这一章,我们的主题是一种集成学习算法的代表,GBDT,Gradient Boosting Decision Tree,梯度提升决策树,也简称梯度提升树。
还是那句话,在《经典机器学习及其Python实现:10.集成学习和随机森林》 中,我们已经讨论过"集成学习"以及一种集成学习的方法的代表"随机森林",但当时我们的讨论的太浅显了。这一章,我们重新讨论。
集成学习方法
三种集成学习方法
集成学习是通过构建并组合多个基学习器来完成学习任务的算法,常见的集成学习方法有三种:
Bagging :对训练集进行抽样,将抽样的结果用于训练基学习器。特点是并行,独立训练,各个基学习器之间互相不影响。Boosting :利用训练集训练出的模型,根据本次模型的预测结果,调整训练集,然后利用调整后的训练集训练下一个模型。特点是串行,需要首先有第一个模型。Stacking :Bagging和Boosting都有一个共同点,基学习器是同一类(不一定都是决策树,但都是同一类)。而Stacking中基学习器可以是不同的类别。
Stacking
例如,下图就是一种Stacking的结构。
graph LR
lr{逻辑回归}
svm{支持向量机}
dt{决策树}
3rd{又一个基学习器}
o(输出)
lr -- w1 --> 3rd
svm -- w2 --> 3rd
dt -- w3 --> 3rd
3rd --> o
不同的基学习器以不同的权重,输入到又一个基学习器中,然后输出。这个结构,非常的类似于神经网络。
Stacking至少要有两层,一层的不算Stacking。就像Stacking这个单词一样,堆叠。
实际上也是一种多模型的融合方法。
关于Stacking,在本章的最后,我们会讨论GBDT+LR,这就是一种典型的Stacking方法。
并行与串行
Bagging和Boosting,除了对训练集的处理不一样,Boosting会去调整训练集,但Bagging不会。还有一个区别。
Bagging
关于Bagging及其代表算法随机森林,我们在《经典机器学习及其Python实现:10.集成学习和随机森林》 中已经讨论过了,这里不再赘述。
除了用众数(投票)的方法,对于回归树,可以用求平均的方法。
随机森林的随机性体现在每颗树的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。即随机性体现在随机选取子集和随机选取特征。
Boosting
上文,我们讨论了,Boosting是利用训练集训练出的模型,根据本次模型的预测结果,调整训练集,然后利用调整后的训练集训练下一个模型,而且是串行。
加法模型是指,强学习器由一系列弱学习器线性相加而成。组合形式如下:
F M ( x ; P ) = ∑ m = 1 n β m h ( x ; a m ) F_M(x;P) = \sum_{m=1}^{n}\beta_mh(x;a_m)
F M ( x ; P ) = m = 1 ∑ n β m h ( x ; a m )
h ( x ; a m ) h(x;a_m) h ( x ; a m ) a m a_m a m β m \beta_m β m P P P a m a_m a m β m \beta_m β m
前向分步是指,在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。即
F m ( x ) = F m − 1 ( x ) + β m h m ( x ; a m ) F_{m}(x) = F_{m-1}(x) + \beta_m h_m(x;a_m)
F m ( x ) = F m − 1 ( x ) + β m h m ( x ; a m )
Adaboost
接下来,我们讨论Boosting的一个代表,Adaboost,这个模型用于处理二分类问题。
Adaboost的原理
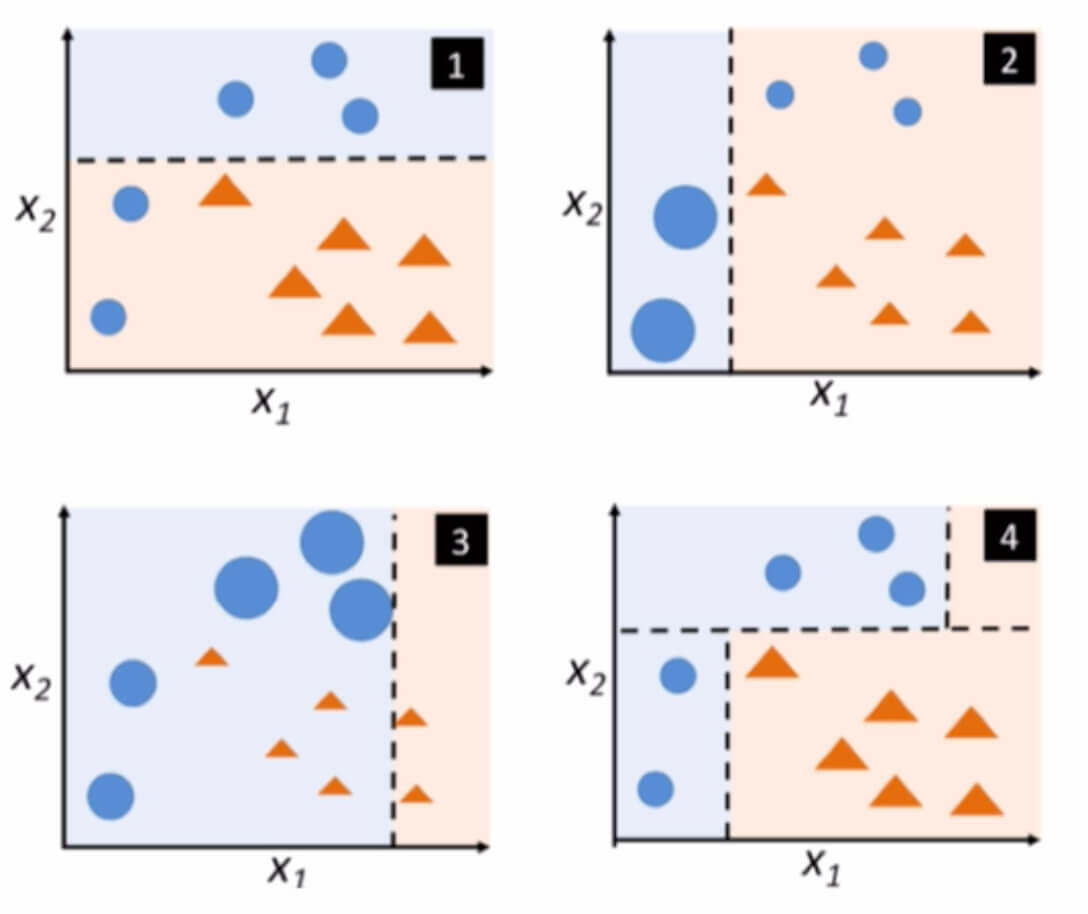
我们知道Boosting做的事情是调整训练集。
首先对圆形和三角形进行分类,这时候左下角的圆被错误分类了。
提高左下角圆的权值,降低被正确分类的右下方三角形的权值,重新分类。这时候右上角的圆被错误分类了。
提高右上角圆的权值,降低被正确分类的样本权值,重新分类。
将上述三个分类器加起来,得到新的分类器。
Adaboost采用加权投票的方法,分类误差小的弱分类器权重大,而分类误差大的弱分类器权重小。
Adaboost的算法
假设输入训练数据为:
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\}
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) }
x i ∈ X x_i \in \bold{X} x i ∈ X y i ∈ Y y_i \in \bold{Y} y i ∈ Y − 1 -1 − 1 1 1 1
第一步 初始化训练样本的权值。
D 1 = ( w 1 , 1 , w 1 , 2 , ⋯ , w 1 , i ) , w 1 , i = 1 N , i = 1 , 2 , ⋯ , N D_1 = (w_{1,1},w_{1,2},\cdots,w_{1,i}),\quad w_{1,i} = \frac{1}{N},\quad i=1,2,\cdots,N D 1 = ( w 1 , 1 , w 1 , 2 , ⋯ , w 1 , i ) , w 1 , i = N 1 , i = 1 , 2 , ⋯ , N
其中w 1 , 1 w_{1,1} w 1 , 1 1 1 1 1 1 1
第二步 循环M M M M M M m − 1 m-1 m − 1 m m m
1、使用具有权值分布D m D_m D m G m ( x ) G_m(x) G m ( x )
训练过程也是上一章的决策树构建过程。 D m D_m D m m − 1 m-1 m − 1 2、计算G m ( x ) G_m(x) G m ( x )
e m = ∑ i = 1 N w m , i ∗ I ( G m ( x i ) ≠ y i ) e_m = \sum_{i=1}^{N} w_{m,i} * I(G_m(x_i) \neq y_i) e m = i = 1 ∑ N w m , i ∗ I ( G m ( x i ) = y i )
I ( ⋅ ) I(\cdot) I ( ⋅ ) 1 1 1 0 0 0 这个式子的含义是把分错的权重叠加。 3、计算G m ( x ) G_m(x) G m ( x )
α m = 1 2 log 1 − e m e m \alpha_m = \frac{1}{2}\log\frac{1-e_m}{e_m} α m = 2 1 log e m 1 − e m
当弱分类器的误差率e m ≤ 0.5 e_m \leq 0.5 e m ≤ 0 . 5 α m ≥ 0 \alpha_m \geq 0 α m ≥ 0 α m \alpha_m α m e m e_m e m 4、更新数据集的权值分布。
D m + 1 = ( w m + 1 , 1 , w m + 1 , 2 , ⋯ , w m + 1 , N ) D_{m+1} = (w_{m+1,1},w_{m+1,2},\cdots,w_{m+1,N}) D m + 1 = ( w m + 1 , 1 , w m + 1 , 2 , ⋯ , w m + 1 , N )
w m + 1 , i = w m , i z m exp ( − α m y i G m ( x i ) ) , i = 1 , 2 , ⋯ , 10 w_{m+1,i} = \frac{w_{m,i}}{z_m}\exp(-\alpha_m y_i G_m(x_i)),\quad i=1,2,\cdots,10 w m + 1 , i = z m w m , i exp ( − α m y i G m ( x i ) ) , i = 1 , 2 , ⋯ , 1 0
α m \alpha_m α m G m ( x ) G_m(x) G m ( x ) y i y_i y i G m ( x i ) G_m(x_i) G m ( x i ) y i y_i y i − 1 -1 − 1 1 1 1 y i G m ( x i ) > 0 y_i G_m(x_i) > 0 y i G m ( x i ) > 0 y i G m ( x i ) < 0 y_i G_m(x_i) < 0 y i G m ( x i ) < 0 z m z_m z m 1 1 1 z m = ∑ i = 1 N w m , i exp ( − α m y i G m ( x i ) ) z_m = \sum_{i=1}^{N}w_{m,i}\exp(-\alpha_m y_i G_m(x_i)) z m = ∑ i = 1 N w m , i exp ( − α m y i G m ( x i ) )
第三步 M M M
F ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ i = 1 N α m G m ( x ) ) F(x) = sign(f(x)) = sign\bigg(\sum_{i=1}^{N}\alpha_m G_m(x) \bigg) F ( x ) = s i g n ( f ( x ) ) = s i g n ( i = 1 ∑ N α m G m ( x ) )
GBDT的原理
GBDT,Gradient Boosting Decision Tree,梯度提升决策树。
GBDT是一种利用多棵回归树解决回归问题的方案,每一个基学习器都是回归树。虽然通过调整损失函数,也可以解决分类问题,但需要强调的是,即使用GBDT来解决分类问题了,其基学习器依旧是回归树。
那么,这时候就有一个问题了,为什么GBDT要用回归树去解决分类问题?
GBDT还有一个特点,通过全部样本迭代生成多棵回归树。y y y y y y
刚刚我们说,用回归树的目的是想用均方误差,现在就讨论。
1 2 ∑ ( y − f ( x ) ) 2 \frac{1}{2} \sum (y - f(x))^2
2 1 ∑ ( y − f ( x ) ) 2
为了便于计算,不乘以1 N \frac{1}{N} N 1 1 2 \frac{1}{2} 2 1
对于单个样本就是
1 2 ( y i − f ( x i ) ) 2 \frac{1}{2}(y_i - f(x_i))^2
2 1 ( y i − f ( x i ) ) 2
现在,我们对函数求负梯度(梯度提升)就是:
− ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) = y i − f ( x i ) -\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)} = y_i - f(x_i)
− ∂ f ( x i ) ∂ L ( y i , f ( x i ) ) = y i − f ( x i )
f ( x i ) f(x_i) f ( x i ) f ( x i ) f(x_i) f ( x i )
然后,现在有一个非常巧的事情,y i − f ( x i ) y_i - f(x_i) y i − f ( x i )
GBDT的算法
输入 :训练数据集{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } y i ∈ { + 1 , − 1 } y_i \in \{+1,-1\} y i ∈ { + 1 , − 1 } 输出 :回归树F T ( x ) F_T(x) F T ( x ) f 0 ( x ) = arg min h 0 ∑ i = 1 N L ( y i , h 0 ( x ) ) f_0(x) = \argmin_{h_0} \sum_{i=1}^{N} L(y_i,h_0(x)) f 0 ( x ) = a r g m i n h 0 ∑ i = 1 N L ( y i , h 0 ( x ) ) M M M m = 1 , 2 , ⋯ , M m=1,2,\cdots,M m = 1 , 2 , ⋯ , M y ~ i = − [ ∂ L ( y i , F ( x i ) ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) , i = 1 , 2 , ⋯ , N \tilde{y}_i = - \bigg[\frac{\partial L(y_i,F(x_i))}{\partial F(x_i)}\bigg]_{F(x) = F_{m-1}(x)},\quad i = 1,2,\cdots,N y ~ i = − [ ∂ F ( x i ) ∂ L ( y i , F ( x i ) ) ] F ( x ) = F m − 1 ( x ) , i = 1 , 2 , ⋯ , N 这里的负梯度也就是残差。 ω m = arg min ω m ∑ i = 1 N ( y ~ i − h t ( x ; ω m ) ) 2 \omega_m=\argmin_{\omega_m} \sum_{i=1}^{N}(\tilde{y}_i - h_t(x;\omega_m))^2 ω m = a r g m i n ω m ∑ i = 1 N ( y ~ i − h t ( x ; ω m ) ) 2 y ~ i \tilde{y}_i y ~ i α m = arg min α m ∑ i = 1 N L ( y i , f m − 1 ( x i ) ) + α m h m ( x ; ω m ) \alpha_m=\argmin_{\alpha_m}\sum_{i=1}^{N}L(y_i,f_{m-1}(x_i))+\alpha_{m}h_m(x;\omega_m) α m = a r g m i n α m ∑ i = 1 N L ( y i , f m − 1 ( x i ) ) + α m h m ( x ; ω m ) F m ( x ) = F m − 1 ( x ) + α m h m ( x ; ω m ) F_m(x)=F_{m-1}(x) + \alpha_m h_m(x;\omega_m) F m ( x ) = F m − 1 ( x ) + α m h m ( x ; ω m )
提起GBDT,让我想起了费马大定理的证明过程,长达400年的科学家们的接力。每一位科学家在前人研究的基础上,再往前进步一点。就像每一颗决策树,在之前决策树的基础上,再进步一点。
GBDT解决分类问题
在上文我们讨论了,GBDT是一种利用多棵回归树解决回归问题的方案,每一颗回归树就是一个基学习器。
二分类
原本是解决回归问题的模型,经过简单的改造后,就成了可以解决二分类问题的模型。这个我们很容易联想到线性回归和逻辑回归。
Sigmoid的函数形式是
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1 + e^{-x}}
s i g m o i d ( x ) = 1 + e − x 1
那么,在原本的GBDT的外面套一层Sigmoid就是
P ( y = 1 ∣ x ) = 1 1 + e − ∑ m = 1 M h m ( x ) P(y=1|x) = \frac{1}{1 + e^{-\sum_{m=1}^{M}h_m(x)}}
P ( y = 1 ∣ x ) = 1 + e − ∑ m = 1 M h m ( x ) 1
P ( y = 1 ∣ x ) P(y=1|x) P ( y = 1 ∣ x ) 1 1 1 h m ( x ) h_m(x) h m ( x )
交叉熵是
H ( p ∣ ∣ q ) = − ∑ i p i log 2 q i H(\bold{p}||\bold{q}) = - \sum_i p_i \log_2 q_i
H ( p ∣ ∣ q ) = − i ∑ p i log 2 q i
二分类的交叉熵损失是
L o s s ( y ^ i ) = − y i log y ^ i − ( 1 − y i ) log ( 1 − y ^ i ) Loss(\hat{y}_i) = - y_i \log \hat{y}_i - (1 - y_i)\log (1 - \hat{y}_i)
L o s s ( y ^ i ) = − y i log y ^ i − ( 1 − y i ) log ( 1 − y ^ i )
那么,对于GBDT二分类的交叉熵损失就是
L o s s ( F ( x ) ) = y i log ( 1 + e − F ( x i ) ) + ( 1 − y i ) [ F ( x i ) + log ( 1 + e − F ( x i ) ) ] Loss(F(x)) = y_i \log(1 + e^{-F(x_i)}) + (1 - y_i)[F(x_i) + \log(1 + e^{-F(x_i)})]
L o s s ( F ( x ) ) = y i log ( 1 + e − F ( x i ) ) + ( 1 − y i ) [ F ( x i ) + log ( 1 + e − F ( x i ) ) ]
F ( x ) = ∑ m = 1 M h m ( x ) F(x) = \sum_{m=1}^{M}h_m(x) F ( x ) = ∑ m = 1 M h m ( x )
与解决回归问题一样,我们求负梯度,则有:
− ∂ L o s s ( F ( x ) ) ∂ F ( x ) ∣ x i , y i = y i − 1 1 + e − F ( x i ) = y i − y ^ i \begin{aligned}
-\frac{\partial Loss(F(x))}{\partial F(x)}\bigg|_{x_i,y_i} & = y_i - \frac{1}{1 + e^{-F(x_i)}} \\
& = y_i - \hat{y}_i
\end{aligned}
− ∂ F ( x ) ∂ L o s s ( F ( x ) ) ∣ ∣ ∣ ∣ ∣ x i , y i = y i − 1 + e − F ( x i ) 1 = y i − y ^ i
y i − y ^ i y_i - \hat{y}_i y i − y ^ i
所以呢,就有了下面的GBDT解决二分类的算法:
初始化:F 0 ( x ) = h 0 ( x ) = log p 1 1 − p 1 F_0(x) = h_0(x) = \log\frac{p_1}{1-p_1} F 0 ( x ) = h 0 ( x ) = log 1 − p 1 p 1 p 1 p_1 p 1 y = 1 y=1 y = 1 M M M m = 1 , 2 , ⋯ , M m=1,2,\cdots,M m = 1 , 2 , ⋯ , M y ~ i \tilde{y}_i y ~ i y ~ i = y ^ i − y i \tilde{y}_i = \hat{y}_i - y_i y ~ i = y ^ i − y i y ^ i = 1 1 + e − F m − 1 ( x i ) \hat{y}_i = \frac{1}{1 + e^{-F_{m-1}(x_i)}} y ^ i = 1 + e − F m − 1 ( x i ) 1 ω m = arg min ω m ∑ i = 1 N ( y ~ i − h m ( x ; ω m ) ) 2 \omega_m=\argmin_{\omega_m} \sum_{i=1}^{N}(\tilde{y}_i - h_m(x;\omega_m))^2 ω m = a r g m i n ω m ∑ i = 1 N ( y ~ i − h m ( x ; ω m ) ) 2 y ~ i \tilde{y}_i y ~ i α m = arg min α m ∑ i = 1 N L ( y i , f m − 1 ( x i ) ) + α m h m ( x ; ω m ) \alpha_m=\argmin_{\alpha_m}\sum_{i=1}^{N}L(y_i,f_{m-1}(x_i))+\alpha_{m}h_m(x;\omega_m) α m = a r g m i n α m ∑ i = 1 N L ( y i , f m − 1 ( x i ) ) + α m h m ( x ; ω m ) F m ( x ) = F m − 1 ( x ) + α m h m ( x ; ω m ) F_m(x)=F_{m-1}(x) + \alpha_m h_m(x;\omega_m) F m ( x ) = F m − 1 ( x ) + α m h m ( x ; ω m ) 因为损失函数不一样,所以负梯度不一样。另外,因为是分类问题,所以初始化方法不一样。除了这两点,并没有其他区别。
多分类问题
多分类问题,不过是原本套一层Sigmoid的,现在改成套一层Softmax。另外,有几个类别,我们就需要几个GBDT。即
P ( y = 1 ∣ x ) = e F 1 ( x ) ∑ i = 1 k e F i ( x ) P ( y = 2 ∣ x ) = e F 2 ( x ) ∑ i = 1 k e F i ( x ) ⋯ P ( y = k ∣ x ) = e F k ( x ) ∑ i = 1 k e F i ( x ) \begin{aligned}
P(y=1|x) & = \frac{e^{F_1(x)}}{\sum_{i=1}^{k}e^{F_i(x)}} \\
P(y=2|x) & = \frac{e^{F_2(x)}}{\sum_{i=1}^{k}e^{F_i(x)}} \\
& \cdots \\
P(y=k|x) & = \frac{e^{F_k(x)}}{\sum_{i=1}^{k}e^{F_i(x)}} \\
\end{aligned}
P ( y = 1 ∣ x ) P ( y = 2 ∣ x ) P ( y = k ∣ x ) = ∑ i = 1 k e F i ( x ) e F 1 ( x ) = ∑ i = 1 k e F i ( x ) e F 2 ( x ) ⋯ = ∑ i = 1 k e F i ( x ) e F k ( x )
损失函数为:
L o s s ( F i ( x ) ) = − ∑ i = 1 k y i log e F i ( x ) ∑ j = 1 k e F j ( x ) Loss(F_i(x)) = - \sum_{i=1}^{k} y_i \log \frac{e^{F_i(x)}}{\sum_{j=1}^k e^{F_j(x)}}
L o s s ( F i ( x ) ) = − i = 1 ∑ k y i log ∑ j = 1 k e F j ( x ) e F i ( x )
y i y_i y i k k k y y y 1 1 1 0 0 0
求负梯度,则有:
− ∂ L o s s ( F q ) ∂ F q = y q − e F q ( x ) ∑ j = 1 k e F j ( x ) = y q − y ^ q \begin{aligned}
-\frac{\partial Loss(F_q)}{\partial F_q} & = y_q - \frac{e^{F_q(x)}}{\sum_{j=1}^{k}e^{F_j(x)}} \\
& = y_q - \hat{y}_q
\end{aligned}
− ∂ F q ∂ L o s s ( F q ) = y q − ∑ j = 1 k e F j ( x ) e F q ( x ) = y q − y ^ q
后续内容略,与二分类非常相似。
GBDT和随机森林的区别
集成学习方法:GBDT是Boosting方法,随机森林是Bagging方法。
GBDT不断的降低模型的偏差,随机森林不断降低模型的方差。
GBDT每次使用全部样本,随机森林则是随机有放回的抽样。
GBDT是加权融合,随机森林是多棵树进行多数表决(回归问题是取平均)。
GBDT对异常值比较敏感,随机森林对异常值不敏感。
GBDT容易过拟合,随机森林不容易过拟合。
GBDT+LR
GBDT+LR的原理
GBDT和LR结合后,在一个领域有重要应用,计算广告。《Practical Lessons from Predicting Clicks on Ads at Facebook》
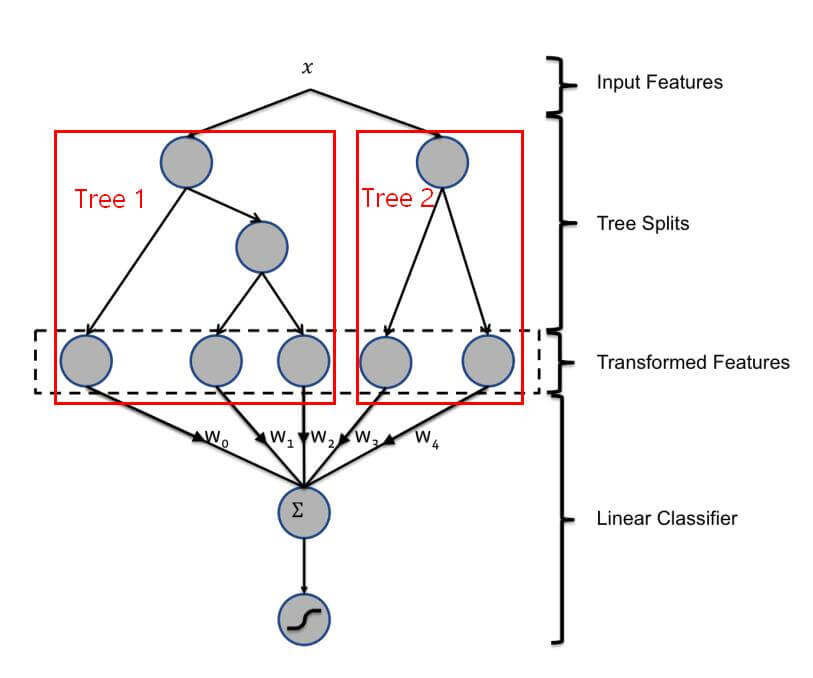
现在,我们讨论这个模型。结构如下图:
我们知道,LR,逻辑回归,其实本质上是一个线性回归,其优点是速度快,缺点是处理非线性的数据效果不好。对此,我们有一个办法是数据升维。比如我们有两个维度X 1 X_1 X 1 X 2 X_2 X 2 X 1 ∗ X 2 X_1 * X_2 X 1 ∗ X 2 X 1 2 X_1^2 X 1 2 X 2 2 X_2^2 X 2 2
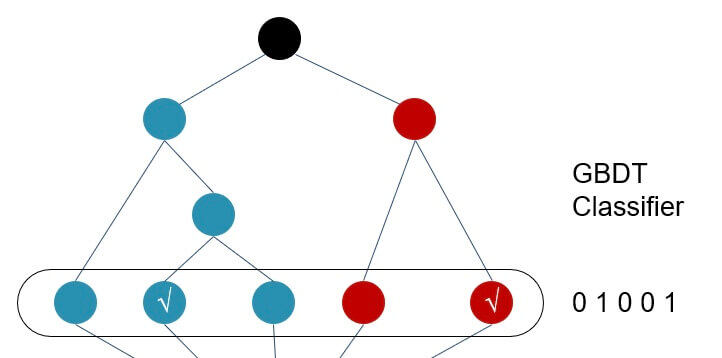
就如上面的图,一个样本在进入Tree1后,会不断的进行if-else的判断,最后落在一个叶子节点上,而叶子的含义其实也就是一个或多个特征的组合;然后这个样本再进入Tree2,同样,也会落在某一个叶子节点上,也是一个或多个特征的组合。
比如:
剩下的事情,就交给LR了。
GBDT+LR的实现
接下来,我们看看如何实现GBDT+LR。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 import numpy as npfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import roc_auc_scorefrom sklearn.preprocessing import OneHotEncoderfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitclass GradientBoostingWithLR (object) : def __init__ (self) : self.gbdt_model = None self.lr_model = None self.gbdt_encoder = None self.X_train_leafs = None self.X_test_leafs = None self.X_trans = None def gbdt_train (self, X_train, y_train) : """ 只训练GBDT模型 :param X_train: :param y_train: :return: """ gbdt_model = GradientBoostingClassifier(n_estimators=10 , max_depth=6 , verbose=0 , max_features=0.5 ) gbdt_model.fit(X_train, y_train) return gbdt_model def lr_train (self, X_train, y_train) : """ 只训练逻辑回归模型 :param X_train: :param y_train: :return: """ lr_model = LogisticRegression() lr_model.fit(X_train, y_train) return lr_model def gbdt_lr_train (self, X_train, y_train) : """ 训练gbdt+lr :param X_train: :param y_train: :return: """ self.gbdt_model = self.gbdt_train(X_train, y_train) self.X_train_leafs = self.gbdt_model.apply(X_train)[:, :, 0 ] self.gbdt_encoder = OneHotEncoder(sparse=False ) self.X_trans = self.gbdt_encoder.fit_transform(self.X_train_leafs) self.lr_model = self.lr_train(self.X_trans, y_train) return self.lr_model def gbdt_lr_pred (self, model, X_test, y_test) : """ 预测及AUC评估 :param model: :param X_test: :param y_test: :return: """ self.X_test_leafs = self.gbdt_model.apply(X_test)[:, :, 0 ] (train_rows, cols) = self.X_train_leafs.shape X_trans_all = self.gbdt_encoder.fit_transform(np.concatenate((self.X_train_leafs, self.X_test_leafs), axis=0 )) y_pred = model.predict_proba(X_trans_all[train_rows:])[:, 1 ] auc_score = roc_auc_score(y_test, y_pred) print('GBDT+LR AUC score: %.5f' % auc_score) return auc_score def model_assessment (self, model, X_test, y_test, model_name="GBDT" ) : """ 模型评估 :param model: :param X_test: :param y_test: :param model_name: :return: """ y_pred = model.predict_proba(X_test)[:, 1 ] auc_score = roc_auc_score(y_test, y_pred) print("%s AUC score: %.5f" % (model_name, auc_score)) return auc_score def load_data () : """ 调用sklearn的iris数据集,将多类数据构造成2分类数据,同时切分训练测试数据集 """ iris_data = load_iris() X = iris_data['data' ] y = iris_data['target' ] == 1 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4 , random_state=0 ) return X_train, X_test, y_train, y_test if __name__ == '__main__' : X_train, X_test, y_train, y_test = load_data() gblr = GradientBoostingWithLR() gbdt_lr_model = gblr.gbdt_lr_train(X_train, y_train) gblr.model_assessment(gblr.gbdt_model, X_test, y_test) gblr.gbdt_lr_pred(gbdt_lr_model, X_test, y_test)
运行结果:
1 2 GBDT AUC score: 0.98355 GBDT+LR AUC score: 0.99412