138亿年前,宇宙大爆炸。
46亿年前,地球诞生。
40亿年前,在早期的海洋中,出现了最早的生命,生物开始了复杂而漫长的演化。
6亿年前,地球上出现了多细胞的埃迪卡拉生物群,原始的腔肠动物在埃迪卡拉纪的海洋中浮游着。控制它们运动的,是它们体内一群特殊的细胞——神经元。不同于那些主要与附近细胞形成各种组织结构的同类,神经元从胞体上抽出细长的神经纤维,与另一个神经元的神经纤维相会,形成名为突触的单向连接结构。这些最早的神经元,凭着自身的结构特点,组成了一张分布于腔肠动物全身的网络。这就是最早的神经网络。
第一次兴盛
光阴似箭,日月如梭。时间来到1943年。
这一年,心理学家Warren McCulloch和逻辑学家Walter Pitts根据生物神经元结构,提出了最早的神经元数学模型,称为MP神经元模型。
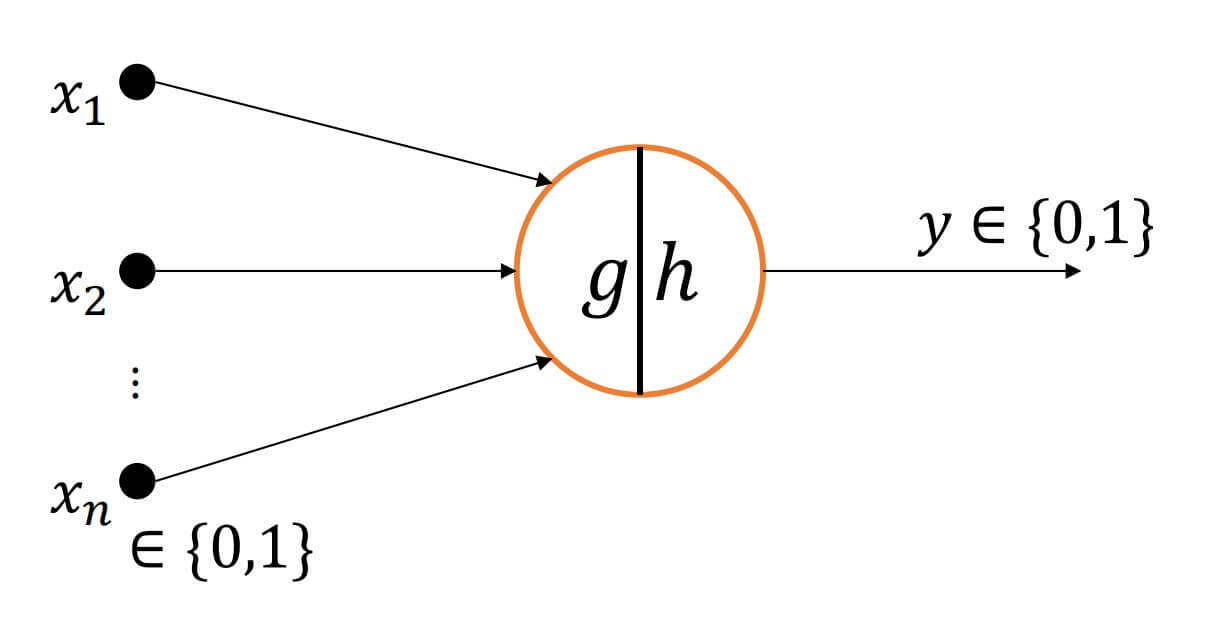
- 。
如果大于一定的阀值,
如果小于一定的阀值,。
但是这个神经元模型,只能处理固定逻辑的判断。
直到1958年,美国心理学家Frank Rosenblatt提出了第一个可以自动学习权重的神经元模型,称为感知机(Perceptron)。

当时的感知机结构如下:
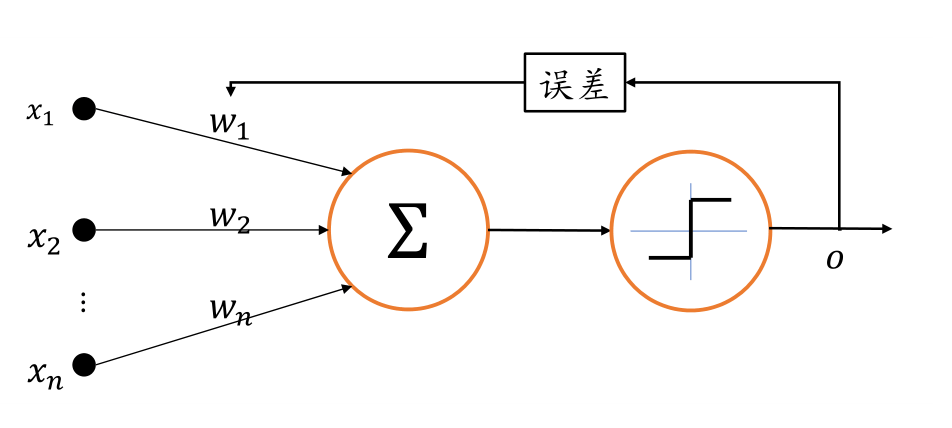
我们看到这时候的感知机已经有权重、误差的概念了,而且还有了激活函数。但,这个激活函数其实是一个阶跃函数,正如我们之前的讨论,阶跃函数的导数要么是0,要么是不可导,这样是没办法梯度下降的。不过,这难不住我们的科学家们,他们仍然有办法去根据误差调整权重,启发式搜索。而且,还真真实实的把感知机造出来了。

这个布满了密密麻麻的导线的机器,就是感知机。可以实现正方形、三角形和圆形的识别。
这个现在看起来功能简单,甚至似乎没有实用价值的东西,在当时可是引起了轰动,第一次人类设计并制造了一个机器,在将其进行训练后,有了智能的雏形。
第一次寒冬
1969年,Marvin Minsky写了一本书,《Perceptrons》。

在书中,他指出了感知机的主要缺陷,无法处理简单的异或等线性不可分问题。而且,从理论上进行了严密的证明。
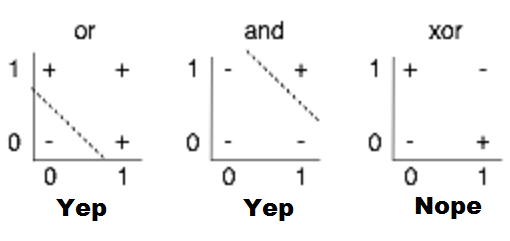
例如,上图中的or和and,都可以用直接用一根直线分割,但是对于xor却无法,这就是线性不可分。
而且在这本书中,他还指出,多层的感知机也不行,多层的感知机,无法进行优化。
这在当时,就像告诉其他科学家,你们的研究是死胡同。我已经从理论上进行了完美的证明。
由此,深度学习进入了第一次寒冬。
但即便是寒冬,仍有许多重大的研究相继发表。而且,在这个黑暗且寒冷的冬天,还有那星星之火在闪烁,反向传播。1974年,Paul Werbos在他的博士论文中第一次提出可以将反向传播算法应用到神经网络上。遗憾的是,在当时,这一成果在并没有获得足够重视。尽管Paul Werbos还为此专程去拜访过Marvin Minsky。
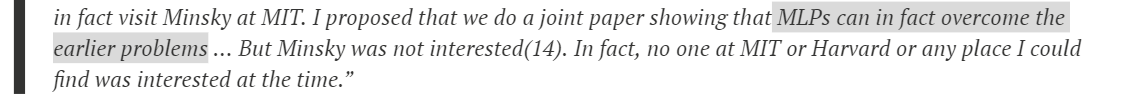
正如Paul Werbos本人所说:no one at MIT or Harvard or any place I could find was interested at the time.
毕竟,寒冬期。
第二次复兴
直到1986年,如今被称为深度学习之父的Geoffrey Hinton等人重新发现了反向传播算法在神经网络的应用,并将其发表在《Nature》上。

由此,开启了这一轮的复兴。
仅仅3年后,1989年,又有一篇重要的论文公布。

这篇论文,从理论上证明了,多层的神经网络可以逼近任何的数据分布。由此,给深度学习带来了一定的理论基础。
同年,Yann LeCun等人将反向传播算法应用在手写数字图片识别上。

并且这套系统成功商用在邮政编码识别、银行支票识别等系统上。
下面的视频就是当时Yann LeCun所拍摄的demo,可以看到当时科学家们的喜悦之情。
除了在手写数字上,在语音识别上,神经网络也取得了一定的成绩。

而且,在当时,已经有循环神经网络的雏形了。随后循环神经网络很快被发明。
在1997年,循环神经网络的变种之一LSTM被Jürgen Schmidhuber提出。

第二次寒冬
在深度学习大放异彩的同时,却有一个更强劲的"对手"在悄悄地孕育而生,支持向量机(Support Vector Machine,简称 SVM)。
1992年,支持向量机出现。

支持向量机拥有严格的理论基础,训练需要的样本数量较少,同时也具有良好的泛化能力,相比之下,神经网络理论基础欠缺,可解释性差,很难训练深层网络,性能也相对一般。深度学习再一次进入寒冬期。
第三次复兴
直到2006年,Geoffrey Hinton再一次开启了深度学习的复兴。两次深度学习陷入寒冬,两次都是Geoffrey Hinton开启复兴。所以他真的是当之无愧的深度学习之父。
他们发现通过逐层预训练的方式可以较好地训练多层神经网络,并在MNIST手写数字图片数据集上取得了优于SVM的错误率。

在论文中,Geoffrey Hinton首次提出了Deep Learning的概念,这也是深度学习这个名词的由来。
2009年,Andrew Y. Ng发表了一篇论文。

提出了用GPU对模型进行训练,所耗费的时间更少。

2011年,Xavier Glorot提出了ReLU激活函数,为更深层次网络铺平了道路。也是现在使用最为广泛的激活函数之一。
这里还有一张ReLU函数和人脑激活模型的对比。
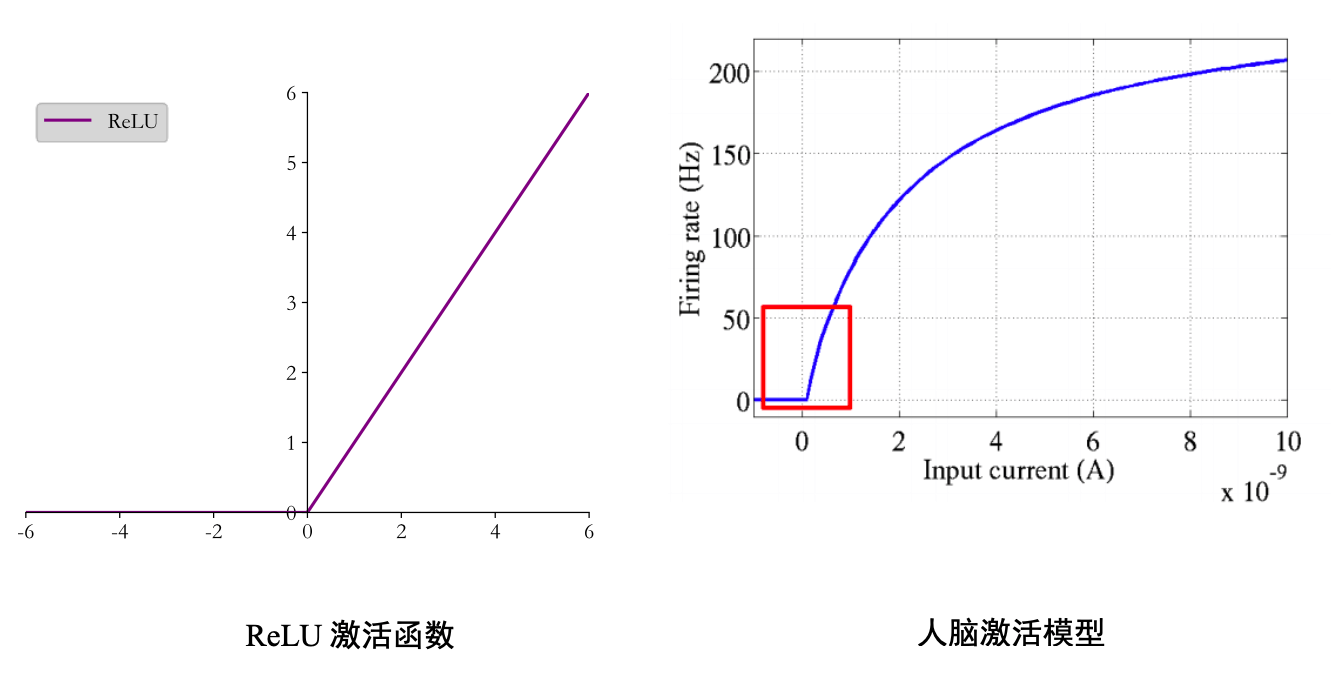
仿佛是上天的安排,ReLU函数和人脑激活模型前半部分如此相似。
2012年,Alex Krizhevsky提出8层的深度神经网络AlexNet,采用ReLU激活函数,并使用了Dropout技术来防止过拟合,直接在两块NVIDIA GTX580 GPU上训练网络。

AlexNet在ILSVRC-2012图片识别比赛中获得了第一名的成绩,比第二名在Top-5错误率上低了惊人的10.9%。自AlexNet模型提出后,各种各样的算法模型相继被发表,其中有VGG系列、GoogLeNet系列、ResNet系列、DenseNet系列等。
2014年,Ian Goodfellow等人提出了生成对抗网络,通过对抗训练的方式学习样本的真实分布,从而生成逼近度较高的样本。

此后,大量的生成对抗网络模型相继被提出,最新的图片生成效果已经达到了肉眼难辨真伪的逼真度。
2016年,Google应用深度神经网络到强化学习领域,提出了深度强化学习算法。

在Atari游戏平台中的49个游戏上取得了与人类相当甚至超越人类的水平。

在围棋领域,Google提出的AlphaGo和AlphaGo Zero智能程序相继打败人类顶级围棋专家李世石、柯洁等。
在多智能体协作的Dota2游戏平台,OpenAI开发的OpenAI Five在受限游戏环境中打败了TI8冠军队伍OG队,展现出了大量专业级的高层智能操作。