SELECT初探
SELECT
第一种结构,只有SELECT,没有任何子句。
示例代码:
1 | SELECT 1; |
运行结果:
1 | +-+ |
示例代码:
1 | SELECT 9/2; |
运行结果:
1 | +------+ |
SELECT-FROM
语法格式
语法:
1 | SELECT ... |
SELECT:标识选择哪些列。FROM:标识从哪些表中选择。
选择全部列
选择全部列,用通配符,*,示例代码:
1 | SELECT * FROM departments; |
选择特定的列
选择特定的列,示例代码:
1 | SELECT department_id, location_id FROM departments; |
列的别名
格式为列名 AS "列的别名"。
- 其中
AS可以省略,但建议保留。 - 如果别名中有空格等其他特殊字符,可以将别名用双引号
""括起来。
示例代码:
1 | SELECT last_name AS "Name", salary * 12 AS "Annual Salary" |
运行结果:
1 | +-----------+-------------+ |
去除重复行
使用关键字DISTINCT可以去除重复行。
用法
例如,未使用DISTINCT,示例代码:
1 | SELECT department_id FROM employees; |
运行结果:
1 | +-------------+ |
- 有很多重复的数据。
使用DISTINCT之后,没有重复数据,示例代码:
1 | SELECT DISTINCT department_id FROM employees; |
运行结果:
1 | +-------------+ |
注意
需要注意的有两点。
DISTINCT,需要放到所有列名的前面。DISTINCT,是对后面所有列名的组合进行去重。
例如,没有将DISTINCT,放在所有列名的前面,示例代码:
1 | SELECT salary, DISTINCT department_id |
运行结果:
1 | [42000][1064] You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'DISTINCT department_id |
将DISTINCT,放在所有列名的前面,组合去重,示例代码:
1 | SELECT DISTINCT department_id, salary |
运行结果:
1 | +-------------+------+ |
分布式中的性能问题
在分布式数据库中,去重的更好办法是用GROUP BY。
例如,对于SELECT DISTINCT department_id FROM employees;,SELECT department_id FROM employees GROUP BY department_id;的性能会更好。
我们在下文讨论GROUP BY的时候会解释原因。
着重号
表中字段、表名等,不能和保留字、常用方法名等相同,如果相同了,可以在SQL中使用一对着重号``引起来。
例如,ORDER是属于一个保留字,示例代码:
1 | SELECT * FROM ORDER; |
运行结果:
1 | [42000][1064] You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'ORDER' at line 1 |
示例代码:
1 | SELECT * FROM `order`; |
运行结果:
1 | +--------+----------+ |
查询常数
SELECT 常数,即对常数进行查询。
示例代码:
1 | SELECT '少林寺驻武当山办事处' as corporation, last_name |
运行结果:
1 | +-----------+-----------+ |
SELECT-FROM-WHERE
格式如下:
1 | SELECT 字段1,字段2 FROM 表名 WHERE 过滤条件 |
示例代码:
1 | SELECT employee_id, last_name, job_id, department_id |
运行结果:
1 | +-----------+---------+-------+-------------+ |
运算符
MySQL中的运算符有四种:
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
其中,位运算符,我们不讨论。在实际中,或许的确应用不多,主要讨论前三种。
这些运算符,还有一个共同的特点,几乎所有的运算符遇到NULL,运算的结果都为NULL。
注意,是几乎,有三种例外:
- 安全等于运算符
<=> - 专门为
NULL设计的运算符,例如:IS NULL。 - 在
AND中,0 AND NULL结果为0,1 AND NULL结果为NULL。
例如,12 * NULL,示例代码:
1 | SELECT employee_id, salary, commission_pct, 12 * commission_pct AS "test" |
运行结果:
1 | +-----------+------+--------------+----+ |
算术运算符
算术运算符由可以分为:
- 加和减
- 乘和除
- 求余(取模)
加和减
类型提升
在《基于Java的后端开发入门:1.基础语法》中,我们讨论过"算术表达式的类型自动提升"。在MySQL中,也有类型的自动提升。
规则如下:
- 整数和整数进行加减,结果是整数。
- 整数和浮点数进行加减,结果是浮点数。
字符串参与运算
在《基于Java的后端开发入门:1.基础语法》中,我们还讨论过,+的左右两边如果有字符串,表示字符串的拼接。
在MySQL中,+只表示数值相加。如果遇到非数值类型,会先尝试转成数值,如果转换失败,就按0计算。
(如果需要在MySQL中做字符串拼接,可以通过字符串函数CONCAT()实现。)
示例代码:
1 | SELECT 100 + 0, 100 + 0.0, 100 + '1', 100 + 'One' |
运行结果:
1 | +-------+---------+---------+-----------+ |
乘和除
类型提升
加和减的类型提升,Java和MySQL的规则是一样的。但是对于乘和除,存在区别。
- 在Java中,对于乘法和除法,如果两个数字都是整型,则结果也是整型,不会有类型的自动提升。
- 但是在MySQL中:
- 对于除法,无论是否能除尽,都会保留4位小数(四舍五入)。
- 对于乘法,会类型提升,并保留"乘数"中的最大位。
在Java中,示例代码:
1 | package com.kakawanyifan; |
运行结果:
1 | 1 |
在MySQL中,示例代码:
1 | SELECT 9 / 5, 9 * 0.2, 9 * 1.0; |
运行结果:
1 | +------+-------+-------+ |
0作为被除数
在Java中,如果0作为了被除数,会报错。
在MySQL中,如果0作为了被除数,结果会为NULL。
在Java中,示例代码:
1 | package com.kakawanyifan; |
运行结果:
1 | Exception in thread "main" java.lang.ArithmeticException: / by zero |
在MySQL中,示例代码:
1 | SELECT 9 / 0; |
运行结果:
1 | +-----+ |
字符串参与运算
和在加减中一样,MySQL会自动将字符串转成数字,转换失败,作为0。
示例代码:
1 | SELECT 100 * 1, |
运行结果:
1 | +-------+---------+---------+-----------+-----------+--------+---------+---------+-----------+-----------+ |
求模(求余)
%和MOD,求模(求余)。
示例代码:
1 | SELECT 12 % 3, 12 MOD 5 |
运行结果:
1 | +------+--------+ |
特别的,如果我们对浮点数求余呢?
结果还是浮点数。
示例代码:
1 | SELECT 12 % 3.0, 12 MOD 5.5 |
运行结果:
1 | +--------+----------+ |
比较运算符
分类
比较运算符可以分为两类,符号类,非符号类。
符号类
| 运算符 | 作用 |
|---|---|
= |
等于 |
<=> |
安全等于 |
<> != |
不等于 |
< |
小于 |
<= |
小于等于 |
> |
大于 |
>= |
大于等于 |
非符号类
| 运算符 | 作用 |
|---|---|
IS NULL |
空 |
NOT |
非 |
LEAST |
最小值 |
GREATEST |
最大值 |
BETWEEN-AND |
两个值之间 |
IN |
属于 |
LIKE |
模糊查询 |
REGEXP RLIKE |
正则表达式 |
=,等于
=,判断等号两边的值、字符串或表达式是否相等,如果相等返回1,不相等返回0。
规则如下:
- 能转成数字的用数字
- 不能转成数字的用字母
- 需要转成数字的,但转换失败就是
0 NULL需要特别注意
其实,不单单
=运算符,所有的运算符都是这个规则。
示例代码:
1 | SELECT 1 = 1, |
运行结果:
1 | +-----+-----+-----------------+---------+---------+-------+---------+---------+--------+--------+---------+----------+---------+-----------+ |
<=>,安全等于
安全等于运算符,<=>。该运算符与等于运算符=的作用是相似的,唯一的区别是<=>可以用来对NULL进行判断。
示例代码:
1 | SELECT 1 <=> 1, |
运行结果:
1 | +-------+-------+-------------------+-----------+-----------+---------+-----------+-----------+----------+----------+-----------+------------+-----------+-------------+ |
<>和!=,不等于
不等于运算符,<>和!=。
用于判断两边的数字、字符串或者表达式的值是否不相等,如果不相等则返回1,相等则返回0。
示例代码:
1 | SELECT 1 <> 1, |
运行结果:
1 | +------+------+------------------+----------+----------+----------+---------+----------+-----------+------------+ |
IS NULL,是否为空
空运算符IS NULL,判断一个值是否为NULL,如果为NULL则返回1,否则返回0。
示例代码:
1 | SELECT NULL IS NULL, 1 IS NULL; |
运行结果:
1 | +------------+---------+ |
有一个与IS NULL作用相同的,ISNULL(),这是一个函数,不是运算符。
BETWEEN-AND,区间
BETWEEN和AND,两边均是闭区间,符合结果为1,不符合结果为0。
示例代码:
1 | SELECT 1 BETWEEN 0 AND 1, |
运行结果:
1 | +-----------------+-----------------+-----------------------+-----------------------+-----------------------+----------------------+ |
IN,是否在列表中
IN,用于判断给定的值是否是IN列表中的值,如果是则返回1,否则返回0。
示例代码:
1 | SELECT 'a' IN ('a', 'b', 'c'), |
运行结果:
1 | +----------------------+-----------+----------------+------------------+------------------+------------------+ |
有部分资料说:如果给定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
实际上,在IN列表中存在NULL,并不会导致结果为NULL。
LIKE,模糊匹配
LIKE,用于模糊匹配,如果满足条件则返回1,否则返回0。
通常与如下两个通配符配合使用:
%:匹配0个或多个字符。_:能且只能匹配一个字符。
示例代码:
1 | SELECT 'aabcc' LIKE '%b%', |
运行结果:
1 | +------------------+------------------+----------------+----------------+--------------+--------------+---------------+---------------+ |
如果,LIKE的关键词中有%或_,可以使用\,转义运算符。
示例代码:
1 | SELECT 'aab_ccccc' LIKE '%b\_%'; |
运行结果:
1 | +------------------------+ |
REGEXP,正则
REGEXP运算符用来匹配字符串,语法格式为:expr REGEXP 匹配条件,如果expr满足匹配条件,返回1;如果不满足,则返回0。
常见匹配条件有:
^【某个字符】,匹配以某个字符开头的字符串。【某个字符】$,匹配以某个字符结尾的字符串。.,匹配任何一个单字符。[...],匹配在方括号内的任何字符。例如,[abc]匹配a或b或c。[a-z]匹配任何字母,[0-9]匹配任何数字。【某个字符】*,匹配零个或多个的某个字符。例如,x*匹配任何数量的x字符,[0-9]*匹配任何数量的数字,而.*匹配任何数量的任何字符。
关于正则表达式,可以参考:https://www.runoob.com/regexp/regexp-tutorial.html
示例代码:
1 | SELECT 'shkstart' REGEXP '^s', |
运行结果:
1 | +----------------------+----------------------+----------------------+----------------------+----------------------+---------------------+ |
逻辑运算符
| 运算符 | 作用 |
|---|---|
NOT ! |
非 |
AND && |
与 |
OR || |
或 |
XOR ! |
异或 |
NOT,非
示例代码:
1 | SELECT NOT 1, NOT 0, NOT(1+1), NOT !1, NOT NULL; |
运行结果:
1 | +-----+-----+--------+------+--------+ |
示例代码:
1 | SELECT NULL IS NOT NULL, NOT ISNULL(NULL), NOT ISNULL('a'), 1 IS NOT NULL; |
运行结果:
1 | +----------------+----------------+---------------+-------------+ |
示例代码:
1 | SELECT 1 NOT BETWEEN 0 AND 1, 2 NOT BETWEEN 0 AND 1, 'b' NOT BETWEEN 'a' AND 'c'; |
运行结果:
1 | +---------------------+---------------------+---------------------------+ |
示例代码:
1 | SELECT 'a' NOT IN ('a', 'b', 'c'), 1 NOT IN (2, 3), NULL NOT IN ('a', 'b'), 'a' NOT IN ('a', NULL); |
运行结果:
1 | +--------------------------+----------------+----------------------+----------------------+ |
AND,与
示例代码:
1 | SELECT 1 AND -1, 0 AND 1, 0 AND NULL, 1 AND NULL; |
运行结果:
1 | +--------+-------+----------+----------+ |
OR,或
示例代码:
1 | SELECT 1 OR -1, 1 OR 0, 1 OR NULL, 0 || NULL, NULL || NULL; |
运行结果:
1 | +-------+------+---------+---------+------------+ |
XOR,异或
XOR,异或,主要用来判断两个值是否不同。
示例代码:
1 | SELECT 1 XOR -1, |
运行结果:
1 | +--------+-------+-------+---------+-----------+-----------+----------+----------+-------------+-------------+----------+ |
运算符的优先级
| 优先级由低到高排列 | 运算符 |
|---|---|
| 1 | =(赋值运算)、:= |
| 2 | ||、OR |
| 3 | XOR |
| 4 | &&、AND |
| 5 | NOT |
| 6 | BETWEEN、CASE、WHEN、THEN、ELSE |
| 7 | =、<=>、>=、>、<=、<、<>、!=、IS、LIKE、REGEXP、IN |
| 8 | | |
| 9 | & |
| 10 | <<、>> |
| 11 | -(减号)、+ |
| 12 | *、/、% |
| 13 | ^ |
| 14 | -(负号)、~(位反转) |
| 15 | ! |
| 16 | () |
特别注意:OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
记不住怎么办?
不用记。
多敲几个括号(),耽误不了多大功夫。
排序
排序规则
使用ORDER BY子句排序。
ASC,ascend,升序(从小到大),默认升序DESC,descend,降序(从大到小)。
注意事项有:
ORDER BY子句在SELECT语句的结尾。- 可以使用不在
SELECT列表中的列排序。 - 可以使用别名进行排序。
NULL值最小。
单列排序
默认升序,示例代码:
1 | SELECT last_name, job_id, department_id, hire_date |
运行结果:
1 | +-----------+----------+-------------+----------+ |
指定降序,示例代码:
1 | SELECT last_name, job_id, department_id, hire_date |
运行结果:
1 | +-----------+----------+-------------+----------+ |
可以使用别名进行排序,示例代码:
1 | SELECT employee_id, last_name, salary * 12 as "annsal" |
运行结果:
1 | +-----------+-----------+------+ |
NULL值最小,示例代码:
1 | SELECT * |
运行结果:
1 | +-------------+--------------------+----------+-----------+ |
多列排序
在对多列进行排序的时候,首先对第一列进行排序,只有当第一列的有相同的列值时,才会对第二列进行排序。
(即,排序的稳定性。我们在《算法入门经典(Java与Python描述):5.排序》中,讨论过。)
在对多列进行排序的时候,未指定的字段,依旧按照默认升序,指定的字段,按照按照指定的方式进行排列;示例代码:
1 | SELECT last_name, department_id, salary |
运行结果:
1 | +-----------+-------------+------+ |
分页
MySQL中使用LIMIT实现分页。
格式:LIMIT [位置偏移量,] 行数
位置偏移量参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定位置偏移量,将会从表中的第一条记录开始(第一条记录的位置偏移量是0)。- 第二个参数行数指示返回的记录条数。
例如,每页10条。
第一页:SELECT * FROM 表名 LIMIT 0,10;、SELECT * FROM 表名 LIMIT 10;。
第二页:SELECT * FROM 表名 LIMIT 10,10;。
第三页:SELECT * FROM 表名 LIMIT 20,10;。
在MySQL 8.0中,还可以使用LIMIT 3 OFFSET 4,和LIMIT 4,3效果相同。
关联查询
关联查询,也称多表查询,指多张表一起完成查询操作。
笛卡尔积
我们先讨论笛卡尔积。因为只要多张表一起完成查询,就很有可能会有笛卡尔积。
例子
假设存在三张表如下:
employees:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| employee_id | int | NO | PRI | 0 | |
| first_name | varchar(20) | YES | NULL | ||
| last_name | varchar(25) | NO | NULL | ||
| varchar(25) | NO | UNI | NULL | ||
| phone_number | varchar(20) | YES | NULL | ||
| hire_date | date | NO | NULL | ||
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | NULL | ||
| commission_pct | double(2,2) | YES | NULL | ||
| manager_id | int | YES | MUL | NULL | |
| department_id | int | YES | MUL | NULL |
departments:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| department_id | int | NO | PRI | 0 | |
| department_name | varchar(30) | NO | NULL | ||
| manager_id | int | YES | MUL | NULL | |
| location_id | int | YES | MUL | NULL |
locations:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| location_id | int | NO | PRI | 0 | |
| street_address | varchar(40) | YES | NULL | ||
| postal_code | varchar(12) | YES | NULL | ||
| city | varchar(30) | NO | NULL | ||
| state_province | varchar(25) | YES | NULL | ||
| country_id | char(2) | YES | MUL | NULL |
现在,我们要查询员工的姓名及其部门名称。
员工的姓名在employees表中,部门名称在departments表中。
来吧!
示例代码:
1 | SELECT last_name, department_name |
运行结果:
1 | +-----------+--------------------+ |
好像不太对,好像每个人,都属于任何一个部门。
特别的,我们还可以查查记录数,示例代码:
1 | SELECT count(*) |
运行结果:
1 | +--------+ |
- 恰好等于
这就是出现笛卡尔积了。
笛卡尔积
笛卡尔积,一种数学运算。
假设我有两个集合X和Y,那么X和Y的所有可能组合,就是就是X和Y的笛卡尔积,组合的个数即为两个集合中元素个数的乘积数。
例如:
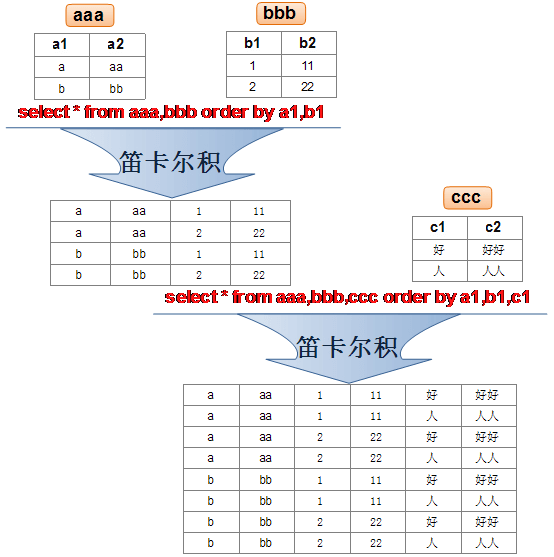
在上文的例子中,employees.last_name和departments.department_name的所有可能组合,就是其笛卡尔积。
以下几种,也是笛卡尔积。
CROSS JOIN(没有连接条件):
1 | SELECT last_name, department_name |
INNER JOIN(没有连接条件):
1 | SELECT last_name, department_name |
JOIN(没有连接条件):
1 | SELECT last_name, department_name |
表的连接条件
那么,怎么解决问题呢?
笛卡尔积的"错误"出现的原因是缺少表的连接条件,所以,解决问题的关键点是添加表的连接条件。
例如:
1 | SELECT last_name, department_name |
1 | SELECT last_name, department_name |
1 | SELECT last_name, department_name |
1 | SELECT last_name, department_name |
关联查询的分类
- 根据连接条件,可以分为:
- 等值连接
- 非等值连接
- 根据关联的表是否同一张,可以分为:
- 自连接
- 非自连接
- 根据关联方式,可以分为:
- 内连接
- 外连接
等值连接与非等值连接
等值连接
等值连接,是指关联条件是"相等"。
示例代码:
1 | SELECT employees.employee_id, |
1 | SELECT e.employee_id, |
解释说明:
- 多个表中有相同列时,必须在列名之前加上表名前缀。
- 可以使用表的别名。需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
强烈建议指定表
在阿里巴巴的开发规范中,对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。
正例:
1 | SELECT t1.name |
反例:
在某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现1052异常:Column ‘name’ in field list is ambiguous。
非等值连接
非等值连接,顾名思义,连接条件不是"相等"。
示例代码:
1 | SELECT e.last_name, e.salary, j.grade_level |
1 | SELECT e.last_name, e.salary, j.grade_level |
自连接与非自连接
自连接: table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。反之,如果不是同一张表,则被称为非自连接。
示例代码:
1 | SELECT CONCAT(worker.last_name, ' works for ' |
运行结果:
1 | +----------------------------------------------------------------------+ |
内连接和外连接
内连接和外连接,是关联查询的分类的第三种分类方式,根据关联方式进行分类。
内连接
关键字有:JOIN、INNER JOIN、CROSS JOIN。
取交集。
语法:
1 | SELECT 字段列表 |
示例代码:
1 | SELECT e.employee_id, |
1 | SELECT e.employee_id, l.city, d.department_name |
外连接
外连接,OUTER JOIN,可以分为三种:
- 左外连接,
LEFT OUTER JOIN - 右外连接,
RIGHT OUTER JOIN - 满外连接,
FULL OUTER JOIN
左外连接
LEFT JOIN,以左边的表为准,右边的表没有的数据补NULL。
语法:
1 | SELECT 字段列表 |
示例代码:
1 | SELECT e.last_name, e.department_id, d.department_name |
运行结果:
1 | +-----------+-------------+----------------+ |
解释说明:有一行的department_id和department_name是NULL。
右外连接
RIGHT JOIN,以右边的表为准,左边的表没有的数据补NULL。
语法:
1 | SELECT 字段列表 |
示例代码:
1 | SELECT e.last_name, e.department_id, d.department_name |
运行结果:
1 | +-----------+-------------+--------------------+ |
解释说明:有若干行的last_name和department_id是NULL。
满外连接
FULL OUTER JOIN,满外连接。
需要注意的是,MySQL不支持FULL JOIN,但是可以用UNION的方式代替。
示例代码:
1 | SELECT e.last_name, e.department_id, d.department_name |
七种JOIN
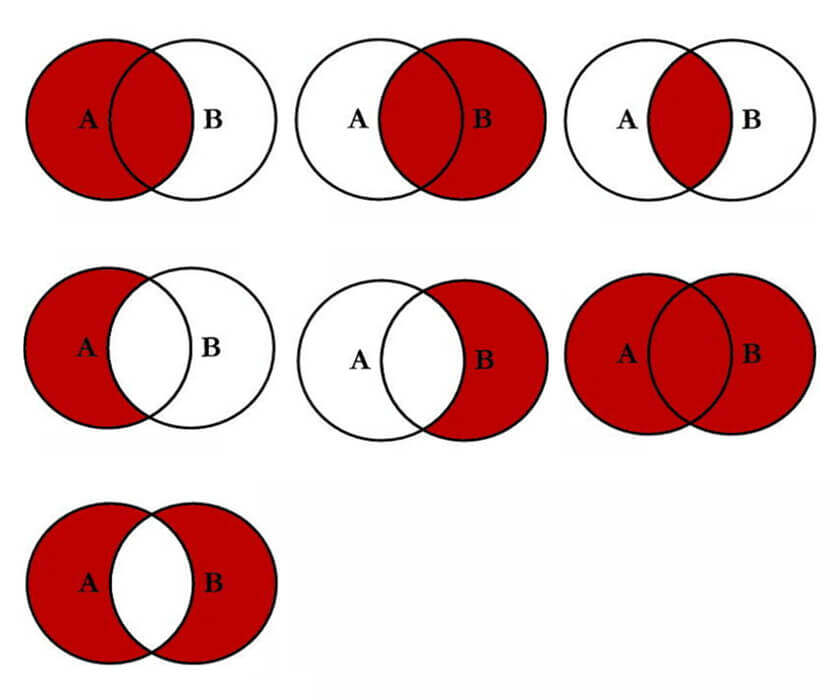
- 查询以左边的表为准,右边没有的数据补
NULL。
左连接。
示例代码:1
2
3SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`; - 查询以右边的表为准,左边没有的数据补
NULL。
右连接。
示例代码:1
2
3SELECT employee_id, last_name, department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`; - 查询左边和右边都有数据的。
内连接。
示例代码:1
2
3SELECT employee_id, last_name, department_name
FROM employees e
JOIN departments d ON e.`department_id` = d.`department_id`; - 查询左边有,且右边没有的。
先做左连接,然后剔除掉右边为NULL的。
示例代码:1
2
3
4SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL; - 查询右边有,且左边没有的。
先做右连接,然后剔除掉左边为NULL的。
示例代码:1
2
3
4SELECT employee_id, last_name, department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL; - 查询左边和右边的全连接
用UNION1
2
3
4
5
6
7
8SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id, last_name, department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`; - 查询左边有右边没有和右边有左边没有的
1
2
3
4
5
6
7
8
9SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id, last_name, department_name
FROM employees e
RIGHT JOIN departments d ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
UNION
UNION,格式如下:
1 | SELECT column,... FROM table1 |
其中:
UNION,去重,效率较低。UNION ALL,不去重,效率较高。
如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
(在《5.索引和优化》,我们还会讨论,UNION ALL效率更高的具体原因。)
规范
- 在阿里巴巴的开发规范中,超过三个表禁止JOIN。
- 需要JOIN的字段,数据类型保持绝对一致。
- 多表关联查询时,保证被关联的字段有索引。
(后两个规范要求,和效率有关,在《5.索引和优化》会讨论。)
单行函数
函数的分类
按照入参是一行还是多行,MySQL中的内置函数可以分为:
- 单行函数
入参只有一行,例如:数值函数、字符串函数、日期和时间函数、流程控制函数、MySQL信息函数。 - 多行函数
入参有多行,例如:聚合函数。
数值函数
| 函数 | 用法 |
|---|---|
ABS(x) |
返回绝对值 |
SIGN(x) |
返回符号,正数返回,负数返回,返回 |
PI() |
返回圆周率 |
CEIL(x) CEILING(x) |
返回大于或等于某个值的最小整数 |
FLOOR(x) |
返回小于或等于某个值的最大整数 |
LEAST(e1,e2,e3…) |
返回列表中的最小值 |
GREATEST(e1,e2,e3…) |
返回列表中的最大值 |
MOD(x,y) |
返回除以后的余数 |
RAND() |
返回的随机值 |
RAND(x) |
返回的随机值,其中的值用作随机数种子 |
ROUND(x) |
对进行四舍五入,返回整数。 |
ROUND(x,y) |
对进行四舍五入,并保留到小数点后面位 |
TRUNCATE(x,y) |
返回数字截断为位小数的结果 |
SQRT(x) |
返回的平方根。当的值为负数时,返回NULL |
FORMAT(value,n) |
返回对数字value进行格式化后的结果数据,n表示四舍五入后保留到小数点后n位,不足的补0 |
绝对值、符号、圆周率、向上取整、向下取整、余数,示例代码:
1 | SELECT ABS(-123), |
运行结果:
1 | +---------+-------+---------+--------+--------+-----------+---------------+------------+-------------+----------+ |
随机数,示例代码:
1 | SELECT RAND(), RAND(), RAND(10), RAND(10), RAND(-1), RAND(-1) |
运行结果:
1 | +-----------------+-------------------+------------------+------------------+------------------+------------------+ |
四舍五入(ROUND)和截断(TRUNCATE),示例代码:
1 | SELECT ROUND(13.579), ROUND(13.579, 2), ROUND(13.579, -1), TRUNCATE(13.579, 2), TRUNCATE(13.579, -1); |
运行结果:
1 | +-------------+----------------+-----------------+-------------------+--------------------+ |
格式化,不足的补0,示例代码:
1 | SELECT FORMAT(123.123, 2), |
运行结果:
1 | +------------------+------------------+------------------+-------------------+-------------------+--------------+ |
解释说明:如果n的值小于或等于0,则只保留整数部分。
除了上述的,数值函数还有很多,例如:
- 角度与弧度函数:
RADIANS(x):将角度转化为弧度。DEGREES(x):将弧度转化为角度。
- 三角函数:
SIN(x):返回正弦值,其中,参数为弧度值。COS(x):返回余弦值,其中,参数为弧度值。
- 指数与对数:
POW(x,y),POWER(X,Y):返回的次方。EXP(x):返回的次方。LN(x),LOG(x):返回以为底的的对数,当时,返回NULL。LOG10(x):返回以为底的的对数,当时,返回NULL。LOG2(x):返回以为底的的对数,当时,返回NULL。
- 进制间的转换:
BIN(x):返回二进制编码。HEX(x):返回十六进制编码。OCT(x):返回八进制编码。CONV(value,from,to):将value的值进行不同进制之间的转换
示例代码:
1 | SELECT SIN(RADIANS(30)), |
运行结果:
1 | +-------------------+------------------+---------+-----------+----------------+-----------------+---------+-------+-------+-------+-------+--------------+---------------+----------------+-----------------+ |
字符串函数
| 函数 | 用法 |
|---|---|
ASCII(s) |
返回字符串s中的第一个字符的ASCII码值 |
CHAR_LENGTH(s) CHARACTER_LENGTH(s) |
返回字符串s的字符数 |
LENGTH(s) |
返回字符串s的字节数,具体字节数和字符集有关 |
CONCAT(s1,s2,...,sn) |
连接"s1,s2,…,sn"为一个字符串 |
CONCAT_WS(x, s1,s2,...,sn) |
同CONCAT(s1,s2,...,sn)函数,但在"s1,s2,…,sn"之间要加上指定的字符x |
INSERT(str, idx, len, replacestr) |
将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr |
REPLACE(str, a, b) |
将字符串str中所有出现的字符串a,替换成b |
UPPER(s) UCASE(s) |
将字符串s的所有字母转成大写字母 |
LOWER(s) LCASE(s) |
将字符串s的所有字母转成小写字母 |
LEFT(str,n) |
返回字符串str最左边的n个字符 |
RIGHT(str,n) |
返回字符串str最右边的n个字符 |
LPAD(str, len, pad) |
用字符串pad对str最左边进行填充,直到str的长度为len个字符 |
RPAD(str ,len, pad) |
用字符串pad对str最右边进行填充,直到str的长度为len个字符 |
LTRIM(s) |
去掉字符串s左侧的空格 |
RTRIM(s) |
去掉字符串s右侧的空格 |
TRIM(s) |
去掉字符串s开始与结尾的空格 |
TRIM(s1 FROM s) |
去掉字符串s开始与结尾的s1 |
TRIM(LEADING s1 FROM s) |
去掉字符串s开始处的s1 |
TRIM(TRAILING s1 FROM s) |
去掉字符串s结尾处的s1 |
REPEAT(str, n) |
str重复n次的结果 |
SPACE(n) |
n个空格 |
STRCMP(s1,s2) |
比较字符串s1,s2的ASCII码值的大小 |
SUBSTR(s,index,len) SUBSTRING(s,n,len) MID(s,n,len) |
从字符串s的index位置其len个字符 |
LOCATE(substr,str) POSITION(substr IN str) INSTR(str,substr) |
字符串substr在字符串str中首次出现的位置;未找到,返回0 |
ELT(m,s1,s2,…,sn) |
返回指定位置的字符串,如果m=1,则返回s1,如果m=2,则返回s2,以此类推 |
FIELD(s,s1,s2,…,sn) |
返回字符串s在字符串列表中第一次出现的位置 |
FIND_IN_SET(s1,s2) |
返回字符串s1在字符串s2中出现的位置。其中,字符串s2是一个以逗号分隔的字符串 |
REVERSE(s) |
返回s反转后的字符串 |
NULLIF(value1,value2) |
比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1 |
- 注意!在MySQL中,字符串的位置是从
1开始的。
查找某个字符串在另一个字符串中的位置,示例代码:
1 | SELECT LOCATE('s', 'str'), |
运行结果:
1 | +------------------+----------------------+-----------------+------------------+----------------------+-----------------+ |
在Java,Python和JavaScript中,也都有类似的功能,如下:
示例代码:
1 | System.out.println("str".contains("s")); |
1 | true |
示例代码:
1 | print('str'.find('s')) |
1 | 0 |
示例代码:
1 | console.log('str'.indexOf('s')) |
1 | 0 |
返回字符串s在字符串列表中第一次出现的位置,示例代码:
1 | SELECT FIELD('mm', 'hello', 'mm', 'amma'), FIND_IN_SET('mm', 'hello,mm,amma'); |
运行结果:
1 | +----------------------------------+----------------------------------+ |
比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1,示例代码:
1 | SELECT NULLIF('mysql', 'mysql'), NULLIF('mysql', ''); |
运行结果:
1 | +------------------------+-------------------+ |
日期和时间函数
获取日期、时间
| 函数 | 用法 |
|---|---|
CURDATE() CURRENT_DATE() |
返回当前日期,只包含年、月、日 |
CURTIME() CURRENT_TIME() |
返回当前时间,只包含时、分、秒 |
NOW() CURRENT_TIMESTAMP() LOCALTIME() LOCALTIMESTAMP() |
返回当前系统日期和时间(语句执行时刻) |
SYSDATE() |
返回当前系统日期和时间(动态) |
UTC_DATE() |
返回UTC(世界标准时间)日期 |
UTC_TIME() |
返回UTC(世界标准时间)时间 |
当前日期、当前时间、当前日期和时间、UTC(世界标准时间)日期、UTC(世界标准时间)时间,示例代码:
1 | SELECT CURDATE(), |
运行结果:
1 | +----------+---------+-------------------+----------+----------+ |
SYSDATE()和NOW()的区别,示例代码:
1 | SELECT NOW(), |
运行结果:
1 | +-------------------+-------------------+-------------------+-------------------+-------------------+--------+-------------------+-------------------+-------------------+-------------------+-------------------+ |
解释说明:NOW()取的是语句开始执行的时间,在整个语句执行过程中都不会变化,SYSDATE()取的是动态的实时时间,在语句的不同执行时刻会存在变化。
日期与时间戳的转换
| 函数 | 用法 |
|---|---|
UNIX_TIMESTAMP() |
以UNIX时间戳的形式返回当前时间 |
UNIX_TIMESTAMP(date) |
将时间date以UNIX时间戳的形式返回 |
FROM_UNIXTIME(timestamp) |
将UNIX时间戳的时间转换为普通格式的时间 |
日期与时间戳的转换,示例代码:
1 | SELECT UNIX_TIMESTAMP(), |
运行结果:
1 | +----------------+---------------------+-------------------------+-------------------------+-------------------------------------+-------------------------+ |
获取月份、星期、星期数、天数等
| 函数 | 用法 |
|---|---|
YEAR(date) MONTH(date) DAY(date) |
返回具体的日期值:年、月、日 |
HOUR(time) MINUTE(time) SECOND(time) |
返回具体的时间值:时、分、秒 |
MONTHNAME(date) |
返回月份名:January、February等 |
DAYNAME(date) |
返回星期名:Monday、Tuesday等 |
WEEKDAY(date) |
返回星期数字:0代表周一、1代表周二、…、6代表周天 |
DAYOFWEEK(date) |
返回一周的第几天:周天是1、周一是2、…、周六是7 |
QUARTER(date) |
返回日期对应的季度,范围为 |
WEEK(date) WEEKOFYEAR(date) |
返回一年中的第几周 |
DAYOFYEAR(date) |
返回日期是一年中的第几天 |
DAYOFMONTH(date) |
返回日期位于所在月份的第几天 |
WEEKDAY(date)和DAYOFWEEK(date)的计数方式不一样。
获取年、月、日、时、分、秒,示例代码:
1 | SELECT YEAR(CURDATE()), |
运行结果:
1 | +---------------+----------------+--------------+---------------+-------------+-----------------+ |
获取月份名、星期名、星期数字、季度、一年中的第几周、一年中的第几天、第一月中的第几天、一周中的第几天,示例代码:
1 | SELECT MONTHNAME('2022-02-15'), |
运行结果:
1 | +-----------------------+---------------------+---------------------+------------------+---------------+----------------+-----------------+----------------+ |
WEEKDAY(date),获取星期数字,0代表周一、1代表周二;DAYOFWEEK(date),返回一周的第几天,周天是1、周一是2。
示例代码:
1 | SELECT WEEKDAY(CURDATE()), DAYOFWEEK(CURDATE()); |
运行结果:
1 | +------------------+--------------------+ |
时间和秒钟转换
| 函数 | 用法 |
|---|---|
TIME_TO_SEC(time) |
将time转化为秒并返回结果值 |
SEC_TO_TIME(seconds) |
将seconds描述转化为包含小时、分钟和秒的时间 |
时间和秒钟转换,示例代码:
1 | SELECT TIME_TO_SEC(NOW()), SEC_TO_TIME(TIME_TO_SEC(NOW())); |
运行结果:
1 | +------------------+-------------------------------+ |
计算日期和时间的函数
| 函数 | 用法 |
|---|---|
DATE_ADD(date, INTERVAL expr type) ADDDATE(date, INTERVAL expr type) |
在给定日期时间基础上,加上一定的日期时间 |
DATE_SUB(date, INTERVAL expr type) SUBDATE(date, INTERVAL expr type) |
在给定日期时间基础上,减去一定的日期时间 |
type的取值为:YEAR、MONTH、DAY、HOUR、MINUTE、SECOND,以及其中的某些组合,YEAR_MONTH、DAY_HOUR、DAY_MINUTE、DAY_SECOND、HOUR_MINUTE、HOUR_SECOND、MINUTE_SECOND。
加1天、加1秒、加1秒、加1分1秒、加-1年、加1年1月,示例代码:
1 | SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) AS col1, |
运行结果:
1 | +-------------------+-------------------+-------------------+-------------------+-------------------+-------------------+ |
减31天、减31天、减-1天、减1天1小时,示例代码:
1 | SELECT DATE_SUB('2022-02-15', INTERVAL 31 DAY) AS col1, |
运行结果:
1 | +----------+----------+----------+-------------------+ |
解释说明:可以加上或减去一个负的时间单位。
除了上述,还有其他更灵活的。
| 函数 | 用法 |
|---|---|
ADDTIME(time1,time2) |
返回time1加上time2的时间;当time2为一个数字时,代表的是秒,可以为负数。 |
SUBTIME(time1,time2) |
返回time1减去time2后的时间;当time2为一个数字时,代表的是秒,可以为负数。 |
DATEDIFF(date1,date2) |
返回date1-date2的日期间隔天数。 |
TIMEDIFF(time1,time2) |
返回time1-time2的时间间隔。 |
FROM_DAYS(N) |
返回从0000年1月1日起,N天以后的日期 |
TO_DAYS(date) |
返回日期date距离0000年1月1日的天数 |
LAST_DAY(date) |
返回date所在月份的最后一天的日期 |
MAKEDATE(year,n) |
针对给定年份与所在年份中的天数返回一个日期 |
MAKETIME(hour,minute,second) |
将给定的小时、分钟和秒组合成时间并返回 |
PERIOD_ADD(time,n) |
返回time加上n后的时间 |
日期的格式化与解析
| 函数 | 用法 |
|---|---|
DATE_FORMAT(date,fmt) |
按照字符串fmt格式化日期date值 |
TIME_FORMAT(time,fmt) |
按照字符串fmt格式化时间time值 |
STR_TO_DATE(str,fmt) |
按照字符串fmt对str进行解析,解析为一个日期 |
fmt参数常用的格式符:
- 年:
%Y:四位数字表示年份
%y:表示两位数字表示年份 - 月:
%M:月名表示月份(January)
%b:缩写的月名(Jan,Feb)
%m:两位数字表示月份(01,02,03)
%c:数字表示月份(1,2,3) - 天:
%D:英文后缀表示月中的天数(1st,2nd,3rd)
%d:两位数字表示月中的天数(01,02,03)
%e:数字形式表示月中的天数(1,2,3) - 时:
%H:两位数字表示小数,24小时制(01,02,03)
%h、%I:两位数字表示小时,12小时制(01,02,03)
%k:数字形式的小时,24小时制(1,2,3)
%l:数字形式表示小时,12小时制(1,2,3) - 分:
%i:两位数字表示分钟(00,01,02) - 秒:
%S、%s:两位数字表示秒(00,01,02) - 星期:
%W:一周中的星期名称(Sunday)
%a:一周中的星期缩写(Sun,Mon,Tue)
%w:以数字表示周中的天数(0:Sunday,1:Monday) - 天数:
%j:以3位数字表示年中的天数(001,002,003) - 周数:
%U:以数字表示年中的第几周(1,2,3),周天为一周的第一天
%u:以数字表示年中的第几周(1,2,3),周一为一周的第一天 - 时制:
%T:24小时制
%r:12小时制 - 上下午:
%p:AM或PM - 转义:
%%:表示%
示例代码:
1 | SELECT DATE_FORMAT(NOW(), '%H:%i:%s'), |
运行结果:
1 | +------------------------------+-------------------------------------+---------------------------------------------+-------------------------------------------------------+ |
流程控制函数
MySQL中的流程处理函数主要包括:
IF(value,value1,value2):
如果value的值为TRUE,返回value1,否则返回value2。IFNULL(value1, value2):
如果value1不为NULL,返回value1,否则返回value2`。CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END:
相当于Java的if...else if...else if...else...CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 .... [ELSE 值n] END:
相当于Java的switch...case...break...default
IF(value,value1,value2),示例代码:
1 | SELECT IF(1 > 0, '正确', '错误'); |
运行结果:
1 | +---------------------+ |
IFNULL(value1, value2),示例代码:
1 | SELECT IFNULL(null, 'Hello Word'); |
运行结果:
1 | +--------------------------+ |
解释说明:第一个参数为NULL,所以返回第二个参数。
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END,示例代码:
1 | SELECT CASE WHEN 1 > 0 THEN '1 > 0' WHEN 2 > 0 THEN '2 > 0' ELSE '3 > 0' END; |
运行结果:
1 | +---------------------------------------------------------------------+ |
解释说明:相当于Java的if...else if...else if...else...,所以当第一个判断为真的时候,不会进入第二个判断,所以输出且只输出1 > 0
CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 .... [ELSE 值n] END,示例代码:
1 | SELECT CASE 1 WHEN 1 THEN '我是1' WHEN 1 THEN '我也是1' WHEN 2 THEN '我是2' ELSE '你是谁' END; |
运行结果:
1 | +----------------------------------------------------------------------------+ |
解释说明:相当于Java的switch...case...break...default,所以当第一个条件符合的时候,会break掉,所以不会进入后面的条件。
MySQL信息函数
| 函数 | 用法 |
|---|---|
VERSION() |
返回当前MySQL的版本号 |
CONNECTION_ID() |
返回当前MySQL服务器的连接ID |
DATABASE() SCHEMA() |
返回MySQL命令行当前所在的数据库 |
USER() CURRENT_USER() SYSTEM_USER() SESSION_USER() |
返回当前连接MySQL的用户名,返回结果格式为"主机名@用户名" |
CHARSET(value) |
返回字符串value自变量的字符集 |
COLLATION(value) |
返回字符串value的比较规则 |
MySQL信息函数,示例代码:
1 | SELECT VERSION(), |
运行结果:
1 | +---------+---------------+----------+---------+------------------+--------------+------------------+------------------+----------------+------------------+ |
聚合函数
五种聚合函数
聚合函数,入参有多行,对一组数据进行聚合,只返回一个值。
常见的五种聚合函数有:
AVG():数值型数据的平均值SUM():数值型数据的总和MAX():任意数据类型的数据的最大值MIN():任意数据类型的数据的最小值COUNT():个数
注意:聚合函数不能嵌套调用。比如不能出现类似AVG(SUM(字段名称))形式的调用。
COUNT
三种用法
在5种聚合函数中,需要专门讨论的是COUNT()。
COUNT()中,常见的三种用法为:
COUNT(*)COUNT(1)COUNT(字段名)
在计数规则方面
COUNT(*)和COUNT(1),会去统计表中的行数,如果某一行有一个或多个字段为NULL,依旧会被视作一行。COUNT(字段名),会统计该字段名的列中,不为NULL的数据个数,即不统计NULL。
也就是说,COUNT(*)和COUNT(1),统计的是表的行数,COUNT(字段名)统计的是某一列的个数。
在查询效率方面
对于InnoDB引擎
- 对于
COUNT(1),InnoDB引擎会去找到一个最小的索引树去遍历(不一定是主键索引),但是不会读取数据,而是读到一个叶子节点,就返回1,最后将结果累加。 - 对于
COUNT(字段名)- 如果该字段是主键索引,性能OK。
- 如果该字段不是主键索引,InnoDB引擎会遍历整张表做全表扫描; 所以,不要这么用!
- 对于
COUNT(*),InnoDB引擎会自动进行优化。
对于MyISAM引擎
对于MyISAM引擎,且没有其他WHERE条件,或者GROUP BY条件,三种方法的效率是一样的。
即,如下三个SQL的效率是一样的。
1 | SELECT COUNT(*) FROM 表; |
这是因为MyISAM把表中的行数直接存在磁盘中了,需要的时候直接读取出来就行了,所以非常快。
GROUP BY
基本使用
可以使用GROUP BY子句将表中的数据分成若干组。
用法:
1 | SELECT column, group_function(column) |
注意:
- 在SELECT列表中所有未包含在聚合函数中的列都应该被包含在
GROUP BY子句中,即在上述例子中的所有的column,都应该被包含在group_by_expression。 - 包含在
GROUP BY子句中的列不必包含在SELECT列表中。 - 可以使用多个列分组。
示例代码:
1 | SELECT department_id, AVG(salary) |
1 | SELECT AVG(salary) |
1 | SELECT department_id dept_id, job_id, SUM(salary) |
WITH ROLLUP
WITH ROLLUP,可以理解成"汇总"。
例如,所有的和。
示例代码:
1 | SELECT department_id, SUM(salary) |
运行结果:
1 | +-------------+-----------+ |
又如,所有的平均。
示例代码:
1 | SELECT department_id, AVG(salary) |
运行结果:
1 | +-------------+------------+ |
注意,是对结果的汇总,是上述三行结果的平均,不是对所有的表中的数据求平均。
GROUP_CONCAT
GROUP_CONCAT()中的字段,以逗号进行拼接。
假设存在表如下:
| deptno | dname | loc |
|---|---|---|
| 1 | 信息技术 | 上海 |
| 2 | 信息技术 | 北京 |
| 3 | 市场 | 纽约 |
| 4 | 市场 | 新加坡 |
示例代码:
1 | SELECT dname, group_concat(loc) |
运行结果:
1 | +-----+-----------------+ |
替换DISTINCT
正如我们上文所说,在分布式数据库中,去重的更好办法是用GROUP BY。
对于SELECT DISTINCT department_id FROM employees;,SELECT department_id FROM employees GROUP BY department_id;的性能会更好。
因为在分布式数据库中,DISTINCT会将所有节点的数据进行汇总到主节点,然后进行运算。但是GROUP是,每个节点先分别计算,最后汇总到主节点再进行一次运算。
HAVING
用法
HAVING:过滤分组,满足HAVING子句中条件的分组将被显示。
例如:查询部门平均工资比10000高的部门。
首先,查询部门平均工资,这个很简单。
1 | SELECT department_id, AVG(salary) |
那么,怎么找到平均工资比10000高的部门呢?
加上HAVING AVG(salary)>10000;。
1 | SELECT department_id, AVG(salary) |
HAVING子句使用的前提
- 已经被分组(所以
HAVING不能单独使用,必须要和GROUP BY一起使用。) - 使用了聚合函数。
特别的,HAVING中的聚合函数,不必和SELECT中的聚合函数一致。
示例代码:
1 | SELECT department_id, AVG(salary) |
运行结果:
1 | +-------------+------------+ |
HAVING和WHERE的区别
在查询语法结构上
WHERE在GROUP BY之前,所以无法对分组结果进行筛选,被WHERE排除的记录不再包括在分组中。HAVING在GROUP BY之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选。
在筛选条件上
WHERE可以使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件。HAVING可以使用分组计算的函数作为筛选条件,也可以表中的字段作为筛选条件。
HAVING使用表中的字段作为筛选条件,示例代码:
1 | SELECT department_id, AVG(salary) |
运行结果:
1 | +-------------+-----------+ |
在关联查询效率上
WHERE是先筛选后连接。HAVING是先连接后筛选。
所以,在关联查询中,WHERE比HAVING更高效。
那么,到底是选择WHERE还是HAVING呢?
一般,包含分组统计函数的条件用HAVING,普通条件用WHERE。
子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询。
例子
例如,我们要查询薪资比Abel高的员工。
我们有多种方式:
- 用两个SQL,先查到Abel的工资具体是多少,然后找到工资比那个数字大的员工。
1
2
3SELECT salary
FROM employees
WHERE last_name = 'Abel';1
2
3SELECT last_name, salary
FROM employees
WHERE salary > 11000; - 自连接,构造Abel的薪资表,两张表进行关联,设置条件"工资大于Abel工资"。
1
2
3
4
5SELECT e2.last_name, e2.salary
FROM employees e1,
employees e2
WHERE e1.last_name = 'Abel'
AND e2.`salary` > e1.`salary` - 子查询,先查到Abel的工资具体是多少,然后找到工资比那个数字大的员工
1
2
3
4
5
6
7SELECT last_name, salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
基本使用
子查询的基本语法结构:

注意:
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询(子查询的结果返回一条)
多行操作符对应多行子查询(子查询的结果返回多条)
接下来,我们分别讨论单行子查询和多行子查询。
单行子查询
基础操作
例如,查询job_id与141号员工相同,salary比143号员工多的员工姓名、job_id和工资。
1 | SELECT last_name, job_id, salary |
查询公司工资最少的员工的last_name、job_id和salary。
1 | SELECT last_name, job_id, salary |
成对比较法
例如,查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id、manager_id和department_id。
分别比较法(不成对比较):
即,manager_id和department_id,分别进行比较,用AND进行关联。
1 | SELECT employee_id, manager_id, department_id |
成对比较法:
即,manager_id和department_id,同时进行比较。
1 | SELECT employee_id, manager_id, department_id |
HAVING中的子查询
HAVING中的子查询,首先执行子查询,然后向主查询中的HAVING子句返回结果。
例如,查询最低工资大于50号部门最低工资的部门id和其最低工资。
1 | SELECT department_id, MIN(salary) |
CASE中的子查询
在CASE中使用单列子查询:
例如,查询员工的employee_id,last_name和location。若该department_id对应的location_id为1800,则location为’Canada’,否则为’USA’。
1 | SELECT employee_id, |
多行子查询
多行子查询,也被称为集合比较子查询,其特点有子查询返回多行,使用多行比较操作符。
多行比较操作符,除了有IN(等于任意一个),还有ANY(任意一个)、ALL(所有)。
相关子查询
什么是相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为相关子查询。
(也有些资料会把"相关子查询",称为"关联子查询",为了避免和"关联查询"混淆,我们采取"相关子查询"这个名称。)
例如:
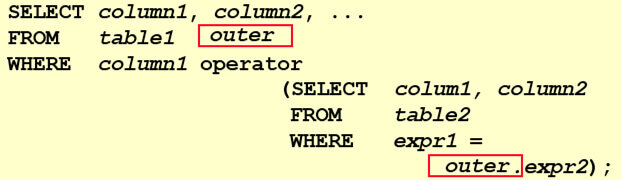
在子查询的语句中,出现了外部的表,这时候需要先把外部表中的相关数据送进子查询。
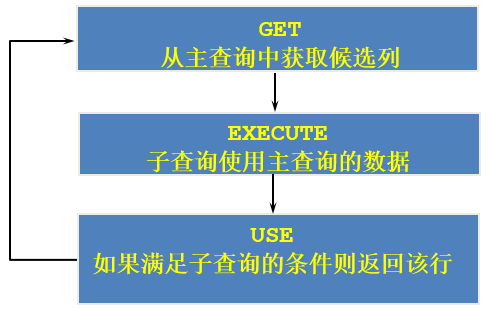
即,相关子查询的步骤如下:
例子
接下里,我们来举几个相关子查询例子。
子查询的位置
子查询可以写在:
SELECTFROMWHEREHAVINGORDER BY
子查询不可以写在:
LIMITGROUP BY
关键字的顺序
最后,在一个查询语句中,几个关键字的顺序,如下:
SELECTFROMWHEREGROUP BYHAVINGORDER BYLIMIT