之前我们讨论的都是分类问题。这一章,我们讨论的回归问题。
矩阵
首先,我们复习一下"矩阵的定义及其基本运算"。
矩阵的定义:
由m ∗ n m * n m ∗ n m m m n n n
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋮ a m 1 a m 2 ⋯ a m n ] \left[
\begin{matrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & & \vdots \\
a_{m1} & a_{m2} & \cdots & a_{mn} \\
\end{matrix}
\right]
⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 1 a 2 1 ⋮ a m 1 a 1 2 a 2 2 ⋮ a m 2 ⋯ ⋯ ⋯ a 1 n a 2 n ⋮ a m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
称为一个m ∗ n m * n m ∗ n A \bold{A} A ( a i j ) m ∗ n (a_{ij})_{m * n} ( a i j ) m ∗ n
当m = n m = n m = n n n n
对于两个矩阵,A = ( a i j ) m ∗ n \bold{A}=(a_{ij})_{m * n} A = ( a i j ) m ∗ n B = ( b i j ) s ∗ k \bold{B}=(b_{ij})_{s * k} B = ( b i j ) s ∗ k m = s m=s m = s n = k n=k n = k A \bold{A} A B \bold{B} B
矩阵的基本运算
相等
当A \bold{A} A B \bold{B} B A = B \bold{A} = \bold{B} A = B
加法
只有A \bold{A} A B \bold{B} B C = A + B \bold{C} = \bold{A} + \bold{B} C = A + B c i j = a i j + b i j c_{ij} = a_{ij} + b_{ij} c i j = a i j + b i j
数乘矩阵
k k k A \bold{A} A
k A = k [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋮ a m 1 a m 2 ⋯ a m n ] = [ k ∗ a 11 k ∗ a 12 ⋯ k ∗ a 1 n k ∗ a 21 k ∗ a 22 ⋯ k ∗ a 2 n ⋮ ⋮ ⋮ k ∗ a m 1 k ∗ a m 2 ⋯ k ∗ a m n ] k\bold{A} = k \left[
\begin{matrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & & \vdots \\
a_{m1} & a_{m2} & \cdots & a_{mn} \\
\end{matrix}
\right] = \left[
\begin{matrix}
k*a_{11} & k*a_{12} & \cdots & k*a_{1n} \\
k*a_{21} & k*a_{22} & \cdots & k*a_{2n} \\
\vdots & \vdots & & \vdots \\
k*a_{m1} & k*a_{m2} & \cdots & k*a_{mn} \\
\end{matrix}
\right]
k A = k ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 1 a 2 1 ⋮ a m 1 a 1 2 a 2 2 ⋮ a m 2 ⋯ ⋯ ⋯ a 1 n a 2 n ⋮ a m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ k ∗ a 1 1 k ∗ a 2 1 ⋮ k ∗ a m 1 k ∗ a 1 2 k ∗ a 2 2 ⋮ k ∗ a m 2 ⋯ ⋯ ⋯ k ∗ a 1 n k ∗ a 2 n ⋮ k ∗ a m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
矩阵加法和数乘的运算律
交换律 A + B = B + A \bold{A} + \bold{B} = \bold{B + \bold{A}} A + B = B + A
结合率 ( A + B ) + C = A + ( B + C ) (\bold{A} + \bold{B}) + \bold{C} = \bold{A} + (\bold{B} + \bold{C}) ( A + B ) + C = A + ( B + C )
分配律 k ( A + B ) = k A + k B k(\bold{A} + \bold{B}) = k\bold{A} + k\bold{B} k ( A + B ) = k A + k B
矩阵的乘法
当A \bold{A} A m ∗ s m * s m ∗ s B \bold{B} B s ∗ n s * n s ∗ n A \bold{A} A B \bold{B} B A \bold{A} A B \bold{B} B C = A B \bold{C} = \bold{A}\bold{B} C = A B C \bold{C} C i i i j j j c i j c_{ij} c i j A \bold{A} A i i i s s s B \bold{B} B j j j s s s
A = [ a 11 a 12 a 13 a 21 a 22 a 23 ] B = [ b 11 b 21 b 31 ] \bold{A} = \left[
\begin{matrix}
a_{11} & a_{12} & a_{13} \\
a_{21} & a_{22} & a_{23}
\end{matrix}
\right]
\bold{B} = \left[
\begin{matrix}
b_{11} \\
b_{21} \\
b_{31}
\end{matrix}
\right]
A = [ a 1 1 a 2 1 a 1 2 a 2 2 a 1 3 a 2 3 ] B = ⎣ ⎢ ⎡ b 1 1 b 2 1 b 3 1 ⎦ ⎥ ⎤
c 11 = a 11 ∗ b 11 + a 12 ∗ b 21 = a 13 ∗ b 31 c_{11} = a_{11} * b_{11} + a_{12} * b_{21} = a_{13} * b_{31}
c 1 1 = a 1 1 ∗ b 1 1 + a 1 2 ∗ b 2 1 = a 1 3 ∗ b 3 1
c 21 = a 21 ∗ b 11 + a 22 ∗ b 21 = a 23 ∗ b 31 c_{21} = a_{21} * b_{11} + a_{22} * b_{21} = a_{23} * b_{31}
c 2 1 = a 2 1 ∗ b 1 1 + a 2 2 ∗ b 2 1 = a 2 3 ∗ b 3 1
C = [ c 11 c 21 ] \bold{C} = \left[
\begin{matrix}
c_{11} \\
c_{21}
\end{matrix}
\right]
C = [ c 1 1 c 2 1 ]
矩阵的转置
m m m n n n n n n m m m
A m ∗ n T = [ a 11 a 21 ⋯ a m 1 a 12 a 22 ⋯ a m 2 ⋮ ⋮ ⋮ a 1 n a 2 n ⋯ a m n ] {\bold{A}_{m * n}}^T = \left[
\begin{matrix}
a_{11} & a_{21} & \cdots & a_{m1} \\
a_{12} & a_{22} & \cdots & a_{m2} \\
\vdots & \vdots & & \vdots \\
a_{1n} & a_{2n} & \cdots & a_{mn} \\
\end{matrix}
\right]
A m ∗ n T = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 1 a 1 2 ⋮ a 1 n a 2 1 a 2 2 ⋮ a 2 n ⋯ ⋯ ⋯ a m 1 a m 2 ⋮ a m n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
矩阵的逆
A \bold{A} A B \bold{B} B n n n E \bold{E} E n n n A B = B A = E \bold{AB} = \bold{BA} = \bold{E} A B = B A = E B \bold{B} B A \bold{A} A A − 1 \bold{A}^{-1} A − 1
模型
线性回归模型:通过特征的线性组合来进行预测的函数。
h w ( x ) = w 0 + w 1 x 1 + w 2 x 2 + ⋅ ⋅ ⋅ + w d x d h_w(x) = w_0 + w_1x_1 + w_2x_2 + ··· + w_dx_d
h w ( x ) = w 0 + w 1 x 1 + w 2 x 2 + ⋅ ⋅ ⋅ + w d x d
h w ( x ) = w T x h_w(x) = \bold{w}^T \bold{x}
h w ( x ) = w T x
其中w \bold{w} w x \bold{x} x
w = [ w 0 w 1 ⋮ w m ] x = [ 1 x 1 ⋮ x m ] \bold{w} = \left[
\begin{matrix}
w_0 \\
w_1 \\
\vdots \\
w_{m}
\end{matrix}
\right] \
\bold{x} = \left[
\begin{matrix}
1 \\
x_1 \\
\vdots \\
x_{m}
\end{matrix}
\right]
w = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ w 0 w 1 ⋮ w m ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ x = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ 1 x 1 ⋮ x m ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
在上文,我们把矩阵的定义和运算都复习了一下,现在,问,我们这个模型的输出是什么?1 1 1 M M M M M M 1 1 1 1 1 1 1 1 1 1 1 1
损失函数
我们还需要一个函数来对模型的拟合效果进行评估,这个函数叫做损失函数,计作J ( w ) J(\bold{w}) J ( w )
J ( w ) = ∑ i = 1 m ( h w ( x i ) − y i ) 2 J(\bold{w}) = \sum_{i=1}^m(h_w(x_i) - y_i)^2
J ( w ) = i = 1 ∑ m ( h w ( x i ) − y i ) 2
其中
y i y_i y i i i i h w ( x i ) h_w(x_i) h w ( x i ) i i i x i x_i x i h w h_w h w
所以,我们现在的目标是要使损失函数的值最小。
优化
优化,就是寻找一个w \bold{w} w
正规方程
正规方程的公式
W = ( X T X ) − 1 X T y \bold{W} = (\bold{X}^T\bold{X})^{-1}\bold{X}^T\bold{y}
W = ( X T X ) − 1 X T y
其中
X \bold{X} X y \bold{y} y
该方法的缺点有
求解速度太慢
如果X T X \bold{X}^T\bold{X} X T X W \bold{W} W
无法解决拟合问题
梯度下降
我们以只有一个变量的为例。w 0 w_0 w 0 w 1 w_1 w 1
w 0 = − w 0 − α ∂ J ( w 0 , w 1 ) ∂ w 0 w_0 = -w_0 - \alpha\frac{\partial J(w_0,w_1)}{\partial w_0}
w 0 = − w 0 − α ∂ w 0 ∂ J ( w 0 , w 1 )
w 1 = − w 1 − α ∂ J ( w 0 , w 1 ) ∂ w 1 w_1 = -w_1 - \alpha\frac{\partial J(w_0,w_1)}{\partial w_1}
w 1 = − w 1 − α ∂ w 1 ∂ J ( w 0 , w 1 )
其中
J ( w 0 , w 1 ) J(w_0,w_1) J ( w 0 , w 1 ) α \alpha α
梯度下降的动态过程如图:
正规方程与梯度下降的对比
梯度下降
正规方程
需要选择学习率α \alpha α
不需要
需要多次迭代计算
不需要
在特征数量n较大时也能较好适用
通常特征数量小于10000适用
适用于各种模型
只适用线性模型,不适合包括逻辑模型在内的其它模型
关于什么是梯度,我们在《深度学习初步及其Python实现:3.梯度下降》 中有更好的论述。
评估
线性回归作为回归模型,评估方法当然按照我们第四章提到的回归模型评估方法。
平均绝对误差
平均方差
R平方
这么我们再发散一下。
R 2 = 1 − R S S T S S = 1 − ∑ i = 1 n ( y i − y i ^ ) 2 ∑ i = 1 n ( y i − y i ˉ ) 2 \begin{aligned}
R^2 & = 1 - \frac{RSS}{TSS} \\
& = 1 - \frac{\sum_{i=1}^n(y_i - \hat{y_i})^2}{\sum_{i=1}^n(y_i - \bar{y_i})^2}
\end{aligned}
R 2 = 1 − T S S R S S = 1 − ∑ i = 1 n ( y i − y i ˉ ) 2 ∑ i = 1 n ( y i − y i ^ ) 2
分子部分是我们的模型预测产生的错误
分母部分是样本真实值的方差,是常数
在这里,我们的R平方越大越好,所以严格意义上,我们是不能把R平方作为我们的损失函数的,因为损失函数要尽量小。但是,不能作为严格意义上的损失函数,绝对可以作为目标函数,我们可以用梯度上升方法求。1 1 1
实现
注意:scikit-learn 0.19及以上的版本中,要求传入转换器、估计器的数据必须是二维的形式。reshape转换成二维的形式。
正规方程:
1 from sklearn.linear_model import LinearRegression
梯度下降:
1 from sklearn.linear_model import SGDRegressor
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from sklearn.datasets import load_bostonfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.linear_model import SGDRegressorlb = load_boston() x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25 ) std_x = StandardScaler() x_train = std_x.fit_transform(x_train) x_test = std_x.transform(x_test) std_y = StandardScaler() y_train = std_y.fit_transform(y_train.reshape(-1 ,1 )) y_test = std_y.transform(y_test.reshape(-1 ,1 )) print('正规方程' ) lr = LinearRegression() lr.fit(x_train,y_train) print(lr.coef_) print(lr.score(x_test,y_test)) print('梯度下降' ) sr = SGDRegressor() sr.fit(x_train,y_train) print(sr.coef_) print(sr.score(x_test,y_test))
运行结果:
1 2 3 4 5 6 7 8 9 10 正规方程 [[-0.0999584 0.15770857 0.02429477 0.0665903 -0.23935036 0.26475608 0.02780978 -0.36994635 0.3173723 -0.23827149 -0.23136748 0.11666166 -0.42261817]] 0.7440813832822074 梯度下降 [-0.07546204 0.11049403 -0.0201109 0.06968199 -0.15184666 0.30057596 0.00334009 -0.29757264 0.14135882 -0.07130111 -0.2087188 0.11581215 -0.39141166] 0.7476643999577666
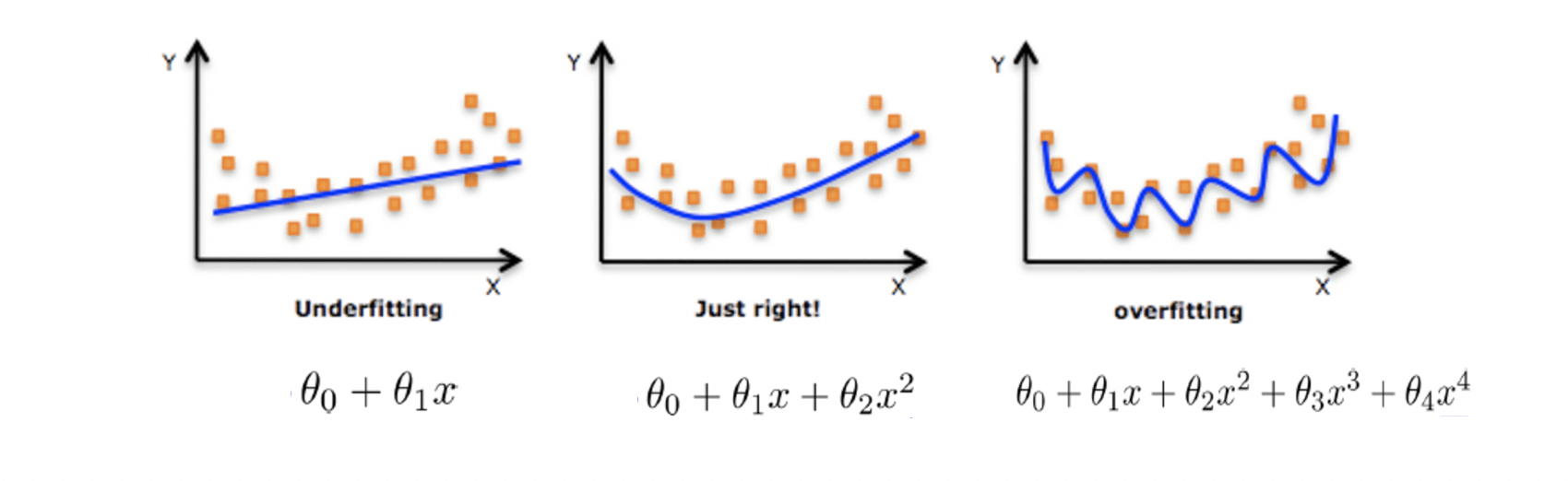
拟合问题
过拟合和欠拟合的定义
过拟合:模型过于复杂
欠拟合:模型过于简单
过拟合和欠拟合的原因和办法
欠拟合原因以及解决办法
原因:学习到数据的特征过少
办法:增加数据的特征数量
过拟合原因以及解决办法
原因:原始特征过多,存在一些嘈杂特征。模型试图兼顾各个测试数据点,以至于模型过于复杂。
办法:
进行特征选择,消除关联性大的特征
交叉验证
交叉验证用以检查是过拟合或欠拟合
如果测试集效果不好,交叉验证效果好,那么可能过拟合
如果测试集效果不好,交叉验证效果也不好,那么就是欠拟合
正则化(尽量减小高次项特征的权重)
学习率衰减