核心理论
2.神经网络基础
原文连接:https://kakawanyifan.com/10402
全连接层
全连接层的定义:
每一个结点都与上一层的所有结点相连。
神经网络
神经网络的定义:
由神经元相互连接而成的网络叫做神经网络。
神经网络的结构:
- 输入层
- 隐藏层
- 输出层
输出层
不同的应用场景有不同的输出层。
输出值属于实数空间:
oi∈Rd
常见的应有场景:回归。
输出值在[0,1]的区间:
oi∈[0,1]
常见的应有场景:二分类。
激活函数::sigmoid。
sigmoid(x)=1+e−x1
实现方法:
输出值在[0,1]的区间,并且所有输出值之和为1:
oi∈[0,1]且∑oi=1
常见的应有场景:二分类和多分类。
激活函数:SoftMax。
softmax(zi)=∑1jezjezi
实现方法:
输出值在[-1,1]之间:
oi∈[−1,1]
激活函数:tanh。
tanh(x)=ex+e−xex−e−x
实现方法:
损失函数
常见的损失函数有两中:
- 均方误差(MSE)
- 交叉熵损失(Cross Entropy Loss)
均方误差:
MSE(y,o)=dout1i=1∑dout(yi−oi)2
有时候,为了计算方便,会有非标的均方误差。
两种实现方法:
1
| tf.keras.losses.mean_squared_error()
|
交叉熵损失:
交叉熵的公式
H(p∣∣q)=−i∑pilog2qi
和KL散度的关系
DKL(p∣∣q)代表p和q的KL散度:
DKL(p∣∣q)=∑pilog(qipi)
H(p∣∣q)=H(p)+DKL(p∣∣q)
即
H(p∣∣q)=p的熵+p和q的KL散度
KL散度和交叉熵的不对称性
- DKL(p∣∣q)=DKL(q∣∣p)
- H(p∣∣q)=H(q∣∣p)
当p采用One-Hot编码时
H(p∣∣q)=−logoj
其中j为One-Hot编码中1所在的索引号。
实现方法
1
| tf.losses.categorical_crossentropy()
|
3.梯度下降
原文连接:https://kakawanyifan.com/10403
梯度
整体框架:
导数 ⟶ 偏导数 ⟶ 方向导数 ⟶ 梯度
导数:
f′(x0)=Δx→0limΔxΔy=Δxf(x+Δx)−f(x)
即,随着自变量x的变化,y的变化。是y在x上的变化率。
偏导数:
∂x∂f(x,y)=Δx→0limΔxf(x0+Δx,y0)−f(x0,y0)
即,f(x,y)在点(x0,y0)处对x的偏导数。同理,我们可以知道f(x,y)在点(x0,y0)处对y的偏导数。
函数在不同的坐标轴上的变化率就是偏导数。
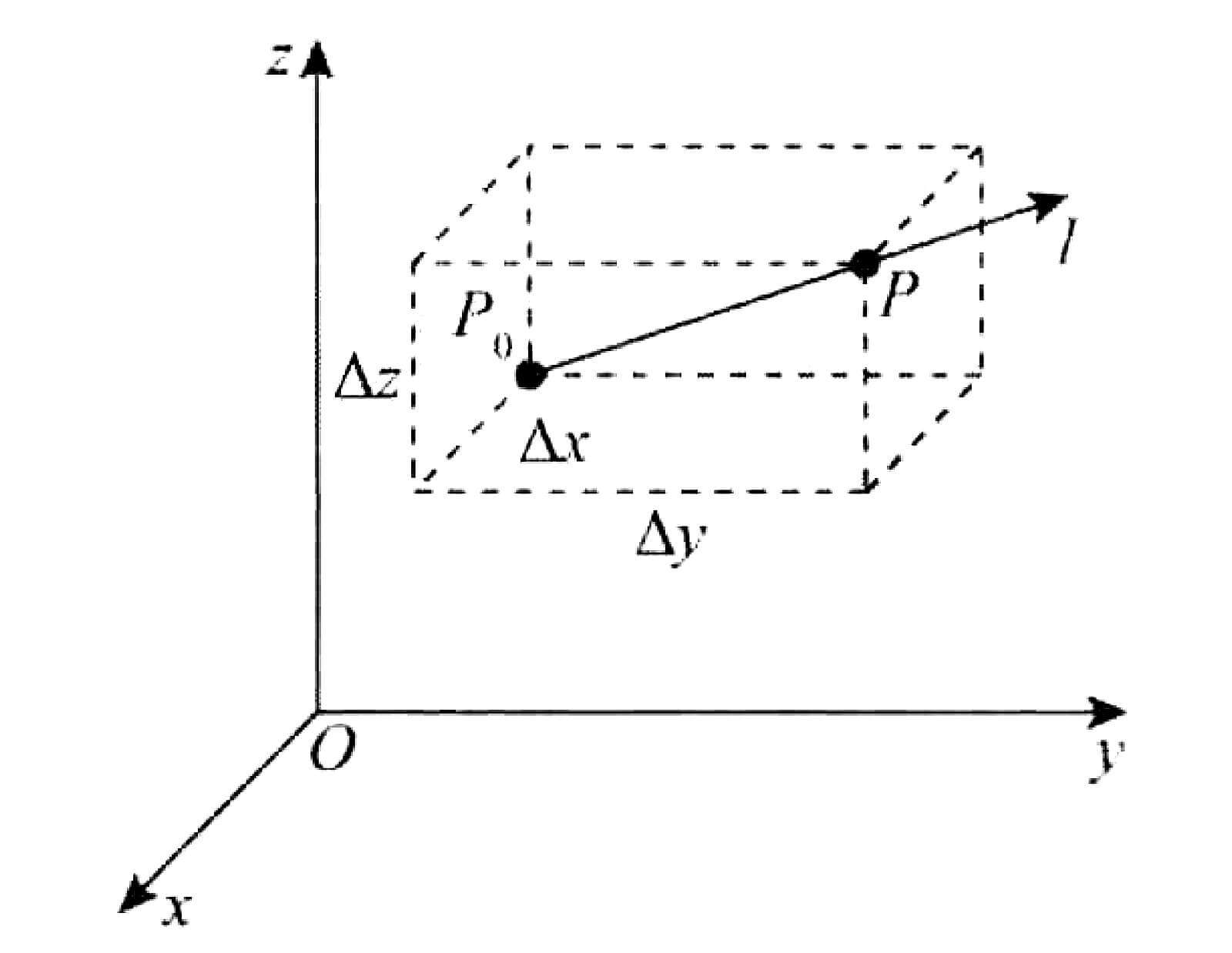
方向导数:
方向导数的定义
函数在某点,沿着某特定方向(不一定是坐标轴)的变化率就是方向导数。

假设存在一个三元函数u=u(x,y,z)在点P0(x0,y0,z0)的某空间领域U⊂R3内有定义,l为从点P0出发的射线,P(x,y,z)为l上的且U内的任一点。则有:
⎩⎪⎪⎨⎪⎪⎧x−x0=Δx=tcosαy−y0=Δy=tcosβz−z0=Δz=tcosγ
其中t表示P到P0之间的距离,t=(Δx)2+(Δy)2+(Δz)2。
t→0+limtu(P)−u(P0)=t→0+limtu(x0+tcosα,y0+tcosβ,z0+tcosγ)−u(x0,y0,z0)
这个极限,就是函数u=u(x,y,z)在P0处,沿方向l的方向导数,记作∂l∂u∣∣∣∣p0
方向导数的计算公式:
假设存在一个三元函数u=u(x,y,z)在P0(x0,y0,z0)处可微,则有:
∂l∂u∣∣∣∣∣p0=ux′(P0)cosα+uy′(P0)cosβ+uz′(P0)cosγ
其中,cosα、cosβ、cosγ是方向l的方向余弦。
梯度:
把方向导数的计算公式,写成这种形式:
∂l∂u∣∣∣∣∣p0=[ux′(P0)uy′(P0)uz′(P0)]⋅⎣⎢⎡cosαcosβcosγ⎦⎥⎤
其中,[ux′(P0),uy′(P0),uz′(P0)]就是grad u,梯度。
方向导数和梯度的关系:
为什么梯度是方向导数最大的方向?
∂l∂u∣∣∣∣∣p0=[ux′(P0)uy′(P0)uz′(P0)]⋅⎣⎢⎡cosαcosβcosγ⎦⎥⎤=grad u∣P0⋅l=∣grad u∣P0∣∗∣l∣∗cosθ
其中,θ是grad u∣P0和l的夹角。而且,∣l∣=1,则有
∂l∂u∣∣∣∣∣p0=∣grad u∣P0∣∗cosθ
显然,当θ=0时候,cosθ取得最大值,∂l∂u∣p0也取得最大值。
函数在某点的梯度是一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
求解梯度的实现方法
- 首先,我们需要用
with tf.GradientTape() as tape:把函数表达式包进去。
- 用
[w_grad] = tape.gradient(func,[w])求解梯度,传入函数和需要求解的参数。返回参数的梯度。
示例代码:
1
2
3
4
5
6
7
8
9
| import tensorflow as tf
with tf.GradientTape() as tape:
x = tf.Variable(1.0)
y = tf.Variable(2.0)
tape.watch([x,y])
z = tf.math.pow(x,2) + tf.math.pow(y,2)
print(tape.gradient(z,[x,y]))
|
运行结果:
1
| [<tf.Tensor: shape=(), dtype=float32, numpy=2.0>, <tf.Tensor: shape=(), dtype=float32, numpy=4.0>]
|
损失函数的梯度
均方误差:
均方误差的公式:
MSE(y,o)=dout1i=1∑dout(yi−oi)2
均方误差的梯度:
∂oi∂L=(oi−yi)
交叉熵
交叉熵的公式:
L=−k=1∑Kyklog(pk)
交叉熵的梯度,非One-Hot编码:
∂zi∂L=pi(yi+k=i∑Kyk)−yi)
交叉熵的梯度,One-Hot编码:
∂zi∂L=pi−yi
4.反向传播
原文链接:https://kakawanyifan.com/10404
链式法则
假设存在函数f(u),而u也是一个函数,u=g(x),则有
∂x∂f(g(x))=∂u∂f(u)∂x∂g(x)=f′(u)g′(x)
反向传播算法
反向传播算法的定义:
误差以某种形式在各层的表现,并以此来修正各层的权重。
对于输出层节点,k∈K,有:
∂wjk∂loss=ojδkK
δkK=(ok−tk)(ok−ok2)
对于输出层的前一个隐藏层,j∈J,有:
∂wij∂loss=oiδjJ
δjJ=(oj−oj2)k=1∑KδkKwjk
对于再前一个隐藏层,i∈I,有
∂wni∂loss=onδiI
δiI=(oi−oi2)j=1∑JδjIwij
其中,on是输入。
依照此规律,只需要循环迭代计算每一层每个节点的δk(K)、δj(J)、δi(I)的值即可求得当前层的偏导数,从而得到每一层每一个节点的权值的梯度。
反向传播的梯度下降方法:
- 网络初始化:对各连接权重赋一个初始值,设定误差函数,设定学习率和最大学习次数。
- 随机选取:随机选取第n个训练样本以及对应的期望输出。
- 隐藏层计算:计算隐藏层各神经元的输入和输出。
- 求偏导数:利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数。
- 修正输出层权值:利用输出层各神经元的偏导数和隐藏层各神经元的输出来修正输出层的权值。
- 修正隐藏层权值:利用当前隐藏层各神经元的偏导数和输入层各神经元的输入修正当前隐藏层的权值。
- 计算误差:用修正后的权重,计算新模型的误差。
- 如此迭代更新。
5.过拟合
原文链接:https://kakawanyifan.com/10405
什么是过拟合
过拟合:
过于复杂的模型,在训练集上表现非常好,但在测试集上表现不如人意。这种现象就是过拟合。
模型的复杂程度:
模型的复杂程度用模型的容量来衡量,模型的容量就是模型假设空间的大小,模型假设空间的大小就是模型可以表示的函数集的大小。
泛化能力:
通过训练集所训练出的模型在测试集上也能表现良好,这个就叫泛化能力较好。反之,则称为泛化能力较差。
交叉验证
例如:4折交叉验证。
| 第一份 |
第二份 |
第三份 |
第四份 |
结果 |
| 验证集 |
训练集 |
训练集 |
训练集 |
当前情况下,模型的准确率 |
| 训练集 |
验证集 |
训练集 |
训练集 |
当前情况下,模型的准确率 |
| 训练集 |
训练集 |
验证集 |
训练集 |
当前情况下,模型的准确率 |
| 训练集 |
训练集 |
训练集 |
验证集 |
当前情况下,模型的准确率 |
在每一种的训练集和验证集下,我们都可以一个得到模型的准确率,对准确率求平均。通过这种方法让模型的评估结果更加准确可信,看看到底是不是过拟合。
-
过拟合:
一个假设在训练数据上能获得比较好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。
-
欠拟合:
一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。
实现方法:在model.fit()中传入validation_split的参数。
1
| model.fit(x_train, y_train, epochs=5,validation_split=validation_split, verbose=1)
|
重新设计模型
如果真的是过拟合了,可以重新设计模型。
提前停止
间隔一定数量的epoch或者一定数量的step,做交叉验证,如果模型的效果持续一定的次数没有提升,就提前停止。
实现方法:
1
2
3
4
5
| early_stopping=tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0,
patience=0, verbose=0, mode='auto',
baseline=None, restore_best_weights=False)
model.fit(callbacks = [early_stopping])
|
参数介绍:
monitor:被监测的数据。min_delta:在被监测的数据中被认为是提升的最小变化, 例如,小于min_delta的绝对变化会被认为没有提升。patience:没有进步的训练轮数,在这之后训练就会被停止。verbose:详细信息模式。mode:{auto,min,max} 其中之一。 在min模式中, 当被监测的数据停止下降,训练就会停止;在max模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。baseline:要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。restore_best_weights:是否从具有监测数量的最佳值的时期恢复模型权重。 如果为False,则使用在训练的最后一步获得的模型权重。
Dropout
Dropout通过随机断开神经网络的连接,减少每次训练时实际参与的参数量;需要注意的是,在测试的时候,Dropout会恢复所有的连接,保证模型测试时获得最好的性能。
两种实现方法:
1
| model.add(layers.Dropout())
|
正则化
在损失函数中加入模型复杂度的惩罚。
L(fθ(x,y))+λ⋅Ω(θ)
Ω(θ)=∑∣∣θi∣∣l
其中
- λ是正则化力度,这是一个超参数。
- ∣∣θi∣∣l表示参数θi的l范数。
常见的有
- L0正则化:Ω(θ)=∑∣∣θi∣∣0,表示θi中非零元素的个数。
- L1正则化:Ω(θ)=∑∣∣θi∣∣1,表示θi中非所有元素的绝对值之和。
- L2正则化:Ω(θ)=∑∣∣θi∣∣2,表示θi中非所有元素的平方和。
两种实现方法:
1
2
3
4
5
6
| # L1 Regularization Penalty
tf.keras.regularizers.L1(0.3)
# L2 Regularization Penalty
tf.keras.regularizers.L2(0.1)
# L1 + L2 penalties
tf.keras.regularizers.L1L2(l1=0.01, l2=0.01)
|
1
2
3
4
5
| layer = tf.keras.layers.Dense(
5, input_dim=5,
kernel_initializer='ones',
kernel_regularizer=tf.keras.regularizers.L1(0.01),
activity_regularizer=tf.keras.regularizers.L2(0.01))
|
动量
添加动量后的修改梯度下降:
zk+1=βzk+f′(wk)
wk+1=wk−lr∗zk+1
实现方法:通过设置momentum参数实现。
1
| optimizers.SGD(learning_rate=0.02,momentum=0.9)
|
1
| optimizers.RMSprop(learning_rate=0.01,momentum=0.02)
|
学习率衰减
学习效率从大到小,逐步衰减。
实现方法:每迭代一定的epoch或者一定的step后,为优化器设置新的学习率。
1
2
3
4
5
6
7
8
9
| optimizer = optimizers.SGD(learning_rate=0.2)
for epoch in range(100):
# 部分代码略
optimizer.learning_rate = 0.2 * (100-epoch)/100
# 部分代码略
|
数据增强
人为添加脏数据或噪音数据等。
常见模型
6.卷积神经网络
原文链接:https://kakawanyifan.com/10406
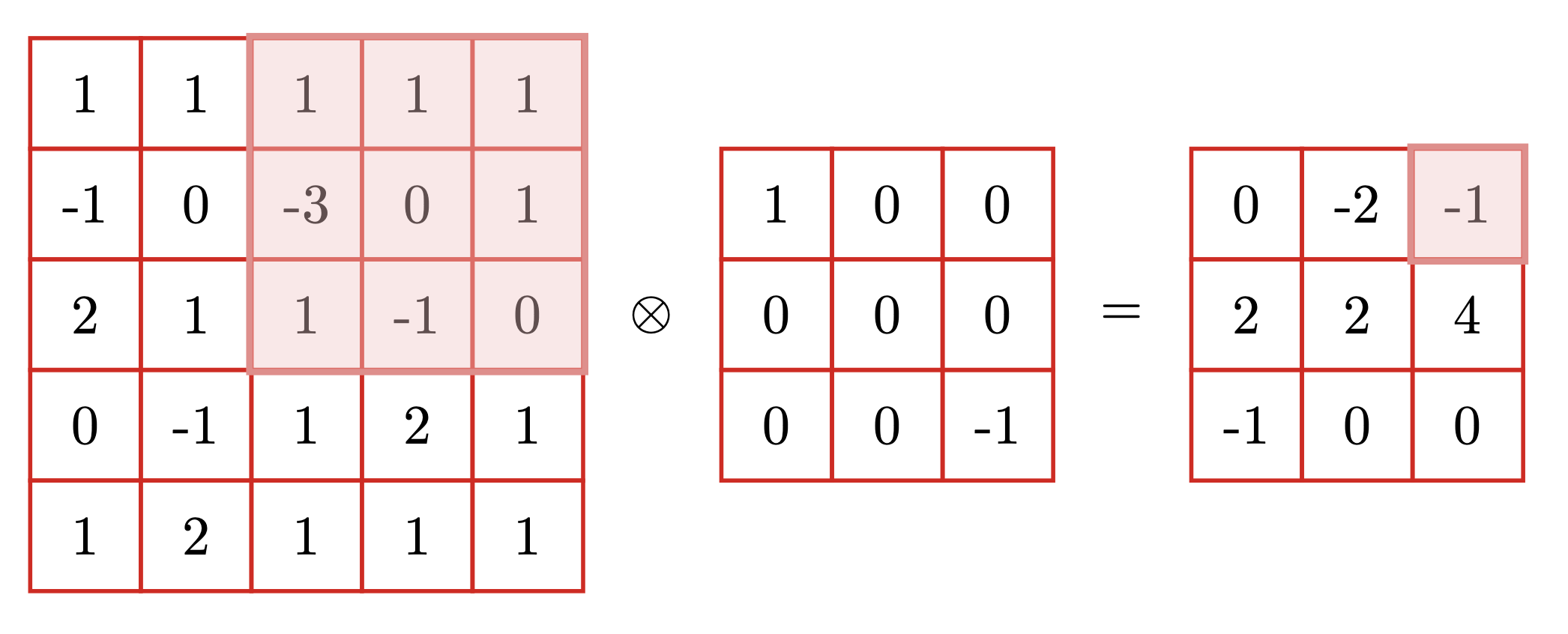
卷积
卷积的两个特点:
- 局部连接
- 权值共享
卷积的运算法则:
翻转卷积
y=u=1∑mv=1∑n=wu,v⋅xm−u+1,n−v+1
不翻转卷积:
y=u=1∑mv=1∑n=wu,v⋅xu,v
通常,在神经网络中,我们所指的的卷积,都是不翻转卷积。
输出和步长、填充的关系:
卷积层的输出尺寸[h′,w′]由卷积核的大小k,步长s,上下填充数量ph,左右填充数量pw以及输入X的高宽[h,w]共同决定:
h′=sh+2⋅ph−k+1
w′=sw+2⋅pw−k+1
- 特别注意:这里只考虑上下填充数量ph,左右填充数量pw相同的情况。
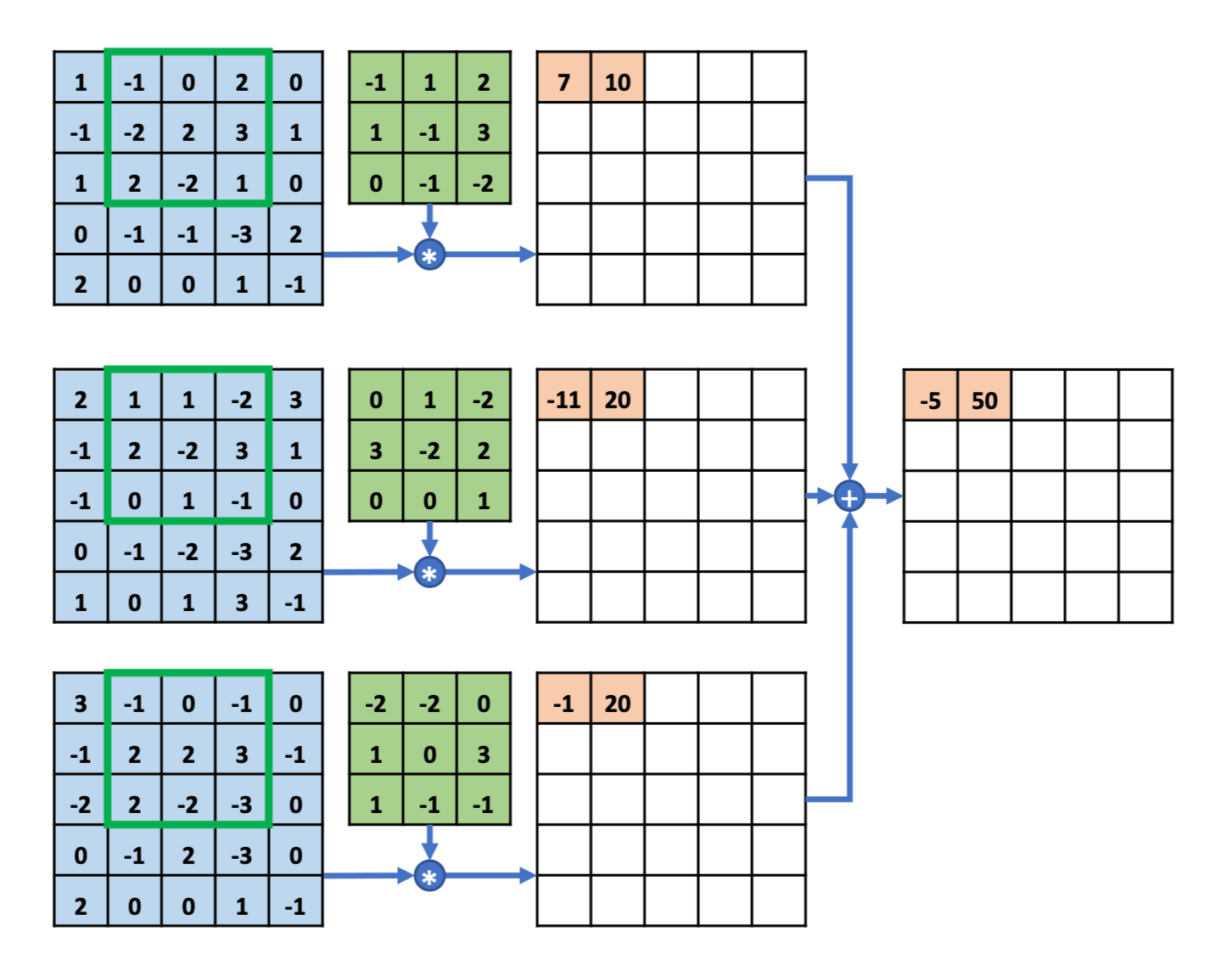
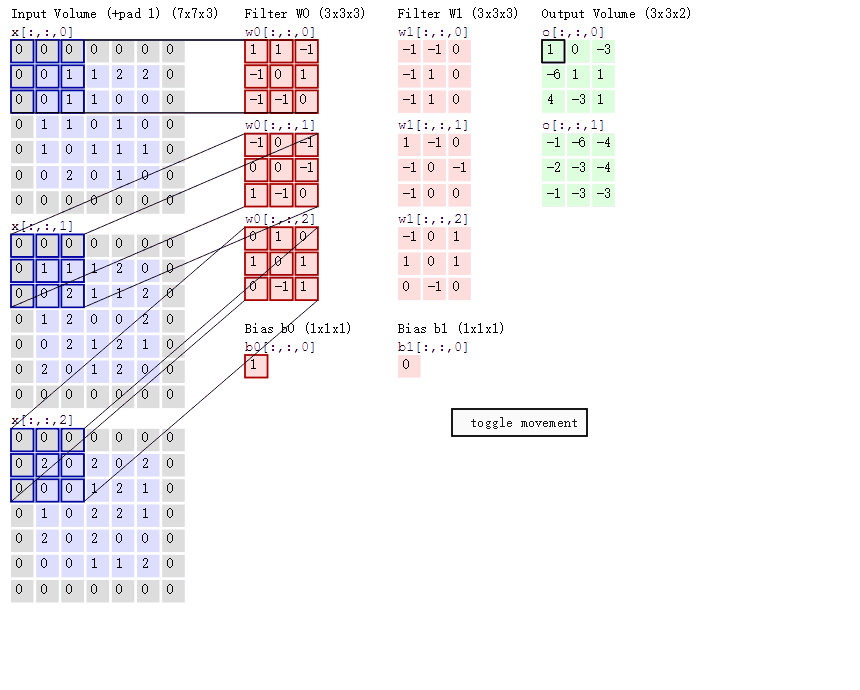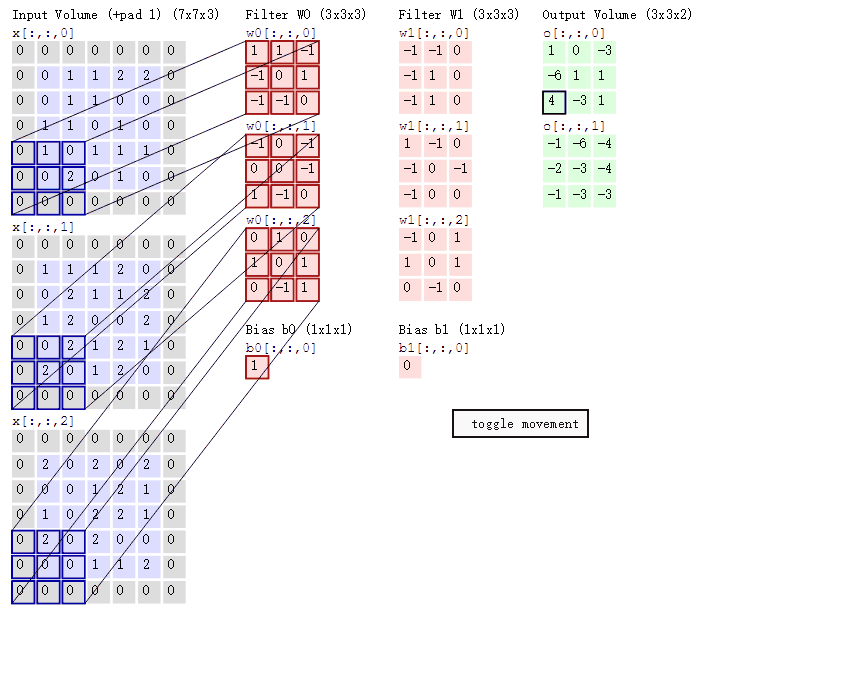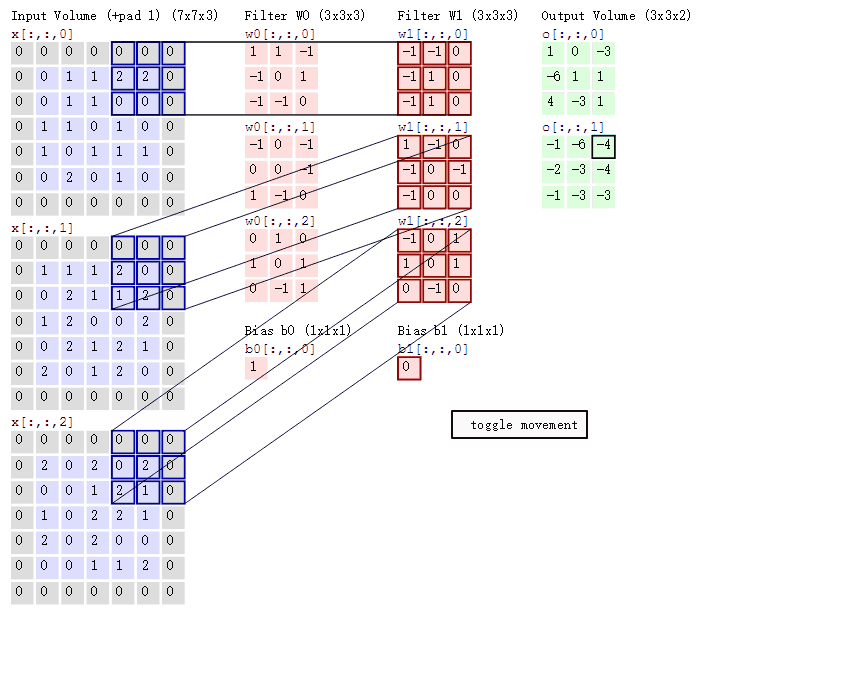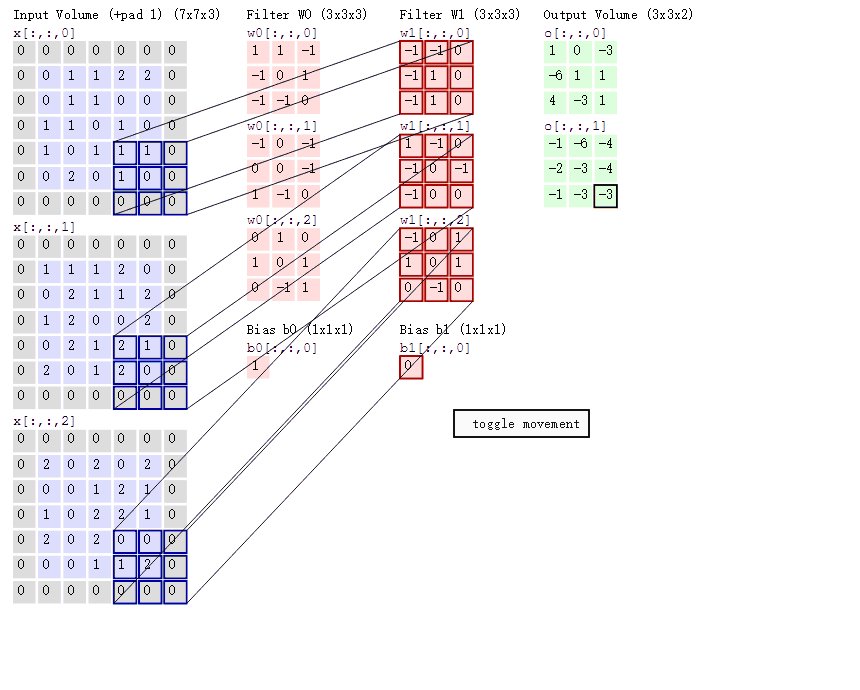
多通道输入的计算:
多通道输入,单卷积核
多通道输入,多卷积核
有几个卷积核,结果就有几个通道。
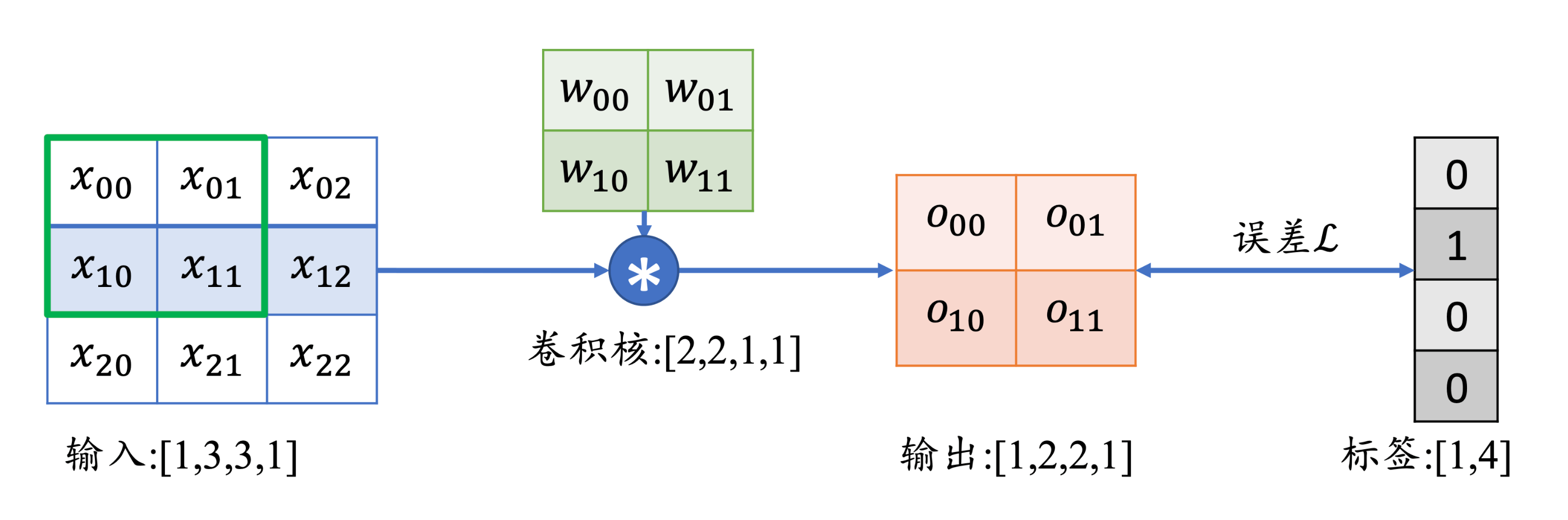
卷积的梯度:
∂w00∂L=i∈{00,01,10,11}∑∂oi∂L∂w00∂oi
卷积层的两种实现方法:
1
| tf.nn.conv2d(input=x,filters=w,strides=1,padding=[[0,0],[0,0],[0,0],[0,0]])
|
池化
池化的一个特点:
局部连接
常见的两种池化:
- 最大池化层(Max Pooling)从局部相关元素集中选取最大的一个元素值。
- 平均池化层(Average Pooling)从局部相关元素集中计算平均值并返回。
池化层的两种实现方法:
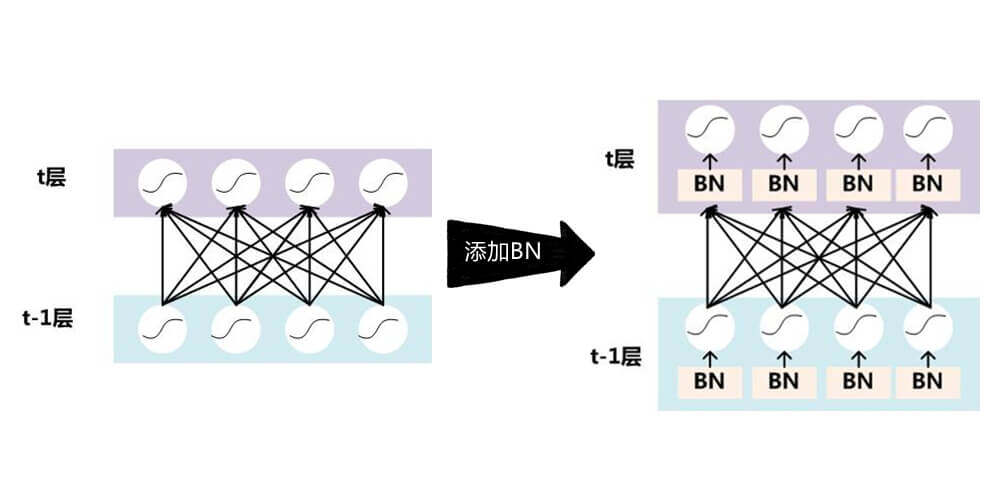
BatchNorm
BatchNorm层所处的位置
BatchNorm的计算公式
训练阶段
x~train=σB2+ϵxtrain−μB⋅γ+β
- μB和σB2是当前Batch的均值和方差。
- ϵ是为防止出现除
0错误而设置的较小数字,如10−9。
- γ和β,将由反向传播算法进行优化。
同时按照
μr←momentum⋅μr+(1−momentum)⋅μB
σr2←momentum⋅σr2+(1−momentum)⋅σB2
迭代更新全局训练数据的统计值μr和σr2。
所以,Batch_Size也是一个超参数了,但在大样本的情况下,影响有限。
测试阶段
x~test=σr2+ϵxtest−μr⋅γ+β
测试阶段的μr和σr2是之前训练阶段所得到的μr和σr2。
BatchNorm的实现方法:
1
| layer = layers.BatchNormalization()
|
7.经典卷积神经网络
原文链接:https://kakawanyifan.com/10407
这一章我们讨论了5个经典的卷积网络:
- AlexNet
- VGG
- GoogLeNet
- ResNet
- DenseNet
但对于这5个经典卷积神经网络,我们都不总结,因为他们都是网络结构不同的卷积神经网络。但是,有一些网络有一些小技巧。
比如:
- GoogLeNet的
Inception
- ResNet的
Skip Connection
Inception
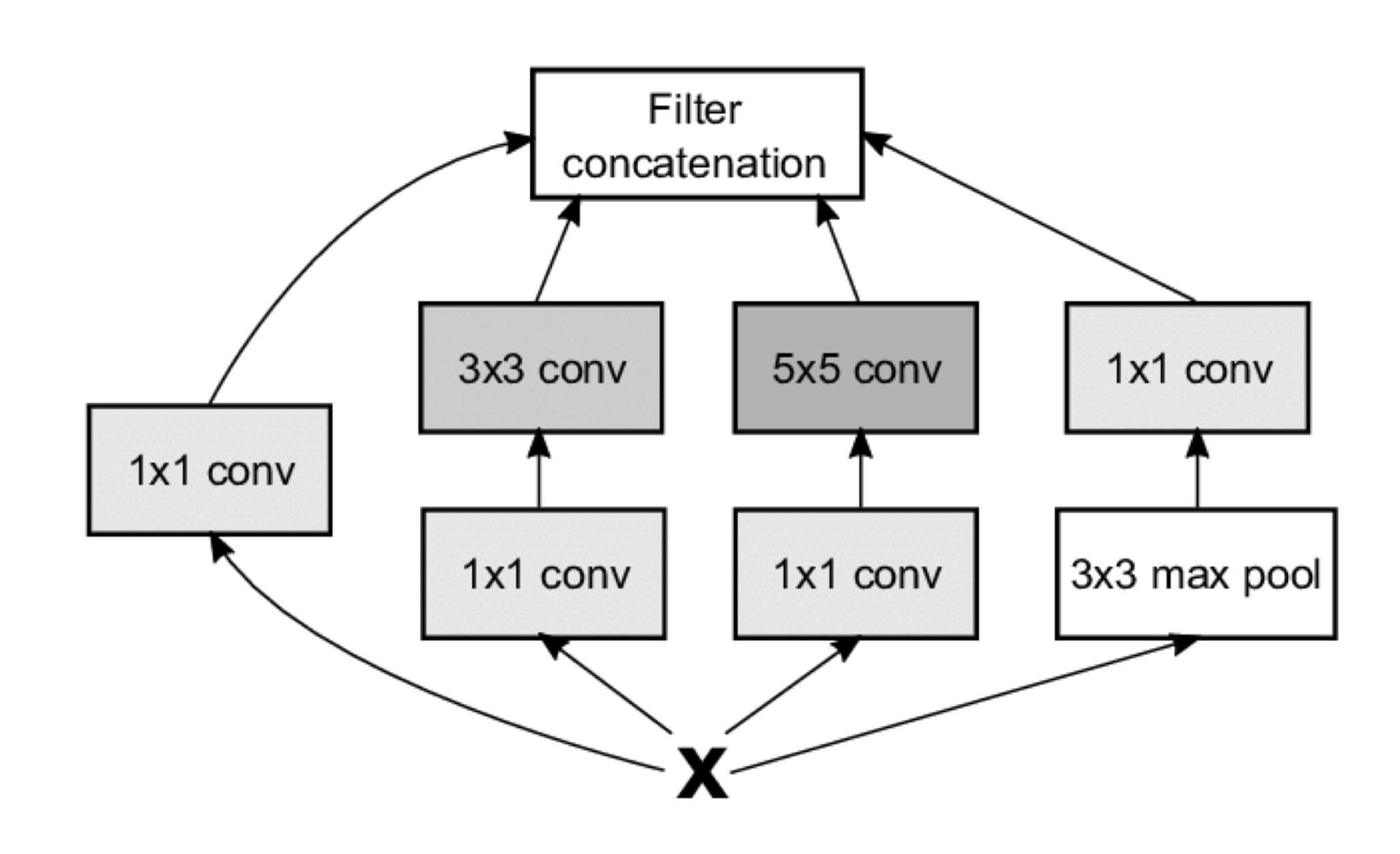
Inception的结构如图所示:
由4个子网络组成,从左到右依次是:
1*1卷积层1*1卷积层 + 3*3卷积层1*1卷积层 + 5*5卷积层3*3最大池化层 + 1*1卷积层
这里每一个卷积层和池化层的步长都是1,padding都是'same'。所以最后的四个子网络的输出和一开始的输入,h相同,w也相同。
四个子网络的输出,会通过Filter concatenation进行合并。
1
| concatenated_tensor = tf.concat(3, [branch1, branch2, branch3, branch4])
|
即,如果存在4个[10*10*3]的数据,会按照深度拼接成[10*10*12]的数据。
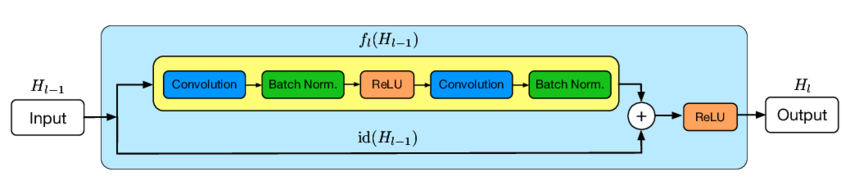
Skip Connection
Skip Connection的机制如下:
H(x)=x+F(x)。
为了保证x和F(x)的Shape相同,可以在Skip Connection中添加额外的卷积运算,比如identity(x)。其中identity(x)以1*1的卷积运算居多,主要用于调整输入的通道数。
8.循环神经网络
原文链接:https://kakawanyifan.com/10408
序列
序列的定义:
序列(Sequence)是具有先后顺序的数据。
One-Hot的缺点:
无法表达词语之间的相似性
Word Embedding:
(100100000000)⎝⎜⎜⎜⎜⎜⎜⎜⎛w11w21w31w41w51w61w12w22w32w42w52w62w13w23w33w43w53w63⎠⎟⎟⎟⎟⎟⎟⎟⎞=(w11w21w12w22w13w23)
输入是One-Hot的全连接层,参数是"字向量表"。
循环神经网络
全连接层的缺点:
不能感知序列顺序,导致句子整体语义的缺失。
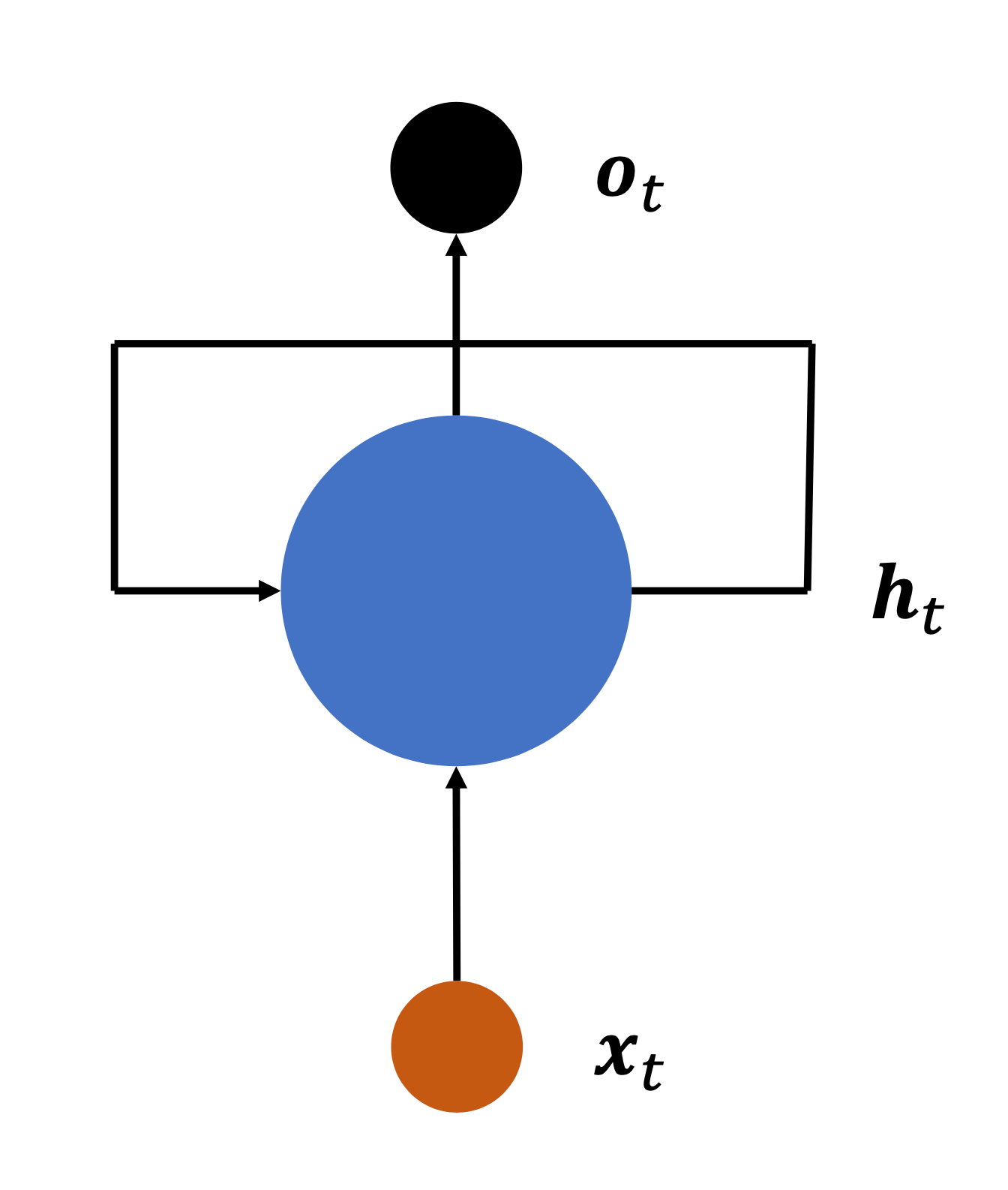
循环神经网络的结构:
ht=tanh(Wxhxt+Whhht−1+b)
ot可以等于ht,也可以在ht的基础上再乘一个东西,Whoht。
循环神经网络的循环是指:网络循环接受序列的每个特征向量xt,并刷新内部状态向量ht,同时形成输出ot。
循环神经网络的梯度弥散和梯度爆炸:
循环神经网络的梯度有Whh的连乘,容易导致梯度爆炸和梯度爆炸
梯度爆炸的解决方法:
1、直接对张量进行限幅
实现方法:
1
| tf.clip_by_value(a,0.4,0.6)
|
2、通过限制张量W的范数进行梯度裁剪
实现方法:
3、全局范数裁剪
神经网络的更新方向是由所有参数的梯度张量W共同决定的,前两种方式只考虑单个梯度张量的限幅,会出现网络更新方向发生变动的情况。
实现方法:
1
| tf.clip_by_global_norm([w1,w2],2)
|
梯度弥散的解决方法:
- 增大学习率。
- 减少网络深度。
- skip connection
RNN层的两种实现方法:
1、基于SimpleRNNCell
我们可以在RNN层的Call方法中,循环调用RNNCell的前向计算,这样能最便捷的实现权值共享。这也是循环神经网络的循环。
2、基于SimpleRNN
循环神经网络的缺点:
长程依赖,或者说"RNN会遗忘"。
9.LSTM和GRU
原文链接:https://kakawanyifan.com/10409
LSTM
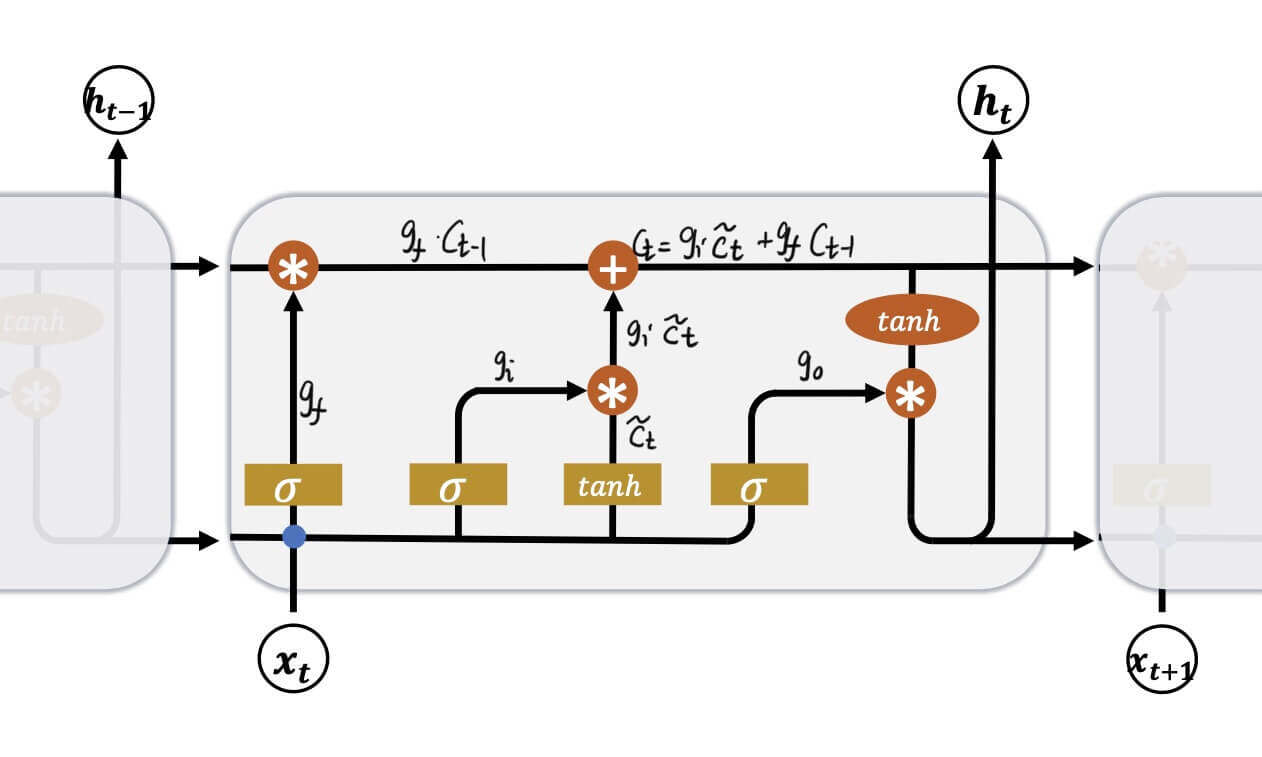
LSTM的结构:
三扇门:
遗忘门:gf输入门:gi输出门:go=σ(Wf⋅[ht−1,xt]+bf)=σ(Wi⋅[ht−1,xt]+bi)=σ(Wo⋅[ht−1,xt]+bo)
这三扇门都是由ht−1和xt控制的。
一个中间状态
c~t=tanh(Wc⋅[ht−1,xt]+bc)
两个输出
ctht=gic~t+gfct−1=go∗tanh(ct)
LSTM克服了梯度弥散:
只要没有忘记,或者几乎没有忘记。即遗忘门控gf=1或遗忘门控gf≈1,就不会梯度弥散。
两种LSTM层的实现方法:
1、基于LSTMCell
2、基于LSTM
和RNN相比,LSTM的优缺点:
优点:
- 具有更长的记忆能力
- 不容易出现梯度弥散现象
缺点:
- LSTM结构相对复杂,计算代价较高,模型参数量较大。
GRU
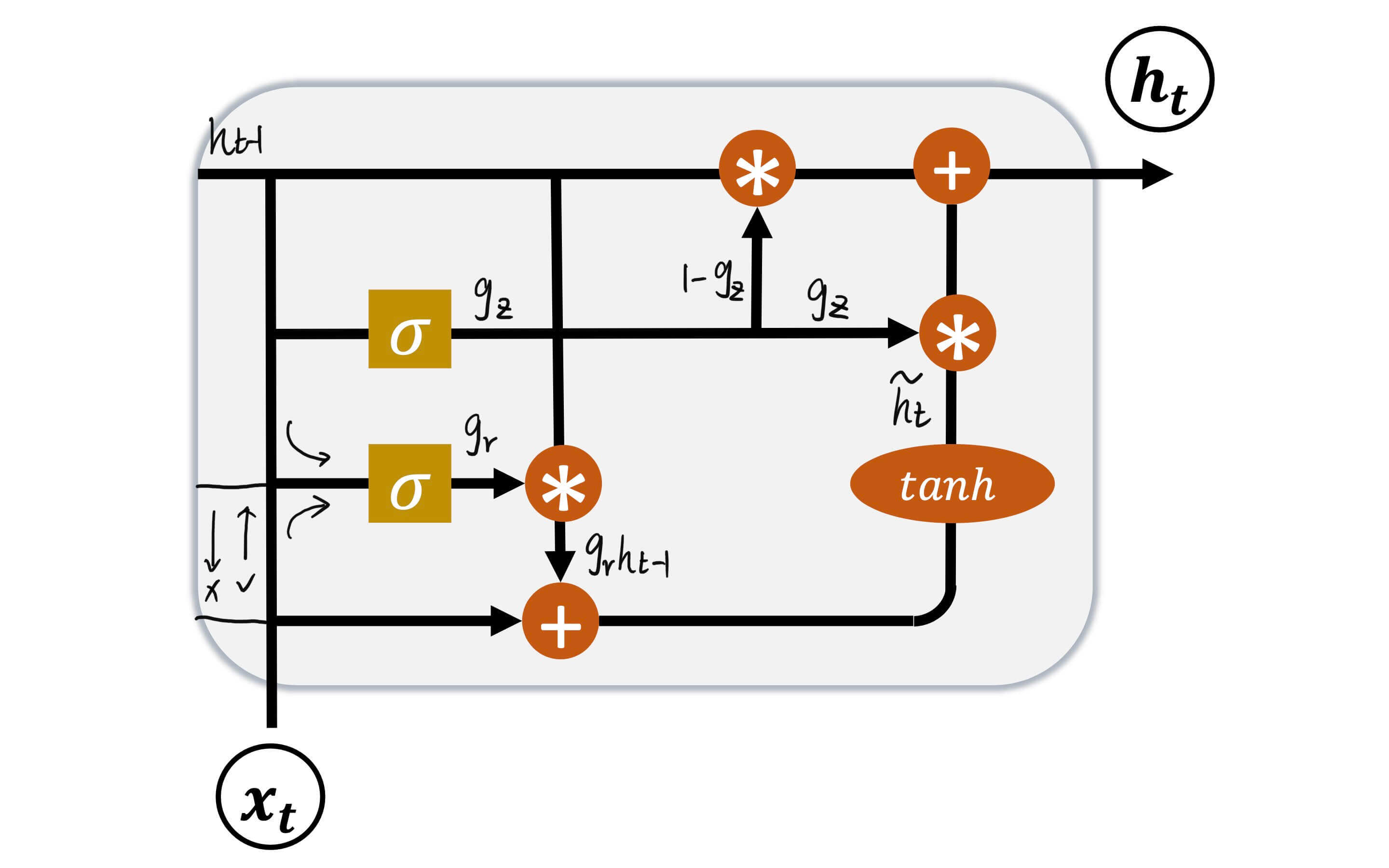
GRU的结构:
两扇门:
复位门:gr=σ(Wr[ht−1,xt]+br)更新门:gz=σ(Wz[ht−1,xt]+bz)
这两扇门都是由ht−1和xt控制的。
一个中间状态:
h~t=tanh(Wh⋅[grht−1,xt]+bh)
一个输出:
ht=(1−gz)ht−1+gzh~t
10.自编码器
原文链接:https://kakawanyifan.com/10410
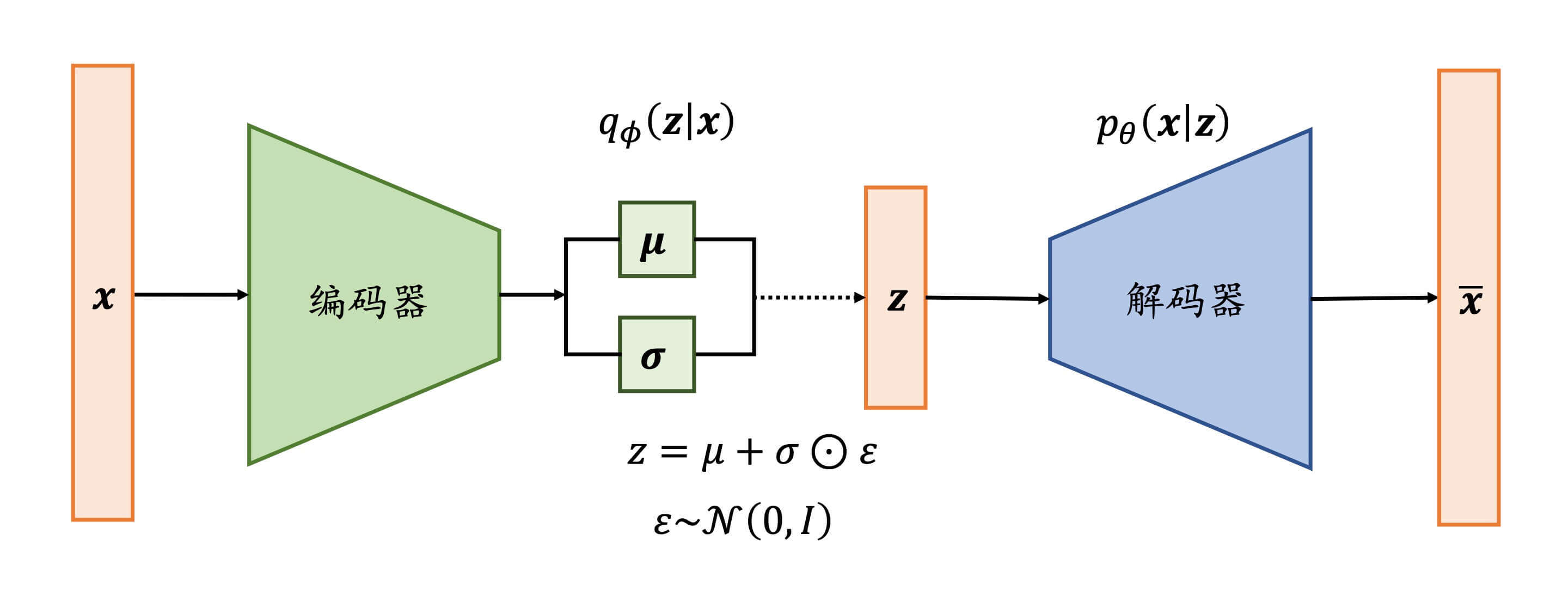
编码器
编码器的结构:
- 函数f()是编码器,z=f(x)。
- 函数g()是解码器,x=g(z)=g(f(x))。
- 损失函数loss=dist(x,x),通常用欧式距离(两点间的距离)。
模型评估:
一般依赖于人工主观评价图片生成的质量,也有一些图片逼真度计算方法。
KL散度
(这一章我们再讨论了KL散度,但是总体和第二章类似,所以不再重复总结。)
变分自编码器
变分自编码器的结构:
- 用一个分布qϕ(z∣x)去逼近p(z∣x)。
- 通常解码器网络层输出的是logσ2,而不是σ,这么做的原因是logσ2(−∞,+∞),而σ2的值域是[0,+∞)。相当于自带激活函数。后面再把logσ2还原回σ。
损失函数:
损失函数的推导过程:
ϕminDKL(qϕ(z∣x)∣∣p(z∣x)) ⟶ maxL(ϕ,θ)⟶{minDKL(qϕ(z∣x)∣∣p(z))maxEz∼q[logpθ(x∣z)]
Reparameterization Trick
通过z=μ+σ⊙ε进行采样,这样同时保证梯度传播是连续的。
11.生成对抗网络
原文链接:https://kakawanyifan.com/10411
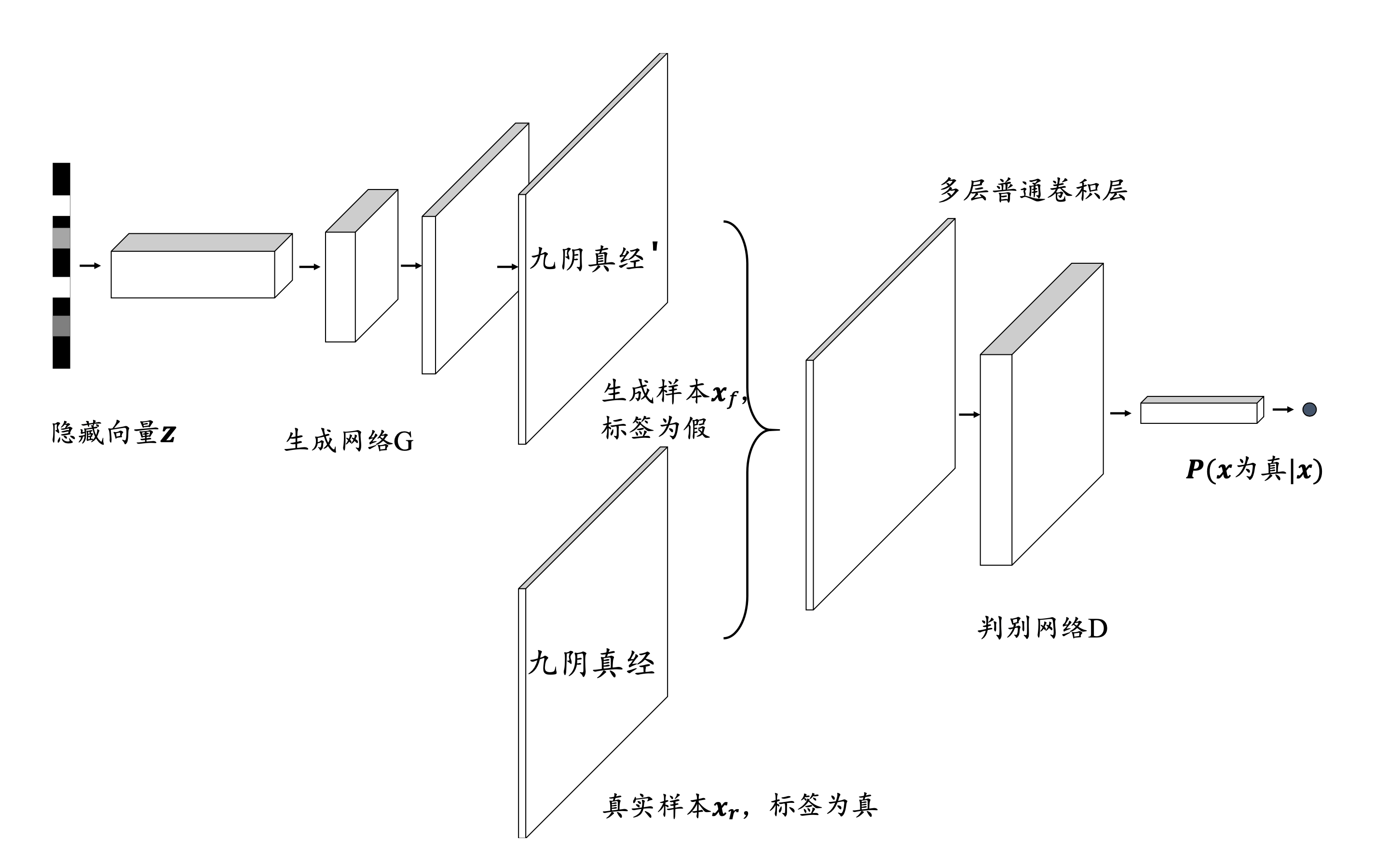
生成对抗网络的解释
生成对抗网络的结构:
目标函数:
对于鉴别器:
Dmax E(x∼pdata)[log(D(x))]+Ez∼pz[log(1−D(G(z)))]
对于生成器:
Gmin Ez∼pz[log(1−D(G(z)))]
总目标:
先实现鉴别器,再成就生成器。先max,再min。
GminDmax E(x∼pdata)[log(D(x))]+Ez∼pz[log(1−D(G(z)))]
算法流程:
随机初始化参数θ和ϕ
repeat
for step = 1,2,…,N do
随机采样 z∼pz
随机采样真实样本xr∼pr
根据梯度上升算法更新鉴别器D网络:
∇θ Exr∼prlogDθ(xr)+Exf∼pglog(1−Dθ(xf))
随机采样隐向量z∼pz
根据梯度下降算法更新生成器G网络:
∇ϕ Ez∼pzlog(1−Dθ(Gϕ(z)))
end
until 训练达到最大回合数 Epoch 或者达到要求
输出:训练之后的生成器Gϕ
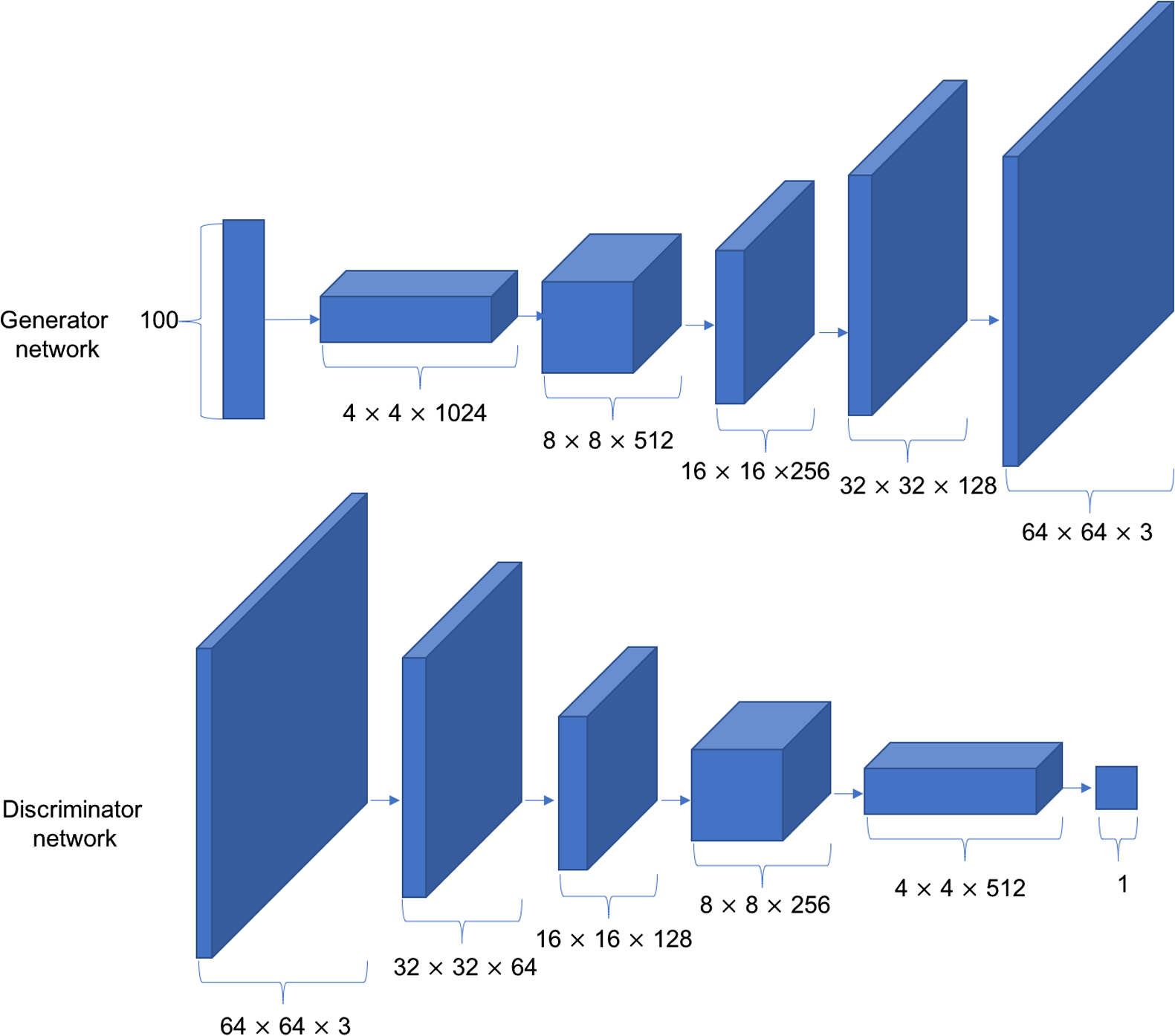
DCGAN的结构
生成器内部结构和鉴别器内部结构,可以多种多样,完全可以自定义的。其中,最经典的是深度卷积生成对抗网络(Deep Convolution Generative Adversarial Networks,简称DCGAN)。
GAN的不稳定性
两个不稳定性:
- 超参数敏感
网络结构、学习率、初始化状态等这些都是超参数。这些超参数的一个微小的调整可能导致网络的训练结果截然不同。
- 模式崩塌
生成模型倾向于生成真实分布的部分区间中的少量高质量样本,以此来在鉴别器中获得较高的概率值,而不会学习到全部的真实分布。导致生成器生成的样本单一,多样性很差。
原因:
JS散度在不重叠的分布p和q上的梯度曲面是恒为0的。
WGAN-GP
WANG-GP克服了不稳定性。和GAN相比有三个主要区别。
- 梯度惩罚项
- 鉴别器的损失函数
直接最大化真实样本的输出值,最小化生成样本的输出值,没有交叉熵计算的过程。
- 生成器的损失函数
只需要最大化生成样本在判别器D的输出值即可,同样没有交叉熵的计算过程。
12.强化学习初探
原文链接:https://kakawanyifan.com/10412
强化学习
强化学习的定义:
智能体(agent)在和环境(environment)的交互中学习,根据环境的状态(state),执行动作(action),并根据环境的反馈(reward)来指导更好的动作。
两个主体:
- 智能体(agent)
- 环境(environment)
三个要素:
- 状态(state)
- 动作(action)
- 反馈(reward)
和监督学习,无监督学习的区别:
- 监督学习是寻找输入到输出之间的映射
- 无监督学习是寻找数据之间的隐藏关系
- 强化学习是在与环境的交互中学习和寻找最佳决策
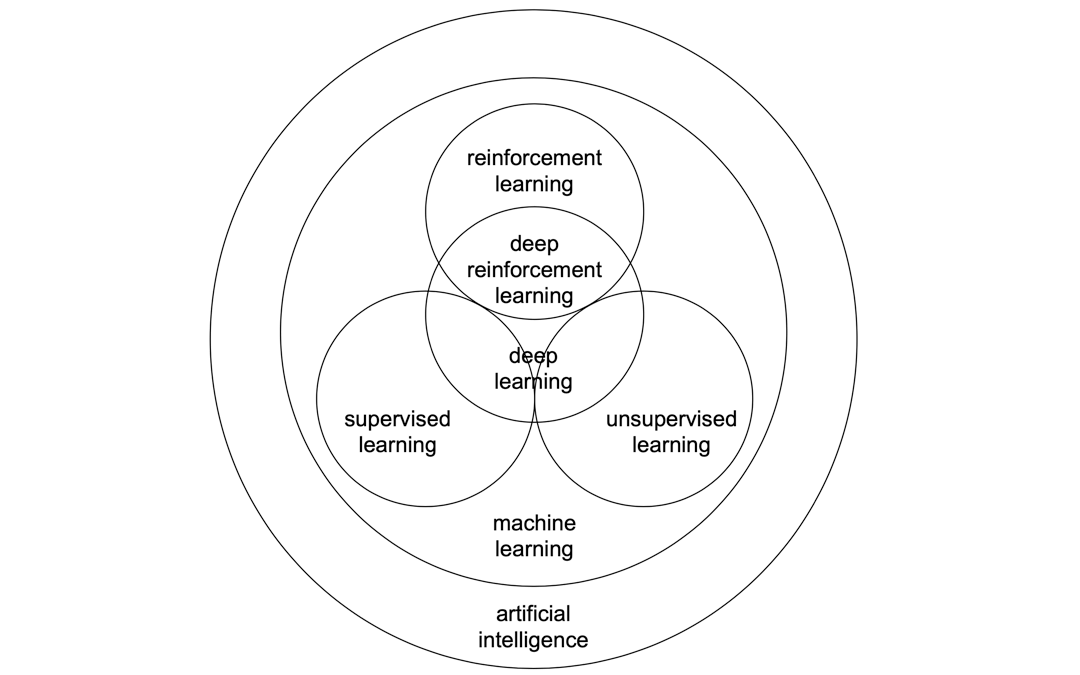
强化学习、监督学习、无监督学习、机器学习、深度学习之间的关系可以用下面的图表示。
强化学习的分类:
按照环境是否已知,强化学习可以分为两类:
Model-Based,环境已知,代表算法是动态规划。Model-Free,环境未知,在这种情况下,只有一种办法,探索与利用。
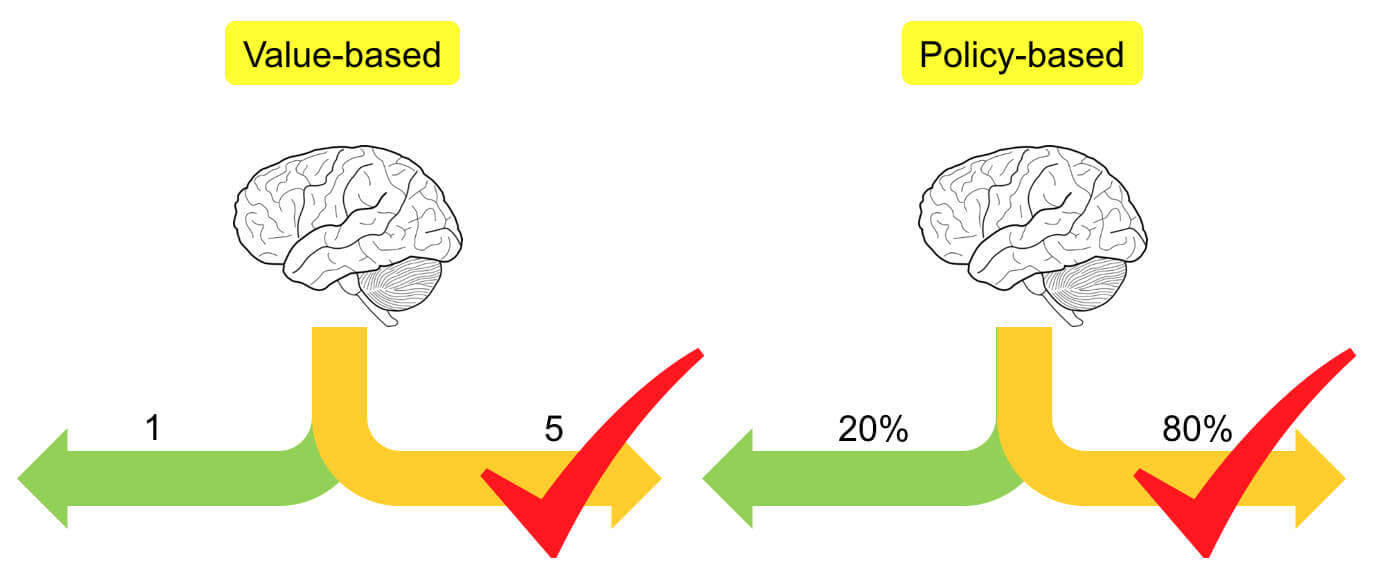
而Model-Free又可以分为两类:
Value-Based:基于价值Policy-Based:基于策略
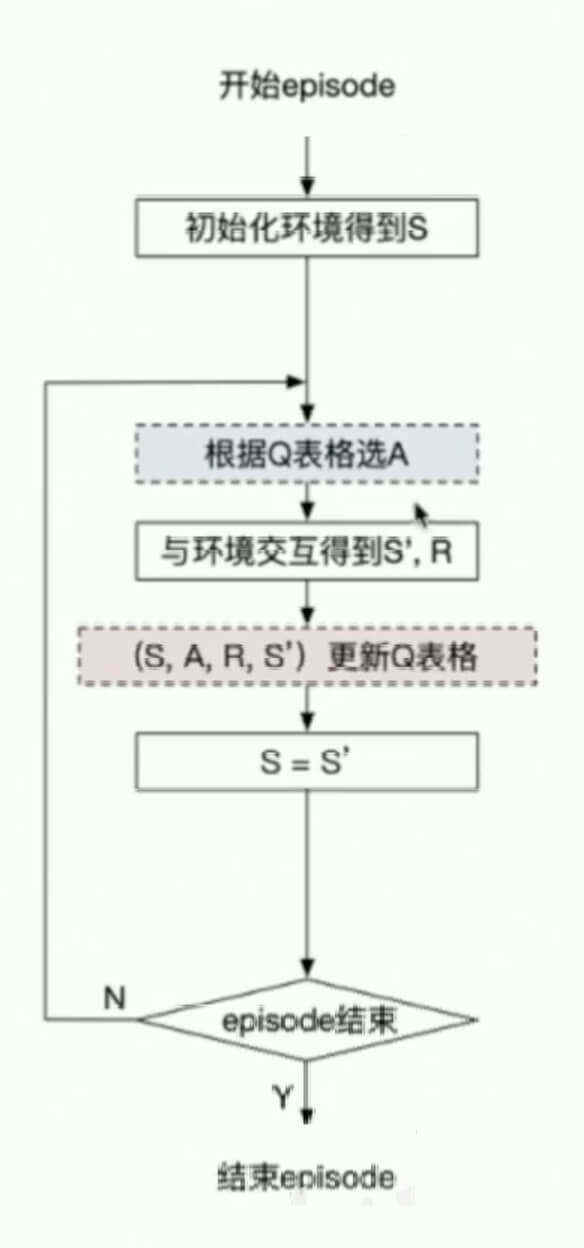
基于表格型方法求解RL
Q表格:
在不同的S下采取不同的A,分别有多少价值。
目标:
max 总收益Gt=Rt+1+γRt+2+γ2Rt+3+⋅⋅⋅
Q表格的更新:
“巴普洛夫的狗”,下一个状态的价值,会强化去影响当前状态的价值。
Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
两个代表算法:
- SARSA
- Q-Learning
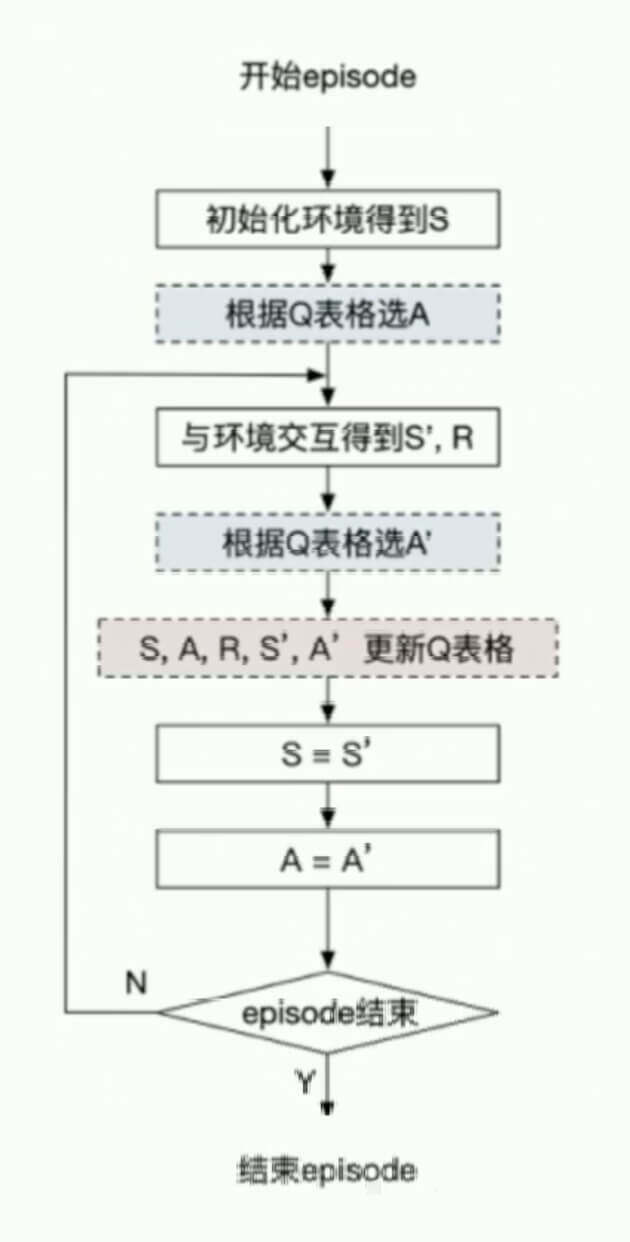
SARSA:
更新策略:
Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
Q-Learning:
更新策略:
Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
基于神经网络方法求解RL
构造一个值函数q^(s,a,w)≈Q(s,a)
基于策略梯度求解RL
目标:
maxRθ=τ∑R(τ)pθ(τ)
求R的方法:
蒙特卡洛法(抽样调查)