日志
六种日志
MySQL有不同类型的日志文件,用来存储不同类型的日志,最常用的有4种:
慢查询日志long_query_time设置值并且扫描记录数不小于min_examined_row_limit的所有的SQL语句的日志min_examined_row_limit",在实践中,这个参数确实一般不用,默认为0。)
通用查询日志
错误日志
二进制日志
在8版本中新增了两种日志:
中继日志
数据定义语句日志
其中,除二进制日志和中继日志外,其他日志都是文本文件。默认情况下,所有日志创建于MySQL数据目录中。
有些日志如果不需要的话,可以选择关闭,因为大量的记录日志,存在两个弊端:
降低MySQL数据库的性能
占用大量的磁盘空间
慢查询日志
慢查询日志,slow query log,关于该部分,我们在《5.索引和优化》 已经讨论过了。
通用查询日志
什么是通用查询日志
通用查询日志,general query log,记录用户的所有操作,包括启动和停止MySQL服务、连接的开始时间和截止时间、发给MySQL服务的所有SQL指令等。
在发生异常时,可以查看通用查询日志,还原操作时的具体场景,帮助我们准确定位问题。
管理
查看日志状态
通过show variables like '%general%';,查看通用查询日志的状态。示例代码:
1 show variables like '%general%' ;
运行结果:
1 2 3 4 5 6 +------------------+---------------------------------+ | Variable_name | Value | +------------------+---------------------------------+ | general_log | OFF | | general_log_file | /var/lib/mysql/centos-linux.log | +------------------+---------------------------------+
开启日志
永久性方式
修改my.cnf或者my.ini配置文件,在[mysqld]组下加入log选项,并重启MySQL服务。
格式如下:
1 2 3 4 5 6 7 [mysqld] general_log =1 general_log_file =mysql_query.log
临时性方式
开启通用查询日志:
1 SET GLOBAL general_log=on ;
设置日志文件保存位置:
1 SET GLOBAL general_log_file=’path /filename’;
关闭日志
永久性方式
修改my.cnf或者my.ini文件,把[mysqld]组下的general_log值注释掉,或者设置为OFF。修改保存后,再重启MySQL服务,即可生效。
1 2 3 [mysqld] # general_log=ON general_log=OFF
临时性方式
使用SET语句关闭MySQL通用查询日志功能。
1 SET GLOBAL general_log=off ;
查看日志
通用查询日志是文本文件,在查看日志方面没有任何不同。需要注意的是时间,我们需要在原本的时间上,加上8小时。
1 2 3 4 5 6 7 8 9 10 2023-10-01T07:37:37.169489Z 16 Query SET net_write_timeout=60 2023-10-01T07:37:37.171759Z 16 Query SHOW WARNINGS 2023-10-01T07:37:37.173306Z 16 Query SHOW WARNINGS 2023-10-01T07:37:37.174006Z 16 Query /* ApplicationName=DataGrip 2023.1.2 */ SET net_write_timeout=600 2023-10-01T07:37:37.174361Z 16 Query /* ApplicationName=DataGrip 2023.1.2 */ select Host, User, Routine_name, Proc_priv, Routine_type = 'PROCEDURE' as is_proc from mysql.procs_priv where Db = 's' 2023-10-01T07:37:37.174839Z 16 Query SET net_write_timeout=60 2023-10-01T07:37:37.177129Z 16 Query SHOW WARNINGS 2023-10-01T07:37:37.178791Z 16 Query SHOW WARNINGS 2023-10-01T07:37:37.179608Z 16 Query /* ApplicationName=DataGrip 2023.1.2 */ SET net_write_timeout=600 2023-10-01T07:37:37.180242Z 16 Query /* ApplicationName=DataGrip 2023.1.2 */ select grantee, table_name, column_name, privilege_type, is_grantable from information_schema.column_privileges where table_schema = 's' union all select grantee, table_name, '' column_name, privilege_type, is_grantable from information_schema.table_privileges where table_schema = 's' order by table_name, grantee, privilege_type
删除日志
如果数据的使用非常频繁,那么通用查询日志会占用非常大的磁盘空间。我们可以删除很长时间之前的查询日志,以保证MySQL服务器上的硬盘空间。
通过show variables like '%general%';可以查看通用查询日志所在的目录,然后手动删除即可。
备份日志
步骤如下:
进入日志目录
将旧日志复制出来或者改名
刷新1 mysqladmin -uroot -p flush-logs
错误日志
管理
在MySQL中,错误日志功能是必须开启的,无法被禁止。
查看日志位置,示例代码:
1 show variables like '%log_error%' ;
运行结果:
1 2 3 4 5 6 7 8 9 +----------------------------+----------------------------------------+ | Variable_name | Value | +----------------------------+----------------------------------------+ | binlog_error_action | ABORT_SERVER | | log_error | /var/log/mysqld.log | | log_error_services | log_filter_internal; log_sink_internal | | log_error_suppression_list | | | log_error_verbosity | 2 | +----------------------------+----------------------------------------+
如果需要自定义文件名,可以在my.cnf或者my.ini添加如下配置:
1 2 3 4 [mysqld] log-error =[path/[filename]]
查看日志
(和上文通用查询日志的查看没有区别)
删除日志
(和上文通用查询日志的删除没有区别)
备份日志
现象
备份日志,来吧。
1 mv mysqld.log mysqld.log.bak
第二步,刷新:
1 mysqladmin -uroot -p flush-logs
运行结果:
1 mysqladmin: refresh failed; error: 'Could not open file '/var/log/mysqld.log' for error logging.'
报错了!
如果我们通过ll命令检查,会发现,没有/var/log/mysqld.log这个文件。
原因
在5.5.7之前的版本,flush-logs会将错误日志文件重命名为filename-err_old,并创建新的日志文件。
从MysQL5.5.7开始,flush-logs只会重新打开日志文件,并不做日志备份和创建的操作。
因为/var/log/mysqld.log不存在,所以会报错。
解决
解决方法为,在flush-logs之前,执行
1 install -omysql -gmysql -m0644 /dev/null /var/log/mysqld.log
然后再执行mysqladmin -uroot -p flush-logs。
中继日志
什么是中继日志
中继日志,relay log,只在主从服务器架构的从服务器上存在,日志默认会保存在从服务器的数据目录下。从服务器名-relay-bin.序号,中继日志还有一个索引文件:从服务器名-relay-bin.index,用来定位当前正在使用的中继日志。
如果想理解中继日志在主从复制中发挥的作用,就必须先理解什么是主从复制,可以参考下文关于主从复制的讨论,这里暂时只讨论中继日志本身。
查看中继日志
中继日志也是二进制的,可以用mysqlbinlog工具查看。
如下,是中继日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # The proper term is pseudo_replica_mode, but we use this compatibility alias # to make the statement usable on server versions 8.0.24 and older. /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; # at 4 #231001 15:36:05 server id 2 end_log_pos 126 CRC32 0x7c5de2b8 Start: binlog v 4, server v 8.0.34 created 231001 15:36:05 # This Format_description_event appears in a relay log and was generated by the replica thread. # at 126 #231001 15:36:05 server id 2 end_log_pos 157 CRC32 0x2a83bb6f Previous-GTIDs # [empty] # at 157 #700101 8:00:00 server id 1 end_log_pos 0 CRC32 0x25330355 Rotate to binlog.000006 pos: 685 # at 201 #231001 15:31:27 server id 1 end_log_pos 0 CRC32 0xa173bb4f Start: binlog v 4, server v 8.0.34 created 231001 15:31:27 BINLOG ' TyAZZQ8BAAAAegAAAAAAAAAAAAQAOC4wLjM0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAEwANAAgAAAAABAAEAAAAYgAEGggAAAAICAgCAAAACgoKKioAEjQA CigAAU+7c6E= '/*!*/;
一种错误
如果服务器宕机,发生了严重的错误,甚至需要重装操作系统。在这种场景下,可能会导致服务器名称与之前的不同。
二进制日志
介绍
二进制日志,binlog,binary log,二进制日志文件,也被称作变更日志(update log)。记录了数据库所有的DDL和DML等语句,但是不包含没有修改任何数据的语句(如数据查询语句select、show等)。
二进制日志的主要应用场景:
数据恢复
主从复制
管理
查看日志状态
在MySQL8版本中,默认二进制日志是开启着的。
可以通过如下的命令,查看记录二进制日志的状态:
1 show variables like '%log_bin%' ;
运行结果:
1 2 3 4 5 6 7 8 9 10 +---------------------------------+-----------------------------+ | Variable_name | Value | +---------------------------------+-----------------------------+ | log_bin | ON | | log_bin_basename | /var/lib/mysql/binlog | | log_bin_index | /var/lib/mysql/binlog.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+-----------------------------+
解释说明:
log_bin:二进制日志的状态,ON表示是开启的。log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名会在该basename的基础上加上编号(从000001开始)。log_bin_index:binlog的索引文件,记录了当前服务器关联的binlog文件有哪些。
开启日志
永久性方式
修改MySQL的my.cnf或my.ini文件,添加如下内容可以设置二进制日志的相关参数。修改保存后,再重启MySQL服务,即可生效。
1 2 3 4 5 [mysqld] log-bin =mysql-kaka-bin binlog_expire_logs_seconds =600 max_binlog_size =100M
解释说明:
log-bin=mysql-kaka-bin,打开日志并定义基础名称。也可以加上路径,例如:/home/www/mysql_bin_log/mysq-binbinlog_expire_1ogs_seconds,二进制日志文件保留的时长,单位是秒,默认2592000即30天。max_binlog_size:单个二进制日志大小,当前日志文件大小超过此变量时,执行切换动作,此参数的最大和默认值是1GB。修改保存后,再重启MySQL服务,即可生效。
题外话,上述配置定义了日志三个属性,名称、过期时间和文件大小。不仅仅MySQL如此,我们自己写代码的时候,也是专这样,例如在SpringBoot中和日志相关的三个参数:max-file-size: 10MB,文件最大10MB;file-name-pattern: server.%d{yyyyMMdd}.%i.log,文件名格式,%d{yyyyMMdd}日期,%i序号;max-history: 365,最多保留365天的日志。
关闭日志
永久性方式
修改MySQL的my.cnf或my.ini文件,添加如下配置,重启实例即可关闭二进制日志。
MySQL官方的配置文件,又如下一段,添加disable_log_bin即可关闭二进制日志。
有些资料会说添加skip-log-bin关闭二进制日志,在我的实测中,发现这种方法也可以。
注意
如果指定了上述选项,同时还指定了log-bin,则后面指定的选项log-bin优先。log-bin设置的后面才能真正生效。
临时性方式
1 2 3 4 5 set global sql_log_bin=0 ;SET sql_log_bin=0 ;
分磁盘存储
注意,不建议把数据库文件和日志文件放在同一个磁盘上。 这样的话,即使某一块磁盘出现了故障,影响有限,而且可以恢复。
例如,在下文中,我们将binlog文件放在/var/lib/mysql目录下,my.cnf或my.ini中的log_bin参数修改如下:
1 2 [mysqld] log-bin ="/var/lib/mysql/binlog/kaka-bin"
然后,一定要给mysql用户进行授权,可以使用下面的命令:
1 chown mysql:mysql -R binlog
关于chown的更多用法,可以参考《Linux操作系统使用入门:2.命令》 。
mysqlbinlog
语法
日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具mysqlbinlog来查看。
具体语法如下:
1 mysqlbinlog [参数选项] logfilename
参数选项:
-d:指定数据库名称,只列出指定的数据库相关操作。-o:忽略掉日志中的前n行命令。-v:将行事件(数据变更)重构为SQL语句。-vv:将行事件(数据变更)重构为SQL语句,并输出注释信息。
例子
假设存在一张表t,我们执行SQL如下:
1 update t set c3 = 10 + c3;
通过mysqlbinlog binlog.000001,查看二进制日志,没有找到相关的SQL。
1 mysqlbinlog binlog.000001
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # The proper term is pseudo_replica_mode, but we use this compatibility alias # to make the statement usable on server versions 8.0.24 and older. /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; 【部分运行结果略】 BINLOG ' cKgSZRMBAAAALgAAAFUKAAAAAKQAAAAAAAEAAXMAAXQAAwMDAwAHAQEAa6gbOQ== cKgSZR8BAAAAcgAAAMcKAAAAAKQAAAAAAAEAAgAD//8AAQAAAAEAAAABAAAAAAEAAAABAAAACwAA AAACAAAAAgAAAAIAAAAAAgAAAAIAAAAMAAAAAAMAAAADAAAAAwAAAAADAAAAAwAAAA0AAADM7lgr '/*!*/; # at 2759 #230926 17:46:24 server id 1 end_log_pos 2790 CRC32 0x8fa58839 Xid = 986 COMMIT/*!*/; SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
如果加上参数-v的话,就可以看到SQL了。示例代码:
1 mysqlbinlog -v binlog.000001
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 【部分运行结果略】 BINLOG ' cKgSZRMBAAAALgAAAFUKAAAAAKQAAAAAAAEAAXMAAXQAAwMDAwAHAQEAa6gbOQ== cKgSZR8BAAAAcgAAAMcKAAAAAKQAAAAAAAEAAgAD//8AAQAAAAEAAAABAAAAAAEAAAABAAAACwAA AAACAAAAAgAAAAIAAAAAAgAAAAIAAAAMAAAAAAMAAAADAAAAAwAAAAADAAAAAwAAAA0AAADM7lgr '/*!*/; ### UPDATE `s`.`t` ### WHERE ### @1=1 ### @2=1 ### @3=1 ### SET ### @1=1 ### @2=1 ### @3=11 ### UPDATE `s`.`t` ### WHERE ### @1=2 ### @2=2 ### @3=2 ### SET ### @1=2 ### @2=2 ### @3=12 ### UPDATE `s`.`t` ### WHERE ### @1=3 ### @2=3 ### @3=3 ### SET ### @1=3 ### @2=3 ### @3=13 # at 2759 #230926 17:46:24 server id 1 end_log_pos 2790 CRC32 0x8fa58839 Xid = 986 COMMIT/*!*/; SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
特别的,如果我们修改日志格式为STATEMENT,再执行一次更新,示例代码:
1 update t set c2 = 10 + c2;
然后再查看日志,能看到原始的SQL语句。示例代码:
1 mysqlbinlog binlog.000002
运行结果:
1 2 3 4 5 6 7 8 9 【部分运行结果略】 #230926 18:10:55 server id 1 end_log_pos 466 CRC32 0xe842db66 Query thread_id=8 exec_time=0 error_code=0 use `s`/*!*/; SET TIMESTAMP=1695723055/*!*/; /* ApplicationName=DataGrip 2023.1.2 */ update t set c2 = 10 + c2 【部分运行结果略】
解释说明:
修改日志格式后,会起一个新的日志文件binlog.000002。因为日志格式变了,所以MySQL开启了新的binlog,不在原文件上继续记录。
不同日志格式,主要对主从复制有影响。我们会在主从复制部分,更详细的讨论。
使用日志恢复数据
恢复数据的命令
语法如下:
1 mysqlbinlog [option] 【binlog日志】|mysql 【库】 –u【用户名】 -p【密码】;
这个命令的含义是:使用mysqlbinlog命令来读取filename中的内容,然后使用mysql命令将这些内容恢复到数据库中。
相关参数有:
--database,指定库--start-date和--stop-date:可以指定恢复数据库的起始时间点和结束时间点。--start-position和--stop-position:可以指定恢复数据的开始位置和结束位置。
查看Pos
查看到pos点信息,除了翻阅日志,有一种更为方便的查询命令:
1 show binlog events [IN 'log_name' ] [FROM pos] [LIMIT [offset ,] row_count ];
参数:
IN 'log_name':指定要查询的binlog文件名,不指定就是第一个binlog文件。FROM pos:指定从哪个pos起始点开始查起,不指定就是从整个文件首个pos点开始算。LIMIT [offset]:偏移量,不指定就是0row_count:查询总条数,不指定就是所有行。
示例代码:
1 show binlog events IN 'mysql-kaka-bin.000001' ;
运行结果:
1 2 3 4 5 6 7 8 9 10 11 +-----------------------+-----+----------------+-----------+-------------+--------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+-----+----------------+-----------+-------------+--------------------------------------+ | mysql-kaka-bin.000001 | 4 | Format_desc | 1 | 126 | Server ver: 8.0.34, Binlog ver: 4 | | mysql-kaka-bin.000001 | 126 | Previous_gtids | 1 | 157 | | | mysql-kaka-bin.000001 | 157 | Anonymous_Gtid | 1 | 236 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000001 | 236 | Query | 1 | 308 | BEGIN | | mysql-kaka-bin.000001 | 308 | Table_map | 1 | 361 | table_id: 89 (s.t) | | mysql-kaka-bin.000001 | 361 | Write_rows | 1 | 401 | table_id: 89 flags: STMT_END_F | | mysql-kaka-bin.000001 | 401 | Xid | 1 | 432 | COMMIT /* xid=11 */ | +-----------------------+-----+----------------+-----------+-------------+--------------------------------------+
案例
假设,现在存在一张表,我们先往表中插入了10条数据:
1 2 3 4 5 6 7 8 9 10 INSERT INTO t (c) VALUES (1 )INSERT INTO t (c) VALUES (2 )INSERT INTO t (c) VALUES (3 )INSERT INTO t (c) VALUES (4 )INSERT INTO t (c) VALUES (5 )INSERT INTO t (c) VALUES (6 )INSERT INTO t (c) VALUES (7 )INSERT INTO t (c) VALUES (8 )INSERT INTO t (c) VALUES (9 )INSERT INTO t (c) VALUES (10 )
然后再删除了一条数据:
1 DELETE FROM t WHERE c = 10
再错误的执行了一个不带WHERE条件的DELETE,把表中的数据都删除了。
现在,我们要把数据恢复。
首先我们找到指定的Pos,示例代码:
1 show binlog events IN 'mysql-kaka-bin.000002' ;
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 +-----------------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------+ | mysql-kaka-bin.000002 | 4 | Format_desc | 1 | 126 | Server ver: 8.0.34, Binlog ver: 4 | | mysql-kaka-bin.000002 | 126 | Previous_gtids | 1 | 157 | | | mysql-kaka-bin.000002 | 157 | Anonymous_Gtid | 1 | 234 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000002 | 234 | Query | 1 | 389 | use `s`; /* ApplicationName=DataGrip 2023.1.2 */ create table t( c int null) /* xid=178 */ | | mysql-kaka-bin.000002 | 389 | Anonymous_Gtid | 1 | 468 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000002 | 468 | Query | 1 | 540 | BEGIN | | mysql-kaka-bin.000002 | 540 | Table_map | 1 | 584 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 584 | Write_rows | 1 | 624 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 624 | Table_map | 1 | 668 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 668 | Write_rows | 1 | 708 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 708 | Table_map | 1 | 752 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 752 | Write_rows | 1 | 792 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 792 | Table_map | 1 | 836 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 836 | Write_rows | 1 | 876 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 876 | Table_map | 1 | 920 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 920 | Write_rows | 1 | 960 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 960 | Table_map | 1 | 1004 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1004 | Write_rows | 1 | 1044 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1044 | Table_map | 1 | 1088 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1088 | Write_rows | 1 | 1128 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1128 | Table_map | 1 | 1172 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1172 | Write_rows | 1 | 1212 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1212 | Table_map | 1 | 1256 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1256 | Write_rows | 1 | 1296 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1296 | Xid | 1 | 1327 | COMMIT /* xid=347 */ | | mysql-kaka-bin.000002 | 1327 | Anonymous_Gtid | 1 | 1406 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000002 | 1406 | Query | 1 | 1478 | BEGIN | | mysql-kaka-bin.000002 | 1478 | Table_map | 1 | 1522 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1522 | Write_rows | 1 | 1562 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1562 | Xid | 1 | 1593 | COMMIT /* xid=399 */ | | mysql-kaka-bin.000002 | 1593 | Anonymous_Gtid | 1 | 1672 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000002 | 1672 | Query | 1 | 1744 | BEGIN | | mysql-kaka-bin.000002 | 1744 | Table_map | 1 | 1788 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 1788 | Delete_rows | 1 | 1828 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 1828 | Xid | 1 | 1859 | COMMIT /* xid=427 */ | | mysql-kaka-bin.000002 | 1859 | Anonymous_Gtid | 1 | 1938 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-kaka-bin.000002 | 1938 | Query | 1 | 2010 | BEGIN | | mysql-kaka-bin.000002 | 2010 | Table_map | 1 | 2054 | table_id: 107 (s.t) | | mysql-kaka-bin.000002 | 2054 | Delete_rows | 1 | 2134 | table_id: 107 flags: STMT_END_F | | mysql-kaka-bin.000002 | 2134 | Xid | 1 | 2165 | COMMIT /* xid=473 */ | +-----------------------+------+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------+
根据上述我们的操作步骤,我们可以知道:
从第468个Pos到第1562个Pos,都是INSERT操作。
从第1593个Pos到第1828个Pos,是我们删除一行的操作。
从第1859个Pos到第2134个Pos,是我们错误的删除所有行的操作。
所以,我们应该恢复从第468个Pos到第1859个Pos的所有操作。示例代码:
1 mysqlbinlog --start-position=468 --stop-position=1859 --database=s mysql-kaka-bin.000002 | mysql s -uroot -p;
注意开闭区间,--stop-position的值应该是下一个事务开始时的Pos。
题外话
通过上述操作,我们可以深刻的感受到:
二进制日志可以通过数据库的"全量备份"和二进制日志中保存的"增量信息",完成数据库的"无损失恢复"。 但是,如果遇到数据量大、数据库和数据表很多(比如分库分表的应用)的场景,用二进制日志进行数据恢复,是很有挑战性的,因为起止位置不容易管理。
删除二进制日志
删除指定日志
PURGE MASTER LOGS,删除指定日志文件,语法如下:
PURGE {MASTER I BINARY} LOGS TO '指定日志文件名'PURGE {MASTER I BINARY} LOGS BEFORE 指定日期
删除mysql-kaka-bin.000002之前,不含mysql-kaka-bin.000002的日志文件,示例代码:
1 purge master logs to 'mysql-kaka-bin.000002' ;
我们可以通过show binary logs;,比较一下删除前后的日志。
删除所有日志
RESET MASTER,删除所有二进制日志文件。
题外话
从删库到跑路,感觉自己还有回头路,怎么办?RESET MASTER,这样指定是没有回头路了。
二进制日志进阶
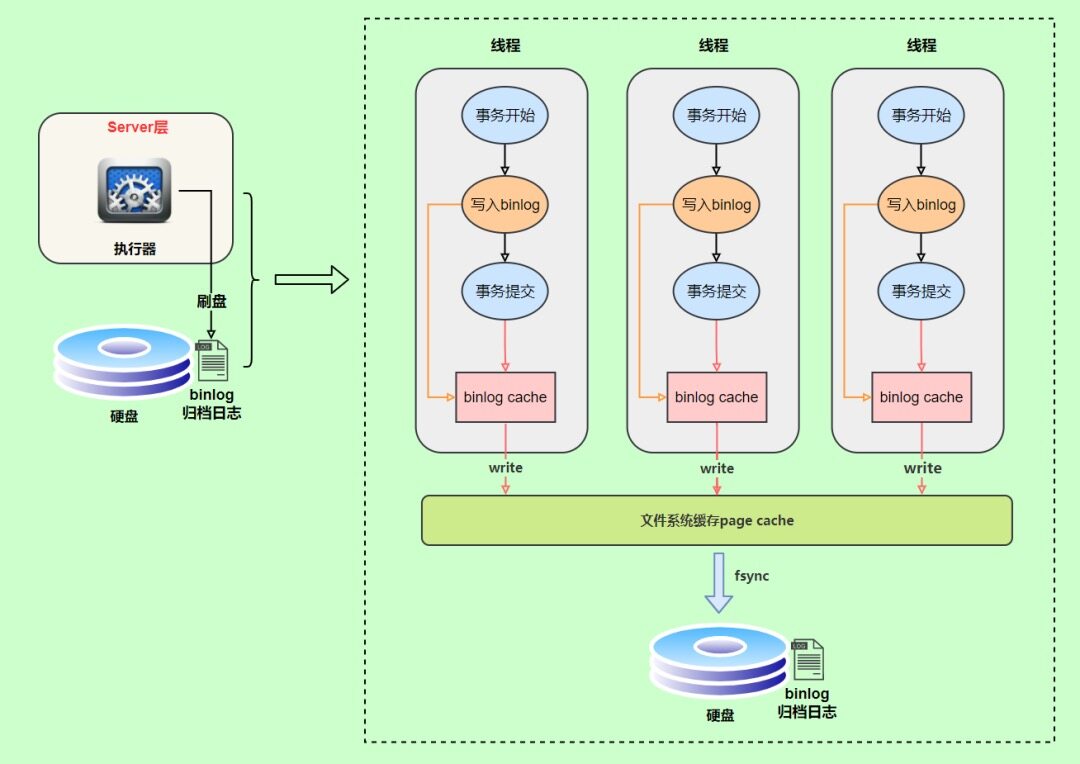
写入机制
在事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。
注意:
一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入。
系统会给每个线程分配一个块内存作为binlog cache,我们可以通过binlog_cache_size参数控制单个线程binlog cache大小,如果存储内容超过了这个参数,就要暂存到磁盘(swap)。
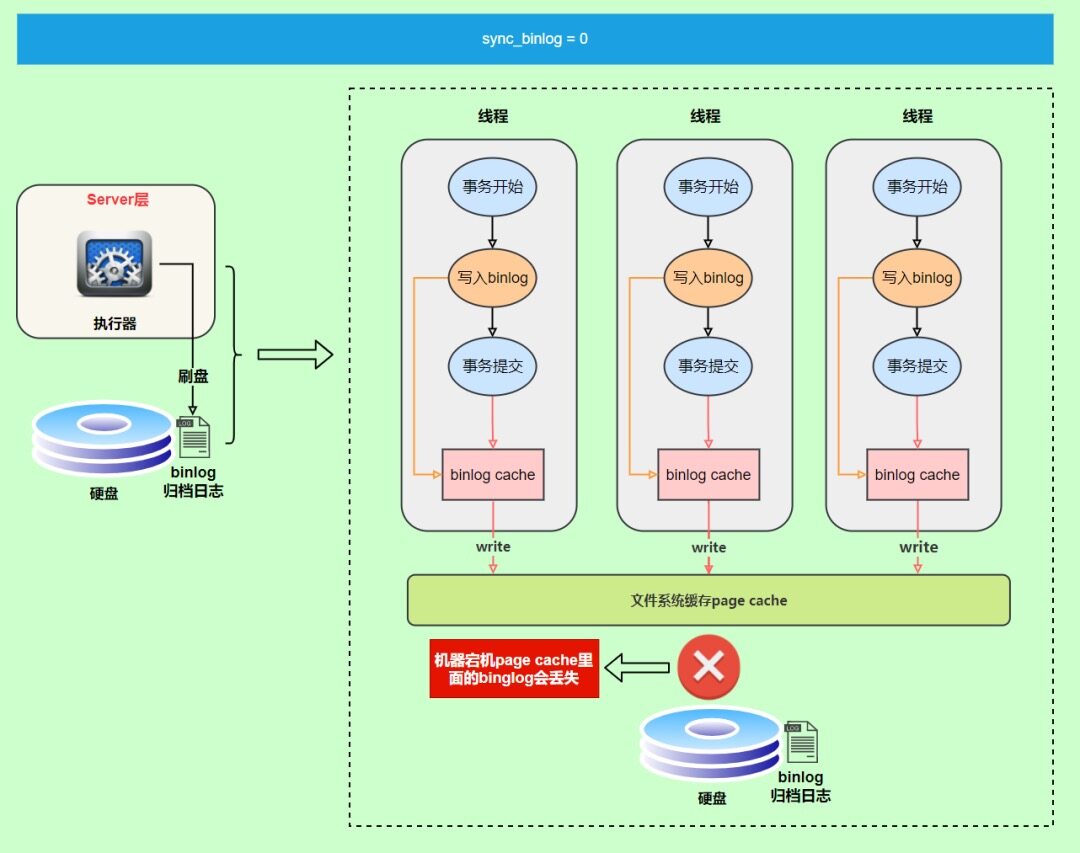
write和fsync的时机,由参数sync_binlog控制,默认是0。0的时候,表示每次提交事务都只write,由系统自行判断什么时候执行fsync。这样虽然性能得到提升,但是机器宕机,page cache里面的binglog会丢失。如下图:
为了安全起见,可以设置sync_binlog为1,表示每次提交事务都会执行fsync,就如同redo log刷盘流程一样。
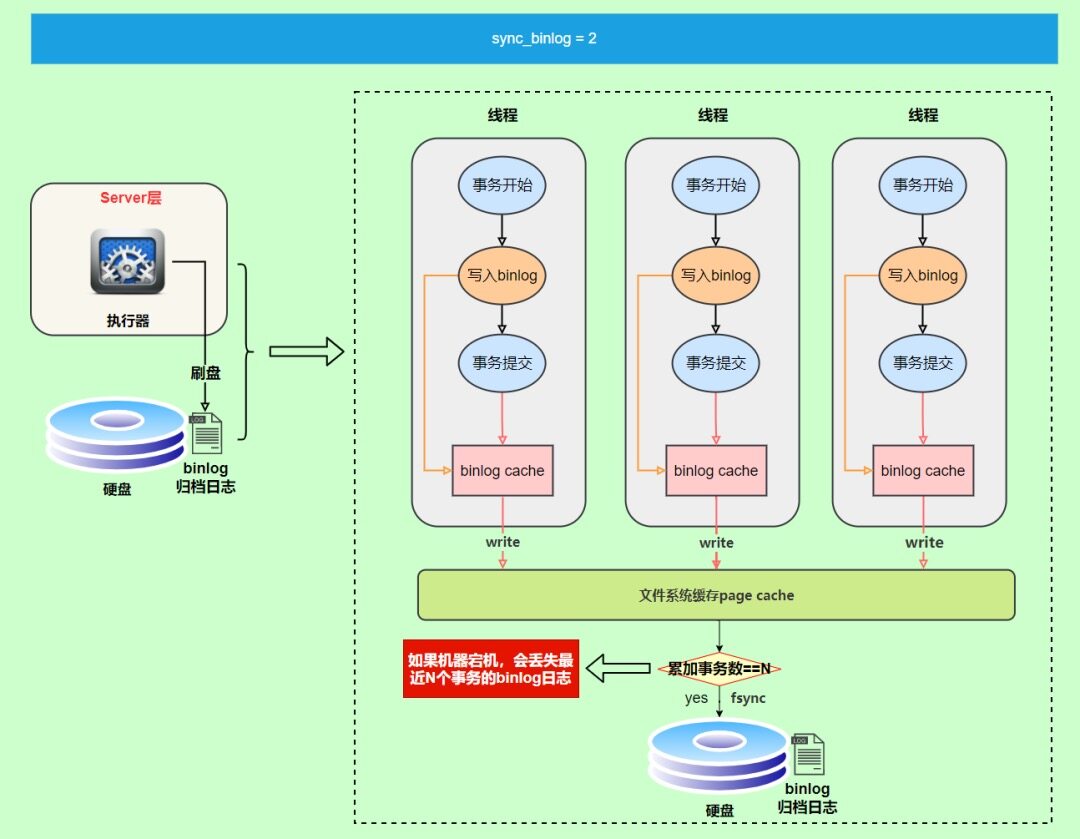
还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write,但累积N个事务后才fsync。
在出现IO瓶颈时,将sync_binlog设置成一个比较大的值,可以提升性能。但是,如果机器宕机,会丢失最近N个事务的binlog日志。
binlog与redolog对比
日志记录
redo log是物理日志,记录内容是"在某个数据页上做了什么修改",属于InnoDB存储引擎层产生的。
binlog是逻辑日志,记录内容是语句的原始逻辑,类似于"给 ID=2 这一行的 c 字段加 1",属于MySQL Server层。
虽然都属于持久化的保证,但是则重点不同。
redo log让InnoDB存储引擎拥有了崩溃恢复能力。
binlog保证了MySQL集群架构的数据一致性。
写入时机
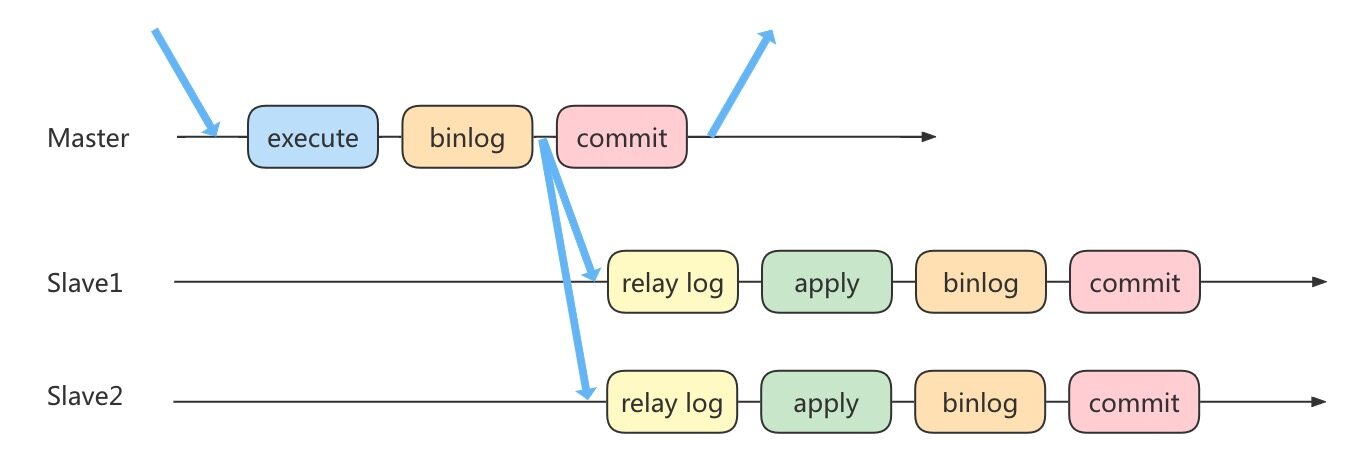
在执行更新语句过程,会记录redo log与binlog两块日志,以基本的事务为单位,redo log在事务执行过程中可以不断写入。
而binlog只有在提交事务时才写入,所以redo log与binlog的 写入时机 不一样。
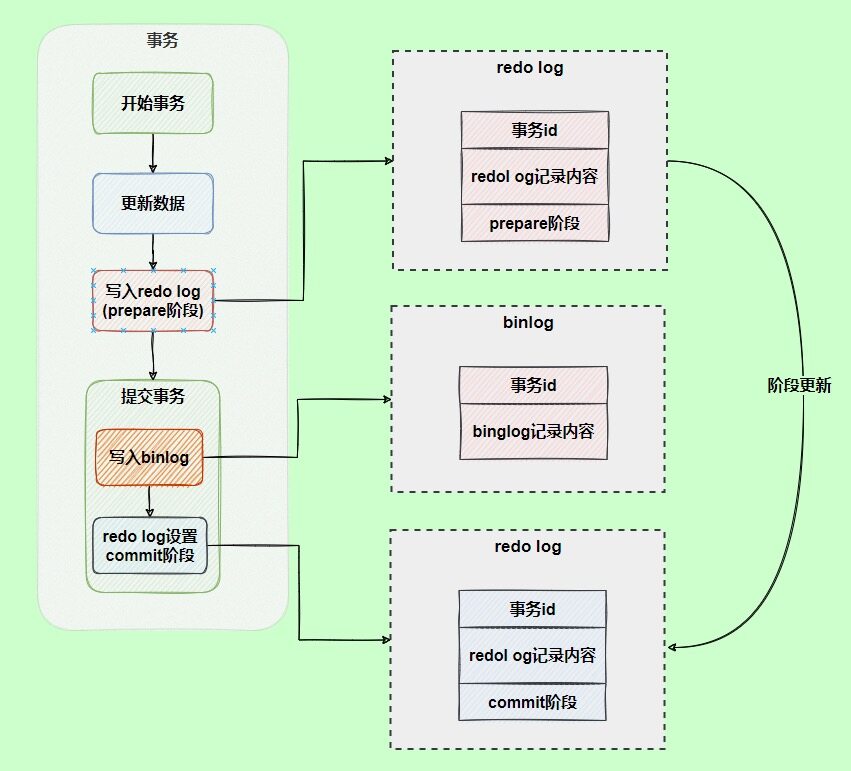
两阶段提交
问题
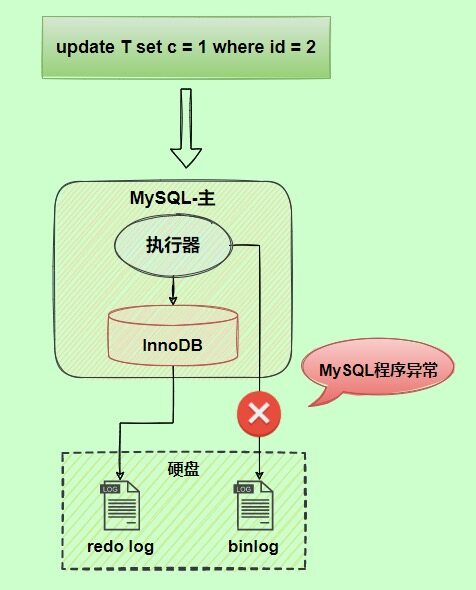
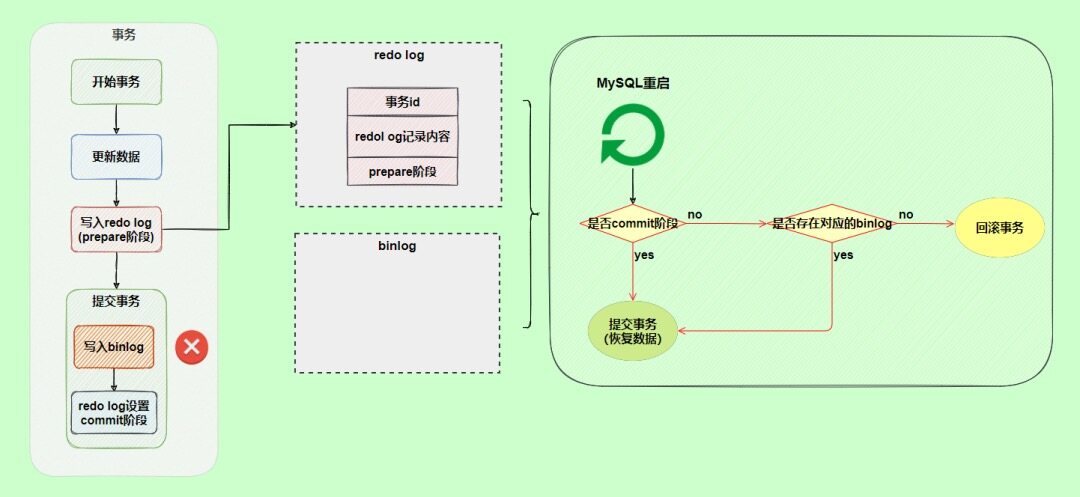
假设现在有这么一个现象,写入redo log是正常的,但是在写入binlog的时候失败了。
这时候,MySQL重启,会基于redo log恢复数据,导致主机和从机、备机之间的数据不一致。
解决
解决方案是,两阶段提交。
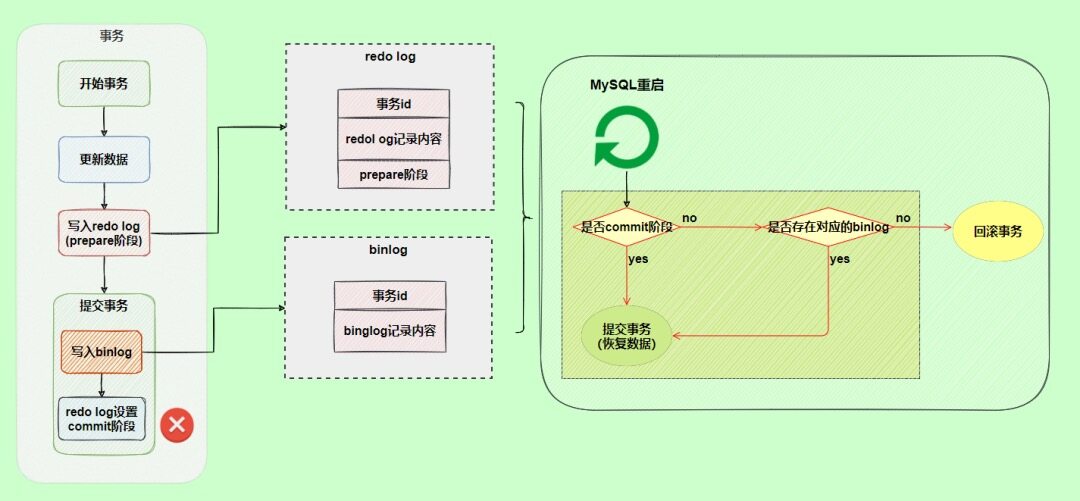
使用两阶段提交后,写入binlog时发生异常也不会有影响。
redo log设置commit阶段发生异常,也不会有影响。虽然redo log是处于prepare阶段,但是能通过事务id找到对应的binlog日志,所以MySQL认为是完整的,就会提交事务恢复数据。
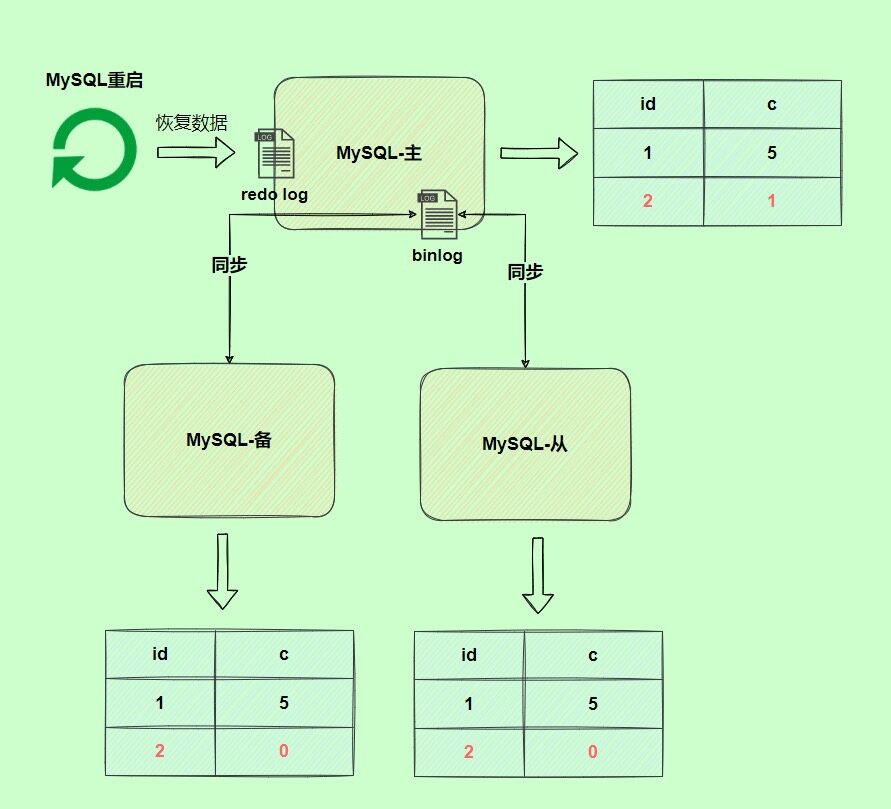
主从复制
概述
主从复制是指将主数据库的DDL和DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
主从复制可以实现以下三点:
高性能:实现读写分离,降低主库的访问压力。
高可用:主库出现问题,可以快速切换到从库提供服务。
热备份:可以在从库中执行备份,以避免备份期间影响主库服务。
原理
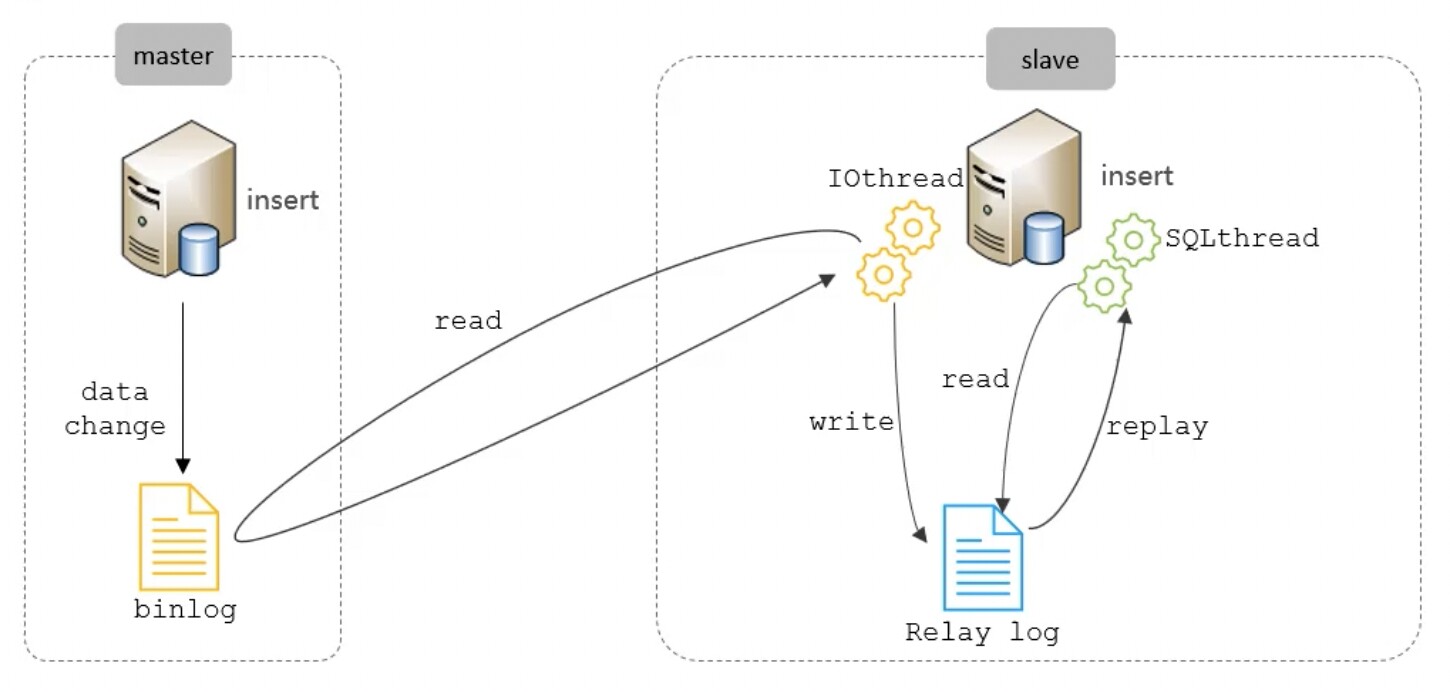
MySQL主从复制的核心就是"二进制日志"。
以上图为例,主从复制的过程如下:
master执行insert语句,记录在binlog日志中。
slave的IOthread读取master的binlog日志,并将其写入到中继日志,Relay log。
slave的SQLthread读取中继日志Relay log,并将Relay log所记录的数据库变化,反应到自身的变化,从而实现主从复制。
基本原则
每个Slave只有一个Master
每个Master可以有多个Slave
每个实例(Master和Slave)只能有一个唯一的服务器ID
搭建
主库配置
配置文件
修改配置文件/etc/my.cnf。
1 2 3 4 5 6 7 8 server-id =1 read-only =0 binlog-do-db =s
配置文件修改完成后,需要重启MySQL服务。
创建账号
创建远程连接的账号,并授予主从复制权限
1 2 3 4 CREATE USER 'u' @'%' IDENTIFIED WITH mysql_native_password BY 'MySQL@2023' ;GRANT REPLICATION SLAVE ON *.* TO 'u' @'%' ;
查看二进制日志坐标
示例代码:
运行结果:
1 2 3 4 5 +---------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +---------------+----------+--------------+------------------+-------------------+ | binlog.000005 | 157 | s | mysql | | +---------------+----------+--------------+------------------+-------------------+
字段含义说明:
File:从哪个日志文件开始推送日志文件Position:从哪个位置开始推送日志Binlog_Do_DB:指定需要同步的数据库Binlog_Ignore_DB:指定不需要同步的数据库
从库配置
配置文件
修改配置文件/etc/my.cnf,修改完成后重启MySQL服务。
1 2 3 4 # mysql 服务ID,保证整个集群环境中唯一,取值范围:[1,(2^32)-1],和主库不一样即可 server-id=2 # 是否只读,1 代表只读, 0 代表读写 read-only=1
设置主库配置
1 CHANGE MASTER TO MASTER_HOST='10.211.55.7' , MASTER_USER='u' , MASTER_PASSWORD='MySQL@2023' , MASTER_LOG_FILE='binlog.000005' , MASTER_LOG_POS=157 ;
在有些资料中,使用的是SOURCE,而不是MASTER。在8.0.23之后的版本支持SOURCE,而MASTER在所有的版本中都支持。MASTER改成SOURCE,和2020年6月的一场反动种族歧视的运动有关。
1 CHANGE REPLICATION SOURCE TO SOURCE_HOST='10.211.55.7' , SOURCE_USER='u' , SOURCE_PASSWORD='MySQL@2023' , SOURCE_LOG_FILE='binlog.000005' , SOURCE_LOG_POS=157 ;
参数:
MASTER_HOST/SOURCE_HOST:主库IP地址MASTER_USER/SOURCE_USER:连接主库的用户名MASTER_PASSWORD/SOURCE_PASSWORD:连接主库的密码MASTER_LOG_FILE/SOURCE_LOG_FILE:binlog日志文件名MASTER_LOG_POS/SOURCE_LOG_POS:binlog日志文件位置
注意!我们是先指定日志文件和日志文件的位置,然后才会进行主从复制。所以,一般建议先搭建完主从复制,再创建数据库。MySQL主从复制起始时,从机不继承主机数据。
同步状态管理
开启同步:start slave,或者start replica。
查看主从同步状态:show slave status,或者show replica status。
查看主从同步状态,示例代码:
运行结果:
1 2 3 4 5 +----------------------------------+-------------+-------------+-------------+---------------+-----------------+---------------------+------------------------------------+---------------+-----------------------+--------------------+---------------------+-----------------+---------------------+--------------------+------------------------+-------------------------+-----------------------------+------------+------------+--------------+---------------------+-----------------+-----------------+----------------+---------------+--------------------+--------------------+--------------------+-----------------+-------------------+----------------+-----------------------+-------------------------------+---------------+---------------+----------------+----------------+-----------------------------+------------------+--------------------------------------+-------------------------+-----------+---------------------+----------------------------------------------------------+--------------------+-------------+-------------------------+--------------------------+----------------+--------------------+--------------------+-------------------+---------------+----------------------+--------------+--------------------+------------------------+-----------------------+-------------------+ | Replica_IO_State | Source_Host | Source_User | Source_Port | Connect_Retry | Source_Log_File | Read_Source_Log_Pos | Relay_Log_File | Relay_Log_Pos | Relay_Source_Log_File | Replica_IO_Running | Replica_SQL_Running | Replicate_Do_DB | Replicate_Ignore_DB | Replicate_Do_Table | Replicate_Ignore_Table | Replicate_Wild_Do_Table | Replicate_Wild_Ignore_Table | Last_Errno | Last_Error | Skip_Counter | Exec_Source_Log_Pos | Relay_Log_Space | Until_Condition | Until_Log_File | Until_Log_Pos | Source_SSL_Allowed | Source_SSL_CA_File | Source_SSL_CA_Path | Source_SSL_Cert | Source_SSL_Cipher | Source_SSL_Key | Seconds_Behind_Source | Source_SSL_Verify_Server_Cert | Last_IO_Errno | Last_IO_Error | Last_SQL_Errno | Last_SQL_Error | Replicate_Ignore_Server_Ids | Source_Server_Id | Source_UUID | Source_Info_File | SQL_Delay | SQL_Remaining_Delay | Replica_SQL_Running_State | Source_Retry_Count | Source_Bind | Last_IO_Error_Timestamp | Last_SQL_Error_Timestamp | Source_SSL_Crl | Source_SSL_Crlpath | Retrieved_Gtid_Set | Executed_Gtid_Set | Auto_Position | Replicate_Rewrite_DB | Channel_Name | Source_TLS_Version | Source_public_key_path | Get_Source_public_key | Network_Namespace | +----------------------------------+-------------+-------------+-------------+---------------+-----------------+---------------------+------------------------------------+---------------+-----------------------+--------------------+---------------------+-----------------+---------------------+--------------------+------------------------+-------------------------+-----------------------------+------------+------------+--------------+---------------------+-----------------+-----------------+----------------+---------------+--------------------+--------------------+--------------------+-----------------+-------------------+----------------+-----------------------+-------------------------------+---------------+---------------+----------------+----------------+-----------------------------+------------------+--------------------------------------+-------------------------+-----------+---------------------+----------------------------------------------------------+--------------------+-------------+-------------------------+--------------------------+----------------+--------------------+--------------------+-------------------+---------------+----------------------+--------------+--------------------+------------------------+-----------------------+-------------------+ | Waiting for source to send event | 10.211.55.7 | u | 3306 | 60 | binlog.000005 | 157 | centos-linux-temp-relay-bin.000002 | 323 | binlog.000005 | Yes | Yes | | | | | | | 0 | | 0 | 157 | 545 | None | | 0 | No | | | | | | 0 | No | 0 | | 0 | | | 1 | 71899db7-548c-11ee-8d4e-001c42462b2d | mysql.slave_master_info | 0 | NULL | Replica has read all relay log; waiting for more updates | 86400 | | | | | | | | 0 | | | | | 0 | | +----------------------------------+-------------+-------------+-------------+---------------+-----------------+---------------------+------------------------------------+---------------+-----------------------+--------------------+---------------------+-----------------+---------------------+--------------------+------------------------+-------------------------+-----------------------------+------------+------------+--------------+---------------------+-----------------+-----------------+----------------+---------------+--------------------+--------------------+--------------------+-----------------+-------------------+----------------+-----------------------+-------------------------------+---------------+---------------+----------------+----------------+-----------------------------+------------------+--------------------------------------+-------------------------+-----------+---------------------+----------------------------------------------------------+--------------------+-------------+-------------------------+--------------------------+----------------+--------------------+--------------------+-------------------+---------------+----------------------+--------------+--------------------+------------------------+-----------------------+-------------------+
解释说明:重点关注Replica_IO_Running和Replica_SQL_Running两个值。
binlog格式设置
STATEMENT
STATEMENT模式,基于SQL语句的复制,statement-based replication,简称SBR。
特点:每一条会修改数据的sql语句会记录到binlog中。
基于其特点,会衍生出如下的优缺点。
优点:
不需要记录每一行的变化,减少了binlog日志量,文件较小。
binlog中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况。
binlog可以用于实时的还原,而不仅仅用于复制。
主从版本可以不一样,从服务器版本可以比主服务器版本高。
缺点:
不是所有的UPDATE语句都能被复制,尤其是包含不确定操作的时候。LOAD_FILE()、UUID()、USER()、FOUND_ROWS()、SYSDATE()
INSERT...SELECT会产生比"RBR"更多的行级锁。复制需要进行全表扫描(WHERE 语句中没有使用到索引)的UPDATE时,需要比"RBR"请求更多的行级锁。
对于有AUTO_INCREMENT字段的InnoDB表而言,INSERT语句会阻塞其他INSERT语句。
对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而"RBR"模式下,只会对那个发生变化的记录产生影响。
数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错。
总之,对于主机有优点,对于从机有缺点。
ROW
ROW模式,基于行的复制,row-based replication,简称RBR。
特点:不记录每条sql语句的上下文信息,仅记录哪条数据被修改了,修改成什么样了。
基于其特点,会衍生出如下的优缺点。
优点:
任何情况都可以被复制,这对复制来说是最安全可靠的。不会出现某些特定情况下的存储过程、函数、触发器无法被正确复制的问题。
多数情况下,从服务器上的表如果有主键的话,复制就会快很多。
复制以下几种语句时的行锁更少:INSERT...SELECT、包含AUTO_INCREMENT字段的INSERT、没有附带条件或者并没有修改很多记录的UPDATE或DELETE语句。
执行INSERT,UPDATE,DELETE语句时锁更少。
从服务器上采用多线程来执行复制成为可能。
缺点:
binlog大了很多。
复杂的回滚时binlog 中会包含大量的数据
主服务器上执行UPDATE语句时,所有发生变化的记录都会写到binlog中,而SBR只会写一次,这会导致频繁发生binlog的并发写问题。
无法从binlog中看到都复制了些什么语句
总之,对于从机有优点,对于主机有缺点。
MIXED
MIXED模式,混合模式复制,mixed-based replication,简称MBR。
Mixed模式,Statement与Row的结合。MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
同步数据一致性问题
主从同步的要求
读库和写库的数据一致,主从复制一定会有延迟,能做到的只是最终一致,同时减少延迟。
主从延迟问题原因
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
在网络正常的时候,日志从主库传给从库所需的时间是很短的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。造成原因:
从库的机器性能比主库要差
从库的压力大
大事务的执行
如何减少主从延迟
降低多线程大事务并发的概率,优化业务逻辑。
优化SQL,避免慢SQL,减少批量操作,建议写脚本以update-sleep这样的形式完成。
提高从库机器的配置,减少主库写binlog和从库读binlog的速度方面的差距。
尽量采用短的链路,即主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。
实时性要求高的业务读强制走主库。
如何解决一致性问题
三种方法
如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。
读写分离情况下,解决主从同步中数据不一致的问题,就是解决主从之间数据复制方式的问题,按照数据一致性从弱到强来进行划分,有以下3种复制方式:
异步复制
半同步复制
组复制
异步复制
异步模式是指客户端提交COMMIT之后不需要等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。
这时候如果从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。
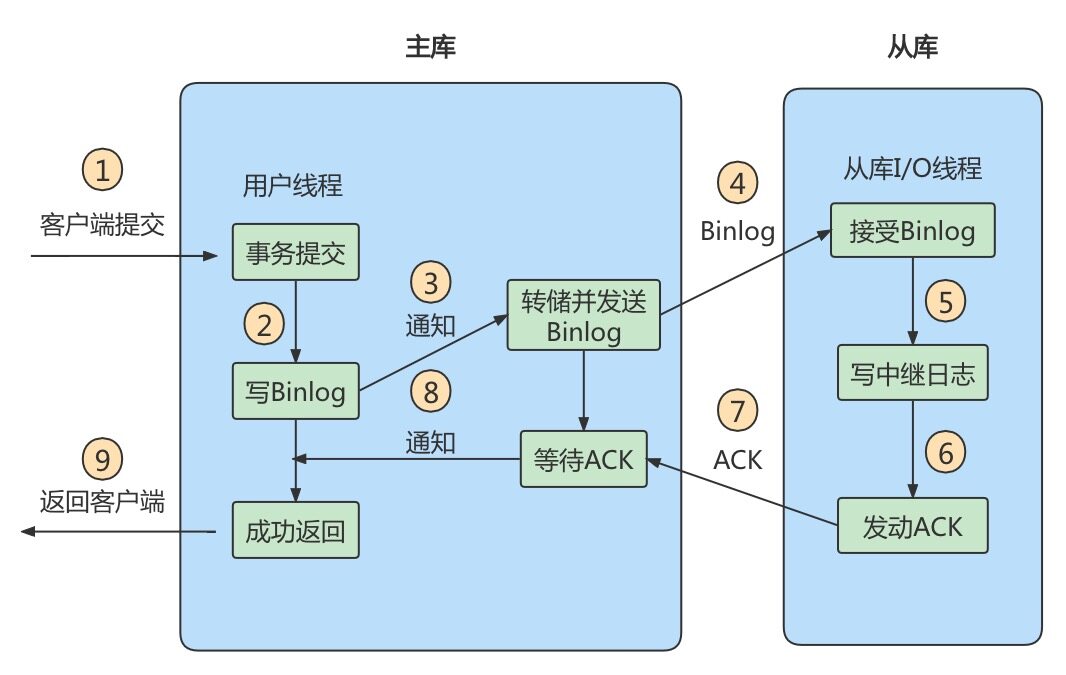
半同步复制
5.5版本之后开始支持半同步复制的方式。
原理是在客户端提交COMMIT之后不直接将结果返回给客户端,而是等待至少有一个从库接收到了binlog,并且写入到中继日志中,再返回给客户端。
这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
在5.7版本中还增加了一个rpl_semi_sync_master_wait_for_slave_count参数,可以对应答的从库数量进行设置,默认为1,也就是说只要有1个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。
组复制
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景,比如金融领域。
MGR很好地弥补了这两种复制模式的不足。
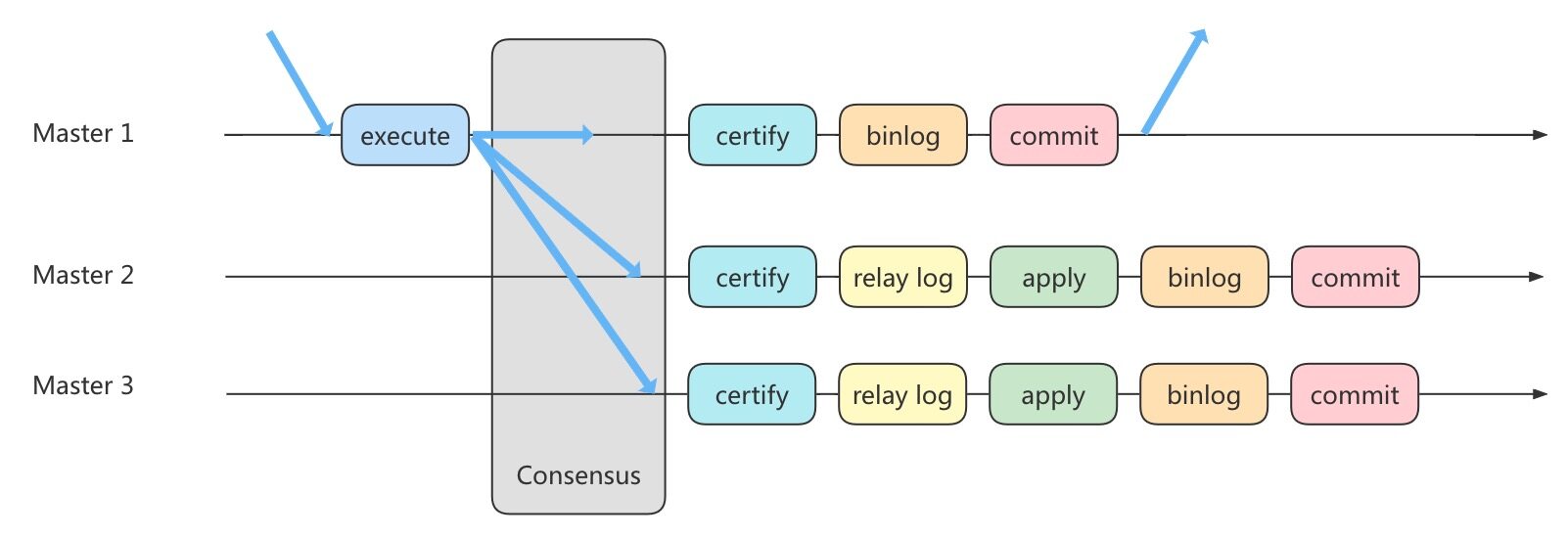
MGR,MySQL Group Replication,组复制技术,是在5.7.17版本中推出的一种新的数据复制技术,这种复制技术是基于"Paxos"协议的状态机复制。
首先我们将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus层)的同意,也就是读写事务想要进行提交,必须要经过组里"大多数Node节点"(大多数人)的同意,大多数指的是同意的节点数量需要大于N 2 + 1 \frac{N}{2} + 1 2 N + 1
在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
附录:常用命令
mysql
语法:
1 mysql [options] [database]
注意,该mysql不是指mysql服务,而是指mysql的客户端工具。
连接选项:
-u/--user=name:指定用户名。-p/--password[=password]:指定密码。-h/--host=name,指定服务器IP或域名。-P/--port=#,指定连接端口。
执行选项:-e/--execute=SQL语句,执行SQL语句并退出。该选项可以在MySQL客户端执行SQL语句,而不用连接到MySQL数据库再执行,对于一些批处理脚本,这种方式尤其方便。
示例代码:
1 mysql -uroot -p db01 -e "select * from tb_book";
source
在已经通过mysql命令登录后,可以使用mysql中的source指令,执行文件。
1 source /root/tb_book.sql
mysqlbinlog
语法:
1 mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d/--database=name:指定数据库名称。-o/--offset=#:忽略掉日志中的前n行。-r/--result-file=name:将输出的文本格式日志输出到指定文件。-s/--short-form:显示简单格式,省略掉一些信息。--start-datatime=date1/--stop-datetime=date2:指定日期间隔内的所有日志。--start-position=pos1/--stop-position=pos2:指定位置间隔内的所有日志。
mysqldump
语法:
1 mysqldump –u【用户名】 –h【主机名】 –p【密码】 待备份的数据库名称[tbname, [tbname...]] > 备份文件名称.sql
连接选项:
-u/--user=name:指定用户名-p/--password[=password]:指定密码-h/--host=hostname:指定服务器IP或域名-P/--port=#:指定连接端口
输出内容选项:
-A/--all-databases,整个实例。--add-drop-database:在每个数据库创建语句前加上Drop database语句--add-drop-table:在每个表创建语句前加上Drop table语句, 默认开启
--skip-add-drop-table,不开启。
-n/--no-create-db:不包含数据库的创建语句-t/--no-create-info:不包含数据表的创建语句-d/--no-data:不包含数据-T/--tab=name:自动生成两个文件:一个.sql文件,创建表结构的语句;一个.txt文件,数据文件,相当于select into outfile--where:where后面附带需要满足的条件,可以备份单表的部分数据。--routines/-R:备份存储过程及函数--events/-E:来备份事件。
报错如下:
1 ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
secure_file_priv参数用于限制导入或者导出:
secure_file_priv为NULL时,表示限制mysqld不允许导入或导出。默认为NULL。secure_file_priv为/tmp时,表示限制mysqld只能在/tmp目录中执行导入导出,其他目录不能执行。secure_file_priv没有值时,表示不限制mysqld在任意目录的导入导出。查看secure_file_priv的值:
1 show global variables like '%secure_file_priv%' ;
因为secure_file_priv参数是只读参数,不能使用set global命令修改,需要修改配置文件my.cnf或my.ini,在[mysqld]块下加入以下语句后重启mysql。
注意,这个参数在Windows系统下是secure-file-priv,中划线,而非下划线。
mysqlimport
mysqlimport是客户端数据导入工具,用来导入文本文件。
语法:
1 mysqlimport [options] db_name textfile1 [textfile2...]
常用选项:
--fields-terminated-by=字符串:设置字符串为字段之间的分隔符,可以为单个或多个字符。默认值为制表符\t。-L、--local:表示从客户端任意路径读取文件导入表中,未设置该选项时,默认只从datadir下同名数据库目录下读取文件导入--ignore-lines=n:表示可以忽略前n行。-l、--lock-tables:写入时锁定所有表。-p、--password[=name]:指定用户密码。-u、--user=name:指定登入MySQL用户名。-h、--host=name:指定远程连接的服务器。-c、--columns=name:往表里导入指定字段,如:--columns='Name,Age,Gender'-C、--compress:在客户端和服务器之间启用压缩传递所有信息。
其它可用选项和默认参数设置可以使用mysqlimport -help查询。
示例:
1 mysqlimport -uroot -p test /tmp/city.txt
mysqladmin
mysqladmin是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前状态、创建并删除数据库等。
可以通过mysqladmin --help查看帮助文档。