简介
Quartz:任务调度框架。http://www.quartz-scheduler.org
所谓的任务调度,其实就是我们想在什么时候做什么事情?
我们想做的事情就是Job(任务)。
我们期望的时候就是Trigger(触发器)。
最后还需要一个Scheduler(调度器),将其整合起来。
案例
新建一个最简单的Maven工程,引入Quartz的Jar包。
1 2 3 4 5 <dependency > <groupId > org.quartz-scheduler</groupId > <artifactId > quartz</artifactId > <version > 2.3.2</version > </dependency >
有些资料会说还需要引入quartz-jobs。
1 2 3 4 5 <dependency > <groupId > org.quartz-scheduler</groupId > <artifactId > quartz-jobs</artifactId > <version > 2.3.2</version > </dependency >
实际上,这个包不一定需要引用。
创建HelloJob任务类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
创建主方法的类,在该类中定义Trigger(触发器)以及Scheduler(调度器)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ). withIdentity("job1", "group1"). build(); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
运行任务调度类,运行结果:
1 2 3 4 5 2022-12-10T08:24:57.480 2022-12-10T08:25:02.385 2022-12-10T08:25:07.384 【部分运行结果略】
解释说明:
每一个Job必须实现org.quartz.job接口,并实现execute()方法。
JobDetail,定义任务实例。在上文,JobDetail实例是通过JobBuilder创建的。JobBuilder,用于创建一个任务实例。TriggerBuilder,用于创建触发器实例。scheduler的方法除了start()、shutdown(),还有standby()(暂停操作)。
除了上文的创建scheduler的方法,我们还可以通过如下的方法创建:
1 2 SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler();
上文的方法属于静态工厂,这种方法属于实例工厂。《15.Spring Framework [1/2]》 有过讨论。
生命周期
每次调度器执行Job时,在调用execute方法前都会创建一个新的Job实例,当调用完成后,关联的Job对象实例会被释放,释放的实例会被垃圾回收机制回收。
我们可以验证一下,修改HelloJob类,新增构造方法,并在构造方法中打印HelloJob Constructor。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import java.time.LocalDateTime;public class HelloJob implements Job public HelloJob () System.out.println("HelloJob Constructor" ); } @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
运行结果:
1 2 3 4 5 6 7 8 HelloJob Constructor : 2022-12-10T21:20:09.829 2022-12-10T21:20:09.831 HelloJob Constructor : 2022-12-10T21:20:14.776 2022-12-10T21:20:14.776 HelloJob Constructor : 2022-12-10T21:20:19.780 2022-12-10T21:20:19.780 【部分运行结果略】
特别的,如果我们创建一个有参构造方法,并且我们不创建无参构造方法呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.quartz.PersistJobDataAfterExecution;import java.time.LocalDateTime;@PersistJobDataAfterExecution public class HelloJob implements Job private String k1; public HelloJob (String k1) System.out.println("HelloJob Constructor" ); this .k1 = k1; } @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
运行结果:
程序不会运行。
所以,我们在《2.面向对象》 说:“无论是否使用,都手工书写无参数构造方法”。
JobExecutionContext
当Scheduler调用一个Job,就会将JobExecutionContext传递给Job的execute()方法。
获取Job的明细数据
Job能通过JobExecutionContext对象访问到Quartz运行时候的环境以及Job本身的明细数据。例如:Group、Name、Class、当前任务执行时间(.getFireTime())、下一次任务执行时间(.getNextFireTime())等。
获取Group、Name、Class,示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan.job;import org.quartz.*;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException JobKey jobKey = jobExecutionContext.getJobDetail().getKey(); System.out.println("jobKey.getGroup() : " + jobKey.getGroup()); System.out.println("jobKey.getName() : " + jobKey.getName()); System.out.println("jobKey.getClass() : " + jobKey.getClass()); TriggerKey triggerKey = jobExecutionContext.getTrigger().getKey(); System.out.println("triggerKey.getGroup() : " + triggerKey.getGroup()); System.out.println("triggerKey.getName() : " + triggerKey.getName()); System.out.println("triggerKey.getClass() : " + triggerKey.getClass()); System.out.println(LocalDateTime.now()); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 jobKey.getGroup() : group1 jobKey.getName() : job1 jobKey.getClass() : class org.quartz.JobKey triggerKey.getGroup() : group1 triggerKey.getName() : trigger1 triggerKey.getClass() : class org.quartz.TriggerKey 2022-12-10T21:32:20.901 【部分运行结果略】
获取当前任务执行时间(.getFireTime())、下一次任务执行时间(.getNextFireTime()),示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.kakawanyifan.job;import org.quartz.*;import java.time.LocalDateTime;import java.util.Date;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException Date fireTime = jobExecutionContext.getFireTime(); System.out.println("当前任务执行时间:" + fireTime); Date nextFireTime = jobExecutionContext.getNextFireTime(); System.out.println("下一次任务执行时间:" + nextFireTime); System.out.println(LocalDateTime.now()); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 当前任务执行时间:Tue Jan 10 21:55:57 CST 2023 下一次任务执行时间:Tue Jan 10 21:56:02 CST 2023 2022-12-10T21:55:57.939 当前任务执行时间:Tue Jan 10 21:56:02 CST 2023 下一次任务执行时间:Tue Jan 10 21:56:07 CST 2023 2022-12-10T21:56:02.880 当前任务执行时间:Tue Jan 10 21:56:07 CST 2023 下一次任务执行时间:Tue Jan 10 21:56:12 CST 2023 2022-12-10T21:56:07.880 【部分运行结果略】
传递参数
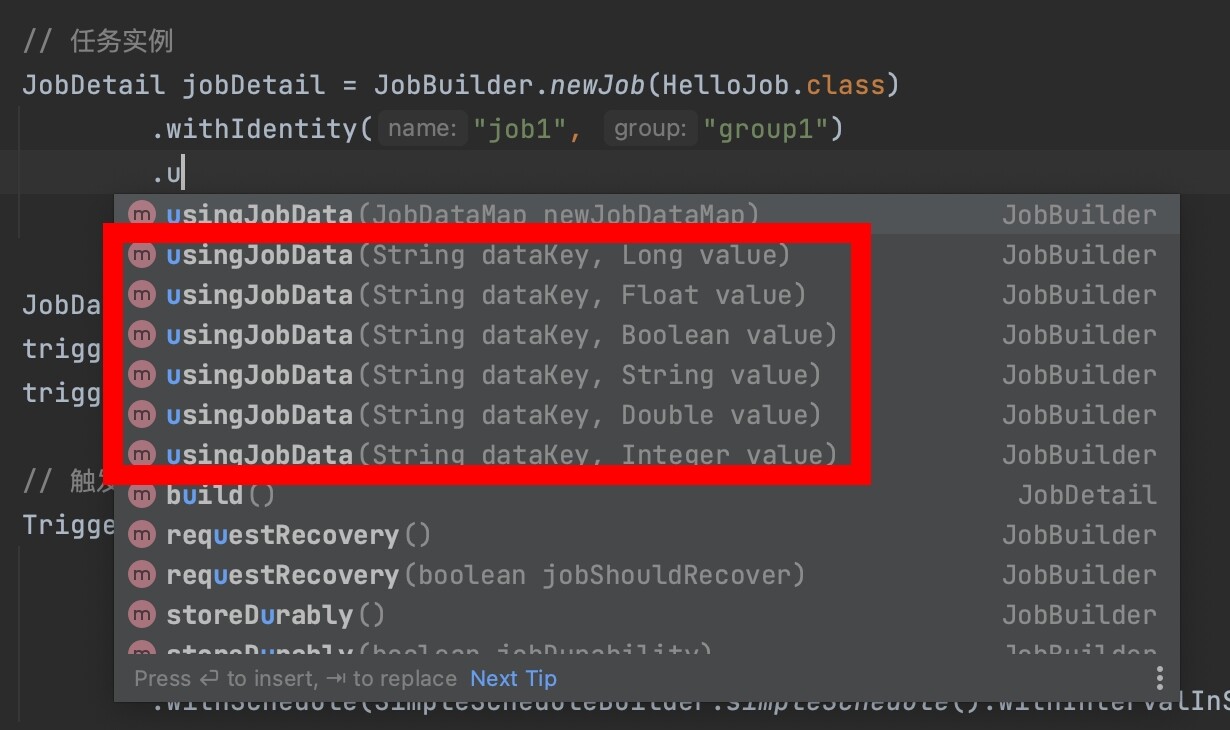
可以在定义JobDetail实例时,通过.usingJobData(jobDataMap)进行参数传递。
可以在Job中通过jobExecutionContext.getJobDetail().getJobDataMap()解析参数。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class App public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDataMap jobDataMap = new JobDataMap(); jobDataMap.put("jobK1" ,"jjj-1" ); jobDataMap.put("jobK2" ,2 ); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") .usingJobData(jobDataMap) .build(); JobDataMap triggerDataMap = new JobDataMap(); triggerDataMap.put("triggerK1" ,"ttt-1" ); triggerDataMap.put("triggerK2" ,2.0 ); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .usingJobData(triggerDataMap) .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.kakawanyifan.job;import org.quartz.*;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException JobDataMap jobDataMap = jobExecutionContext.getJobDetail().getJobDataMap(); for (String jobDataMapKey: jobDataMap.keySet()) { System.out.println(jobDataMapKey + " : " + jobDataMap.get(jobDataMapKey)); } JobDataMap triggerDataMap = jobExecutionContext.getTrigger().getJobDataMap(); for (String triggerDataMapKey: triggerDataMap.keySet()) { System.out.println(triggerDataMapKey + " : " + triggerDataMap.get(triggerDataMapKey)); } System.out.println(LocalDateTime.now()); } }
运行结果:
1 2 3 4 5 6 7 8 jobK2 : 2 jobK1 : jjj-1 triggerK1 : ttt-1 triggerK2 : 2.0 2022-12-10T21:42:37.001 【部分运行结果略】
除了上文的getJobDataMap,也可以采取如下的方式传递参数,解析方法不变。
Setter方法
如果我们在Job类中添加成员变量及其Setter方法对应JobDataMap的键值,Quartz默认的JobFactory实现类在初始化JobDetail对象时会自动地调用这些Setter方法。
这样,解析参数会更方便一些,因为这些参数都作为了Job类的成员变量。
例子
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import java.time.LocalDateTime;public class HelloJob implements Job private String k1; private Integer k2; public void setK1 (String k1) System.out.println("setK1 : " + k1); this .k1 = k1; } public void setK2 (Integer k2) System.out.println("setK2 : " + k2); this .k2 = k2; } @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(k1); System.out.println(k2); System.out.println(LocalDateTime.now()); } }
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDataMap jobDataMap = new JobDataMap(); jobDataMap.put("k1" ,"kkk-1" ); jobDataMap.put("k2" ,2 ); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") .usingJobData(jobDataMap) .build(); JobDataMap triggerDataMap = new JobDataMap(); triggerDataMap.put("k1" ,"kkk-vvv-1" ); triggerDataMap.put("k2" ,100 ); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .usingJobData(triggerDataMap) .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
运行结果:
1 2 3 4 5 setK1 : kkk-vvv-1 setK2 : 100 kkk-vvv-1 100 2022-12-11T08:00:57.275
覆盖规则
如果遇到同名的key,Trigger中的.usingJobData()会覆盖JobDetail中的.usingJobData()。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDataMap triggerDataMap = new JobDataMap(); triggerDataMap.put("k1" ,"kkk-vvv-1" ); triggerDataMap.put("k2" ,100 ); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .usingJobData(triggerDataMap) .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); JobDataMap jobDataMap = new JobDataMap(); jobDataMap.put("k1" ,"kkk-1" ); jobDataMap.put("k2" ,2 ); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") .usingJobData(jobDataMap) .build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
运行结果:
1 2 3 4 5 setK1 : kkk-vvv-1 setK2 : 100 kkk-vvv-1 100 2022-12-11T08:03:24.843
有状态的Job
所谓的有状态的Job是指多次Job调用期间可以持有一些状态信息,这些状态信息存储在JobDataMap中。@PersistJobDataAfterExecution注解即可。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.quartz.PersistJobDataAfterExecution;import java.time.LocalDateTime;@PersistJobDataAfterExecution public class HelloJob implements Job private String k1; private Integer k2; public void setK1 (String k1) System.out.println("setK1 : " + k1); this .k1 = k1; } public void setK2 (Integer k2) System.out.println("setK2 : " + k2); this .k2 = k2; } @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println("k1 :" + k1); System.out.println("k2 :" + k2); k2 = k2 + 1 ; jobExecutionContext.getJobDetail().getJobDataMap().put("k2" , k2); System.out.println(LocalDateTime.now()); } }
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") .usingJobData("k1" ,"kv1" ) .usingJobData("k2" ,1 ) .build(); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 setK1 : kv1 setK2 : 1 k1 :kv1 k2 :1 2022-12-11T08:07:33.029 setK1 : kv1 setK2 : 2 k1 :kv1 k2 :2 2022-12-11T08:07:37.933 setK1 : kv1 setK2 : 3 k1 :kv1 k2 :3 2022-12-11T08:07:42.934
有些资料说,添加@PersistJobDataAfterExecution注解后,不会每次调用都创建一个新的实例,这个说法是错误的。实际上,还是每次都创建了新的实例。
(通过注解名字,我们也能知道,被持久化的,是JobData,而不是JobDetail。)
我们可以创建一个无参的构造方法,并打印一行内容,进行验证。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.quartz.PersistJobDataAfterExecution;import java.time.LocalDateTime;@PersistJobDataAfterExecution public class HelloJob implements Job public HelloJob () System.out.println("HelloJob..." ); } private String k1; private Integer k2; public void setK1 (String k1) System.out.println("setK1 : " + k1); this .k1 = k1; } public void setK2 (Integer k2) System.out.println("setK2 : " + k2); this .k2 = k2; } @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println("k1 :" + k1); System.out.println("k2 :" + k2); k2 = k2 + 1 ; jobExecutionContext.getJobDetail().getJobDataMap().put("k2" , k2); System.out.println(LocalDateTime.now()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDetail jobDetail = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") .usingJobData("k1" ,"kv1" ) .usingJobData("k2" ,1 ) .build(); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startNow() .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()).build(); scheduler.scheduleJob(jobDetail,trigger); scheduler.start(); } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 HelloJob... setK1 : kv1 setK2 : 1 k1 :kv1 k2 :1 2022-12-11T08:10:17.520 HelloJob... setK1 : kv1 setK2 : 2 k1 :kv1 k2 :2 2022-12-11T08:10:22.459 HelloJob... setK1 : kv1 setK2 : 3 k1 :kv1 k2 :3 2022-12-11T08:10:27.458
Trigger
Quartz有多种触发器,使用最多的是SimpleTrigger和CronTrigger。
Trigger的属性
我们可以在Trigger中定义startTime(开始时间)和endTime(结束时间)。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.quartz.Trigger;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); Trigger trigger = jobExecutionContext.getTrigger(); System.out.println("name : " +trigger.getJobKey().getName()); System.out.println("group : " + trigger.getJobKey().getGroup()); System.out.println("任务开始时间 : " + trigger.getStartTime()); System.out.println("任务结束时间 : " + trigger.getEndTime()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;import java.util.Date;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); Date startDate = new Date(); startDate.setTime(startDate.getTime() + 3000 ); Date endDate = new Date(); endDate.setTime(endDate.getTime() + 10000 ); JobDetail job = JobBuilder.newJob(HelloJob.class ) .withIdentity("job1", "group1") // 定义该实例唯一标识 .usingJobData("message" , "打印日志" ) .build(); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1" , "group1" ) .startAt(startDate) .endAt(endDate) .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()) .usingJobData("message" , "simple触发器" ) .build(); scheduler.scheduleJob(job, trigger); scheduler.start(); } }
运行结果:
1 2 3 4 5 2022-12-11T08:35:50.408 name : job1 group : group1 任务开始时间 : Wed Jan 11 08:35:50 CST 2023 任务结束时间 : Wed Jan 11 08:35:57 CST 2023
SimpleTrigger
SimpleTrigger的使用场景:在指定的时间启动,且以指定的间隔时间重复执行若干次。
例子一:在指定的时间启动,只执行一次。 示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;import java.util.Date;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); Date startDate = new Date(); startDate.setTime(startDate.getTime() + 10000 ); JobDetail job = JobBuilder.newJob(HelloJob.class ) .build () ; Trigger trigger = TriggerBuilder.newTrigger() .startAt(startDate) .build(); scheduler.scheduleJob(job, trigger); scheduler.start(); } }
运行结果:
例子二:在指定的时间启动,每次间隔5秒,永久执行。 示例代码:
1 2 3 4 Trigger trigger = TriggerBuilder.newTrigger() .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()) .startAt(startDate) .build();
例子三:在指定的时间启动,每次间隔5秒,永久执行。并在指定的时间结束 示例代码:
1 2 3 4 5 Trigger trigger = TriggerBuilder.newTrigger() .withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5 ).repeatForever()) .startAt(startDate) .endAt(endDate) .build();
CronTrigger
CronTriggers:基于日历的作业调度器。
使用CronTrigger,你可以指定诸如"每个周五12:00"、"每周一、周三、周五的上午9:00到上午10:00之间每隔五分钟"等,这样日程安排来触发。
Cron表达式
这不是我们第一次讨论Cron表达式,在《Linux操作系统使用入门:2.命令》 ,我们也讨论过Cron表达式。
Linux中的Cron表达式一共5位,从左到右,分别是:
分钟
小时
日期
月份
星期
QuartZ中的Cron表达式,有7位,从左到右,分别是
秒 分钟
小时
日期
月份
星期
年(可选)
(粗体字标识的,是相较于Linux中的Cron表达式,多的两位。)
注意:
星期:用1到7来表示(1代表星期天),或者用字符串SUN、MON、TUE、WED、THU、FRI和SAT来表示。
这部分与在Linux中不同,Linux中1代表星期一。
月份,用1到12来表示,或者用字符串JAN、FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV和DEC来表示。
在《Linux操作系统使用入门:2.命令》 ,我们还讨论了一些特殊值:
特殊字符
含义
示例
*所有可能的值
在月域中,*表示每个月;在星期域中,*表示星期的每一天。
,列出枚举值
在分钟域中,5,20表示分别在5分钟和20分钟触发一次。
-范围
在分钟域中,5-20表示从5分钟到20分钟之间每隔一分钟触发一次。
/指定数值的增量
在分钟域中,0/15表示从第0分钟开始,每15分钟,3/20表示从第3分钟开始,每20分钟。
在Cron中有更多的特殊值:
特殊字符
含义
示例
?表示不指定值
例如,"月份中的日期"和"星期中的日期"这两个元素是互斥的,因此应该通过设置一个问号?来表明不想设置某个字段
L最后一个
在day-of-month中,L表示这个月的最后一天,例如一月的31日、二月的28日。在day-of-week中,表示7或者SAT。但是如果在day-of-week中,这个字符跟在别的值后面,则表示"当月的最后一个的周XXX",例如:6L或者FRIL,表示当月的最后一个周五。注意,使用L选项时,不要指定列表或者值范用。
W指定离给定日期最近的工作日(周一到周五)
在日期域中5W,如果5日是星期六,则将在最近的工作日星期五,即4日触发。如果5日是星期天,则将在最近的工作日星期一,即6日触发;如果5日在星期一到星期五中的一天,则就在5日触发。
#确定每个月第几个星期几,仅星期域支持该字符。
在星期域中,4#2表示某月的第二个星期四。
0 0 10,14,16 * * ?
最近10次运行时间
1 2 3 4 5 6 7 8 9 10 2022-12-12 10:00:00 2022-12-12 14:00:00 2022-12-12 16:00:00 2022-12-13 10:00:00 2022-12-13 14:00:00 2022-12-13 16:00:00 2022-12-14 10:00:00 2022-12-14 14:00:00 2022-12-14 16:00:00 2022-12-15 10:00:00
0 0/30 9-12 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 09:00:00 2022-12-12 09:30:00 2022-12-12 10:00:00 2022-12-12 10:30:00 2022-12-12 11:00:00 2022-12-12 11:30:00 2022-12-12 12:00:00 2022-12-12 12:30:00 2022-12-13 09:00:00 2022-12-13 09:30:00
0 0 12 ? * WED
1 2 3 4 5 6 7 8 9 10 2022-12-18 12:00:00 2022-12-25 12:00:00 2023-02-01 12:00:00 2023-02-08 12:00:00 2023-02-15 12:00:00 2023-02-22 12:00:00 2023-03-01 12:00:00 2023-03-08 12:00:00 2023-03-15 12:00:00 2023-03-22 12:00:00
0 0 12 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 12:00:00 2022-12-13 12:00:00 2022-12-14 12:00:00 2022-12-15 12:00:00 2022-12-16 12:00:00 2022-12-17 12:00:00 2022-12-18 12:00:00 2022-12-19 12:00:00 2022-12-20 12:00:00 2022-12-21 12:00:00
0 15 10 ? * *
1 2 3 4 5 6 7 8 9 10 2022-12-12 10:15:00 2022-12-13 10:15:00 2022-12-14 10:15:00 2022-12-15 10:15:00 2022-12-16 10:15:00 2022-12-17 10:15:00 2022-12-18 10:15:00 2022-12-19 10:15:00 2022-12-20 10:15:00 2022-12-21 10:15:00
0 15 10 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 10:15:00 2022-12-13 10:15:00 2022-12-14 10:15:00 2022-12-15 10:15:00 2022-12-16 10:15:00 2022-12-17 10:15:00 2022-12-18 10:15:00 2022-12-19 10:15:00 2022-12-20 10:15:00 2022-12-21 10:15:00
0 15 10 * * ? *
1 2 3 4 5 6 7 8 9 10 2022-12-12 10:15:00 2022-12-13 10:15:00 2022-12-14 10:15:00 2022-12-15 10:15:00 2022-12-16 10:15:00 2022-12-17 10:15:00 2022-12-18 10:15:00 2022-12-19 10:15:00 2022-12-20 10:15:00 2022-12-21 10:15:00
0 15 10 * * ? 2099
1 2 3 4 5 6 7 8 9 10 2099-01-01 10:15:00 2099-01-02 10:15:00 2099-01-03 10:15:00 2099-01-04 10:15:00 2099-01-05 10:15:00 2099-01-06 10:15:00 2099-01-07 10:15:00 2099-01-08 10:15:00 2099-01-09 10:15:00 2099-01-10 10:15:00
0 * 14 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 14:00:00 2022-12-12 14:01:00 2022-12-12 14:02:00 2022-12-12 14:03:00 2022-12-12 14:04:00 2022-12-12 14:05:00 2022-12-12 14:06:00 2022-12-12 14:07:00 2022-12-12 14:08:00 2022-12-12 14:09:00
0 0/55 14 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 14:00:00 2022-12-12 14:55:00 2022-12-13 14:00:00 2022-12-13 14:55:00 2022-12-14 14:00:00 2022-12-14 14:55:00 2022-12-15 14:00:00 2022-12-15 14:55:00 2022-12-16 14:00:00 2022-12-16 14:55:00
0 0/55 14,18 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 14:00:00 2022-12-12 14:55:00 2022-12-12 18:00:00 2022-12-12 18:55:00 2022-12-13 14:00:00 2022-12-13 14:55:00 2022-12-13 18:00:00 2022-12-13 18:55:00 2022-12-14 14:00:00 2022-12-14 14:55:00
0 0-5 14 * * ?
1 2 3 4 5 6 7 8 9 10 2022-12-12 14:00:00 2022-12-12 14:01:00 2022-12-12 14:02:00 2022-12-12 14:03:00 2022-12-12 14:04:00 2022-12-12 14:05:00 2022-12-13 14:00:00 2022-12-13 14:01:00 2022-12-13 14:02:00 2022-12-13 14:03:00
0 10 14 ? 3 WED
1 2 3 4 5 6 7 8 9 10 2023-03-01 14:10:00 2023-03-08 14:10:00 2023-03-15 14:10:00 2023-03-22 14:10:00 2023-03-29 14:10:00 2024-03-06 14:10:00 2024-03-13 14:10:00 2024-03-20 14:10:00 2024-03-27 14:10:00 2025-03-05 14:10:00
0 15 10 ? * MON-FRI
1 2 3 4 5 6 7 8 9 10 2022-12-12 10:15:00 2022-12-13 10:15:00 2022-12-16 10:15:00 2022-12-17 10:15:00 2022-12-18 10:15:00 2022-12-19 10:15:00 2022-12-20 10:15:00 2022-12-23 10:15:00 2022-12-24 10:15:00 2022-12-25 10:15:00
0 15 10 15 * ?
1 2 3 4 5 6 7 8 9 10 2022-12-15 10:15:00 2023-02-15 10:15:00 2023-03-15 10:15:00 2023-04-15 10:15:00 2023-05-15 10:15:00 2023-06-15 10:15:00 2023-07-15 10:15:00 2023-08-15 10:15:00 2023-09-15 10:15:00 2023-10-15 10:15:00
0 15 10 L * ?
1 2 3 4 5 6 7 8 9 10 2022-12-31 10:15:00 2023-02-28 10:15:00 2023-03-31 10:15:00 2023-04-30 10:15:00 2023-05-31 10:15:00 2023-06-30 10:15:00 2023-07-31 10:15:00 2023-08-31 10:15:00 2023-09-30 10:15:00 2023-10-31 10:15:00
0 15 10 ? * 6L
1 2 3 4 5 6 7 8 9 10 2022-12-27 10:15:00 2023-02-24 10:15:00 2023-03-31 10:15:00 2023-04-28 10:15:00 2023-05-26 10:15:00 2023-06-30 10:15:00 2023-07-28 10:15:00 2023-08-25 10:15:00 2023-09-29 10:15:00 2023-10-27 10:15:00
0 15 10 ? * 6#3
1 2 3 4 5 6 7 8 9 10 2022-12-20 10:15:00 2023-02-17 10:15:00 2023-03-17 10:15:00 2023-04-21 10:15:00 2023-05-19 10:15:00 2023-06-16 10:15:00 2023-07-21 10:15:00 2023-08-18 10:15:00 2023-09-15 10:15:00 2023-10-20 10:15:00
应用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.kakawanyifan;import com.kakawanyifan.job.HelloJob;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;public class HelloSchedule public static void main (String[] args) throws SchedulerException Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDetail job = JobBuilder.newJob(HelloJob.class ) .build () ; Trigger trigger = TriggerBuilder.newTrigger() .withSchedule(CronScheduleBuilder.cronSchedule("0/30 * * * * ?" )) .build(); scheduler.scheduleJob(job, trigger); scheduler.start(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.kakawanyifan.job;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import java.time.LocalDateTime;public class HelloJob implements Job @Override public void execute (JobExecutionContext jobExecutionContext) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
运行结果:
1 2 3 4 5 2022-12-12T08:32:00.054 2022-12-12T08:32:30.003 2022-12-12T08:33:00.002 2022-12-12T08:33:30.015 2022-12-12T08:34:00.018
Quartz.properties
在quartz-2.3.2.jar的内部,org/quartz目录下默认的配置文件quartz.properties,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 org.quartz.scheduler.instanceName : DefaultQuartzScheduler org.quartz.scheduler.rmi.export : false org.quartz.scheduler.rmi.proxy : false org.quartz.scheduler.wrapJobExecutionInUserTransaction : false org.quartz.threadPool.class : org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount : 10 org.quartz.threadPool.threadPriority : 5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread : true org.quartz.jobStore.misfireThreshold : 60000 org.quartz.jobStore.class : org.quartz.simpl.RAMJobStore
调度器属性:
org.quartz.scheduler.instanceName,调度器的实例名。用来区分特定的调度器实例,可以按照功能用途来给调度器起名。org.quartz.scheduler.instanceId,调度器的实例ID。和前者一样,也允许任何字符串,但这个值必须在所有调度器实例中是唯一的,尤其是在一个集群环境中,作为集群的唯一key。假如你想Quartz帮你生成这个值的话,可以设置为AUTO,大多数情况设置为AUTO即可。
线程池属性:
org.quartz.threadPool.threadCount,处理Job的线程个数,至少为1,但最多的话最好不要超过100。org.quartz.threadPool.threadPriority,线程的优先级,优先级别高的线程比级别低的线程优先得到执行。最小为1,最大为10,默认为5org.quartz.threadPool.class,线程池的实现类。
作业存储设置:
org.quartz.jobStore.class,Job存储实现类,在本文中,Job存储在内存里。
我们也可以在项目的资源下添加quartz.properties文件,去覆盖底层的配置文件。
整合Spring
spring-context-support
需要引入Jar包spring-context-support:
1 2 3 4 5 <dependency > <groupId > org.springframework</groupId > <artifactId > spring-context-support</artifactId > <version > 5.3.24</version > </dependency >
Job类
新建Job类,继承QuartzJobBean。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan.job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.springframework.scheduling.quartz.QuartzJobBean;import java.time.LocalDateTime;public class QuartzJob extends QuartzJobBean @Override protected void executeInternal (JobExecutionContext context) throws JobExecutionException System.out.println(LocalDateTime.now()); } }
配置类
新建一个配置类,配置类中做的事情,其实就是我们上文的App类中的Main方法做的事情。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.kakawanyifan.config;import com.kakawanyifan.job.QuartzJob;import org.springframework.context.annotation.Bean;import org.springframework.scheduling.quartz.CronTriggerFactoryBean;import org.springframework.scheduling.quartz.JobDetailFactoryBean;import org.springframework.scheduling.quartz.SchedulerFactoryBean;public class QuartzJobConfig @Bean public JobDetailFactoryBean jobDetail () JobDetailFactoryBean jobDetailFactoryBean = new JobDetailFactoryBean(); jobDetailFactoryBean.setName("n1" ); jobDetailFactoryBean.setGroup("g1" ); jobDetailFactoryBean.setJobClass(QuartzJob.class ) ; return jobDetailFactoryBean; } @Bean public CronTriggerFactoryBean cronTrigger (JobDetailFactoryBean jobDetail) CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean(); cronTriggerFactoryBean.setName("n1" ); cronTriggerFactoryBean.setGroup("g1" ); cronTriggerFactoryBean.setJobDetail(jobDetail.getObject()); cronTriggerFactoryBean.setCronExpression("0/5 * * * * ?" ); return cronTriggerFactoryBean; } @Bean public SchedulerFactoryBean scheduler (CronTriggerFactoryBean cronTrigger) SchedulerFactoryBean schedulerFactoryBean = new SchedulerFactoryBean(); schedulerFactoryBean.setTriggers(cronTrigger.getObject()); return schedulerFactoryBean; } }
当然,该配置类需要被Import到Spring的配置类中。
@Import({JdbcConfig.class, MyBatisConfig.class, QuartzJobConfig.class})
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.kakawanyifan.config;import org.springframework.context.annotation.*;import org.springframework.stereotype.Controller;import org.springframework.transaction.annotation.EnableTransactionManagement;@Configuration @ComponentScan (value = "com.kakawanyifan" , excludeFilters = @ComponentScan .Filter( type = FilterType.ANNOTATION, classes = Controller.class )) @PropertySource("classpath:jdbc.properties") @Import ({JdbcConfig.class , MyBatisConfig .class , QuartzJobConfig .class }) @EnableTransactionManagement public class SpringConfig }
XML方式
新建一个XML文件quartzConfig.xml。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns ="http://www.springframework.org/schema/beans" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd" > <bean id ="jobDetail" class ="org.springframework.scheduling.quartz.JobDetailFactoryBean" > <property name ="name" value ="n1" /> <property name ="group" value ="g1" /> <property name ="jobClass" value ="com.kakawanyifan.job.QuartzJob" /> </bean > <bean id ="trigger" class ="org.springframework.scheduling.quartz.CronTriggerFactoryBean" > <property name ="name" value ="n1" /> <property name ="group" value ="g1" /> <property name ="jobDetail" ref ="jobDetail" /> <property name ="cronExpression" value ="0/5 * * * * ?" /> </bean > <bean class ="org.springframework.scheduling.quartz.SchedulerFactoryBean" > <property name ="triggers" > <list > <ref bean ="trigger" /> </list > </property > </bean > </beans >
同样的,该配置文件需要被Import到Spring的配置文件中。
<import resource="classpath:quartzConfig.xml" />
有些资料会介绍另一种方法,将Job类的Bean也交给Spring管理,然后在"JobDetailFactoryBean"指定"TargetObject"。 在5版本的Spring中已经找不到这种方法。 在上文我们讨论过Job的生命周期,每次执行都会实例化,而在Spring中默认Bean是单例的。 这样的设计,存在冲突,这或许是这种方法被弃用的原因。
Spring中的定时任务
除了Quartz,Spring中也自带了定时任务。
@EnableScheduling
@EnableScheduling注解,开启定时任务设置。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.kakawanyifan.config;import org.springframework.context.annotation.*;import org.springframework.scheduling.annotation.EnableScheduling;import org.springframework.stereotype.Controller;import org.springframework.transaction.annotation.EnableTransactionManagement;@Configuration @ComponentScan (value = "com.kakawanyifan" , excludeFilters = @ComponentScan .Filter( type = FilterType.ANNOTATION, classes = Controller.class )) @PropertySource("classpath:jdbc.properties") @Import ({JdbcConfig.class , MyBatisConfig .class , QuartzJobConfig .class }) @EnableTransactionManagement @EnableScheduling public class SpringConfig }
@Scheduled
@Scheduled注解,定义定时任务。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan.job;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import java.time.LocalDateTime;@Component public class SpringJob @Scheduled (cron = "0/10 * * * * ?" ) public void runJob () System.out.println("SpringJob : " + LocalDateTime.now()); } }
@Scheduled注解的参数有:
cron:cron表达式进行执行。@Scheduled(cron = "0/10 * * * * ?")fixedDelay,上次调用结束后,指定毫秒后再执行。@Scheduled(fixedDelay = 5000):上次调用结束后5秒再执行。fixedDelayString,与fixedDelay含义相同。只是使用字符串的形式,可以支持占位符。@Scheduled(fixedDelayString = "${time.fixedDelay}")fixedRate,无论上次是否结束,指定毫秒之后都会再次执行。@Scheduled(fixedRate = 5000):上次开始无论是否结束5秒钟之后会再次执行fixedRateString,与fixedRate含义相同。只是使用字符串的形式,可以支持占位符。initialDelay,初次执行延时时间。initialDelayString,与initialDelay含义相同。只是使用字符串的形式,支持占位符。
XML方式
xmlns:task="http://www.springframework.org/schema/task"http://www.springframework.org/schema/taskhttp://www.springframework.org/schema/task/spring-task.xsd
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns ="http://www.springframework.org/schema/beans" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xmlns:context ="http://www.springframework.org/schema/context" xmlns:task ="http://www.springframework.org/schema/task" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd" >【部分代码略】 <bean id ="springJob" class ="com.kakawanyifan.job.SpringJob" > </bean > <task:scheduler id ="springJobScheduler" /> <task:scheduled-tasks scheduler ="springJobScheduler" > <task:scheduled ref ="springJob" method ="runJob" cron ="0/10 * * * * *" /> </task:scheduled-tasks > </beans >
除了上文的配置方式,也可以开启注解<task:annotation-driven/>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns ="http://www.springframework.org/schema/beans" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xmlns:context ="http://www.springframework.org/schema/context" xmlns:task ="http://www.springframework.org/schema/task" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd" >【部分代码略】 <task:annotation-driven /> </beans >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.kakawanyifan.job;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import java.time.LocalDateTime;@Component public class SpringJob @Scheduled (cron = "0/10 * * * * *" ) public void runJob () System.out.println("SpringJob : " + LocalDateTime.now()); } }
在Quartz中,还有一部分是监听器。有JobListener(任务监听器)、TriggerListener(触发监听器)和SchedulerListener(调度监听器)三种。
番外篇:APScheduler
APScheduler,Python中的定时任务模块。
概述
简介
APScheduler,定时任务模块。
安装方法:
定时任务模块对比
模块名称
简介
优点
缺点
Apscheduler
基于Quartz的一个Python定时任务框架,提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化作业。
支持定时、定期、一次性任务,支持任务持久化及动态添加。
配置可选项较多,配置起来较为复杂,有一定的学习成本。
Celery
一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具,也可用于任务调度。
支持配置定期任务、支持 crontab 模式配置。
不支持一次性定时任务,单独为定时任务功能而搭建celery显得过于重量级。
schedule
轻量级,无需配置的作业调度库。
轻量级、无需配置、语法简单。
阻塞式调用、无法动态添加或删除任务,无任务状态存储。
python-crontab
针对系统Cron操作crontab文件的作业调度库。
支持定时、定期任务,能够动态添加任务。
不能实现一次性任务需求,没有状态存储,无法跨平台执行。
一些概念
触发器(triggers)
作业存储器(job stores)
执行器(executors)
调度器(schedulers)
工作流程
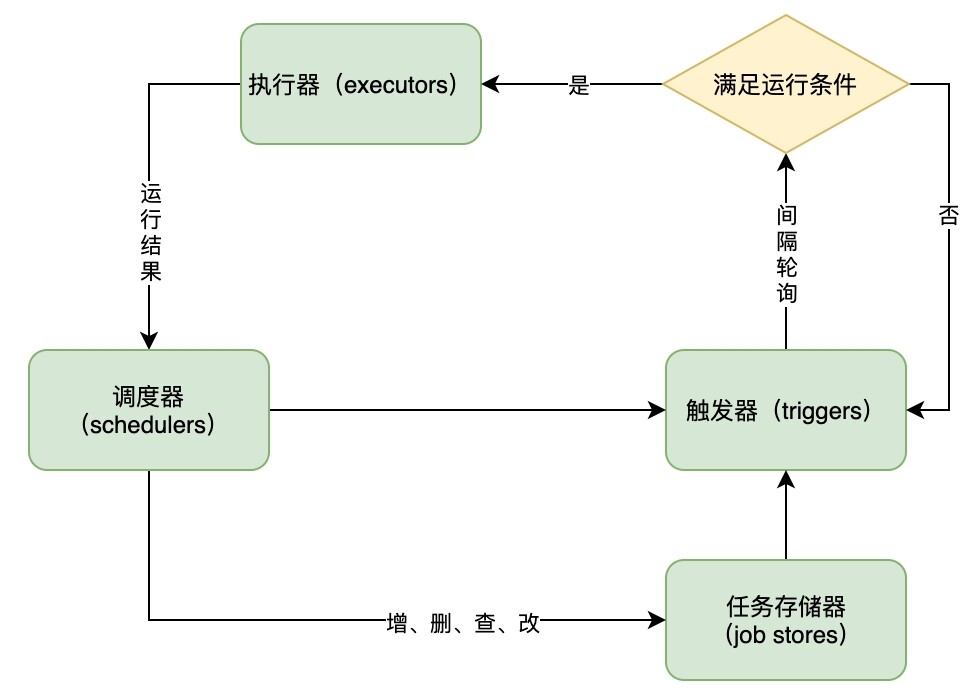
调度器的工作流程如图所示,调度器的主循环其实就是反复检查是否有需要执行的任务,具体分以下两步进行:
询问自己的每一个触发器,是否有需要执行的任务。
提交给执行器按时间点运行。
入门案例
入门案例。实例化一个BlockingScheduler类的对象,添加任务,指定触发器为IntervalTrigger,每隔3秒执行一次,然后调用start方法启动。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from datetime import datetimefrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.interval import IntervalTriggerdef task () : print("tick! The time is: %s" % datetime.now()) if __name__ == '__main__' : scheduler = BlockingScheduler() scheduler.add_job(task, trigger=IntervalTrigger(seconds=3 )) scheduler.start()
运行结果:
1 2 3 4 5 6 7 tick! The time is: 2024-01-21 16:44:37.988249 tick! The time is: 2024-01-21 16:44:40.994318 tick! The time is: 2024-01-21 16:44:43.986083 tick! The time is: 2024-01-21 16:44:46.983994 tick! The time is: 2024-01-21 16:44:49.985926 【部分运行结果略】
配置详解
触发器(triggers)
APScheduler支持的触发器主要有:
DateTrigger,日期触发器。
IntervalTrigger,间隔触发器。
CronTrigger,cron表达式触发器。
DateTrigger 日期触发器
DateTrigger,日期触发器。在某一日期时间点上运行任务时调用,是APScheduler里面最简单的一种触发器,通常适用于一次性的任务或作业调度。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from datetime import datetime, datefrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.date import DateTriggerdef task () : print("tick! The time is: %s" % datetime.now()) if __name__ == '__main__' : scheduler = BlockingScheduler() scheduler.add_job(task, trigger=DateTrigger(run_date=date(2024 , 1 , 22 ), timezone="Asia/Shanghai" )) scheduler.add_job(task, trigger=DateTrigger(run_date=datetime(2024 , 1 , 21 , 20 , 0 , 30 ), timezone="Asia/Shanghai" )) scheduler.add_job(task, trigger=DateTrigger(run_date="2024-01-21 20:00:30" , timezone="Asia/Shanghai" )) scheduler.start()
IntervalTrigger 间隔触发器
IntervalTrigger,间隔触发器。用以对重复性任务进行设定或调度的一个常用调度器。设定了时间部分之后,从起始日期开始(默认是当前)会按照设定的时间去执行任务。
IntervalTrigger触发器支持设置如下参数:
参数
含义
类型
weeks
周
整型
days
一个月中的第几天
整型
hours
小时
整型
minutes
分钟
整型
seconds
秒
整型
start_date
间隔触发的起始时间
时间格式字符串
end_date
间隔触发的结束时间
时间格式字符串
jitter
触发的时间误差
整型
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from datetime import datetimefrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.interval import IntervalTriggerdef task () : print("tick! The time is: %s" % datetime.now()) if __name__ == '__main__' : scheduler = BlockingScheduler() scheduler.add_job(task, trigger=IntervalTrigger(minutes=10 , timezone="Asia/Shanghai" )) scheduler.add_job(task, trigger=IntervalTrigger(minutes=10 , start_date="2024-01-22 09:00:00" , end_date="2024-01-22 15:00:00" , timezone="Asia/Shanghai" )) scheduler.start()
CronTrigger cron表达式触发器
CronTrigger,cron 表达式触发器,用于更复杂的日期时间进行设定。
cron触发器支持设置如下参数:
参数
含义
year
4位数字的年份
month
1-12月份
day
1-31日
week
1-53周
day_of_week
一个星期中的第几天(0-6或者mon、tue、wed、thu、fri、sat、sun)
hour
0-23小时
minute
0-59分钟
second
0-59秒
start_date
datetime类型或者字符串类型,起始时间
end_date
datetime类型或者字符串类型,结束时间
timezone
时区
jitter
任务触发的误差时间
也可以用表达式类型:
表达式
字段
描述
*
任何
在每个值都触发
*/a
任何
每隔a触发一次
a-b
任何
在a-b区间内任何一个时间触发
a-b/c
任何
在a-b区间内每隔c触发一次
xth y
day
在x个星期y触发
last x
day
在最后一个星期x触发
last
day
在一个月中的最后一天触发
x,y,z
任何
将上面的表达式进行组合
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from datetime import datetimefrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.cron import CronTriggerdef task () : print("tick! The time is: %s" % datetime.now()) if __name__ == '__main__' : scheduler = BlockingScheduler() scheduler.add_job(task, trigger=CronTrigger(month="1-3,6-9" , day="3th 5" , hour="0-4/2" , timezone="Asia/Shanghai" )) scheduler.add_job(task, trigger=CronTrigger.from_crontab("0 0 1-15 * *" , timezone="Asia/Shanghai" )) scheduler.start()
调度器(schedulers)
APScheduler 提供了以下几种调度器:
BlockingScheduler,阻塞调度器。
BackgroundScheduler,后台调度器。
AsyncIOScheduler,AsyncIO调度器。asyncio模块进行异步操作,使用该调度器。
GeventScheduler,Gevent调度器。gevent模块进行协程操作,使用该调度器。
TornadoScheduler,Tornado调度器。
TwistedScheduler,Twisted调度器。
QtScheduler,Qt调度器。
最常用的是BlockingScheduler和BackgroundScheduler。BlockingScheduler调度器来进行操作,它会在当前进程中启动相应的线程来进行任务调度与处理。BackgroundScheduler调度器,因为它不会干扰当前应用的线程或进程状况。
我们针对这两个调度器,分别举例。
BlockingScheduler 阻塞调度器
BlockingScheduler,阻塞调度器,当程序中没有任何存在主进程之中运行东西时,考虑使用该调度器。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from datetime import datetimeimport osfrom apscheduler.schedulers.blocking import BlockingSchedulerdef tick () : print('Tick! The time is: %s' % datetime.now()) if __name__ == '__main__' : scheduler = BlockingScheduler() scheduler.add_job(tick, 'interval' , seconds=3 ) print('Press Ctrl+{0} to exit' .format('Break' if os.name == 'nt' else 'C' )) try : scheduler.start() except (KeyboardInterrupt, SystemExit): pass
运行结果:
1 2 3 4 5 6 7 Press Ctrl+C to exit Tick! The time is: 2024-01-21 20:27:40.714006 Tick! The time is: 2024-01-21 20:27:43.712426 Tick! The time is: 2024-01-21 20:27:46.713549 Tick! The time is: 2024-01-21 20:27:49.714501 Tick! The time is: 2024-01-21 20:27:52.712833 Tick! The time is: 2024-01-21 20:27:55.710006
BackgroundScheduler 后台调度器
BackgroundScheduler,后台调度器,使用单独的线程执行,在不使用后面任何的调度器且希望在应用程序内部运行时的后台启动时考虑使用,如当前你已经开启了一个 Django或Flask服务。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from datetime import datetimeimport timeimport osfrom apscheduler.schedulers.background import BackgroundSchedulerdef tick () : print('Tick! The time is: %s' % datetime.now()) if __name__ == '__main__' : scheduler = BackgroundScheduler() scheduler.add_job(tick, 'interval' , seconds=3 ) scheduler.start() print('Press Ctrl+{0} to exit' .format('Break' if os.name == 'nt' else 'C' )) try : while True : time.sleep(2 ) except (KeyboardInterrupt, SystemExit): scheduler.shutdown()
运行结果:
1 2 3 4 5 6 Press Ctrl+C to exit Tick! The time is: 2024-01-21 20:29:37.640619 Tick! The time is: 2024-01-21 20:29:40.638832 Tick! The time is: 2024-01-21 20:29:43.640907 Tick! The time is: 2024-01-21 20:29:46.637337 Tick! The time is: 2024-01-21 20:29:49.640262
执行器(executors)
APScheduler提供了以下几种执行器:
ThreadPoolExecutor:默认的线程池执行器。大部分情况下是可以满足我们需求。
ProcessPoolExecutor:进程池执行器。涉及到一些CPU密集计算的操作,使用此执行器。
AsyncIOExecutor:asyncio程序执行器,如果代码是通过asyncio模块进行异步操作,使用该执行器。
TornadoExecutor:Tornado程序执行器,在Tornado框架中使用。
TwistedExecutor:Twisted程序执行器,在基于Twisted的框架或应用程序中使用。
GeventExecutor:Gevent程序执行器,在Gevent框架中使用
任务存储器(job stores)
默认的任务存储器是内存。除此之外,可以将任务保存在数据库中,APScheduler支持的数据库主要有:
sqlalchemy,各类关系型的数据库,如MySQL、PostgreSQL、SQLite等。redis。mongodb。
sqlalchemy 关系型的数据库
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.interval import IntervalTriggerfrom apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStoredef task () : print("开始执行任务" ) if __name__ == '__main__' : scheduler = BlockingScheduler() url = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/job' scheduler.add_jobstore(jobstore=SQLAlchemyJobStore(url=url)) scheduler.add_job(task, trigger=IntervalTrigger(seconds=10 , timezone="Asia/Shanghai" )) scheduler.start()
运行结果:
特别的,我们可以查看在job数据库中的内容,会发现多了一张表,表的内容如下:
1 select * from apscheduler_jobs
运行结果:
1 2 3 4 5 +--------------------------------+-----------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |id |next_run_time |job_state | +--------------------------------+-----------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |4d3572aef9d34e58b69fb3cc49aefc39|1705841017.393986|0x800595E8010000000000007D94288C0776657273696F6E944B018C026964948C203464333537326165663964333465353862363966623363633439616566633339948C0466756E63948C0D5F5F6D61696E5F5F3A7461736B948C0774726967676572948C1D61707363686564756C65722E74726967676572732E696E74657276616C948C0F496E74657276616C547269676765729493942981947D942868014B028C0874696D657A6F6E65948C047079747A948C025F70949394288C0D417369612F5368616E67686169944DE8714B008C034C4D5494749452948C0A73746172745F64617465948C086461746574696D65948C086461746574696D65949394430A07E8011514293906030294680F2868104D80704B008C034353549474945294869452948C08656E645F64617465944E8C08696E74657276616C9468158C0974696D6564656C74619493944B004B0A4B00879452948C066A6974746572944E75628C086578656375746F72948C0764656661756C74948C046172677394298C066B7761726773947D948C046E616D65948C047461736B948C126D6973666972655F67726163655F74696D65944B018C08636F616C6573636594888C0D6D61785F696E7374616E636573944B018C0D6E6578745F72756E5F74696D65946817430A07E80115142B2506030294681B86945294752E| +--------------------------------+-----------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
redis 内存数据库
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.interval import IntervalTriggerfrom apscheduler.jobstores.redis import RedisJobStoredef task () : print("开始执行任务" ) if __name__ == '__main__' : scheduler = BlockingScheduler() REDIS = { 'host' : '10.211.55.14' , 'port' : '6379' , 'db' : 0 , 'password' : 'Redis@2023' } scheduler.add_jobstore(jobstore=RedisJobStore(**REDIS)) scheduler.add_job(task, trigger=IntervalTrigger(seconds=10 , timezone="Asia/Shanghai" )) scheduler.start()
运行结果:
1 2 3 4 5 开始执行任务 开始执行任务 开始执行任务 开始执行任务 开始执行任务
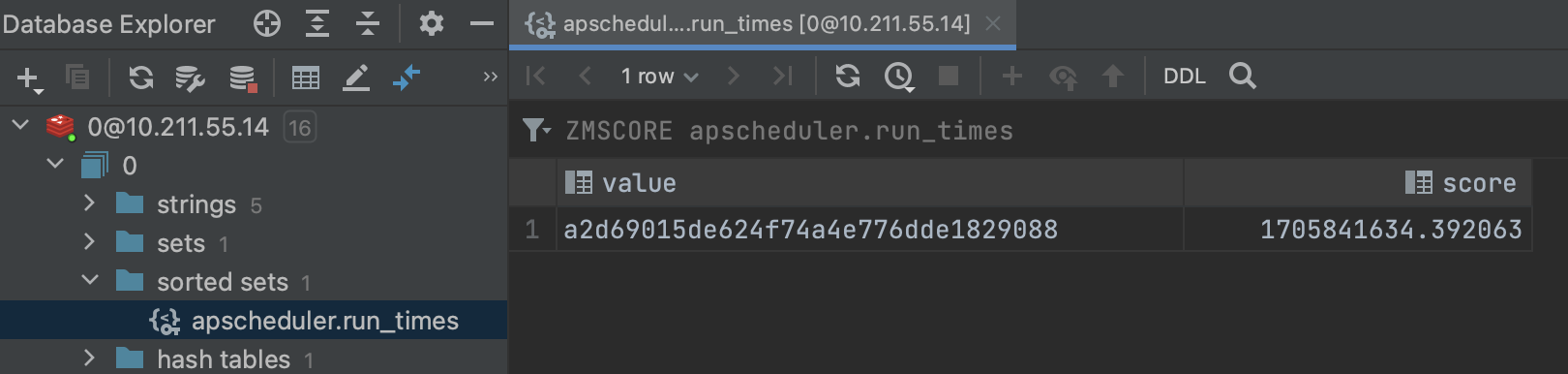
类似的,我们在Redis中可以看到内容如下。
常见job属性
coalesce=Truecoalesce=True,那么下次恢复运行的时候,会只执行一次,而如果设置coalesce=False,那么就不会合并,会5次全部执行。max_instances=3max_instance=3,那么在第3~10分钟上,新的运行实例不会被执行,因为已经有3个实例在运行。name="job"misfire_grace_time=3misfire_grace_time决定这个任务在错过执行时间之后还需不需要执行。
配置schedulers
配置方式
对于scheduler属性的配置,支持以下的方式灵活配置:
在创建实例化对象时配置参数
在创建实例化之后再配置参数
对于scheduler参数的配置,支持以下的方式灵活配置:
使用配置字典参数配置
将关键字参数传递配置
假设现在有这样一个需求:
组件
模块
需求
调度器(schedulers)
阻塞调度器(BlockingScheduler)
为新任务关闭合并模式,同一个任务同一时间最多只能有3个实例在运行。
触发器(triggers)
cron表达式触发器(CronTrigger)
使用cron表达式,每分钟执行一次
执行器(executors)
线程池执行器(ThreadPoolExecutor)
最大10个线程
任务存储器(job stores)
关系型的数据库(sqlalchemy)
将结果保存到MySQL数据库
在创建实例化对象时配置参数+将关键字参数传递配置
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import randomfrom apscheduler.executors.pool import ThreadPoolExecutorfrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.cron import CronTriggerdef task (number) : print("开始执行任务,传入的随机数为%s" % number) job_stores = { 'default' : { 'type' : 'sqlalchemy' , 'url' : 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/job' } } executors = { 'default' : ThreadPoolExecutor(10 ), } job_defaults = { 'coalesce' : False , 'max_instances' : 3 } scheduler = BlockingScheduler( jobstores=job_stores, executors=executors, job_defaults=job_defaults, timezone='Asia/Shanghai' ) if __name__ == '__main__' : number = random.randint(0 , 9 ) scheduler.add_job(task, trigger=CronTrigger.from_crontab("* * * * *" ), args=[number]) try : scheduler.start() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
在创建实例化对象时配置参数+使用配置字典参数配置
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import randomfrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.cron import CronTriggerdef task (number) : print("开始执行任务,传入的随机数为%s" % number) config = { 'apscheduler.jobstores.default' : { 'type' : 'sqlalchemy' , 'url' : 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/job' }, 'apscheduler.executors.default' : { 'class' : 'apscheduler.executors.pool:ThreadPoolExecutor' , 'max_workers' : '10' }, 'apscheduler.job_defaults.coalesce' : 'false' , 'apscheduler.job_defaults.max_instances' : '3' , 'apscheduler.timezone' : 'Asia/Shanghai' , } scheduler = BlockingScheduler(config) if __name__ == '__main__' : number = random.randint(0 , 9 ) scheduler.add_job(task, trigger=CronTrigger.from_crontab("* * * * *" ), args=[number]) try : scheduler.start() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
在创建实例化之后再配置参数+将关键字参数传递配置
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from apscheduler.executors.pool import ThreadPoolExecutorfrom apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStorefrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.cron import CronTriggerimport randomdef task (number) : print("开始执行任务,传入的随机数为%s" % number) scheduler = BlockingScheduler() url = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/job' executors = { 'default' : ThreadPoolExecutor(10 ), } job_defaults = { 'coalesce' : False , 'max_instances' : 3 } scheduler.configure( job_defaults=job_defaults, timezone='Asia/Shanghai' ) scheduler.add_jobstore(jobstore=SQLAlchemyJobStore(url=url)) scheduler.add_executor(executor=ThreadPoolExecutor(max_workers=10 )) if __name__ == '__main__' : number = random.randint(0 , 9 ) scheduler.add_job(task, trigger=CronTrigger.from_crontab("* * * * *" ), args=[number]) try : scheduler.start() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
在创建实例化之后再配置参数+使用配置字典参数配置
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import randomfrom apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.triggers.cron import CronTriggerdef task (number) : print("开始执行任务,传入的随机数为%s" % number) scheduler = BlockingScheduler() config = { 'apscheduler.jobstores.default' : { 'type' : 'sqlalchemy' , 'url' : 'mysql://root:1q2w3e4r@127.0.0.1:3306/job?charset=utf8mb4' }, 'apscheduler.executors.default' : { 'class' : 'apscheduler.executors.pool:ThreadPoolExecutor' , 'max_workers' : '10' }, 'apscheduler.job_defaults.coalesce' : 'false' , 'apscheduler.job_defaults.max_instances' : '3' , 'apscheduler.timezone' : 'Asia/Shanghai' , } scheduler.configure(config) if __name__ == '__main__' : number = random.randint(0 , 9 ) scheduler.add_job(task, trigger=CronTrigger.from_crontab("* * * * *" ), args=[number]) try : scheduler.start() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
常用任务操作
add_job()
add_job(),以传参的形式指定对应的函数名,此方法会返回一个apscheduler.job.Job实例。
可以通过操作该实例,根据需要动态添加任务。
通过add_job()添加任务在上面的配置schedulers时已经演示,此处不再赘述。
通过装饰器scheduled_job添加任务
scheduled_job(),是以装饰器的形式直接对我们要执行的函数进行修饰。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from apscheduler.schedulers.blocking import BlockingSchedulerscheduler = BlockingScheduler() @scheduler.scheduled_job(trigger="interval", args=(1,), seconds=3) def task (number) : print("开始执行任务,传入的参数是%s" % number) if __name__ == '__main__' : try : scheduler.start() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
注意:
如果添加job时,scheduler尚未运行,job会被临时地进行排列,直到scheduler启动之后,它的首次运行时间才会被确切地计算出来。
如果在程序初始化时,是从数据库读取任务的,那么必须为每个任务定义一个明确的ID,并且使replace_existing=True,否则每次重启程序,你都会得到一份新的任务拷贝,也就意味着任务的状态不会保存。
内置任务储存器中,只有MemoryJobStore不会序列化任务;内置执行器中,只有ProcessPoolExecutor会序列化任务。
如果想要立刻运行任务,可以在添加任务时省略trigger参数
获取任务列表
可以使用get_jobs()方法来获得机器上可处理的作业调度列表,方法会返回一个Job实例的列表。
也可以使用print_jobs()来格式化输出作业列表以及它们的触发器和下一次的运行时间。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerdef task () : print("执行任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() my_job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=1 )) scheduler.start() scheduler.print_jobs() print(scheduler.get_jobs()) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 Jobstore default: task (trigger: interval[0:00:01], next run at: 2024-01-22 10:55:39 CST) [<Job (id=c4b2eb25a67c4a3c94be6cd072f40e80 name=task)>]
删除任务
两种方法
当从scheduler中移除一个job时,会自动从关联的job-store中被移除,不再被执行。移除任务有两种方式:
调用remove_job(),参数为任务ID,任务储存器名称。通过修饰器添加的任务,可以使用此方法删除任务。
在通过add_job()创建的任务实例上调用remove()方法
remove_job()
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timefrom apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler() @scheduler.scheduled_job(trigger="interval", seconds=1, id="task") def task () : print("开始执行任务" ) if __name__ == '__main__' : try : print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("删除定时任务" ) scheduler.remove_job(job_id="task" ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 开始定时任务 开始执行任务 开始执行任务 开始执行任务 删除定时任务
remove()
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("开始执行任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=1 )) print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("删除定时任务" ) job.remove() except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 开始定时任务 开始执行任务 开始执行任务 开始执行任务 删除定时任务
注意!如果使用BlockingScheduler调度器的话,在其start之后的任何操作都不会去执行。因此想要修改删除任务,必须使用BackgroundScheduler。
暂停/恢复任务
两种方法
可以通过Job实例或者scheduler实例本身,暂停和恢复job 。
当一个job被暂停,它的下一次运行时间将会被清空,同时不再计算之后的运行时间,直到这个job被恢复。
对于使用add_job添加的任务,可以使用pause()方法暂停任务,使用resume()方法恢复任务。
通过修饰器添加的任务,可以使用pause_job()方法暂停任务,使用resume_job()方法恢复任务
通过job实例
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("执行任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=1 )) print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("暂停定时任务" ) job.pause() time.sleep(3 ) print("恢复定时任务" ) job.resume() time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 8 9 开始定时任务 执行任务 执行任务 执行任务 暂停定时任务 恢复定时任务 执行任务 执行任务 执行任务
通过scheduler实例
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import timefrom apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler() @scheduler.scheduled_job(trigger="interval", seconds=1, id="task") def task () : print("执行任务" ) if __name__ == '__main__' : try : print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("暂停定时任务" ) scheduler.pause_job(job_id="task" ) time.sleep(3 ) print("恢复定时任务" ) scheduler.resume_job(job_id="task" ) time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 8 9 开始定时任务 执行任务 执行任务 暂停定时任务 执行任务 恢复定时任务 执行任务 执行任务 执行任务
修改任务属性
两种方法
apscheduler支持修改job的属性,例如max_instances,coalesce等属性信息。
对于使用add_job添加的任务,可以使用modify()方法修改任务属性。
通过修饰器添加的任务,可以使用modify_job()方法修改任务属性
通过job实例
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("执行task任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=1 )) print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("修改定时任务属性" ) job.modify(max_instances=3 , name='new task' ) time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 8 开始定时任务 执行task任务 执行task任务 执行task任务 修改定时任务属性 执行task任务 执行task任务 执行task任务
通过apscheduler实例
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from apscheduler.schedulers.background import BackgroundSchedulerimport timescheduler = BackgroundScheduler() @scheduler.scheduled_job(trigger="interval", seconds=1, id="task") def task () : print("执行任务" ) if __name__ == '__main__' : try : print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("修改定时任务属性" ) scheduler.modify_job(job_id="task" ) time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 8 开始定时任务 执行任务 执行任务 执行任务 修改定时任务属性 执行任务 执行任务 执行任务
修改任务触发器
两种方法
如果你想重新调度一个job,即要修改其trigger,可以使用apscheduler.job.Job.reschedule()或reschedule_job()方法。这些方法都会为job构建新的 trigger,然后根据新的trigger重新计算其下一次的运行时间。
对于使用add_job添加的任务,可以使用reschedule()方法修改任务触发器。
通过修饰器添加的任务,可以使用reschedule_job()方法修改任务触发器
通过job对象
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("执行task任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=1 )) print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("修改定时任务触发器" ) job.reschedule(trigger=IntervalTrigger(seconds=2 )) time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 开始定时任务 执行task任务 执行task任务 修改定时任务触发器 执行task任务 执行task任务
通过scheduler对象
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from apscheduler.schedulers.background import BackgroundSchedulerimport timescheduler = BackgroundScheduler() @scheduler.scheduled_job(trigger="interval", seconds=1, id="task") def task () : print("执行任务" ) if __name__ == '__main__' : try : print("开始定时任务" ) scheduler.start() time.sleep(3 ) print("修改定时任务属性" ) scheduler.reschedule_job(job_id="task" ) time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 开始定时任务 执行任务 执行任务 执行任务 修改定时任务属性 执行任务
调度器常用操作
终止调度器
默认情况,会终止任务存储器以及执行器,然后等待所有目前执行的job完成后(自动终止)。如果使用wait=False,不会等待任何运行中的任务完成,直接终止。
默认情况 等待任务完成后终止
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("开始执行task任务" ) time.sleep(2 ) print("task任务执行完成" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=3 )) print("开始定时任务" ) scheduler.start() time.sleep(6 ) print("终止调度器" ) scheduler.shutdown() print(scheduler.get_jobs()) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 开始定时任务 开始执行task任务 task任务执行完成 终止调度器 开始执行task任务 task任务执行完成 []
使用wait=False参数直接终止
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timedef task () : print("开始执行task任务" ) time.sleep(2 ) print("task任务执行完成" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=3 )) print("开始定时任务" ) scheduler.start() time.sleep(6 ) print("终止调度器" ) scheduler.shutdown(wait=False ) print(scheduler.get_jobs()) except (KeyboardInterrupt, SystemExit): logger.error("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 开始定时任务 开始执行task任务 task任务执行完成 终止调度器 开始执行task任务 [] task任务执行完成
调度器事件监听
可以为scheduler绑定事件监听器(event listen)。
事件
对应枚举值
描述
归属类
EVENT_SCHEDULER_STARTED
1
调度程序启动
SchedulerEvent
EVENT_SCHEDULER_SHUTDOWN
2
调度程序关闭
SchedulerEvent
EVENT_SCHEDULER_PAUSED
4
调度程序中任务处理暂停
SchedulerEvent
EVENT_SCHEDULER_RESUMED
8
调度程序中任务处理恢复
SchedulerEvent
EVENT_EXECUTOR_ADDED
16
将执行器添加到调度程序中
SchedulerEvent
EVENT_EXECUTOR_REMOVED
32
执行器从调度程序中删除
SchedulerEvent
EVENT_JOBSTORE_ADDED
64
将任务存储添加到调度程序中
SchedulerEvent
EVENT_JOBSTORE_REMOVED
128
任务存储从调度程序中删除
SchedulerEvent
EVENT_ALL_JOBS_REMOVED
256
所有任务从所有任务存储中删除或从一个特定的任务存储中删除
SchedulerEvent
EVENT_JOB_ADDED
512
任务添加到任务存储中
JobEvent
EVENT_JOB_REMOVED
1024
从任务存储中删除了任务
JobEvent
EVENT_JOB_MODIFIED
2048
从调度程序外部修改了任务
JobEvent
EVENT_JOB_EXECUTED
4096
任务被成功执行
JobExecutionEvent
EVENT_JOB_ERROR
8192
任务在执行期间引发异常
JobExecutionEvent
EVENT_JOB_MISSED
16384
错过了任务执行
JobExecutionEvent
EVENT_JOB_SUBMITTED
32768
任务已经提交到执行器中执行
JobSubmissionEvent
EVENT_JOB_MAX_INSTANCES
65536
任务因为达到最大并发执行时,触发的事件
JobSubmissionEvent
EVENT_ALL
包含以上的所有事件
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerfrom apscheduler.events import EVENT_ALLimport timedef task () : print("执行task任务" ) def listener (event) : match event.code: case 4096 : print("任务被成功执行" ) case 32768 : print("任务已经提交到执行器中执行" ) case _: print(event.code) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() my_job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=2 )) print("开始定时任务" ) scheduler.start() scheduler.add_listener(listener, mask=EVENT_ALL) time.sleep(4 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 开始定时任务 执行task任务 任务被成功执行 任务已经提交到执行器中执行 任务已经提交到执行器中执行 执行task任务 任务被成功执行
执行一个会报错的异常任务,示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERRORimport datetimedef aps_test (x) : print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' ), x) def date_test (x) : print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' ), x) print(1 / 0 ) def my_listener (event) : if event.exception: print('任务出错了' ) else : print('任务正常运行' ) scheduler = BlockingScheduler() scheduler.add_job(func=date_test, args=('一次性任务,会出错' ,), next_run_time=(datetime.datetime.now() + datetime.timedelta(seconds=15 )), id='date_task' ) scheduler.add_job(func=aps_test, args=('循环任务' ,), trigger='interval' , seconds=3 , id='interval_task' ) scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR) scheduler.start()
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 /Users/kaka/Documents/pythonProject/venv/bin/python /Users/kaka/Documents/pythonProject/main.py 2024-01-22 13:06:12 循环任务 任务正常运行 2024-01-22 13:06:15 循环任务 任务正常运行 2024-01-22 13:06:18 循环任务 任务正常运行 2024-01-22 13:06:21 循环任务 任务正常运行 2024-01-22 13:06:24 一次性任务,会出错 2024-01-22 13:06:24 循环任务 任务正常运行 任务出错了 Job "date_test (trigger: date[2024-01-22 13:06:09 CST], next run at: 2024-01-22 13:06:24 CST)" raised an exception Traceback (most recent call last): File "/Users/kaka/Documents/pythonProject/venv/lib/python3.11/site-packages/apscheduler/executors/base.py", line 125, in run_job retval = job.func(*job.args, **job.kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/Users/kaka/Documents/pythonProject/main.py", line 12, in date_test print(1 / 0) ~~^~~ ZeroDivisionError: division by zero 2024-01-22 13:06:27 循环任务 任务正常运行 2024-01-22 13:06:30 循环任务 任务正常运行
故障排查
如果scheduler没有如预期般正常运行,可以尝试将apscheduler的logger的日志级别提升到DEBUG等级,打印更多的日志,排查原因。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from apscheduler.schedulers.background import BackgroundSchedulerfrom apscheduler.triggers.interval import IntervalTriggerimport timeimport logginglogging.basicConfig() logging.getLogger('apscheduler' ).setLevel(logging.DEBUG) def task () : print("执行task任务" ) if __name__ == '__main__' : try : scheduler = BackgroundScheduler() job = scheduler.add_job(task, trigger=IntervalTrigger(seconds=2 )) print("开始定时任务" ) scheduler.start() time.sleep(3 ) except (KeyboardInterrupt, SystemExit): print("进程已结束运行" )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 开始定时任务 INFO:apscheduler.scheduler:Adding job tentatively -- it will be properly scheduled when the scheduler starts INFO:apscheduler.scheduler:Added job "task" to job store "default" INFO:apscheduler.scheduler:Scheduler started DEBUG:apscheduler.scheduler:Looking for jobs to run DEBUG:apscheduler.scheduler:Next wakeup is due at 2024-01-22 12:56:10.428849+08:00 (in 1.998914 seconds) 执行task任务 DEBUG:apscheduler.scheduler:Looking for jobs to run INFO:apscheduler.executors.default:Running job "task (trigger: interval[0:00:02], next run at: 2024-01-22 12:56:10 CST)" (scheduled at 2024-01-22 12:56:10.428849+08:00) INFO:apscheduler.executors.default:Job "task (trigger: interval[0:00:02], next run at: 2024-01-22 12:56:10 CST)" executed successfully DEBUG:apscheduler.scheduler:Next wakeup is due at 2024-01-22 12:56:12.428849+08:00 (in 1.995158 seconds)