这一章,我们会讨论
Java内存模型
多线程特性
ThreadLocal
原子类
Lock类
Volatile关键字
并发容器
线程池
在上一章《7.多线程 [1/2]》 ,我们讨论的内容有:
什么是多线程
线程创建
线程传递入参
线程控制
线程调度
线程生命周期
线程安全
线程死锁
线程通信
Java内存模型
在上一章《7.多线程 [1/2]》 ,我们通过CPU时间片理解了为什么会出现线程不安全,这一章,我们通过讨论Java内存模型,更深刻的理解为什么会线程不安全。
这部分的一些内容,其实在之前的章节中,讨论栈内存和堆内存的时候,都有过很通俗的解释。
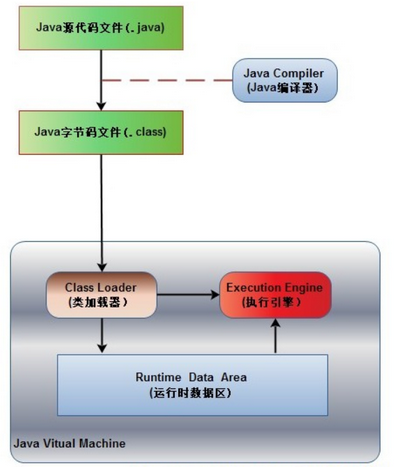
Java程序执行流程回顾
早在第一章《1.基础语法》 ,我们就讨论过,我们写的Java代码,是首先编译成class字节码文件,然后交由JVM去执行的。
如图所示:
(关于类加载器,我们在《9.类的加载与反射》 ,有更详细的讨论。)
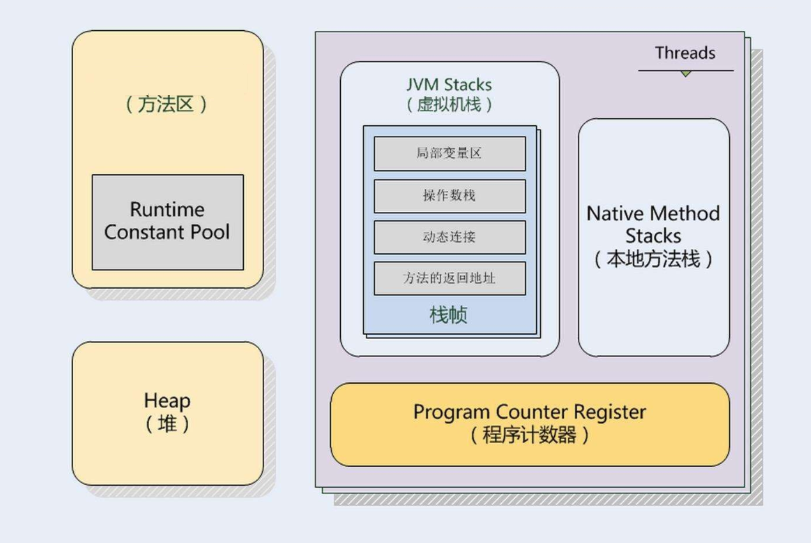
Java内存模型
根据JVM规范,JVM内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。结构如下图:
我们解释一下。
方法区和堆,颜色是一样的。都属于堆,方法区也是堆。但是方法区是堆里的永久区,垃圾回收的概率低,数据稳定。但是Heap堆会频繁的进行垃圾回收。
Runtime constant pool,是运行时常量池。是方法区里面的专门存放运行时常量的。
JVM Stacks,Java虚拟机栈。也有资料称之为:线程栈、Java栈。每一个线程在执行过程中都会在这个栈里面创建一个栈帧。栈由无数个栈帧构成。
本地方法栈也是一个栈,但不同的是本地方法栈执行的是native方法,也就是Java最底层的方法,由其他语言实现的。而虚拟机栈里的是Java方法。
程序计数器,是帮助执行栈帧里面方法的。
有几个再重点解释一下。
程序计数器
每个线程对应有一个程序计数器。
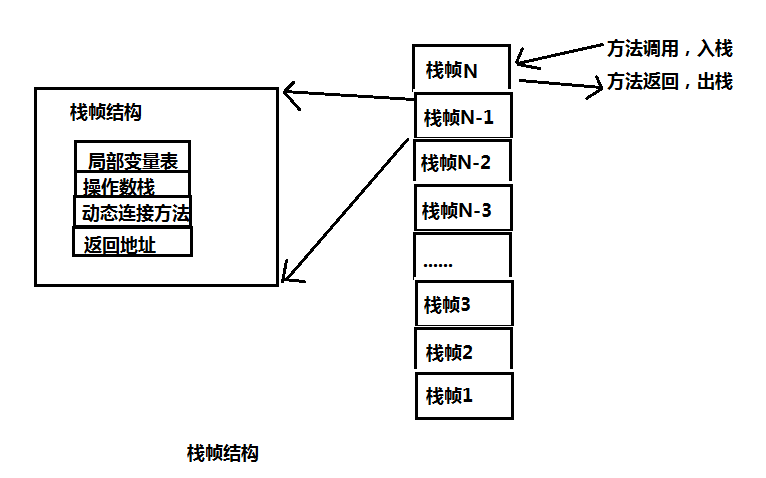
Java虚拟机栈
每个线程会对应一个Java栈。
每一个栈帧的结构如下
栈帧1代表创建的线程的第一个方法,其他依次类推。
每一个栈帧的结构都有:局部变量表、操作数栈、动态连接方法、返回地址
局部变量指的是基本类型的。
引用类型的话变量在栈帧结构里,但是具体的对象在堆里。
方法区MethodArea
方法区是Java堆的永久区(PermanetGeneration)
常量池ConstantPool
常量池是方法区的一部分。顾名思义,存储常量的。比如字符串,比如被final修饰的变量。
本地方法栈Native Method Stack
本地方法栈和Java栈所发挥的作用非常相似,区别不过是Java栈为JVM执行Java方法服务,而本地方法栈为JVM执行Native方法服务。
Java内存模型的工作
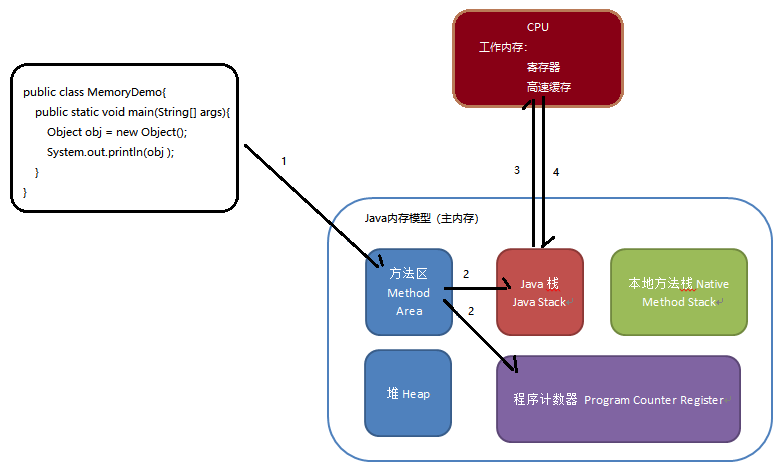
在讨论了Java内存模型之后,我们来讨论Java内存模型的工作。
首先类加载器将Java代码对应的Class文件加载到方法区。
方法区存储类的名称,关键字,方法,方法名,参数,返回值类型。
然后执行引擎从方法区找到main方法。
为main方法创建虚拟机栈,同时创建该main方法的程序计数器。
执行引擎请求CPU执行该方法。
CPU将方法栈数据加载到工作内存(寄存器和高速缓存),执行该方法。
CPU执行完之后将执行结果从工作内存同步到主内存。
例如我们的代码,创建了Object对象。那么这个对象同步到堆中。
假如我们再对这个Object对象进行更改,这个更改会在寄存器和高速缓存完成,再保存到堆当中。
在部分不考虑CPU的资料中,把Java栈称之为工作内存,把堆称之为主内存。我们这里把CPU考虑了,把继承器和高速换成称之为工作内存。
如果只有一个线程的话,上述过程没有一点问题。
要解决这些问题就涉及到多线程编程三个特性:原子性,有序性,可见性。
多线程特性
通过上文对"Java内存模型的工作"的讨论,我们更深刻的理解了线程不安全的原因。
原子性
可见性
有序性
我们依次讨论。
原子性
这个名词的来源于,原子不可分。
原子性,即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性
有序性即程序执行的顺序按照我们的预期顺序执行。《7.多线程 [1/2]》 ,我们利用同步关键字和锁等方法解决了。
线程不安全解决方法
为了保证多线程的三个特性,Java引入了很多线程控制机制,下面介绍其中常用的几种:
ThreadLocal:为每一个线程保存线程本地变量。
原子类:特点保证变量的写操作是原子性。
Lock类:保证线程的有序性,按照我们预期的顺序。
Volatile关键字:保证线程变量的可见性。
ThreadLocal
应用
这种方法,其实就是我们上一章《7.多线程 [1/2]》 通俗讨论的让线程不要共享变量。
ThreadLocal的常用方法有:
方法名
说明
initialValue
创建副本
get
获取副本
set
设置副本
我们举个例子,两个线程分别转账,各自往各自转账,这样即使两个线程并发,也没有任何线程不安全的问题。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package com.kakawanyifan;public class Bank ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>() { @Override protected Integer initialValue () return 0 ; } }; public Integer add (Integer money) threadLocal.set(threadLocal.get() + money); return threadLocal.get(); } public Integer minus (Integer money) threadLocal.set(threadLocal.get() - money); return threadLocal.get(); } public Integer query () return threadLocal.get(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;public class Transfer implements Runnable private Bank bank; public Transfer (Bank bank) this .bank = bank; } @Override public void run () for (int i = 0 ; i < 10 ; i++) { bank.add(10 ); System.out.println(Thread.currentThread().getName() + " 余额:" + bank.query()); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.kakawanyifan;public class ThreadLocalDemo public static void main (String[] args) Bank bank = new Bank(); Transfer transfer = new Transfer(bank); Thread t1 = new Thread(transfer, "一" ); Thread t2 = new Thread(transfer, "二" ); t1.start(); t2.start(); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 一 余额:10 一 余额:20 二 余额:10 一 余额:30 二 余额:20 一 余额:40 一 余额:50 一 余额:60 二 余额:30 二 余额:40 一 余额:70 二 余额:50 二 余额:60 二 余额:70 二 余额:80 二 余额:90 一 余额:80 二 余额:100 一 余额:90 一 余额:100
源码分析
我们来看ThreadLocal的源码,主要看get方法和set方法的源码。
get方法
1 2 3 4 5 6 7 8 9 10 11 12 13 public T get () Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null ) { ThreadLocalMap.Entry e = map.getEntry(this ); if (e != null ) { @SuppressWarnings ("unchecked" ) T result = (T)e.value; return result; } } return setInitialValue(); }
set方法
1 2 3 4 5 6 7 8 public void set (T value) Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null ) map.set(this , value); else createMap(t, value); }
特别注意两行:
Thread t = Thread.currentThread()ThreadLocalMap map = getMap(t)
这两行是关键,每一个线程绑定了一个线程专属的Map,在这个Map中保存值。从而确保两个线程并发,没有任何线程不安全的问题。
原子类
接下来,我们来讨论原子类。《7.多线程 [1/2]》 也具有和原子类比较类似的效果,但是实现原理不一样。
应用
Java的java.util.concurrent.atomic包里面提供了很多可以进行原子操作的类,分为以下四类:
原子基本类型:AtomicInteger、AtomicBoolean、AtomicLong等
原子数组:AtomicIntegerArray、AtomicLongArray等
原子引用类型:AtomicReference、AtomicStampedReference等
原子属性类型:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater等
非原子性操作问题演示
非原子性的操作会引发什么问题呢?i++为例演示非原子性操作问题。i++实际上由三个操作构成。
tp1 = itp2 = tp1+1i = tp2
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.kakawanyifan;public class AtomicClass static int n = 0 ; public static void main (String[] args) throws InterruptedException int j = 0 ; while (j < 10 ) { n = 0 ; Thread t1 = new Thread() { public void run () for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } n++; } } }; Thread t2 = new Thread() { public void run () for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } n++; } } }; t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("n的最终值是:" + n); j++; } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 n的最终值是:18 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20
解释说明:i++,在实验了10次后,发现n的最终值可能不是20
原子类解决非原子性操作问题
AtomicInteger的四个常用方法:
getAndIncrement:n++
incrementAndGet:++n
decrementAndGet:–n
getAndDecrement:n–
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package com.kakawanyifan;import java.util.concurrent.atomic.AtomicInteger;public class AtomicClass static AtomicInteger n; public static void main (String[] args) throws InterruptedException int j = 0 ; while (j < 1000 ) { n = new AtomicInteger(0 ); Thread t1 = new Thread() { public void run () for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } n.getAndIncrement();; } } }; Thread t2 = new Thread() { public void run () for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } n.getAndIncrement();; } } }; t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("n的最终值是:" + n); j++; } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 【部分运行结果略】 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20
解释说明:
源码分析:CAS
上文我们说原子类的实现原理和我们上一章《7.多线程 [1/2]》 的线程安全的类不一样。
我们以getAndIncrement为例。
1 2 3 public final int getAndIncrement () return unsafe.getAndAddInt(this , valueOffset, 1 ); }
再来看看getAndAddInt都做了什么。
1 2 3 4 5 6 7 8 public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
解释一下:
this.getIntVolatile(var1, var2):var1是n的当前值,var2是地址偏移量。找到物理地址上寸的地址compareAndSwapInt(var1, var2, var5, var5 + var4):这就是所谓的。
再来看看compareAndSwapInt都做了什么。
1 public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5)
居然是一个native方法。
这就是所谓的原子性的CAS,比较并交换。
ABA问题
CAS也有问题,这个问题我们称之为ABA问题。
现象
ABA问题比较难以代码进行复现,我们举例子说明。
假设张三同学的银行卡有100块钱余额,且假定银行转账操作就是一个单纯的CAS命令,对比余额旧值是否与当前值相同,如果相同则发生扣减/增加,我们将这个指令用CAS(origin,expect)表示。于是,我们看看接下来发生了什么:
出问题了!
再来捋一下这个过程。ABA。
那么怎么办?
如果没有序列号呢?
解决
在上文我们讨论的原子类的时候,提到了AtomicStampedReference,这个就可以用来解决ABA问题。
方法名
说明
getStamp
获取时间戳
getReference
获取预期值
compareAndSet(预期值,更新值,预期时间戳,更新时间戳)
实现CAS时间戳和预期值的比对
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 package com.kakawanyifan;import java.util.concurrent.atomic.AtomicStampedReference;public class AtomicClass static AtomicStampedReference<Integer> n; public static void main (String[] args) throws InterruptedException int j = 0 ; while (j<1000 ){ n = new AtomicStampedReference<Integer>(0 ,0 ); Thread t1 = new Thread(){ public void run () for (int i=0 ; i<10 ; i++){ int stamp; Integer reference; do { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } stamp = n.getStamp(); reference = n.getReference(); } while (!n.compareAndSet(reference, reference+1 , stamp, stamp+1 )); } } }; Thread t2 = new Thread(){ public void run () for (int i=0 ; i<10 ; i++){ int stamp; Integer reference; do { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } stamp = n.getStamp(); reference = n.getReference(); } while (!n.compareAndSet(reference, reference+1 , stamp, stamp+1 )); } } }; t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("n的最终值是:" +n.getReference()); j++; } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 【部分运行结果略】 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20 n的最终值是:20
Lock类
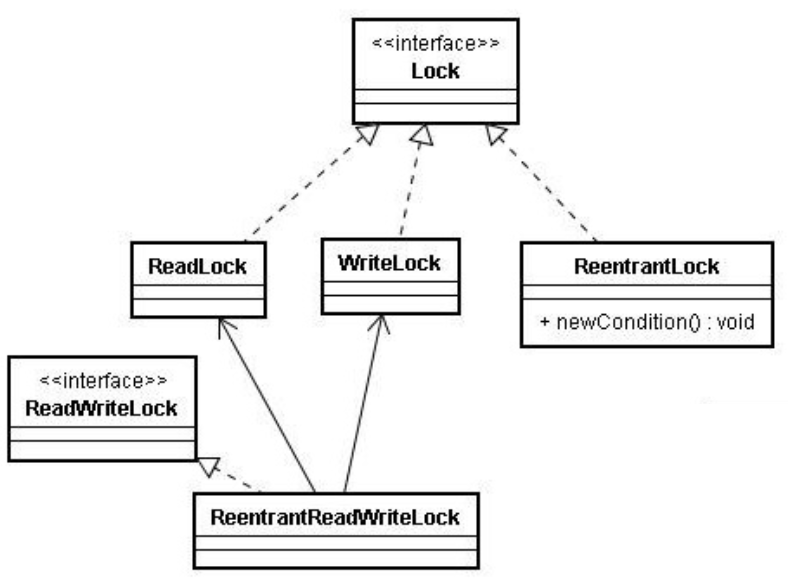
Lock接口关系
在上一章《7.多线程 [1/2]》 ,我们已经讨论过Lock类,作为一种解决线程安全问题的方法。而且,当时我们讨论了synchronized和Lock的区别,其中一个:synchronized是Java的关键字,在jvm层面上。Lock是一个类。
Lock和ReadWriteLock是两大锁的根接口。
特别注意!ReentrantReadWriteLock不是继承了ReadLock和WriteLock,而是包含了ReadLock和WriteLock。
1 2 3 4 5 6 7 public class ReentrantReadWriteLock implements ReadWriteLock , java .io .Serializable { private static final long serialVersionUID = -6992448646407690164L ; private final ReentrantReadWriteLock.ReadLock readerLock; private final ReentrantReadWriteLock.WriteLock writerLock;
在上一章,讨论synchronized和Lock的区别时候,我们还说了:synchronized,可重入,不可中断,非公平。Lock:可重入,可中断,可公平(两者皆可),类型更丰富。
可重入锁
不可重入锁,即线程请求它已经拥有的锁时会阻塞。
我们来演示一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.kakawanyifan;public class Lock private boolean isLocked = false ; public synchronized void lock () throws InterruptedException System.out.println("等待上锁" ); while (isLocked){ wait(); } isLocked = true ; System.out.println("上锁成功" ); } public synchronized void unlock () isLocked = false ; notify(); System.out.println("解锁成功" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.kakawanyifan;public class LockDemo private static Lock lock = new Lock(); public static void main (String[] args) throws InterruptedException lock.lock(); doSomething(); lock.unlock(); } public static void doSomething () throws InterruptedException lock.lock(); lock.unlock(); } }
运行结果:
解释说明:
再来看看可重入锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.kakawanyifan;import java.util.concurrent.locks.ReentrantLock;public class ReentrantLockTest public static void main (String[] args) throws InterruptedException ReentrantLock lock = new ReentrantLock(); for (int i = 1 ; i <= 3 ; i++) { lock.lock(); System.out.println("加锁 " + i); } for (int i=1 ;i<=3 ;i++){ try { System.out.println("解锁 " + i); } finally { lock.unlock(); } } } }
运行结果:
1 2 3 4 5 6 加锁 1 加锁 2 加锁 3 解锁 1 解锁 2 解锁 3
读写锁
读写锁:可以 同时读,读的时候不能写;不能 同时写,写的时候不能读。
这也是所谓的"悲观锁",读的时候不允许写,就是悲观锁,ReadWriteLock。
与之相对的还有"乐观锁",读的过程允许写入,这时候读的数据可能不一致,StampedLock。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 package com.kakawanyifan;import java.util.HashMap;import java.util.Map;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReadWriteLock;import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadWriteLockDemo private Map<String, Object> map = new HashMap<String, Object>(); private ReadWriteLock rw = new ReentrantReadWriteLock(); private Lock r = rw.readLock(); private Lock w = rw.writeLock(); public Object get (String key) r.lock(); System.out.println(Thread.currentThread().getName() + "读操作开始执行......" ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } try { return map.get(key); } finally { r.unlock(); System.out.println(Thread.currentThread().getName() + "读操作执行完成......" ); } } public void put (String key, Object value) try { w.lock(); System.out.println(Thread.currentThread().getName() + "写操作开始执行......" ); try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } map.put(key, value); } finally { w.unlock(); System.out.println(Thread.currentThread().getName() + "写操作执行完成......" ); } } public static void main (String[] args) final ReadWriteLockDemo d = new ReadWriteLockDemo(); d.put("key1" , "value1" ); new Thread(new Runnable() { public void run () d.get("key1" ); } }).start(); new Thread(new Runnable() { public void run () d.get("key1" ); } }).start(); new Thread(new Runnable() { public void run () d.get("key1" ); } }).start(); } }
运行结果:
1 2 3 4 5 6 7 8 main写操作开始执行...... main写操作执行完成...... Thread-0读操作开始执行...... Thread-1读操作开始执行...... Thread-2读操作开始执行...... Thread-0读操作执行完成...... Thread-2读操作执行完成...... Thread-1读操作执行完成......
公平锁
公平锁是Lock锁自带的功能,我们用Lock锁来演示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.kakawanyifan;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;public class SellTicket implements Runnable private int tickets = 100 ; private Lock lock = new ReentrantLock(true ); @Override public void run () while (true ) { try { lock.lock(); if (tickets > 0 ) { try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "正在出售第" + tickets + "张票" ); tickets--; } } finally { lock.unlock(); } } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 窗口1正在出售第100张票 窗口2正在出售第99张票 窗口3正在出售第98张票 窗口1正在出售第97张票 窗口2正在出售第96张票 窗口3正在出售第95张票 窗口1正在出售第94张票 窗口2正在出售第93张票 窗口3正在出售第92张票 窗口1正在出售第91张票 窗口2正在出售第90张票 【部分运行结果略】 窗口2正在出售第9张票 窗口3正在出售第8张票 窗口1正在出售第7张票 窗口2正在出售第6张票 窗口3正在出售第5张票 窗口1正在出售第4张票 窗口2正在出售第3张票 窗口3正在出售第2张票 窗口1正在出售第1张票
解释说明:
Volatile关键字
概述
在上文还提到了,多线程的一个特性,可见性。Volatile关键字就是用来实现可见性的。
其实,除了可见性,这个关键字还有一个含义,不允许进行指令重排。
我们解释一下什么是指令重排。
1 2 3 4 int i; i = 1; i = 2; i = 3;
然后不会执行i=1和1=2。
应用
使用volatile必须满足以下两个条件:
对变量的写操作不依赖于当前值。
该变量没有包含在具有其他变量的不变式中。
因此,常见应用场景如下:
状态量标记
双重校验
状态量标记
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.kakawanyifan;import java.util.Scanner;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.Executors;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class VolatileDemo public static volatile boolean flag = true ; public static void main (String[] args) new Thread(()->{ Scanner scanner = new Scanner(System.in); while (scanner.hasNext()){ String s = scanner.nextLine(); if ("stop" .equals(s)){ flag = false ; break ; } } }).start(); ThreadPoolExecutor executor = new ThreadPoolExecutor( 2 , 5 , 10 , TimeUnit.SECONDS, new ArrayBlockingQueue<>(10 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy ()); for (int i = 0 ; i < 20 ; i++) { try { executor.execute(new MyRunnable("第" +(i+1 )+"号任务" )); } catch (Throwable e) { e.printStackTrace(); System.out.println("丢弃任务: " + (i+1 ) ); } } } static class MyRunnable implements Runnable private String name; public MyRunnable (String name) this .name = name; } @Override public void run () System.out.println(Thread.currentThread().getName() +"==>" +name); while (flag){ } } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 pool-1-thread-1==>第1号任务 pool-1-thread-3==>第13号任务 pool-1-thread-2==>第2号任务 pool-1-thread-5==>第15号任务 pool-1-thread-4==>第14号任务 丢弃任务: 16 丢弃任务: 17 丢弃任务: 18 丢弃任务: 19 丢弃任务: 20 java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@7b23ec81 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@3feba861 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@6f496d9f rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@10f87f48 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@2f4d3709 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) stop pool-1-thread-1==>第4号任务 pool-1-thread-2==>第3号任务 pool-1-thread-2==>第8号任务 pool-1-thread-2==>第9号任务 pool-1-thread-2==>第10号任务 pool-1-thread-2==>第11号任务 pool-1-thread-2==>第12号任务 pool-1-thread-1==>第7号任务 pool-1-thread-5==>第5号任务 pool-1-thread-3==>第6号任务
这就是作为状态量标记的应用。
特别的,我们可以仔细看看运行结果。这个运行结果很有意思,我们会在本章讨论线程池的时候进行讨论。
双重校验
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Singleton private volatile static Singleton instance = null ; private Singleton () } public static Singleton getInstance () if (instance==null ) { synchronized (Singleton.class ) { if (instance==null ) instance = new Singleton(); } } return instance; } }
解释说明:if(instance==null)。
1 2 3 4 5 6 7 8 public static Singleton getInstance () if (instance==null ) { synchronized (Singleton.class ) { instance = new Singleton(); } } return instance; }
线程一进入到getInstance()这个方法,首先判断if(instance==null),不是空,所以进入synchronized (Singleton.class),上锁。然后这时候线程二也进入到了getInstance(),也判断if(instance==null),也进入到synchronized (Singleton.class),但这时候只能在外面等着。然后线程一继续,instance = new Singleton();,然后释放锁。线程二获得锁,然后又执行instance = new Singleton();。这时候就出问题了。
并发容器
常见的并发容器
在上一章我们讨论过线程安全的类,其特点是都用synchronized进行同步,也被称为同步容器。这样保证了线程的安全性,但代价就是严重降低了并发性能,当多个线程竞争容器时,吞吐量严重降低。
并发容器如下:
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
ConcurrentSkipListMap
ConcurrentSkipListSet
ConcurrentLinkedQueue
LinkedBlockingQueue、ArrayBlockingQueue、PriorityBlockingQueue
LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列
ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列
PriorityBlockingQueue:按优先级排序的队列
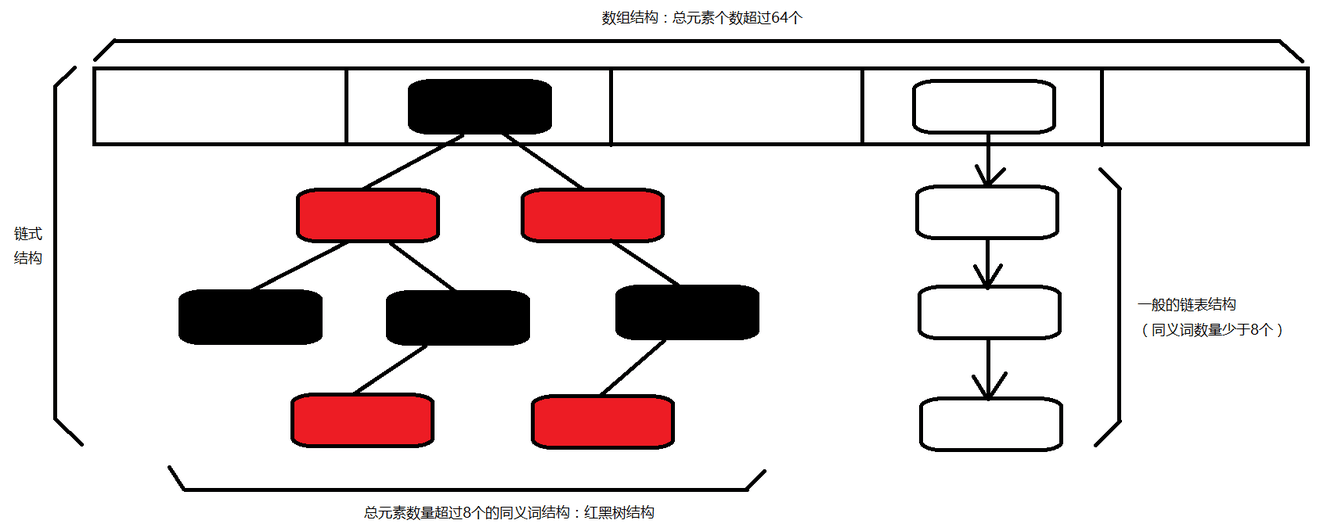
ConcurrentHashMap源码分析
接下来以ConcurrentHashMap为例,讨论并发容器是怎么做到线程安全的。
首先我们要知道的是HashMap的数据结构,这我们在《算法入门经典(Java与Python描述):7.哈希表》 有过讨论。
在知道了结构之后,我们来看源码。
1 2 3 public V put (K key, V value) return putVal(key, value, false ); }
调用了putVal,再来看看putVal的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 final V putVal (K key, V value, boolean onlyIfAbsent) if (key == null || value == null ) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node<K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node<K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; }
有两处需要特别注意。casTabAtsynchronized(f)
casTabAt的作用是放数组中的元素,调用了我们之前讨论过的CAS方法。
1 2 3 4 static final <K,V> boolean casTabAt (Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) return U.compareAndSwapObject(tab, ((long )i << ASHIFT) + ABASE, c, v); }
synchronized(f),在放链表数据的时候,加锁,f是头节点。
有了这两个,就可以做到线程安全吗?《算法入门经典(Java与Python描述):7.哈希表》 讨论过,还有动态扩容、数据迁移和初始化等。
那么,这些线程是怎么做到线程安全的呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0 ) { if ((sc = sizeCtl) < 0 ) Thread.yield(); else if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if ((tab = table) == null || tab.length == 0 ) { int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY; Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } break ; } } return tab; }
注意看,if ((sc = sizeCtl) < 0),把sizeCtl赋值给sc,然后如果sc小于0,就放弃CPU的执行权。否则的话呢,调用if (U.compareAndSwapInt(this, SIZECTL, sc, -1))方法,给sizeCtl赋值-1,锁住。利用这种方法做到线程安全。
再来看动态扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private final void tryPresize (int size) int c = (size >= (MAXIMUM_CAPACITY >>> 1 )) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1 ) + 1 ); int sc; while ((sc = sizeCtl) >= 0 ) { Node<K,V>[] tab = table; int n; if (tab == null || (n = tab.length) == 0 ) { n = (sc > c) ? sc : c; if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { 【部分代码略】 } } else if (c <= sc || n >= MAXIMUM_CAPACITY) break ; else if (tab == table) { int rs = resizeStamp(n); if (sc < 0 ) { 【部分代码略】 if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); } } }
逻辑类似,注意两行:while ((sc = sizeCtl) >= 0)if (U.compareAndSwapInt(this, SIZECTL, sc, -1))
数据迁移方法是transfer,逻辑也是类似的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { Node<K,V>[] nextTab; int sc; if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null ) { int rs = resizeStamp(tab.length); while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) { transfer(tab, nextTab); break ; } } return nextTab; } return table; }
线程池
接下来,我们讨论线程池。在上一章《7.多线程 [1/2]》 ,在讨论创建线程的方法的时候,有一种方法就是线程池。
多线程的缺点
多线程有什么缺点?《7.多线程 [1/2]》 ,讨论线程调度的时候,我们讲过,CPU有一个一个细小的时间片,线程需要去抢占时间片,也就是说CPU需要在多线程之间不断的切换。这个非常消耗资源。《7.多线程 [1/2]》 ,我们讨论过线程的生命周期。一共有新建、就绪、运行、阻塞和销毁几个状态,其中新建和销毁也非常消耗资源。
到这里,就可以解释我们在之前章节说的多线程不一定快了,原因就是这两点。
线程创建和销毁都非常耗时并消耗资源。
线程之间的切换也会非常耗时并消耗资源。
线程池介绍
正因为上述缺点,所以有了线程池这种东西。
可以通过有限的几个固定线程为大量的操作服务,减少了创建和销毁线程所需的时间,从而提高效率。
在开发过程中,合理地使用线程池能够带来3个好处。
降低资源消耗 。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。提高响应速度 。当任务到达时,任务可以不需要等到线程创建就能立即执行。提高线程的可管理性 。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
线程数量选择
注意,在上文我们一直说合理的使用线程,合理的使用线程。
CPU密集型运算
假如是CPU密集型运算
线程数 = CPU核数 + 1 \text{线程数} = \text{CPU核数} + 1
线程数 = CPU 核数 + 1
这样能够实现最优的CPU利用率。+ 1 +1 + 1
I/O密集型运算
假如是I/O密集型运算
经验公式如下
线程数 = 核数 ∗ 期望CPU利用率 ∗ 总时间 CPU计算时间 \text{线程数} = \text{核数} * \text{期望CPU利用率} * \frac{\text{总时间}}{\text{CPU计算时间}}
线程数 = 核数 ∗ 期望 CPU 利用率 ∗ CPU 计算时间 总时间
总时间 = CPU计算时间 + 等待时间 \text{总时间} = \text{CPU计算时间} + \text{等待时间} 总时间 = CPU 计算时间 + 等待时间
例如4核CPU计算时间是50%,其它等待时间是50%,期望CPU被100%利用,则有
4 ∗ 100 % ∗ 100 % 50 % = 8 4 * 100\% * \frac{100\%}{50\%} = 8
4 ∗ 1 0 0 % ∗ 5 0 % 1 0 0 % = 8
例如4核CPU计算时间是10%,其它等待时间是90%,期望CPU被100%利用,套用公式
4 ∗ 100 % ∗ 100 % 10 % = 40 4 * 100\% * \frac{100\%}{10\%} = 40
4 ∗ 1 0 0 % ∗ 1 0 % 1 0 0 % = 4 0
线程池的工作过程
在上文讨论volatile关键字的时候,我们举了一个用作状态量标记的例子,并且我们说运行结果很有意思,会在本章讨论线程池的时候进行讨论。就在这里。
为了方便大家看,我们把上述的代码搬过来。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.kakawanyifan;import java.util.Scanner;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.Executors;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class VolatileDemo public static volatile boolean flag = true ; public static void main (String[] args) new Thread(()->{ Scanner scanner = new Scanner(System.in); while (scanner.hasNext()){ String s = scanner.nextLine(); if ("stop" .equals(s)){ flag = false ; break ; } } }).start(); ThreadPoolExecutor executor = new ThreadPoolExecutor( 2 , 5 , 10 , TimeUnit.SECONDS, new ArrayBlockingQueue<>(10 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy ()); for (int i = 0 ; i < 20 ; i++) { try { executor.execute(new MyRunnable("第" +(i+1 )+"号任务" )); } catch (Throwable e) { e.printStackTrace(); System.out.println("丢弃任务: " + (i+1 ) ); } } } static class MyRunnable implements Runnable private String name; public MyRunnable (String name) this .name = name; } @Override public void run () System.out.println(Thread.currentThread().getName() +"==>" +name); while (flag){ } } } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 pool-1-thread-1==>第1号任务 pool-1-thread-2==>第2号任务 pool-1-thread-3==>第13号任务 pool-1-thread-4==>第14号任务 pool-1-thread-5==>第15号任务 丢弃任务: 16 丢弃任务: 17 丢弃任务: 18 丢弃任务: 19 丢弃任务: 20 java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@7b23ec81 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@3feba861 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@6f496d9f rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@10f87f48 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) java.util.concurrent.RejectedExecutionException: Task com.kakawanyifan.VolatileDemo$MyRunnable@2f4d3709 rejected from java.util.concurrent.ThreadPoolExecutor@6acbcfc0[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.kakawanyifan.VolatileDemo.main(VolatileDemo.java:37) stop pool-1-thread-1==>第4号任务 pool-1-thread-2==>第3号任务 pool-1-thread-2==>第8号任务 pool-1-thread-2==>第9号任务 pool-1-thread-2==>第10号任务 pool-1-thread-2==>第11号任务 pool-1-thread-2==>第12号任务 pool-1-thread-1==>第7号任务 pool-1-thread-5==>第5号任务 pool-1-thread-3==>第6号任务
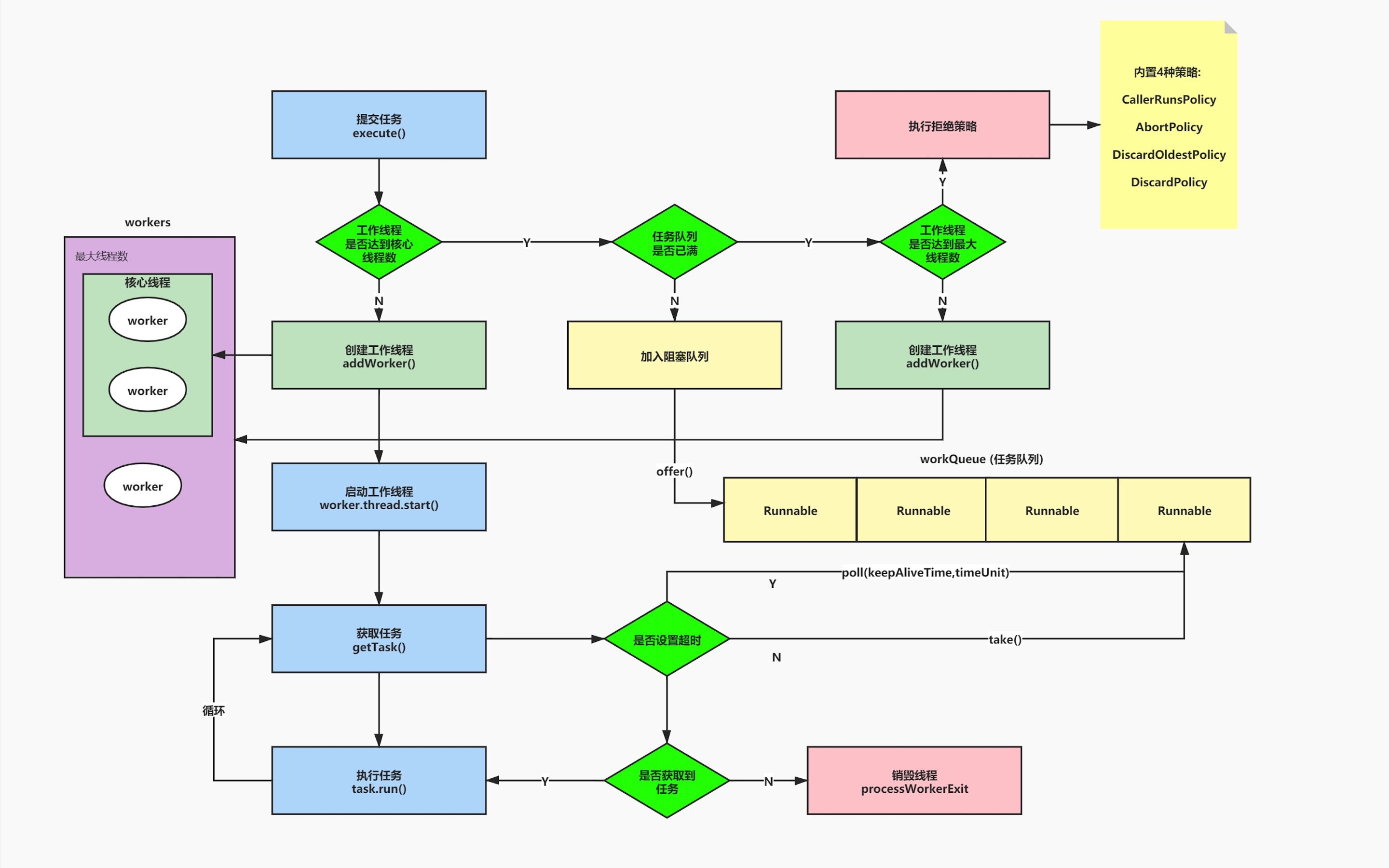
线程池在刚创建的时候,里面一个线程也没有。
现在要执行第1号任务了,线程池里没有线程,那谁来执行?第一个判断:判断核心线程数pool-1-thread-1==>第1号任务,第一个线程执行第1号任务。
然后我们执行第2号任务,同样进入第一个判断,所以,pool-1-thread-2==>第2号任务,第二个线程执行第2号任务。
再执行第3号任务,判断正在运行的工作线程是否小于设置的核心线程数,不小于。所以,进入下一个判断。第二个判断:判断任务队列
再执行第13号任务,判断当前线程池的任务队列是否已满,满了。所以,进入下一个判断。第三个判断:判断最大线程数pool-1-thread-3==>第13号任务,第三个线程执行第13号任务。pool-1-thread-4==>第14号任务,第四个线程执行第14号任务;pool-1-thread-5==>第15号任务,第五个线程执行第15号任务。
再执行第16号任务,再创建临时线程。不,最大线程数是5,核心线程是2,临时线程是3。所以,进入下一个判断。第四个判断:判断饱和拒绝策略new ThreadPoolExecutor.AbortPolicy (),丢弃后续的任务,并抛出异常。丢弃任务: 16、丢弃任务: 17、丢弃任务: 18、丢弃任务: 19、丢弃任务: 20。
然后我们在控制台输入了stop,所以while循环不再是死循环了。
线程池中线程的销毁
通过上述的讨论,我们已经知道了线程池的工作过程。《7.多线程 [1/2]》 ,我们讨论过。
executorService.shutdown();
executorService.shutdownNow();
还有吗?
示例代码:
1 2 3 4 5 6 7 8 9 ThreadPoolExecutor executor = new ThreadPoolExecutor( 2 , 5 , 10 , TimeUnit.SECONDS, new ArrayBlockingQueue<>(10 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy ()); executor.allowCoreThreadTimeOut(true );
注意:executor.allowCoreThreadTimeOut(true),如果10秒内都没有新的任务的话,都会被销毁。
线程池的饱和拒绝策略
在上文的例子中,如果线程池中工作线程数量已经达到最大线程,并且任务队列已满。这时候就会根据我们设置的饱和拒绝策略进行处理。
CallerRunsPolicy: 不丢弃任务,让调用线程池的线程帮忙执行任务。
AbortPolicy: 丢弃后续的任务,并抛出异常【默认的是这种】。
DiscardOldestPolicy: 丢弃任务队列中 存放最久的任务,不抛异常。
DiscardPolicy: 丢弃后续任务,不抛异常。
特别的,我们可以看看这四种策略的源代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static class CallerRunsPolicy implements RejectedExecutionHandler 【部分代码略】 } public static class AbortPolicy implements RejectedExecutionHandler 【部分代码略】 } public static class DiscardPolicy implements RejectedExecutionHandler 【部分代码略】 } public static class DiscardOldestPolicy implements RejectedExecutionHandler 【部分代码略】 }
都实现了RejectedExecutionHandler这个接口。
这里比较难理解的是,CallerRunsPolicy,不丢弃任务,让调用线程池的线程帮忙执行任务。
示例代码:
1 2 3 4 5 6 7 8 9 ThreadPoolExecutor executor = new ThreadPoolExecutor( 2 , 5 , 10 , TimeUnit.SECONDS, new ArrayBlockingQueue<>(10 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy ()); executor.allowCoreThreadTimeOut(true );
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pool-1-thread-1==>第1号任务 pool-1-thread-3==>第13号任务 pool-1-thread-2==>第2号任务 pool-1-thread-4==>第14号任务 main==>第16号任务 pool-1-thread-5==>第15号任务 stop main==>第17号任务 pool-1-thread-3==>第4号任务 pool-1-thread-4==>第3号任务 pool-1-thread-2==>第8号任务 pool-1-thread-3==>第7号任务 pool-1-thread-5==>第6号任务 pool-1-thread-1==>第5号任务 pool-1-thread-5==>第12号任务 pool-1-thread-3==>第11号任务 pool-1-thread-2==>第10号任务 pool-1-thread-4==>第9号任务 pool-1-thread-3==>第20号任务 pool-1-thread-5==>第19号任务 pool-1-thread-1==>第18号任务
线程池的核心参数
在上文我们已经用了ThreadPoolExecutor这个类,现在,我们回过头,再来系统的讨论这个类。
核心构造器参数
组件
含义
int corePoolSize
核心线程池的大小
int maximumPoolSize
最大线程池的大小
BlockingQueue workQueue
用来暂时保存任务的工作队列
RejectedExecutionHandler
当ThreadPoolExecutor已经关闭或ThreadPoolExecutor已经饱和时(达到了最大线程池的大小且工作队列已满),execute()方法将要调用的Handler
long keepAliveTime,
表示空闲线程的存活时间。
TimeUnit
表示keepAliveTime的单位。
ThreadFactory threadFactory
指定创建线程的线程工厂
线程池的三种队列
上述参数其实我们刚刚在讨论都讨论过了,除了队列。
SynchronousQueue LinkedBlockingQueue ArrayBlockingQueue
线程池工具类
在上一章《7.多线程 [1/2]》 ,讨论线程创建的时候,其实我们用的是线程池工具类,Executors。现在我们讨论一下。
Executors的四种线程
为了方便的创建线程池,Java中又定义了Executors类,Eexcutors类提供了四个创建线程池的方法,分别如下
newCachedThreadPool
newFixedThreadPool
newSingleThreadExecutor
newScheduledThreadPool
特别注意!
newCachedThreadPool
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class CachedThreadPoolDemo public static void main (String[] args) ExecutorService es = Executors.newCachedThreadPool(); for (int i = 0 ; i < 10 ; i++) { es.execute(()->{ for (int j = 0 ; j < 10 ; j++) { try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + ":" + j); } }); } es.shutdown(); } }
运行结果:
1 2 3 4 5 6 7 8 9 pool-1-thread-1:0 pool-1-thread-6:0 pool-1-thread-10:0 【部分运行结果略】 pool-1-thread-4:9 pool-1-thread-8:9 pool-1-thread-1:9
我们来看看源代码newCachedThreadPool的源代码。
1 2 3 4 5 public static ExecutorService newCachedThreadPool () return new ThreadPoolExecutor(0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
解释说明:
newFixedThreadPool
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package com.kakawanyifan;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class FixedThreadPoolDemo public static void main (String[] args) ExecutorService es = Executors.newFixedThreadPool(2 ); for (int i = 0 ; i < 10 ; i++) { es.execute(()->{ try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } for (int j = 0 ; j < 10 ; j++) { System.out.println(Thread.currentThread().getName() + ":" + j); } }); } es.shutdown(); } }
运行结果:
1 2 3 4 5 6 7 8 9 pool-1-thread-2:0 pool-1-thread-2:1 pool-1-thread-2:2 【部分运行结果略】 pool-1-thread-2:9 pool-1-thread-1:8 pool-1-thread-1:9
我们来看看newFixedThreadPool的源代码。
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
解释说明:
newSingleThreadExecutor
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class SingleThreadExecutorDemo public static void main (String[] args) ExecutorService es = Executors.newSingleThreadExecutor(); for (int i = 0 ; i < 10 ; i++) { es.execute(()->{ try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } for (int j = 0 ; j < 10 ; j++) { System.out.println(Thread.currentThread().getName() + ":" + j); } }); } es.shutdown(); } }
运行结果:
1 2 3 4 5 6 7 8 9 pool-1-thread-1:0 pool-1-thread-1:1 pool-1-thread-1:2 【部分运行结果略】 pool-1-thread-1:7 pool-1-thread-1:8 pool-1-thread-1:9
我们来看看newSingleThreadExecutor的源代码。
1 2 3 4 5 6 public static ExecutorService newSingleThreadExecutor () return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
解释说明:
newScheduleThreadPool
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import java.time.Instant;import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ScheduledFuture;import java.util.concurrent.TimeUnit;public class ScheduledThreadPool public static void main (String[] args) throws InterruptedException ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(5 ); ScheduledFuture<?> schedule = newScheduledThreadPool.schedule(() -> { System.out.println(Instant.now() + " 延迟执行任务" ); }, 3 , TimeUnit.SECONDS); ScheduledFuture<?> scheduledFuture = newScheduledThreadPool.scheduleAtFixedRate(() -> { System.out.println(Instant.now() + " 周期性执行任务" ); }, 0 , 3 , TimeUnit.SECONDS); Thread.sleep(10000 ); scheduledFuture.cancel(false ); } }
运行结果:
1 2 3 4 5 2021-09-16T14:32:08.253Z 周期性执行任务 2021-09-16T14:32:11.252Z 延迟执行任务 2021-09-16T14:32:11.252Z 周期性执行任务 2021-09-16T14:32:14.252Z 周期性执行任务 2021-09-16T14:32:17.255Z 周期性执行任务
scheduleAtFixedRate,是以上一个任务开始的时间计时,period时间过去后,检测上一个任务是否执行完毕,如果上一个任务执行完毕,则当前任务立即执行,如果上一个任务没有执行完毕,则需要等上一个任务执行完毕后立即执行。
scheduleWithFixedDelay,是以上一个任务结束时开始计时,period时间过去后,立即执行。
线程池中线程的复用
最后一个话题,线程池中的线程是如何实现复用的?java.util.concurrent.ThreadPoolExecutor进行更深入的分析。
创建线程
我们从这段代码开始。
1 2 3 4 private final HashSet<Worker> workers = new HashSet<Worker>();
所有的"线程"都被放在了这个HashSet中。
再来看看Worker内部的结构怎么用的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private final class Worker extends AbstractQueuedSynchronizer implements Runnable 【部分代码略】 final Thread thread; Runnable firstTask; 【部分代码略】 Worker(Runnable firstTask) { setState(-1 ); this .firstTask = firstTask; this .thread = getThreadFactory().newThread(this ); } 【部分代码略】 }
Worker实现了Runnable接口,还有两个成员变量,一个是Thread thread,一个是Runnable firstTask?this.firstTask = firstTask:传入worker第一次要执行的任务。this.thread = getThreadFactory().newThread(this):使用工厂对象创建线程, 并把worker本身传入。
所以,这是第一个任务来了,就创建线程。
run方法
那么,线程是怎么执行的呢?
1 2 3 public void run () runWorker(this ); }
看看runWorker都做了啥。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 final void runWorker (Worker w) Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null ; w.unlock(); boolean completedAbruptly = true ; try { while (task != null || (task = getTask()) != null ) { w.lock(); if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); Throwable thrown = null ; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); } } finally { task = null ; w.completedTasks++; w.unlock(); } } completedAbruptly = false ; } finally { processWorkerExit(w, completedAbruptly); } }
注意,这里就有文章了。有一个while循环,只要还有任务,while循环就不会停止。task = getTask(),获取任务?
获取任务
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private Runnable getTask () boolean timedOut = false ; for (;;) { int c = ctl.get(); int rs = runStateOf(c); if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { decrementWorkerCount(); return null ; } int wc = workerCountOf(c); boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null ; continue ; } try { Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null ) return r; timedOut = true ; } catch (InterruptedException retry) { timedOut = false ; } } }
用for的死循环来获取任务?然后有一个timeOut。
1 2 3 Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
timed怎来的?
1 boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
如果允许核心线程TimeOut或者线程数大于了核心线程数,timed即使true,就会通过workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)方法获取r。
小结
每一个线程都是一个worker对象,当把工作者启动之后,工作者会执行一个while循环,不断的调用getTask()方法,去任务队列workQueue里获取任务,只要能得到任务,getTask()就会有返回值,while循环就会不断运行。如果是临时线程,用poll()方法,在指定的时间没有获取到任务,得到的就是null。如果是核心线程,用的是take,这个是阻塞队列里的方法,会一直阻塞到这里。特别的,如果核心线程设置了超时时间,也是poll。
线程池最佳实践
正确声明线程池线程池
必须手动通过ThreadPoolExecutor的构造函数来声明,避免使用Executors类创建线程池。
Executors返回线程池对象的弊端如下:
FixedThreadPool和SingleThreadExecutor:使用的是有界阻塞队列LinkedBlockingQueue,任务队列的默认长度和最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
CachedThreadPool:使用的是同步队列SynchronousQueue,允许创建的线程数量为Integer.MAX_VALUE,可能会创建大量线程,从而导致OOM。
ScheduledThreadPool和SingleThreadScheduledExecutor:使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
除了避免OOM的原因之外,不推荐使用Executors提供的两种快捷的线程池的原因还有:
实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
监测线程池运行状态
我们可以通过一些手段来检测线程池的运行状态比如SpringBoot中的Actuator组件。
建议不同类别的业务用不同的线程池
一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务。
别忘记给线程池命名
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
给线程池里的线程命名通常有下面两种方式:
利用guava的ThreadFactoryBuilder1 2 3 4 ThreadFactory threadFactory = new ThreadFactoryBuilder() .setNameFormat(threadNamePrefix + "-%d" ) .setDaemon(true ).build(); ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
自己实现ThreadFactory:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.concurrent.ThreadFactory;import java.util.concurrent.atomic.AtomicInteger;public final class NamingThreadFactory implements ThreadFactory private final AtomicInteger threadNum = new AtomicInteger(); private final String name; public NamingThreadFactory (String name) this .name = name; } @Override public Thread newThread (Runnable r) Thread t = new Thread(r); t.setName(name + " [#" + threadNum.incrementAndGet() + "]" ); return t; } }
正确配置线程池参数
适用面比较广的公式
CPU密集型任务:N+1
I/O密集型任务:2N
美团的建议
美团技术团队在《Java 线程池实现原理及其在美团业务中的实践》这篇文章中介绍到对线程池参数实现可自定义配置的思路和方法。
corePoolSize:核心线程数线程数定义了最小可以同时运行的线程数量。
maximumPoolSize:当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
别忘记关闭线程池
当线程池不再需要使用时,应该显式地关闭线程池,释放线程资源。
shutdown():关闭线程池,线程池的状态变为SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。shutdownNow():关闭线程池,线程池的状态变为STOP。线程池会终止当前正在运行的任务,停止处理排队的任务并返回正在等待执行的List。
注意:调用完shutdownNow和shuwdown方法后,并不代表线程池已经完成关闭操作,只是异步的通知线程池进行关闭处理。
线程池尽量不要放耗时任务
线程池本身的目的是为了提高任务执行效率,避免因频繁创建和销毁线程而带来的性能开销。CompletableFuture等其他异步操作的方式来处理,以避免阻塞线程池中的线程。