概述
定义
设计模式,是一套被反复使用、经过分类编目的、代码设计经验的总结。
设计模式描述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方案。
即,设计模式是解决特定问题的一系列套路,是前辈们的代码设计经验的总结,具有一定的普遍性,可以反复使用。
分类
-
创建型模式
用于描述怎样创建对象,其主要特点是将对象的创建与使用分离。
5种创建型模式:单例、原型、工厂方法、抽象工厂、建造者。 -
结构型模式
用于描述如何将类或对象按某种布局组成更大的结构。
7种结构型模式:代理、适配器、桥接、装饰、外观、享元、组合。 -
行为型模式
用于描述类或对象之间怎样相互协作共同完成单个对象无法单独完成的任务,以及怎样分配职责。
11种行为型模式:模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器。
UML
什么是UML
UML,Unified Modeling Language,统一建模语言,用来设计软件的可视化建模语言。
其特点有:统一、图形化、能表达软件设计中的动态与静态信息。
UML从目标系统的不同角度出发,定义了用例图、类图、对象图、状态图、活动图、时序图、协作图、构件图、部署图等9种图。
类图概述
类图,Class diagram,显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。
在软件工程中,类图是一种静态的结构图,描述了系统的类的集合,类的属性和类之间的关系。
类的表示方法
整体结构
在UML类图中,类使用包含类名、属性(field)和方法(method)且带有分割线的矩形来表示。
比如下图表示一个Employee类,它包含name、age和address这3个属性,以及work()方法。

可见性
属性/方法名称前加的加号和减号表示了这个属性/方法的可见性,UML类图中表示可见性的符号有三种:
+:表示public。-:表示private。#:表示protected。
表示方式
- 属性的表示方式是:
可见性 名称 :类型 [ = 缺省值] - 方法的表示方式是:
可见性 名称(参数列表) [ : 返回类型]
注意:
- 中括号中的内容表示是可选的。
- 也有将类型放在变量名前面,返回值类型放在方法名前面。
关系的表示方法
概述
关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系。
一般可以分为:
- 关联关系
- 聚合关系
- 组合关系
- 依赖关系
- 继承关系
- 实现关系
也有一些资料,阐述如下:关联关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系。
而对于关联关系,称之为:一般关联关系。
关联关系
关联关系又可以分为单向关联、双向关联、自关联。
单向关联
单向关联用一个带箭头的实线表示。
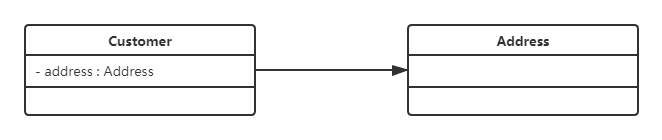
上图表示每个顾客都有一个地址,这通过让Customer类持有一个类型为Address的成员变量类实现。
双向关联
双向关联用一个不带箭头的直线表示。
所谓的双向关联就是双方各自持有对方类型的成员变量。

上图中在Customer类中维护一个List <Product>,表示一个顾客可以购买多个商品;在Product类中维护一个Customer类型的成员变量表示这个产品被哪个顾客所购买。
自关联
自关联用一个带有箭头且指向自身的线表示。
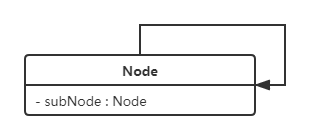
上图的意思就是Node类包含类型为Node的成员变量,也就是"自己包含自己"。
聚合关系
什么是聚合关系
聚合关系,是强关联关系,是整体和部分之间的关系。
聚合关系也是通过成员对象来实现的,其中成员对象是整体对象的一部分,但是成员对象可以脱离整体对象而独立存在。
例如,学校与老师的关系,学校包含老师,但如果学校停办了,老师依然存在。
表示方法
聚合关系用带空心菱形的实线来表示,菱形指向整体。
下图所示是大学和教师的关系图。

组合关系
什么是组合关系
组合关系也是整体与部分的关系,但它是一种更强烈的聚合关系。
在组合关系中,整体对象可以控制部分对象的生命周期,一旦整体对象不存在,部分对象也将不存在,部分对象不能脱离整体对象而存在。
例如,头和嘴的关系,没有了头,嘴也就不存在了。
表示方法
组合关系用带实心菱形的实线来表示,菱形指向整体。
下图所示是头和嘴的关系图:

依赖关系
什么是依赖关系
依赖关系是一种使用关系,它是对象之间耦合度最弱的一种关联方式,是临时性的关联。
在代码中,某个类的方法通过局部变量、方法的参数或者对静态方法的调用来访问另一个类(被依赖类)中的某些方法来完成一些职责。
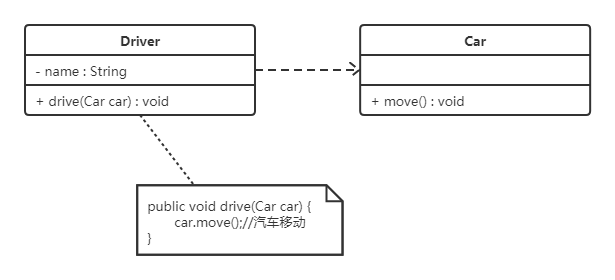
表示方法
依赖关系使用带箭头的虚线来表示,箭头从使用类指向被依赖的类。
下图所示是司机和汽车的关系图,司机驾驶汽车:
继承关系
什么是继承关系
继承关系是对象之间耦合度最大的一种关系,表示一般与特殊的关系,父类与子类之间的关系。
有些资料,把继承关系,称作泛化关系。
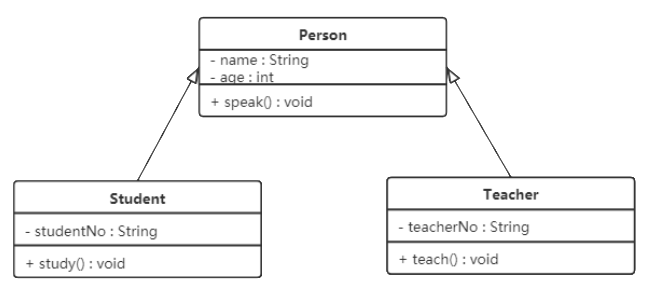
表示方法
继承关系用带空心三角箭头的实线来表示,箭头从子类指向父类。
例如,Student类和Teacher类都是Person类的子类,其类图如下图所示:
实现关系
什么是实现关系
实现关系是接口与实现类之间的关系。
在这种关系中,类实现了接口,类中的操作实现了接口中所声明的所有的抽象操作。
表示方法
实现关系使用带空心三角箭头的虚线来表示,箭头从实现类指向接口。
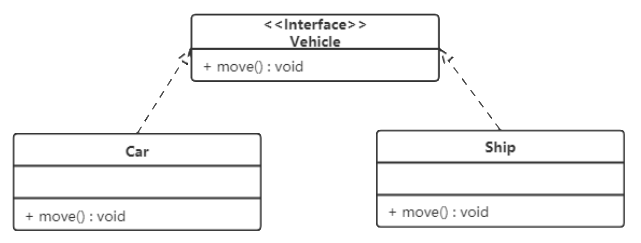
例如,汽车和船实现了交通工具:
七种设计原则
开闭原则
定义
软件实体应当对扩展开放,对修改关闭。
即,当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。
作用
- 对软件测试的影响
测试时只需要对扩展的代码进行测试就可以了,因为原有的测试代码仍然能够正常运行。 - 提高代码的可复用性
粒度越小,被复用的可能性就越大;在面向对象的程序设计中,根据原子和抽象编程可以提高代码的可复用性。 - 提高软件的可维护性
稳定性高和延续性强,从而易于扩展和维护。
案例
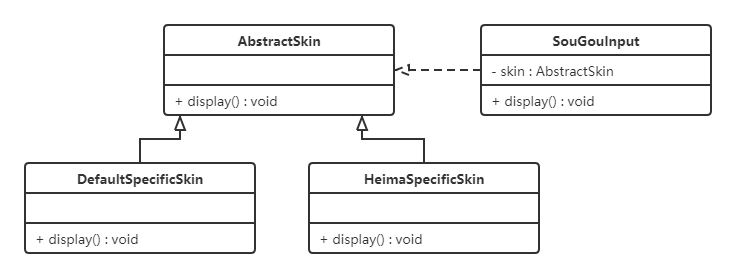
我们以搜狗输入法的皮肤为例介绍开闭原则的应用。
搜狗输入法的皮肤共同的特点,可以为其定义一个抽象类(AbstractSkin),而每个具体的皮肤是其子类,用户窗体可以根据需要选择或者增加新的主题,而不需要修改原代码,所以它是满足开闭原则的。
里氏替换原则
定义
继承必须确保基类所拥有的性质在子类中仍然成立。
即,子类可以扩展父类的功能,但不能改变父类原有的功能。
作用
- 是实现开闭原则的重要方式之一。
- 克服了继承中重写父类造成的可复用性变差的缺点。
- 类的扩展不会给已有的系统引入新的错误,降低了代码出错的可能性。
反例
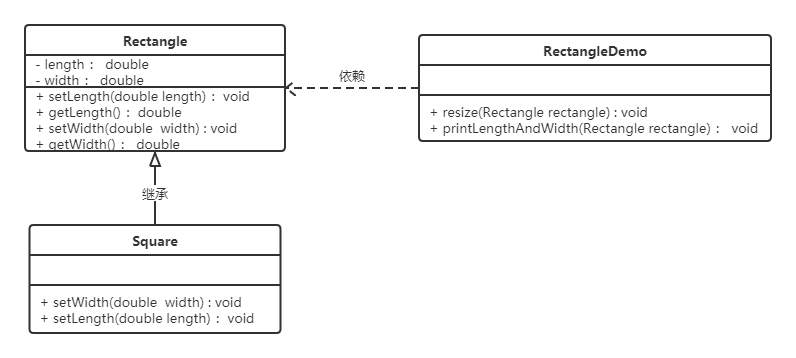
例如,我们定义正方形继承自长方形。
1 | package com.kakawanyifan; |
1 | package com.kakawanyifan; |
- 由于正方形的长和宽相同,所以在方法setLength和setWidth中,对长度和宽度都需要赋相同值。
1 | class Rectangle: |
类RectangleDemo是我们的软件系统中的一个组件,它有一个resize方法依赖基类Rectangle,resize方法是RectandleDemo类中的一个方法,用来实现宽度逐渐增长的效果。
1 | package com.kakawanyifan; |
1 | class RectangleDemo: |
我们运行一下这段代码就会发现:
假如我们把一个普通长方形作为参数传入resize方法,就会看到长方形宽度逐渐增长的效果,当宽度大于长度,代码就会停止,这种行为的结果符合我们的预期。
假如我们再把一个正方形作为参数传入resize方法后,就会看到正方形的宽度和长度都在不断增长,代码会一直运行下去,直至系统产生溢出错误。
即,普通的长方形是适合这段代码的,正方形不适合。
也就是说,在我们的这个场景中,类的扩展给已有的系统引入了新的错误,子类扩展了父类的功能,但同时也改变父类原有的功能。
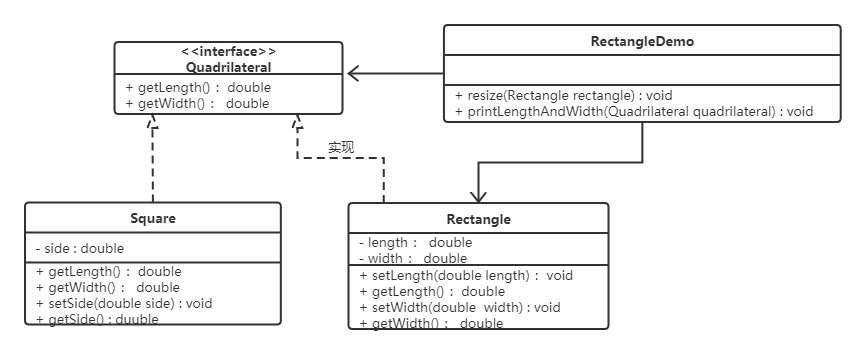
改进方法是,重新设计他们之间的关系。抽象出来一个四边形接口(Quadrilateral),让Rectangle类和Square类实现Quadrilateral接口
依赖倒置原则
定义
要面向接口编程,不要面向实现编程。
即,高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。
作用
- 可以降低类间的耦合性。
- 可以减少并行开发引起的风险。
- 可以提高代码的可读性和可维护性。
反例
现要组装一台电脑,需要配件CPU、硬盘、内存条。只有这些配置都有了,计算机才能正常的运行。可选择CPU有很多选择,如Intel,AMD等,可选择的硬盘有希捷,西数等,可选择的内存条有金士顿,海盗船等。
我们的设计如下:
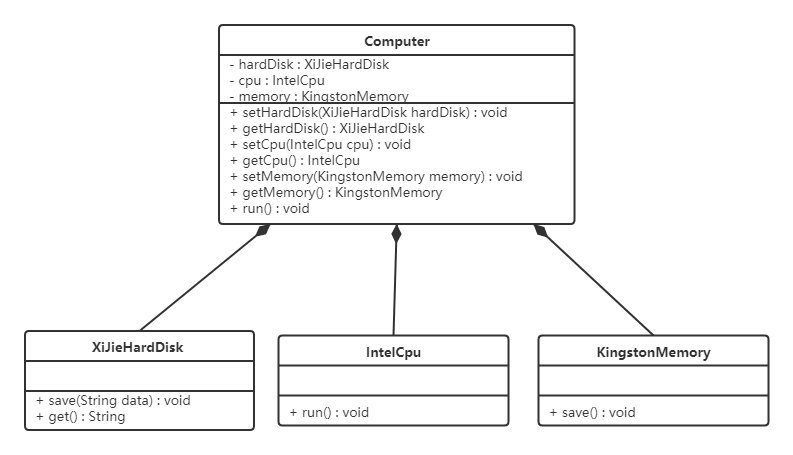
上述设计存在的问题是,CPU只能是Intel的,内存条只能是金士顿的,硬盘只能是希捷的。
根据依赖倒转原则进行改进,新的设计如下:
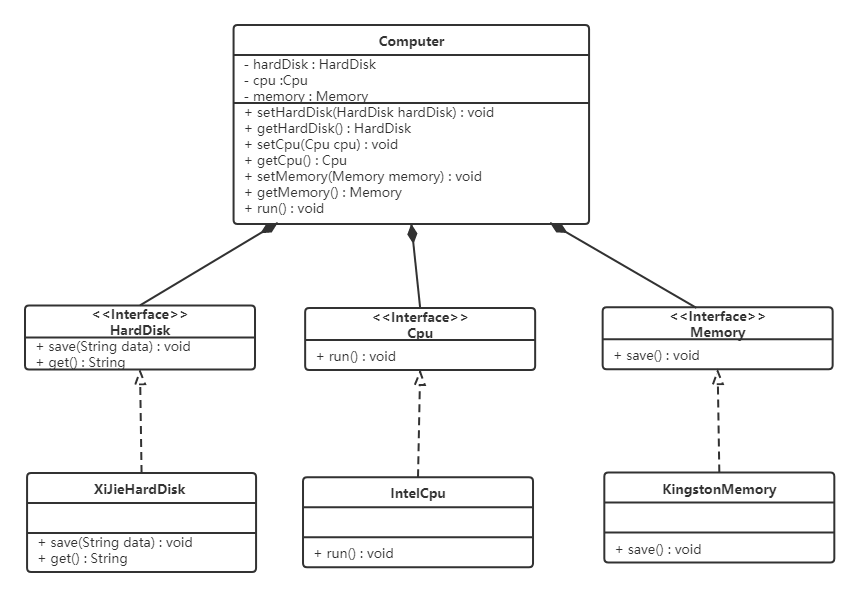
新的设计,很好的解决了这个问题。一般情况下抽象的变化概率很小,让用户程序依赖于抽象,实现的细节也依赖于抽象。即使实现细节不断变动,只要抽象不变,客户程序就不需要变化。这大大降低了客户程序与实现细节的耦合度。
单一职责原则
定义
单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
如果一个对象承担了太多的职责,至少存在以下两个缺点
- 一个职责的变化可能会削弱或者抑制这个类实现其他职责的能力。
- 当客户端需要该对象的某一个职责时,不得不将其他不需要的职责全都包含进来,从而造成冗余代码或代码的浪费。
作用
- 降低类的复杂度
一个类只负责一项职责,其逻辑肯定要比负责多项职责简单得多。 - 提高类的可读性
复杂性降低,自然其可读性会提高。 - 提高系统的可维护性
可读性提高,那自然更容易维护了。 - 变更引起的风险降低
变更是必然的,如果单一职责原则遵守得好,当修改一个功能时,可以显著降低对其他功能的影响。
反例
假设我们正在开发一个简单的博客系统,其中有一个Article类,该类不仅包含了文章的数据属性(如标题、内容、作者等),还包含了与数据库交互的方法(如保存到数据库、从数据库加载)、以及一些业务逻辑处理方法(如计算阅读时间、检查敏感词等)。
这种设计违反了单一职责原则,因为Article类承担了数据模型、持久化操作和业务逻辑等多个职责。
这可能导致代码难以维护和扩展:每当数据库访问层发生变化时(例如更换数据库类型或调整存储结构),或者业务规则改变时,都需要修改Article类,增加了出错的可能性。
要遵循单一职责原则,我们可以将Article类拆分为几个更小的类,每个类专注于一种类型的职责。
例如:数据模型Article类,仅包含数据属性;持久化逻辑ArticleRepository接口及其实现类,负责所有关于文章的持久化操作;业务逻辑ArticleService类,处理与文章相关的业务逻辑。
接口隔离原则
定义
客户端不应该被迫依赖于它不使用的方法
一个类对另一个类的依赖应该建立在最小的接口上
与单一职责原则的区别
- 单一职责原则注重的是职责,而接口隔离原则注重的是对接口依赖的隔离。
- 单一职责原则主要是约束类,它针对的是程序中的实现和细节;接口隔离原则主要约束接口,主要针对抽象和程序整体框架的构建。
作用
- 将臃肿庞大的接口分解为多个粒度小的接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
- 接口隔离提高了系统的内聚性,减少了对外交互,降低了系统的耦合性。
- 使用多个专门的接口还能够体现对象的层次,因为可以通过接口的继承,实现对总接口的定义。
- 能减少项目工程中的代码冗余。过大的大接口里面通常放置许多不用的方法,当实现这个接口的时候,被迫设计冗余的代码。
反例
例如,我们需要创建一个HeiMa安全门,该安全门具有防火、防水、防盗的功能。
我们可以将防火,防水,防盗功能提取成一个接口,形成一套规范。类图如下:
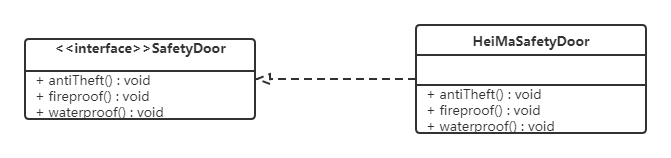
如果我们还需要再创建一个新的安全门,而该安全门只具有防盗、防水功能呢?
很显然如果实现SafetyDoor接口就违背了接口隔离原则。
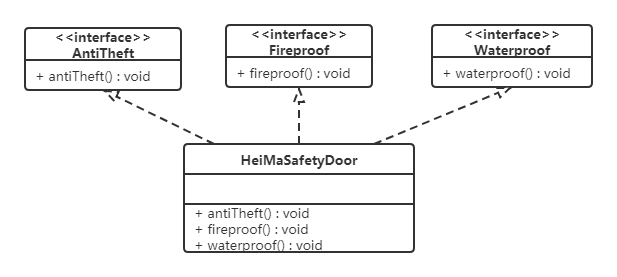
修改如下:
迪米特法则
定义
迪米特法则,Law of Demeter,LoD,也被称为最少知识原则,Least Knowledge Principle,LKP。
如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。
作用
- 降低了类之间的耦合度,提高了模块的相对独立性。
- 由于亲合度降低,从而提高了类的可复用率和系统的扩展性。
反例
假设我们有一个简单的图书管理系统,其中包含以下几个类:Library、Book和Author。在初始设计中,Library类试图直接访问Book的作者信息,并且进一步访问该作者的详细信息。这种设计违反了迪米特法则,因为Library不仅与Book交流,还直接与Author交流,这增加了不必要的耦合。
1 | public class Author { |
1 | class Author: |
在这个例子中,Library类通过Book实例获取到了Author对象,并且直接调用了Author的方法来获取作者的名字和详细信息。这样的设计使得Library和Author之间存在不必要的耦合。
为了遵循迪米特法则,我们可以对代码进行重构,让每个对象只处理自己的职责范围内的事情。例如,可以让Book类提供一个方法来返回作者的信息,而不是直接暴露Author对象。
1 | // Author保持不变 |
1 | # Author保持不变 |
现在,Library类不再需要知道Author的存在,它只需通过Book类提供的方法就可以获得所需的信息。这样做的好处是降低了Library与Author之间的耦合度,如果未来Author类的设计发生变化,只需要调整Book类的相关方法即可,而不需要修改Library类。这提高了系统的灵活性和可维护性。
合成复用原则
定义
合成复用原则,Composite Reuse Principle,CRP,也被称为组合/聚合复用原则,Composition/Aggregate Reuse Principle,CARP。
在软件复用时,要尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
作用
- 通常类的复用分为继承复用和合成复用两种,继承复用虽然有简单和易实现的优点,但它也存在以下缺点:
- 继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为"白箱"复用。
- 子类与父类的耦合度高。父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展。
- 限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生变化。
- 采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能,它有以下优点:
- 维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为"黑箱"复用。
- 新旧类之间的耦合度低。这种复用所需的依赖较少,新对象存取成分对象的唯一方法是通过成分对象的接口。
- 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。
反例
汽车按"动力源"划分可分为汽油汽车、电动汽车等;按"颜色"划分可分为白色汽车、黑色汽车和红色汽车等。如果同时考虑这两种分类,其组合就很多。类图如下:
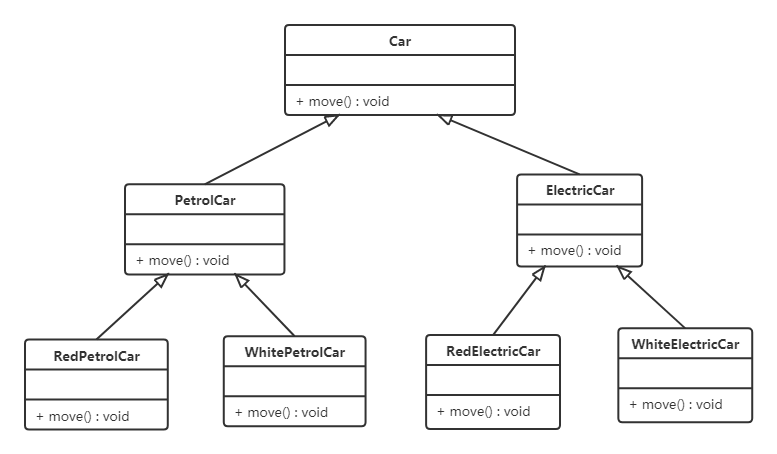
从上面类图我们可以看到使用继承复用产生了很多子类,如果现在又有新的动力源或者新的颜色的话,就需要再定义新的类。我们试着将继承复用改为聚合复用看一下。
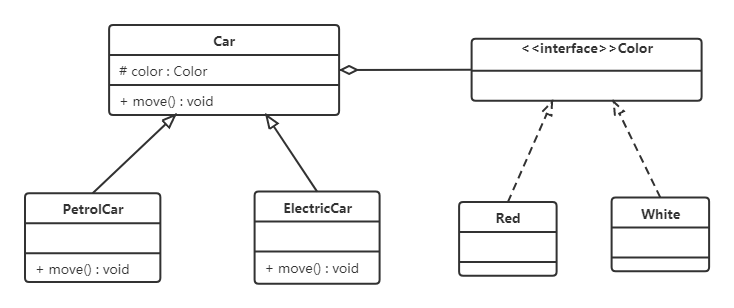
单例模式
创建型模式
创建型模式的主要关注点是怎样创建对象,它的主要特点是将对象的创建与使用分离。
这样可以降低系统的耦合度,使用者不需要关注对象的创建细节。
创建型模式分为:
- 单例模式
- 工厂方法模式
- 抽象工程模式
- 原型模式
- 建造者模式
单例设计模式
单例模式,Singleton Pattern。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。
这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式的结构
单例模式的主要有以下角色:
- 单例类,只能创建一个实例的类。
- 访问类,使用单例类。
单例模式的实现
分类
单例设计的实现,分为两类:
- 饿汉式
类加载就会导致该单实例对象被创建。 - 懒汉式
类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建。
饿汉式
方式一(静态变量方式)
示例代码:
1 | package com.kakawanyifan; |
示例代码:
1 | class Singleton: |
解释说明:
@classmethod的作用@classmethod装饰器标记的方法是一个类方法,它绑定到类而不是实例。- 类方法的第一个参数是类本身(通常命名为
cls),而非实例(通常命名为self)。 - 类方法可以在不创建实例的情况下通过类名直接调用:
Singleton.get_instance()。
- 在单例模式中的应用:
- 提供了一个不需要实例化就能访问的入口点(类似Java的静态方法)。
- 通过
cls参数访问类变量_instance。 - 使用类方法而非静态方法,可以保证即使Singleton被继承,子类也能正确获取自己的单例实例。
- 上述代码模拟了Java饿汉式单例实现,主要特点:
- 类变量
_instance用来保存单例对象。 - 类定义后立即创建实例:
Singleton._instance = Singleton()。 get_instance()方法仅返回这个预先创建好的实例
- 类变量
该方式在成员位置声明Singleton类型的静态变量,并创建Singleton类的对象instance。instance对象是随着类的加载而创建的。如果该对象足够大的话,而一直没有使用就会造成内存的浪费。
方式二(静态代码块方式)
1 | package com.kakawanyifan; |
1 | class Singleton: |
该方式在成员位置声明Singleton类型的静态变量,而对象的创建是在静态代码块中,也是对着类的加载而创建。
该方式和静态变量方式基本上一样,该方式也存在内存浪费问题。
方式三(枚举方式)
优点:
- 线程安全:枚举的实例化是线程安全的。
- 防止反射攻击:枚举类型的构造函数默认是私有的,因此无法通过反射创建新的实例。
- 序列化安全:枚举类型天然支持序列化,能够保证在反序列化时不会创建新的实例。
1 | public enum ConfigManager { |
1 | from enum import Enum, auto |
解释说明:
__new__的基本作用:__new__是对象创建的第一步,在__init__之前被调用。- 负责创建并返回一个新实例,而
__init__只负责初始化已创建的实例。 - 是一个类方法(虽然不需要显式使用
@classmethod装饰器)。
- 与
__init__的区别:__new__的第一个参数是类。__init__的第一个参数是实例。- 如果
__new__不返回类的实例,则__init__不会被调用。
- 在枚举实现单例中,重写
__new__方法允许我们:- 控制实例的创建过程。
- 为枚举成员设置自定义属性(如
_value_)。 - 创建具有可变状态的枚举成员(通常枚举成员是不可变的)。
懒汉式
方式一(线程不安全)
示例代码:
1 | package com.kakawanyifan; |
示例代码:
1 | class Singleton: |
该方式在成员位置声明Singleton类型的静态变量,并没有进行对象的赋值操作。
而是当调用getInstance()方法获取Singleton类的对象的时候才创建Singleton类的对象,这样就实现了懒加载的效果。
但是,如果是多线程环境,会出现线程安全问题。
方式二(线程安全)
示例代码:
1 | package com.kakawanyifan; |
示例代码:
1 | import threading |
该方式也实现了懒加载效果,同时又解决了线程安全问题。
但是在getInstance()方法上添加了synchronized关键字(在Python中通过锁机制实现。),导致该方法的执行效果特别低。
方式三(双重检查锁)
再来讨论一下懒汉模式中加锁的问题,对于 getInstance() 方法来说,绝大部分的操作都是读操作,读操作是线程安全的,所以我们没必让每个线程必须持有锁才能调用该方法,我们需要调整加锁的时机。由此也产生了一种新的实现模式:双重检查锁模式。
示例代码:
1 | package com.kakawanyifan; |
示例代码:
1 | class Singleton: |
volatile
上文的双重检测锁模式看上去完美无缺,其实是存在问题,在多线程的情况下,可能会出现空指针问题,出现问题的原因是JVM在实例化对象的时候会进行优化和指令重排序操作。
要解决双重检查锁模式带来空指针异常的问题,只需要使用volatile关键字,volatile关键字可以保证可见性和有序性。
示例代码:
1 | package com.kakawanyifan; |
无(不适用)
添加 volatile 关键字之后的双重检查锁模式是一种比较好的单例实现模式,能够保证在多线程的情况下线程安全也不会有性能问题。
方式四(静态内部类方式)
静态内部类单例模式中实例由内部类创建,由于JVM在加载外部类的过程中,是不会加载静态内部类的,只有内部类的属性/方法被调用时才会被加载,并初始化其静态属性。
静态属性由于被static修饰,保证只被实例化一次,并且严格保证实例化顺序。
示例代码:
1 | package com.kakawanyifan; |
无(不适用)
第一次加载Singleton类时不会去初始化INSTANCE,只有第一次调用getInstance,虚拟机加载SingletonHolder并初始化INSTANCE,这样不仅能确保线程安全,也能保证Singleton类的唯一性。
静态内部类单例模式是一种优秀的单例模式,是开源项目中比较常用的一种单例模式。在没有加任何锁的情况下,保证了多线程下的安全,并且没有任何性能影响和空间的浪费。
破坏单例
破坏方法
除了枚举方式,其他的单例都有两种方法可以破坏:
- 序列化
序列化后反序列化可以生成新的对象,破坏单例。
当一个单例对象实现了Serializable接口时,可以通过序列化将该对象的状态保存到文件中,然后反序列化恢复。在反序列化过程中,即使原单例已经存在,Java的默认行为是会创建一个新的实例。这意味着反序列化后得到的对象与原来的单例不是同一个实例,从而破坏了单例模式的唯一性。 - 反射
利用反射可以访问私有构造方法,创建新的单例实例,也破坏了单例。
如果单例类的构造方法没有被声明为私有(或者虽然是私有的但未做额外保护),那么可以通过反射机制调用私有构造方法来创建新的实例。这同样会导致系统中存在多个单例实例,也破坏了单例。
解决方法
针对序列化的解决方法
1 | package com.kakawanyifan; |
1 | import pickle |
解释说明:
- 问题背景:
- 在Python中使用
pickle模块序列化对象时,反序列化默认会创建新实例。 - 这会破坏单例模式的唯一实例保证。
- 在Python中使用
__reduce__方法的关键作用:- 这是Python控制序列化行为的特殊方法。
- 返回值决定了对象在反序列化时如何被重建。
- 这里返回的元组指示pickle使用
get_instance()方法来获取实例,而不是创建新对象。
- 工作原理:
- 当对象被反序列化时,Python会调用
get_instance()。 - 该方法会返回已存在的单例实例,而不是创建新实例。
- 这样确保了无论反序列化多少次,始终返回同一个实例。
- 当对象被反序列化时,Python会调用
解释说明
当Singleton的一个实例被序列化到文件或其他存储介质后,再从该介质反序列化回来时,Java会在创建新的Singleton对象后立即调用readResolve方法。
此时,readResolve方法返回的是之前已经存在的INSTANCE实例,而不是新创建的那个。
因此,反序列化过程不会生成新的实例,而是复用了原有的单例实例,从而防止了通过序列化破坏单例的情况。
在Python中,当单例对象被pickle序列化后反序列化时,会调用对象的__reduce__方法。
此方法返回类的get_instance方法,使得反序列化过程中不创建新实例,而是调用get_instance()获取已存在的单例。
这样就确保了反序列化不会破坏单例模式,始终返回同一个实例。
针对反射的解决方法
当通过反射方式调用构造方法进行创建创建时,直接抛异常,不运行此中操作。
示例代码:
1 | package com.kakawanyifan; |
示例代码:
1 | class Singleton: |
解释说明:
- 构造函数防护机制:
- 在
__init__方法中检查_instance是否已存在。 - 如果实例已经存在,则抛出异常,阻止新实例创建。
- 这确保了只能通过
get_instance()方法获取实例。
- 在
- Python中的"反射":
- 虽然Python没有像Java那样的反射API,但可以通过直接调用构造函数来尝试创建新实例
- 这种防护措施确保即使直接调用
Singleton()也会被阻止。
- 与Java对比:
- Java中通过反射API可以强制访问私有构造函数。
- Python中所有方法本质上都是可访问的,防护依赖于运行时检查。
- 当使用Singleton()尝试创建实例时,会触发异常;而通过Singleton.get_instance()则能正确获取唯一实例。