这一章我们讨论IO流。
简单来说,比如,如果数据从硬盘到内存,那么就是文件 读取。如果数据从内存到硬盘,那么就是文件 写入。
File类
File类,顾名思义,文件类。
File类的常见方法有:
构造方法
创建方法
判断方法
获取方法
删除方法
我们依次讨论。
构造方法
方法名
说明
File(String pathname)
根据给定的路径字符串,实例化File对象
File(String parent, String child)
根据给定的父路径字符串和子路径字符串,实例化File对象
File(File parent, String child)
根据给定的父路径的File对象和子路径字符串,实例化新的File对象
创建方法
方法名
说明
public boolean createNewFile()
当该路径的文件不存在时,创建一个该路径的新的空文件
public boolean mkdir()
创建由该路径的目录
public boolean mkdirs()
创建由该路径的目录,包括任何必需但不存在的父目录
我们来试一下。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.kakawanyifan;import java.io.File;import java.io.IOException;public class FileDemo public static void main (String[] args) throws IOException File f = new File("testdir\\testfile.test" ); System.out.println(f.getAbsolutePath()); System.out.println(f.createNewFile()); } }
运行结果:
1 2 3 4 5 D:\java-server-for-blog\testdir\testfile.test Exception in thread "main" java.io.IOException: 系统找不到指定的路径。 at java.io.WinNTFileSystem.createFileExclusively(Native Method) at java.io.File.createNewFile(File.java:1021) at com.kakawanyifan.FileDemo.main(FileDemo.java:11)
居然报错了,这是因为D:\java-server-for-blog\testdir这个目录还不存在。
改一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan;import java.io.File;import java.io.IOException;public class FileDemo public static void main (String[] args) throws IOException File f = new File("testdir" ); System.out.println(f.mkdir()); f = new File("testdir\\testfile.test" ); System.out.println(f.getAbsolutePath()); System.out.println(f.createNewFile()); } }
运行结果:
1 2 3 true D:\java-server-for-blog\testdir\testfile.test true
f.getAbsolutePath()方法我们很快就会讨论。
判断方法
方法名
说明
public boolean isDirectory()
测试该路径的File是否为目录
public boolean isFile()
测试该路径的File是否为文件
public boolean exists()
测试该路径的File是否存在
获取方法
方法名
说明
public String getAbsolutePath()
获取绝对路径字符串
public String getPath()
获取相对路径字符串
public String getName()
获取该路径的文件或目录的名称
public String[] list()
获取该路径的目录中文件和目录的路径字符串数组
public File[] listFiles()
获取该路径的目录中文件和目录的File对象数组
特别的,我们可以通过如下的方法获取项目的根目录。
1 System.getProperty("user.dir")
删除方法
方法名
说明
public boolean delete()
删除由该路径名表示的文件或目录
我们来试一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.kakawanyifan;import java.io.File;import java.io.IOException;public class FileDemo public static void main (String[] args) throws IOException File f = new File("testdir" ); System.out.println(f.mkdir()); f = new File("testdir\\testfile.test" ); System.out.println(f.createNewFile()); f = new File("testdir" ); System.out.println(f.delete()); } }
运行结果:
居然删除失败了?
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;import java.io.File;import java.io.IOException;public class FileDemo public static void main (String[] args) throws IOException File f = new File("testdir" ); System.out.println(f.mkdir()); f = new File("testdir\\testfile.test" ); System.out.println(f.createNewFile()); f.delete(); f = new File("testdir" ); System.out.println(f.delete()); } }
运行结果:
这样就OK了。
那么,现在问题来了。
套娃?
那么怎么解决呢?
递归遍历目录
其实解决方法我们已经讨论过,在《算法入门经典(Java与Python描述):4.递归》 这一章。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.kakawanyifan;import java.io.File;public class FileDemo public static void main (String[] args) File srcFile = new File("C:\\Windows" ); getAllFilePath(srcFile); } public static void getAllFilePath (File srcFile) File[] fileArray = srcFile.listFiles(); if (fileArray != null ) { for (File file : fileArray) { if (file.isDirectory()) { getAllFilePath(file); } else { System.out.println(file.getAbsolutePath()); } } } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 C:\Windows\addins\FXSEXT.ecf C:\Windows\appcompat\appraiser\Appraiser_AlternateData.cab C:\Windows\appcompat\appraiser\APPRAISER_TelemetryBaseline_21H1.bin C:\Windows\appcompat\appraiser\APPRAISER_TelemetryBaseline_21H2.bin C:\Windows\appcompat\appraiser\APPRAISER_TelemetryBaseline_UNV.bin 【部分运行结果略】 C:\Windows\zh-CN\notepad.exe.mui C:\Windows\zh-CN\regedit.exe.mui C:\Windows\zh-CN\twain_32.dll.mui C:\Windows\zh-CN\winhlp32.exe.mui C:\Windows\zh-cn.log
获取给定的File目录下所有的文件或者目录的File数组1 File[] fileArray = srcFile.listFiles();
题外话,如果是Python怎么做?
1 2 3 4 5 6 7 import ospath = '/Users/kaka/Documents/' for dirpath, dirs, files in os.walk(path): for file in files: print(file)
字节流
经过上文的讨论,我们已经知道了怎么创建文件,可是有一个问题,创建文件都是空的。
按照数据的流向,IO流可以分为
那么,现在提一个问题。
按照数据的类型,IO流可以分为
我们先讨论字节流。
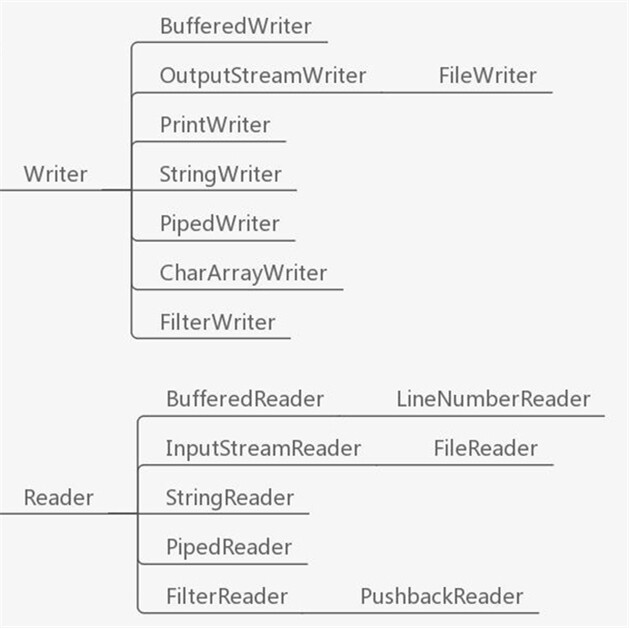
所有字节流的类都继承自两个抽象类。
每一个子类还都有特点,以其父类名作为子类名的后缀。
字节输出流
那么,怎么利用字节输出流读取数据呢?
首先,我们要有一个字节输出流对象。构造方法 。
然后,我们要往这个字节输出流对象里塞数据。写入方法 。
最后,我们要关闭这个字节输出流,释放资源。关闭方法 。
构造方法
构造方法一共有四种,但其实本质上只有两种,更准确说的话,只有一种。
四种是:
FileOutputStream(String name)FileOutputStream(String name, boolean append)FileOutputStream(File file)FileOutputStream(File file, boolean append)
那为什么有本质上是两种,更准确是一种呢?
我们来分析源代码
1 2 3 public FileOutputStream (String name) throws FileNotFoundException this (name != null ? new File(name) : null , false ); }
1 2 3 4 public FileOutputStream (String name, boolean append) throws FileNotFoundException this (name != null ? new File(name) : null , append); }
1 2 3 public FileOutputStream (File file) throws FileNotFoundException this (file, false ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public FileOutputStream (File file, boolean append) throws FileNotFoundException String name = (file != null ? file.getPath() : null ); SecurityManager security = System.getSecurityManager(); if (security != null ) { security.checkWrite(name); } if (name == null ) { throw new NullPointerException(); } if (file.isInvalid()) { throw new FileNotFoundException("Invalid file path" ); } this .fd = new FileDescriptor(); fd.attach(this ); this .append = append; this .path = name; open(name, append); }
第一种和第二种,在传入String类型的name之后,再通过new File(name)进行实例化。
所以说,FileOutputStream的构造方法有四种,但本质上只有两种,更准确只有一种。
写入方法
写入方法一共有三种,但其实本质上只有两种,更准确说的话,也是两种。
三种是:
void write(int b)void write(byte[] b)void write(byte[] b, int off, int len)
那为什么有本质上是两种,更准确也是两种呢?
我们来看源码。
1 2 3 public void write (int b) throws IOException write(b, append); }
1 2 3 public void write (byte b[]) throws IOException writeBytes(b, 0 , b.length, append); }
1 2 3 public void write (byte b[], int off, int len) throws IOException writeBytes(b, off, len, append); }
其中两个调用了write方法,两个调用了writeBytes方法。
1 private native void write (int b, boolean append) throws IOException
1 private native void writeBytes (byte b[], int off, int len, boolean append) throws IOException
注意看,native,简单的说,这是java调用非java代码的接口。
关闭方法
关闭方法:void close()
例子
最后,我们来看个例子。
示例代码:
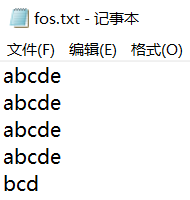
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.kakawanyifan;import java.io.FileOutputStream;import java.io.IOException;public class FileOutputStreamDemo public static void main (String[] args) throws IOException FileOutputStream fos = new FileOutputStream("fos.txt" ); fos.write(97 ); fos.write(98 ); fos.write(99 ); fos.write(100 ); fos.write(101 ); fos.write("\r\n" .getBytes()); byte [] bys = {97 , 98 , 99 , 100 , 101 }; fos.write(bys); fos.write("\r\n" .getBytes()); bys = "abcde" .getBytes(); fos.write(bys); fos.write("\r\n" .getBytes()); fos.write(bys,0 ,bys.length); fos.write("\r\n" .getBytes()); fos.write(bys,1 ,3 ); fos.close(); } }
运行结果:
我们打开文件看一下。
解释一下。《1.基础语法》 ,讨论过ASCII码。
a:97,a-z是连续的,所以b对应的数值是98,c是99,依次递加。A:65,A-Z是连续的,所以B对应的数值是66,C是67,依次递加。0:48,0-9是连续的,所以1对应的数值是49,2是50,依次递加。
上文代码的\r\n是什么含义?\r是回车。\n是换行。
在Windows系统里,文件每行结尾是"<回车><换行>“,所以是\r\n\r\n
记不住怎么办?
1 2 3 4 5 6 String lineSeparator = System.lineSeparator() String filePathSplit = File.separator; System.out.println(filePathSplit);
题外话,换行符和路径分隔符,建议用这种方式,而不是自己写\或者/,尤其是当项目组中有同事用Mac,又有同事用Windows的时候。
异常处理
接下来我们来做一件事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan;import java.io.FileOutputStream;import java.io.IOException;public class FileOutputStreamDemo public static void main (String[] args) FileOutputStream fos = null ; try { fos = new FileOutputStream("fos.txt" ); fos.write(null ); System.out.println("准备关闭" ); fos.close(); System.out.println("已经关闭" ); } catch (IOException e) { e.printStackTrace(); } } }
运行结果:
1 2 3 Exception in thread "main" java.lang.NullPointerException at java.io.FileOutputStream.write(FileOutputStream.java:313) at com.kakawanyifan.FileOutputStreamDemo.main(FileOutputStreamDemo.java:11)
我们传入null,然后触发了空指针异常。这个没有任何问题。
这里介绍一个关键字,finally。
1 2 3 4 5 6 7 try { 可能出现异常的代码; }catch (异常类名 变量名){ 异常的处理代码; }finally { 执行所有清除操作; }
字节输入流
通过上文的讨论,我们知道了怎么利用字节输出流往硬盘里写数据。现在,我们讨论怎么从硬盘里读数据。
"程序"都是一样的。
首先,我们要有一个字节输入 流对象。构造方法 。
然后,我们要往这个字节输入 流对象里塞数据。读取方法 。
最后,我们要关闭这个字节输入 流,释放资源。关闭方法 。
构造方法
构造方法有两种,本质上只有一种。
FileInputStream(String name)
FileInputStream(File file)
具体源代码我们就不再分析了。
读取方法
读取方法有三种,本质上有两种,更准确的说也是两种。
read()
read(byte b[])
read(byte b[], int off, int len)
例子
接下来我们就来举几个例子。
一次读一个字节
一次读一个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.kakawanyifan;import java.io.FileInputStream;import java.io.IOException;public class FileInputStreamDemo public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("哈利波特1-7英文原版.txt" ); int by; while ((by=fis.read())!=-1 ) { System.out.print((char )by); } fis.close(); } }
运行结果:
1 2 3 4 5 6 7 8 1.Harry Potter and the Sorcerer's Stone.txt Harry Potter and the Sorcerer's Stone CHAPTER ONE THE BOY WHO LIVED Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you'd expect to be involved in anything strange or mysterious, because they just didn't hold with such nonsense. 【部分运行结果略】
解释:
1 2 3 4 5 6 7 8 9 10 11 public int read () throws IOException return read0(); }
一次读一个字节数组
一次读一个字节数组
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;import java.io.FileInputStream;import java.io.IOException;public class FileInputStreamDemo public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("哈利波特1-7英文原版.txt" ); byte [] bys = new byte [1024 ]; int len; int i = 0 ; while ((len=fis.read(bys))!=-1 ) { System.out.print(new String(bys,0 ,len)); if (i++ > 100 ){ break ; } } fis.close(); } }
运行结果:
1 2 3 4 5 6 7 8 1.Harry Potter and the Sorcerer's Stone.txt Harry Potter and the Sorcerer's Stone CHAPTER ONE THE BOY WHO LIVED Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you'd expect to be involved in anything strange or mysterious, because they just didn't hold with such nonsense. 【部分运行结果略】
复制
接下来,我们做一件事情,利用字节输入流读取文件,再把读取到的内容利用字节输出流写入到文件中。
复制不用这么麻烦。
1 Files.copy(source, target)
示例代码:
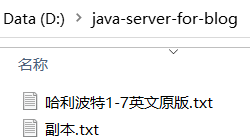
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.kakawanyifan;import java.io.File;import java.io.IOException;import java.nio.file.Files;public class FilesCopyDemo public static void main (String[] args) throws IOException File source = new File("哈利波特1-7英文原版.txt" ); File target = new File("副本.txt" ); Files.copy(source.toPath(), target.toPath()); } }
复制文本文件
但如果在复制的同时,还需要对文件进行修改呢?《基于Java的后端开发入门:99.iPhone设备的一个BUG》 这一章的那个应用场景。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.kakawanyifan;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;public class FilesCopyDemo public static void main (String[] args) throws IOException File source = new File("哈利波特1-7英文原版.txt" ); FileInputStream fileInputStream = new FileInputStream(source); File target = new File("副本.txt" ); FileOutputStream fileOutputStream = new FileOutputStream(target); int by; while ((by = fileInputStream.read()) != -1 ){ fileOutputStream.write(by); } fileInputStream.close(); fileOutputStream.close(); } }
复制图片
如果说复制文本文件的话,是因为可能在复制的同时,对文本文件的内容进行修改。那么复制图片,有什么用呢?
这个还真有用,保不齐有一天,我们需要把图片以二进制的形式存在数据库中,然后又要从数据库中读出来。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.kakawanyifan;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;public class FilesCopyDemo public static void main (String[] args) throws IOException FileInputStream fileInputStream = new FileInputStream("武林外传.png" ); FileOutputStream fileOutputStream = new FileOutputStream("武林外传-副本.png" ); byte [] bys = new byte [1024 ]; int len; while ((len=fileInputStream.read(bys))!=-1 ) { fileOutputStream.write(bys,0 ,len); } fileInputStream.close(); fileOutputStream.close(); } }
字节缓冲流
但是呢,上述的字节输入流和字节输出流都有一个缺点,当读写数据量大的文件时,读写的速度会很慢。针对这个,Java中提供了一套缓冲流,它的存在,可提高IO流的读写速度。
字节缓冲输出流 BufferedOutputStream
字节缓冲输入流 BufferedInputStream
构造方法:
方法名
说明
BufferedOutputStream(OutputStream out)
创建字节缓冲输出流对象
BufferedInputStream(InputStream in)
创建字节缓冲输入流对象
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import java.io.*;public class BufferStreamDemo public static void main (String[] args) throws IOException BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt" )); bos.write("May it be an evening star\r\n" .getBytes()); bos.write("Shines down upon you\r\n" .getBytes()); bos.close(); BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bos.txt" )); bos = new BufferedOutputStream(new FileOutputStream("bos2nd.txt" )); byte [] bys = new byte [1024 ]; int len; while ((len=bis.read(bys))!=-1 ) { System.out.print(new String(bys,0 ,len)); bos.write(bys,0 ,len); } bis.close(); } }
运行结果:
1 2 May it be an evening star Shines down upon you
乱码
现象
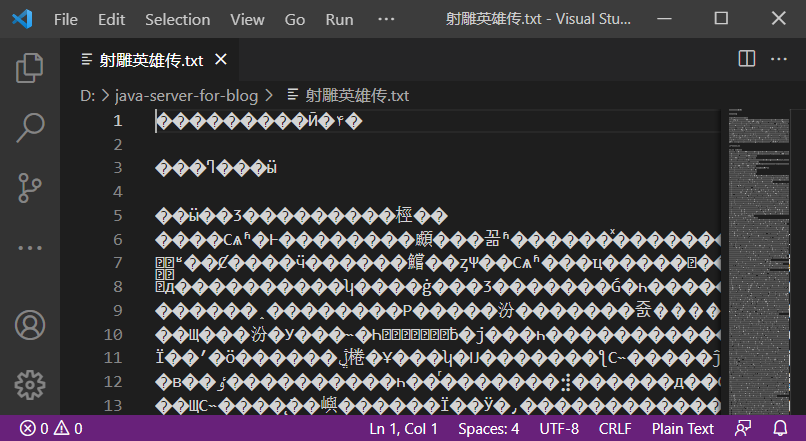
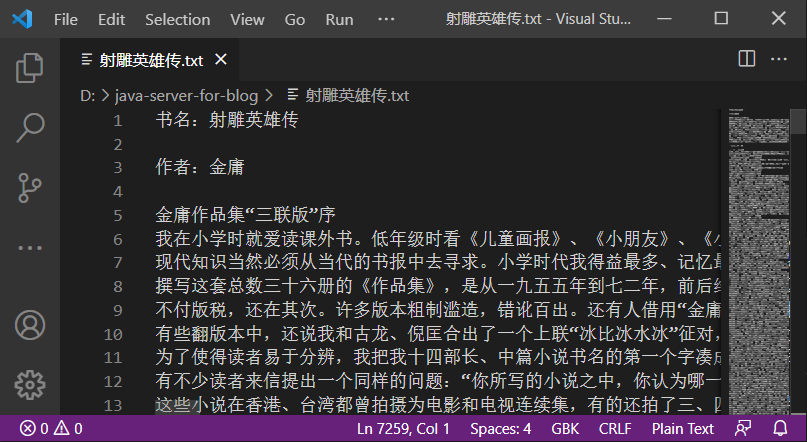
接下来,让我们来读《射雕英雄传》
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.kakawanyifan;import java.io.FileInputStream;import java.io.IOException;public class FileInputStreamDemo public static void main (String[] args) throws IOException FileInputStream fis = new FileInputStream("射雕英雄传.txt" ); byte [] bys = new byte [1024 ]; int len; while ((len=fis.read(bys))!=-1 ) { System.out.print(new String(bys,0 ,len)); } fis.close(); } }
运行结果:
1 2 3 4 5 6 7 8 ���������Ӣ�۴� ���ߣ���ӹ ��ӹ��Ʒ���������桱�� ����Сѧʱ�Ͱ��������顣���꼶ʱ������ͯ����������С���ѡ�����Сѧ���������������ݷḻ�ġ�С�����Ŀ⡱�����ƶ��Ƕ����Ķ����ָ����»�С˵���������꼶ʱ���Ϳ�ʼ����������Ʒ�ˡ������ڣ��һ���ϲ���ŵ���ѧ��Ʒ���ڽ�����������ѧ�����Ǹ���ʹȻ���кܶ����ѣ���ֻϲ������ѧ�������ŵ���ѧ�� 【部分运行结果略】
居然乱码了?
我们用VS CODE打开这个文件。
确实乱码了。
接下来,我们点击右下角的UTF-8,在弹出框选择Reopen with Encoding,再输入GBK。
现在没有乱码了。
字符集编码
为什么会这样呢?
什么是字符集?
常见的字符集
ASCII:基本的ASCII字符集,使用7位表示一个字符,共128字符。ASCII的扩展字符集使用8位表示一个字符,共256字符,方便支持欧洲常用字符。主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)注意,我们说ASCII的扩展字符集使用8位表示一个字符,8位,在《1.基础语法》 ,我们讨论过。1字节 = 8位。
GBK:最常用的中文码表,一个汉字占两个字节。完全兼容GB2312标准。除了简体汉字,还支持繁体汉字以及日韩汉字等
UTF-8:可以用来表示Unicode标准中任意字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。使用一至四个字节为每个字符编码:128个US-ASCII字符,只需一个字节编码;拉丁文等字符,需要二个字节编码;大部分常用字(含中文),使用三个字节编码;其他极少使用的Unicode辅助字符,使用四字节编码。
关于字符集编码的更多内容,可以参考本文的附录部分。
字符串中的编码解码问题
在了解了什么是字节之后,接下来我们要做的是,读取到了字节,再用指定的编码格式解码。
字符串中的编码解码的相关方法有
方法名
说明
byte[] getBytes()
使用平台的默认字符集将该 String编码为一系列字节
byte[] getBytes(String charsetName)
使用指定的字符集将该 String编码为一系列字节
String(byte[] bytes)
使用平台的默认字符集解码指定的字节数组来创建字符串
String(byte[] bytes, String charsetName)
通过指定的字符集解码指定的字节数组来创建字符串
我们把
1 System.out.print(new String(bys,0,len));
修改为
1 System.out.print(new String(bys,0,len, "GBK"));
即可。
那么如果写文件呢?
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.kakawanyifan;import java.io.UnsupportedEncodingException;import java.util.Arrays;public class CharsetDemo public static void main (String[] args) throws UnsupportedEncodingException String s = "中国" ; byte [] bys = s.getBytes(); System.out.println(Arrays.toString(bys)); bys = s.getBytes("UTF-8" ); System.out.println(Arrays.toString(bys)); bys = s.getBytes("GBK" ); System.out.println(Arrays.toString(bys)); } }
运行结果:
1 2 3 [-28, -72, -83, -27, -101, -67] [-28, -72, -83, -27, -101, -67] [-42, -48, -71, -6]
上述运行结果也印证了汉字在UTF-8是三个字节,在GBK是两个字节。
字符流
接下来,我们讨论字符流。
所有字符流的类都继承自两个抽象类。
每一个子类还都有特点,以其父类名作为子类名的后缀。
"程序"都是一样的,字节流也是这样的。
而且,字符流,就像其名字一样,为字符而生。
构造方法
根据是输入还是输出,是读文件,还是文件。字符流可以分为两类
OutputStreamWriter:输出字符流、写文件。
InputStreamReader:输入字符流,读文件。
其构造方法如下
方法名
说明
OutputStreamWriter(OutputStream out)
使用默认字符编码创建OutputStreamWriter对象。
OutputStreamWriter(OutputStream out,String charset)
使用指定的字符编码创建OutputStreamWriter对象。
InputStreamReader(InputStream in)
使用默认字符编码创建InputStreamReader对象。
InputStreamReader(InputStream in,String chatset)
使用指定的字符编码创建InputStreamReader对象。
我们来看示例代码
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("osw.txt" )); OutputStreamWriter osw_gbk = new OutputStreamWriter(new FileOutputStream("osw_gbk.txt" ),"GBK" ); osw.write("中国" ); osw_gbk.write("中国" ); osw.close(); osw_gbk.close(); int ch; InputStreamReader isr = new InputStreamReader(new FileInputStream("osw.txt" )); InputStreamReader isr_gbk = new InputStreamReader(new FileInputStream("osw.txt" ),"GBK" ); System.out.println("默认字符集文件,默认读取。" ); while ((ch=isr.read())!=-1 ) { System.out.print((char )ch); } isr.close(); System.out.println(); System.out.println("默认字符集文件,GBK读取。" ); while ((ch=isr_gbk.read())!=-1 ) { System.out.print((char )ch); } isr_gbk.close(); isr = new InputStreamReader(new FileInputStream("osw_gbk.txt" )); isr_gbk = new InputStreamReader(new FileInputStream("osw_gbk.txt" ),"GBK" ); System.out.println(); System.out.println("GBK字符集文件,默认读取。" ); while ((ch=isr.read())!=-1 ) { System.out.print((char )ch); } isr.close(); System.out.println(); System.out.println("GBK字符集文件,GBK读取。" ); while ((ch=isr_gbk.read())!=-1 ) { System.out.print((char )ch); } isr_gbk.close(); } }
运行结果:
1 2 3 4 5 6 7 8 默认字符集文件,默认读取。 中国 默认字符集文件,GBK读取。 涓浗 GBK字符集文件,默认读取。 �й� GBK字符集文件,GBK读取。 中国
往流里写数据
在刚刚的例子中,我们已经见到了怎么往字符流里写是数据。我们直接write了一个字符串进去。
方法名
说明
void write(int c)
写一个字符。
void write(char[] cbuf)
写入一个字符数组。
void write(char[] cbuf, int off, int len)
写入字符数组的一部分。
void write(String str)
写一个字符串。
void write(String str, int off, int len)
写一个字符串的一部分。
来看个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("osw.txt" )); System.out.println(osw.getEncoding()); osw.write(97 ); osw.write(98 ); osw.write(99 ); osw.close(); InputStreamReader isr = new InputStreamReader(new FileInputStream("osw.txt" )); System.out.println(isr.getEncoding()); int ch; while ((ch=isr.read())!=-1 ) { System.out.print((char )ch); } isr.close(); } }
运行结果:
我们用的是默认的字符集,然后字节写97、98、99。再用默认的字符集读出来,结果就是abc。
刷新和关闭的方法
方法名
说明
flush()
刷新流,之后还可以继续写数据。
close()
关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据。
从流里读取数据
从流里读取数据,我们也已经见过了。我们直接read(),无参。
方法名
说明
int read()
一次读一个字符数据
int read(char[] cbuf)
一次读一个字符数组数据
我们来看看第二种方法的例子。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException InputStreamReader isr = new InputStreamReader(new FileInputStream("射雕英雄传.txt" ),"gbk" ); int temp = 0 ; char [] chs = new char [1024 ]; int len; while ((len = isr.read(chs)) != -1 ) { System.out.print(new String(chs, 0 , len)); temp ++; if (temp > 100 ){ break ; } } isr.close(); } }
运行结果:
1 2 3 4 5 6 7 8 书名:射雕英雄传 作者:金庸 金庸作品集“三联版”序 我在小学时就爱读课外书。低年级时看《儿童画报》、《小朋友》、《小学生》,后来看内容丰富的“小朋友文库”,再似懂非懂地阅读各种各样章回小说。到五六年级时,就开始看新文艺作品了。到现在,我还是喜爱古典文学作品多于近代或当代的新文学。那是个性使然。有很多朋友,就只喜欢新文学,不爱古典文学。 【部分运行结果略】
复制
接下来,我们来复制。但为了发挥字符流的特点,我们做点不一样的复制。
以UTF-8字符集写文件
以UTF-8字符集读文件
把读到的文件以GBK字符集写文件
把文件以GBK字符集读出来
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException String text = "生命中一定有一个或几个瞬间拥有穿透时间的魔力,正如穿上22号球衣的刹那,他仍是那个22岁的志满青年。时间不过是在卡卡的脸上刻下了皱纹,但他终究不忍让他清澈的眼神受到侵染,更不忍破坏他纯洁的少年之心。17年职业生涯后时间最善良的举动就是让那个来到过,离开过,荣耀过,失落过,被岁月风霜过,被生活刁难过的曾经少年,初心不变,善良如一。告别的时刻终会到来,现在看来卡卡在奥兰多城的最后一场比赛,他已经为告别做好了一切准备,那一天他久久目视着前方,不忍转身,仿佛一回头就再也看不到来时的路上,那个鲜衣怒马的少年正跨着横空出世的步伐飞驰而行。他那么俊美,笑容仿佛有融化一切的力量。家乡圣保罗是他的起点,遥远的圣西罗却是梦想成真的圣殿,那是仗剑豪情的卡卡,不可阻挡的卡卡,青春正以最写实的风格讲绿茵场描绘成浓墨重彩,注定在绚丽年华时登上世界的巅峰。皇马生涯不过是一场修行,如果他是被上天选中的孩子,那么他一定是被上天考验的孩子,最好的卡卡从不忘仰望天空,感谢上天的恩宠,孤独的卡卡依然满怀感激,苦难也是上天的恩宠。没有得到时的张狂,没有失去时的颓然,坦然接受生命的一切赠予,这就是卡卡用十七年的时间所书写下的岁月童话,他也和童话一样美好,也和童话一样在受难后重新归来。他依然俊美,依然清新,依然满怀感激,依然虔诚如初,他依然安静内敛,也依然严苛的控制着自己的情绪起伏,他只是不舍得让记忆停顿下来,才终于追不上这唯一一滴偷跑的泪水。这已经是他对青春所有的眷恋和告白。" ; OutputStreamWriter osr = new OutputStreamWriter(new FileOutputStream("kaka.txt" )); osr.write(text); osr.close(); char [] chs = new char [1024 ]; int len; InputStreamReader isr = new InputStreamReader(new FileInputStream("kaka.txt" )); StringBuilder resultStringBuilder = new StringBuilder(); while ((len = isr.read(chs)) != -1 ) { resultStringBuilder.append(new String(chs, 0 , len)); } isr.close(); String result = resultStringBuilder.toString(); osr = new OutputStreamWriter(new FileOutputStream("kaka_gbk.txt" ),"gbk" ); osr.write(result); osr.close(); isr = new InputStreamReader(new FileInputStream("kaka_gbk.txt" ),"gbk" ); StringBuilder resultStringBuilder_GBK = new StringBuilder(); chs = new char [1024 ]; while ((len = isr.read(chs)) != -1 ) { resultStringBuilder_GBK.append(new String(chs, 0 , len)); } isr.close(); System.out.println(resultStringBuilder_GBK.toString()); } }
运行结果:
1 生命中一定有一个或几个瞬间拥有穿透时间的魔力,正如穿上22号球衣的刹那,他仍是那个22岁的志满青年。时间不过是在卡卡的脸上刻下了皱纹,但他终究不忍让他清澈的眼神受到侵染,更不忍破坏他纯洁的少年之心。17年职业生涯后时间最善良的举动就是让那个来到过,离开过,荣耀过,失落过,被岁月风霜过,被生活刁难过的曾经少年,初心不变,善良如一。告别的时刻终会到来,现在看来卡卡在奥兰多城的最后一场比赛,他已经为告别做好了一切准备,那一天他久久目视着前方,不忍转身,仿佛一回头就再也看不到来时的路上,那个鲜衣怒马的少年正跨着横空出世的步伐飞驰而行。他那么俊美,笑容仿佛有融化一切的力量。家乡圣保罗是他的起点,遥远的圣西罗却是梦想成真的圣殿,那是仗剑豪情的卡卡,不可阻挡的卡卡,青春正以最写实的风格讲绿茵场描绘成浓墨重彩,注定在绚丽年华时登上世界的巅峰。皇马生涯不过是一场修行,如果他是被上天选中的孩子,那么他一定是被上天考验的孩子,最好的卡卡从不忘仰望天空,感谢上天的恩宠,孤独的卡卡依然满怀感激,苦难也是上天的恩宠。没有得到时的张狂,没有失去时的颓然,坦然接受生命的一切赠予,这就是卡卡用十七年的时间所书写下的岁月童话,他也和童话一样美好,也和童话一样在受难后重新归来。他依然俊美,依然清新,依然满怀感激,依然虔诚如初,他依然安静内敛,也依然严苛的控制着自己的情绪起伏,他只是不舍得让记忆停顿下来,才终于追不上这唯一一滴偷跑的泪水。这已经是他对青春所有的眷恋和告白。
FileWriter和FileReader
回到上文的图。
OutputStreamWriter和InputStreamReader还有各自的子类FileWriter和FileReader。
这两个使用起来会更方便,但是呢,无法自定义字符集。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package java.io;public class FileWriter extends OutputStreamWriter public FileWriter (String fileName) throws IOException super (new FileOutputStream(fileName)); } public FileWriter (String fileName, boolean append) throws IOException super (new FileOutputStream(fileName, append)); } public FileWriter (File file) throws IOException super (new FileOutputStream(file)); } public FileWriter (File file, boolean append) throws IOException super (new FileOutputStream(file, append)); } public FileWriter (FileDescriptor fd) super (new FileOutputStream(fd)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package java.io;import java.nio.charset.Charset;import java.nio.charset.CharsetEncoder;import sun.nio.cs.StreamEncoder;public class OutputStreamWriter extends Writer private final StreamEncoder se; public OutputStreamWriter (OutputStream out, String charsetName) throws UnsupportedEncodingException { super (out); if (charsetName == null ) throw new NullPointerException("charsetName" ); se = StreamEncoder.forOutputStreamWriter(out, this , charsetName); } public OutputStreamWriter (OutputStream out) super (out); try { se = StreamEncoder.forOutputStreamWriter(out, this , (String)null ); } catch (UnsupportedEncodingException e) { throw new Error(e); } } public OutputStreamWriter (OutputStream out, Charset cs) super (out); if (cs == null ) throw new NullPointerException("charset" ); se = StreamEncoder.forOutputStreamWriter(out, this , cs); } public OutputStreamWriter (OutputStream out, CharsetEncoder enc) super (out); if (enc == null ) throw new NullPointerException("charset encoder" ); se = StreamEncoder.forOutputStreamWriter(out, this , enc); } 【部分代码略】 }
那么,如果一定要自定义字符集呢?利用多态。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException FileWriter fw = (FileWriter) new OutputStreamWriter(new FileOutputStream("亨利.txt" ),"gbk" ); fw.write("32岁的亨利就坐在那里,深情的目光望过去,都是自己22岁的影子。" ); fw.close(); } }
运行结果:
1 2 Exception in thread "main" java.lang.ClassCastException: java.io.OutputStreamWriter cannot be cast to java.io.FileWriter at com.kakawanyifan.ReaderWriterDemo.main(ReaderWriterDemo.java:7)
失败了?为什么?在《2.面向对象》 那一章,我们专门讨论过向下转型的注意事项。
向下转型只能转型为本类对象(猫是不能变成狗的)。
向下转型的前提是父类对象指向的是子类对象(也就是说,在向下转型之前,它得先向上转型)。
在这里,不符合第二点。
字符缓冲流
同字节流一样,字符流也有字符缓冲流。作用也是提高效率。
方法名
说明
BufferedWriter(Writer out)
创建字符缓冲输出流对象
BufferedReader(Reader in)
创建字符缓冲输入流对象
比如,我们把天下足球中亨利的解说词,换成德彪。就像这个视频一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.kakawanyifan;import java.io.*;public class ReaderWriterDemo public static void main (String[] args) throws IOException BufferedReader br = new BufferedReader(new FileReader("亨利.txt" )); BufferedWriter bw = new BufferedWriter(new FileWriter("德彪.txt" )); StringBuilder textStringBuilder = new StringBuilder(); char [] chs = new char [1024 ]; int len; while ((len=br.read(chs))!=-1 ) { textStringBuilder.append(new String(chs,0 ,len)); } String text = textStringBuilder.toString(); text = text.replace("酋长球场" ,"维多利亚娱乐广场" ); text = text.replace("亨利" ,"德彪" ); bw.write(text); br.close(); bw.close(); } }
运行结果:
字符缓冲流特有功能
BufferedWriter:
方法名
说明
void newLine()
写一行行分隔符,行分隔符字符串由系统属性定义
BufferedReader:
方法名
说明
String readLine()
读一行文字。 结果包含行的内容的字符串,不包括任何行终止字符如果流的结尾已经到达,则为null
举个例子,就以我们在《基于Java的后端开发入门:99.iPhone设备的一个BUG》 中的那个渲染需求为例。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 package com.kakawanyifan;import java.io.*;import org.apache.commons.text.StringEscapeUtils;public class ReaderWriterDemo public static void main (String[] args) throws IOException String file = "md.md" ; int three = 0 ; int front = 0 ; int script = 0 ; boolean code = false ; BufferedReader br = new BufferedReader(new FileReader(file)); BufferedWriter bw = new BufferedWriter(new FileWriter(file + ".md" )); String line; while ((line = br.readLine()) != null ) { if (line.startsWith("hide:" )) { bw.write("hide: true" ); bw.newLine(); bw.flush(); continue ; } if (line.startsWith("sitemap:" )) { bw.write("sitemap: false" ); bw.newLine(); bw.flush(); continue ; } if (line.startsWith("url:" )) { bw.write(line + "0" ); bw.newLine(); bw.flush(); continue ; } if (line.startsWith("---" ) && front < 2 ) { front = front + 1 ; if (front == 2 ) { bw.write("---" ); bw.newLine(); String scriptStr = "<script type=\"text/javascript\">\n" + " // 如果不是iPhone\n" + " if(navigator.platform != \"iPhone\"){\n" + " var url = window.location.href;\n" + " var replace = url.substr(-7,6);\n" + " location.replace(replace);\n" + " }\n" + " var dom = document.querySelector(\".post-meta-wordcount\");\n" + " dom.removeAttribute(\"class\");\n" + " dom.setAttribute(\"style\",\"display:none\");\n" + "</script>" ; bw.write(scriptStr); bw.flush(); continue ; } } if (script == 0 && line.startsWith("<script type=\"text/javascript\">" )){ script = script + 1 ; } if (script == 1 && line.startsWith("</script>" )){ script = script + 1 ; continue ; } if (script > 0 && script < 2 ){ continue ; } if (line.startsWith("```" )){ three = three + 1 ; if (three % 2 == 1 ){ code = true ; }else { code = false ; } } String content = "" ; if (code){ if (line.startsWith("```" )){ content = "{% raw %}\n" + "<div style=\"background-color:#F6F6F6;width: 100%;padding:10px;white-space: nowrap;overflow-x: auto;-webkit-overflow-scrolling:touch;\">" ; }else { content = StringEscapeUtils.escapeHtml4(line); content = content.replace(" " ," " ); content = "<span>" + content + "</span><br/>" ; } System.out.println(content); }else { if (line.startsWith("```" )){ content = "</div>\n" + "<br/>\n" + "{% endraw %}" ; System.out.println(content); }else { content = line; } } bw.write(content); bw.newLine(); bw.flush(); } bw.close(); br.close(); } }
org.apache.commons.text.StringEscapeUtils.escapeHtml4会对单引号'和全角的双引号“”等进行转义,但是Python中的html.escape不会对这些符号进行转义。
其他IO流
标准流
标准流有两个,他们都是System类中有两个静态的成员变量。
public static final InputStream in:标准输入流,通常该流对应于键盘输入或由主机环境或用户指定的另一个输入源。
public static final PrintStream out:标准输出流,通常该流对应于显示输出或由主机环境或用户指定的另一个输出目标。
其中System.in或许我们用的不多,但是System.out肯定是已经用过很多遍了。
我们在讨论标准流的同时,对上文的内容再进行复习。
字节流的复习
我们来实现一个最简单的例子,输入什么,输出什么。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan;import java.io.IOException;import java.io.InputStream;public class SystemInDemo public static void main (String[] args) throws IOException InputStream is = System.in; int by; while ((by = is.read()) != -1 ){ System.out.println((char )by); } } }
运行结果:
我们输入1,然后输出1,输入a,然后输出a。这都是ok的。
字符流的复习
解决方法是字符流。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.kakawanyifan;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;public class SystemInDemo public static void main (String[] args) throws IOException InputStream is = System.in; InputStreamReader isr = new InputStreamReader(is); int by; while ((by = isr.read()) != -1 ){ System.out.println((char )by); } } }
运行结果:
字符缓冲流的复习
最后,如果我们想一次读一行呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;public class SystemInDemo public static void main (String[] args) throws IOException while (true ){ BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); String line = br.readLine(); System.out.println(line); } } }
运行结果:
Scanner源码分析
1 Scanner scanner = new Scanner(System.in)
其实,我们上文讨论的字符缓冲流,就是java.util.Scanner的一个构造方法的源码。
1 2 3 public Scanner (InputStream source) this (new InputStreamReader(source), WHITESPACE_PATTERN); }
打印流
打印流分为两种
字节打印流:PrintStream
字符打印流:PrintWriter
其中字节打印流,其实我们用了很多遍了。就是System.out.Xxx的时候。
1 public final static PrintStream out = null;
打印流特点是:
只负责输出数据,不负责读取数据
有自己的特有方法
永远不会抛出IOException
注意,是不会抛出IOException,但是还是会抛出异常。早在第一章《1.基础语法》 ,我们就见过其抛出异常。
1 System.out.println(null );
运行结果:
1 2 java: 对println的引用不明确 java.io.PrintStream 中的方法 println(char[]) 和 java.io.PrintStream 中的方法 println(java.lang.String) 都匹配
字节打印流
PrintStream(String fileName):使用指定的文件名创建新的打印流System.setOut改变输出语句的目的地。
1 2 // 重新分配"标准"输出流 public static void setOut(PrintStream out)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan;import java.io.IOException;import java.io.PrintStream;public class SystemInDemo public static void main (String[] args) throws IOException PrintStream ps = new PrintStream("ps.txt" ); ps.print(97 ); ps.println(); ps.write(97 ); ps.close(); } }
字符打印流
字符打印流构造方法
方法名
说明
PrintWriter(String fileName)
使用指定的文件名创建一个新的PrintWriter,而不需要自动执行刷新
PrintWriter(Writer out, boolean autoFlush)
创建一个新的PrintWriter out:字符输出流 autoFlush: 自动刷新。
示例代码:
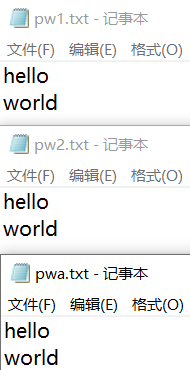
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.kakawanyifan;import java.io.FileNotFoundException;import java.io.FileWriter;import java.io.IOException;import java.io.PrintWriter;public class PrintWriterDemo public static void main (String[] args) throws IOException PrintWriter pw = new PrintWriter("pw1.txt" ); pw.write("hello" ); pw.write("\r\n" ); pw.flush(); pw.write("world" ); pw.flush(); pw = new PrintWriter("pw2.txt" ); pw.println("hello" ); pw.println("world" ); pw.flush(); pw.close(); PrintWriter pwa = new PrintWriter(new FileWriter("pwa.txt" ),true ); pwa.println("hello" ); pwa.write("world" ); pwa.flush(); } }
序列化和反序列化
序列化流和反序列化流
在讨论了怎么写文件,怎么读文件之后。
对象序列化流:ObjectOutputStream。将Java对象的写入OutputStream,可以使用ObjectInputStream读取(重构)对象,可以通过使用流的文件来实现对象的持久存储。如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象。
构造方法
方法名
说明
ObjectOutputStream(OutputStream out)
创建一个写入指定的OutputStream的ObjectOutputStream
序列化对象的方法
方法名
说明
void writeObject(Object obj)
将指定的对象写入ObjectOutputStream
对象反序列化流:ObjectInputStream。ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象。
构造方法
方法名
说明
ObjectInputStream(InputStream in)
创建从指定的InputStream读取的ObjectInputStream
反序列化对象的方法
方法名
说明
Object readObject()
从ObjectInputStream读取一个对象
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import java.io.Serializable;public class Student implements Serializable private String name; private int age; public Student (String name, int age) this .name = name; this .age = age; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import java.io.*;public class ObjectOutputStreamDemo public static void main (String[] args) throws IOException, ClassNotFoundException ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("oos.txt" )); Student s1 = new Student("林青霞" ,30 ); oos.writeObject(s1); oos.close(); ObjectInputStream ois = new ObjectInputStream(new FileInputStream("oos.txt" )); Object obj = ois.readObject(); Student s2 = (Student) obj; System.out.println(s2.getName() + "," + s2.getAge()); ois.close(); } }
运行结果:
注意!一个对象要想被序列化,该对象所属的类必须必须实现Serializable接口。Serializable是一个标记接口,实现该接口,不需要重写任何方法。
serialVersionUID和transient
serialVersionUID
用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据会不会出问题呢?
不知道。
但是具体会出什么问题呢?
先序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;import java.io.*;public class ObjectStreamDemo public static void main (String[] args) throws IOException write(); } private static void write () throws IOException ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("oos.txt" )); Student s = new Student("林青霞" , 30 ); oos.writeObject(s); oos.close(); } }
然后修改Student类,做一个很小的改动,新增一个toString方法。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.kakawanyifan;import java.io.*;public class ObjectStreamDemo public static void main (String[] args) throws IOException, ClassNotFoundException read(); } private static void read () throws IOException, ClassNotFoundException ObjectInputStream ois = new ObjectInputStream(new FileInputStream("oos.txt" )); Object obj = ois.readObject(); Student s = (Student) obj; System.out.println(s.getName() + "," + s.getAge()); ois.close(); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 Exception in thread "main" java.io.InvalidClassException: com.kakawanyifan.Student; local class incompatible: stream classdesc serialVersionUID = -2391437376183522082, local class serialVersionUID = 1167257999999731235 at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699) at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2001) at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1848) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2158) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1665) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:501) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:459) at com.kakawanyifan.ObjectStreamDemo.read(ObjectStreamDemo.java:22) at com.kakawanyifan.ObjectStreamDemo.main(ObjectStreamDemo.java:8)
果真出问题了。
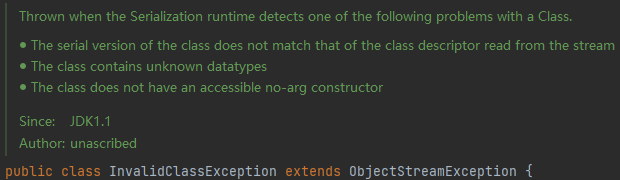
类的串行版本与从流中读取的类的描述符的类型不匹配
该类包含未知的数据类型
该类没有可访问的无参构造函数
那么,怎么办呢?
1 private static final long serialVersionUID = 42L;
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import java.io.Serializable;public class Student implements Serializable private static final long serialVersionUID = 42L ; private String name; private int age; public Student (String name, int age) this .name = name; this .age = age; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } @Override public String toString () return "Student{" + "name='" + name + '\'' + ", age=" + age + '}' ; } }
关于该部分,再JAVA-API的文档中有详细的描述,摘抄如下。
序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的serialVersionUID与对应的发送者的类的版本号不同,则反序列化将会导致InvalidClassException。可序列化类可以通过声明名为"serialVersionUID"的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的serialVersionUID。
transient
如果一个对象中的某个成员变量的值不想被序列化,给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程。
Properties
本章的最后一个话题,Properties。Hashtable<Object,Object>,所以准确来说,Properties是一个Map体系的集合类。
Properties作为Map集合的特有方法
方法名
说明
Object setProperty(String key, String value)
设置集合的键和值,都是String类型,底层调用 Hashtable方法 put
String getProperty(String key)
使用此属性列表中指定的键搜索属性
Set stringPropertyNames()
从该属性列表中返回一个不可修改的键集,其中键及其对应的值是字符串
Properties和IO流相结合的方法
方法名
说明
void load(InputStream inStream)
从输入字节流读取属性列表(键和元素对)
void load(Reader reader)
从输入字符流读取属性列表(键和元素对)
void store(OutputStream out, String comments)
将此属性列表(键和元素对)写入此 Properties表中,以适合于使用 load(InputStream)方法的格式写入输出字节流
void store(Writer writer, String comments)
将此属性列表(键和元素对)写入此 Properties表中,以适合使用 loa(Reader)方法的格式写入输出字符流
例子
举个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;import java.util.Properties;public class PropertiesDemo public static void main (String[] args) throws IOException Store(); Load(); } private static void Load () throws IOException Properties prop = new Properties(); FileReader fr = new FileReader("properties.properties" ); prop.load(fr); fr.close(); System.out.println(prop); System.out.println(prop.getProperty("1" )); } private static void Store () throws IOException Properties prop = new Properties(); prop.setProperty("1" ,"A" ); prop.setProperty("2" ,"B" ); prop.setProperty("3" ,"C" ); FileWriter fw = new FileWriter("properties.properties" ); prop.store(fw,null ); fw.close(); } }
运行结果:
在实际项目开发中,我们很少会使用setProperty方法,因为properties更多用于读取配置文件,而配置文件一般不由程序去修改,程序只读配置文件。如果某个配置,经常需要根据业务进行修改,比如数据库的日切表等,这个配置通常有数据库的某张表记录。
附录:字符集编码
什么是编码
在计算机中所有的数据都是字节的形式进行存储和处理的,但是这些字节本身又是没有任何意义的。
ASCII
一个字节有8位,每位有0和1两种状态,因此一个字节可以有256种状态。
第一种编码方式,ASCII码一共定义了128个字符,包括英文字母A-Z、a-z、数字0-9,一些标点符号和控制符号等,这128个字符只使用了8位中的后面7位,最前面的一位统一规定为0。
英语用128个字符来编码完全是足够的,但是用来表示其他语言,128个字符是远远不够的。
如果将ASCII码中闲置的最高位利用起来,这样一来就能表示256个字符。
在具体实践中,没有做到统一。阿拉伯有阿拉伯的ASCII码,俄罗斯有俄罗斯的ASCII码,同一个二进制,在阿拉伯的ASCII码是گ,在俄罗斯的ASCII码是ђ。
对于一些亚洲语言,需要更多的字符,一个字节已经不够。
GB2312
GB2312规定:
ASCII原本的意义不变,即小于127的字符的意义与原来相同。
用两个大于127的字节,表示一个汉字。0xA1用到0xF70xA1到0xFE
这样的话,就可以表示大约7000多个简体汉字了。
在GB2312中,还把数学符号、罗马字母、希腊字母等都编进去了。
GBK和GB18030
但是GB2312发现不够,中国的汉字太多了。
因此,约定:只要第一个字节是大于127就固定表示这是一个汉字的开始(依旧用两个字节表示一个汉字)。
这就是GBK,GBK包括了GB2312的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后开,再加入了少数民族的文字,这就是GB18030。
这样的话,彻底解决了ASCII不支持亚洲语言的问题。但是,对于第一个问题,还是没解决,编码方式没有统一。
Unicode
Unicode的设想,将全世界所有的字符包含在一个集合里,计算机只要支持这一个字符集。0表示位空,将两个字节的110110001001001(0x6c49)表示为汉字的"汉",其他的甚至有用3个字节、4个字节表示。
这就导致了一些问题,计算机怎么知道你这个2个字节表示的是一个字符,而不是分别表示两个字符呢?
那就取最大的,Unicode可以规定所有的符号用4个字节(这其实就是UTF-32)表示,不够的前面补0。
为了解决Unicode的编码问题, UTF-8诞生了。
UTF-8
UTF-8,实现了对ASCII码的向后兼容,保证Unicode的设计可以被大众接受。
对于单个字节的字符,第一位设为0,后面的7位对应这个字符的Unicode码。因此,对于英文中的0-127号字符,与ASCII码完全相同。
对于需要使用N个字节来表示的字符(N>1)
第一个字节的前N位都设为1,第(N+1)位设为0
剩余的(N-1)个字节的前两位都设位10,剩下的则使用这个字符的Unicode码点来填充。
Unicode十六进制码点范围
UTF-8二进制
0000 0000 - 0000 007F
0…
0000 0080 - 0000 07FF
110… 10…
0000 0800 - 0000 FFFF
1110… 10… 10…
0001 0000 - 0010 FFFF
11110… 10… 10… 10…
例如,对于汉字的"汉",110 1100 0100 1001(0x6c49),0x6c49,位于第三行的范围,那么得出其格式为1110.... 10...... 10......。.,多出的.用0补上。11100110 10110001 10001001,转换成十六进制就是0xE6 0xB7 0x89。
解码的过程:
如果一个字节的第一位是0,则说明这个字节对应一个字符
如果一个字节的第一位1,那么连续有多少个1,就表示该字符占用多少个字节。