拷贝和深拷贝
栈内存和堆内存
首先,来看一段代码。
示例代码:
1 2 3 4 5 6 7 t1 = 1 t2 = t1 t1 = 11 print(t1) print(t2)
运行结果:
这段代码的运行结果没有任何问题。t1改成一个列表,并修改列表的元素。
示例代码:
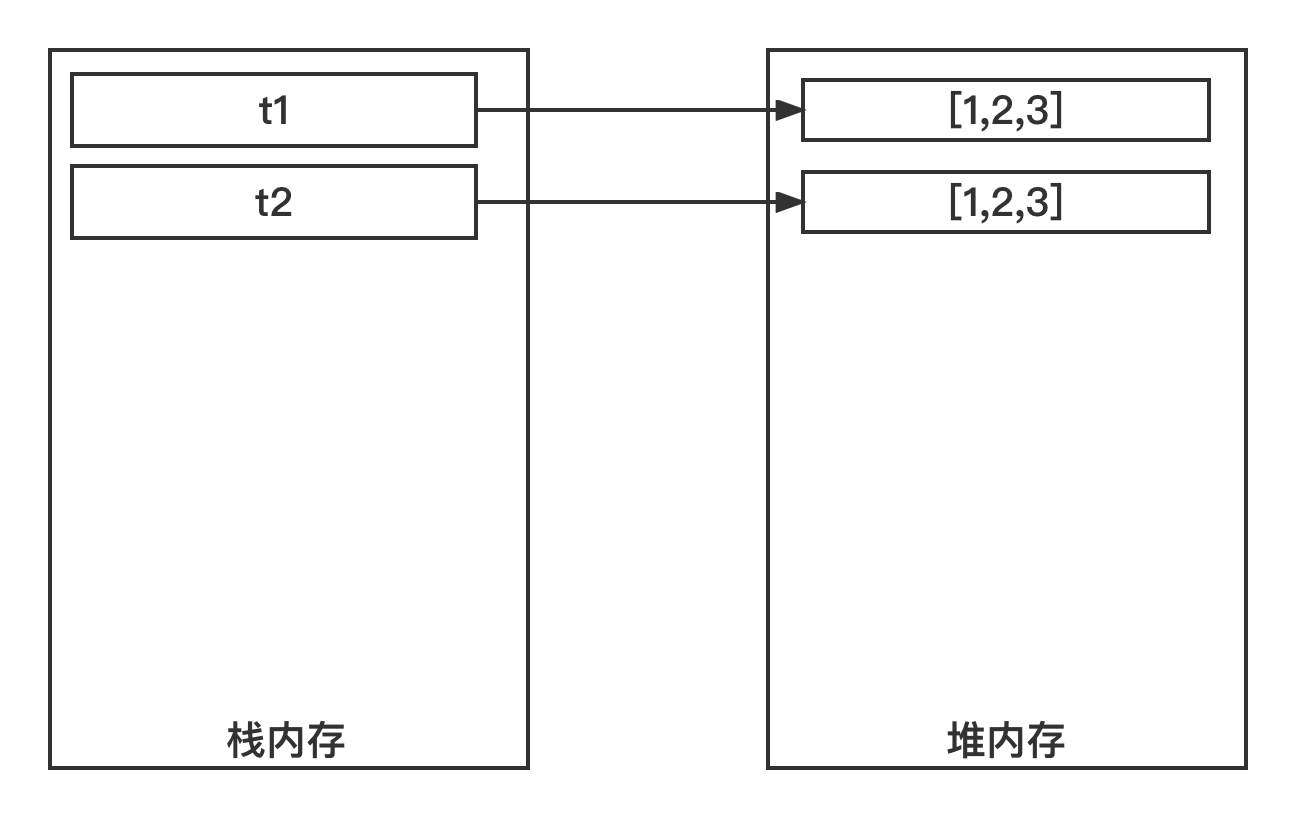
1 2 3 4 5 6 7 t1 = [1 , 2 , 3 ] t2 = t1 t1[0 ] = 11 print(t1) print(t2)
运行结果:
我们只修改了t1,但是打印的t2感觉也被修改了。
首先,执行t1 = [1, 2, 3]和t2 = t1,此时内存结构如图所示。
t1和t2指向堆内存中的同一块区域。所以,执行t1[0] = 11,修改堆内存中的第一个元素为11,会导致t1和t2都受影响。
不可变数据类型和可变数据类型
实际上,在Python的内存结构中,除了栈内存和堆内存,还有一块区域,“常量区”,本文的内存结构有省略。
在Java中,有"栈内存"和"堆内存",基本数据类型在"栈内存"中;引用数据类型,在"栈内存"中存储的是地址,指向"堆内存"中的区域。
Python中有"不可变数据类型"和"可变数据类型"。
“不可变数据类型"对应Java中的"基本数据类型”,有:int(整型)、float(浮点型)、str(字符串)、bool(布尔型)。
“可变数据类型"对应Java中的"引用数据类型”,有:list(列表)、set(集合)、dic(字典)和tuple(元组)。
tuple(元组),其实属于"不可变数据类型",但将其比拟为"引用数据类型"更好。
我们可以看看如下代码的运行,"引用数据类型"的id和"基本数据类型"的id长度都不一样,而且t3元祖的id,看起来更像是"引用数据类型"的长度。
示例代码:
1 2 3 4 5 6 7 8 9 t1 = [1 , 2 , 3 ] t2 = t1 t3 = (1 , 2 , 3 ) print(id(t1)) print(id(t2)) print(id(1 )) print(id(t1[0 ])) print(id(t3))
运行结果:
1 2 3 4 5 140168006292928 140168006292928 4498938560 4498938560 140167940343040
那么,为什么称元祖是"不可变数据类型"呢?不可变 。
示例代码:
1 2 3 4 5 6 7 8 l = [1 , 2 , 3 ] t = (1 , 2 , 3 ) l[0 ] = 11 print(l) t[0 ] = 11 print(t)
运行结果:
1 2 [11, 2, 3] TypeError: 'tuple' object does not support item assignment
但是,我们可以修改元祖中的 "可变数据类型"的内容 。
1 2 3 4 t = ([1 , 2 , 3 ], 1 , 2 , 3 ) t[0 ][0 ] = 11 print(t)
运行结果:
注意,是 "可变数据类型"的内容 ,如下的代码就会报错。
1 2 3 4 t = ([1 , 2 , 3 ], 1 , 2 , 3 ) t[0 ] = 11 print(t)
运行结果:
1 TypeError: 'tuple' object does not support item assignment
关于Python中的数据类型,在《1.基础语法》 中,有更多讨论。
copy
那么,如果想修改t1的同时,不影响t2呢?copy()方法。
示例代码:
1 2 3 4 5 6 7 8 9 10 t1 = [1 , 2 , 3 ] t2 = t1.copy() print(id(t1)) print(id(t2)) t1[0 ] = 11 print(t1) print(t2)
运行结果:
1 2 3 4 140686581646720 140686581468416 [11, 2, 3] [1, 2, 3]
我们看到t2 = t1.copy(),这时候t2并没有和t1指向同一个地址,此时的内存结构如图。
所以,t1[0] = 11,不会影响t2。
deepcopy
再来看一个例子,这回写的是t2 = t1.copy()。
示例代码:
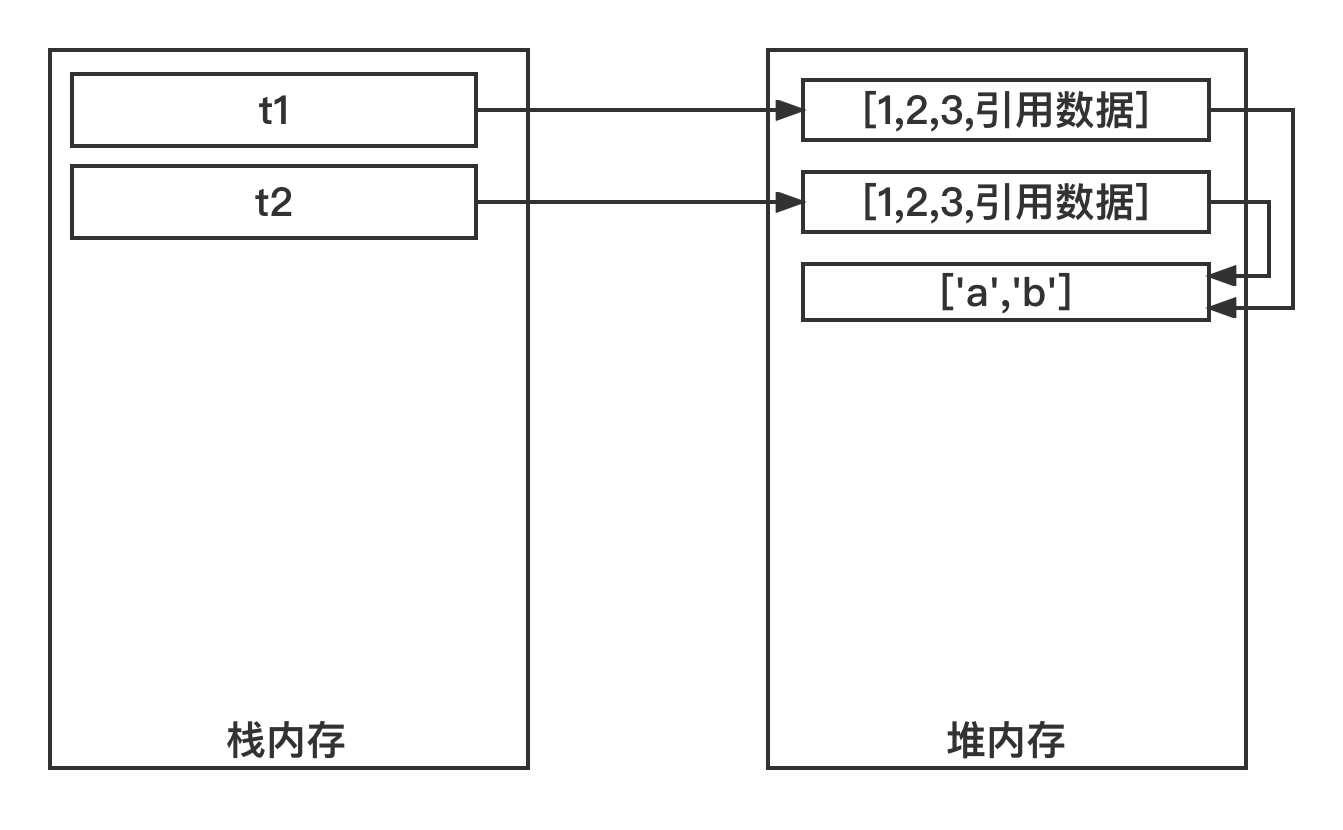
1 2 3 4 5 6 7 8 9 10 t1 = [1 , 2 , 3 , ['a' , 'b' ]] t2 = t1.copy() print(id(t1)) print(id(t2)) t1[-1 ][0 ] = 'aaa' print(t1) print(t2)
运行结果:
1 2 3 4 140361615183104 140361614692160 [1, 2, 3, ['aaa', 'b']] [1, 2, 3, ['aaa', 'b']]
因为t1 = [1, 2, 3, ['a', 'b']],最后一个元素是"引用数据类型"。
我们还可以打印id看一下。
示例代码:
1 2 3 4 5 6 7 8 t1 = [1 , 2 , 3 , ['a' , 'b' ]] t2 = t1.copy() print(id(t1)) print(id(t2)) print(id(t1[-1 ])) print(id(t2[-1 ]))
运行结果:
1 2 3 4 140384734186496 140384733687680 140384734365312 140384734365312
那么,怎么解决呢?copy,以及这个工具包的一个方法,deepcopy()
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import copyt1 = [1 , 2 , 3 , ['a' , 'b' ]] t2 = copy.deepcopy(t1) print(id(t1)) print(id(t2)) print(id(t1[-1 ])) print(id(t2[-1 ])) print(t1) print(t2) t1[-1 ][0 ] = 'aaa' print(t1) print(t2)
运行结果:
1 2 3 4 5 6 7 8 140267864099840 140267863608960 140267864278848 140267862635520 [1, 2, 3, ['a', 'b']] [1, 2, 3, ['a', 'b']] [1, 2, 3, ['aaa', 'b']] [1, 2, 3, ['a', 'b']]
一个"混乱"的现象
示例代码:
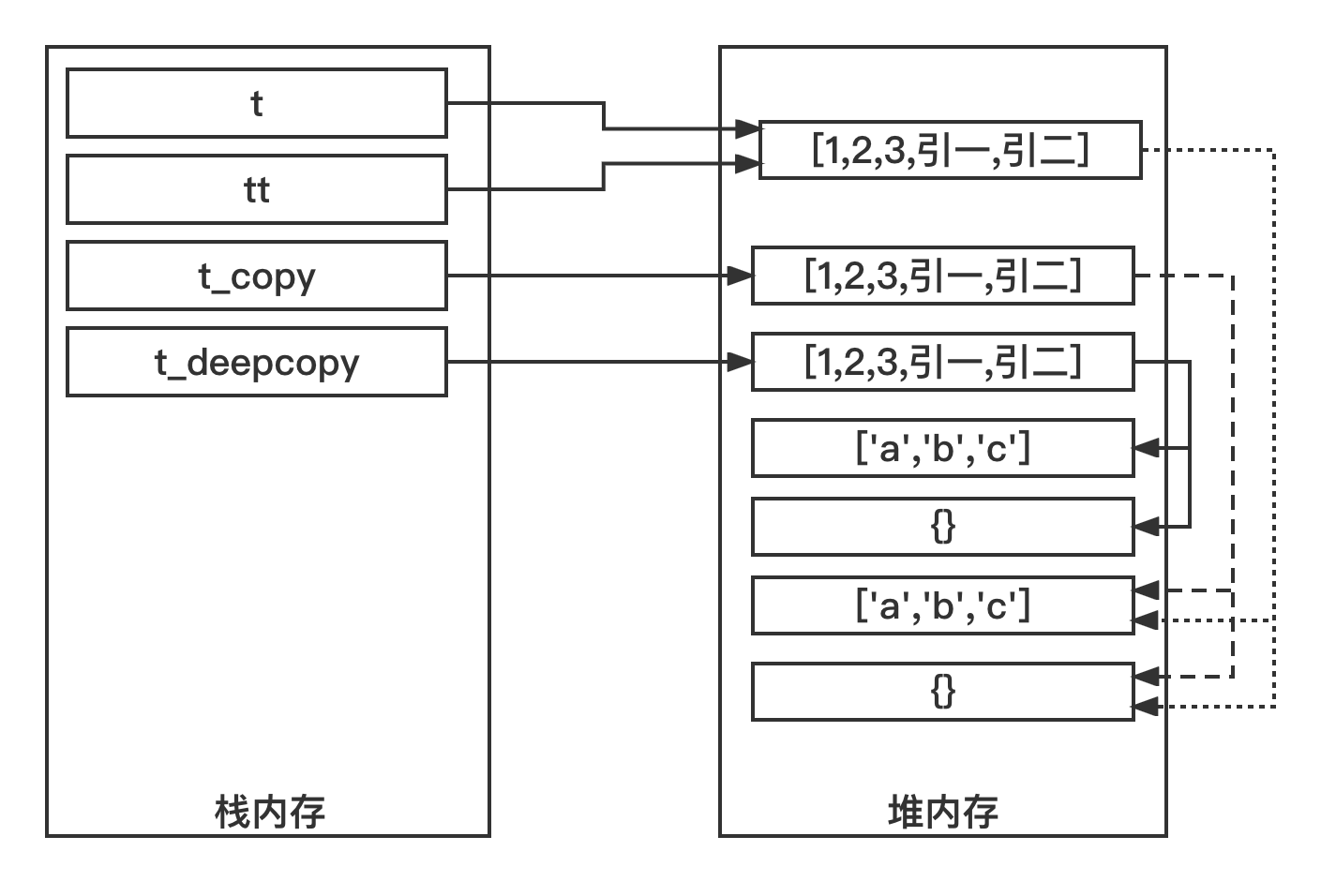
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import copyt = [1 , 2 , 3 , ['a' , 'b' , 'c' ], {}] tt = t t_copy = t.copy() t_deepcopy = copy.deepcopy(t) print(id(t)) print(id(tt)) print(id(t_copy)) print(id(t_deepcopy)) print() print(id(t[3 ])) print(id(tt[3 ])) print(id(t_copy[3 ])) print(id(t_deepcopy[3 ])) print() print(id(t[-1 ])) print(id(tt[-1 ])) print(id(t_copy[-1 ])) print(id(t_deepcopy[-1 ]))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 140298566224256 140298566224256 140298565733504 140298564759936 140298566407680 140298566407680 140298566407680 140298566222400 140298555008064 140298555008064 140298555008064 140298555008448
这个是没有任何问题的。
tt = t,所以id(t)和id(tt)是一样的,指向堆内存中的同一块区域。t_copy = t.copy(),所以id(t)和id(t_copy)不一样,但是id(t[3])和id(t_copy[3])是一样的,因为index为3的是"引用数据类型",id(t[-1])和id(t_copy[-1])同理。t_deepcopy = copy.deepcopy(t),所以id(t)和id(t_deepcopy)不一样,而且id(t[3])和id(t_deepcopy[3])也不一样的,id(t[-1])和id(t_deepcopy[-1])同理。
接下来,我们修改t[3][0] = 'aaa'。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import copyt = [1 , 2 , 3 , ['a' , 'b' , 'c' ], {}] tt = t t_copy = t.copy() t_deepcopy = copy.deepcopy(t) print(t) print(tt) print(t_copy) print(t_deepcopy) print(id(t[3 ])) print(id(tt[3 ])) print(id(t_copy[3 ])) print(id(t_deepcopy[3 ])) t[3 ][0 ] = 'aaa' print() print(t) print(tt) print(t_copy) print(t_deepcopy) print(id(t[3 ])) print(id(tt[3 ])) print(id(t_copy[3 ])) print(id(t_deepcopy[3 ]))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] 140194765948672 140194765948672 140194765948672 140194765767680 [1, 2, 3, ['aaa', 'b', 'c'], {}] [1, 2, 3, ['aaa', 'b', 'c'], {}] [1, 2, 3, ['aaa', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] 140194765948672 140194765948672 140194765948672 140194765767680
这一步也没有任何问题,除了t_deepcopy,其他的都受影响。
接下来,就是见证奇迹的时刻了。
示例代码:
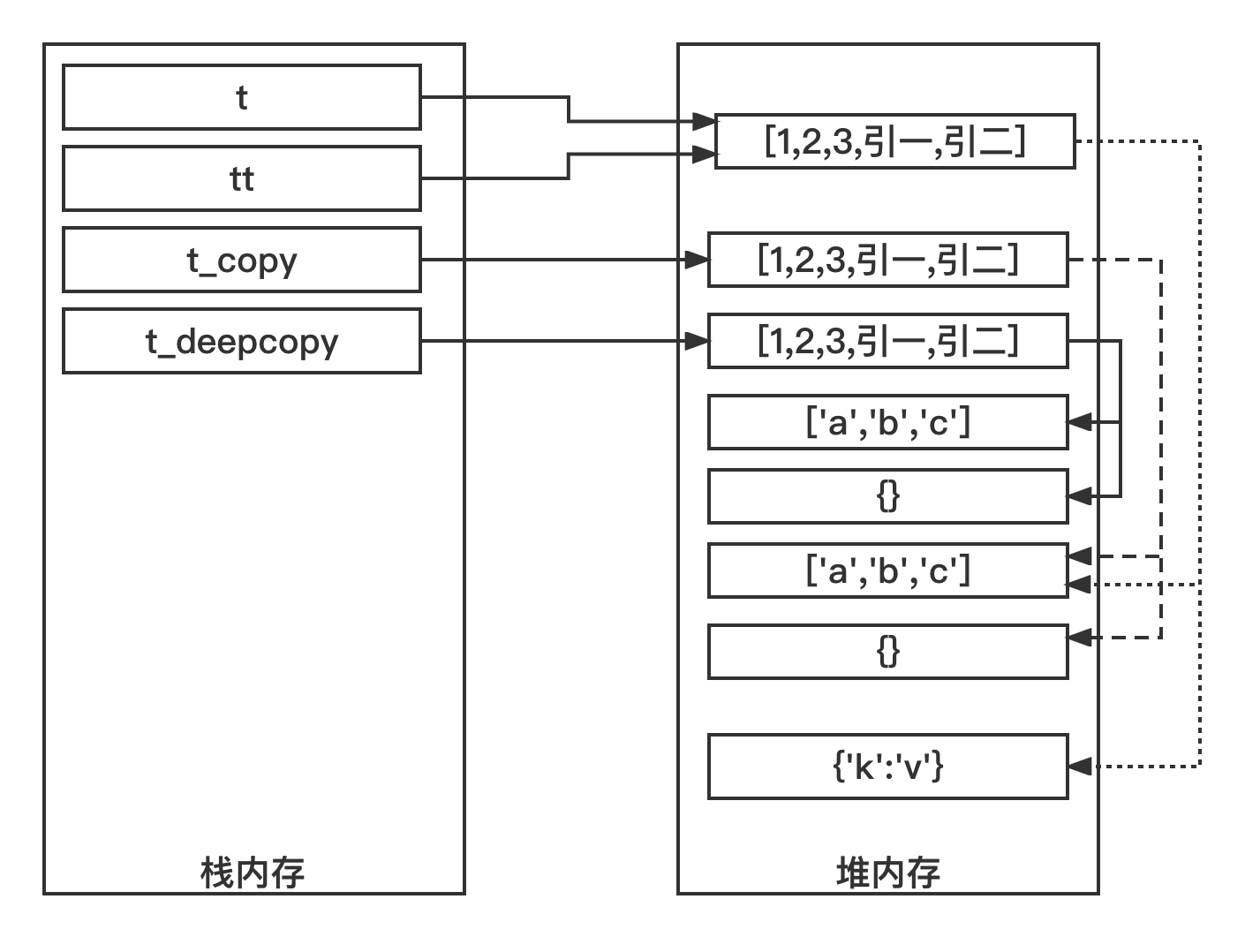
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import copyt = [1 , 2 , 3 , ['a' , 'b' , 'c' ], {}] tt = t t_copy = t.copy() t_deepcopy = copy.deepcopy(t) print(t) print(tt) print(t_copy) print(t_deepcopy) t[-1 ] = {'k' : 'v' } print() print(t) print(tt) print(t_copy) print(t_deepcopy)
运行结果:
1 2 3 4 5 6 7 8 9 [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {'k': 'v'}] [1, 2, 3, ['a', 'b', 'c'], {'k': 'v'}] [1, 2, 3, ['a', 'b', 'c'], {}] [1, 2, 3, ['a', 'b', 'c'], {}]
理论上,应该t_copy也应该受影响啊!t_copy也应该打印[1, 2, 3, ['a', 'b', 'c'], {'k': 'v'}]才对啊!
问题的根源出在哪里?t[-1] = {'k': 'v'}。
我们来分析一下。
1 2 3 4 t = [1 , 2 , 3 , ['a' , 'b' , 'c' ], {}] tt = t t_copy = t.copy() t_deepcopy = copy.deepcopy(t)
这时候的内存结构如图所示。
然后执行t[-1] = {'k': 'v'}t和tt受影响了。
这就是为什么t和tt是[1, 2, 3, ['a', 'b', 'c'], {'k': 'v'}],而t_copy和t_deepcopy是[1, 2, 3, ['a', 'b', 'c'], {}]。
类型注解
现象
如图,我们导入一个包,使用其中一个方法。这时候如果我们按照command + p(或者ctrl + p),会看到有变量类型的提示。
但是,如果我们自己写一个方法,却只有变量名提示,没有变量类型提示。
因为PyCharm无法通过代码,确定应传入什么类型。
变量的类型注解
语法格式
基础数据类型注解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 my_int: int = 1 my_float: float = 1.23 my_str: str = "kkk" my_bool: bool = True my_tuple: tuple = (1 , 2 , 3 ) my_list: list = [1 , 2 , 3 ] my_set: set = {1 , 2 , 3 } my_dict: dict = {'k' : 'v' }
容器类型详细注解
Python中的容器类型有:list,tuple,dict, set。
tuple类型,设置类型详细注解,需要将每一个元素都标记出来。dict类型,设置类型详细注解,需要2个类型,第一个是key,第二个是value。
1 2 3 4 5 6 7 my_list: list[int] = [1 , 2 , 3 ] my_tuple: tuple[int, str, float] = (1 , "abc" , 1.23 ) my_set: set[int] = {1 , 2 , 3 } my_dict: dict[str, int] = {"k" : 123 }
类对象类型注解
1 2 3 4 5 class T : pass t: T = T()
函数的类型注解
形参注解
语法格式:
1 def 函数方法名(形参名一: 类型, 形参名二: 类型, ...) :
形参注解和默认值
对于同时有形参注解和默认值的情况,其顺序如下,先写形参注解,再写默认值。
语法格式:
1 def func (pa: bool = True) :
返回值注解
语法格式:
1 def 函数方法名(形参名一: 类型, 形参名二: 类型, ...) -> 返回值类型:
联合类型注解
联合类型注解,有两种形式:
|Union
或(|)
比如以下函数的参数应为类型int或float。
1 2 def square (number: int | float) -> int | float: return number ** 2
Union
再来看一个现象,如果我们想为这种形式的定义注解怎么办?
1 2 3 my_list = [1 , 2 , "a" , "b" ] my_dict = {"k1" : 1 , "k2" : "vv" }
这时候,就需要联合类型注解,Union了。
1 2 3 4 5 from typing import Unionmy_list: list[Union[int, str]] = [1 , 2 , "a" , "b" ] my_dict: dict[str, Union[str, int]] = {"k1" : 1 , "k2" : "vv" }
1 2 3 4 5 from typing import Uniondef func (v: list[Union[int, str]]) -> Union[str, int]: pass
更多类型
NoReturn
如果函数没有返回值,那么可以这样写:
1 2 3 4 from typing import NoReturndef hello () -> NoReturn: raise RuntimeError('oh no' )
注意下面这样写是错误的,示例代码:
1 2 def hello () -> NoReturn: pass
因为Python的函数运行结束时隐式返回None ,这和真正的无返回值是有区别的。
Optional
假如,存在一个类型注解,用法如下。示例代码:
1 2 3 def foo (a: int = 0 ) -> str: if a == 1 : return 'Yeah'
因为函数既有可能返回None(隐式返回),也有可能返回str。单凭返回值注解为str是不能准确表达此情况的。
这种"可能有也可能没有"的状态被称为可选值,有专门的可选值类型注解可以处理这种情况:
1 2 3 4 5 from typing import Optionaldef foo (a: int = 0 ) -> Optional[str]: if a == 1 : return 'Yeah'
Callable
在Python中的函数和类的区别并不明显。只要实现了对应的接口,类实例也可以是可调用的。如果不关心对象的具体类型,只要求是可调用的,那么可以这样写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from typing import Callableclass Foo : def __call__ (self) : print('I am foo' ) def bar () : print('I am bar' ) def hello (a: Callable) : a() hello(Foo()) hello(bar)
Literal
在定义简单的枚举值时非常好用,比如:
1 2 3 4 5 6 7 8 from typing import LiteralMODE = Literal['r' , 'rb' , 'w' , 'wb' ] def open_helper (file: str, mode: MODE) -> str: ... open_helper('/some/path' , 'r' ) open_helper('/other/path' , 'typo' )
Any
Any,任意。
1 2 3 4 from typing import Anydef foo () -> Any: pass
任何类型都与Any兼容。当然如果你把所有的类型都注解为Any将毫无意义。
闭包
现象
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 amount = 0 def atm (v, add=True) : global amount if add: amount = amount + v print(amount) else : amount = amount - v print(amount) atm(100 ) atm(200 , False ) amount = amount + 1000 print(amount)
运行结果:
上述代码存在的问题是:
代码在变量定义不够干净、整洁。
全局变量有被修改的风险。
简单闭包
1 2 3 4 5 6 7 8 9 def outer (ov) : def inner (iv) : print(f"{ov} {iv} " ) return inner of = outer('hi' ) of('k' )
运行结果:
nonlocal
那么,我们就照葫芦画瓢,示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def func (amount=0 ) : def atm (v, add=True) : if add: amount = amount + v print(amount) else : amount = amount - v print(amount) return atm f = func(100 ) f(100 ) f(100 , False )
运行结果:
1 2 3 4 5 6 Traceback (most recent call last): File "/Users/kaka/Documents/auto-work/1.py", line 15, in <module> f(100) File "/Users/kaka/Documents/auto-work/1.py", line 5, in atm amount = amount + v UnboundLocalError: local variable 'amount' referenced before assignment
报错了!
需要在内部函数,使用nonlocal关键字修饰外部函数的变量,才可在内部函数中修改它。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def func (amount=0 ) : def atm (v, add=True) : nonlocal amount if add: amount = amount + v print(amount) else : amount = amount - v print(amount) return atm f = func(100 ) f(100 ) f(100 , False )
运行结果:
作用
小结一下闭包的作用:
无需定义全局变量即可实现通过函数,持续的访问、修改某个值。
闭包使用的变量的所用于在函数内,难以被错误的调用修改。
装饰器
简介
装饰器其实也是一种闭包,其功能是:在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能。
例如,我们现在有一个sleep函数,我们要在该函数执行前后,分别打印"开始"和"结束"。
1 2 3 4 5 import timedef sleep () : time.sleep(3 )
一般写法
我们可以用闭包来实现。
定义一个闭包函数,在闭包西数内部,执行目标函数并完成功能的添加。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timedef outer (func) : def inner () : print('开始' ) func() print('结束' ) return inner def sleep () : time.sleep(3 ) f = outer(sleep) f()
运行结果:
快捷写法
使用@【闭包函数名】,定义在目标函数之上,然后直接调用目标函数。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timedef sleep_outer (func) : def inner () : print('开始' ) func() print('结束' ) return inner @sleep_outer def sleep () : time.sleep(3 ) sleep()
运行结果:
进阶
现象
我们先开看一个现象print(sleep.__name__)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import timedef sleep_outer (func) : def inner () : print('开始' ) func() print('结束' ) return inner @sleep_outer def sleep () : time.sleep(3 ) sleep() print(sleep.__name__)
运行结果:
方法名居然是inner。
如果想让方法是原本的名称,@functools.wraps(func)。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import timeimport functoolsdef sleep_outer (func) : @functools.wraps(func) def inner () : print('开始' ) func() print('结束' ) return inner @sleep_outer def sleep () : time.sleep(3 ) sleep() print(sleep.__name__)
运行结果:
这样函数名就是sleep了。
多层装饰器
一个函数可以被多个装饰器装饰。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import timeimport functoolsdef sleep_outer (func) : @functools.wraps(func) def inner () : print('开始' ) func() print('结束' ) return inner def sleep_outer_2 (func) : @functools.wraps(func) def inner () : print('开始2' ) func() print('结束2' ) return inner @sleep_outer_2 @sleep_outer def sleep () : time.sleep(3 ) sleep() print(sleep.__name__)
运行结果:
应用
那么,上文讨论的进阶内容,有什么用呢?《基于Python的后端开发入门:8.Flask [1/2]》 ,我们会看到。
@property
定义
@property,装饰器,把一个方法变成属性调用,而且只能作为属性进行调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Temp : def __init__ (self, t) : self._t = t @property def get_t (self) : return self._t temp = Temp(False ) print(temp.get_t) print(temp.get_t())
运行结果:
1 2 3 4 5 False Traceback (most recent call last): File "/Users/kaka/Documents/examples/t.py", line 13, in <module> print(temp.get_t()) TypeError: 'bool' object is not callable
解释说明:temp.get_t的值是False,temp.get_t()报错了。
Python设计@property这个装饰器的目的是,可以在获取属性的方法中,对数据进行一些加工操作。
例子
我们可以再来看一个现象。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Temp : def __init__ (self, t) : self._t = t @property def get_t (self) : return self._t def get_tt (self) : return self._t temp = Temp(False ) if temp.get_t: print('True' ) else : print('False' ) if temp.get_tt: print('True' ) else : print('False' )
运行结果:
get_tt方法上没有装饰器,if temp.get_tt的值为真。
在Python中,函数也可以作为参数。
在if中,函数为True
具体可以参考:《1.基础语法》
网络编程
在《基于Java的后端开发入门:6.网络编程》 ,我们也讨论过网络编程。UDP和TCP的实现方式。
UDP
服务端
1 2 3 4 5 6 7 8 9 10 11 12 13 import socketip_port = ('127.0.0.1' , 9999 ) sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, 0 ) sk.bind(ip_port) while True : data = sk.recv(1024 ).strip().decode() print(data) if data == "exit" : print("客户端主动断开连接!" ) break sk.close()
客户端
1 2 3 4 5 6 7 8 9 10 11 import socketip_port = ('127.0.0.1' , 9999 ) sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, 0 ) while True : inp = input('发送的消息:' ).strip() sk.sendto(inp.encode(), ip_port) if inp == 'exit' : break sk.close()
TCP
服务端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import socketip_port = ('127.0.0.1' , 9999 ) sk = socket.socket() sk.bind(ip_port) sk.listen(5 ) print('启动socket服务,等待客户端连接...' ) conn, address = sk.accept() while True : client_data = conn.recv(1024 ).decode() if client_data == "exit" : exit("通信结束" ) print("来自%s的客户端向你发来信息:%s" % (address, client_data)) conn.sendall('服务器已经收到你的信息' .encode()) conn.close()
客户端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import socketip_port = ('127.0.0.1' , 9999 ) s = socket.socket() s.connect(ip_port) while True : inp = input("请输入要发送的信息: " ).strip() if not inp: continue s.sendall(inp.encode()) if inp == "exit" : print("结束通信!" ) break server_reply = s.recv(1024 ).decode() print(server_reply) s.close()
日志logging
快速开始
使用场景
Python内置的logging模块,为我们提供了现成的高效好用的日志解决方案。
但,不是所有的场景都需要使用logging模块,下面是Python官方推荐的使用方法:
任务场景
最佳工具
普通情况下,在控制台显示输出
print()
报告正常程序操作过程中发生的事件
logging.info()或者更详细的logging.debug()
发出有关特定事件的警告
warnings.warn()或者logging.warning()
报告错误
弹出异常
在不引发异常的情况下报告错误
logging.error()、logging.exception()或者logging.critical()
logging模块定义了下表所示的5种日志级别
级别
级别数值
使用时机
DEBUG10
详细信息,常用于调试。
INFO20
程序正常运行过程中产生的一些信息。
WARNING30
警告用户,虽然程序还在正常工作,但有可能发生错误。
ERROR40
由于更严重的问题,程序已不能执行一些功能了。
CRITICAL50
严重错误,程序已不能继续运行。
默认级别是WARNING,表示只有WARING和比WARNING更严重的事件才会被记录到日志内,低级别的信息会被忽略。因此,默认情况下,DEBUG和INFO会被忽略,WARING、ERROR和CRITICAL会被记录。
基本用法
示例代码:
1 2 3 4 5 import logginglogging.warning('Watch out!' ) logging.info('I told you so' )
运行结果:
解释说明:在什么都不配置和设定的情况下,logging会简单地将日志打印在显示器上。
记录到文件内
我们可以通过logging.basicConfig()方法,设置记录到文件中。
示例代码:
1 2 3 4 5 6 import logginglogging.basicConfig(filename='example.log' , level=logging.DEBUG) logging.debug('This message should go to the log file' ) logging.info('So should this' ) logging.warning('And this, too' )
解释说明:level参数,设定日志记录的门槛。
然后我们会在Python脚本的同一级目录下,找到example.log,内容如下:
1 2 3 DEBUG:root:This message should go to the log file INFO:root:So should this WARNING:root:And this, too
如果我们再次运行该脚本,日志会被追加到文件的后面。将filemode设置为'w'
1 logging.basicConfig(filename='example.log' , filemode='w' , level=logging.DEBUG)
日志的变量数据
在logging模块中通过百分符%方式的格式化控制,生成消息字符串。
示例代码:
1 2 3 import logginglogging.warning('%s before you %s' , 'Look' , 'leap!' )
运行结果:
1 WARNING:root:Look before you leap!
解释说明:两个%s分别被'Look'和'leap!'代替了。
日志格式
如果想控制日志格式,可以利用format参数。
示例代码:
1 2 3 4 5 6 import logginglogging.basicConfig(format='%(levelname)s:%(message)s' , level=logging.DEBUG) logging.debug('This message should appear on the console' ) logging.info('So should this' ) logging.warning('And this, too' )
运行结果:
1 2 3 DEBUG:This message should appear on the console INFO:So should this WARNING:And this, too
附加时间信息
要在日志内容中附加时间信息,可以在format字符串中添加%(asctime)s。
示例代码:
1 2 3 4 import logginglogging.basicConfig(format='%(asctime)s %(message)s' ) logging.warning('is when this event was logged.' )
运行结果:
1 2023-02-01 16:41:03,268 is when this event was logged.
默认情况下,时间的显示使用ISO8601格式。如果想做更深入的定制,可以提供datefmt参数,示例代码:
1 2 3 4 import logginglogging.basicConfig(format='%(asctime)s %(message)s' , datefmt='%m/%d/%Y %I:%M:%S %p' ) logging.warning('is when this event was logged.' )
运行结果:
1 02/01/2023 04:41:59 PM is when this event was logged.
logging的组件
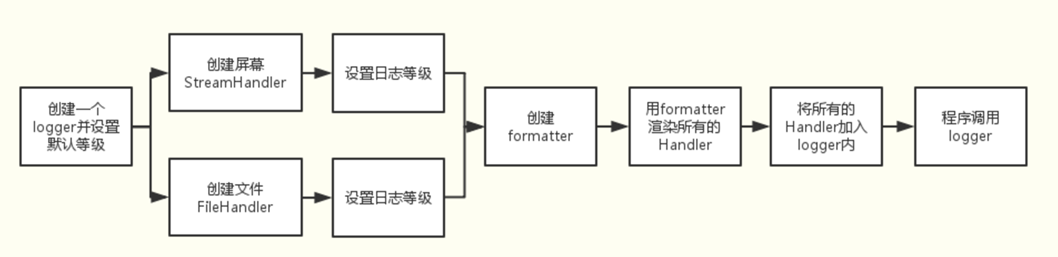
流程图
logging主要包含四种组件:
Loggers:记录器,提供应用程序代码能直接使用的接口。Handlers:处理器,将记录器产生的日志发送至目的地。Filters:过滤器,提供更好的粒度控制,决定哪些日志会被输出。Formatters:格式化器,设置日志内容的组成结构和消息字段。
之间的关系,如图所示:
同时向屏幕和文件进行日志输出的流程:
(实际上,在Java中,我们同时向屏幕和文件进行日志输出的流程,也是这样。)
Loggers(记录器)
logging模块的日志功能是基于Logger类实现的。root logger,并应用默认的日志级别(WARN),默认的处理器StreamHandler,即将日志信息打印在标准输出上,和默认的格式化器Formatter.
logger对象有三大功能:提供应用程序调用的接口、决定日志记录的级别和将日志内容传递到相关联的handlers中。
logger对象的用法:
配置方法:
Logger.setLevel():设置日志记录级别Logger.addHandler()和Logger.removeHandler():为logger对象添加或删除handler处理器对象。Logger.addFilter()和Logger.removeFilter():为为logger对象添加或删除filter过滤器对象。
消息发送:
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():创建对应级别的日志,但不一定会被记录。Logger.exception():创建一个类似Logger.error()的日志消息。不同的是Logger.exception()保存有一个追踪栈。该方法只能在异常handler中调用。Logger.log():显式的创建一条日志,是前面几种方法的通用方法。
注意,getLogger()方法返回一个logger对象的引用,并以你提供的name参数命名,如果未提供名字,那么默认为root。使用同样的name参数,多次调用getLogger(),将返回同样的logger对象。
Handlers(处理器)
Handlers对象是日志信息的处理器、分发器。它们将日志分发到不同的目的地。
比如有时候我们希望将所有的日志都记录在本地文件内,将error及其以上级别的日志发送到标准输出stdout,将critical级别的日志以邮件的方法发送给管理员。这就需要同时有三个独立的handler,分别负责一个方向的日志处理。
logging模块内置了很多的handler处理器,使用较多的有两个:
StreamHandler
FileHandler
handlers对象有下面的方法:
setLevel():和logger对象的一样,设置日志记录级别。那为什么要设置两层日志级别呢?logger对象的日志级别是全局性的,对所有handler都有效,相当于默认等级。而handlers的日志级别只对自己接收到的logger传来的日志有效,进行了更深一层的过滤。
setFormatter():设置当前handler对象使用的消息格式。
addFilter()和removeFilter():配置或删除一个filter过滤对象
Formatter用来最终设置日志信息的顺序、结构和内容。其构造方法为:
1 ft = logging.Formatter.__init__(fmt=None , datefmt=None , style=’%’)
可以使用的logging内置的keys,如下表所示:
属性
格式
描述
asctime%(asctime)s日志产生的时间,默认格式为2003-07-08 16:49:45,896
created%(created)ftime.time()生成的日志创建时间戳
filename%(filename)s生成日志的程序名
funcName%(funcName)s调用日志的函数名
levelname%(levelname)s日志级别
levelno%(levelno)s日志级别对应的数值
lineno%(lineno)d日志所针对的代码行号(如果可用的话)
module%(module)s生成日志的模块名
msecs%(msecs)d日志生成时间的毫秒部分
message%(message)s具体的日志信息
name%(name)s日志调用者
pathname%(pathname)s生成日志的文件的完整路径
process%(process)d生成日志的进程ID(如果可用)
processName%(processName)s进程名(如果可用)
thread%(thread)d生成日志的线程ID(如果可用)
threadName%(threadName)s线程名(如果可用)
Filter过滤器
Handlers和Loggers可以使用Filters来完成比日志级别更复杂的过滤。比如我们定义了filter = logging.Filter(‘a.b.c’),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带a.b.c前缀的Logger才能输出其日志。
配置文件
除了上文的用Python代码设置配置,我们也可以利用配置文件的方式。
创建一个logging配置文件
使用fileConfig()方法读取
示例代码:logging.conf:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [loggers] keys =root,simpleExample [handlers] keys =consoleHandler [formatters] keys =simpleFormatter [logger_root] level =DEBUG handlers =consoleHandler [logger_simpleExample] level =DEBUG handlers =consoleHandler qualname =simpleExample propagate =0 [handler_consoleHandler] class =StreamHandler level =DEBUG formatter =simpleFormatter args =(sys.stdout,) [formatter_simpleFormatter] format =%(asctime)s - %(name)s - %(levelname)s - %(message)s datefmt =
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import logging.configlogging.config.fileConfig('logging.conf' ) logger = logging.getLogger('simpleExample' ) logger.debug('debug message' ) logger.info('info message' ) logger.warning('warn message' ) logger.error('error message' ) logger.critical('critical message' )
运行结果:
1 2 3 4 5 2023-02-01 17:33:29,839 - simpleExample - DEBUG - debug message 2023-02-01 17:33:29,839 - simpleExample - INFO - info message 2023-02-01 17:33:29,839 - simpleExample - WARNING - warn message 2023-02-01 17:33:29,839 - simpleExample - ERROR - error message 2023-02-01 17:33:29,839 - simpleExample - CRITICAL - critical message
多模块中使用日志
如果我们的程序包含多个文件(模块),可以通过如下的方式组织日志。
app.py的示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 import loggingimport myfuncdef main () : logging.basicConfig(filename='myapp.log' , level=logging.INFO) logging.info('Started' ) myfunc.do_something() logging.info('Finished' ) if __name__ == '__main__' : main()
myfunc.py的示例代码:
1 2 3 4 5 import loggingdef do_something () : logging.info('Doing something' )
运行app.py模块,然后我们可以在app.log看到如下的内容:
1 2 3 INFO:root:Started INFO:root:Doing something INFO:root:Finished
SMTP发送邮件
发送邮件的对象
什么是smtplib
Python的smtplib对smtp协议进行了简单的封装,提供了一种很方便的途径发送电子邮件。
创建SMTP对象
Python创建SMTP对象语法如下:
1 2 3 4 5 6 7 import smtplibsmtp_obj = smtplib.SMTP( [host [, port ]] ) smtp_obj = smtplib.SMTP_SSL([host [, port ]])
参数说明:
host:SMTP服务主机地址。port:SMTP服务主机的端口号。
登录方法
调用SMTP对象使用login()登录,语法如下:
1 server.login(sender, password)
参数说明:
sender,发件人邮箱账号。password,发件人邮箱密码。
发送方法
调用SMTP对象使用sendmail()发送邮件,语法如下:
1 smtp_obj.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options])
参数说明:
from_addr:发件人地址。to_addrs:收件人地址,多个用,分隔。msg:发送消息msg的数据类型是字符串,邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意msg字符串的格式。as_string()方法即可。
入门案例
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom email.utils import formataddrsender = '【发件人】' password = '【密码】' receivers = 'i@m.kakawanyifan.com' message = MIMEText('邮件内容' , 'plain' , 'utf-8' ) message['From' ] = formataddr(("发件人" , sender)) message['To' ] = formataddr(("收件人" , receivers)) message['Subject' ] = Header('邮件主题' , 'utf-8' ) smtp_obj = smtplib.SMTP_SSL('smtp.qq.com' ,465 ) smtp_obj.login(sender,password) smtp_obj.sendmail(sender, receivers, message.as_string()) smtp_obj.quit() print('邮件发送成功' )
发送HTML格式的邮件
发送HTML格式的邮件与发送纯文本消息的邮件不同之处就是将MIMEText中_subtype设置为html。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import smtplibfrom email.mime.text import MIMETextfrom email.header import Headerfrom email.utils import formataddrimport pandas as pdsender = '【发件人】' password = '【密码】' receivers = 'i@m.kakawanyifan.com' import pandas as pddf = pd.DataFrame({ 'a' :[1 ,2 ,3 ], 'b' :[11 ,22 ,33 ] }) css = """ .mystyle { font-size: 11pt; font-family: Arial; border-collapse: collapse; border: 1px solid silver; } .mystyle th { padding: 5px; border: 1px solid silver; background: #E0E0E0; } .mystyle td { padding: 5px; border: 1px solid silver; } .mystyle tr:nth-child(even) { background: #F5F5F5; } """ mail_msg = '<style>' + css + '</style>' + '<p>Python 邮件发送测试...</p>' mail_msg = mail_msg + df.to_html(classes='mystyle' ,index=False ) message = MIMEText(mail_msg, 'html' , 'utf-8' ) message['From' ] = formataddr(("发件人" , sender)) message['To' ] = formataddr(("收件人" , receivers)) message['Subject' ] = Header('邮件主题' , 'utf-8' ) smtp_obj = smtplib.SMTP_SSL('smtp.qq.com' ,465 ) smtp_obj.login(sender,password) smtp_obj.sendmail(sender, receivers, message.as_string()) smtp_obj.quit() print('邮件发送成功' )
df.to_html(classes='mystyle'),指定表格的样式为mystylemail_msg = '<style>' + css + '</style>',在HTML中定义样式mystyle
在HTML文本中添加图片
邮件的HTML文本中一般添加外链是无效的,正确添加图片的实例如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import smtplibfrom email.mime.image import MIMEImagefrom email.mime.text import MIMETextfrom email.mime.multipart import MIMEMultipartfrom email.header import Headerfrom email.utils import formataddrsender = '【发件人】' password = '【密码】' receivers = 'i@m.kakawanyifan.com' mail_msg = """ <p>Python 邮件发送测试...</p> <p><a href="https://kakawanyifan.com">这是一个链接</a></p> """ message = MIMEText(mail_msg, 'html' , 'utf-8' ) message['From' ] = formataddr(("发件人" , sender)) message['To' ] = formataddr(("收件人" , receivers)) message['Subject' ] = Header('邮件主题' , 'utf-8' ) msg_alternative = MIMEMultipart('alternative' ) mail_msg = """ <p>Python 邮件发送测试...</p> <p><a href="https://kakawanyifan.com">KakaWanYifan</a></p> <p>图片演示:</p> <p><img decoding="async" src="cid:image1"></p> """ msg_alternative.attach(MIMEText(mail_msg, 'html' , 'utf-8' )) fp = open('IMG_9114.JPG' , 'rb' ) msg_image = MIMEImage(fp.read()) fp.close() msg_image.add_header('Content-ID' , '<image1>' ) message = MIMEMultipart('related' ) message['From' ] = formataddr(("发件人" , sender)) message['To' ] = formataddr(("收件人" , receivers)) message['Subject' ] = Header('邮件主题' , 'utf-8' ) message.attach(msg_alternative) message.attach(msg_image) smtp_obj = smtplib.SMTP_SSL('smtp.qq.com' ,465 ) smtp_obj.login(sender,password) smtp_obj.sendmail(sender, receivers, message.as_string()) smtp_obj.quit() print('邮件发送成功' )
发送带附件的邮件
发送带附件的邮件,需要创建MIMEMultipart()实例,然后构造附件,如果有多个附件,可依次构造。
关于该部分,可以参考《关于弹幕视频网站的例子:基于Serverless的弹幕视频网站实现方案》 的"数据更新"的"跑批脚本"部分,其中对于新的弹幕,会每天凌晨,通过跑批的方式,及时更新;并将弹幕、关键词等以邮件的形式发送。
pickle(序列化)
什么是pickle
pickle,Python专用的持久化模块,只能用于Python环境,不能用作与其它语言进行数据交换,不通用。
主要方法
方法
功能
pickle.dump(obj, file)将Python数据转换并保存到pickle格式的文件内
pickle.dumps(obj)将Python数据转换为pickle格式的bytes字串
pickle.load(file)从pickle格式的文件中读取数据并转换为python的类型
pickle.loads(bytes_object)将pickle格式的bytes字串转换为python的类型
例子
示例代码:
1 2 3 4 5 6 7 8 9 10 import pickledic = {"k1" :"v1" ,"k2" :123 } s = pickle.dumps(dic) print(type(s)) print(s) dic2 = pickle.loads(s) print(type(dic2)) print(dic2)
运行结果:
1 2 3 4 <class 'bytes'> b'\x80\x04\x95\x16\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x02k1\x94\x8c\x02v1\x94\x8c\x02k2\x94K{u.' <class 'dict'> {'k1': 'v1', 'k2': 123}
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pickledata_raw = { 'a' : [1 , 2.0 , 3 , 4 +6 ], 'b' : ("character string" , b"byte string" ), 'c' : {None , True , False } } with open('data.pickle' , 'wb' ) as f: pickle.dump(data_raw, f) with open('data.pickle' , 'rb' ) as f: data = pickle.load(f) print(data)
运行结果:
1 {'a': [1, 2.0, 3, 10], 'b': ('character string', b'byte string'), 'c': {None, True, False}}
dump()方法可以一个接一个将几个对象转储到同一个文件,随后调用load()可以同样的顺序一个一个检索出这些对象。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import picklea1 = 'apple' b1 = {1 : 'One' , 2 : 'Two' , 3 : 'Three' } c1 = ['fee' , 'fie' , 'foe' , 'fum' ] f1 = open('temp.pkl' , 'wb' ) pickle.dump(a1, f1) pickle.dump(b1, f1) pickle.dump(c1, f1) f1.close() f2 = open('temp.pkl' , 'rb' ) a2 = pickle.load(f2) print(a2) b2 = pickle.load(f2) print(b2) c2 = pickle.load(f2) print(c2) f2.close()
运行结果:
1 2 3 apple {1: 'One', 2: 'Two', 3: 'Three'} ['fee', 'fie', 'foe', 'fum']
Pickle可以持久化Python的自定义数据类型,但是在反持久化的时候,必须能够读取到类的定义。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pickleclass Person : def __init__ (self, n, a) : self.name = n self.age = a def show (self) : print(self.name+"_" +str(self.age)) aa = Person("张三" , 20 ) aa.show() f = open('d:\\1.txt' , 'wb' ) pickle.dump(aa, f) f.close() f = open('d:\\1.txt' , 'rb' ) bb = pickle.load(f) f.close() bb.show()
运行结果:
如果我们取消对del Person这一行的注释,在代码中删除了Person类的定义,那么后面的load()方法将会出现错误。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pickleclass Person : def __init__ (self, n, a) : self.name = n self.age = a def show (self) : print(self.name+"_" +str(self.age)) aa = Person("张三" , 20 ) aa.show() f = open('d:\\1.txt' , 'wb' ) pickle.dump(aa, f) f.close() del Personf = open('d:\\1.txt' , 'rb' ) bb = pickle.load(f) f.close() bb.show()
运行结果:
1 2 3 4 5 6 7 8 9 10 11 张三_20 --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[6], line 19 17 del Person 18 f = open('d:\\1.txt', 'rb') ---> 19 bb = pickle.load(f) 20 f.close() 21 bb.show() AttributeError: Can't get attribute 'Person' on
操作MySQL
PyMySQL
简介
PyMySQL,一个第三方的库,用于对MySQL数据库的进行操作。
安装方法:
连接
创建连接
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pymysql import Connectionconn = Connection( host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2022' ) print(conn.get_host_info()) print(conn.get_proto_info()) print(conn.get_server_info()) print(conn.get_autocommit()) conn.close()
运行结果:
1 2 3 4 socket 127.0.0.1:3306 10 8.0.29 False
AutoCommit
我们看到打印的连接信息,最后一项conn.get_autocommit(),自动提交。《MySQL从入门到实践:6.事务》 和《基于Java的后端开发入门:10.JDBC》 ,都有过讨论。这里不赘述。
在PyMySQL中,Connection的构造方法,有一个参数就是autocommit。
指定数据库
在《基于Java的后端开发入门:10.JDBC》 中,我们创建连接的时候,已经指定了数据库。
在创建连接时:利用的是Connection的构造方法的参数database。
在创建连接后:利用的是Connection对象的方法select_db()。
执行
非查询
步骤:
通过连接对象的cursor()方法,得到游标对象。
游标对象.execute()执行SQL语句。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pymysql import Connectionconn = Connection( host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2022' , autocommit=True , database='ssm' ) cursor = conn.cursor() cursor.execute('update book set name = "新名字" where id = 10' ) conn.close()
查询
步骤:
通过连接对象调用cursor()方法,得到游标对象。
游标对象.fetchall()得到全部的查询结果封装入元组内。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pymysql import Connectionconn = Connection( host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2022' , autocommit=True , database='ssm' ) cursor = conn.cursor() cursor.execute('select * from book' ) result = cursor.fetchall() for result_iter in result: print(result_iter) conn.close()
运行结果:
1 2 3 4 5 6 7 8 9 10 (3, '计算机理论', 'Spring 5设计模式', '深入Spring源码刨析Spring源码中蕴含的10大设计模式') (4, '计算机理论', 'Spring MVC+Mybatis开发从入门到项目实战', '全方位解析面向Web应用的轻量级框架,带你成为Spring MVC开发高手') (5, '计算机理论', '轻量级Java Web企业应用实战', '源码级刨析Spring框架,适合已掌握Java基础的读者') (6, '计算机理论', 'Java核心技术 卷Ⅰ 基础知识(原书第11版)', 'Core Java第11版,Jolt大奖获奖作品,针对Java SE9、10、11全面更新') (7, '计算机理论', '深入理解Java虚拟机', '5个纬度全面刨析JVM,大厂面试知识点全覆盖') (8, '计算机理论', 'Java编程思想(第4版)', 'Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉') (9, '计算机理论', '零基础学Java(全彩版)', '零基础自学编程的入门图书,由浅入深,详解Java语言的编程思想和核心技术') (10, '市场营销', '新名字', '李子柒、李佳奇、薇娅成长为网红的秘密都在书中') (11, '市场营销', '直播销讲实战一本通', '和秋叶一起学系列网络营销书籍') (12, '市场营销', '直播带货:淘宝、天猫直播从新手到高手', '一本教你如何玩转直播的书,10堂课轻松实现带货月入3W+')
异步操作MySQL
当通过Python去操作MySQL时,连接、执行SQL、关闭都涉及网络IO请求。可以基于协程,利用asycio异步的方式可以在IO等待时去做一些其他任务,从而提升性能。
(关于"协程",可以参考《4.多线程、协程、多进程》 )
我们需要安装第三方的包: aiomysql
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import asyncioimport aiomysqlasync def execute () : conn = await aiomysql.connect(host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2022' , db='ssm' ) cur = await conn.cursor() await cur.execute("SELECT * FROM book" ) result = await cur.fetchall() print(result) await cur.close() conn.close() asyncio.run(execute())
运行结果:
1 ((3, '计算机理论', 'Spring 5设计模式', '深入Spring源码刨析Spring源码中蕴含的10大设计模式'), (4, '计算机理论', 'Spring MVC+Mybatis开发从入门到项目实战', '全方位解析面向Web应用的轻量级框架,带你成为Spring MVC开发高手'), (5, '计算机理论', '轻量级Java Web企业应用实战', '源码级刨析Spring框架,适合已掌握Java基础的读者'), (6, '计算机理论', 'Java核心技术 卷Ⅰ 基础知识(原书第11版)', 'Core Java第11版,Jolt大奖获奖作品,针对Java SE9、10、11全面更新'), (7, '计算机理论', '深入理解Java虚拟机', '5个纬度全面刨析JVM,大厂面试知识点全覆盖'), (8, '计算机理论', 'Java编程思想(第4版)', 'Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉'), (9, '计算机理论', '零基础学Java(全彩版)', '零基础自学编程的入门图书,由浅入深,详解Java语言的编程思想和核心技术'), (10, '市场营销', '新名字', '李子柒、李佳奇、薇娅成长为网红的秘密都在书中'), (11, '市场营销', '直播销讲实战一本通', '和秋叶一起学系列网络营销书籍'), (12, '市场营销', '直播带货:淘宝、天猫直播从新手到高手', '一本教你如何玩转直播的书,10堂课轻松实现带货月入3W+'))
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncioimport aiomysqlasync def execute (sql) : conn = await aiomysql.connect(host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2022' , db='ssm' ) cur = await conn.cursor() await cur.execute(sql) result = await cur.fetchall() print(result) await cur.close() conn.close() task_list = [ execute('select count(*) from book' ), execute('select count(*) from book2' ) ] asyncio.run(asyncio.wait(task_list))
运行结果:
数据库连接池
例子
假设存在一个Flask项目,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import pymysqlfrom flask import Flaskapp = Flask(__name__) def fetchall (sql) : conn = pymysql.connect(host='127.0.0.1' , port=3306 , user='root' , passwd='MySQL@2023' , db='ft' ) cursor = conn.cursor() cursor.execute(sql) result = cursor.fetchall() cursor.close() conn.close() return result @app.route('/login') def login () : result = fetchall('select * from user' ) return 'login' @app.route('/index') def index () : result = fetchall('select * from user' ) return 'xxx' @app.route('/order') def order () : result = fetchall('select * from user' ) return 'xxx' if __name__ == '__main__' : app.run()
我们看到,在fetchall方法中,频繁的连接数据库,断开连接。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import pymysqlfrom flask import Flaskapp = Flask(__name__) CONN = pymysql.connect(host='127.0.0.1' , port=3306 , user='root' , passwd='MySQL@2023' , db='ft' ) def fetchall (sql) : cursor = CONN.cursor() cursor.execute(sql) result = cursor.fetchall() cursor.close() return result @app.route('/login') def login () : result = fetchall('select * from user' ) return 'login' @app.route('/index') def index () : result = fetchall('select * from user' ) return 'xxx' @app.route('/order') def order () : result = fetchall('select * from user' ) return 'xxx' if __name__ == '__main__' : app.run()
dbutils
dbutils,Python中的数据库连接池工具,类似于我们在《基于Java的后端开发入门:10.JDBC》 讨论的Druid和HikariCP。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import pymysqlfrom dbutils.pooled_db import PooledDBPOOL = PooledDB( creator=pymysql, maxconnections=6 , mincached=2 , blocking=True , ping=0 , host='127.0.0.1' , port=3306 , user='root' , password='MySQL@2023' , database='ft' , charset='utf8' ) conn = POOL.connection() cursor = conn.cursor() cursor.execute('select * from t1' ) result = cursor.fetchall() cursor.close() conn.close() print(result)
在有些资料import PooledDB写的是from DBUtils.PooledDB import PooledDB,这时候可能会报DBUtils这个包不存在的错误。 实际上,from DBUtils.PooledDB import PooledDB,是DBUtils的1版本的写法。在2版本和3版本,方法如下:
1 from dbutils.pooled_db import PooledDB
SQLAlchemy
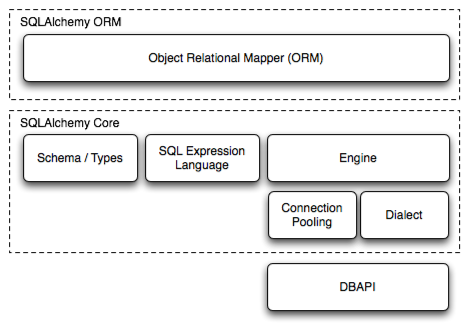
SQLAlchemy,是一个用于Python的SQL工具和对象关系映射(ORM)库。
对比Java中的概念,我们很容易理解这是什么。
类别
Java
Python
数据库驱动
JDBC规范的各类驱动
类似PyMySQL的各类驱动
ORM库
Hibernate
SQLAlchemy
其架构结构如图:
安装SQLAlchemy
创建连接
SQLAlchemy中使用create_engine来创建连接(池),create_engine()的入参是数据库的URL。
1 2 3 4 from sqlalchemy import create_engineurl = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/demo' engine = create_engine(url)
解释一下URL部分:
mysql:SQL方言。(关于什么是SQL方言,可以参考《MySQL从入门到实践:1.概述和工具准备》 的"SQL"部分)pymysql:数据库驱动root:用户名MySQL%4001:密码,实际密码是MySQL@2023,@符号被转义了127.0.0.1:地址3306:端口demo:库名
即,连接如下:
1 【方言】+【驱动】://【用户名】:【密码】@【地址】:【端口】/【数据库】
直接使用SQL
开始
示例代码:
1 2 3 4 5 6 7 8 9 10 from sqlalchemy import create_enginefrom sqlalchemy import texturl = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/demo' engine = create_engine(url) with engine.connect() as conn: result = conn.execute(text("select * from users" )) print(result.all())
运行结果:
1 [(None, 'kaka', '123456'), (None, 'kaka', '123456')]
查询结果遍历
可以对result进行遍历,每一个行结果是一个Row对象。示例代码:
1 2 3 for row in result: print(row.username, row.password) print(row[1 ], row[2 ])
传递参数
传递参数,使用:var。示例代码:
1 2 3 4 5 6 result = conn.execute( text('SELECT * FROM users WHERE username = :y' ), {'y' : 'Kaka' } ) print(result.all())
示例代码:
1 2 3 4 5 stmt = text("SELECT * FROM users WHERE password = :y" ).bindparams(y=123456 ) result = conn.execute(stmt) print(result.all())
事务与commit
SQLAlchemy提供三种提交的方式:
手工commit
半自动commit,官方文档建议。
完全自动的,每一行提交一次的autocommit方式,不建议使用。
手工commit,示例代码:
1 2 3 4 5 6 7 8 with engine.connect() as conn: conn.execute(text("CREATE TABLE some_table (x int, y int)" )) conn.execute( text("INSERT INTO some_table (x, y) VALUES (:x, :y)" ), [{"x" : 1 , "y" : 1 }, {"x" : 2 , "y" : 4 }] ) conn.commit()
半自动commit,示例代码:
1 2 3 4 5 with engine.begin() as conn: conn.execute( text("INSERT INTO some_table (x, y) VALUES (:x, :y)" ), [{"x" : 6 , "y" : 8 }, {"x" : 9 , "y" : 10 }] )
数据模型
使用方法
__tablename__,指定数据库表名。Column,声明每个字段。Integer/String...,指定字段类型。index,指定索引。unique,指定唯一索引。__table_args__,指定其他属性,比如联合索引。
例子
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from sqlalchemy import Integer, Column, String, func, UniqueConstraintfrom sqlalchemy import create_engine, DateTime, Textfrom sqlalchemy.orm import declarative_base, deferredurl = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/demo' engine = create_engine(url) Base = declarative_base() class U (Base) : __tablename__ = "u" __table_args__ = (UniqueConstraint("name" , "time_created" ),) id = Column(Integer, primary_key=True ) name = Column(String(30 ), index=True ) fullname = Column(String(50 ), unique=True ) description = deferred(Column(Text)) time_created = Column(DateTime(timezone=True ), server_default=func.now()) time_updated = Column(DateTime(timezone=True ), onupdate=func.now()) U.__table__.create(engine)
关联关系
什么是关联关系
关联关系是指数据库中多个表的数据之间的相互依赖关系,常见的关联关系有:
在SQLAlchemy的数据模型中,还可以使用relationship函数定义关联关系,relationship函数的常用参数如下:
argumentargument参数名,直接在第一个参数位置指定数据模型类名称。backrefuselistTrue。remote_sidesecondaryback_populatescascade
一对一关系
一对一关系就是表A中的一条记录对应表B中的唯一一条记录,在SQLAlchemy中用代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from sqlalchemy import Integer, Columnfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy.orm import relationshipBase = declarative_base() class User (Base) : __table_name__ = 'user' id = Column(Integer, primary_key=True ) account = relationship('Account' , uselist=False , backref='account' )
解释说明:uselist=False,建立一对一的关系。
一对多、多对一关系
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, ForeignKey, String, DateTimefrom sqlalchemy.orm import relationshipBase = declarative_base() class User (Base) : __tablename__ = 'user' id = Column(Integer, primary_key=True ) name = Column('name' , String(50 )) bookrecords = relationship('BookRecord' , backref='user' ) class BookRecord (Base) : __tablename__ = 'book_record' id = Column(Integer, primary_key=True ) book_name = Column('book_name' , String(50 )) borrow_time = Column('borrow_time' , DateTime) user_id = Column(Integer, ForeignKey('user.id' ))
在上文代码中,定义了两个数据模型类:User、BookRecord。User类中包含字段bookrecords,使用relationship函数,与数据模型类BookRecord建立一对多关系;其中backref参数在BookRecord中增加反向引用并命名为user,其作用是在BookRecord类的每个实例上增加一个user字段,指向User类的实例。BookRecord类中的字段user_id使用 ForeignKey定义了外键指向user表id字段,BookRecord类通过外键的方式与User类形成了多对一关系。
多对多关系
多对多关系一般需要一个中间表,中间表的两个字段分别指向另外两张表中的字段。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, ForeignKey, Table, Stringfrom sqlalchemy.orm import relationshipBase = declarative_base() user_action_rel = Table( 'user_action_rel' , Base.metadata, Column('user_id' , Integer, ForeignKey('user.id' )), Column('action_id' , Integer, ForeignKey('action.id' )) ) class User (Base) : __tablename__ = 'user' id = Column(Integer, primary_key=True ) name = Column('name' , String(50 )) actions = relationship('Action' , secondary=user_action_rel, backref='user' ) class Action (Base) : __tablename__ = 'action' id = Column(Integer, primary_key=True ) name = Column('name' , String(50 )) users = relationship('User' , secondary=user_action_rel, backref='actions' )
上文代码中,定义了两个数据模型类,User、Action,另外通过SQLAlchemy提供的Table类创建了实例,用来定义中间表user_action_rel。user_action_rel中的两个字段user_id、action_id,分别以外键的形式关联到User、Action数据模型的字段上;两个数据模型中,都使用 relationship函数的secondary参数指定了中间表。User和Action形成了多对多的关系。
CRUD
查询
where
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from sqlalchemy import Integer, Column, String, func, UniqueConstraintfrom sqlalchemy import create_engine, DateTime, Textfrom sqlalchemy.orm import declarative_base, deferred, Sessionfrom sqlalchemy import selecturl = 'mysql+pymysql://root:MySQL%4001@127.0.0.1:3306/demo' engine = create_engine(url) Base = declarative_base() class U (Base) : __tablename__ = "u" __table_args__ = (UniqueConstraint("name" , "time_created" ),) id = Column(Integer, primary_key=True ) name = Column(String(30 ), index=True ) fullname = Column(String(50 ), unique=True ) description = deferred(Column(Text)) time_created = Column(DateTime(timezone=True ), server_default=func.now()) time_updated = Column(DateTime(timezone=True ), onupdate=func.now()) with Session(engine) as session: stmt = select(U).where(U.name == "john" ).order_by(U.id) result = session.execute(stmt) print(result.all())
filter_by
filter_by使用**kwargs作为参数,示例代码:
1 stmt = select(User).filter_by(name="some_user" )
scalars
一般情况下,当选取整个对象的时候,都要用scalars方法,否则返回的是一个包含一个对象的tuple。示例代码:
1 2 for user in result.scalars(): print(user.name)
查询模型单个属性时,不需要使用scalars。示例代码:
1 2 3 result = session.execute(select(User.name)) for row in result: print(row.name)
根据id查询的快捷方式
1 user = session.get(User, pk=1 )
更新
update
更新数据需要使用update语句,示例代码:
1 from sqlalchemy import update
synchronize_session
synchronize_session有三个选项:
false,完全不更新Python中的对象。fetch,重新从数据库中加载一份对象。evaluate,在更新数据库的同时,也尽量在Python中的对象上使用同样的操作。evaluate。示例代码:
1 2 stmt = update(User).where(User.name == "john" ).values(name="John" ).execution_options(synchronize_session="fetch" ) session.execute(stmt)
直接对属性赋值,示例代码:
1 2 user.name = "John" session.commit()
新增
add
添加对象使用session.add方法。示例代码:
add_all
add_all。示例代码:
1 session.add_all([user1, user2])
删除
删除使用session.delete,示例代码:
批量
bulk_save_objects
使用session.bulk_save_objects直接插入多个对象,示例代码:
1 2 3 4 5 6 7 8 s = Session() objects = [ User(name="u1" ), User(name="u2" ), User(name="u3" ) ] s.bulk_save_objects(objects) s.commit()
bulk_insert_mappings
使用bulk_insert_mappings可以省去创建对象的开销,直接插入字典,示例代码:
1 2 3 4 5 6 7 users = [ {"name" : "u1" }, {"name" : "u2" }, {"name" : "u3" }, ] s.bulk_insert_mappings(User, users) s.commit()
bulk_update_mappings
使用bulk_update_mappings可以批量更新对象,字典中的id会被用作where条件。
问题解决
_cffi_backend
如果在运行过程中提示:
1 ModuleNotFoundError: No module named '_cffi_backend'
删除Python环境的site-packages中以cffi开头的两个,cffi和cffi-1.15.1.dist-info,然后重新安装cffi。