上一章,我们讨论了损失函数。损失函数用以衡量模型的拟合效果。那么如何寻找一组参数,使损失函数的值最小呢?梯度下降。
梯度
首先,我们需要讨论的第一个问题,到底什么是梯度?
导数 ⟶ 偏导数 ⟶ 方向导数 ⟶ 梯度 \text{导数} \ \longrightarrow \ \text{偏导数} \ \longrightarrow \ \text{方向导数} \ \longrightarrow \ \text{梯度}
导数 ⟶ 偏导数 ⟶ 方向导数 ⟶ 梯度
导数
在高中期间,我们就已经学过了导数。
f ′ ( x 0 ) = lim Δ x → 0 Δ y Δ x = f ( x 0 + Δ x ) − f ( x 0 ) Δ x f'(x_0) = \lim_{\Delta x \rightarrow 0}\frac{\Delta y}{\Delta x} = \frac{f(x_0+\Delta x) - f(x_0)}{\Delta x}
f ′ ( x 0 ) = Δ x → 0 lim Δ x Δ y = Δ x f ( x 0 + Δ x ) − f ( x 0 )
即,随着自变量x x x y y y y y y x x x
偏导数
后来,在大一的时候,我们学习了偏导数。
∂ f ( x 0 , y 0 ) ∂ x = lim Δ x → 0 f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 ) Δ x \frac{\partial f(x_0,y_0)}{\partial x} = \lim_{\Delta x \rightarrow 0}\frac{f(x_0 + \Delta x,y_0) - f(x_0,y_0)}{\Delta x}
∂ x ∂ f ( x 0 , y 0 ) = Δ x → 0 lim Δ x f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 )
即,f ( x , y ) f(x,y) f ( x , y ) ( x 0 , y 0 ) (x_0,y_0) ( x 0 , y 0 ) x x x f ( x , y ) f(x,y) f ( x , y ) ( x 0 , y 0 ) (x_0,y_0) ( x 0 , y 0 ) y y y
方向导数
方向导数的定义
那么,函数在某点,沿着某特定方向(不一定是坐标轴)的变化率就是方向导数。
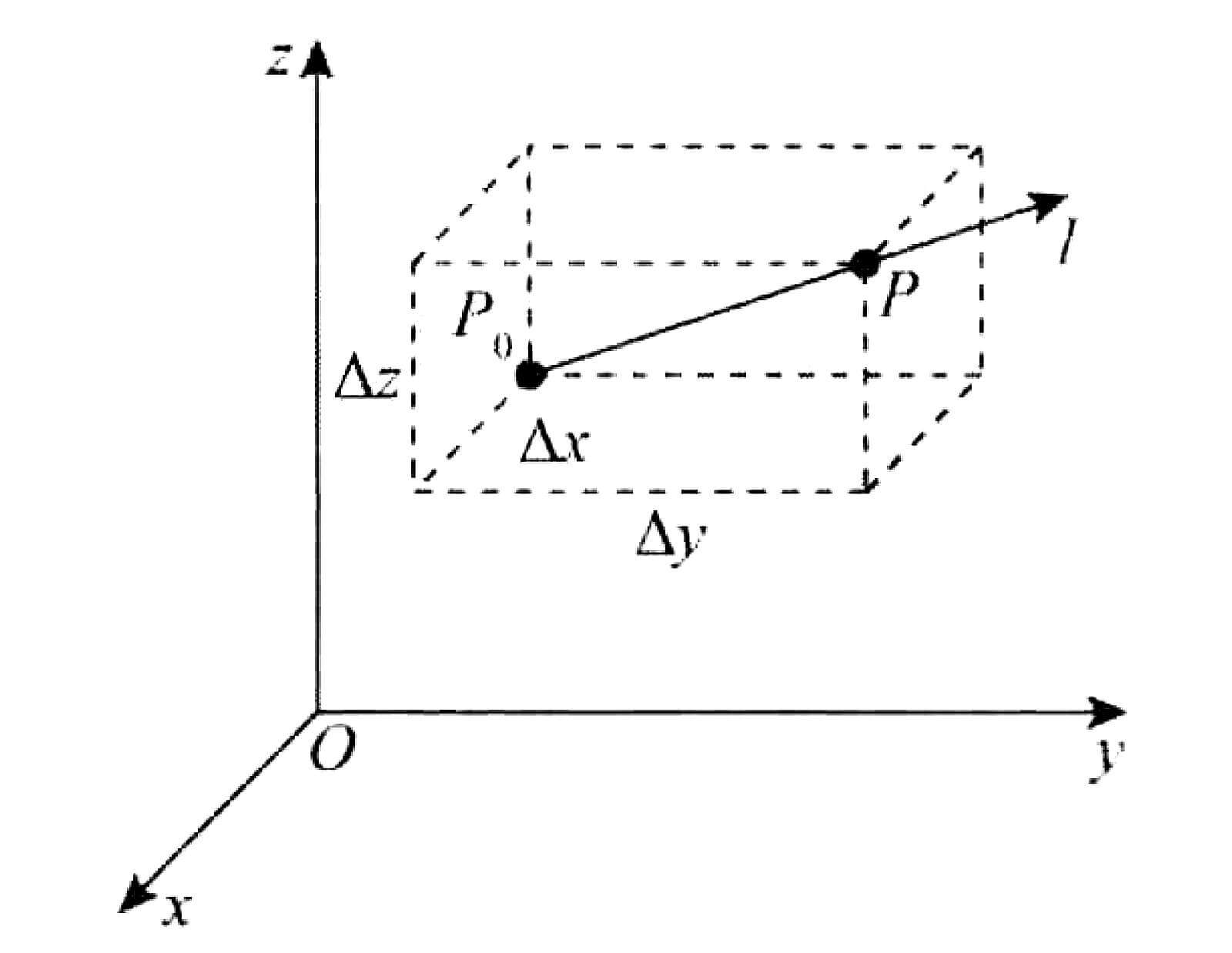
如图所示,假设存在一个三元函数u = u ( x , y , z ) u=u(x,y,z) u = u ( x , y , z ) P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P 0 ( x 0 , y 0 , z 0 ) U ⊂ R 3 U\subset\bold{R}^3 U ⊂ R 3 l l l P 0 P_0 P 0 P ( x , y , z ) P(x,y,z) P ( x , y , z ) l l l U U U
{ x − x 0 = Δ x = t cos α y − y 0 = Δ y = t cos β z − z 0 = Δ z = t cos γ \begin{cases}
x - x_0 = \Delta x = t \cos \alpha \\
y - y_0 = \Delta y = t \cos \beta \\
z - z_0 = \Delta z = t \cos \gamma
\end{cases}
⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ x − x 0 = Δ x = t cos α y − y 0 = Δ y = t cos β z − z 0 = Δ z = t cos γ
其中t t t P P P P 0 P_0 P 0 t = ( Δ x ) 2 + ( Δ y ) 2 + ( Δ z ) 2 t=\sqrt{(\Delta x)^2 + (\Delta y)^2 + (\Delta z)^2} t = ( Δ x ) 2 + ( Δ y ) 2 + ( Δ z ) 2
lim t → 0 + u ( P ) − u ( P 0 ) t = lim t → 0 + u ( x 0 + t cos α , y 0 + t cos β , z 0 + t cos γ ) − u ( x 0 , y 0 , z 0 ) t \lim_{t \rightarrow 0^+}\frac{u(P) - u(P_0)}{t} = \lim_{t \rightarrow 0^+}\frac{u(x_0 + t\cos\alpha,y_0 + t\cos\beta,z_0 + t\cos\gamma) - u(x_0,y_0,z_0)}{t}
t → 0 + lim t u ( P ) − u ( P 0 ) = t → 0 + lim t u ( x 0 + t cos α , y 0 + t cos β , z 0 + t cos γ ) − u ( x 0 , y 0 , z 0 )
这个极限,就是函数u = u ( x , y , z ) u=u(x,y,z) u = u ( x , y , z ) P 0 P_0 P 0 l l l ∂ u ∂ l ∣ p 0 \frac{\partial u}{\partial l}\Big|_{p_{0}} ∂ l ∂ u ∣ ∣ ∣ ∣ p 0
方向导数的计算公式
但是有了定义还不够,根据定义,我们并不能很快的进行计算。我们还需要一个东西,计算公式。u = u ( x , y , z ) u=u(x,y,z) u = u ( x , y , z ) P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P 0 ( x 0 , y 0 , z 0 )
∂ u ∂ l ∣ p 0 = u x ′ ( P 0 ) cos α + u y ′ ( P 0 ) cos β + u z ′ ( P 0 ) cos γ \frac{\partial u}{\partial l}\bigg|_{p_{0}} = u'_{x}(P_0)\cos\alpha + u'_{y}(P_0)\cos\beta + u'_{z}(P_0)\cos\gamma
∂ l ∂ u ∣ ∣ ∣ ∣ ∣ p 0 = u x ′ ( P 0 ) cos α + u y ′ ( P 0 ) cos β + u z ′ ( P 0 ) cos γ
其中,cos α \cos\alpha cos α cos β \cos\beta cos β cos γ \cos\gamma cos γ l l l
∂ u ∂ l ∣ p 0 = [ u x ′ ( P 0 ) u y ′ ( P 0 ) u z ′ ( P 0 ) ] ⋅ [ cos α cos β cos γ ] \frac{\partial u}{\partial l}\bigg|_{p_{0}} =
\left[
\begin{matrix}
u'_{x}(P_0) \quad u'_{y}(P_0) \quad u'_{z}(P_0)
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
\cos\alpha \\
\cos\beta \\
\cos\gamma \\
\end{matrix}
\right]
∂ l ∂ u ∣ ∣ ∣ ∣ ∣ p 0 = [ u x ′ ( P 0 ) u y ′ ( P 0 ) u z ′ ( P 0 ) ] ⋅ ⎣ ⎢ ⎡ cos α cos β cos γ ⎦ ⎥ ⎤
其中,[ u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ] [u'_{x}(P_0),u'_{y}(P_0),u'_{z}(P_0)] [ u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ] g r a d u \bold{grad}\ u g r a d u
例题
求函数z = x e 2 y z = xe^{2y} z = x e 2 y P ( 1 , 0 ) P(1,0) P ( 1 , 0 ) Q ( 2 , − 1 ) Q(2,-1) Q ( 2 , − 1 )
解: l → \overrightarrow{l} l P Q → = ( 1 , − 1 ) \overrightarrow{PQ} = (1,-1) P Q = ( 1 , − 1 ) x x x l → \overrightarrow{l} l α = − π 4 \alpha = - \frac{\pi}{4} α = − 4 π y y y l → \overrightarrow{l} l β = − 3 π 4 \beta = - \frac{3\pi}{4} β = − 4 3 π
∂ z ∂ l → ∣ ( 1 , 0 ) = [ ∂ z ∂ x ∣ ( 1 , 0 ) ∂ z ∂ y ∣ ( 1 , 0 ) ] ⋅ [ cos α cos β ] = − 2 2 \frac{\partial z}{\partial \overrightarrow{l}}\bigg|_{(1,0)} =
\left[
\begin{matrix}
\frac{\partial z}{\partial x}\bigg|_{(1,0)} \quad \frac{\partial z}{\partial y}\bigg|_{(1,0)}
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
\cos\alpha \\
\cos\beta
\end{matrix}
\right]
= - \frac{\sqrt{2}}{2}
∂ l ∂ z ∣ ∣ ∣ ∣ ∣ ( 1 , 0 ) = [ ∂ x ∂ z ∣ ∣ ∣ ∣ ∣ ( 1 , 0 ) ∂ y ∂ z ∣ ∣ ∣ ∣ ∣ ( 1 , 0 ) ] ⋅ [ cos α cos β ] = − 2 2
梯度
那么,现在我们讨论第二个问题,沿着哪一个方向的方向导数最大呢?这就需要引出第二个概念,梯度。u = u ( x , y , z ) u=u(x,y,z) u = u ( x , y , z ) P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P 0 ( x 0 , y 0 , z 0 )
g r a d u ∣ P 0 = ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) \bold{grad}\ u |_{P_{0}} = (u'_x(P_0),u'_y(P_0),u'_z(P_0))
g r a d u ∣ P 0 = ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) )
为函数u = u ( x , y , z ) u = u(x,y,z) u = u ( x , y , z ) P 0 P_0 P 0
那么为什么梯度的方向就是方向导数值最大的方向呢?这就不得不从方向导数和梯度的关系讲起。
方向导数和梯度的关系
正如我们之前讨论的。
∂ u ∂ l ∣ p 0 = [ u x ′ ( P 0 ) u y ′ ( P 0 ) u z ′ ( P 0 ) ] ⋅ [ cos α cos β cos γ ] = g r a d u ∣ P 0 ⋅ l → = ∣ g r a d u ∣ P 0 ∣ ∗ ∣ l → ∣ ∗ cos θ \begin{aligned}
\frac{\partial u}{\partial l}\bigg|_{p_{0}} &=
\left[
\begin{matrix}
u'_{x}(P_0) \quad u'_{y}(P_0) \quad u'_{z}(P_0)
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
\cos\alpha \\
\cos\beta \\
\cos\gamma \\
\end{matrix}
\right] \\
&= \bold{grad}\ u|_{P_0} \cdot \overrightarrow{l} \\
&= \bold{|}\bold{grad}\ u|_{P_0}\bold{|} * \bold{|}\overrightarrow{l}\bold{|} * \cos\theta
\end{aligned}
∂ l ∂ u ∣ ∣ ∣ ∣ ∣ p 0 = [ u x ′ ( P 0 ) u y ′ ( P 0 ) u z ′ ( P 0 ) ] ⋅ ⎣ ⎢ ⎡ cos α cos β cos γ ⎦ ⎥ ⎤ = g r a d u ∣ P 0 ⋅ l = ∣ g r a d u ∣ P 0 ∣ ∗ ∣ l ∣ ∗ cos θ
其中,θ \theta θ g r a d u ∣ P 0 \bold{grad}\ u|_{P_0} g r a d u ∣ P 0 l → \overrightarrow{l} l ∣ l → ∣ = 1 \bold{|}\overrightarrow{l}\bold{|} = 1 ∣ l ∣ = 1
∂ u ∂ l ∣ p 0 = ∣ g r a d u ∣ P 0 ∣ ∗ cos θ \frac{\partial u}{\partial l}\bigg|_{p_{0}} = \bold{|}\bold{grad}\ u|_{P_0}\bold{|} * \cos\theta
∂ l ∂ u ∣ ∣ ∣ ∣ ∣ p 0 = ∣ g r a d u ∣ P 0 ∣ ∗ cos θ
显然,当θ = 0 \theta = 0 θ = 0 cos θ \cos\theta cos θ ∂ u ∂ l ∣ p 0 \frac{\partial u}{\partial l}|_{p_{0}} ∂ l ∂ u ∣ p 0
举例
在讨论梯度之后,我们再来举一个例子。
f ( x , y ) = x 2 + y 2 f(x,y) = x^2 + y^2
f ( x , y ) = x 2 + y 2
那么我们的目标当然是求解一组( x , y ) (x,y) ( x , y ) f ( x , y ) f(x,y) f ( x , y )
x = x − l r ∂ f ( x , y ) ∂ x x = x - lr \frac{\partial f(x,y)}{\partial x}
x = x − l r ∂ x ∂ f ( x , y )
y = y − l r ∂ f ( x , y ) ∂ y y = y - lr \frac{\partial f(x,y)}{\partial y}
y = y − l r ∂ y ∂ f ( x , y )
其中:
∂ f ( x , y ) ∂ x = ∂ x 2 x + ∂ y 2 x = 2 x \frac{\partial f(x,y)}{\partial x} = \frac{\partial x^2}{x} + \frac{\partial y^2}{x} = 2x
∂ x ∂ f ( x , y ) = x ∂ x 2 + x ∂ y 2 = 2 x
∂ f ( x , y ) ∂ y = ∂ x 2 y + ∂ y 2 y = 2 y \frac{\partial f(x,y)}{\partial y} = \frac{\partial x^2}{y} + \frac{\partial y^2}{y} = 2y
∂ y ∂ f ( x , y ) = y ∂ x 2 + y ∂ y 2 = 2 y
那么,当x = 1 y = 2 x=1\ y=2 x = 1 y = 2 ( 2 , 4 ) (2,4) ( 2 , 4 )
求解梯度的实现方法
当然,我们不用每次都手工去求解梯度,在TensorFlow中有自动求解梯度的方法。
首先,我们需要用with tf.GradientTape() as tape:把函数表达式包进去。
用[w_grad] = tape.gradient(func,[w])求解梯度,传入函数和需要求解的参数。返回参数的梯度。
示例代码:
1 2 3 4 5 6 7 8 9 import tensorflow as tfwith tf.GradientTape() as tape: x = tf.Variable(1.0 ) y = tf.Variable(2.0 ) tape.watch([x,y]) z = tf.math.pow(x,2 ) + tf.math.pow(y,2 ) print(tape.gradient(z,[x,y]))
运行结果:
1 [<tf.Tensor: shape=(), dtype=float32, numpy=2.0>, <tf.Tensor: shape=(), dtype=float32, numpy=4.0>]
二阶梯度
还有一个概念是二阶梯度,这个有点像是导数的导数。
z = x 2 + y 2 z = x^2 + y^2
z = x 2 + y 2
则
∂ z ∂ x = 2 x \frac{\partial z}{\partial x} = 2x
∂ x ∂ z = 2 x
∂ 2 z ∂ x 2 = 2 \frac{\partial^2 z}{\partial x^2} = 2
∂ x 2 ∂ 2 z = 2
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 import tensorflow as tfx = tf.Variable(1.0 ) y = tf.Variable(2.0 ) with tf.GradientTape() as t1: with tf.GradientTape() as t2: t2.watch([x]) z = tf.math.pow(x,2 ) + tf.math.pow(y,2 ) dz_dx = t2.gradient(z,[x]) t1.watch([x]) d2z_dx2 = t1.gradient(dz_dx,[x]) print(d2z_dx2)
运行结果:
1 [<tf.Tensor: shape=(), dtype=float32, numpy=2.0>]
激活函数及其梯度
在上一章讨论输出层的时候,其实我们讨论的就是激活函数。这次我们会更系统的讨论一下激活函数及其梯度。
阶跃函数SigmoidTanhReLULeakyReLu
阶跃函数
最初,人们在通过模拟青蛙的神经元,创建了第一个激活函数,阶跃函数。
O = { 1 if ∑ w i x i > 0 0 otherwise O =
\begin{cases}
1 & \text{if }\sum w_i x_i > 0 \\
0 & \text{otherwise}
\end{cases}
O = { 1 0 if ∑ w i x i > 0 otherwise
现在,我们试图对这个激活函数进行求导,其导函数非常简单:
O ′ = { 0 if ∑ w i x i ≠ 0 不可导 if ∑ w i x i = 0 O' = \begin{cases}
0 & \text{if }\sum w_i x_i \neq 0 \\
\text{不可导 } & \text{if } \sum w_i x_i = 0
\end{cases}
O ′ = { 0 不可导 if ∑ w i x i = 0 if ∑ w i x i = 0
这个导函数会导致一个问题,没法梯度下降,要么是学习率 × 0 \text{学习率} \times 0 学习率 × 0
当时的科学家们用了一个方法,启发式搜索。
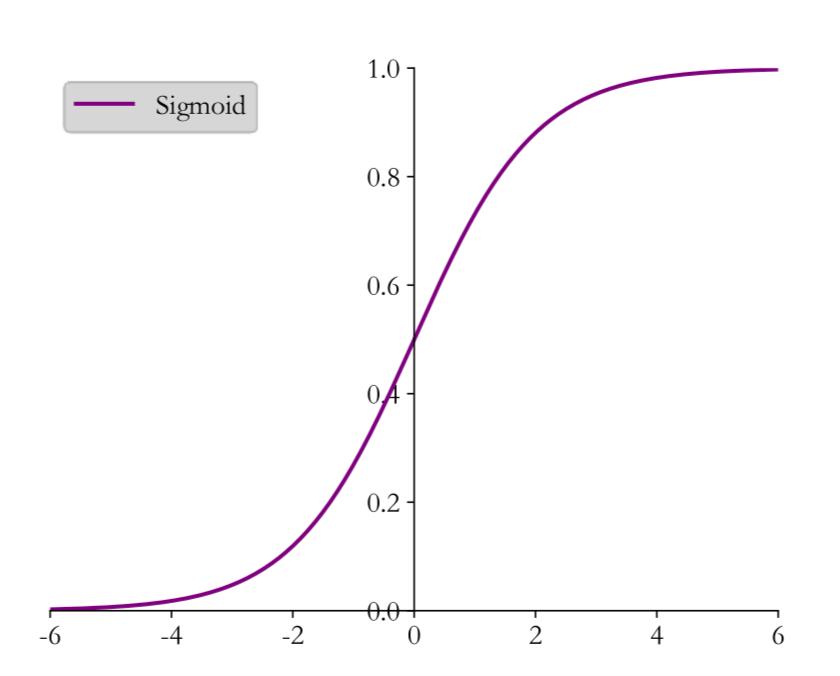
Sigmoid
为了解决没法进行梯度下的问题,我们引入Sigmoid。
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1 + e^{-x}}
s i g m o i d ( x ) = 1 + e − x 1
如果我们再对Sigmoid函数进行求导,还会有惊喜发现:
s i g m o i d ′ = e − x ( 1 + e − x ) 2 sigmoid' = \frac{e^{-x}}{(1+e^{-x})^2}
s i g m o i d ′ = ( 1 + e − x ) 2 e − x
我们对其结果进行简化。
e − x ( 1 + e − x ) 2 = ( ( 1 1 + e − x ) − 1 − 1 ) ( 1 1 + e − x ) 2 = ( s i g m o i d − 1 − 1 ) s i g m o i d 2 = s i g m o i d − s i g m o i d 2 \begin{aligned}
\frac{e^{-x}}{(1+e^{-x})^2} &= \Big(\Big(\frac{1}{1+e^{-x}}\Big)^{-1} - 1\Big)\Big(\frac{1}{1+e^{-x}}\Big)^2 \\
&= ({sigmoid}^{-1} - 1){sigmoid}^2 \\
&= sigmoid - {sigmoid}^2
\end{aligned}
( 1 + e − x ) 2 e − x = ( ( 1 + e − x 1 ) − 1 − 1 ) ( 1 + e − x 1 ) 2 = ( s i g m o i d − 1 − 1 ) s i g m o i d 2 = s i g m o i d − s i g m o i d 2
即
s i g m o i d ′ = s i g m o i d − s i g m o i d 2 {sigmoid}' = sigmoid - {sigmoid}^2
s i g m o i d ′ = s i g m o i d − s i g m o i d 2
那么什么是惊喜呢?
在TensorFlow中,Sigmoid的实现方法是:
示例代码:
1 2 3 4 5 6 7 8 9 import tensorflow as tfa = tf.linspace(-10 ,10 ,21 ) with tf.GradientTape() as tape: tape.watch(a) y = tf.sigmoid(a) grads = tape.gradient(y,[a]) print(grads)
运行结果:
1 2 3 4 5 6 7 [<tf.Tensor: shape=(21,), dtype=float64, numpy= array([4.53958077e-05, 1.23379350e-04, 3.35237671e-04, 9.10221180e-04, 2.46650929e-03, 6.64805667e-03, 1.76627062e-02, 4.51766597e-02, 1.04993585e-01, 1.96611933e-01, 2.50000000e-01, 1.96611933e-01, 1.04993585e-01, 4.51766597e-02, 1.76627062e-02, 6.64805667e-03, 2.46650929e-03, 9.10221180e-04, 3.35237671e-04, 1.23379350e-04, 4.53958077e-05])>]
这么看起来,Sigmoid函数似乎完美?不但可以梯度下降,求导函数的值还方便。梯度弥散 。
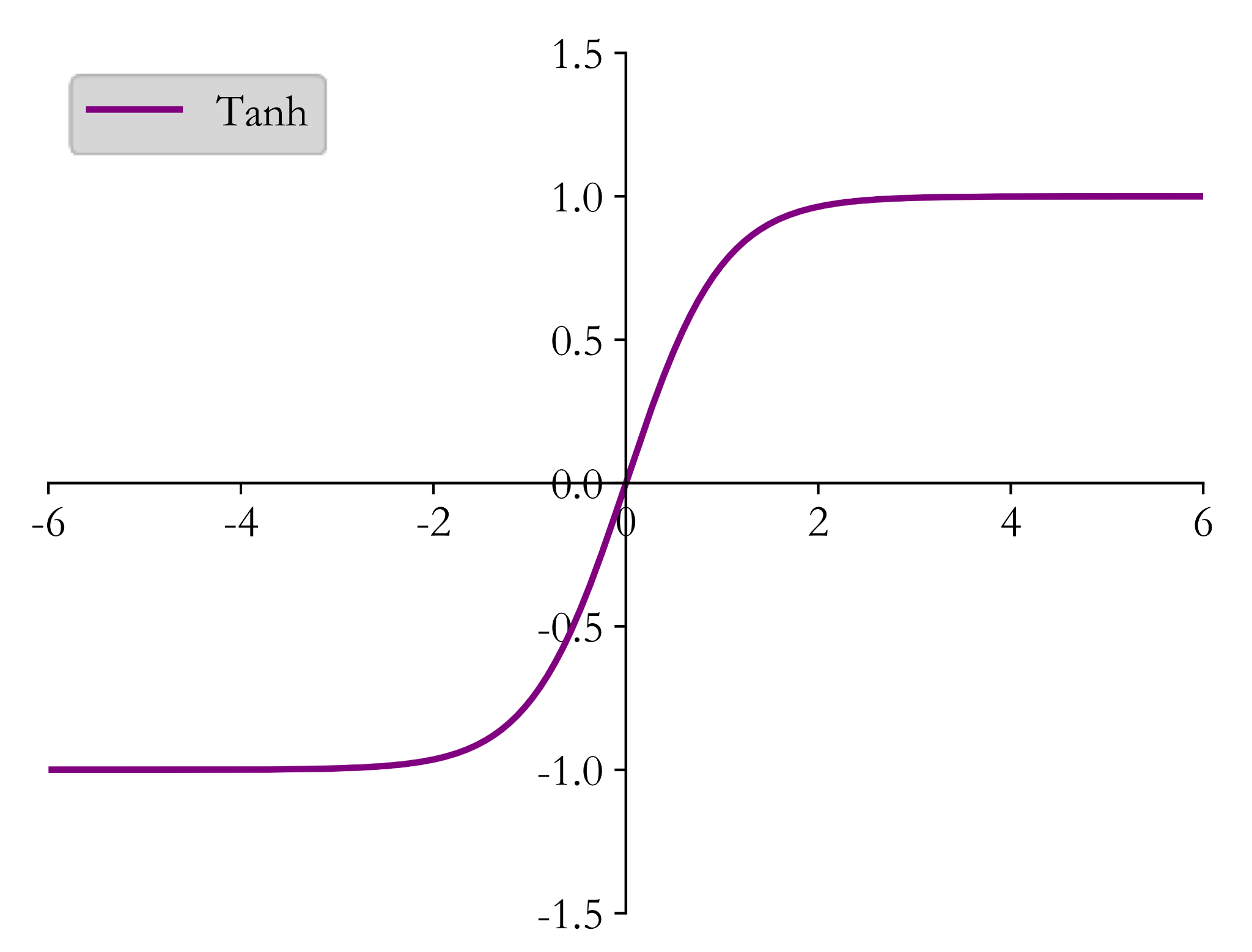
Tanh
我们再讨论一个激活函数,tanh \tanh tanh
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
t a n h ( x ) = e x + e − x e x − e − x
我们对其进行简单的变换,则有:
t a n h ( x ) = 2 s i g m o i d ( 2 x ) − 1 tanh(x) = 2 sigmoid(2x) - 1
t a n h ( x ) = 2 s i g m o i d ( 2 x ) − 1
我们对其进行求导,则有:
t a n h ′ = 1 − t a n h 2 tanh' = 1 - tanh^2
t a n h ′ = 1 − t a n h 2
在TensorFlow中,Tanh的实现方法是:
示例代码:
1 2 3 4 5 6 7 8 9 import tensorflow as tfa = tf.linspace(-10 ,10 ,21 ) with tf.GradientTape() as tape: tape.watch(a) y = tf.tanh(a) grads = tape.gradient(y,[a]) print(grads)
运行结果:
1 2 3 4 5 6 7 [<tf.Tensor: shape=(21,), dtype=float64, numpy= array([8.24461455e-09, 6.09199171e-08, 4.50140598e-07, 3.32610934e-06, 2.45765474e-05, 1.81583231e-04, 1.34095068e-03, 9.86603717e-03, 7.06508249e-02, 4.19974342e-01, 1.00000000e+00, 4.19974342e-01, 7.06508249e-02, 9.86603717e-03, 1.34095068e-03, 1.81583231e-04, 2.45765474e-05, 3.32610934e-06, 4.50140598e-07, 6.09199171e-08, 8.24461455e-09])>]
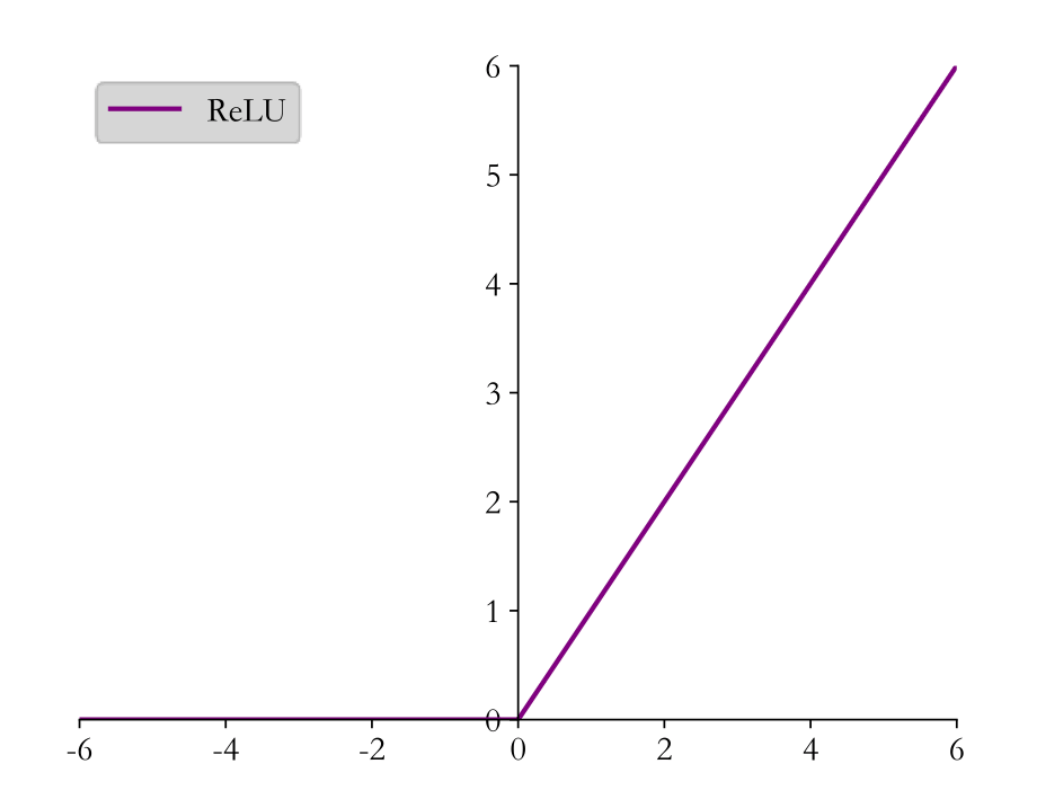
ReLU
ReLU函数,非常的简单,重剑无锋,大巧不工。Rectified Linear Unit,译作线性整流函数。
r e l u ( x ) = { x for x ≥ 0 0 for x < 0 relu(x) = \begin{cases}
x & \text{for } x \ge 0 \\
0 & \text{for } x < 0
\end{cases}
r e l u ( x ) = { x 0 for x ≥ 0 for x < 0
ReLU的导函数也非常简单。
r e l u ′ ( x ) = { 1 for x ≥ 0 0 for x < 0 relu'(x) = \begin{cases}
1 & \text{for } x \ge 0 \\
0 & \text{for } x < 0
\end{cases}
r e l u ′ ( x ) = { 1 0 for x ≥ 0 for x < 0
在TensorFlow中,ReLU的实现方法是:
示例代码:
1 2 3 4 5 6 7 8 9 import tensorflow as tfa = tf.linspace(-10 ,10 ,21 ) with tf.GradientTape() as tape: tape.watch(a) y = tf.nn.relu(a) grads = tape.gradient(y,[a]) print(grads)
运行结果:
1 2 3 [<tf.Tensor: shape=(21,), dtype=float64, numpy= array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])>]
正如运行结果所示,ReLU函数的的缺点是,当x < 0 x<0 x < 0 0 0 0
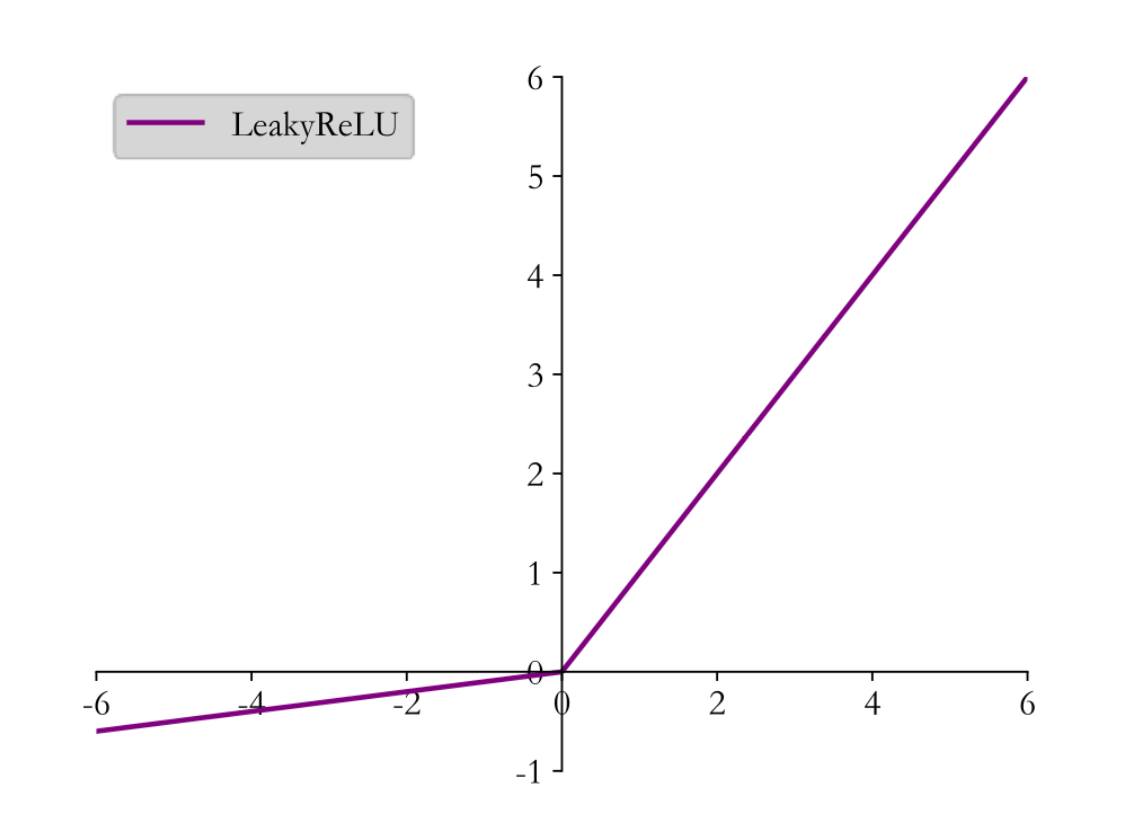
LeakyReLU
为了克服ReLU函数的梯度弥散问题,我们再引入一个激活函数,LeakyReLU。
l e a k y r e l u ( x ) = { x for x ≥ 0 p x for x < 0 leakyrelu(x) = \begin{cases}
x & \text{for } x \ge 0 \\
px & \text{for } x < 0
\end{cases}
l e a k y r e l u ( x ) = { x p x for x ≥ 0 for x < 0
其中p p p
l e a k y r e l u ′ ( x ) = { 1 for x ≥ 0 p for x < 0 leakyrelu'(x) = \begin{cases}
1 & \text{for } x \ge 0 \\
p & \text{for } x < 0
\end{cases}
l e a k y r e l u ′ ( x ) = { 1 p for x ≥ 0 for x < 0
在TensorFlow中,LeakyReLU的实现方法是:
示例代码:
1 2 3 4 5 6 7 8 9 import tensorflow as tfa = tf.linspace(-10 ,10 ,21 ) with tf.GradientTape() as tape: tape.watch(a) y = tf.nn.leaky_relu(a,alpha=0.01 ) grads = tape.gradient(y,[a]) print(grads)
运行结果:
1 2 3 [<tf.Tensor: shape=(21,), dtype=float64, numpy= array([0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. ])>]
如何选择激活函数
现在,我们来讨论一个问题,哪个激活函数是最好的?
我们选择激活函数,也要在不同的情况下,选择不同的激活函数。
几个经验总结有:
如果输出是0、1值(二分类问题),则输出层选择Sigmoid函数,然后其它的所有单元都选择ReLU函数。
如果在隐藏层上不确定使用哪个激活函数,那么通常会使用ReLU激活函数。有时,也会使用tanh激活函数。
Sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
ReLU激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLU,再去尝试其他的激活函数。
如果遇到了一些死的神经元,我们可以使用Leaky ReLU函数。
损失函数及其梯度
损失函数,其实在上一章,我们已经讨论过了。
均方误差(MSE)
交叉熵损失(Cross Entropy Loss)
这一章,我们主要讨论损失函数的梯度。
均方误差
均方误差的公式:
M S E ( y , o ) = 1 d o u t ∑ i = 1 d o u t ( y i − o i ) 2 MSE(\bold{y},\bold{o}) = \frac{1}{d_{out}}\sum_{i=1}^{d_{out}}(y_i - o_i)^2
M S E ( y , o ) = d o u t 1 i = 1 ∑ d o u t ( y i − o i ) 2
但是,这个公式求导计算不方便。所以,我们考虑进行缩放,因为缩放并不会改变梯度的方向。这就是我们说的非标的均方误差
L = 1 2 ∑ k = 1 K ( y k − o k ) 2 L = \frac{1}{2}\sum_{k=1}^K\big(y_k - o_k)^2
L = 2 1 k = 1 ∑ K ( y k − o k ) 2
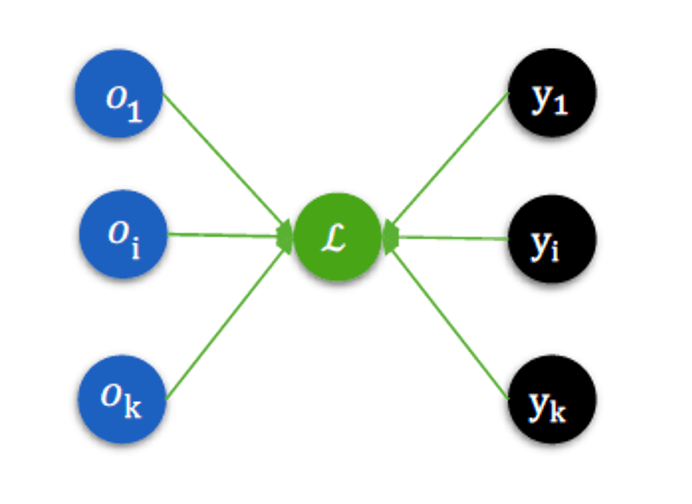
我们还可以用一张图来描述均方误差,这样有助于我们计算均方误差的梯度。∂ L ∂ o i \frac{\partial L}{\partial o_i} ∂ o i ∂ L
∂ L ∂ o i = ∑ k = 1 K ( y k − o k ) ∂ ( y k − o k ) ∂ o i = ∑ k = 1 K ( y k − o k ) ∗ − 1 ∗ ∂ o k ∂ o i \begin{aligned}
\frac{\partial L}{\partial o_i} &= \sum_{k=1}^{K}(y_k - o_k) \frac{\partial (y_k - o_k)}{\partial o_i} \\
&= \sum_{k = 1}^{K}(y_k - o_k) * -1 * \frac{\partial o_k}{\partial o_i}
\end{aligned}
∂ o i ∂ L = k = 1 ∑ K ( y k − o k ) ∂ o i ∂ ( y k − o k ) = k = 1 ∑ K ( y k − o k ) ∗ − 1 ∗ ∂ o i ∂ o k
由图像,我们也可以看出,当k ≠ i k \neq i k = i o k o_k o k o i o_i o i ∂ o k ∂ o i = 0 \frac{\partial o_k}{\partial o_i} = 0 ∂ o i ∂ o k = 0 k = i k=i k = i ∂ o k ∂ o i = 1 \frac{\partial o_k}{\partial o_i} = 1 ∂ o i ∂ o k = 1
∂ L ∂ o i = ( o i − y i ) \frac{\partial L}{\partial o_i} = (o_i - y_i)
∂ o i ∂ L = ( o i − y i )
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 import tensorflow as tfy = tf.constant([1. ,2. ,3. ]) o = tf.constant([2. ,2. ,3. ]) with tf.GradientTape() as tape: tape.watch([o]) loss = tf.square(y - o)/2 grads = tape.gradient(loss,[o]) print(grads)
运行结果:
1 [<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 1., -0., -0.], dtype=float32)>]
交叉熵损失
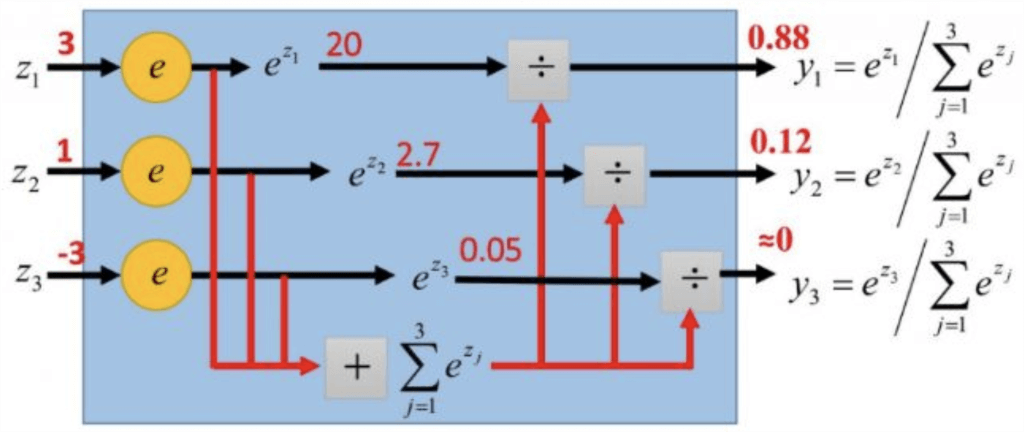
交叉熵损失通常和Softmax配合使用,我们先讨论Softmax。
Softmax
p i = e z i ∑ k = 1 K e z k p_i = \frac{e^{z_i}}{\sum_{k=1}^{K} e^{z_k}}
p i = ∑ k = 1 K e z k e z i
正如我们上一章所讨论的,Softmax的作用是将K K K 1 1 1
如图所示:
y 1 = e z 1 e z 1 + e z 2 + e z 3 y_1 = \frac{e^{z_1}}{e^{z_1} + e^{z_2} + e^{z_3}}
y 1 = e z 1 + e z 2 + e z 3 e z 1
首先,我们讨论∂ y 1 ∂ z 1 \frac{\partial y_1}{\partial z_1} ∂ z 1 ∂ y 1 i = j i=j i = j
∂ y 1 ∂ z 1 = e z 1 ( e z 1 + e z 2 + e z 3 ) − e z 1 e z 1 ( e z 1 + e z 2 + e z 3 ) 2 = e z 1 ( e z 1 + e z 2 + e z 3 − e z 1 ) ( e z 1 + e z 2 + e z 3 ) 2 = e z 1 ( e z 1 + e z 2 + e z 3 ) 2 × e z 1 + e z 2 + e z 3 − e z 1 e z 1 + e z 2 + e z 3 = y 1 ( 1 − y 1 ) \begin{aligned}
\frac{\partial y_1}{\partial z_1} &= \frac{e^{z_1}(e^{z_1} + e^{z_2} + e^{z_3}) - e^{z_1}e^{z_1}}{(e^{z_1} + e^{z_2} + e^{z_3})^2} \\
&= \frac{e^{z_1}(e^{z_1} + e^{z_2} + e^{z_3} - e^{z_1})}{(e^{z_1} + e^{z_2} + e^{z_3})^2} \\
&= \frac{e^{z_1}}{(e^{z_1} + e^{z_2} + e^{z_3})^2} \times \frac{e^{z_1} + e^{z_2} + e^{z_3} - e^{z_1}}{e^{z_1} + e^{z_2} + e^{z_3}} \\
&= y_1(1- y_1)
\end{aligned}
∂ z 1 ∂ y 1 = ( e z 1 + e z 2 + e z 3 ) 2 e z 1 ( e z 1 + e z 2 + e z 3 ) − e z 1 e z 1 = ( e z 1 + e z 2 + e z 3 ) 2 e z 1 ( e z 1 + e z 2 + e z 3 − e z 1 ) = ( e z 1 + e z 2 + e z 3 ) 2 e z 1 × e z 1 + e z 2 + e z 3 e z 1 + e z 2 + e z 3 − e z 1 = y 1 ( 1 − y 1 )
然后,我们再讨论一个,∂ y 1 ∂ z 2 \frac{\partial y_1}{\partial z_2} ∂ z 2 ∂ y 1 i ≠ j i\neq j i = j
∂ y 1 ∂ z 2 = 0 − e z 1 e z 2 e z 1 + e z 2 + e z 3 = − y 1 y 2 \begin{aligned}
\frac{\partial y_1}{\partial z_2} &= \frac{0 - e^{z_1}e^{z_2}}{e^{z_1} + e^{z_2} + e^{z_3}} \\
&= - y_1 y_2
\end{aligned}
∂ z 2 ∂ y 1 = e z 1 + e z 2 + e z 3 0 − e z 1 e z 2 = − y 1 y 2
现在,我们把这个推广到一般的形式。
p i = e z i ∑ k = 1 K e z k p_i = \frac{e^{z_i}}{\sum_{k=1}^{K} e^{z_k}}
p i = ∑ k = 1 K e z k e z i
∂ p i ∂ z j = e z i ( ∑ k = 1 K e z k ) − e z i e z j ( ∑ k = 1 K e z k ) 2 = e z i ∑ k = 1 K e z k × ∑ k = 1 K e z k − e z j ∑ k = 1 K e z k = p i ( 1 − p j ) \begin{aligned}
\frac{\partial p_i}{\partial z_j} &= \frac{e^{z_i}(\sum_{k=1}^K e^{z_k}) - e^{z_i}e^{z_j}}{(\sum_{k=1}^K e^{z_k})^2} \\
&= \frac{e^{z_i}}{\sum_{k=1}^{K} e^{z_k}} \times \frac{\sum_{k=1}^{K} e^{z_k} - e^{z_j}}{\sum_{k=1}^{K} e^{z_k}} \\
&= p_i(1-p_j)
\end{aligned}
∂ z j ∂ p i = ( ∑ k = 1 K e z k ) 2 e z i ( ∑ k = 1 K e z k ) − e z i e z j = ∑ k = 1 K e z k e z i × ∑ k = 1 K e z k ∑ k = 1 K e z k − e z j = p i ( 1 − p j )
∂ p i ∂ z j = − e z i e z j ( ∑ k = 1 K e z k ) 2 = − p i p j \begin{aligned}
\frac{\partial p_i}{\partial z_j} &= \frac{- e^{z_i}e^{z_j}}{(\sum_{k=1}^K e^{z_k})^2} \\
&= - p_i p_j
\end{aligned}
∂ z j ∂ p i = ( ∑ k = 1 K e z k ) 2 − e z i e z j = − p i p j
交叉熵损失
交叉熵:
H ( p ∣ ∣ q ) = D K L ( p ∣ ∣ q ) = ∑ i y i log ( y i o i ) \begin{aligned}
H(\bold{p}||\bold{q}) &= D_{KL}(\bold{p}||\bold{q})
&= \sum_i y_i\log\Big(\frac{y_i}{o_i}\Big)
\end{aligned}
H ( p ∣ ∣ q ) = D K L ( p ∣ ∣ q ) = i ∑ y i log ( o i y i )
如果我们用y y y p p p L L L
L = − ∑ k = 1 K y k log ( p k ) L = - \sum_{k=1}^{K} y_k \log(p_k)
L = − k = 1 ∑ K y k log ( p k )
则,损失函数对z i z_i z i
∂ L ∂ z i = − ∑ k = 1 K y k ∂ log ( p k ) ∂ z i \frac{\partial L}{\partial z_i} = - \sum_{k=1}^{K} y_k \frac{\partial \log(p_k)}{\partial z_i}
∂ z i ∂ L = − k = 1 ∑ K y k ∂ z i ∂ log ( p k )
根据复合函数的求导法则,我们还有:
∂ L ∂ z i = − ∑ k = 1 K y k ∂ log ( p k ) ∂ p k ⋅ ∂ p k ∂ z i = − ∑ k = 1 K y k 1 p k ⋅ ∂ p k ∂ z i \begin{aligned}
\frac{\partial L}{\partial z_i} &= - \sum_{k=1}^{K} y_k \frac{\partial \log(p_k)}{\partial p_k} \cdot \frac{\partial p_k}{\partial z_i} \\
&= - \sum_{k=1}^{K} y_k \frac{1}{p_k} \cdot \frac{\partial p_k}{\partial z_i}
\end{aligned}
∂ z i ∂ L = − k = 1 ∑ K y k ∂ p k ∂ log ( p k ) ⋅ ∂ z i ∂ p k = − k = 1 ∑ K y k p k 1 ⋅ ∂ z i ∂ p k
那么,∂ p k ∂ z i \frac{\partial p_k}{\partial z_i} ∂ z i ∂ p k k k k 1 1 1 K K K k = i k=i k = i
∂ L ∂ z i = − y i ( 1 − p i ) − ∑ k ≠ i K y k 1 p k ( − p k p i ) = − y i ( 1 − p i ) + ∑ k ≠ i K y k p i = p i ( y i + ∑ k ≠ i K y k ) − y i ) \begin{aligned}
\frac{\partial L}{\partial z_i} &= -y_i(1-p_i) - \sum_{k \neq i}^{K} y_k \frac{1}{p_k}(- p_k p_i) \\
&= -y_i(1-p_i) + \sum_{k \neq i}^{K} y_k p_i \\
&= p_i\Big( y_i + \sum_{k \neq i}^{K} y_k) - y_i \Big)
\end{aligned}
∂ z i ∂ L = − y i ( 1 − p i ) − k = i ∑ K y k p k 1 ( − p k p i ) = − y i ( 1 − p i ) + k = i ∑ K y k p i = p i ( y i + k = i ∑ K y k ) − y i )
特别的,当p \bold{p} p
L = − ∑ k y k log ( P k ) L = - \sum_k y_k \log (P_k)
L = − k ∑ y k log ( P k )
根据复合函数求导法则。f ( g ( x ) ) f(g(x)) f ( g ( x ) ) u = g ( x ) u = g(x) u = g ( x )
∂ f ( g ( x ) ) ∂ x = ∂ f ( u ) ∂ u ∂ g ( x ) ∂ x = f ′ ( u ) g ′ ( x ) \frac{\partial f(g(x))}{\partial x} = \frac{\partial f(u)}{\partial u} \frac{\partial g(x)}{\partial x} = f'(u) g'(x)
∂ x ∂ f ( g ( x ) ) = ∂ u ∂ f ( u ) ∂ x ∂ g ( x ) = f ′ ( u ) g ′ ( x )
可以求得交叉熵损失的导数为
∂ L ∂ z i = p i ( y i + ∑ k ≠ i y k ) − y i \frac{\partial L}{\partial z_i} = p_i \Big( y_i + \sum_{k \neq i} y_k \Big) - y_i
∂ z i ∂ L = p i ( y i + k = i ∑ y k ) − y i
特别的,对于用One-Hot编码表示的标签y,有
∑ k y k = 1 \sum_k y_k = 1
k ∑ y k = 1
y i + ∑ k ≠ i y k = 1 y_i + \sum_{k \neq i}y_k = 1
y i + k = i ∑ y k = 1
因此有
∂ L ∂ z i = p i − y i \frac{\partial L}{\partial z_i} = p_i - y_i
∂ z i ∂ L = p i − y i
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import tensorflow as tfx = tf.random.normal([2 ,4 ]) w = tf.random.normal([4 ,3 ]) b = tf.zeros([3 ]) y = tf.constant([2 ,0 ]) y = tf.one_hot(y,depth=3 ) with tf.GradientTape() as tape: tape.watch([w,b]) logits = x@w + b loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y,logits,from_logits=True )) grads = tape.gradient(loss,[w,b]) print(grads[0 ]) print(grads[1 ])
运行结果:
1 2 3 4 5 6 tf.Tensor( [[ 0.14168215 0.0084892 -0.15017135] [-0.08154044 -0.09412258 0.17566304] [ 0.07595219 0.01904502 -0.0949972 ] [-0.03096705 0.0171328 0.01383425]], shape=(4, 3), dtype=float32) tf.Tensor([-0.12995178 0.07289901 0.05705276], shape=(3,), dtype=float32)
全连接层及其梯度
截止目前,我们讨论了激活函数及其梯度,损失函数及其梯度。现在我们把两者串在一起,讨论全连接层及其梯度。
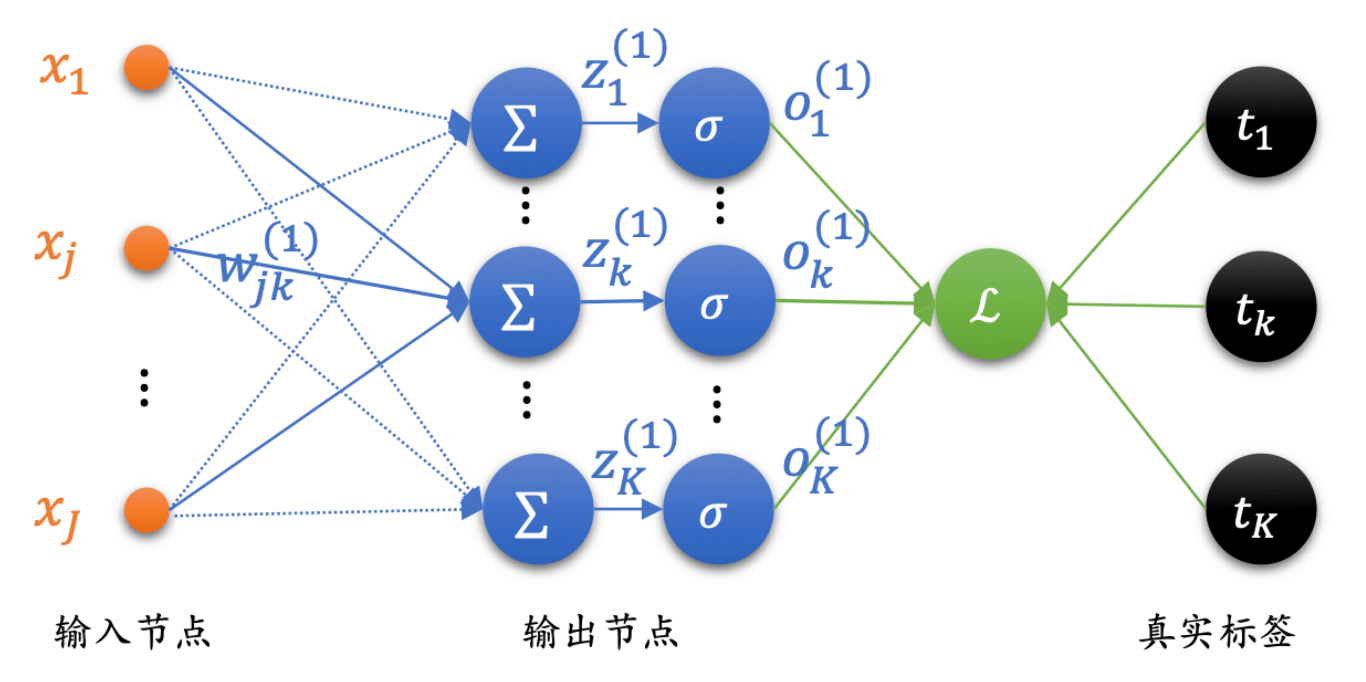
一个输出节点的全连接层
首先,我们从最简单的,只有一个输出节点的情况开始。
x 1 x_1 x 1 x 2 x_2 x 2 x j x_j x j x J x_J x J w j 1 ( 1 ) w^{(1)}_{j1} w j 1 ( 1 ) j 1 j1 j 1 j j j 1 1 1 ( 1 ) (1) ( 1 ) o 1 ( 1 ) o_1^{(1)} o 1 ( 1 ) 1 1 1 ( 1 ) (1) ( 1 )
我们采用均方误差作为损失函数,为了便于计算,采用的是非标的均方误差,这个我们之前已经讨论过了,不影响梯度的方向。
为了表达方便,我们把上标省略。
l o s s = 1 2 ( o 1 ( 1 ) − t ) 2 = 1 2 ( o 1 − t ) 2 loss = \frac{1}{2}\Big( o_1^{(1)} - t \Big)^2 = \frac{1}{2}(o_1 - t)^2
l o s s = 2 1 ( o 1 ( 1 ) − t ) 2 = 2 1 ( o 1 − t ) 2
则,l o s s loss l o s s w j 1 w_{j1} w j 1
∂ l o s s ∂ w j 1 = ( o 1 − t ) ∂ o 1 ∂ w j 1 \frac{\partial loss}{\partial w_{j1}} = (o_1 - t)\frac{\partial o_1}{\partial w_{j1}}
∂ w j 1 ∂ l o s s = ( o 1 − t ) ∂ w j 1 ∂ o 1
而o 1 = s i g m o i d ( z 1 ) o_1 = sigmoid(z_1) o 1 = s i g m o i d ( z 1 ) s i g m o i d ′ = s i g m o i d − s i g m o i d 2 {sigmoid}' = sigmoid - {sigmoid}^2 s i g m o i d ′ = s i g m o i d − s i g m o i d 2
∂ l o s s ∂ w j 1 = ( o 1 − t ) ( s i g m o i d ( z 1 ) − s i g m o i d ( z 1 ) 2 ) ∂ z 1 ∂ w j 1 \frac{\partial loss}{\partial w_{j1}} = (o_1 - t)(sigmoid(z_1) - sigmoid(z_1)^2)\frac{\partial z_1}{\partial w_{j1}}
∂ w j 1 ∂ l o s s = ( o 1 − t ) ( s i g m o i d ( z 1 ) − s i g m o i d ( z 1 ) 2 ) ∂ w j 1 ∂ z 1
其中∂ z 1 ∂ w j 1 = x j \frac{\partial z_1}{\partial w_{j1}} = x_j ∂ w j 1 ∂ z 1 = x j
∂ l o s s ∂ w j 1 = ( o 1 − t ) ( s i g m o i d ( z 1 ) − s i g m o i d ( z 1 ) 2 ) x j \frac{\partial loss}{\partial w_{j1}} = (o_1 - t)(sigmoid(z_1) - sigmoid(z_1)^2)x_j
∂ w j 1 ∂ l o s s = ( o 1 − t ) ( s i g m o i d ( z 1 ) − s i g m o i d ( z 1 ) 2 ) x j
我们再把s i g m o i d ( z 1 ) sigmoid(z_1) s i g m o i d ( z 1 ) o 1 o_1 o 1
∂ l o s s ∂ w j 1 = ( o 1 − t ) ( o 1 − o 1 2 ) x j \frac{\partial loss}{\partial w_{j1}} = (o_1 - t)(o_1 - {o_1}^2)x_j
∂ w j 1 ∂ l o s s = ( o 1 − t ) ( o 1 − o 1 2 ) x j
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import tensorflow as tfx = tf.random.normal([1 ,3 ]) w = tf.ones([3 ,1 ]) b = tf.ones([1 ]) y = tf.constant([1 ]) with tf.GradientTape() as tape: tape.watch([w,b]) logits = tf.sigmoid(x@w + b) loss = tf.reduce_mean(tf.losses.MSE(y,logits)) grads = tape.gradient(loss,[w,b]) print(grads[0 ]) print(grads[1 ])
运行结果:
1 2 3 4 5 tf.Tensor( [[-0.00134863] [-0.00221338] [-0.00171576]], shape=(3, 1), dtype=float32) tf.Tensor([-0.00225344], shape=(1,), dtype=float32)
多个输出节点的全连接层
现在,我们把一个输出节点的全连接层扩展到多个输出节点的全连接层。
l o s s = 1 2 ∑ i = 1 K ( o i ( 1 ) − t i ) 2 loss = \frac{1}{2}\sum_{i=1}^{K}\Big( o_i^{(1)} - t_i \Big)^2
l o s s = 2 1 i = 1 ∑ K ( o i ( 1 ) − t i ) 2
而且,如图所示,我们发现w j k ( 1 ) w^{(1)}_{jk} w j k ( 1 ) z k ( 1 ) z^{(1)}_k z k ( 1 ) o k ( 1 ) o^{(1)}_k o k ( 1 )
∂ l o s s ∂ w j k = ( o k − t k ) ∂ o k w j k \frac{\partial loss}{\partial w_{jk}} = (o_k - t_k)\frac{\partial o_k}{w_{jk}}
∂ w j k ∂ l o s s = ( o k − t k ) w j k ∂ o k
与之前的讨论类似。o k = s i g m o i d ( z k ) o_k = sigmoid(z_k) o k = s i g m o i d ( z k ) s i g m o i d ′ = s i g m o i d − s i g m o i d 2 {sigmoid}' = sigmoid - {sigmoid}^2 s i g m o i d ′ = s i g m o i d − s i g m o i d 2
∂ l o s s ∂ w j k = ( o k − t k ) ( s i g m o i d ( z k ) − s i g m o i d ( z k ) 2 ) ∂ z k ∂ w j k \frac{\partial loss}{\partial w_{jk}} = (o_k - t_k)(sigmoid(z_k) - sigmoid(z_k)^2)\frac{\partial z_k}{\partial w_{jk}}
∂ w j k ∂ l o s s = ( o k − t k ) ( s i g m o i d ( z k ) − s i g m o i d ( z k ) 2 ) ∂ w j k ∂ z k
其中∂ z k ∂ w j k = x j \frac{\partial z_k}{\partial w_{jk}} = x_j ∂ w j k ∂ z k = x j
∂ l o s s ∂ w j k = ( o k − t k ) ( s i g m o i d ( z k ) − s i g m o i d ( z k ) 2 ) x j \frac{\partial loss}{\partial w_{jk}} = (o_k - t_k)(sigmoid(z_k) - sigmoid(z_k)^2)x_j
∂ w j k ∂ l o s s = ( o k − t k ) ( s i g m o i d ( z k ) − s i g m o i d ( z k ) 2 ) x j
我们再把s i g m o i d ( z k ) sigmoid(z_k) s i g m o i d ( z k ) o k o_k o k
∂ l o s s ∂ w j k = ( o k − t k ) ( o k − o k 2 ) x j \frac{\partial loss}{\partial w_{jk}} = (o_k - t_k)(o_k - o_k^2)x_j
∂ w j k ∂ l o s s = ( o k − t k ) ( o k − o k 2 ) x j
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import tensorflow as tfx = tf.random.normal([2 ,4 ]) w = tf.ones([4 ,3 ]) b = tf.ones([3 ]) y = tf.constant([2 ,0 ]) y = tf.one_hot(y,depth=3 ) with tf.GradientTape() as tape: tape.watch([w,b]) prob = tf.nn.softmax(x@w + b,axis=1 ) loss = tf.reduce_mean(tf.losses.MSE(y,prob)) grads = tape.gradient(loss,[w,b]) print(grads[0 ]) print(grads[1 ])
运行结果:
1 2 3 4 5 6 tf.Tensor( [[-0.02149573 -0.02382743 0.04532316] [-0.00848718 0.1299872 -0.12150002] [ 0.16653773 -0.00511115 -0.16142657] [-0.11861646 0.05700291 0.06161355]], shape=(4, 3), dtype=float32) tf.Tensor([-0.03703704 0.07407407 -0.03703704], shape=(3,), dtype=float32)