这一章我们讨论集合。
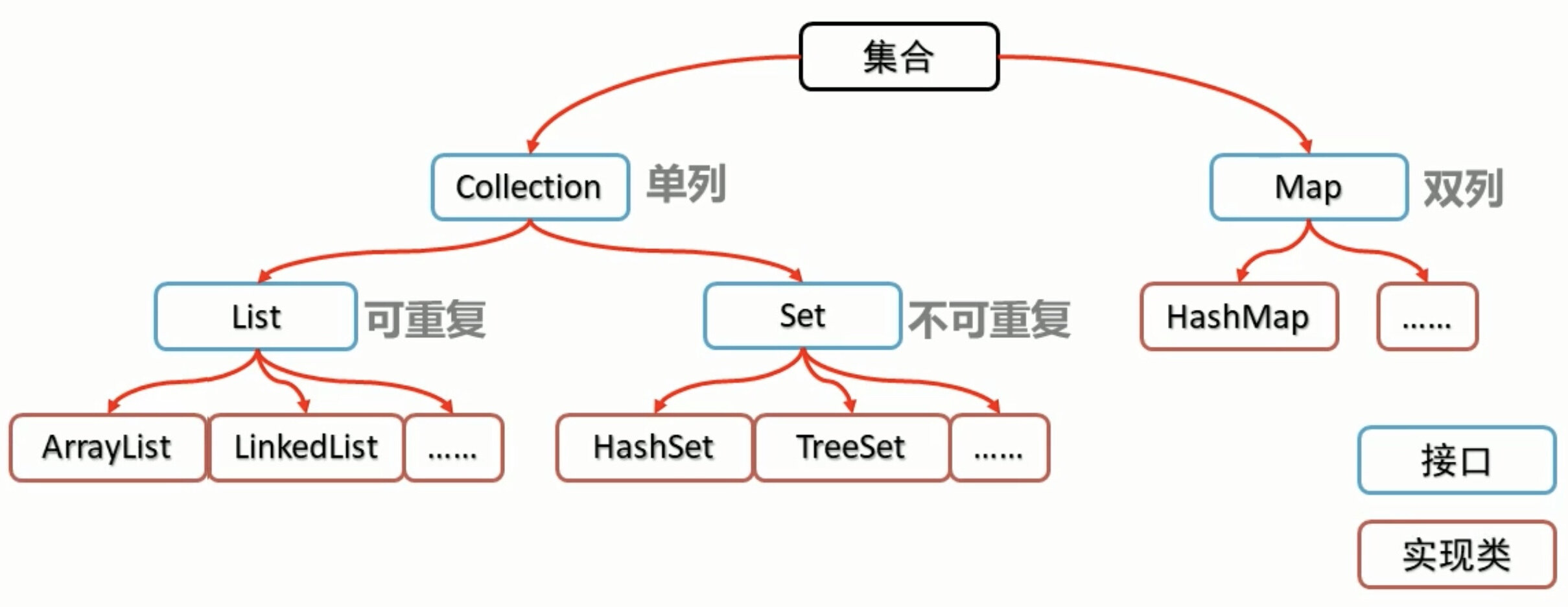
集合
在《3.最常用的Java自带的类》 ,我们讨论了ArrayList,当时我们说:ArrayList是集合的一种,集合是指一种存储空间可变的存储模型,存储的数据容量可以发生改变。
但当时我们只讨论了这些,现在我做更详细的讨论。
首先,是集合的体系结构。
注意,Collection、Map、List和Set都是接口。
我们一个一个讨论。
Collection
概述
Collection是单列集合的顶层接口,JDK不提供此接口的任何直接实现,但为该接口的子接口(Set和List)提供了具体实现。
我们举一个例子,来说明Collection的基本使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.ArrayList;import java.util.Collection;public class M public static void main (String[] args) Collection<String> c = new ArrayList<String>(); c.add("hello" ); c.add("world" ); c.add("java" ); System.out.println(c); } }
运行结果:
这是一种典型的向上转型的多态,从子到父,父类引用指向子类对象。
常用方法
Collection的常用方法有:
方法名
说明
boolean add(E e)
添加元素
boolean remove(Object o)
从集合中移除指定的元素
void clear()
清空集合中的元素
boolean contains(Object o)
判断集合中是否存在指定的元素
boolean isEmpty()
判断集合是否为空
int size()
集合的长度,也就是集合中元素的个数
注意,没有set方法和get方法。没有不是因为不常用,是因为本身就没有。
迭代器遍历
在上一章《3.最常用的Java自带的类》 讨论ArrayList的时候,我们说ArrayList有size方法有set和get方法,那么就可以做遍历了。迭代器
迭代器,集合的专有的遍历方式。
1 Iterator<E> iterator = 集合对象.iterator()
我们来看个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.kakawanyifan;import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;public class IteratorDemo public static void main (String[] args) Collection<String> c = new ArrayList<String>(); c.add("hello" ); c.add("world" ); c.add("java" ); Iterator<String> it = c.iterator(); while (it.hasNext()) { String s = it.next(); System.out.println(s); } } }
运行结果:
迭代器源码
it.next()运行一次就输出下次的结果,就像有指针一直记录着已经next多少记录了一样。
我们来看源码。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private class Itr implements Iterator <E > int cursor; 【部分代码略】 Itr() {} public boolean hasNext () return cursor != size; } @SuppressWarnings ("unchecked" ) public E next () checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1 ; return (E) elementData[lastRet = i]; } 【部分代码略】 }
每调用一次next方法,cursor变量都会加一。
题外话readline。
示例代码:
1 2 3 4 5 6 7 8 with open(fileName, 'r' ) as fr: while True : line = fr.readline() if not line: break
List
Collection接口有两个子接口,List和Set。我们先讨论List。
概述
List是有序集合,用户可以精确控制列表中每个元素的插入位置,可以通过整数索引访问元素。
特有方法
List继承自Collection,除了Collection有的方法,List中还有一些特有的方法。
方法名
描述
void add(int index,E element)
在此集合中的指定位置插入指定的元素。
E remove(int index)
删除指定索引处的元素,返回被删除的元素。
E set(int index,E element)
修改指定索引处的元素,返回被修改的元素。
E get(int index)
返回指定索引处的元素。
并发修改异常
接下来。我们来看一个很有意思的现象。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.kakawanyifan;import java.util.ArrayList;import java.util.Iterator;import java.util.List;public class IteratorDemo public static void main (String[] args) List<String> list = new ArrayList<String>(); list.add("hello" ); list.add("world" ); list.add("java" ); Iterator<String> it = list.iterator(); while (it.hasNext()) { String s = it.next(); System.out.println(s); if (s.equals("world" )) { list.add("javaee" ); } } } }
运行结果:
1 2 3 4 5 6 hello world Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911) at java.util.ArrayList$Itr.next(ArrayList.java:861) at com.kakawanyifan.IteratorDemo.main(IteratorDemo.java:20)
出现异常了。
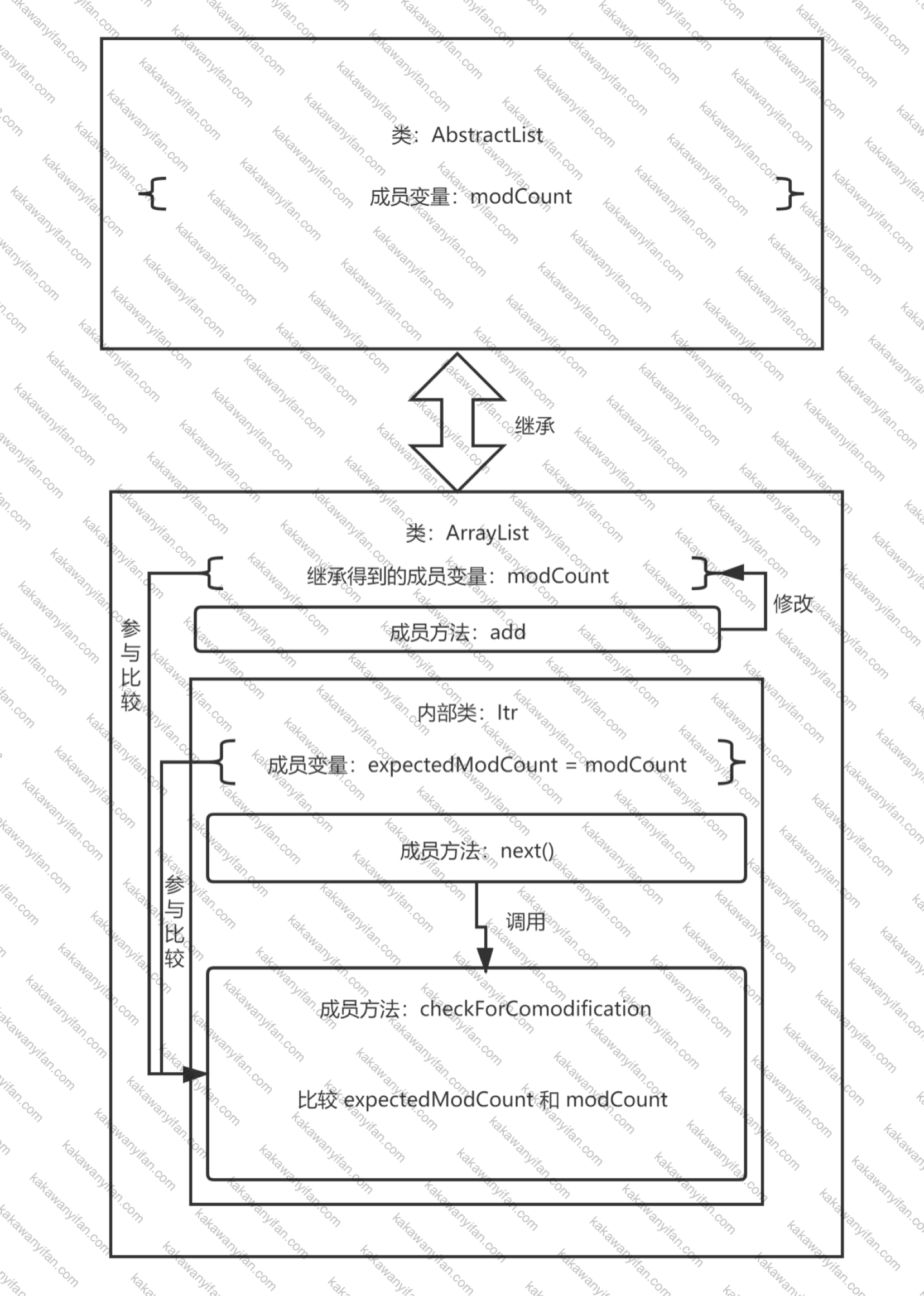
ArrayList源码分析
我们根据at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911),点击ArrayList.java:911,找到这么一段代码。
1 2 3 4 final void checkForComodification () if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
如果modCount和expectedModCount不相等,就抛出异常。
checkForComodification方法属于ArrayList的一个内部类Itr,在这个Itr中,就定义了int expectedModCount = modCount;。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 private class Itr implements Iterator <E > int cursor; int lastRet = -1 ; int expectedModCount = modCount; Itr() {} public boolean hasNext () return cursor != size; } @SuppressWarnings ("unchecked" ) public E next () checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1 ; return (E) elementData[lastRet = i]; } public void remove () 【部分代码略】 } @Override @SuppressWarnings ("unchecked" ) public void forEachRemaining (Consumer<? super E> consumer) 【部分代码略】 } final void checkForComodification () if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
有很多方法都会调用checkForComodification这个方法,但是在这里调用checkForComodification这个方法的就是next方法。next的第一行就是checkForComodification();,这也印证了报错的第二行at java.util.ArrayList$Itr.next(ArrayList.java:861)。expectedModCount属于Itr这个内部类的成员变量,如果代码规范的话,不应该有方法去直接修改内部类的expectedModCount,所以比较有可能是modCount被修改了。或许是add方法的时候,修改了modCount?
右键modCount,Go to,Declaration or Usage,找到modCount的定义,是在AbstractList这个类中被定义的,而且是AbstractList这个类的成员变量。而ArrayList继承了这个类。
来看看add方法。
1 2 3 4 5 public boolean add (E e) ensureCapacityInternal(size + 1 ); elementData[size++] = e; return true ; }
再来看看被add方法调用的ensureCapacityInternal方法。
1 2 3 private void ensureCapacityInternal (int minCapacity) ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); }
再来看看ensureExplicitCapacity方法。
1 2 3 4 5 6 7 private void ensureExplicitCapacity (int minCapacity) modCount++; if (minCapacity - elementData.length > 0 ) grow(minCapacity); }
找到原因了!modCount++;!
小结一下,ArrayList的部分源码结构如图所示。
并发修改方案
那么,怎么解决呢?
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;public class ForDemo public static void main (String[] args) List<String> list = new ArrayList<String>(); list.add("hello" ); list.add("world" ); list.add("java" ); for (int i = 0 ; i < list.size(); i++) { String s = list.get(i); System.out.println(s); if (s.equals("world" )) { list.add("javaee" ); } } System.out.println(list); } }
运行结果:
1 2 3 4 5 hello world java javaee [hello, world, java, javaee]
列表迭代器
在ArrayList中还有一个内部类:ListIterator。该内部类通过listIterator方法实例化。其特点是可以沿着next和previous两个方向进行遍历,并且提供了add和set方法。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;import java.util.ListIterator;public class ListIteratorDemo public static void main (String[] args) List<String> list = new ArrayList<String>(); list.add("hello" ); list.add("world" ); list.add("java" ); ListIterator<String> lit = list.listIterator(); while (lit.hasNext()) { String s = lit.next(); System.out.println(s); if (s.equals("world" )) { lit.add("javaee" ); } } System.out.println("------" ); while (lit.hasPrevious()) { String s = lit.previous(); System.out.println(s); } System.out.println(list); } }
运行结果:
1 2 3 4 5 6 7 8 9 hello world java ------ java javaee world hello [hello, world, javaee, java]
特别注意,这时候并发修改并没有引起异常。我们来看看add方法都做了什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 public void add (E e) checkForComodification(); try { int i = cursor; ArrayList.this .add(i, e); cursor = i + 1 ; lastRet = -1 ; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } }
注意:expectedModCount = modCount
增强for循环
还有一种for循环,这种for循环相比之前的for循环更方便。
1 2 3 for(元素数据类型 变量名 : 数组/集合对象名) { 循环体; }
但是,相比之前的for循环,也有不足。我们来看例子。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;public class ForDemo public static void main (String[] args) List<String> list = new ArrayList<String>(); list.add("hello" ); list.add("world" ); list.add("java" ); for (String s : list) { System.out.println(s); if (s.equals("world" )) { list.add("javaee" ); } } System.out.println(list); } }
运行结果:
1 2 3 4 5 6 hello world Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911) at java.util.ArrayList$Itr.next(ArrayList.java:861) at com.kakawanyifan.ForDemo.main(ForDemo.java:16)
原因是,这种For循环的内部原理是一个Iterator迭代器。所以,同样有并发修改异常。
LinkedList的特有方法
除了ArrayList,还有一种是LinkeList。顾名思义,基于链表实现的。
关于数组和链表,我们在《算法入门经典(Java与Python描述):2.数组、链表》 有非常详细的讨论,这里不赘述。
数组:查询快、增删慢
ArrayList:基于数组实现,查询快、增删慢
LinkedList有一些特有的方法。
方法名
说明
public void addFirst(E e)
在该列表开头插入指定的元素
public void addLast(E e)
将指定的元素追加到此列表的末尾
public E getFirst()
返回此列表中的第一个元素
public E getLast()
返回此列表中的最后一个元素
public E removeFirst()
从此列表中删除并返回第一个元素
public E removeLast()
从此列表中删除并返回最后一个元素
等等!
LinkedList源码分析
因为LinkedList有两个成员变量first和last,在add和remove等操作的时候,都会维护这两个成员变量。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public class LinkedList <E > extends AbstractSequentialList <E > implements List <E >, Deque <E >, Cloneable , java .io .Serializable transient Node<E> first; transient Node<E> last; public boolean add (E e) linkLast(e); return true ; } void linkLast (E e) final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null ); last = newNode; if (l == null ) first = newNode; else l.next = newNode; size++; modCount++; } public boolean remove (Object o) if (o == null ) { for (Node<E> x = first; x != null ; x = x.next) { if (x.item == null ) { unlink(x); return true ; } } } else { for (Node<E> x = first; x != null ; x = x.next) { if (o.equals(x.item)) { unlink(x); return true ; } } } return false ; } E unlink (Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null ) { first = next; } else { prev.next = next; x.prev = null ; } if (next == null ) { last = prev; } else { next.prev = prev; x.next = null ; } x.item = null ; size--; modCount++; return element; }
该示例代码来自JDK的源码,在入选本博客的时候,有删改。
Set
Set的特点
第二种单列的Collection是Set。
元素存取无序
没有索引、只能通过迭代器或增强for循环遍历
不能存储重复元素
我们来看个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;import java.util.HashSet;import java.util.Set;public class SetDemo public static void main (String[] args) Set<String> set = new HashSet<String>(); set.add("hello" ); set.add("world" ); set.add("java" ); set.add("world" ); for (String s : set) { System.out.println(s); } System.out.println(set); } }
运行结果:
1 2 3 4 world java hello [world, java, hello]
执行了两次set.add("world");,但只记录一条world。
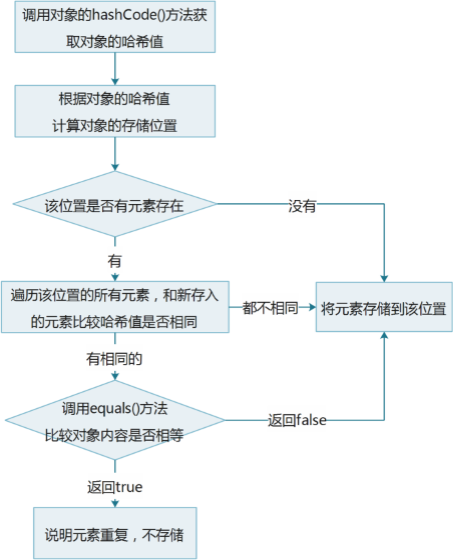
哈希值
那么HashSet是如何做到数据唯一的呢?这就得从哈希值开始说起了。
哈希值是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。public int hashCode(),该方法返回对象的哈希值。
同一个对象多次调用hashCode()方法返回的哈希值是相同的。
默认情况下,不同对象的哈希值是不同的。
如果重写hashCode()方法,可以实现让不同对象的哈希值相同。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.kakawanyifan;public class Student private String name; private int age; public Student (String name,int age) this .name = name; this .age = age; } public void setName (String name) this .name = name; } public String getName () return name; } public void setAge (int age) this .age = age; } public int getAge () return age; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.kakawanyifan;public class HashDemo public static void main (String[] args) Student s1 = new Student("林青霞" ,30 ); System.out.println(s1.hashCode()); System.out.println(s1.hashCode()); System.out.println("--------" ); Student s2 = new Student("林青霞" ,30 ); System.out.println(s2.hashCode()); System.out.println("--------" ); System.out.println("hello" .hashCode()); System.out.println("world" .hashCode()); System.out.println("java" .hashCode()); System.out.println("world" .hashCode()); System.out.println("--------" ); System.out.println("重地" .hashCode()); System.out.println("通话" .hashCode()); System.out.println("通话" .equals("重地" )); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 460141958 460141958 -------- 1163157884 -------- 99162322 113318802 3254818 113318802 -------- 1179395 1179395 false
注意"重地"和"通话",拥有相同的哈希值。"重地".equals("通话"),返回的是false。我们可以看String类源码的equals方法,并没有利用哈希值,这个我们在上一章《3.最常用的Java自带的类》 提到过。
HashSet源码分析
那么,HashSet是怎么保证元素唯一性的呢?
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.kakawanyifan;import java.util.HashSet;import java.util.Set;public class SetDemo public static void main (String[] args) String s1 = "重地" ; String s2 = "通话" ; System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); Set<String> set = new HashSet<>(); set.add(s1); set.add(s2); System.out.println(set); } }
运行结果:
1 2 3 1179395 1179395 [重地, 通话]
居然"重地"和"通话"都被加进去了?
不要猜了!直接看源码!
我们找到HashSet的add方法的源码。
1 2 3 public boolean add (E e) return map.put(e, PRESENT)==null ; }
发现数据是通过map.put(e, PRESENT)添加的,再来看看map.put(e, PRESENT)的源码。
1 2 3 public V put (K key, V value) return putVal(hash(key), key, value, false , true ); }
发现数据是通过putVal(hash(key), key, value, false, true)添加的。此外,还有一个hash(key)方法。我们来看看两个方法的源码
1 2 3 4 static final int hash (Object key) int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); }
到这里,其实可以解答我们的疑惑了。利用了哈希值,但不是在哈希值的基础上还做了操作。
最后,再看一下putVal()方法都做了啥。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
该部分的代码,其逻辑结构如图。
LinkedHashSet的概述和特点
除了HashSet,还有LinkedHashSet。
LinkedHashSet的特点:
哈希表和链表实现的Set接口。
元素的存储和取出顺序是一致的。
元素唯一,没有重复的元素。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.kakawanyifan;import java.util.LinkedHashSet;public class LinkedHashSetDemo public static void main (String[] args) LinkedHashSet<String> linkedHashSet = new LinkedHashSet<String>(); linkedHashSet.add("hello" ); linkedHashSet.add("world" ); linkedHashSet.add("java" ); linkedHashSet.add("world" ); for (String s : linkedHashSet) { System.out.println(s); } } }
运行结果:
TreeSet
TreeSet的特点
在《算法入门经典(Java与Python描述):7.哈希表》 中,我们讨论过TreeMap,特点是所有的key都是排序好的。
元素有序,此外可以通过构造方法自定义排序。
构造方法一 TreeSet():根据其元素的自然排序进行排序
构造方法二 TreeSet(Comparator comparator) :根据指定的比较器进行排序
没有带索引的方法,所以不能使用普通for循环遍历
不包含重复元素的集合
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import java.util.TreeSet;public class M public static void main (String[] args) TreeSet<Integer> ts = new TreeSet<Integer>(); ts.add(10 ); ts.add(40 ); ts.add(30 ); ts.add(50 ); ts.add(20 ); ts.add(30 ); for (Integer i : ts) { System.out.println(i); } } }
运行结果:
接下来,我们利用TreeSet的特点,来做一件事情。
自然排序
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.kakawanyifan;public class Student private String name; private int age; public Student (String name, int age) this .name = name; this .age = age; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.kakawanyifan;import java.util.TreeSet;public class TreeSetDemo public static void main (String[] args) TreeSet<Student> ts = new TreeSet<Student>(); Student s1 = new Student("x" , 29 ); Student s2 = new Student("y" , 28 ); Student s3 = new Student("z" , 30 ); Student s4 = new Student("za" , 33 ); Student s5 = new Student("a" , 33 ); Student s6 = new Student("a" , 33 ); ts.add(s1); ts.add(s2); ts.add(s3); ts.add(s4); ts.add(s5); ts.add(s6); for (Student s : ts) { System.out.println(s.getName() + "," + s.getAge()); } } }
运行结果:
1 2 3 4 5 Exception in thread "main" java.lang.ClassCastException: com.kakawanyifan.Student cannot be cast to java.lang.Comparable at java.util.TreeMap.compare(TreeMap.java:1294) at java.util.TreeMap.put(TreeMap.java:538) at java.util.TreeSet.add(TreeSet.java:255) at com.kakawanyifan.TreeSetDemo.main(TreeSetDemo.java:20)
居然报错了?
那我们就实现一下Comparable的接口。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.kakawanyifan;public class Student implements Comparable <Student > private String name; private int age; public Student (String name, int age) this .name = name; this .age = age; } public String getName () return name; } public void setName (String name) this .name = name; } public int getAge () return age; } public void setAge (int age) this .age = age; } @Override public int compareTo (Student o) return 0 ; } }
运行结果:
compareTo(Student o)这个方法默认return 0,我们不修改,试一下。居然之输出了一个?0代表元素是相等的,所以不会添加。
如果是1呢?
1 2 3 4 5 6 x,29 y,28 z,30 za,33 a,33 a,33
和存储顺序一样?
同理如果是-1
1 2 3 4 5 6 a,33 a,33 za,33 z,30 y,28 x,29
小结一下,A.compareTo(B)
所以呢,为了实现目标,我们修改compareTo方法如下即可
1 2 3 4 5 6 @Override public int compareTo (Student o) int num = this .getAge() - o.getAge(); int num2 = num == 0 ? this .getName().compareTo(o.getName()) : num; return num2; }
运行结果:
1 2 3 4 5 y,28 x,29 z,30 a,33 za,33
String类中已经有了compareTo方法,直接利用即可。
比较器排序
关于比较器,我们在《算法入门经典(Java与Python描述):9.堆》 也有过讨论,这里我们复习一下。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import java.util.Comparator;import java.util.TreeSet;public class TreeSetDemo public static void main (String[] args) TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() { @Override public int compare (Student s1, Student s2) int num = s1.getAge() - s2.getAge(); int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num; return num2; } }); Student s1 = new Student("x" , 29 ); Student s2 = new Student("y" , 28 ); Student s3 = new Student("z" , 30 ); Student s4 = new Student("za" , 33 ); Student s5 = new Student("a" , 33 ); Student s6 = new Student("a" , 33 ); ts.add(s1); ts.add(s2); ts.add(s3); ts.add(s4); ts.add(s5); ts.add(s6); for (Student s : ts) { System.out.println(s.getName() + "," + s.getAge()); } } }
运行结果:
1 2 3 4 5 y,28 x,29 z,30 a,33 za,33
拼音排序
拼音排序有两种方法:
基于java.util.Locale.CHINA,该方法存在准确率的问题,主要是对于多音字不够准确。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.kakawanyifan;import java.text.Collator;import java.util.Arrays;import java.util.Locale;public class main public static void main (String[] args) Collator cmp = Collator.getInstance(Locale.CHINA); String[] arr = { "张三" , "李四" , "王五" }; Arrays.sort(arr, cmp); System.out.println(Arrays.toString(arr)); String[] arr2 = { "上海" , "重庆" }; Arrays.sort(arr2, cmp); System.out.println(Arrays.toString(arr2)); } }
运行结果:
基于第三方的com.ibm.icu.util.ULocale.SIMPLIFIED_CHINESE,该方法更准确。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan;import com.ibm.icu.text.Collator;import com.ibm.icu.util.ULocale;import java.util.Arrays;public class main public static void main (String[] args) Collator cmp = Collator.getInstance(ULocale.SIMPLIFIED_CHINESE); String[] arr = { "张三" , "李四" , "王五" }; Arrays.sort(arr, cmp); System.out.println(Arrays.toString(arr)); String[] arr2 = { "上海" , "重庆" }; Arrays.sort(arr2, cmp); System.out.println(Arrays.toString(arr2)); } }
运行结果:
附,方法二的包:
1 2 3 4 5 6 7 <dependencies > <dependency > <groupId > com.ibm.icu</groupId > <artifactId > icu4j</artifactId > <version > 71.1</version > </dependency > </dependencies >
元素的内容被改变,不会重排
其实希望元素内容被改变还重排,更像我们的一厢情愿。
元素内容被改变了,去触发TreeSet重排
TreeSet有一个很巧妙的办法主动监控
同时,还需要考虑性能问题,以及安全问题。(比如,重排期间被读取。)
现象
假设存在一批数据,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 [{ "cnt" : 1 , "name" : "标签一" , }, { "cnt" : 2 , "name" : "标签二" }, { "cnt" : 3 , "name" : "标签三" }, { "cnt" : 4 , "name" : "标签一" }]
现在需要对这一批数据进行合并,相同name的合为一个,其cnt进行相加。并按照cnt从大到小进行排序。
1 2 3 4 5 6 7 8 9 10 [{ "cnt" : 5 , "name" : "标签一" , }, { "cnt" : 3 , "name" : "标签三" }, { "cnt" : 2 , "name" : "标签二" }]
因为需要从大到小排序,这里考虑TreeSet,这个自带排序。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.kakawanyifan;public class Label implements Comparable <Label > private String name; private Integer cnt; public Label (String name, Integer cnt) super (); this .name = name; this .cnt = cnt; } public String getName () return name; } public void setName (String name) this .name = name; } public Integer getCnt () return cnt; } public void setCnt (Integer cnt) this .cnt = cnt; } @Override public int compareTo (Label o) return o.cnt - cnt; } @Override public String toString () return "Label [name=" + name + ", cnt=" + cnt + "]" ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import java.util.Set;import java.util.TreeSet;import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;public class TreeSetDemo public static void main (String[] args) Set<Label> labelSet = new TreeSet<Label>(); String input = "[{\"cnt\":1,\"name\":\"标签一\",},{\"cnt\":2,\"name\":\"标签二\"},{\"cnt\":3,\"name\":\"标签三\"},{\"cnt\":4,\"name\":\"标签一\"}]" ; JSONArray ja = JSONArray.parseArray(input); for (int i = 0 ; i < ja.size(); i++) { JSONObject jo = ja.getJSONObject(i); String name = jo.getString("name" ); Integer cnt = jo.getInteger("cnt" ); boolean contain = false ; Label conLabel = null ; for (Label tempLabel : labelSet) { if (tempLabel.getName().equals(name)) { conLabel = tempLabel; contain = true ; break ; } } if (contain) { conLabel.setCnt(conLabel.getCnt() + cnt); }else { Label newLabel = new Label(name, cnt); labelSet.add(newLabel); } } System.out.println(labelSet.toString()); } }
运行结果:
1 [Label [name=标签三, cnt=3], Label [name=标签二, cnt=2], Label [name=标签一, cnt=5]]
解释说明:
name为标签一的Label被放在第三个位置,因为后期其cnt被修改了,但是并不会重排。
解决
可以让其先去除再加入,以此触发重排。但是这样代码的确不雅。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 【部分代码略】 if (contain) { labelSet.remove(conLabel); conLabel.setCnt(conLabel.getCnt() + cnt); labelSet.add(conLabel); }else { Label newLabel = new Label(name, cnt); labelSet.add(newLabel); } 【部分代码略】
运行结果:
1 [Label [name=标签一, cnt=5], Label [name=标签三, cnt=3], Label [name=标签二, cnt=2]]
或者先用List,最后统一加入到Set中。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;import java.util.Set;import java.util.TreeSet;import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;public class TreeSetDemo public static void main (String[] args) Set<Label> labelSet = new TreeSet<Label>(); List<Label> labelList = new ArrayList<Label>(); String input = "[{\"cnt\":1,\"name\":\"标签一\",},{\"cnt\":2,\"name\":\"标签二\"},{\"cnt\":3,\"name\":\"标签三\"},{\"cnt\":4,\"name\":\"标签一\"}]" ; JSONArray ja = JSONArray.parseArray(input); for (int i = 0 ; i < ja.size(); i++) { JSONObject jo = ja.getJSONObject(i); String name = jo.getString("name" ); Integer cnt = jo.getInteger("cnt" ); boolean contain = false ; Label conLabel = null ; for (Label tempLabel : labelList) { if (tempLabel.getName().equals(name)) { conLabel = tempLabel; contain = true ; break ; } } if (contain) { conLabel.setCnt(conLabel.getCnt() + cnt); }else { Label newLabel = new Label(name, cnt); labelList.add(newLabel); } } for (Label label:labelList) { labelSet.add(label); } System.out.println(labelSet.toString()); } }
运行结果:
1 [Label [name=标签一, cnt=5], Label [name=标签三, cnt=3], Label [name=标签二, cnt=2]]
compareTo方法的注意
现象
我们修改一下输入,添加两个{"cnt": 1,"name": "标签三"},如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [{ "cnt" : 1 , "name" : "标签一" , }, { "cnt" : 2 , "name" : "标签二" }, { "cnt" : 3 , "name" : "标签三" }, { "cnt" : 4 , "name" : "标签一" }, { "cnt" : 1 , "name" : "标签三" }, { "cnt" : 1 , "name" : "标签三" }]
这时候"标签一"和"标签三"的cnt,都是5了。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;import java.util.Set;import java.util.TreeSet;import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;public class TreeSetDemo public static void main (String[] args) Set<Label> labelSet = new TreeSet<Label>(); List<Label> labelList = new ArrayList<Label>(); String input = "[{\"cnt\":1,\"name\":\"标签一\",},{\"cnt\":2,\"name\":\"标签二\"},{\"cnt\":3,\"name\":\"标签三\"},{\"cnt\":4,\"name\":\"标签一\"},{\"cnt\":1,\"name\":\"标签三\"},{\"cnt\":1,\"name\":\"标签三\"}]" ; JSONArray ja = JSONArray.parseArray(input); for (int i = 0 ; i < ja.size(); i++) { JSONObject jo = ja.getJSONObject(i); String name = jo.getString("name" ); Integer cnt = jo.getInteger("cnt" ); boolean contain = false ; Label conLabel = null ; for (Label tempLabel : labelList) { if (tempLabel.getName().equals(name)) { conLabel = tempLabel; contain = true ; break ; } } if (contain) { conLabel.setCnt(conLabel.getCnt() + cnt); }else { Label newLabel = new Label(name, cnt); labelList.add(newLabel); } } for (Label label:labelList) { labelSet.add(label); } System.out.println(labelSet.toString()); } }
运行结果:
1 [Label [name=标签一, cnt=5], Label [name=标签二, cnt=2]]
解释说明:
原因分析
会是需要重写equals和hashCode方法吗?不会!
所有的类都会继承自java.lang.Object。
java.lang.Object的hashCode值是根据内存地址换算出来的一个值。java.lang.Object的equals方法是判断两个对象是否严格相等(object1 == object2),有时候,我们需要的不是一种严格意义上的相等,而是一种业务上的对象相等。在这种情况下,就需要重写equals方法。
但在这里,{name=标签三, cnt=5},{name=标签一, cnt=5}的hashCode必定不相等,equals也必定为false
解决
修改label类的compareTo方法,即可解决问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 【部分代码略】 @Override public int compareTo (Label o) if (o.cnt - cnt > 0 ) { return 1 ; }else { return -1 ; } } 【部分代码略】
运行结果:
1 [Label [name=标签三, cnt=5], Label [name=标签一, cnt=5], Label [name=标签二, cnt=2]]
解释说明:
返回1,那么当前的值会排在被比较者后面。 返回0,那么当前的值【不会被加入到 TreeSet 中】,因为当前的值【被认为和现有的某一个值相等】。 返回-1,会被添加到被比较者的前边。
Collections
在讨论了Collection的两个子接口List和Set之后,我们来讨论一个工具类,Collections。
注意是Collections,不是Collection,多了一个s
Collections的常用方法:
方法名
说明
public static void sort(List list)
将指定的列表按升序排序
public static void reverse(List<?> list)
反转指定列表中元素的顺序
public static void shuffle(List<?> list)
使用默认的随机源随机排列指定的列表
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.kakawanyifan;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class CollectionsDemo public static void main (String[] args) List<Integer> list = new ArrayList<Integer>(); list.add(30 ); list.add(20 ); list.add(50 ); list.add(10 ); list.add(40 ); Collections.sort(list); System.out.println(list); Collections.reverse(list); System.out.println(list); Collections.shuffle(list); System.out.println(list); } }
运行结果:
1 2 3 [10, 20, 30, 40, 50] [50, 40, 30, 20, 10] [10, 30, 40, 20, 50]
Collections中同样可以利用比较器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.kakawanyifan;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;public class CollectionsDemo public static void main (String[] args) List<Student> array = new ArrayList<Student>(); Student s1 = new Student("x" , 29 ); Student s2 = new Student("y" , 28 ); Student s3 = new Student("z" , 30 ); Student s4 = new Student("za" , 33 ); Student s5 = new Student("a" , 33 ); Student s6 = new Student("a" , 33 ); array.add(s1); array.add(s2); array.add(s3); array.add(s4); array.add(s5); Collections.sort(array, new Comparator<Student>() { @Override public int compare (Student s1, Student s2) int num = s1.getAge() - s2.getAge(); int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num; return num2; } }); for (Student s : array) { System.out.println(s.getName() + "," + s.getAge()); } } }
运行结果:
1 2 3 4 5 y,28 x,29 z,30 a,33 za,33
Map
接下来,我们讨论集合的双列,Map。
概述和特点
Map是一个接口
描述的是键值对映射关系,一个键对应一个值,键不能重复,值可以重复。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.kakawanyifan;import java.util.HashMap;import java.util.Map;public class MapDemo public static void main (String[] args) Map<String,String> map = new HashMap<String,String>(); map.put("001" ,"林青霞" ); map.put("002" ,"张曼玉" ); map.put("003" ,"王祖贤" ); System.out.println(map); map.put("003" ,"柳岩" ); System.out.println(map); } }
运行结果:
1 2 {001=林青霞, 002=张曼玉, 003=王祖贤} {001=林青霞, 002=张曼玉, 003=柳岩}
map.put("003","柳岩")覆盖了map.put("003","王祖贤")。
Map的常用方法
方法名
说明
V put(K key,V value)
添加元素。
V get(Object key)
获取元素。
V remove(Object key)
根据键删除键值对元素。
void clear()
移除所有的键值对元素。
boolean containsKey(Object key)
判断集合是否包含指定的键。
boolean containsValue(Object value)
判断集合是否包含指定的值。
boolean isEmpty()
判断集合是否为空。
int size()
集合的长度,也就是集合中键值对的个数。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.kakawanyifan;import java.util.HashMap;import java.util.Map;public class MapDemo public static void main (String[] args) Map<String,String> map = new HashMap<String,String>(); map.put("张无忌" ,"赵敏" ); map.put("郭靖" ,"黄蓉" ); map.put("杨过" ,"小龙女" ); System.out.println(map); System.out.println(map.remove("郭靖" )); System.out.println(map.remove("郭襄" )); map.clear(); System.out.println(map.containsKey("郭靖" )); System.out.println(map.containsKey("郭襄" )); System.out.println(map.isEmpty()); System.out.println(map.size()); System.out.println(map); } }
运行结果:
1 2 3 4 5 6 7 8 {杨过=小龙女, 郭靖=黄蓉, 张无忌=赵敏} 黄蓉 null false false true 0 {}
Map的获取方法
方法名
说明
V get(Object key)
根据键获取值。
Set keySet()
获取所有键的集合。
Collection values()
获取所有值的集合。
Set<Map.Entry<K,V>> entrySet()
获取所有键值对对象的集合。
我们可以获取所有的键,可以根据键获取值。
所以,我们有三种遍历方式。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.kakawanyifan;import java.util.Collection;import java.util.HashMap;import java.util.Map;import java.util.Set;public class MapDemo public static void main (String[] args) Map<String, String> map = new HashMap<String, String>(); map.put("张无忌" , "赵敏" ); map.put("郭靖" , "黄蓉" ); map.put("杨过" , "小龙女" ); System.out.println(map.get("张无忌" )); System.out.println(map.get("张三丰" )); System.out.println("------" ); Set<String> keySet = map.keySet(); for (String key : keySet) { System.out.println(key + "," + map.get(key)); } System.out.println("------" ); Collection<String> values = map.values(); for (String value : values) { System.out.println(value); } System.out.println("------" ); Set<Map.Entry<String, String>> entrySet = map.entrySet(); for (Map.Entry<String, String> me : entrySet) { String key = me.getKey(); String value = me.getValue(); System.out.println(key + "," + value); } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 赵敏 null ------ 杨过,小龙女 郭靖,黄蓉 张无忌,赵敏 ------ 小龙女 黄蓉 赵敏 ------ 杨过,小龙女 郭靖,黄蓉 张无忌,赵敏
HashMap的源码分析
现象
现在,我们来做一件事情,以学生作为键,以分数作为值。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import java.util.HashMap;import java.util.Set;public class HashMapDemo public static void main (String[] args) HashMap<Student, Integer> hm = new HashMap<Student, Integer>(); Student s1 = new Student("林青霞" , 30 ); Student s2 = new Student("张曼玉" , 35 ); Student s3 = new Student("王祖贤" , 33 ); Student s4 = new Student("王祖贤" , 33 ); hm.put(s1, 99 ); hm.put(s2, 98 ); hm.put(s3, 87 ); hm.put(s4, 90 ); Set<Student> keySet = hm.keySet(); for (Student key : keySet) { int value = hm.get(key); System.out.println(key.getName() + "," + key.getAge() + "," + value); } } }
运行结果:
1 2 3 4 王祖贤,33,87 张曼玉,35,98 林青霞,30,99 王祖贤,33,90
出BUG了!
我们用的是HashMap啊,怎么出现了重复的键?两个王祖贤,33?
到底怎么回事?
源码分析
我们来看看这个put方法到底做了什么。
1 2 3 public V put (K key, V value) return putVal(hash(key), key, value, false , true ); }
先来看看hash方法。
1 2 3 4 static final int hash (Object key) int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); }
哦,利用了hashCode,所以我们的Student类继承自Object类,我们要重写Student类的hashCode方法。
再来看看putVal方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
还利用了equals方法,我们还要重写Student类的equals方法。
即,需要重写Student类的hashCode方法和equals方法。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package com.kakawanyifan;import java.util.Objects;public class Student private String name; private int age; public Student (String name, int age) this .name = name; this .age = age; } public void setName (String name) this .name = name; } public String getName () return name; } public void setAge (int age) this .age = age; } public int getAge () return age; } @Override public boolean equals (Object o) if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Student student = (Student) o; if (age != student.age) return false ; return Objects.equals(name, student.name); } @Override public int hashCode () int result = name != null ? name.hashCode() : 0 ; result = 31 * result + age; return result; } }
为什么是31? 因为31在JVM中是一个神奇的数字。 任何数n*31都可以被jvm优化为(n<<5)-n,移位和减法的操作效率比乘法的操作效率高很多。
集合嵌套
ArrayList嵌套HashMap
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import java.util.ArrayList;import java.util.HashMap;import java.util.Set;public class ArrayListIncludeHashMapDemo public static void main (String[] args) ArrayList<HashMap<String, String>> array = new ArrayList<HashMap<String, String>>(); HashMap<String, String> hm1 = new HashMap<String, String>(); hm1.put("孙策" , "大乔" ); hm1.put("周瑜" , "小乔" ); array.add(hm1); HashMap<String, String> hm2 = new HashMap<String, String>(); hm2.put("郭靖" , "黄蓉" ); hm2.put("杨过" , "小龙女" ); array.add(hm2); HashMap<String, String> hm3 = new HashMap<String, String>(); hm3.put("令狐冲" , "任盈盈" ); hm3.put("林平之" , "岳灵珊" ); array.add(hm3); for (HashMap<String, String> hm : array) { Set<String> keySet = hm.keySet(); for (String key : keySet) { String value = hm.get(key); System.out.println(key + "," + value); } } } }
运行结果:
1 2 3 4 5 6 孙策,大乔 周瑜,小乔 杨过,小龙女 郭靖,黄蓉 令狐冲,任盈盈 林平之,岳灵珊
HashMap嵌套ArrayList
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.kakawanyifan;import java.util.ArrayList;import java.util.HashMap;import java.util.Set;public class ArrayListIncludeHashMapDemo public static void main (String[] args) HashMap<String, ArrayList<String>> hm = new HashMap<String, ArrayList<String>>(); ArrayList<String> sgyy = new ArrayList<String>(); sgyy.add("诸葛亮" ); sgyy.add("赵云" ); hm.put("三国演义" ,sgyy); ArrayList<String> xyj = new ArrayList<String>(); xyj.add("唐僧" ); xyj.add("孙悟空" ); hm.put("西游记" ,xyj); ArrayList<String> shz = new ArrayList<String>(); shz.add("武松" ); shz.add("鲁智深" ); hm.put("水浒传" ,shz); Set<String> keySet = hm.keySet(); for (String key : keySet) { System.out.println(key); ArrayList<String> value = hm.get(key); for (String s : value) { System.out.println("\t" + s); } } } }
运行结果:
1 2 3 4 5 6 7 8 9 水浒传 武松 鲁智深 三国演义 诸葛亮 赵云 西游记 唐僧 孙悟空
泛型
最后一个话题,泛型。《3.最常用的Java自带的类》 这么一章,讨论ArrayList的时候,我们提到了泛型。
1 ArrayList<String> array = new ArrayList<String>();
这里有一个<>,里面写着String。这个含义是说这个ArrayList的元素的数据类型是String。ArryList<Student>,表示每一个元素的数据类型都是Student。
在本章,我们其实也大量用到了泛型。
泛型概述
根据之前的讨论,我们知道泛型的本质是一个参数化类型,也就是说所操作的数据类型被指定为一个参数。
根据参数的个数,泛型的定义有两种格式,两种定义格式,其实我们都已经用过了。
第一种是格式是:
这种格式,我们在Collection中用过。
第二种格式是
这种格式,我们在Map中用过。
泛型类
泛型类初步
泛型类的定义格式
泛型类的使用格式
1 类名<具体的数据类型> 对象名 = new 类名<具体的数据类型>();
在JDK8及之后,后面的<>中的具体的数据类型可以省略不写。
1 类名<具体的数据类型> 对象名 = new 类名<>();
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.kakawanyifan;public class Generic <T > private T t; public T getT () return t; } public void setT (T t) this .t = t; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;public class GenericDemo public static void main (String[] args) Generic<String> g1 = new Generic<String>(); g1.setT("林青霞" ); System.out.println(g1.getT()); Generic<Integer> g2 = new Generic<Integer>(); g2.setT(30 ); System.out.println(g2.getT()); Generic<Boolean> g3 = new Generic<Boolean>(); g3.setT(true ); System.out.println(g3.getT()); } }
运行结果:
特别的,如果实例化了泛型,但是又没有指定数据类型呢?
泛型标识
在刚刚的例子中,泛型类的类型参数是T,这里的T也被称为称为泛型标识。
E,含义是Element,在集合中使用,因为集合中存放的是元素。
T,含义是Type,表示类。
K,含义是Key,表示键,指的是Map中的key。
V,含义是Value,表示值,值得是Map种的Value。
N,含义是Number,表示数值类型。
?,表示不确定的类。
S、U、V,也是类,在多个泛型的时候,以示区分。
泛型类的继承
泛型类也有其继承方法。
子类是泛型类
子类是泛型类,子类和父类的泛型标识要一致。
1 class Zi<T> extends Fu<T>
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.kakawanyifan;public class Fu <E > private E e; public E getE () return e; } public void setE (E e) this .e = e; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.kakawanyifan;public class Zi <T > extends Fu <T > private T t; public T getT () return t; } public void setT (T t) this .t = t; } }
子类不是泛型类
子类不是泛型类,父类要明确泛型的数据类型。
1 class Zi extends Fu<Integer>
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan;public class Zi extends Fu <Integer > @Override public Integer getE () return super .getE(); } @Override public void setE (Integer integer) super .setE(integer); } }
泛型接口
泛型接口定义格式
1 修饰符 interface 接口名<类型>
与继承类似,根据泛型接口的实现类是不是泛型类,在接口实现上分为两种情况。
实现类也是泛型类,实现类和接口的泛型标识要一致。
实现类不是泛型类,接口要明确数据类型。
示例代码:
1 2 3 4 5 package com.kakawanyifan;public interface Generic <T > void show (T t) }
1 2 3 4 5 6 7 8 package com.kakawanyifan;public class GenericImpl <T > implements Generic <T > @Override public void show (T t) System.out.println(t); } }
1 2 3 4 5 6 7 8 9 10 11 package com.kakawanyifan;public class GenericDemo public static void main (String[] args) Generic<String> g1 = new GenericImpl<String>(); g1.show("林青霞" ); Generic<Integer> g2 = new GenericImpl<Integer>(); g2.show(30 ); } }
运行结果:
泛型方法
泛型方法的定义格式
1 修饰符 <类型> 返回值类型 方法名(类型 变量名) { }
<类型>这一部分是泛型方法和其他方法主要区别,只有有这一部分的方法才能被称为泛型方法。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan;public class GenericDemo private static <T> void show (T t) System.out.println(t); } public static void main (String[] args) show("林青霞" ); show(30 ); show(true ); show(12.34 ); } }
运行结果:
类型通配符
类型通配符的分类:
<?>List<?>:表示元素类型未知的List,它的元素可以匹配任何的类型。<? extends 类型>List<? extends Number>:表示的类型是Number或者其子类型。<? super 类型>List<? super Number>:它表示的类型是Number或者其父类型。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;import java.util.ArrayList;import java.util.List;public class GenericDemo public static void main (String[] args) List<?> list1 = new ArrayList<Object>(); List<?> list2 = new ArrayList<Number>(); List<?> list3 = new ArrayList<Integer>(); System.out.println("--------" ); List<? extends Number> list5 = new ArrayList<Number>(); List<? extends Number> list6 = new ArrayList<Integer>(); System.out.println("--------" ); List<? super Number> list7 = new ArrayList<Object>(); List<? super Number> list8 = new ArrayList<Number>(); } }
泛型的特点
泛型的特点有:
泛型的类型参数只能是引用数据类型,不能是基本数据类型。
泛型的类型在逻辑上可以看成是多个不同的类型,但实际上都是相同类型。
第二个特点或许不好理解,我们来看一个例子。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan;public class GenericDemo public static void main (String[] args) Generic<String> g1 = new Generic<String>(); System.out.println(g1.getClass()); Generic<Integer> g2 = new Generic<Integer>(); System.out.println(g2.getClass()); Generic<Boolean> g3 = new Generic<Boolean>(); System.out.println(g3.getClass()); } }
运行结果:
1 2 3 class com.kakawanyifan.Generic class com.kakawanyifan.Generic class com.kakawanyifan.Generic
那么,现在问题来了,其实都是同一种类型吧,那是怎么做到又能支持"String",又能支持"Integer"的呢?
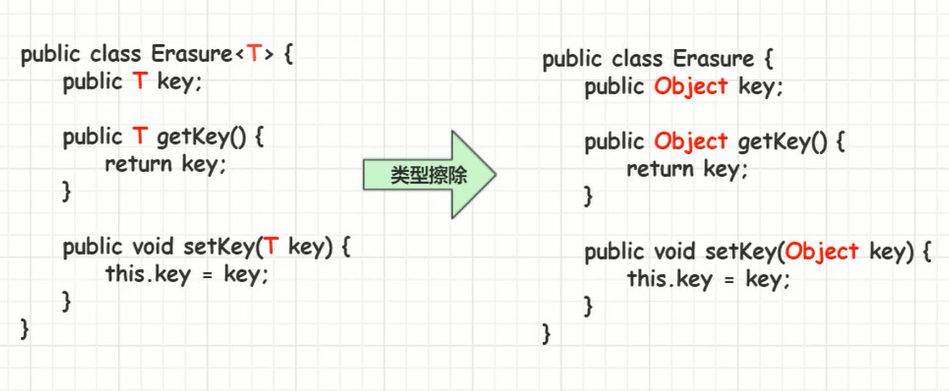
泛型原理:类型擦除
泛型是Java 1.5版本才引进的概念,在这之前是没有泛型的,但是泛型代码能够很好地和之前版本的代码兼容。那是因为,泛型信息只存在于代码编译阶段,在进入JVM之前,与泛型相关的信息会被擦除掉,我们称之为:类型擦除。
类型擦除有四种。
无限制类型擦除
有限制类型擦除
擦除方法中类型定义的参数
桥接方法
我们分别讨论。
无限制类型擦除
无限制类型擦除,在编译的时候,把范型擦除为Object类型。
我们可以通过反射看看,到底是不是这样。
(关于反射,我们在《9.类的加载与反射》 有做专题讨论。)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan;public class Erasure <T > private T t; public T getT () return t; } public void setT (T t) this .t = t; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;import java.lang.reflect.Field;public class ErasureDemo public static void main (String[] args) Erasure<Integer> erasure = new Erasure<>(); Class<? extends Erasure> clz = erasure.getClass(); Field[] declaredFields = clz.getDeclaredFields(); for (Field declareField:declaredFields) { System.out.println(declareField.getName() + " : " + declareField.getType().getName()); } } }
运行结果:
成员变量的名字依旧是t,但是类型已经成为了java.lang.Object,符合我们上文的描述,证明完毕。
也是因为这个原因,在反射中还有一个神奇的现象,越过泛型检查,我们会在《9.类的加载与反射》 讨论反射的时候讨论。
有限制类型擦除
有限制类型擦除,把类型擦除为其extend的类型。
证明过程略。
擦除方法中类型定义的参数
擦除方法中类型定义的参数,该种擦除同样存在有限和无限两种情况。
我们利用反射来看一下。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.kakawanyifan;import java.util.List;public class Erasure <T extends Number > private T t; public T getT () return t; } public void setT (T t) this .t = t; } public <T extends List> T rtn (T t) { return t; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;import java.lang.reflect.Method;public class ErasureDemo public static void main (String[] args) Erasure<Integer> erasure = new Erasure<>(); Class<? extends Erasure> clz = erasure.getClass(); Method[] declaredMethods = clz.getDeclaredMethods(); for (Method declaredMethod:declaredMethods) { System.out.println(declaredMethod.getName() + " : " + declaredMethod.getReturnType().getName()); } } }
运行结果:
1 2 3 setT : void rtn : java.util.List getT : java.lang.Number
确实存在一个方法,方法名是rtn,返回类型是java.util.List,符合我们上文的描述,证明完毕。
桥接方法
最后一种是桥接方法,这种主要存在与接口的实现类中。其特点是利用一个桥接方法,保持接口和类的联系。
我们利用反射来看一下。
示例代码:
1 2 3 4 5 package com.kakawanyifan;public interface Info <T > T info (T t) ; }
1 2 3 4 5 6 7 8 9 package com.kakawanyifan;public class InfoImpl implements Info <Integer > @Override public Integer info (Integer integer) return integer; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.kakawanyifan;import java.lang.reflect.Method;import java.lang.reflect.Parameter;public class InfoImplDemo public static void main (String[] args) InfoImpl infoImpl = new InfoImpl(); Class<? extends InfoImpl> clz = infoImpl.getClass(); Method[] declaredMethods = clz.getDeclaredMethods(); for (Method declaredMethod:declaredMethods) { System.out.println(declaredMethod.getName() + " : " + declaredMethod.getReturnType().getName()); Parameter[] parameters = declaredMethod.getParameters(); for (Parameter parameter:parameters) { System.out.println(parameter.getType().getName()); } System.out.println(); } } }
运行结果:
1 2 3 4 5 info : java.lang.Integer java.lang.Integer info : java.lang.Object java.lang.Object
确实存在两个方法,其中一个是原始的逻辑处理,另一个是桥接方法。符合我们上文的描述,证明完毕。证明完毕。
可变参数
可变参数即参数个数可变,用作方法的形参出现,指该方法参数个数就是可变的。
可变参数定义格式
1 修饰符 返回值类型 方法名(数据类型... 变量名) { }
可变参数的注意事项
这里的变量其实是一个数组
如果一个方法有多个参数,包含可变参数,可变参数要放在最后 。
我们来看个具体的例子。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;public class ArgsDemo public static void main (String[] args) System.out.println(sum(0 )); System.out.println(sum(0 , 1 )); System.out.println(sum(0 , 1 , 2 )); System.out.println(sum(0 , 1 , 2 , 3 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 , 5 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 , 5 , 6 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 )); System.out.println(sum(0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ,9 )); } public static int sum (int ... a) int sum = 0 ; for (int i : a) { sum += i; } return sum; } }
运行结果:
1 2 3 4 5 6 7 8 9 10 0 1 3 6 10 15 21 28 36 45
Arrays源码分析
这不是我们第一次分析Arrays的源码,在《3.最常用的Java自带的类》 这一章我们也分析过Arrays的源码,当时我们以Arrays的源码为例,说设计工具类时候,非常建议的两个准则。
构造方法用private,防止外界创建对象。
成员方法用public static,为了使用类名访问成员方法。
这次,我们来看Arrays的一个似乎不是特别好的地方。
asList的注意
在Arrays类的asList方法中,我们可以看到可变参数,还可以看到泛型。
1 2 3 public static <T> List<T> asList (T... a) { return new ArrayList<>(a); }
修饰符之后紧跟着的<T>,说明这是一个泛型方法。
T...,说明这是一个可变参数方法。
我们来看个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.kakawanyifan;import java.util.Arrays;import java.util.List;public class ArgsDemo public static void main (String[] args) List<String> a = Arrays.asList("a" , "b" , "c" ); System.out.println(a); a.set(0 , "d" ); System.out.println(a); a.add("e" ); System.out.println(a); } }
运行结果:
1 2 3 4 5 6 [a, b, c] [d, b, c] Exception in thread "main" java.lang.UnsupportedOperationException at java.util.AbstractList.add(AbstractList.java:148) at java.util.AbstractList.add(AbstractList.java:108) at com.kakawanyifan.ArgsDemo.main(ArgsDemo.java:13)
可以修改,但是不能新增?不支持的操作?
看看asList方法的源代码。
1 2 3 public static <T> List<T> asList (T... a) { return new ArrayList<>(a); }
调用的是ArrayList的构造方法,再来看看ArrayList的构造方法。
1 2 3 4 5 6 7 8 9 10 11 12 private static class ArrayList <E > extends AbstractList <E > implements RandomAccess , java .io .Serializable private static final long serialVersionUID = -2764017481108945198L ; private final E[] a; ArrayList(E[] array) { a = Objects.requireNonNull(array); } 【部分代码略】 }
注意看!a居然是用final修饰的。在《2.面向对象》 ,讨论继承的访问权限的时候,我们讨论过。“fianl修饰类:该类不能被继承(不能有子类,但是可以有父类)”
此外,我们还讨论了
fianl修饰基本数据类型变量:final修饰指的是基本类型的数据值不能发生改变。
final修饰引用数据类型变量:final修饰指的是引用类型的地址值不能发生改变,但是地址里面的内容是可以发生改变的。
这样就可以解释,为什么我们不可以增加删除,但是可以修改了。
解决方法
那么,我们怎么把一个数组转为ArrayList,同时还能对其进行增删操作呢?
遍历数组,然后一个一个加进去。
利用Collections工具类的addAll()方法。
第一种方法不举例子,第二种方法,我们举个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class ExceptionDemo public static void main (String[] args) String[] array = {"a" , "b" , "c" }; List<String> arrayList = new ArrayList<>(); Collections.addAll(arrayList,array); System.out.println(arrayList); arrayList.set(0 ,"d" ); System.out.println(arrayList); arrayList.add("e" ); System.out.println(arrayList); } }
运行结果:
1 2 3 [a, b, c] [d, b, c] [d, b, c, e]