基本概念
什么是假设检验
参数估计(parameter estimation)和假设检验(hypothesis testing),都是利用样本对总体进行某种推断,但推断的角度不同。
- 参数估计讨论的是用样本统计量估计总体参数的方法,总体参数在估计前是未知的。
- 而在假设检验中,则是先对总体参数提出一个假设,然后利用样本信息去检验这个假设是否成立。
举个例子。
假如我们,根据统计资料得知,1989年某地新生儿的平均体重为3190克,现从1990年的新生儿中随机抽取100个,测得其平均体重为3210克。现在,问1990年的新生儿与1989年相比,体重有无显著差异?
从调查结果看,1990年新生儿的平均体重为3210克,比1989年新生儿的平均体重3190克增加了20克,但这20克的差异可能源于不同的情况。可能是抽样的随机性造成的,也可能是1990年新生儿的体重与1989年新生儿的体重相比确实有所增加。
上述问题的关键点是:20克的差异说明了什么?这个差异能不能用抽样的随机性来解释?为了回答这个问题,我们可以采取假设的方法。
假设1989年和1990年新生儿的体重没有显著差异,如果用μ0表示1989年新生儿的平均体重,μ表示1990年新生儿的平均体重,我们的假设可以表示为μ0=μ或μ0−μ=0。现要利用1990年新生儿体重的样本信息检验上述假设是否成立,如果成立,说明这两年新生儿的体重没有显著差异;如果不成立,说明1990年新生儿的体重有了明显增加。
在这里,问题是以假设的形式提出的,问题的解决方案是检验提出的假设是否成立。
所以假设检验的实质是检验我们关心的参数:1990年的新生儿总体平均体重是否等于某个我们感兴趣的数值。
原假设和备择假设
引例
例如,我们提出的命题是,1990年的新生儿与1989年的新生儿在体重上没有差异。
采用统计的语言描述原假设的话,如下:
H0:μ0=μ
或者
H0:μ0−μ=0
我们H0表示原假设(null hypothesis)。由于原假设(H)的下标用0表示,所以也有资料称之为"零假设"。
除了原假设,还有备择假设(alternative hypothesis),如果原假设不成立,就拒绝原假设,在备选假设中作出选择。
在我们的例子中,备择假设的表达式为:
H1H1:μ0=μ:μ0−μ=0
原假设与备择假设互斥,肯定原假设,意味着放弃备择假设;否定原假设,意味着接受备择假设。有些资料把备择假设称为替换假设、或者研究假设。
定义
- 原假设:待检验的假设,又称"零假设",用H0表示,是研究者想收集证据予以反对的假设。总是有符号=、≥或≤。
- 备择假设:如果原假设不成立,就要拒绝原假设,而需要在另一个假设中做出选择,用H1表示,是研究者想收集证据予以支持的假设。总是有不等号(=、<或>)。
两类错误
对于原假设提出的命题,我们需要作出判断,这种判断可以用"原假设正确"或"原假设错误"来表述。这种判断有可能正确,也有可能不正确,也就是说,我们面临着犯错误的可能。
所犯的错误有两种类型:
- 第I类错误是原假设H0为真却被我们拒绝了。
犯这种错误的概率用α表示,所以也称α错误(α error)或弃真错误;
如果我们没有拒绝,则表明作出了正确的决策,其概率为1−α。
- 第II类错误是原假设为伪我们却没有拒绝。
犯这种错误的概率用β表示,所以也称β错误(β error)或取伪错误;
当H0为伪,我们拒绝H0,这也是正确的决策,其概率为1−β。
我们当然希望犯这两类错误的概率越小越好。但对于一定的样本量n,不能同时做到犯这两类错误的概率都很小。如果减少α错误,就会增大犯β错误的机会;若减少β错误,就会增大犯α错误的机会。
按理说,哪类错误所带来的后果更严重,危害更大,在假设检验中就应当把哪类错误作为首要的控制目标。
但在假设检验中,一般都是,首先控制犯α错误。这样做的主要的原因在于,从实用的观点看,原假设是什么常常是明确的,而备择假设是什么则常常是模糊的。
假设检验的流程
步骤
- 提出假设:首先提出原假设和备择假设。
- 确定适当的检验统计量。
在参数的假设检验中,如同在参数估计中一样,要借助样本统计量进行统计推断,这个统计量称为检验统计量。
选择统计量的方法与参数估计相同,需考虑是大样本还是小样本,总体方差已知还是未知。
- 规定显著性水平α。
原假设为真时,拒绝原假设的概率,被称为抽样分布的拒绝域,表示为α,常用的α值有0.01、0.05、0.10。
- 计算检验统计量的值。
- 作出统计决策。
根据给定的显著性水平α,查表得到临界值;将检验统计量的值与α水平的临界值进行比较,得出拒绝或不拒绝原假设的结论。
案例
提出假设
在上文,我们提出了原假设和备择假设。
H0H1:μ0=μ:μ0−μ=0
确定适当的检验统计量
我们假定总体σ已知,且样本量大,考虑采用z统计量,计算公式为:
z=(nσ)xˉ−μ0
规定显著性水平
我们假设显著性水平α=0.05。
计算检验统计量的值
假设新生儿体重的标准差为80克,即σ=80。
样本均值xˉ=3210,μ0=3190,σ=80,n=100,
z=(nσ)xˉ−μ0=(10080)3210−3190=2.5
作出统计决策

计算出的z值2.5落入拒绝域,所以拒绝原假设,认为与1989年相比,1990年新生儿的体重有显著差异。
利用P值进行决策
为什么需要P值
上文,我们根据检验统计量落入的区域作出是否拒绝原假设的决策。确定α以后,拒绝域的位置也就相应确定了,其好处是进行决策的界限清晰,但缺陷是进行决策面临的风险是笼统的。
在上面的例子中,z=2.5,落入拒绝域,我们拒绝原假设,并知道犯弃真错误的概率(面临的风险)为0.05;如果z=2.0,同样落入拒绝域,我们拒绝原假设面临的风险也是0.05,0.05是一个通用的风险概率。但根据不同的样本结果进行决策,面临的风险事实上是有差别的,为了精确地反映决策的风险度,可以利用P值进行决策。
什么是P值
P值,一个概率值,当原假设为真时所得到的样本观察结果或更极端结果出现的概率。被称为观察到的(或实测的)显著性水平,表示H0能被拒绝的最小值。
如果P值很小,说明这种情况发生的概率很小,P值越小,我们拒绝原假设的理由就越充分。
在左侧检验时,P值为曲线上方小于等于检验统计量部分的面积。
在右侧检验时,P值为曲线上方大于等于检验统计量部分的面积。
P值的大小取决于三个因素:
- 样本数据与原假设之间的差异。
- 样本量。
- 被假设参数的总体分布。
P值的优点是反映了观察到的实际数据与原假设之间不一致的概率值,与传统的拒绝域范围相比,P是一个具体的值,这样就提供了更多的信息。
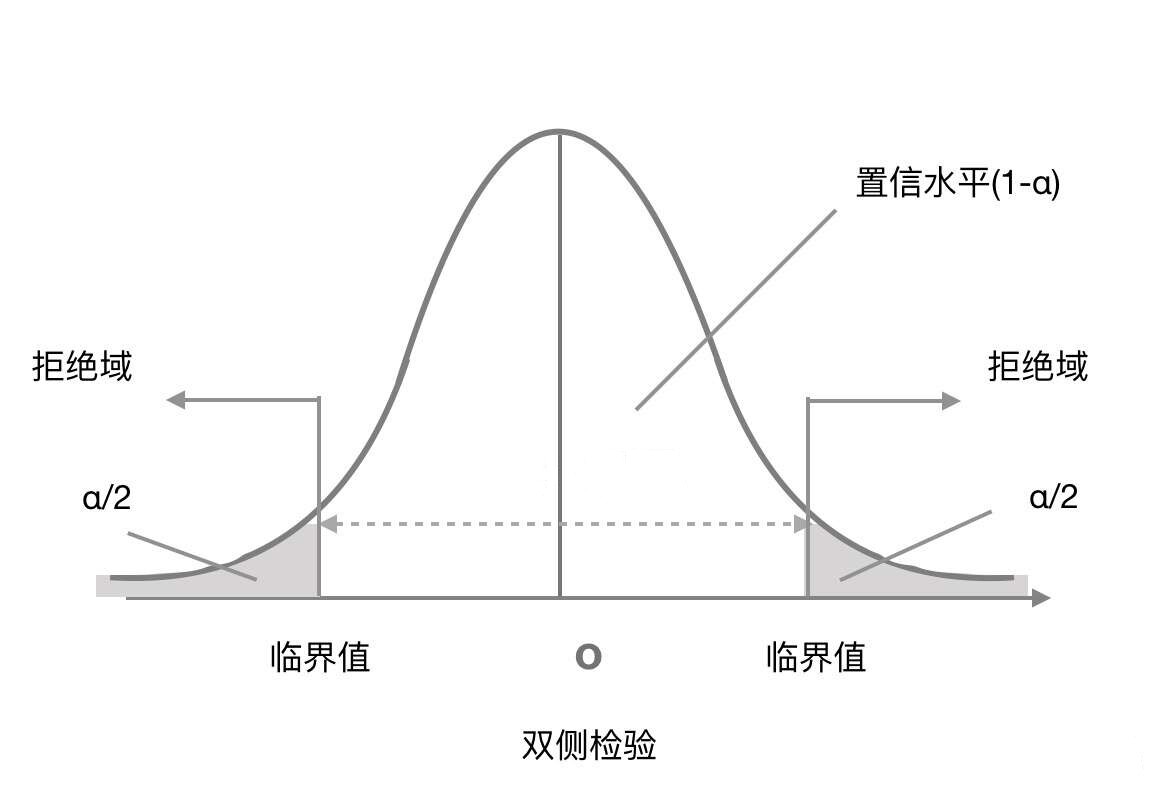
单侧检验
上文的例子,是双侧检验,不能太大,也不能太小。
除了双侧检验,还有单侧检验。
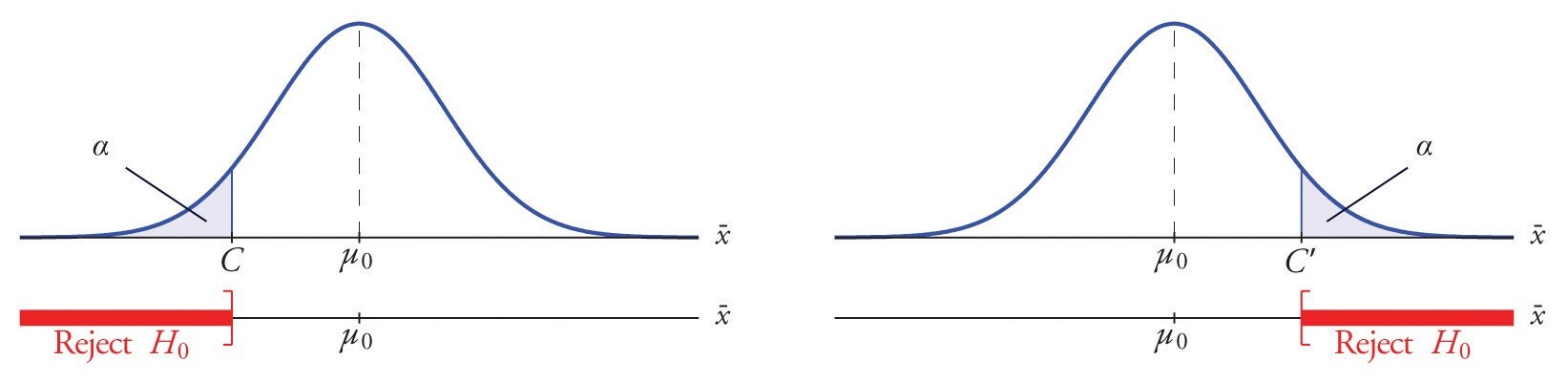
- 左单侧检验:下限检验,所考察的数值越大越好。
- 右单侧检验:上限检验,所考察的数值越小越好。
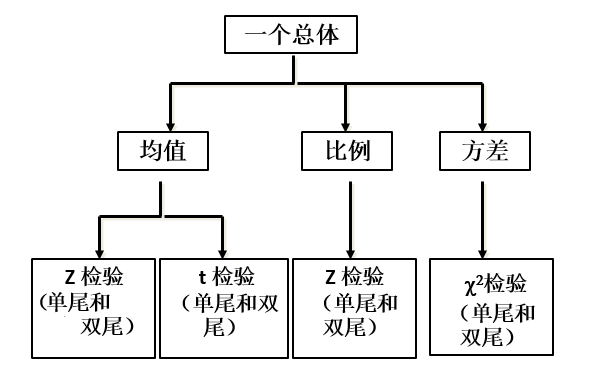
一个总体参数的检验
确定适当的检验统计量
总体均值的检验
大样本
方法
假定条件:
总体服从正态分布;
或者,可用正态分布来近似(大样本)
使用z统计量
如果σ已知
z=(nσ)xˉ−μ0∼N(0,1)
如果σ未知,用S代替σ
z=(ns)xˉ−μ0∼N(0,1)
案例
某机床厂加工一种零件,根据经验知道,该厂加工零件的椭圆度渐近服从正态分布,其总体均值为0.081mm,今另换一种新机床进行加工,取200个零件进行检验,得到椭圆度均值为0.076mm,
样本标准差为0.025mm,问新机床加工零件的椭圆度总体均值与以前有无显著性差别。(α=0.05)
根据题意,设置原假设和备择假设
H0H1:μ=0.081没有显著差别:μ=0.081有显著差别
这是一个双侧检验问题,μ>μ0或μ<μ0都可以拒绝原假设。
由题意可知,可知:
μ0sxˉ=0.076=0.081=0.025
因为n>30,故选用z统计量。
z=(ns)xˉ−μ0=(2000.025)0.076−0.081=−2.83
当α=0.05,有临界值如下:
z2α=±1.96
根据决策准侧,我们拒绝H0,认为新老机床加工零件椭圆度的均值有显著性差异。
样本量小,方差已知
方法
与大样本类似,使用z统计量
z=(nσ)xˉ−μ0∼N(0,1)
案例
假设某产品的使用寿命服从正态分布N(1020,1002)。现从最近生产的一批产品中随机抽取16 只,测得样本平均寿命为1080小时。试在0.05的显著性水平下判断这批产品的使用寿命是否有显著提高?
H0H1z:μ≤1020:μ>1020=(nσ)xˉ−μ0=(16100)1080−1020=2.4
因为这是右侧检验,查表可以得到临界值zα=z0.05=1.645。
因为2.4>1.645,即有证据表明这批灯泡的使用寿命有显著提高。
样本量小,方差未知
方法
假定条件:总体为正态分布,σ未知,且小样本。
使用t统计量
t=(ns)xˉ−μ0∼t(n−1)
案例
某机器制造出的厚度为5cm,今欲了解机器性能是否良好,随机抽取10块肥皂作为样本,测得平均厚度为5.3cm,标准差为0.3cm,试以0.05的显著性水平检验机器性能良好的假设。
如果机器性能良好,生产出的肥皂厚度将在5cm上下波动,过薄或过厚都不符合产品质量标准,所以,根据题意,这是双侧检验问题。
由于总体σ未知,且样本n较小,所以应采用t统计量。
已知条件为:
μxˉσnα=5=5.3=0.3=10=0.05
原假设和备择假设如下:
H0H1:μ=5:μ=5
t=(ns)xˉ−μ0=(100.3)5.3−5=3.16
当α=0.05,自由度n=10−1=9时,t2α=2.2622。
因为t>t2α,样本统计量落入拒绝域,故拒绝H0,接受H1,说明该机器的性能不好。
单样本t检验的效应量
特别的。
如果检验结果是拒绝原假设,则可以用效应量来分析样本统计量与假设值的差异程度。单样本t检验的效应量通常使用(Cohen)的d统计量来度量,计算公式为:
d=样本标准差∣样本均值−假设的总体均值∣
该效应量表示样本均值与假设的总体均值的差异是多少个样本标准差。
总体比例的检验
方法
假设条件
有两类结果
并且,总体服从二项分布,可用正态分布来近似
采用z统计量
z=nπ0(1−π0)p−π0
- p为样本比例
- π0为总体比例π的假设值
案例
一项统计结果声称,某市老年人口(年龄在65岁以上)所占比例为14.7%,该市老年人口研究会为了检验该项统计是否可靠,随机抽选了400名居民,发现其中有57人年龄在65岁以上。
如果α=0.05,问调查结果是否支持该市老年人口比例为14.7%的看法?
原假设和备择假设:
H0H1:π=14.7%:π=14.7%
根据题意有:
pz=40057=0.1425(14.25%)=nπ0(1−π0)p−π0=4000.147(1−0.147)0.1425−0.147=−0.254
这是一个双侧检验,当α=0.05时,有z2α=±1.96。
因此,不能拒绝H0,可以认为调查结果支持了该城市老年人口所占比例为14.7%的看法。
总体方差的检验
方法
方差检验所使用的是χ2统计量。
χ2=σ2(n−1)s2∼χ2(n−1)
若进行双侧检验,拒绝域分布在χ2统计量分布曲线的两边;若是单侧检验,拒绝域分布在χ2统计量分布曲线的一边。
案例
某厂商生产出一种新型的饮料装瓶机器,按设计要求,该机器装一瓶1000ml的饮料误差上下不超过 1ml。如果达到设计要求,表明机器的稳定性非常好。
现从该机器装完的产品中随机抽取25瓶,分别进行测定,然后用样本观测值分别减1000ml,得到数据:0.3、-0.4、-0.7、1.4、-0.6、-0.3、-1.5、0.6、-0.9、1.3、-1.3、0.7、1、-0.5、0、-0.6、0.7、-1.5、-0.2、-1.9、-0.5、1、-0.2、-0.6、1.1
试以α=0.05的显著性水平检验该机器的性能是否达到设计要求。
这里采用单侧检验,原假设和备择假设为
H0H1:σ2≤1:σ2>1
由样本数据可以计算出s2=0.866
对于"误差上下不超过1ml",我们认为其含义是方差为1。
χ2χ0.052(24)=σ2(n−1)s2=1(25−1)×0.866=20.8=36.415
故不拒绝原假设H0,可以认为该机器的性能达到设计要求。
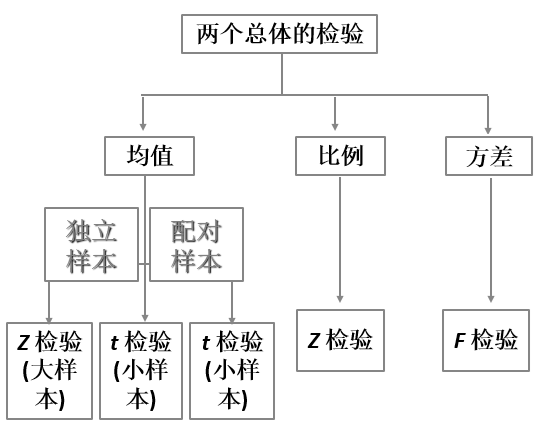
两个总体参数的检验
确定适当的检验统计量
独立样本总体均值之差的检验
方差已知
方法
假定条件:
两个样本是独立的随机样本;
并且,两个总体都是正态分布,或者满足大样本
使用正态分布统计量z
z=n1σ12+n2σ22(xˉ1−xˉ2)−(μ1−μ2)∼N(0,1)
案例
有两种方法可用于制造某种以抗拉强度为重要特征的产品。根据以往的资料得知,第一种方
法生产出的产品抗拉强度的标准差为8千克,第二种方法的标准差为10千克。从两种方法生产的
产品中各抽一个随机样本,样本容量分别为n1=32,n2=40,测得xˉ1=50,xˉ2=44。
问这两种方法生产出来的产品平均抗拉强度是否有显著差别(α=0.05)?
由于检验两种方法生产的产品在抗拉强度上是否存在显著性差别,并未涉及方向,所以是双侧检验。
原假设和备择假设:
H0H1=μ1−μ2=0=μ1−μ2=0
因为σ12和σ22已知,考虑选用z作为检验统计量,即有
z=n1σ12+n2σ22(xˉ1−xˉ2)−(μ1−μ2)=3264+40100(50−44)−0=2.83
当α=0.05时,z2α=1.96。
因为z>z2α,所以拒绝H0,即两种方法生产出来的产品其抗拉强度有显著差别。
方差未知 小样本
假定条价
假设条件:
两个样本是独立的随机样本;
并且,两个总体都是正态分布
方差相等
如果σ12、σ22未知且σ12=σ22
此时σxˉ1−xˉ2的估计为
σ^xˉ1−xˉ2=spn11+n21
检验统计量t:
t=spn11+n21(xˉ1−xˉ2)−(μ1−μ2)∼t(n1+n2−2)
其中
sp2=n1+n2−2(n1−s)s12+(n2−1)s22
方差不相等
两个总体方差未知但不相等,即σ12=σ22;
此时σxˉ1−xˉ2的估计为
σ^xˉ1−xˉ2=n1s12+n2s22
此时,两个样本均值之差经标准化后近似服从自由度为f的t分布。
自由度f的计算公式为:
f=n1−1(n1s12)2+n2−1(n2s22)2(n1s12+n2s22)2
检验统计量t:
t=n1s12+n2s22(xˉ1−xˉ2)−(μ1−μ2)∼t(f)
案例
“多吃谷物,将有助于减肥。”
为了验证这个假设,随机抽取了35人,询问他们早餐和午餐的通常食谱,根据他们的食谱,将其分为二类,一类为经常的谷类食用者(总体1),一类为非经常谷类食用者(总体2)。然后测度每人午餐的大卡摄取量。经过一段时间的实验,得到两组数据。假设总体的方差不相等,检验该假设。(α=0.05)
样本1:568、681、636、607、555、496、540、539、529、562、589、646、596、617、584
样本2:650、569、622、630、596、637、628、706、617、624、563、580、711、480、688、723、651、569、709、632
原假设和备择假设:
H0H1:μ1−μ2≥0:μ1−μ2<0
代入公式,计算f
f=32.34≈32
计算t
t=n1s12+n2s22(xˉ1−xˉ2)−(μ1−μ2)=152431.429+203675.461(589.67−629.25)−0=−2.128
t0.05(32)=1.694,在给定的显著性水平下临界值为−1.694,−2.128<−1.694,落入拒绝域,没有证据表明多吃谷物将有助于减肥。
配对样本的均值差的检验
方法
配对样本的检验需要假定两个总体配对的差值服从正态分布,而且配对差值是从差值总体中随机抽取的。
对于小样本情形,配对差值经标准化后服从自由度为n−1的t分布,检验统计量为:
t=(nsd)dˉ−(μ1−μ2)
其中,dˉ为配对差值的均值;sd为配对差值的标准差。
配对样本t检验的效应量
如果检验结果拒绝原假设,则可以计算效应量来进一步分析配对样本差值的均值与假设的总体配对差值的均值之间的差异程度。
配对样本t检验的效应量的估计由Cohen的d统计量给出。计算公式为:
d=配对差值的标准差∣配对样本差值的均值∣=sddˉ=n∣t∣
两个总体比例之差的检验
设两个总体服从二项分布,这两个总体中具有某种特征单位数的比例分别为π1和π2,但π1和π2未知,可以用样本比例p1和p2代替。
这时候有两种情况:
- 检验两个总体比例之差为零的假设
- 检验两个总体比例之差某个不为零的常数的假设
检验两个总体比例之差为零
方法
检验两个总体比例之差为零的假设,也就是,检验两个总体比例相等的假设。
该假设表达式为:H0:π1−π2=0或H0:π1=π2。
在原假设成立的条件下,最佳的方差是p(1−p),其中p是将两个样本合并后得到的比例估计量,即
p=n1+n2x1+x2=n1+n2p1n1+p2n2
- x1表示样本n1中具有某些特征的单位数。
- x2表示样本n2中具有某些特征的单位数。
在大样本条件下,统计量z的表达式为:
z=p(1−p)(n11+n21)p1−p2
案例
人们普遍认为麦当劳的主要消费群体是青少年,但对市场进一步细分却发现有不同的观点。一种观点认小学生更喜欢麦当劳,另一种观点认为中学生对麦当劳的喜爱程度不亚于小学生。
某市场调查公司对此在某地区进行了一项调查,随机抽取了100名小学生和100名中学生,调查的问题是:如果有麦当劳和其他中式快餐,你会首选哪种作为经常性午餐?
调查结果如下:小学生(样本1)100人中有76人把麦当劳作为首选的经常性午餐,中学生(样本2)100人中有69人作出同样的选择。
调查结果支持哪种观点?
原假设和备择假设:
H0H1:π1−π2=0:π1−π2=0
根据题意有:
pz=n1+n2x1+x2=100+10076+69=0.725=p(1−p)(n11+n21)p1−p2=0.725×(1−0.725)×(1001+1001)0.76−0.69=1.11
由决策准则可知,z=1.11落入接受域,故调查结果支持原假设,即在该地区小学生和中学生对麦当劳的偏爱程度没有显著差异。
检验两个总体比例之差是某个不为零的常数
方法
检验两个总体比例之差是某个不为零的常数的假设,即检验π1−π2=d0(d0=0),在这种情况下,两个样本比例之差p1−p2,近似服从以π1−π2为数学期望,n1p1(1−p1)+n2p2(1−p2)为方差的正态分布,因而可以选择z作为检验统计量。
z=n1p1(1−p1)+n2p2(1−p2)(p1−p2)−(π1−π2)=n1p1(1−p1)+n2p2(1−p2)(p1−p2)−d0
案例
有一项研究报告说青少年经常上网聊天,男生的比例至少超过女生10个百分点,即π1−π2≥10%(π1为男生比例,π2为女生比例)。现对150个男生和150个女生进行上网聊天的频度调查,其中经常聊天的男生有68人,经常聊天的女生有54人。调查结果是否支持研究报告的结论(α=0.05)?
原假设和备择假设:
H0H1:π1−π2≥10%:π1−π2<10%
由题意可知:
n1n2p1p2d0=150=150=15068=0.45=15054=0.36=10%
计算检验统计量z:
z=n1p1(1−p1)+n2p2(1−p2)(p1−p2)−d0=1500.45(1−0.45)+1500.36(1−0.36)(0.45−0.36)−0.1=−0.177
这是一个左单侧检验,zα=−1.645,由决策准则可知z=−0.177,落入非拒绝域,故无法推翻原假设,调查结果支持研究报告的结论。
两个总体方差比的检验
方法
假设条件:
两个总体都服从正态分布;
并且,两个独立的随机样本
检验统计量:
F=(σ22s22)(σ12s12)∼F(n1−1,n2−1)
案例
假设,两个样本的方差分别为s12=2431.429、s22=3675.461,现以α=0.05的显著性水平检验两总体方差是否相等。
原假设和备择假设:
H0H1:σ12=σ22:σ12=σ22
检验统计量F为:
F=(σ22s22)(σ12s12)=s22s12=3675.4612431.429=0.662
在α=0.05的显著性水平下,F0.025(14,19)=2.62,F0.975(14,19)=0.352。统计量落入接受域,不拒绝原假设。因此可以认为两总体方差没有显著差异。
正态性检验
什么是正态性检验
正态性检验(normality test),检验样本数据是否来自正态总体就是。
正态性检验方法有图示法和检验法两大类。关于图示法我们不讨论,我们讨论检验法。
检验的原假设是总体服从正态分布;如果检验获得的P值小于指定的显著性水平,则拒绝原假设,表示总体不服从正态分布;如果P值较大而不能拒绝原假设,则可以认为总体服从正态分布。
正态性的检验方法有很多,本文讨论两种常用的检验方法:
- S-W 检验
- K-S 检验
S-W 检验
S-W检验,也用资料称之为W检验,用顺序统计量W来检验分布的正态性。
S-W检验的具体步骤如下:
首先,对研究的总体提出如下假设
H0H1:总体服从正态分布:总体不服从正态分布
然后,按下列公式计算检验统计量W
W=∑(yi−yˉ)2∑aiyi2
其中,yi为排序后的样本数据;yˉ为样本均值;ai是样本量为n时对应的系数。可以通过《正态性检验统计量W的系数ai(n)数值表》进行查询。
当P值小于指定显著性水平时表示总体不符合正态分布。
S-W检验适用于样本量较小的情形,一般认为样本量[8,50]适用。
K-S 检验
当样本量较大时,可使用K-S检验。该检验既可用于大样本,也可用于小样本,主要用于检验总体是否服从某个己知的理论分布(包括正态分布、泊松分布、均匀分布、指数分布)。
K-S检验是将某一变量的累积分布函数与特定的分布函数进行比较,检验其拟合程度。
设总体的累积分布函数为F(x),已知的理论分布函数为F0(x),则检验的原假设和备择假设为:
H0H1:F(x)=F0(x)(总体分布与指定的理论分布差鼻不显著):F(x)=F0(x)(总体分布与指定的理论分布差异显著)
设各样本观测值在理论分布中出现的累积概率为F0(x),各样本观测值的实际累积概率为S(x),实际累积概率与理论累积概率的差值为D(x),差值序列中的最大绝对差值为:
D=max(∣s(xi)−F0(xi)∣)
由于实际累积概率为离散值,通常做以下修正:
D=max{(∣s(xi)−F0(xi)∣),(∣s(xi−1−F0(xi))∣)}
上式就是K-S检验的统计量。
在小样本情形下,统计量D服从Kolmogorov分布;在大样本情形下,则用正态分布近似,统计量为
z=nD
如果H0成立,每次抽样得到的D值应当不会与零偏离太远,否则就应拒绝H0。
对于设定的显著性水乎α,若检验统计量D(或Z)对应的概率小于α,则拒绝H0,表示总体分布与指定的理论分布差异显著。
K-S检验要求样本数据是连续的数值型数据,而且要求理论分布已知。比如,要检验样本数据是否来自N(100,102)的正态总体。当总体均值和方差未知时,可以用样本均值和方差来代替。
Python计算
总体均值的检验
一个总体均值的检验
大样本的检验
为了监测空气质量,某城市环保部门每隔几周对空气中的PM2.5进行一次随机测试。己知该城市过去每立方米空气中PM2.5的均值是81(微克/立方米)。统计了在最近一段时间的40次检测中,每立方米空气中的PM2.5数值。
根据最近的测量数据,能否认为该城市每立方米空气中的PM2.5均值显薯低于81(微克/立方米) (α=0.05)。
这里关心的是空气中PM2.5的均值是否显著低于过去的均值,也就是是否小于81(微克/立方米),属于左侧检验。
提出的假设为:
H0H1:μ≥81:μ<81
示例代码:
1
2
3
4
5
6
7
8
9
| import pandas as pd
from statsmodels.stats.weightstats import ztest
df = pd.read_csv('XXX.csv')
z, p_value = ztest(x1=df['PM2.5值'], value=81, alternative='smaller')
print(z, p_value)
|
运行结果:
1
| -1.1855576482277341 0.11789851794613643
|
在该项检验中,z=−1.1856,p=0.1179。
因为p>0.05,不拒绝H0,没有证据表明该城市每立方米空气中的PM2.5均值显著低于81(微克/立方米)。
小样本的检验
一种建筑材料的厚度要求为5cm,高于或低于该标准均被认为是不合格的。现对一家生产企业提供的20个样品进行检测,记录其检测结果。假定建筑材料的厚度服从正态分布,在0.05的显著性水平下,检验该企业生产的建筑材料的厚度是否符合要求。
依题意建立如下假设
H0H1:μ=5:μ=5
示例代码:
1
2
3
4
5
6
7
8
9
10
| import pandas as pd
from scipy.stats import ttest_1samp
df = pd.read_csv('XXX.csv')
t, p_value = ttest_1samp(a=df['厚度'], popmean=5)
print(t, p_value)
|
运行结果:
1
| -5.627314338711359 1.997624965504381e-05
|
在该项检验中,t=−5.6273,p=1.998e−05,由于P<0.05,拒绝H0,即有证据显示该企业生产的建筑材料的厚度不符合要求。
两个总体均值差的检验
独立大样本的检验
为分析男女学生上网时间是否有差异,从男女学生中各随机抽取36人,得到每天的上网时间数据。设显著性水平为0.05,检验男女学生上网的平均时间是否有显著差异。
用μ1表示男生上网的平均时间,用μ2表示女生上网的平均时间。由于关心的是上网的平均时间是否有显著差异,故提出的假设为:
H0H1:μ1−μ2=0:μ1−μ2=0
示例代码:
1
2
3
4
5
6
7
8
9
10
11
| import pandas as pd
from statsmodels.stats.weightstats import ztest
df = pd.read_csv('XXX.csv')
x1 = df['男生上网时间']
x2 = df['女生上网时间']
z, p_value = ztest(x1=x1, x2=x2, alternative='two-sided')
print(z, p_value)
|
运行结果:
1
| 1.118824633522991 0.263214960453917
|
在该项检验中,z=1.1188,p=0.2632,由于P>0.05,不拒绝H0,即没有证据显示男女学生上网的平均时间有显著差异。
独立小样本的检验
为比较两家企业生产的同类产品的平均使用寿命是否有显著差异,质检人员对两家企业提供的各20个样品进行检测,得到的使用寿命数据。检验两家企业产品的平均使用寿命是否有显著差异(α=0.05)。
现,假设两种情况,分别检验。
- 假设两个总体方差相等
- 假设两个总体方差不相等
用μ1表示甲企业产品的平均使用寿命,用μ2表示乙企业产品的平均使用寿命。依题意提出如下假设:
H0H1:μ1−μ2=0:μ1−μ2=0
假设总体方差相等,示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import pandas as pd
from statsmodels.stats.weightstats import ttest_ind
df = pd.read_csv('XXX.csv')
x1 = df['甲企业']
x2 = df['乙企业']
xbar1 = x1.mean()
xbar2 = x2.mean()
t, p_value, _ = ttest_ind(x1=x1, x2=x2, alternative='two-sided', usevar='pooled')
print(t, p_value)
|
运行结果:
1
| -3.4942702671563377 0.001224733436714876
|
所以,拒绝原假设,表明两家企业产品的平均使用寿命有显著差异。
假设总体方差不相等,修改ttest_ind方法的usevar参数的值为unequal。示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import pandas as pd
from statsmodels.stats.weightstats import ttest_ind
df = pd.read_csv('XXX.csv')
x1 = df['甲企业']
x2 = df['乙企业']
xbar1 = x1.mean()
xbar2 = x2.mean()
t, p_value, _ = ttest_ind(x1=x1, x2=x2, alternative='two-sided', usevar='unequal')
print(t, p_value)
|
运行结果:
1
| -3.4942702671563377 0.0013526838634792162
|
同样,拒绝原假设。
配对样本的检验
某饮料公司研制出一款新产品,为了比较消费者对新旧产品口感的满意程度,随机抽取10个消费者,让每个消费者先品尝一款饮料,再品尝另一款饮料,两款饮料的品尝顺序是随机的,然后每个消费者要对两款钦料分别进行评分([0,10]分),记录评分结果。设显著性水平α=0.05,检验消费者对两款饮料的评分是否有显著差异。
用μ1表示消费者对旧款饮料的平均评分,用μ2表示消费者对新款饮料的平均评分。依题意提出的原假设与备择假设为:
H0H1:μ1−μ2=0:μ1−μ2=0
示例代码:
1
2
3
4
5
6
7
8
| import pandas as pd
from scipy.stats import ttest_rel
df = pd.read_csv('XXX.csv')
t, p_value = ttest_rel(a=df['旧款饮料'], b=df['新款饮料'])
print(t, p_value)
|
运行结果:
1
| -2.750847901848533 0.022445658672013483
|
在该项检验中,t=−2.750848,p=0.02245,由于p<0.05,拒绝H0,消费者对新旧两款饮料的评分有显著差异。
总体比例的检验
一个总体比例的检验
一家电视台的影视频道制作人认为,某电视连续剧如果在黄金时段播出,收视率将会达到25%以上。经过一周的试播放后,该制作人随机抽取一个由2000人组成的样本,发现有450名观众观看了该电视连续剧。取显著性水平α=0.05,检验收视率是否达到制作人的预期。
制作人想支持的观点是收视率达到25%以上,因此提出的假设为:
H0H1:π≤25%:π>25%
示例代码:
1
2
3
4
5
6
7
8
9
10
| import numpy as np
from scipy.stats import norm
n = 2000
p = 450 / 2000
pi0 = 0.25
z = (p - pi0) / np.sqrt(pi0 * (1 - pi0) / n)
p_value = 1 - norm.cdf(z)
print(z, p_value)
|
运行结果:
1
| -2.5819888974716108 0.9950883627462404
|
在该项检验中,z=−2.581989,p=0.995088,由于p>0.05,不拒绝H0,没有证据表明收视率达到了制作人的预期。
两个总体比例差的检验
一所大学准备采取一项新的上网收费措施,为了解男女学生对这一措施的看法是否有差异,分别抽取200名男生和200名女生进行调查。其中的一个问题是"你是否赞成采取新的上网收费措施?"。其中,男生表示赞成的比例为27%,女生表示赞成的比例为35%。调查者认为,男生表示赞成的比例显著低于女生。取显著性水平α=0.05,样本提供的证据是否支持调查者的看法?
用π1表示男生表示赞成的比例,用π2表示女生表示赞成的比例。
依题意提出如下假设:
H0H1:π1−π2≥0:π1−π2<0
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
from scipy.stats import norm
n1 = 200
n2 = 200
p1 = 0.27
p2 = 0.35
p = (p1 * n1 + p2 * n2) / (n1 + n2)
z = (p1 - p2) / np.sqrt(p * (1 - p) * (1 / n1 + 1 / n2))
p_value = norm.cdf(z)
print(z, p_value)
|
运行结果:
1
| -1.7297550002576414 0.04183702872205522
|
在该项检验中,z=−1.7298,p=0.041837,由于π<0.05,拒绝H0,样本提供的证据文持调查者的看法,即男生表示赞成的比例显著低于女生。
总体方差的检验
一个总体方差的检验
啤酒生产企业采用自动生产线灌装啤酒,每瓶的填装量为640ml,但受某些不可控因素的影响,每瓶的填装量会有差异。假定生产标准规定每瓶填装量的方差不应超过16。企业质检部门抽取了10瓶啤酒进行检验,得到样本数据。检验填装量的方差是否符合要求(α=0.05)。
依题意提出如下假设:
H0H1:σ2≤16:σ>16
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import pandas as pd
from scipy.stats import chi2
data = pd.read_csv('XXX.csv')
x = data['填装量']
sigma0_2 = 16
s2 = x.var()
n = len(x)
df = n - 1
chi2_value = (n - 1) * s2 / sigma0_2
p_value = 1 - chi2.cdf(chi2_value, df=df)
print(chi2_value, p_value)
|
运行结果:
1
| 2.974062500000023 0.9653144162422501
|
在该项检验中,χ2=−2.9741,p=0.9653,由于p>0.05,不拒绝H0,没有证据显示啤酒填装量的方差不符合要求。
两个总体方差比的检验
沿用上文"Python计算-总体均值的检验-两个总体均值差的检验-独立小样本的检验"的数据。
现在检验两家企业产品使用寿命的方差是否有显著差异(α=0.05)。
令甲企业产品使用寿命的方差为σ12,乙企业产品使用寿俞的方差为σ22,依题意建立的原假设与备择假设为:
H0H1:σ22σ12=1:σ22σ12=1
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import pandas as pd
from scipy.stats import f
df = pd.read_csv('XXX.csv')
x1 = df['甲企业']
x2 = df['乙企业']
s1_square = x1.var()
dfn = len(x1) - 1
s2_square = x2.var()
dfd = len(x2) - 1
f_value = s1_square / s2_square
p_value = (1 - (f.cdf(f_value, dfn=dfn, dfd=dfd))) * 2
print(f_value, p_value)
|
运行结果:
1
| 2.115367444040601 0.11103857279289997
|
在该项检验中,f=2.1154,p=0.1110,由于p>0.05,不拒绝H0,没有证据表明两家企业产品使用寿命的方差有显著差异。
正态性检验
S-W 检验
沿用上文"Python计算-总体均值的检验-一个总体均值的检验"的数据。
用S-W方法检验PM2.5是否服从正态分布(α=0.05)。
提出假设:
H0H1:PM2.5服从正态分布:PM2.5不服从正态分布
示例代码:
1
2
3
4
5
6
7
8
| import pandas as pd
from scipy.stats import shapiro
df = pd.read_csv('XXX.csv')
w, p_value = shapiro(df['PM2.5值'])
print(w, p_value)
|
运行结果:
1
| 0.9827210665767173 0.7888236849198136
|
在该项检验中,w=0.9827,p=0.7888,由于p>0.05,不拒绝原假设,即没有证据显示PM2.5不服从正态分布。
K-S 检验
沿用上文"Python计算-总体均值的检验-一个总体均值的检验"的数据。
用K-S检验方法检验该PM2.5是否服从正态分布(α=0.05)。
提出假设:
H0H1:PM2.5服从正态分布:PM2.5不服从正态分布
K-S检验要求正态总体是已知的,即参数μ和σ2已知。当μ和σ2未知,可以考虑分别用样本均值xˉ和样本方差s2来代替。
示例代码:
1
2
3
4
5
6
7
8
9
10
| import pandas as pd
from scipy.stats import kstest
df = pd.read_csv('XXX.csv')
x = df['PM2.5值']
d, p_value = kstest(x, 'norm', alternative='two-sided', mode='asymp', args=(x.mean(), x.std()))
print(d, p_value)
|
运行结果:
1
| 0.09033014922111654 0.8998565903483988
|
在该项检验中,d=0.0903,p=0.8999,由于p>0.05,不拒绝H0,没有证据显示PM2.5不服从正态分布。