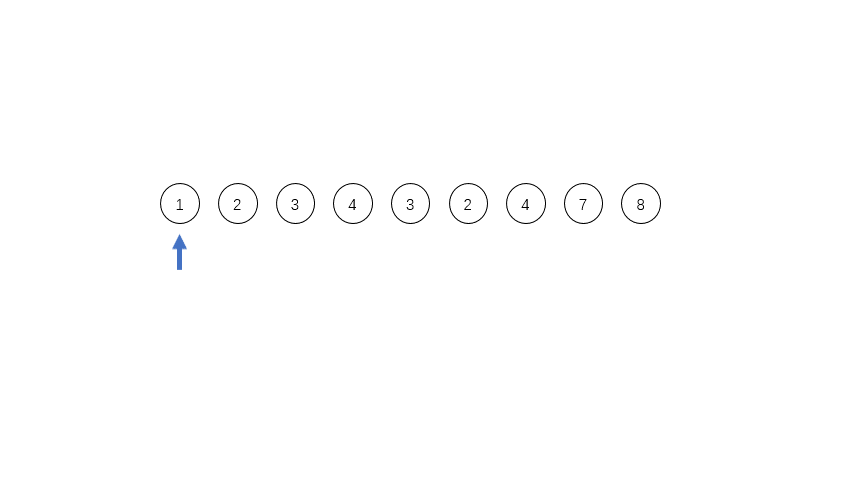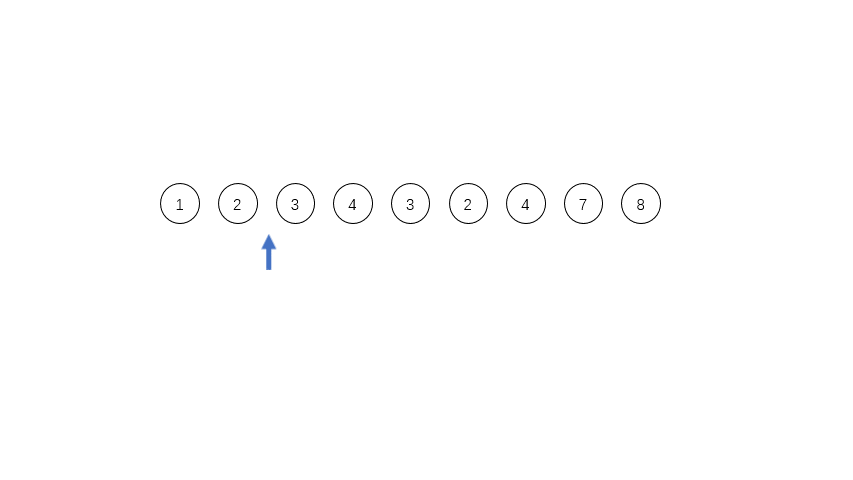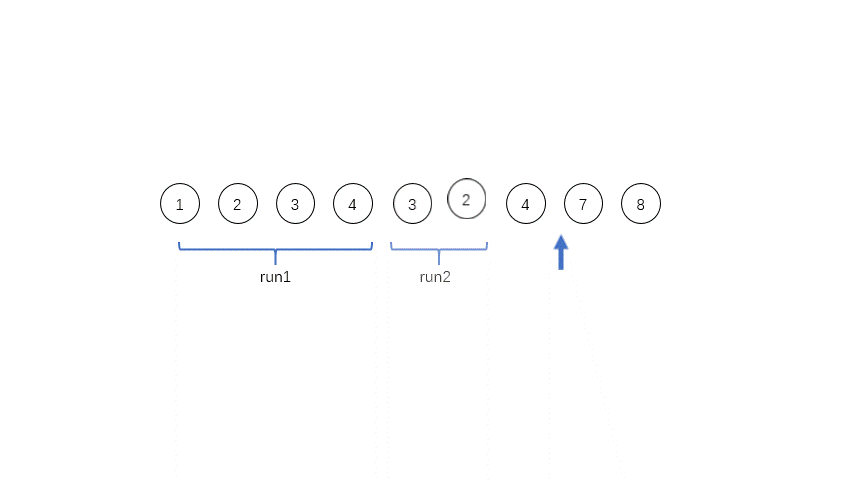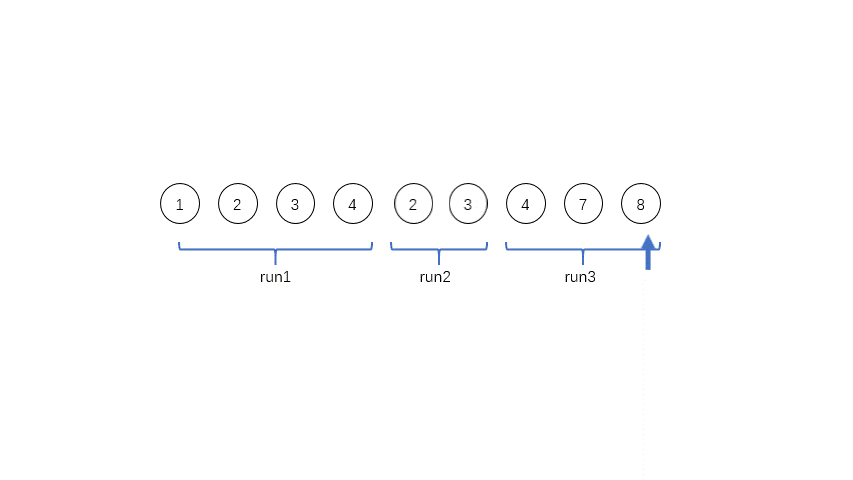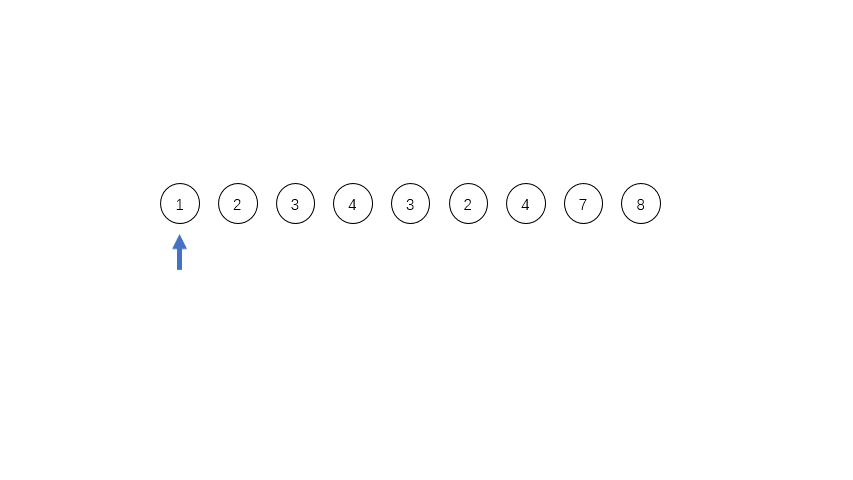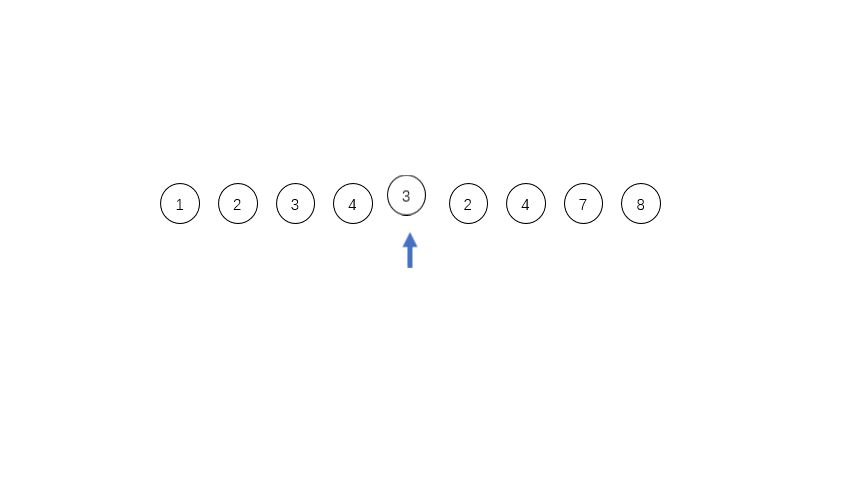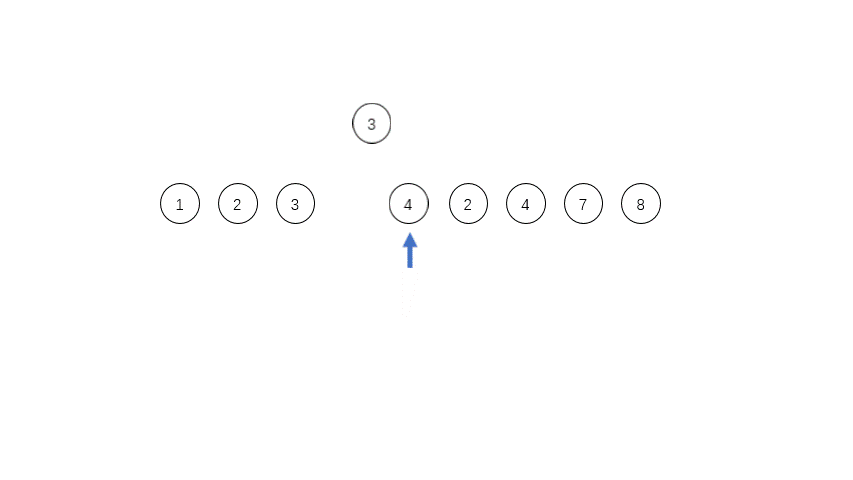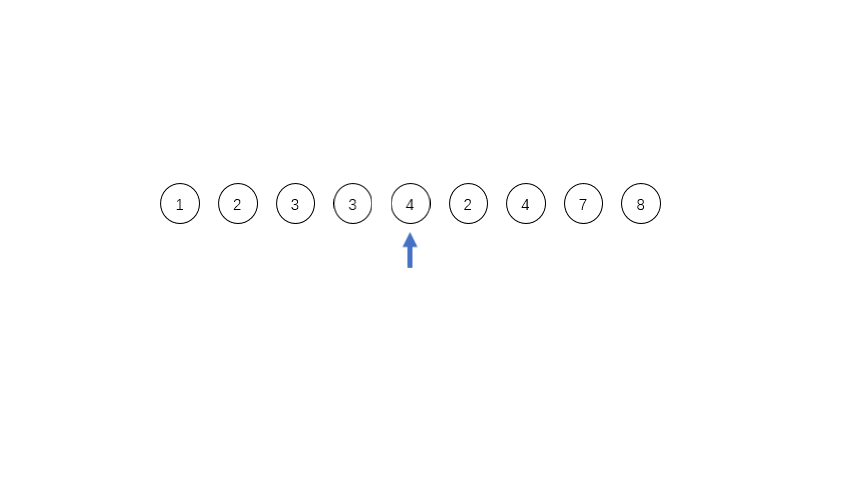排序,这个我们太常用了。而且估计99%的编程语言都内置了排序算法。
示例代码:
1 2 3 int [] a = {3 , 1 , 4 , 5 , 9 , 2 , 6 };Arrays.sort(a); System.out.println(Arrays.toString(a));
运行结果:
示例代码:
1 2 3 a = [3 , 1 , 4 , 5 , 9 , 2 , 6 ] a.sort() print(a)
运行结果:
那些编程语言内置的排序算法是什么?
如何评价一个排序算法
那些创造编程语言的人,才是真正的顶级软件工程师。
所以,我们讨论的第一个问题是,如何评价一个排序算法 ?
关于如何评价一个算法,这个我们讨论过了,两个指标,时间复杂度和空间复杂度。
原地排序
稳定性
原地排序
原地排序(Sorted in place),特指空间复杂度是O ( 1 ) O(1) O ( 1 )
稳定性
如果待排序的序列中存在值相等的元素,经过排序之后,相等的元素之间的原有先后顺序不变。我们就说这个排序算法是稳定的。
举个例子。3,1,4,1,5,9,2,6,其中第一个1的内存位置是a,第二个1的内存位置是b。在经过某个排序算法排序之后,是1,1,2,3,4,5,6,9,并且内存地址为a的1依旧在前面,内存地址为b的1依旧在后面。那么,我们说这个排序算法是稳定的了。
如果b在前,a在后呢?那就不稳定了。
再举个例子
方案一:
完了,如果排序算法不稳定的话,第二步会把第一步按涨跌幅排好的顺序给弄乱了。
方案二:
方案三: 稳定的排序可以保持成交量相同的两只股票,在排序之后的前后顺序不变。
这就是为什么我们要求排序算法稳定。
选择排序
接下来,我们来依次讨论八大排序算法。
选择排序的过程
在第一章讨论时间复杂度的时候,我们已经讨论过了选择排序。当时我们以选择排序为例,讨论了计算时间复杂度的第一个规则:把整个流程拆分为一个个不可以再拆分的常数操作,只考虑最高阶。
现在,我们复习一下选择排序。
排序之前:
1 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
第一轮
3和44相比,3最小,记住最小值的index 3和38相比,3最小,记住最小值的index 3和5相比,3最小,记住最小值的index ······ 最后,我们把最小值移到前部,和0位置的数字进行互换。
1 [2,44,38,5,47,15,36,26,27,3,46,4,19,50,48]
第二轮
1 [2,3,38,5,47,15,36,26,27,44,46,4,19,50,48]
如此迭代循环,每一轮都选择当前轮的最小数,通过互换移到前面,最后完成排序过程。
选择排序的实现
这个参考第一章的代码,不再赘述。
选择排序的特点
我们从三个角度去讨论选择排序的特点。
时间复杂度
是否原地排序(空间复杂度)
是否稳定
时间复杂度
O ( n 2 ) O(n^2) O ( n 2 )
是否原地排序
是原地排序。选择排序只涉及到数据交换,只需要常量级别的额外空间,空间复杂度为O ( 1 ) O(1) O ( 1 )
是否稳定
不稳定
20 2 ^ 1 20\widehat{\bold{2}}1
2 0 2 1
为了以示区分,第二个2,我们写作2 ^ \widehat{\bold{2}} 2
第一轮,当前轮的最小数是0 0 0 2 2 2
02 2 ^ 1 02\widehat{\bold{2}}1
0 2 2 1
第二轮,当前轮的最小数是1 1 1 2 2 2
01 2 ^ 2 01\widehat{\bold{2}}2
0 1 2 2
2的位置不对了。2 2 2 2 ^ \widehat{\bold{2}} 2 2 ^ \widehat{\bold{2}} 2 2 2 2
冒泡排序
接下来,我们讨论第二个排序算法:冒泡排序。
冒泡排序的过程
在第一章,我们以冒泡排序算法为例,讨论了计算时间复杂度的第二个规则:最有参考价值的是最坏时间复杂度
排序之前:
1 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
冒泡过程:
1 [3,38,44,5,47,15,36,26,27,2,46,4,19,50,48]
继续,index为2的数字和index为3的数字进行比较,44和5比较,左边(index为2)的的数大,交换。(冒泡)得到
1 [3,38,5,44,47,15,36,26,27,2,46,4,19,50,48]
最后,当我们index为n-1的数字和index为n的数字进行比较,并按条件进行交换之后,一定是最大的数在最右边。然后我们再进行一轮,这样第二大的数会在从右往左第二个。
如此迭代循环,大的数就像冒泡一样,一个一个冒上去。
需要注意的是:当两个元素大小相等 的时候,我们不交换 。这样才能保证冒泡排序的稳定性。
冒泡排序的实现
这个参考第一章的代码,不再赘述。
冒泡排序的特点
时间复杂度
最坏时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
最好时间复杂度:O ( n ) O(n) O ( n )
是否原地排序
是原地排序。冒泡排序同样只涉及到数据交换,只需要常量级别的额外空间,空间复杂度为O ( 1 ) O(1) O ( 1 )
是否稳定
稳定
插入排序
第三个排序算法,插入排序。
插入排序的过程
“酒一口一口喝,路一步一步走。”
排序之前:
1 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
第一步:
第二步:
1 [3,38,44,5,47,15,36,26,27,2,46,4,19,50,48]
index为1的数再和index为0的数比较,38个2比较,38比3大,有序,不做操作。
第三步:
1 [3,38,5,44,47,15,36,26,27,2,46,4,19,50,48]
index为2的数字和index为1的数字比较,5比38小,互换。得到
1 [3,5,38,44,47,15,36,26,27,2,46,4,19,50,48]
再把index为1的数字和index为0的数字比较,5和3比较,有序,不做操作。
按照上述的操作迭代,按顺序插入,先部分有序,最后整体有序。
插入排序的实现
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 package ch05;import java.util.Arrays;public class InsertionSort public static void main (String[] args) int [] arr = {3 ,44 ,38 ,5 ,47 ,15 ,36 ,26 ,27 ,2 ,46 ,4 ,19 ,50 ,48 }; System.out.println(Arrays.toString(arr)); if (null != arr && arr.length > 1 ){ arr = insertionSort(arr); } System.out.println(Arrays.toString(arr)); } public static int [] insertionSort(int [] arr){ for (int i = 1 ; i < arr.length; i++) { int maxIndex = i; for (int j = maxIndex; j > 0 ; j--) { if (arr[j] < arr[j-1 ]){ swap(arr,j,j-1 ); }else { break ; } } } return arr; } public static void swap (int [] arr,int i,int j) int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } }
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
特别注意:
一定不能是
否则就不稳定了。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def insertionSort (arr_args) : """ 插入排序 :param arr_args: 需要排序的数组 :return: 排序之后的数组 """ for i in range(1 , len(arr_args)): maxIndex = i for j in range(maxIndex, 0 , -1 ): if arr_args[j] < arr_args[j - 1 ]: arr_args[j], arr_args[j - 1 ] = arr_args[j - 1 ], arr_args[j] else : break return arr_args if __name__ == '__main__' : arr = [3 , 44 , 38 , 5 , 47 , 15 , 36 , 26 , 27 , 2 , 46 , 4 , 19 , 50 , 48 ] print(arr) print(insertionSort(arr))
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
特别注意:
1 if arr_args[j] < arr_args[j - 1 ]
一定不能是
1 if arr_args[j] <= arr_args[j - 1]
否则就不稳定了。
插入排序的特点
时间复杂度
最坏时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
最好时间复杂度:O ( n ) O(n) O ( n )
是否原地排序
是原地排序。
是否稳定
稳定
对数器
截止目前,我们已经实现了三个排序算法。
例如,对我们写的选择排序算法进行核验,和Java或者Python自带的排序方法进行比较。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 package ch05;import java.util.Arrays;public class Comparator public static void main (String[] args) throws Exception int testTimes = 5000 ; int maxSize = 100 ; int maxValue = 100 ; boolean isSuccess = true ; for (int i = 0 ; i < testTimes; i++) { int [] arr1 = genRandomArr(maxSize,maxValue); int [] arr2 = copyArr(arr1); knownFunc(arr1); InsertionSort.insertionSort(arr2); if (isEqual(arr1,arr2) == false ){ isSuccess = false ; break ; } } System.out.print(isSuccess); } public static int [] genRandomArr(int maxSize,int maxValue){ int [] arr = new int [(int )(Math.random() * maxSize)]; for (int i = 0 ; i < arr.length; i++) { arr[i] = (int )(Math.random() * maxValue); } return arr; } public static int [] copyArr(int [] arr){ if (null == arr){ return null ; } int [] rnt = new int [arr.length]; for (int i = 0 ; i < arr.length; i++) { rnt[i] = arr[i]; } return rnt; } public static void knownFunc (int [] arr) Arrays.sort(arr); } public static boolean isEqual (int [] arr1,int [] arr2) if ((null == arr1 && null != arr2) || (null != arr1 && null == arr2)){ return false ; } if (null == arr1 && null == arr2){ return true ; } if (arr1.length != arr2.length){ return false ; } for (int i = 0 ; i < arr1.length; i++) { if (arr1[i] != arr2[i]){ return false ; } } return true ; } }
运行结果:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import randomfrom ch05 import InsertionSortdef knownFunc (arr_args) : """ 已经知道的方法 :param arr_args: 需要排序的数组 :return: 排序好的数组 """ list.sort(arr_args) return arr_args def genRandomArr (max_size, max_value) : """ 生成一个随机的数组 :param max_size: 生成的随机数组的最大长度 :param max_value: 生成的随机数组的最大值 :return: 生成的随机数组 """ arr_rnt = [] randomSize = random.randint(0 , max_size) for i in range(randomSize): arr_rnt.append(random.randint(0 , max_value)) return arr_rnt if __name__ == '__main__' : testTimes = 5000 maxSize = 100 maxValue = 100 isSuccess = True for i in range(testTimes): arr1 = genRandomArr(maxSize, maxValue) arr2 = arr1.copy() arr1 = knownFunc(arr1) arr2 = InsertionSort.insertionSort(arr2) if arr1 != arr2: isSuccess = False break print(isSuccess)
运行结果:
归并排序
接下来,我们讨论归并排序。
归并排序的过程
排序之前:
1 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
准备操作
把数据平均的分成两组。前8个数字为一组,3到26;后7个数字为一组,27到48。 对于这两组数字再进行拆分。第一组的前4个数字为一组,后4个数字为一组。第二组的前4个数字为一组,后3个数字为一组。 如此,一直进行拆分,直到不可分。
归并操作 第一步
现在3和44是两个独立的小组,两个小组均有一个指针,指针指向第一个元素。指针所指的元素进行比较,3和44比较,3比44小,先排3,再排44。两个小组都空了,合并成一个新的小组。 38和5是两个独立的小组,两个小组均有一个指针,指针指向第一个元素。指针所指的元素进行比较,38和5大比较,5比38小,先排5,再排38。两个小组都空了,合并成一个小组。
归并操作 第二步 [3,44]、[5,38]。两个小组均有一个指针,指针指向第一个元素。
指针所指的元素进行比较。3和5比较,3比5小。排3,再排谁还要再比较 。 [3,44]的指针后移,[5,38]的指针保持不动。指针所指向的元素进行比较。44和5比较,5比44小,排5,再排谁还要再比较 [5,38]的指针后移,[3,44]的指针保持不懂。指针所指向的元素进行比较。44和38比较,38比44小。排38,再排44。两个小组都空了,合并成一个小组。
如此迭代循环,通过递归,按顺序合并的方法,最后完成排序操作。
归并排序的实现
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 package ch05;import java.util.Arrays;public class MergeSort public static int [] mergeSort(int [] arr,int L,int R) throws Exception { if (L == R){ return arr; } int M = (L+R)/2 ; mergeSort(arr, L, M); mergeSort(arr,M+1 ,R); merge(arr, L, M, R); return arr; } private static void merge (int [] arr, int L, int M, int R) int [] help = new int [R - L + 1 ]; int helpPoint = 0 ; int p1 = L; int p2 = M + 1 ; while (p1 <= M && p2 <= R) { help[helpPoint++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++]; } while (p1 <= M) { help[helpPoint++] = arr[p1++]; } while (p2 <= R) { help[helpPoint++] = arr[p2++]; } for (int i = 0 ; i < help.length; i++) { arr[L + i] = help[i]; } } public static void main (String[] args) throws Exception int [] arr = {3 ,44 ,38 ,5 ,47 ,15 ,36 ,26 ,27 ,2 ,46 ,4 ,19 ,50 ,48 }; System.out.println(Arrays.toString(arr)); if (null != arr && arr.length > 1 ){ arr = mergeSort(arr,0 ,arr.length-1 ); } System.out.println(Arrays.toString(arr)); } }
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 def mergeSort (arr, L, R) : if L == R: return arr M = (L + R) // 2 mergeSort(arr, L, M) mergeSort(arr, M + 1 , R) merge(arr, L, M, R) return arr def merge (arr, L, M, R) : helpArr = [None ] * (R - L + 1 ) helpPoint = 0 p1 = L p2 = M + 1 while p1 <= M and p2 <= R: if arr[p1] <= arr[p2]: helpArr[helpPoint] = arr[p1] p1 = p1 + 1 else : helpArr[helpPoint] = arr[p2] p2 = p2 + 1 helpPoint = helpPoint + 1 while p1 <= M: helpArr[helpPoint] = arr[p1] helpPoint = helpPoint + 1 p1 = p1 + 1 while p2 <= R: helpArr[helpPoint] = arr[p2] helpPoint = helpPoint + 1 p2 = p2 + 1 for i in range(len(helpArr)): arr[L + i] = helpArr[i] if __name__ == '__main__' : a = [3 , 44 , 38 , 5 , 47 , 15 , 36 , 26 , 27 , 2 , 46 , 4 , 19 , 50 , 48 ] print(a) if a is not None and len(a) > 1 : a = mergeSort(a, 0 , len(a) - 1 ) print(a)
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
归并排序的特点
时间复杂度
时间复杂度的计算
归并排序的时间复杂度比较复杂,因为涉及到递归。我们再来捋一下递归的过程。
T ( 大问题 ) = T ( 小问题一 ) + T ( 小问题二 ) + K T(\text{大问题}) = T(\text{小问题一}) + T(\text{小问题二}) + K
T ( 大问题 ) = T ( 小问题一 ) + T ( 小问题二 ) + K
小问题又可以拆成两个小小问题,一直拆分。所以,归并排序的时间复杂度是O ( n log n ) O(n \log n) O ( n log n )
而我们之前讨论的排序算法,时间复杂度都是O ( n 2 ) O(n^2) O ( n 2 )
求个极限
lim n → ∞ n log n n 2 = lim n → ∞ log n n = 0 \lim_{n \rightarrow \infty} \frac{n \log n}{n^2} = \lim_{n \rightarrow \infty} \frac{\log n}{n} = 0
n → ∞ lim n 2 n log n = n → ∞ lim n log n = 0
分别画一下log n \log n log n n n n
O ( n log n ) < O ( n 2 ) O(n \log n) < O(n^2)
O ( n log n ) < O ( n 2 )
为什么归并排序的时间复杂度小
那么为什么归并排序排序的时间复杂度更小呢?归并排序和之前讨论的排序算法,相比之下具体优势在哪里呢?
选择排序 浪费比较行为!
冒泡排序
插入排序 O ( n 2 ) O(n^2) O ( n 2 )
归并排序 9 5 2 7。9和5进行比较,得到5 9,顺序已经固定了。2和7进行比较,得到2 7,顺序也已经固定了。5 9和2 7进行比较,得到2 5 7 9,顺序也固定了。
是否原地排序
当然不是原地排序。都用到了辅助数组了,怎么会是原地。O ( n ) O(n) O ( n )
是否稳定
稳定。左边的数小于或等于 右边的数的时候,我们先排左边的数。
快速排序
接下来,讨论快速排序。
Partition过程
给定一个数组Arr,和一个数字Num。把小于等于Num的数放在数组的左边,大于Num的数放在数组右边。O ( n ) O(n) O ( n )
这个问题太简单了,我们创建两个数组,小于等于数组和大于数组,Arr中的每个数都和Num进行比较,小于等于Num的插入小于等于数组,大于Num的插入大于数组。插入的时候注意,不要往头部插入,从尾部插入,因为从头部插入每次插入后面的数字都要后移。小于等于数组和大于数组两个数组拼接一下。O ( n ) O(n) O ( n )
现在,我们再加一个要求。O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
我们这么做。Arr是
1 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
Num是21。
第一个指针是i,用来遍历数组。初始值为0。
第二个指针是小于等于边界,用来记录小于等于的边界。初始值为-1。-1是数组的最后一个元素,但在这里不是这个含义。)
我们解决方案的核心就两点:
如果Arr[i]小于或等于Num,Arr[i]和小于等于边界的下一个位置的数进行交换。然后i ++,小于等于边界也 ++
如果Arr[i]大于Num,只有i ++。
在上例中。
Arr[0]和Num比较,3小于或等于21,3和小于等于边界的下一个位置的数进行交换,小于等于边界的下一个位置就是0位置,所以3的位置不动。i ++,小于等于边界也 ++。此时i等于1,小于等于边界等于0。1 [3] [44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
Arr[1]和Num比较,44大于21,只有i ++。i等于2。Arr[2]和Num比较,38大于21,只有i ++。i等于3。Arr[3]和Num比较,5小于或等于21,5和小于等于边界的下一个位置的数进行交换,即5和44进行交换。然后i ++,小于等于边界也 ++。此时i等于4,小于等于边界等于1。1 [3 ,5] [38, 44, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
如此迭代循环,完成。
荷兰国旗问题
现在,我们把问题升级一下。Num的放左边,大于Num的放右边,等于Num的放中间。
美国大选?
这个问题,更为人知的一个名字是荷兰国旗。
但是,叫什么名字无所谓。
我们把代号拿掉,关注问题本身。
第一个指针依旧是i,用来遍历数组。初始值为0。
第二个指针是小于边界,用来记录小于的边界。初始值为-1。-1是数组的最后一个元素,但在这里不是这个含义。)
第三个指针是大于边界,用来记录大于的边界。初始指为数组的长度。
我们解决方案的核心就三点:
如果Arr[i]等于Num,i ++。
如果Arr[i]小于Num,Arr[i]与小于边界右一个交换,小于边界右移,i ++。
如果Arr[i]大于Num,Arr[i]与大于边界左一个交换,大于边界左移。i不动。
继续以刚刚的数组为例,现在我们假设Num是19。
Arr[0]和Num比较,3小于19,3和小于边界右一个位置的数进行交换,小于边界的右一个位置就是0位置,所以3的位置不动。i ++,小于边界右扩,也 ++。此时i等于1,小于等于边界等于0。1 [3] [44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
Arr[1]和Num比较,44大于19,44和大于边界左一个位置的数进行交换,大于边界的左一个位置的数是48,44和48交换。大于边界左扩,i不动。此时i依旧等于1,大于边界是14。1 [3] [48, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50] [44]
Arr[1]和Num比较,48大于19,48和大于边界左一个位置的数进行交换,大于边界的左一个位置的数是50,48和50交换。大于边界左扩,i不动。此时i依旧等于1,大于边界是13。1 [3] [50, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19] [48, 44]
Arr[1]和Num比较,50大于19,50和大于边界左一个位置的数进行交换,大于边界的左一个位置的数是19,50和19交换。大于边界左扩,i不动。此时i依旧等于1,大于边界是12。1 [3] [19, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4] [50, 48, 44]
Arr[1]和Num比较,19等于19。i ++。1 [3] [19, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4] [50, 48, 44]
如此迭代循环,完成。
基于荷兰国旗问题的快排
现在,我们把荷兰国旗问题做一些微小的改动。Num了,Arr的最后一个元素就是Num。小于边界内的元素都是小于Num的,中间的元素都是等于Num的,大于边界内的元素都是大于Num的,再把最后一个元素和大于边界的第一个元素交换,大于边界右移。Num的,中间的元素都是等于Num的,右边的元素都是大于Num的。
代码实现如下:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 package ch05;import java.util.Arrays;public class NetherlandsFlag_QuickSort public static int [] netherlandsFlag(int [] arr,int L,int R){ int less = L - 1 ; int more = R; int index = L; while (index < more) { if (arr[index] == arr[R]) { index = index + 1 ; } else if (arr[index] < arr[R]) { swap(arr, less + 1 , index); less = less + 1 ; index = index + 1 ; } else { swap(arr, index, more-1 ); more = more - 1 ; } } swap(arr, more, R); return new int [] { less + 1 , more }; } public static void swap (int [] arr,int i,int j) int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } public static int [] quickSort(int [] arr, int L, int R) { if (L >= R) { return arr; } int [] equalArea = netherlandsFlag(arr, L, R); quickSort(arr, L, equalArea[0 ] - 1 ); quickSort(arr, equalArea[1 ] + 1 , R); return arr; } public static void main (String[] args) int [] arr = {3 ,44 ,38 ,5 ,47 ,15 ,36 ,26 ,27 ,2 ,46 ,4 ,19 ,50 ,48 }; System.out.println(Arrays.toString(arr)); if (null != arr && arr.length > 1 ){ arr = quickSort(arr,0 ,arr.length-1 ); } System.out.println(Arrays.toString(arr)); } }
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 def netherlandsFlag (arr, L, R) : """ 荷兰国旗过程 :param arr: 参与荷兰过程过程的数组 :param L: 左边界 :param R: 右边界 :return: 荷兰国旗过程之后的新的边界 """ less = L - 1 more = R index = L while index < more: if arr[index] == arr[R]: index = index + 1 elif arr[index] < arr[R]: arr[less + 1 ], arr[index] = arr[index], arr[less + 1 ] less = less + 1 index = index + 1 else : arr[index], arr[more - 1 ] = arr[more - 1 ], arr[index] more = more - 1 arr[more], arr[R] = arr[R], arr[more] return [less + 1 , more] def quickSort (arr, L, R) : if L >= R: return arr equalArea = netherlandsFlag(arr, L, R) quickSort(arr, L, equalArea[0 ] - 1 ) quickSort(arr, equalArea[1 ] + 1 , R) return arr if __name__ == '__main__' : a = [3 , 44 , 38 , 5 , 47 , 15 , 36 , 26 , 27 , 2 , 46 , 4 , 19 , 50 , 48 ] print(a) print(quickSort(a, 0 , len(a) - 1 ))
运行结果:
1 2 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48] [2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
那么,现在有一个问题。基于荷兰国旗问题的快排,最坏的时间复杂度是多少?
每一轮的荷兰国旗过程,大于边界都要一步一步的从右推到最左边,然后才能确定一个数的位置。有N个数,就需要N轮。显然
O ( n 2 ) O(n^2)
O ( n 2 )
随机荷兰国旗快排
那么,现在有一个疑问了。O ( n 2 ) O(n^2) O ( n 2 )
别急,画龙就差最后一下"点睛"了。
我们在每一次荷兰国旗过程之前,都把Arr[R]和其他位置的任意一个数交换。
对于Java,我们在quickSort方法中添加这么一行。
1 swap(arr,L + (int ) (Math.random() * (R - L + 1 )), R);
对于Python,我们在quickSort方法中添加这么两行。
1 2 andomVal = randint(L, R) arr[randomVal], arr[R] = arr[R], arr[randomVal]
这样就是快速排序了。
来,我们分析一下。Num之后,Num处在中间的位置,而且这时候左右两侧的规模差不多。
如果Num处在中间的位置。这时候的时间复杂度是
T ( n ) = T ( n 2 ) + T ( n 2 ) + O ( n ) = O ( n log n ) \begin{aligned}
T(n) &= T(\frac{n}{2}) + T(\frac{n}{2}) + O(n) \\
&=O(n \log n)
\end{aligned}
T ( n ) = T ( 2 n ) + T ( 2 n ) + O ( n ) = O ( n log n )
而差的情况就是Num很偏,让左右两侧规模悬殊。
那么,我们随机选一个数。Num有可能在n 3 \frac{n}{3} 3 n
T ( n ) = T ( n 3 ) + T ( 2 3 n ) + O ( n ) T(n) = T(\frac{n}{3}) + T(\frac{2}{3}n) + O(n)
T ( n ) = T ( 3 n ) + T ( 3 2 n ) + O ( n )
Num有可能个在n 5 \frac{n}{5} 5 n
T ( N ) = T ( n 5 ) + T ( 4 5 n ) + O ( n ) T(N) = T(\frac{n}{5}) + T(\frac{4}{5}n) + O(n)
T ( N ) = T ( 5 n ) + T ( 5 4 n ) + O ( n )
Num有可能个在N 6 \frac{N}{6} 6 N Num有可能个在N 7 \frac{N}{7} 7 N Num有可能个在N 8 \frac{N}{8} 8 N Num有可能个在N 9 \frac{N}{9} 9 N Num有可能个在N 10 \frac{N}{10} 1 0 N
各种可能。
概率累加。
O ( n log n ) O(n \log n)
O ( n log n )
有点乱,有点乱。
最差的情况命中的概率也非常的小。
最坏的情况必命中。
快速排序
快速排序的特点
时间复杂度
最好时间复杂度:O ( n log n ) O(n \log n) O ( n log n )
最坏时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
平均时间复杂度:O ( n log n ) O(n \log n) O ( n log n )
通常所指的快速排序的时间复杂度是平均时间复杂度。
是否原地排序
正如我们之前讨论的,快速排序是基于荷兰国旗过程的,而荷兰国旗过程的空间复杂度就是O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
不是。因为要递归啊,递归的时候调用信息不得一个一个入栈?
那既然是递归呢,那就有不用递归的方法实现。O ( 1 ) O(1) O ( 1 )
也不是,因为每一轮递归或者每一轮循环,我们都要记两个东西,L和R。当然咯,我们可以用一个变量,记完L,释放,再记R。
O ( log n ) O(\log n)
O ( log n )
这就是快速排序的空间复杂度。
O ( log n ) O(\log n)
O ( log n )
有部分资料说快速排序的空间复杂度是O ( 1 ) O(1) O ( 1 )
是否稳定
不稳定。
57 7 ^ 81 57\widehat{\bold{7}}81
5 7 7 8 1
我们首先,随机选一个数和最后一个交换,比如选择了7 7 7
51 7 ^ 87 51\widehat{\bold{7}}87
5 1 7 8 7
然后进行荷兰国旗过程,依旧是
51 7 ^ 87 51\widehat{\bold{7}}87
5 1 7 8 7
再把7和大于边界的最左边的一个数交换。
51 7 ^ 78 51\widehat{\bold{7}}78
5 1 7 7 8
乱了,乱了,乱了。7 7 7 7 ^ \widehat{\bold{7}} 7 7 ^ \widehat{\bold{7}} 7 7 7 7
桶排序
最后,我们再讨论三个排序算法:桶排序、计数排序和基数排序。这三个排序算法的时间复杂度都是线性的,即O ( n ) O(n) O ( n )
桶排序的过程
桶排序的核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。
桶排序的特点
时间复杂度
假定要排序的数据有n n n m m m k = n m k=\frac{n}{m} k = m n O ( k log k ) O(k \log k) O ( k log k ) m m m O ( m ∗ k log k ) O(m*k \log k) O ( m ∗ k log k ) k = n m k=\frac{n}{m} k = m n O ( n log ( n m ) ) O(n \log (\frac{n}{m})) O ( n log ( m n ) ) m → n m \rightarrow n m → n log ( n m ) → 1 \log(\frac{n}{m}) \rightarrow 1 log ( m n ) → 1 O ( n ) O(n) O ( n )
你要有已经排好序的而且足够多的桶。所以,桶排序适用于量大但是范围小的问题。
数据在各个桶之间的分布是均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少。例如,如果数据都被划分到一个桶里,那时间复杂度就是O ( n log n ) O(n \log n) O ( n log n )
是否原地排序
不是O ( 1 ) O(1) O ( 1 )
是否稳定
稳定
计数排序
计数排序的过程
计数排序其实和桶排序非常的类似,只是桶的大小粒度不一样。可以理解为一种特殊的桶排序。
计数排序的特点
时间复杂度
O ( n + k ) O(n+k) O ( n + k )
是否原地排序
不是
是否稳定排序
是
计数排序同样适用于量大但是范围小的问题。
基数排序
基数排序的过程
假如数据量大,范围又大呢?
这时候就是基数排序了。
比如:
130928198905281793 130532197901235712 513221197102183838 610523198305134774 230111197104266110 510422198603243893 \begin{aligned}& 130928198905281793 \\& 130532197901235712 \\& 513221197102183838 \\& 610523198305134774 \\& 230111197104266110 \\& 510422198603243893 \end{aligned} 1 3 0 9 2 8 1 9 8 9 0 5 2 8 1 7 9 3 1 3 0 5 3 2 1 9 7 9 0 1 2 3 5 7 1 2 5 1 3 2 2 1 1 9 7 1 0 2 1 8 3 8 3 8 6 1 0 5 2 3 1 9 8 3 0 5 1 3 4 7 7 4 2 3 0 1 1 1 1 9 7 1 0 4 2 6 6 1 1 0 5 1 0 4 2 2 1 9 8 6 0 3 2 4 3 8 9 3
我们用稳定的排序算法,从最小的一位开始排序
23011119710426611 0 ^ 13053219790123571 2 ^ 13092819890528179 3 ^ 51042219860324389 3 ^ 61052319830513477 4 ^ 51322119710218383 8 ^ \begin{aligned}& 23011119710426611 \widehat{\bold{0}} \\& 13053219790123571 \widehat{\bold{2}} \\& 13092819890528179 \widehat{\bold{3}} \\& 51042219860324389 \widehat{\bold{3}} \\& 61052319830513477 \widehat{\bold{4}} \\& 51322119710218383 \widehat{\bold{8}} \end{aligned} 2 3 0 1 1 1 1 9 7 1 0 4 2 6 6 1 1 0 1 3 0 5 3 2 1 9 7 9 0 1 2 3 5 7 1 2 1 3 0 9 2 8 1 9 8 9 0 5 2 8 1 7 9 3 5 1 0 4 2 2 1 9 8 6 0 3 2 4 3 8 9 3 6 1 0 5 2 3 1 9 8 3 0 5 1 3 4 7 7 4 5 1 3 2 2 1 1 9 7 1 0 2 1 8 3 8 3 8
然后再用稳定的排序算法,对倒数第二位进行排序。
2301111971042661 1 ^ 0 ^ 1305321979012357 1 ^ 2 ^ 5132211971021838 3 ^ 8 ^ 6105231983051347 7 ^ 4 ^ 1309281989052817 9 ^ 3 ^ 5104221986032438 9 ^ 3 ^ \begin{aligned}& 2301111971042661 \widehat{\bold{1}} \widehat{\bold{0}} \\& 1305321979012357 \widehat{\bold{1}} \widehat{\bold{2}} \\& 5132211971021838 \widehat{\bold{3}} \widehat{\bold{8}} \\& 6105231983051347 \widehat{\bold{7}} \widehat{\bold{4}} \\& 1309281989052817 \widehat{\bold{9}} \widehat{\bold{3}} \\& 5104221986032438 \widehat{\bold{9}} \widehat{\bold{3}} \end{aligned} 2 3 0 1 1 1 1 9 7 1 0 4 2 6 6 1 1 0 1 3 0 5 3 2 1 9 7 9 0 1 2 3 5 7 1 2 5 1 3 2 2 1 1 9 7 1 0 2 1 8 3 8 3 8 6 1 0 5 2 3 1 9 8 3 0 5 1 3 4 7 7 4 1 3 0 9 2 8 1 9 8 9 0 5 2 8 1 7 9 3 5 1 0 4 2 2 1 9 8 6 0 3 2 4 3 8 9 3
再对第三位进行排序。
230111197104266 1 ^ 1 ^ 0 ^ 130532197901235 7 ^ 1 ^ 2 ^ 610523198305134 7 ^ 7 ^ 4 ^ 130928198905281 7 ^ 9 ^ 3 ^ 513221197102183 8 ^ 3 ^ 8 ^ 510422198603243 8 ^ 9 ^ 3 ^ \begin{aligned}& 230111197104266 \widehat{\bold{1}} \widehat{\bold{1}} \widehat{\bold{0}} \\& 130532197901235 \widehat{\bold{7}} \widehat{\bold{1}} \widehat{\bold{2}} \\& 610523198305134 \widehat{\bold{7}} \widehat{\bold{7}} \widehat{\bold{4}} \\& 130928198905281 \widehat{\bold{7}} \widehat{\bold{9}} \widehat{\bold{3}} \\& 513221197102183 \widehat{\bold{8}} \widehat{\bold{3}} \widehat{\bold{8}} \\& 510422198603243 \widehat{\bold{8}} \widehat{\bold{9}} \widehat{\bold{3}} \end{aligned} 2 3 0 1 1 1 1 9 7 1 0 4 2 6 6 1 1 0 1 3 0 5 3 2 1 9 7 9 0 1 2 3 5 7 1 2 6 1 0 5 2 3 1 9 8 3 0 5 1 3 4 7 7 4 1 3 0 9 2 8 1 9 8 9 0 5 2 8 1 7 9 3 5 1 3 2 2 1 1 9 7 1 0 2 1 8 3 8 3 8 5 1 0 4 2 2 1 9 8 6 0 3 2 4 3 8 9 3
以此类推,最后我们完成全国人民身份证号的排序。
但是基数排序要求数据能分割出独立的"位",而且"位"与"位"之间要有递进关系。
如果每个数据的长度不一,比如单词排序,我们还需要在不足的单词上补特殊的字符,例如"0"。
而且位之间还要排序,在基数排序中,位排序通常基于桶排序或者计数排序。
基数排序的特点
时间复杂度
O ( d n ) O(dn) O ( d n )
d d d 需要基于计数排序或者桶排序,否则没法做到O ( d n ) O(dn) O ( d n )
是否原地排序
不是
是否稳定
是。
八大排序算法的比较
现在,回到我们开篇的那个问题。
那些编程语言内置的排序算法是什么? \text{那些编程语言内置的排序算法是什么?}
那些编程语言内置的排序算法是什么?
我们把八大排序算法都找出来,大家来比赛。
接下来,会用比赛解说的模式。
时间复杂度
欢迎大家来到八大排序算法争夺编程语言内置排序算法的比赛现场。
首先登场的是选择排序,这也是我们认识的第一个排序算法,他的时间复杂度是O ( n 2 ) O(n^2) O ( n 2 )
第二个登场的是冒泡排序,这个排序算法的特点就是像冒泡一样,他的时间复杂度是多少呢?居然也是O ( n 2 ) O(n^2) O ( n 2 )
第三个排序算法登场了,插入排序,他的时间复杂度会也是O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 )
第四个排序算法,归并排序。时间复杂度!打破了!打破了O ( n 2 ) O(n^2) O ( n 2 ) O ( n log n ) O(n \log n) O ( n log n ) 归并排序暂时领先。
第五个排序算法来了,这个排序算法名字就好听,快速排序,看来这个排序算法就是主打快啊。他的时间复杂度是?O ( n 2 ) O(n^2) O ( n 2 ) 快速排序的排序算法,时间复杂居然是O ( n 2 ) O(n^2) O ( n 2 ) 快速排序的时间复杂度是O ( n log n ) O(n \log n) O ( n log n ) 快速排序极难命中最坏的情况O ( n 2 ) O(n^2) O ( n 2 )
接下来登场的是线性排序俱乐部的成员,线性排序作为针对特殊场景的排序算法,主打的就是快。那么,会打破O ( n log n ) O(n \log n) O ( n log n ) 桶排序!桶排序!时间复杂度!O ( n ) O(n) O ( n )
第七个排序算法,计数排序,时间复杂度O ( n + k ) O(n+k) O ( n + k ) 桶排序和计数排序都用了已经排序好的桶,属于作弊行为。成绩无效。
最后一个排序算法登场了,基数排序,时间复杂度O ( d n ) O(dn) O ( d n ) O ( d n ) O(dn) O ( d n ) 桶排序或者计数排序对每一位进行排序。成绩无效!
那么,第一轮是不是尘埃落定呢?这时候,我们看到,场上起了争执!线性排序俱乐部的成员似乎不服裁判的这次判决。组委会出来了!组委会居然登场了!组委居然补刀了,线性排序作为针对特殊场景的排序算法,没有争夺编程语言默认排序算法的资格,但是仍有资格参与比赛。
是否原地排序
好,经过短暂的休息之后,欢迎大家继续来到比赛现场。有些观众可能刚刚打开电视,对上一轮的比赛结果还不太熟悉。归并排序和快速排序并列第一,时间复杂度都是O ( n log n ) O(n \log n) O ( n log n ) 选择排序、冒泡排序和插入排序,他们的时间复杂度都是O ( n 2 ) O(n^2) O ( n 2 ) 线性排序俱乐部的三位选手,桶排序、计数排序和基数排序被裁判判决成绩无效,甚至被组委会取消了争夺编程语言默认排序算法的资格。但是组委会仍然允许他们参加比赛,我们看到他们也来到了现场,准备参加后续的比赛。O ( 1 ) O(1) O ( 1 )
首先上场的还是选择排序,看来几个排序算法的上场顺序已经确定了。选择排序,他的特点是每次选一个当前最小值放前面去,那么他能做到原地排序吗?选择排序给我们展示了,他只需要一个临时变量,把选中的值放前面的那一瞬间,做交换用!原地排序 !
接下来上场的是冒泡排序,我们知道插入排序、冒泡排序、选择排序、归并排序和快速排序,这五个都是基于比较的排序算法。选择排序一样,做到原地排序吗?果然,原地排序 !冒泡排序也只需要一个临时变量,在冒泡的时候,做交换用。
第三个,插入排序,没有疑问,插入排序也只需要一个临时变量,在插入的时候用。归并排序和快速排序他们可以做到吗?
归并排序登场了!诶,归并排序居然用了临时数组来做归并操作,而且这个临时数组的空间复杂度是O ( n ) O(n) O ( n ) 不是所有基于比较的排序算法,都是能做到原地排序。 第五个,快速排序,他会在做到时间复杂度为O ( n log n ) O(n \log n) O ( n log n ) 快速排序脱下了外套,我们看到里面居然穿着"荷兰国旗",快速排序表示自己的核心其实是荷兰国旗,荷兰国旗的空间复杂度是O ( 1 ) O(1) O ( 1 ) 快速排序在每一轮最少都要有一个变量记住L和R,空间复杂度是O ( log n ) O(\log n) O ( log n )
线性排序俱乐部登场了。可惜,他们都没能做到原地排序,他们都用了一个叫做桶的东西。
是否稳定
欢迎大家再回到比赛现场。在第一轮比赛中,冒泡排序、插入排序和选择排序虽然都在时间复杂度方面,以O ( n 2 ) O(n^2) O ( n 2 ) 归并排序和快速排序的O ( n log n ) O(n \log n) O ( n log n ) 归并排序和快速排序。而归并排序和快速排序,很遗憾,都没有做到原地排序。
首先上场的依旧是选择排序,诶?不稳定!选择排序不稳定。20 2 ^ 1 → 02 2 ^ 1 → 01 2 ^ 2 20\widehat{\bold{2}}1 \rightarrow 02\widehat{\bold{2}}1 \rightarrow 01\widehat{\bold{2}}2 2 0 2 1 → 0 2 2 1 → 0 1 2 2 2的位置,2的位置居然乱了。
第二个,冒泡排序,他能做到稳定吗?成功了!相等 的时候,冒泡不做交换 ,这样就做到了稳定!成功。
第三个,插入排序,插入排序也做到了稳定,插入排序说:对于相同的元素,我们会把后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变。
归并排序,归并排序如果也做到了稳定,那么他将会打破第三轮双雄争霸的局面。做到了!归并排序也能做到稳定!当左边的数小于或等于 右边的数的时候,归并排序先排了左边的数。稳定!快速排序,身穿"荷兰国旗"的快速排序是否稳定呢?57 7 ^ 81 57\widehat{\bold{7}}81 5 7 7 8 1 7 7 7 51 7 ^ 87 51\widehat{\bold{7}}87 5 1 7 8 7 快速排序开始进行荷兰国旗过程了,依旧是51 7 ^ 87 51\widehat{\bold{7}}87 5 1 7 8 7 快速排序还有最后一个步骤,最后的时刻会有奇迹发生吗?会有那扭转乾坤的临门一脚吗?快速排序把最后一个元素7 7 7 51 7 ^ 78 51\widehat{\bold{7}}78 5 1 7 7 8 快速排序不是稳定的排序算法。线性排序俱乐部上场了,开挂三人组,他们是桶排序、计数排序和基数排序。没有任何疑问,稳定。
全场比赛结束!冒泡排序、插入排序和归并排序都做到了稳定,选择排序和快速排序,很遗憾,并不是稳定的排序算法。线性排序俱乐部,因为针对特殊场景,虽然他们都做到了稳定,但是他们并没有资格作为编程语言的内置排序算法。
比赛统计表
欢迎大家再次回到比赛现场。
时间复杂度
是否原地排序
是否稳定
选择排序
O ( n 2 ) O(n^2) O ( n 2 ) 是
否
冒泡排序
O ( n 2 ) O(n^2) O ( n 2 ) 是
是
插入排序
O ( n 2 ) O(n^2) O ( n 2 ) 是
是
归并排序
O ( n log n ) O(n \log n) O ( n log n ) 否
是
快速排序
O ( n log n ) O(n \log n) O ( n log n ) 否
否
桶排序
O ( n ) O(n) O ( n ) 否
是
计数排序
O ( n + k ) O(n+k) O ( n + k ) 否
是
基数排序
O ( n + k ) O(n+k) O ( n + k ) 否
是
那么,最后会是谁呢?能够成为编程语言的内置排序算法。
我们看到!这时候有一个身影从天而降!
TimSort
我们讨论的最后一个排序算法,TimSort。
Tim Cook?Apple CEO,不是他。
Tim Berners-Lee?也不是他,他是在伦敦奥运会的开幕式敲代码的科学家,万维网的发明者。The Zen of Python(Python之禅)。
大家在交互式解释器中敲入import this就可以看到Tim Peters的The Zen of Python。
在上一节,我们提到了这么一句"还是说会有几个排序算法联合起来呢?"。二分插入排序和归并排序。
关于插入排序我们已经讨论过了,而二分插入排序,我们在讨论归并排序的时候提到了,就是用二分法来确定要插入的位置。(二分法会在下一章进行讨论)
run
TimSort其实基于了一个事实,在现实生活中,在大多数真实的数据集中,已经有很多元素是排好序的。可能整体是无序的,但是中间的某些子串是有序的。
那么,对于已经排好序的子串,在TimSort中,有一个特别的名字,run,指一个连续上升(包括相等)或者下降(不含相等)的子串。
比如对于序列[1,2,3,4,3,2,4,7,8],其中有三个run,第一个是[1,2,3,4],第二个是[3,2],第三个是[4,7,8]。这三个run都是单调的。run会被反转成单调递增的序列。
得到run之后,我们可以干嘛呢?minrun,表示每个run的最小长度,如果长度太短,会用二分法插入排序把run后面的元素插入到run内。minrun=5,那么第一个run是不符合要求的,就会把后面的3插入到第一个run里面,变成[1,2,3,3,4]。
二分插入出现了minrun取多少合适呢?这就是TimSort的高明之处了,自适应,会根据数据的特点来进行自我调整。minrun ∈ [ 32 , 64 ] \text{minrun} \in [32,64] minrun ∈ [ 3 2 , 6 4 ] minrun ∈ [ 16 , 32 ] \text{minrun} \in [16,32] minrun ∈ [ 1 6 , 3 2 ]
合并
拿到了run就需要合并了,这个也有讲究。run之后都有可能导致一次合并。
我们会有一个栈来保存每个run,比如对于上面的[1,2,3,4,3,2,4,7,8]这个例子,栈底是[1,2,3,4],中间是[3,2],栈顶是[4,7,8]。我们用X、Y和Z表示他们的长度,其中X在栈顶。
如果大家玩过一款叫做《1024》合并数字的游戏就知道。这个游戏的一个技巧是,我们总是要保证最里面的数最大。
与《1024》这款游戏类似,我们必须始终维持以下的两个规则:
Z > Y + X Y > X \begin{aligned}
& Z > Y + X \\
& Y > X
\end{aligned}
Z > Y + X Y > X
一旦有其中的一个条件不被满足,Y这个子序列就会和X与Z中较小的子序列合并形成一个新run,然后会再次检查栈顶的三个run看看是否仍然满足条件。如果不满足则会继续进行合并,直至栈顶的三个元素(如果只有两个run就只需要满足第二个条件)满足这两个条件。
TimSort过程
前面都是理论,现在我们举个例子,看看具体过程。
1 [8 10 15 6 18 12 7 5 4 3 20 8 11 22 9 9 17]
当然因为数据有限,我们设置minrun是4。
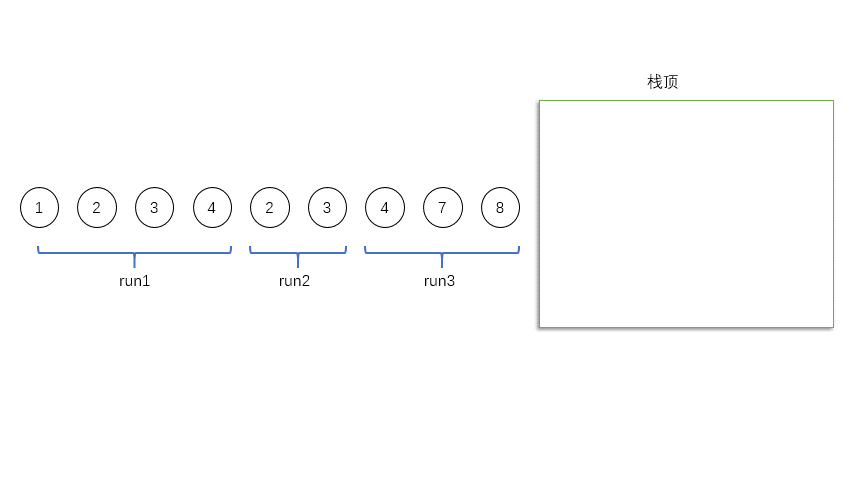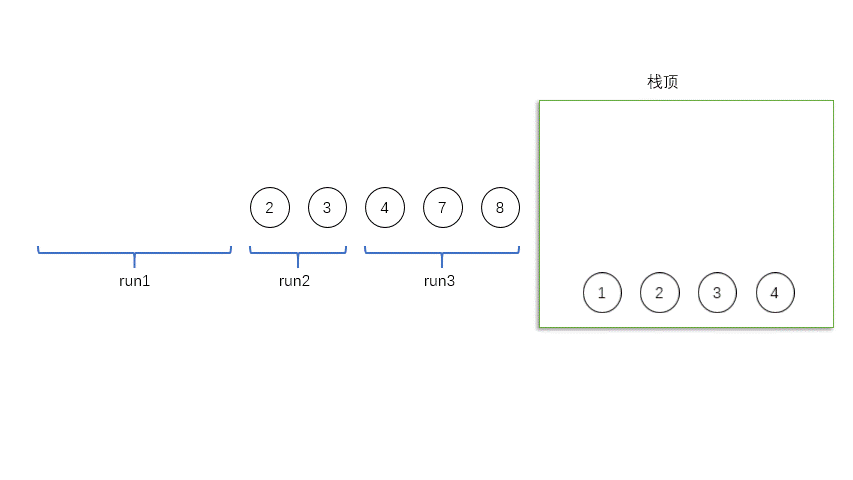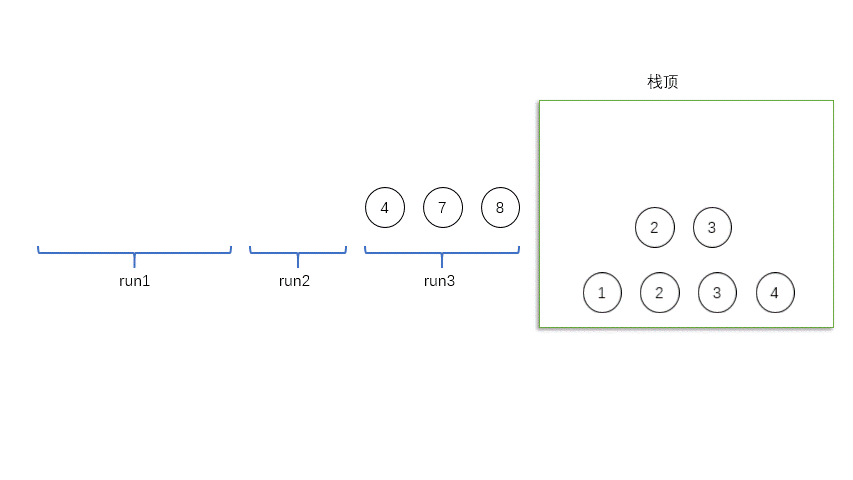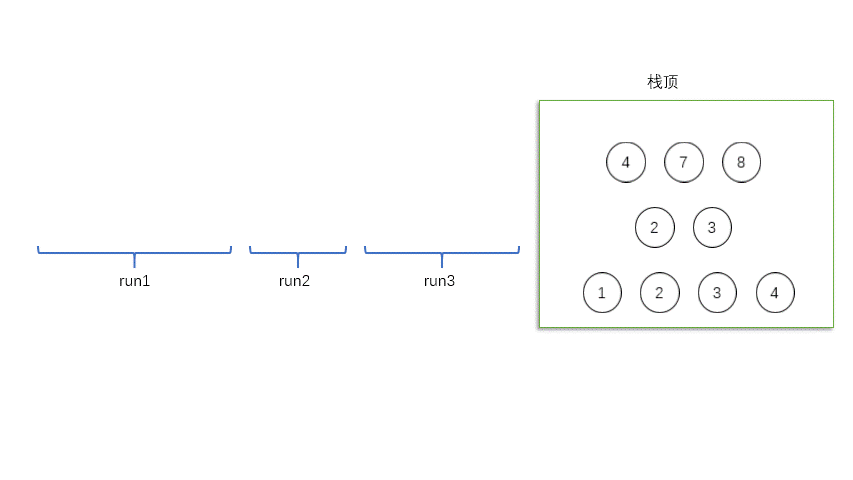
首先遍历数组,[8 10 15]是一个run,但是长度只有3,所以我们把第四个数6加进来,用二分法插入排序的方法,确定位置插入。得到第一个run:[6 8 10 15],记做run_0,入栈。
此时栈里的数据是
然后我们继续找run,[18 12 7 5 4 3],长度大于minrun,但是是单调递减的,所以反转。得到第二个run:[3 4 5 7 12 18],记run_1,入栈。
谁是X,谁是Y?X。
Y < X Y < X
Y < X
所以,我们用合并,把run_0和run_1合并新的run_0,[3 4 5 6 7 8 10 12 15 18]。
继续找run,[20 8],长度不够,再加一个,11,长度还是不够,再加一个,22。得到新的run,[8 11 20 22],记做run_2,入栈。
Y > X Y > X
Y > X
没问题,存下来。
继续找run,[9 9 17]只有三个值啊。怎么办呢?只能入栈,记作run_3。
谁是X?栈顶的是X。从上往下依次是X,Y,Z。
然后我们把最上面的两个合并,得到新的run_2,[8 9 9 11 17 20 22]。
再合并。
1 [3 4 5 6 7 8 8 9 9 10 11 12 15 17 18 20 22]
排序完成。
TimSort的特点
时间复杂度
最坏时间复杂:O ( n log n ) O(n \log n) O ( n log n ) O ( n ) O(n) O ( n )
是否原地排序
否O ( n log n ) O(n \log n) O ( n log n )
是否稳定
稳定。
编程语言内置的排序算法
讨论到现在了,我们还有一个问题没回答。
都不是…
答案揭晓:
在Java中:
当元素个数小于32的时候,是二分插入排序。
当元素个数大于等于32的时候,是TimSort。
在Python中:
当元素个数小于64的时候,是二分插入排序。
当元素个数大于等于64的时候,是TimSort。