = tf.random.uniform([25 , 100 ]) fake_image = generator(z, training=False ) paintImg(fake_image)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 (2, 64, 64, 3) 51223 <PrefetchDataset shapes: (128, 64, 64, 3), types: tf.float32> (64, 64, 3) 400 (128, 64, 64, 3) 0 d-loss: 1.5906527042388916 g-loss: 1.8171882629394531 100 d-loss: 1.2427457571029663 g-loss: 0.8827457427978516 200 d-loss: 1.4038290977478027 g-loss: 0.8095071911811829 【部分运行结果略】 29800 d-loss: 0.15395832061767578 g-loss: 5.291758060455322 29900 d-loss: 0.18237310647964478 g-loss: 4.279458999633789 30000 d-loss: 0.1850486397743225 g-loss: 4.413983345031738
我找了一台废弃的电脑,那台电脑只有一张集成显卡Intel HD Graphics 520,这玩意不支持TensorFlow的GPU运算,所以只能用CPU运算。且CPU的性能也有限,在运行了近36个小时之后,迭代了30000个epoch,效果如上图。如果有GPU的话,速度会更快。
GAN的不稳定
GAN的不稳定主要体现在超参数敏感和模式崩塌。
超参数敏感
网络结构、学习率、初始化状态等这些都是超参数。这些超参数的一个微小的调整可能导致网络的训练结果截然不同。
为此,DCGAN论文作者提出了不使用Pooling层、多使用Batch Normalization层、不使用全连接层、生成网络中激活函数应使用ReLU、最后一层使用tanh、判别网络激活函数应使用LeakyLeLU等一系列经验性的训练技巧。
模式崩塌
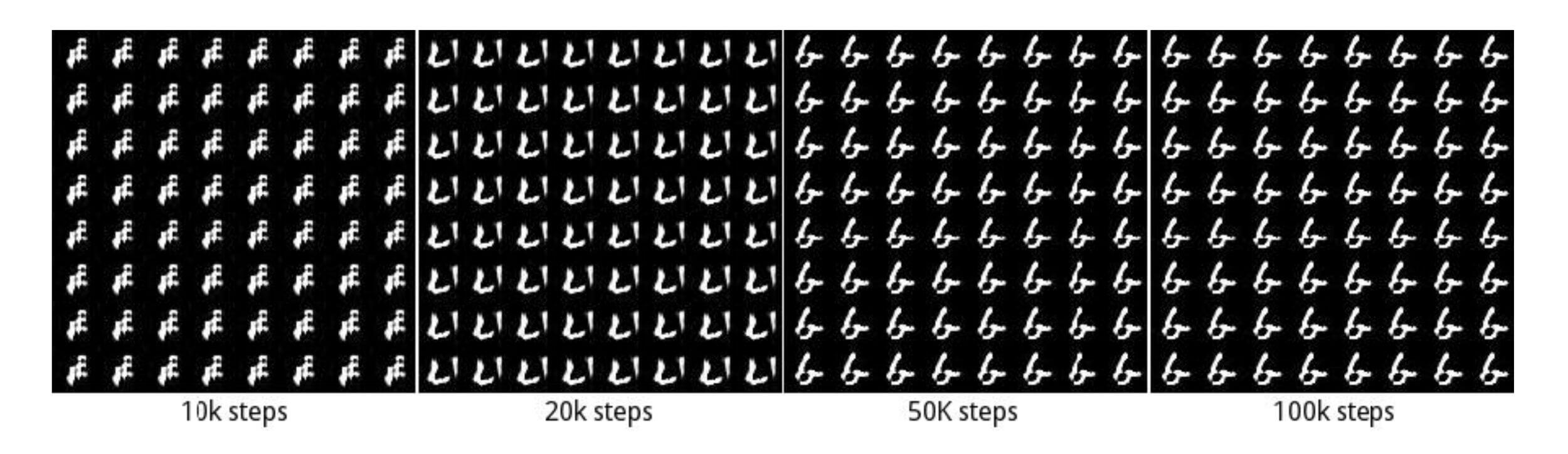
模式崩塌(Mode Collapse)是指模型生成的样本单一,多样性很差的现象。由于鉴别器只能鉴别单个样本是否采样自真实分布,并没有对样本多样性进行约束,导致生成模型倾向于生成真实分布的部分区间中的少量高质量样本,以此来在鉴别器中获得较高的概率值,而不会学习到全部的真实分布。
原因
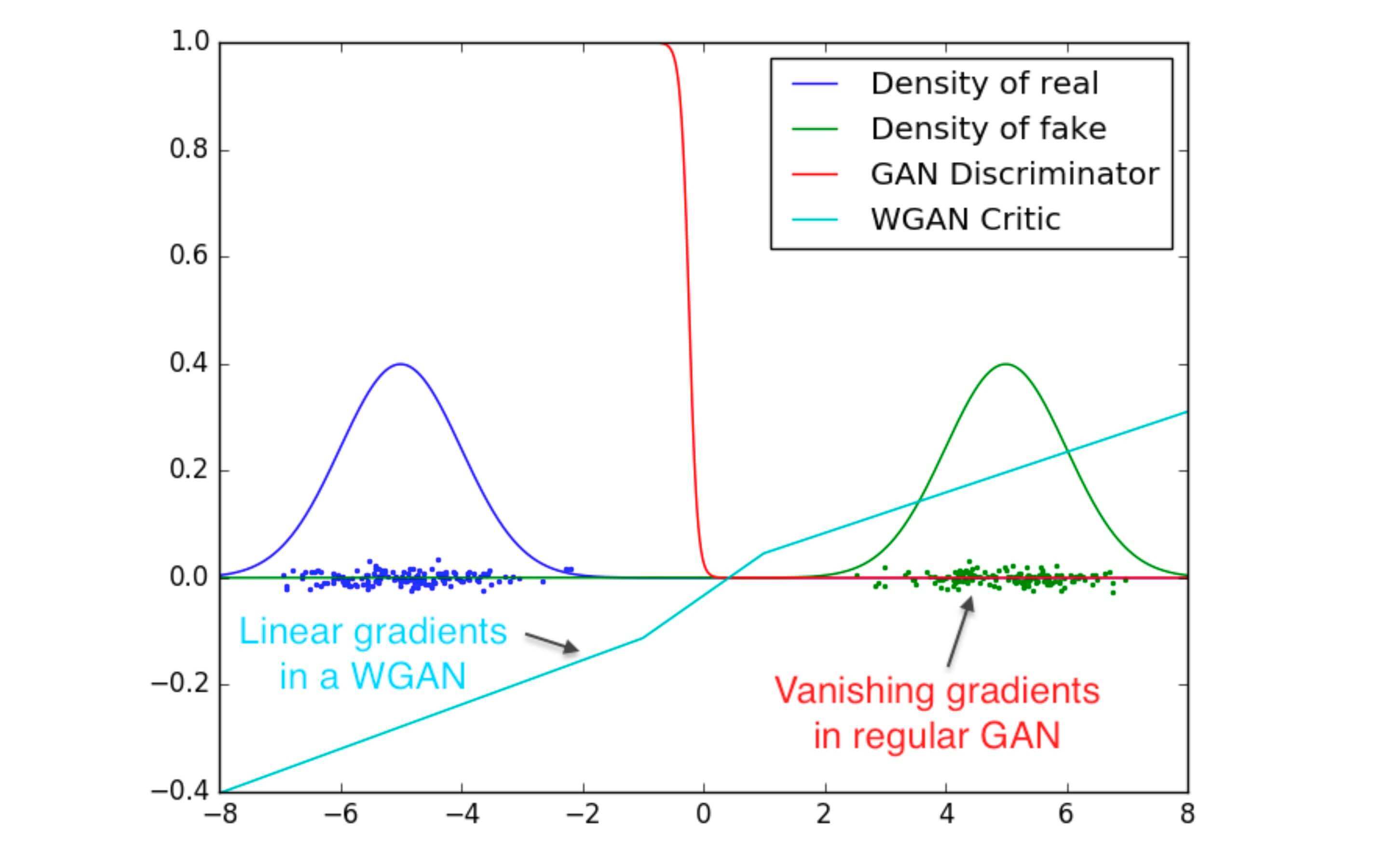
GAN的不稳定性是因为JS散度在不重叠的分布p p p q q q p p p q q q
更通俗的解释是:
WGAN-GP及其实现
WGAN-GP是一种常见的WGAN模型。和GAN的区别主要在三个地方:
梯度惩罚项
鉴别器的损失函数
生成器的损失函数
其他和GAN基本相同。
梯度惩罚项
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def gradient_penalty (discriminator, batch_x, fake_image) : batchsz = batch_x.shape[0 ] t = tf.random.uniform([batchsz, 1 , 1 , 1 ]) t = tf.broadcast_to(t, batch_x.shape) interplate = t * batch_x + (1 - t) * fake_image with tf.GradientTape() as tape: tape.watch([interplate]) d_interplote_logits = discriminator(interplate) grads = tape.gradient(d_interplote_logits, interplate) grads = tf.reshape(grads, [grads.shape[0 ], -1 ]) gp = tf.norm(grads, axis=1 ) gp = tf.reduce_mean( (gp-1. )**2 ) return gp
鉴别器的损失函数
WGAN-GP鉴别器D的损失函数和GAN的不一样。WGAN-GP直接最大化真实样本的输出值,最小化生成样本的输出值,没有交叉熵计算的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 def d_loss_fn (generator, discriminator, batch_z, batch_x, is_training) : fake_image = generator(batch_z, is_training) d_fake_logits = discriminator(fake_image, is_training) d_real_logits = discriminator(batch_x, is_training) gp = gradient_penalty(discriminator, batch_x, fake_image) loss = tf.reduce_mean(d_fake_logits) - tf.reduce_mean(d_real_logits) + 10. * gp return loss, gp
生成器的损失函数
WGAN-GP生成器G的损失函数只需要最大化生成样本在判别器D的输出值即可,同样没有交叉熵的计算过程。
1 2 3 4 5 6 7 8 def g_loss_fn (generator, discriminator, batch_z, is_training) : fake_image = generator(batch_z, is_training) d_fake_logits = discriminator(fake_image, is_training) loss = - tf.reduce_mean(d_fake_logits) return loss
最后一个小技巧,我们可以在一个step中多次训练鉴别器。因为鉴别器越准确,对生成器越有利。 因为:严师出高徒。