案例介绍
本文以Kaggle上的Telco Customer Churn(电信客户流失)为例。https://www.kaggle.com/datasets/blastchar/telco-customer-churn
字段
解释
customerID
用户ID
gender
性别
SeniorCitizen
是否是老年人(1代表是)
Partner
是否有配偶(Yes or No)
Dependents
是否经济独立(Yes or No)
tenure
用户入网时间
PhoneService
是否开通电话业务(Yes or No)
MultipleLines
是否开通多条电话业务(Yes 、 No or No phoneservice)
InternetService
是否开通互联网服务(No、DSL数字网络或filber potic光线网络)
OnlineSecurity
是否开通网络安全服务(Yes、No or No internetservice)
OnlineBackup
是否开通在线备份服务(Yes、No or No internetservice)
DeviceProtection
是否开通设备保护服务(Yes、No or No internetservice)
TechSupport
是否开通技术支持业务(Yes、No or No internetservice)
StreamingTV
是否开通网络电视(Yes、No or No internetservice)
StreamingMovies
是否开通网络电影(Yes、No or No internetservice)
Contract
合同签订方式(按月、按年或者两年)
PaperlessBilling
是否开通电子账单(Yes or No)
PaymentMethod
付款方式(bank transfer、credit card、electronic check、mailed check)
MonthlyCharges
月度费用
TotalCharges
总费用
Churn
是否流失(Yes or No)
把数据下载过来,简单的看一下。示例代码:
1 2 3 t = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv' ) t.head(5 )
运行结果:
1 2 3 4 5 6 customerID gender SeniorCitizen Partner Dependents tenure PhoneService MultipleLines InternetService OnlineSecurity OnlineBackup DeviceProtection TechSupport StreamingTV StreamingMovies Contract PaperlessBilling PaymentMethod MonthlyCharges TotalCharges Churn 0 7590-VHVEG Female 0 Yes No 1 No No phone service DSL No Yes No No No No Month-to-month Yes Electronic check 29.85 29.85 No 1 5575-GNVDE Male 0 No No 34 Yes No DSL Yes No Yes No No No One year No Mailed check 56.95 1889.5 No 2 3668-QPYBK Male 0 No No 2 Yes No DSL Yes Yes No No No No Month-to-month Yes Mailed check 53.85 108.15 Yes 3 7795-CFOCW Male 0 No No 45 No No phone service DSL Yes No Yes Yes No No One year No Bank transfer (automatic) 42.30 1840.75 No 4 9237-HQITU Female 0 No No 2 Yes No Fiber optic No No No No No No Month-to-month Yes Electronic check 70.70 151.65 Yes
查看这个DataFrame的信息。示例代码:
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <class 'pandas.core.frame.DataFrame'> RangeIndex: 7043 entries, 0 to 7042 Data columns (total 21 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 customerID 7043 non-null object 1 gender 7043 non-null object 2 SeniorCitizen 7043 non-null int64 3 Partner 7043 non-null object 4 Dependents 7043 non-null object 5 tenure 7043 non-null int64 6 PhoneService 7043 non-null object 7 MultipleLines 7043 non-null object 8 InternetService 7043 non-null object 9 OnlineSecurity 7043 non-null object 10 OnlineBackup 7043 non-null object 11 DeviceProtection 7043 non-null object 12 TechSupport 7043 non-null object 13 StreamingTV 7043 non-null object 14 StreamingMovies 7043 non-null object 15 Contract 7043 non-null object 16 PaperlessBilling 7043 non-null object 17 PaymentMethod 7043 non-null object 18 MonthlyCharges 7043 non-null float64 19 TotalCharges 7043 non-null object 20 Churn 7043 non-null object dtypes: float64(1), int64(2), object(18) memory usage: 1.1+ MB
重复值处理
拿到数据后,对数据进行一些简单的校验。例如:字段的一致性(检查数据集字段是否和约定的字段一致),数据的重复性(检查数据集中是否有重复值)
检测字段是否一致这个很简单,直接进行比对就可以了。
主要讨论检测数据集是否有重复值的方法。
重复值检测
duplicated()
格式:
1 DataFrame.duplicated(subset=None , keep='first' )
参数:
subset:列标签或标签序列,可选,默认情况下使用所有列。keep:first、last、False,默认为first
first:将重复项标记为True,第一次出现的除外,即保留第一个。last:将重复项标记为True,最后一次出现的除外,即保留最后一个。False:将所有重复项标记为True,都不保留。
返回:Series
定义一个有重复值的DataFrame,示例代码:
1 2 3 4 5 6 df_d = pd.DataFrame({ 'brand' : ['YumYum' , 'YumYum' , 'YumYum' , 'Indomie' , 'Indomie' , 'Indomie' ], 'style' : ['cup' , 'cup' , 'cup' , 'cup' , 'pack' , 'pack' ], 'rating' : [4 , 4 , 4 , 3.5 , 15 , 5 ]}) print(df_d)
运行结果:
1 2 3 4 5 6 7 brand style rating 0 YumYum cup 4.0 1 YumYum cup 4.0 2 YumYum cup 4.0 3 Indomie cup 3.5 4 Indomie pack 15.0 5 Indomie pack 5.0
打印重复记录:示例代码:
1 print(df_d.duplicated())
运行结果:
1 2 3 4 5 6 7 0 False 1 True 2 True 3 False 4 False 5 False dtype: bool
df_d.duplicated()返回的是一个Series。示例代码:
1 print(type(df.duplicated()))
运行结果:
1 <class 'pandas.core.series.Series'>
特别的,我们可以设置为只保留最后一个,即最后一个不被认为是重复的。示例代码:
1 print(df.duplicated(keep='last' ))
运行结果:
1 2 3 4 5 6 7 0 True 1 True 2 False 3 False 4 False 5 False dtype: bool
可以指定列,示例代码:
1 print(df.duplicated(subset=['brand' ]))
运行结果:
1 2 3 4 5 6 7 0 False 1 True 2 True 3 False 4 True 5 True dtype: bool
nunique()
nunique(),统计DataFrame中每列的不同值的个数,Series上也有。
统计DataFrame中每列的不同值的个数,示例代码:
1 2 3 4 5 import pandas as pddf = pd.DataFrame({'A' : [0 , 1 , 1 ], 'B' : [0 , 5 , 6 ]}) print(df) print(df.nunique())
运行结果:
1 2 3 4 5 6 7 A B 0 0 0 1 1 5 2 1 6 A 2 B 3 dtype: int64
Series上也有,示例代码:
1 2 3 4 5 import pandas as pddf = pd.DataFrame({'A' : [0 , 1 , 1 ], 'B' : [0 , 5 , 6 ]}) print(df['A' ]) print(df['A' ].nunique())
运行结果:
1 2 3 4 5 0 0 1 1 2 1 Name: A, dtype: int64 2
在本案例的应用
我们利用duplicated,查找重复的行。
示例代码:
1 print(t.duplicated().sum())
运行结果:
对于主键列,我们利用nunique检测有无重复。
1 2 3 print(t['customerID' ].nunique()) print(t.shape) print(t['customerID' ].nunique() == t.shape[0 ])
运行结果:
去除重复值
drop_duplicates()
方法:
1 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
返回值:返回删除重复值的DataFrame。
参数
subset:用来指定特定的列,默认所有列。keep:first,last,False,保留哪一个?False表示不保留,默认first。inplace:boolean型,默认False,表示是直接在原来数据上修改还是保留一个副本
例子
默认情况下,它会根据所有列删除重复的行。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 import pandas as pddf_d = pd.DataFrame({ 'brand' : ['YumYum' , 'YumYum' , 'YumYum' , 'Indomie' , 'Indomie' , 'Indomie' ], 'style' : ['cup' , 'cup' , 'cup' , 'cup' , 'pack' , 'pack' ], 'rating' : [4 , 4 , 4 , 3.5 , 15 , 5 ]}) print(df_d) df_d = df_d.drop_duplicates() print(df_d)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 brand style rating 0 YumYum cup 4.0 1 YumYum cup 4.0 2 YumYum cup 4.0 3 Indomie cup 3.5 4 Indomie pack 15.0 5 Indomie pack 5.0 brand style rating 0 YumYum cup 4.0 3 Indomie cup 3.5 4 Indomie pack 15.0 5 Indomie pack 5.0
如果要根据特定列,删除重复项,请使用subset,例如df_d.drop_duplicates(subset=['brand'])。示例代码:
1 2 3 4 5 6 7 8 9 10 11 import pandas as pddf_d = pd.DataFrame({ 'brand' : ['YumYum' , 'YumYum' , 'YumYum' , 'Indomie' , 'Indomie' , 'Indomie' ], 'style' : ['cup' , 'cup' , 'cup' , 'cup' , 'pack' , 'pack' ], 'rating' : [4 , 4 , 4 , 3.5 , 15 , 5 ]}) print(df_d) df_d = df_d.drop_duplicates(subset=['brand' ]) print(df_d)
运行结果:
1 2 3 4 5 6 7 8 9 10 brand style rating 0 YumYum cup 4.0 1 YumYum cup 4.0 2 YumYum cup 4.0 3 Indomie cup 3.5 4 Indomie pack 15.0 5 Indomie pack 5.0 brand style rating 0 YumYum cup 4.0 3 Indomie cup 3.5
如果要删除重复项并保留最后一次出现,请使用keep,例如df_d.drop_duplicates(subset=['brand', 'style'], keep='last')。示例代码:
1 2 3 4 5 6 7 8 9 10 11 import pandas as pddf_d = pd.DataFrame({ 'brand' : ['YumYum' , 'YumYum' , 'YumYum' , 'Indomie' , 'Indomie' , 'Indomie' ], 'style' : ['cup' , 'cup' , 'cup' , 'cup' , 'pack' , 'pack' ], 'rating' : [4 , 4 , 4 , 3.5 , 15 , 5 ]}) print(df_d) df_d = df_d.drop_duplicates(subset=['brand' , 'style' ], keep='last' ) print(df_d)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 brand style rating 0 YumYum cup 4.0 1 YumYum cup 4.0 2 YumYum cup 4.0 3 Indomie cup 3.5 4 Indomie pack 15.0 5 Indomie pack 5.0 brand style rating 2 YumYum cup 4.0 3 Indomie cup 3.5 5 Indomie pack 5.0
缺失值处理
缺失值检测
isnull()
语法
我们创建一个DataFrame,其中有一些数据为缺失值。示例代码:
1 2 3 4 5 6 7 8 9 10 import pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randint(10 , 99 , size=(10 , 5 ))) df.iloc[4 :6 , 0 ] = np.nan df.iloc[5 :7 , 2 ] = np.nan df.iloc[7 , 3 ] = None df.iloc[2 :3 , 4 ] = None print(df)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 0 1 2 3 4 0 34.0 51 27.0 32.0 66.0 1 32.0 61 98.0 19.0 34.0 2 61.0 72 80.0 58.0 NaN 3 17.0 56 60.0 17.0 93.0 4 NaN 84 51.0 78.0 18.0 5 NaN 52 NaN 38.0 62.0 6 57.0 13 NaN 68.0 37.0 7 86.0 72 28.0 NaN 52.0 8 50.0 69 70.0 45.0 31.0 9 33.0 48 43.0 54.0 45.0
执行isnull(),对于缺失值,会是True,不是缺失值的是False。示例代码:
运行结果:
1 2 3 4 5 6 7 8 9 10 11 0 1 2 3 4 0 False False False False False 1 False False False False False 2 False False False False True 3 False False False False False 4 True False False False False 5 True False True False False 6 False False True False False 7 False False False True False 8 False False False False False 9 False False False False False
如果和any()或者sum()配合,能发挥更多的作用。
df.isnull().any(),判断哪些列包含缺失值,该列存在缺失值则返回True,反之False。df.isnull().sum(),统计每列缺失值的数量。
示例代码:
1 2 print(df.isnull().any()) print(df.isnull().sum())
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 0 True 1 False 2 True 3 True 4 True dtype: bool 0 2 1 0 2 2 3 1 4 1 dtype: int64
应用
在本文,我们利用isnull()查看数据集缺失情况。
示例代码:
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 customerID 0 gender 0 SeniorCitizen 0 Partner 0 Dependents 0 tenure 0 PhoneService 0 MultipleLines 0 InternetService 0 OnlineSecurity 0 OnlineBackup 0 DeviceProtection 0 TechSupport 0 StreamingTV 0 StreamingMovies 0 Contract 0 PaperlessBilling 0 PaymentMethod 0 MonthlyCharges 0 TotalCharges 0 Churn 0 dtype: int64
更详细统计
我们可以定义如下函数来输出更详细的统计每一列缺失值的数值和占比。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def missing (df) : """ 计算每一列的缺失值及占比 :param df: 需要检测的数据集 :return: """ missing_number = df.isnull().sum().sort_values(ascending=False ) missing_percent = (df.isnull().sum() / df.isnull().count()).sort_values(ascending=False ) missing_values = pd.concat([missing_number, missing_percent], axis=1 , keys=['Missing_Number' , 'Missing_Percent' ]) return missing_values print(missing(t))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Missing_Number Missing_Percent customerID 0 0.0 DeviceProtection 0 0.0 TotalCharges 0 0.0 MonthlyCharges 0 0.0 PaymentMethod 0 0.0 PaperlessBilling 0 0.0 Contract 0 0.0 StreamingMovies 0 0.0 StreamingTV 0 0.0 TechSupport 0 0.0 OnlineBackup 0 0.0 gender 0 0.0 OnlineSecurity 0 0.0 InternetService 0 0.0 MultipleLines 0 0.0 PhoneService 0 0.0 tenure 0 0.0 Dependents 0 0.0 Partner 0 0.0 SeniorCitizen 0 0.0 Churn 0 0.0
不为空
如果我们想找到不为空的呢?
notnull()
示例代码:
1 2 3 4 5 6 7 8 9 10 import pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randint(10 , 99 , size=(10 , 5 ))) df.iloc[4 :6 , 0 ] = np.nan df.iloc[5 :7 , 2 ] = np.nan df.iloc[7 , 3 ] = None df.iloc[2 :3 , 4 ] = None print(pd.notnull(df))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 0 1 2 3 4 0 True True True True True 1 True True True True True 2 True True True True False 3 True True True True True 4 False True True True True 5 False True False True True 6 True True False True True 7 True True True False True 8 True True True True True 9 True True True True True
特殊的缺失值
现象
需要注意的是,上文说的没有缺失值,是技术上没有缺失值,没有空,即不存在None或者Nan(np.Nan)。
isnull(),对于空格,不会将其标识为缺失值。示例代码:
1 2 3 4 5 6 7 import numpy as npimport pandas as pddf = pd.DataFrame({'A' : ['Y' , None , 'N' , 'N' ], 'B' : [np.NaN, ' ' , 'Y' , 'N' ]}) print(df) print(df.isnull())
运行结果:
1 2 3 4 5 6 7 8 9 10 A B 0 Y NaN 1 None 2 N Y 3 N N A B 0 False True 1 True False 2 False False 3 False False
检测方法
我们可以通过比较数据集各列的取值数是否和既定的一致来进行检测。
举例来说,假设对于数据集df,其特征A和B默认情况只有Y和N共2种取值,如果其中某个特征出现了3种取值。那么有可能是通过空格表示了缺失值。
示例代码:
运行结果:
需要注意的是,如果取值数和既定的一致,不一定就是没有缺失值,我们还需要进一步查看B列每个不同取值,及其出现的次数。
1 print(df['B' ].explode().value_counts().to_dict())
运行结果:
1 {' ': 1, 'Y': 1, 'N': 1}
如果是连续变量,则无法使用上述方法进行检测。
所以,我们可以通过类型转换,看看会不会报错,来判断。
应用
1 2 3 numeric_cols = ['tenure' , 'MonthlyCharges' , 'TotalCharges' ] t[numeric_cols].astype(float)
运行结果:
1 ValueError: could not convert string to float: ''
找到缺失值
我们已经发现了在连续特征中存在空格。现在,需要进一步检测空格字符出现在哪一列的哪个位置。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def find_index (data_col, val) : """ 查询某值在某列中第一次出现位置的索引,没有则返回-1 :param data_col: 查询的列 :param val: 具体取值 """ val_list = [val] if data_col.isin(val_list).sum() == 0 : index = -1 else : index = data_col.isin(val_list).idxmax() return index for col in numeric_cols: print(find_index(t[col], ' ' ))
运行结果:
解释说明:
data_col.isin(val_list),返回True和False
在如果进行sum之后,还是等于0,说明不存在;反之,存在。
idxmax(),返回最大的值所位于的index,即True所位于的index。
根据上文的运行结果,空格第一次出现在’TotalCharges’列的索引值为488的位置,即489行。
替换缺失值
常规方法
我们把特殊的缺失值替换为np.Nan。.fillna()方法进行填充。
示例代码:
1 2 3 4 5 6 t['TotalCharges' ] = t['TotalCharges' ].apply(lambda x: x if x != ' ' else np.nan).astype(float) for col in numeric_cols: print(find_index(t[col], ' ' )) print(t['TotalCharges' ].iloc[488 ])
运行结果:
快捷方法(不建议)
有些资料会提供另一种方法,直接使用pd.to_numeric对连续变量进行转化,并在errors参数位上输入'coerce'参数,表示能直接转化为数值类型时直接转化,无法转化的用缺失值填补。
1 2 3 4 5 6 7 8 9 10 11 12 13 import pandas as pddf = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv' ) df.TotalCharges = pd.to_numeric(df.TotalCharges, errors='coerce' ) print(df.TotalCharges.isnull().sum()) print(df.TotalCharges.iloc[488 ]) print(df.TotalCharges.dtype)
运行结果:
这种方法的确省了很多步骤,但不建议。 通过上文的方法,我们知道是具体是哪些值无法转化。但是通过这种方法,不知道哪些值无法转化。
比如说,其中一个值是1万,这个值在这种方法中会被直接转为空。但是实际上,我们可能需要将其转换为10000。
填补缺失值
技术上
在本文,由于缺失值占比较小(15%),可以考虑直接使用均值、中位数或者众数进行填充。
对于连续型,使用均值或者中位数。
对于离散型,使用众数。
1 t['TotalCharges' ].fillna(t['TotalCharges' ].mean())
业务上
在业务上,我们需要去和相关同事进行确认。
在无法确定的情况下,如果能发现一些蛛丝马迹,考虑进行大胆猜测。
在本文,我们注意观察缺失’TotalCharges’信息的每条数据的情况。示例代码:
1 print(t[t['TotalCharges' ].isnull()])
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 customerID gender SeniorCitizen Partner Dependents tenure PhoneService MultipleLines InternetService OnlineSecurity OnlineBackup DeviceProtection TechSupport StreamingTV StreamingMovies Contract PaperlessBilling PaymentMethod MonthlyCharges TotalCharges Churn 488 4472-LVYGI Female 0 Yes Yes 0 No No phone service DSL Yes No Yes Yes Yes No Two year Yes Bank transfer (automatic) 52.55 NaN No 753 3115-CZMZD Male 0 No Yes 0 Yes No No No internet service No internet service No internet service No internet service No internet service No internet service Two year No Mailed check 20.25 NaN No 936 5709-LVOEQ Female 0 Yes Yes 0 Yes No DSL Yes Yes Yes No Yes Yes Two year No Mailed check 80.85 NaN No 1082 4367-NUYAO Male 0 Yes Yes 0 Yes Yes No No internet service No internet service No internet service No internet service No internet service No internet service Two year No Mailed check 25.75 NaN No 1340 1371-DWPAZ Female 0 Yes Yes 0 No No phone service DSL Yes Yes Yes Yes Yes No Two year No Credit card (automatic) 56.05 NaN No 3331 7644-OMVMY Male 0 Yes Yes 0 Yes No No No internet service No internet service No internet service No internet service No internet service No internet service Two year No Mailed check 19.85 NaN No 3826 3213-VVOLG Male 0 Yes Yes 0 Yes Yes No No internet service No internet service No internet service No internet service No internet service No internet service Two year No Mailed check 25.35 NaN No 4380 2520-SGTTA Female 0 Yes Yes 0 Yes No No No internet service No internet service No internet service No internet service No internet service No internet service Two year No Mailed check 20.00 NaN No 5218 2923-ARZLG Male 0 Yes Yes 0 Yes No No No internet service No internet service No internet service No internet service No internet service No internet service One year Yes Mailed check 19.70 NaN No 6670 4075-WKNIU Female 0 Yes Yes 0 Yes Yes DSL No Yes Yes Yes Yes No Two year No Mailed check 73.35 NaN No 6754 2775-SEFEE Male 0 No Yes 0 Yes Yes DSL Yes Yes No Yes No No Two year Yes Bank transfer (automatic) 61.90 NaN No
我们发现,这11条数据的入网时间都是0。
示例代码:
1 print((t['TotalCharges' ] == 0 ).sum())
运行结果:
在本文,我们把将这11条记录的缺失值记录为0,以表示在最后一个月统计消费金额前,这些用户的过去总消费金额为0。
1 2 3 t['TotalCharges' ] = t['TotalCharges' ].fillna(0 ) print(t['TotalCharges' ].isnull().sum()) print(t['TotalCharges' ].describe())
运行结果:
1 2 3 4 5 6 7 8 9 0 count 7043.000000 mean 2279.734304 std 2266.794470 min 0.000000 25% 398.550000 50% 1394.550000 75% 3786.600000 max 8684.800000
异常值处理
离散变量的检测
对于离散型变量的异常值检测,很简单,因为其取值有限,通常有一个枚举值表,比如月份字段,这是一个离散型变量,只有1到12是正常值,其他都是异常值。
我们主要需要把离散变量的每一个取值都找出来。
unique()
在上文的"重复值处理"部分我们讨论了nunique(),这里是unique(),两者的名称上是不一致的,前者多了一个字母n。
unique(),以数组形式(np.ndarray)返回列的所有不同值,只在Series上有,DataFrame上没有。返回的是array。
以数组形式(np.ndarray)返回列的所有不同值,示例代码:
1 2 3 4 5 import pandas as pddf = pd.DataFrame({'A' : [0 , 1 , 1 ], 'B' : [0 , 5 , 6 ]}) print(df['A' ]) print(df['A' ].unique())
运行结果:
1 2 3 4 5 0 0 1 1 2 1 Name: A, dtype: int64 [0 1]
DataFrame上没有,示例代码:
1 2 3 4 import pandas as pddf = pd.DataFrame({'A' : [0 , 1 , 1 ], 'B' : [0 , 5 , 6 ]}) print(df.unique())
运行结果:
1 AttributeError: 'DataFrame' object has no attribute 'unique'
np.unique()
有些资料说,unique()可以统计list中的不同值。unique()指的是pandas中的unique(),而可以统计list中的不同值的unique()位于numpy中。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import numpy as npa = [1 , 5 , 4 , 2 , 3 , 3 , 5 ] print(np.unique(a)) print(np.unique(a, return_index=True )) print(np.unique(a, return_inverse=True )) print(np.unique(a, return_counts=True ))
连续变量的检测
对于连续型变量的异常值检测。有两种方法:
三倍标准差
箱线图
三倍标准差
所谓的三倍标准差法,即:
下界:均值 − 3 倍标注差 \text{均值} - 3 \text{倍标注差} 均值 − 3 倍标注差
上界:均值 + 3 倍标注差 \text{均值} + 3 \text{倍标注差} 均值 + 3 倍标注差
超出界限的为异常点。
示例代码:
1 2 3 4 5 6 7 8 9 max = t['MonthlyCharges' ].mean() + 3 * t['MonthlyCharges' ].std() min = t['MonthlyCharges' ].mean() - 3 * t['MonthlyCharges' ].std() print((t['MonthlyCharges' ] <= min).sum()) print((t['MonthlyCharges' ] >= max).sum()) max = t['TotalCharges' ].mean() + 3 * t['TotalCharges' ].std() min = t['TotalCharges' ].mean() - 3 * t['TotalCharges' ].std() print((t['TotalCharges' ] <= min).sum()) print((t['TotalCharges' ] >= max).sum())
运行结果:
即,通过三倍标准差检测,数据集中不存在异常值点。
题外话,这个方法的英文名是"Three Sigma",这个名字让我想起了一家很知名的量化公司,“Two Sigma”。
类似的用这个方法判断异常值的,还有布林通道。
平均线周期 标准差水平(几倍标准差) 最常用的参数是20日移动平均线和两个标准差。
当股价波动降低,布林通道收紧时,暗示价格趋势正在形成;当价格波动性增加,布林通道变宽,可能暗示趋势的结束;一旦趋势走势形成,那么可以预测近期的潜在价格走势将在布林通道的上限和下限之间。
股价越接近布林通道的上线,市场越接近"超买";股价越接近下线,市场越接近"超卖"。价格超过上限意味着下跌的可能性更高,这可能是一个卖出信号;价格突破下限则相反。
箱线图
定义
箱线图主要利用四分位数来进行检测
上界:上四分位数 + 1.5 倍四分位距 \text{上四分位数} + 1.5 \text{倍四分位距} 上四分位数 + 1 . 5 倍四分位距
下界:下四分位数 + 1.5 倍四分位距 \text{下四分位数} + 1.5 \text{倍四分位距} 下四分位数 + 1 . 5 倍四分位距
超出界限的为异常点。
计算
那么,上四分位数、下四分位数和四分位距,怎么计算呢?
示例代码:
1 print(t['TotalCharges' ].describe())
运行结果:
1 2 3 4 5 6 7 8 9 count 7043.000000 mean 2279.734304 std 2266.794470 min 0.000000 25% 398.550000 50% 1394.550000 75% 3786.600000 max 8684.800000 Name: TotalCharges, dtype: float64
解释说明:
'75%':上四分位数'25%':下四分位数'75%'所对应的数字减去'25%'所对应的数字,即四分位距。
计算上界和下界,示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 q3 = t['MonthlyCharges' ].describe()['75%' ] q1 = t['MonthlyCharges' ].describe()['25%' ] iqr = q3 - q1 max = q3 + 1.5 * iqr print(max) min = q1 - 1.5 * iqr print(min)
运行结果:
1 2 171.375 -46.02499999999999
判断是否有异常值,示例代码:
1 2 print((t['MonthlyCharges' ] <= min).sum()) print((t['MonthlyCharges' ] >= max).sum())
运行结果:
对于DataFrame的describe(),返回每一个数值类型的列的统计数据。示例代码:
运行结果:
1 2 3 4 5 6 7 8 9 SeniorCitizen tenure MonthlyCharges TotalCharges count 7043.000000 7043.000000 7043.000000 7043.000000 mean 0.162147 32.371149 64.761692 2279.734304 std 0.368612 24.559481 30.090047 2266.794470 min 0.000000 0.000000 18.250000 0.000000 25% 0.000000 9.000000 35.500000 398.550000 50% 0.000000 29.000000 70.350000 1394.550000 75% 0.000000 55.000000 89.850000 3786.600000 max 1.000000 72.000000 118.750000 8684.800000
绘制箱线图
示例代码:
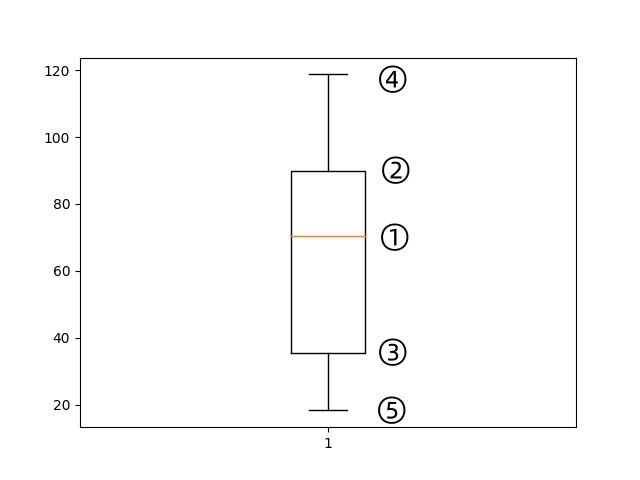
1 2 3 4 import matplotlib.pyplot as pltplt.boxplot(t['MonthlyCharges' ]) plt.show()
解释说明:
①:中位数
②:75%
③:25%
④:max
⑤:min
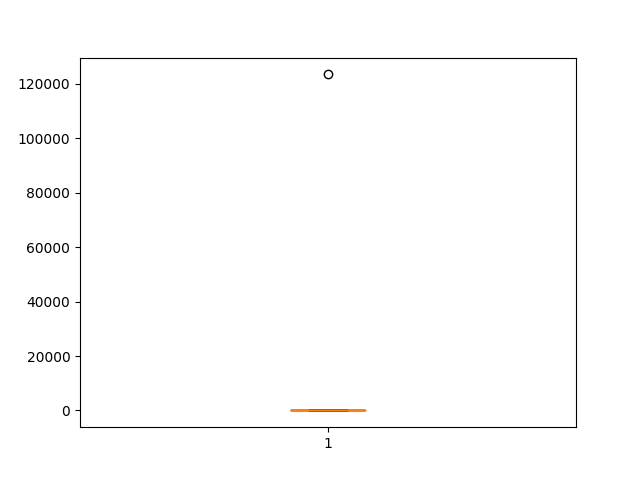
特别的,我们可以看看有异常的情况。
示例代码:
1 2 3 4 5 t = pd.concat([t['MonthlyCharges' ], pd.Series([123456 ])]) plt.boxplot(t) plt.savefig('1.png' ) plt.show()
题外话
箱线图,从外观上看,和K线比较相似,但其实完全不同。
方法的选择
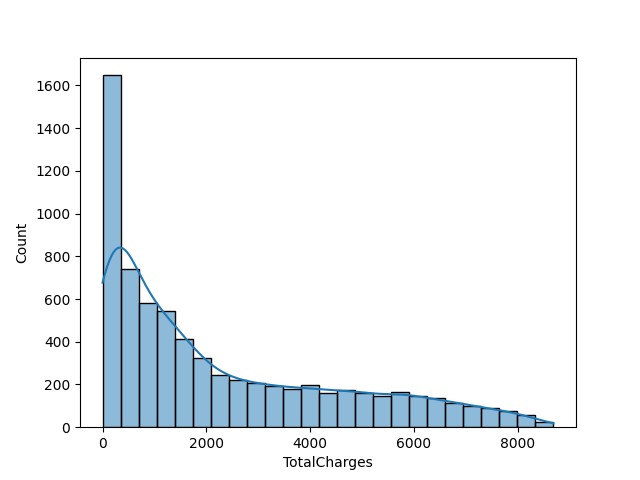
如果数据偏态很严重,箱线图的识别结果可能会更可靠一些。
数据分布越倾向于正态分布,则通过三倍标准差或者箱线图检测的异常值会更加准确一些。
我们可以直接通过绘图的方式,看看数据是正态的还是偏态的。示例代码:
1 2 3 4 import seaborn as snssns.histplot(t['TotalCharges' ], kde=True ) plt.show()
异常值修改
对于离散变量,取众数。
对于连续变量,采用盖帽法,即上界代替特别大的值,下界代替特别小的值。
但是,需要注意,异常值可能是某类特殊用户的标识,异常值可能是数据收集期间的错误;所以,有时候,我们需要围绕异常值进行分析,而不是简单的对其进行修改。
时间字段处理
本案例丢失了信息
注意,tenure(用户入网时间)这个字段。
示例代码:
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 0 1 1 34 2 2 3 45 4 2 .. 7038 24 7039 72 7040 11 7041 4 7042 66 Name: tenure, Length: 7043, dtype: int64
我们看到,原本应该是时间的,却是数字。tenure=0表示开始统计的第一个月、即2014年1月,而tenure=72则表示结束统计的最后一个月,即2020年1月。
这么做,会丢失信息。
丢失了时间的前后和间隔信息
丢失了季节信息
丢失了节日等特殊日期信息
当然,如果我们能确定是用tenure=0表示开始统计的第一个月、即2014年1月,而tenure=72则表示结束统计的最后一个月,即2020年1月。
可以参考《特征工程-3.特征衍生 [2/2]》 的"时序特征衍生"的"有序数字"部分。
没有丢失情况的处理
时间字段的处理
如果我们想让模型更好的发现时间的前后和间隔信息关系,可以用类似"timestamp"的方法标注时间。
如果我们想让模型更好的发现季节规律,可以把时间特征进行拆分,例如拆分成年月日三个特征。
我们可以加特征表示节日等特殊日期信息。
实现方法
方法
作用
dt.year提取年
dt.month提取月
dt.day提取日
dt.hour提取小时
dt.minute提取分钟
dt.second提取秒
dt.quarter提取季度
dt.weekofyear提取年当中的周数
dt.dayofweek, dt.weekday提取周几
注意!dt.dayofweek,返回一个整数,范围为[ 0 , 6 ] [0,6] [ 0 , 6 ]
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 import pandas as pdlist_of_dates = ['2010-11-20' , '2010-01-02' , '2010-02-05' , '2010-03-10' , '2010-04-16' ] list_of_dates_2 = ['11/20/2020' , '01/02/2020' , '02/05/2020' , '03/10/2020' , '04/16/2020' ] employees = ['Hisila' , 'Shristi' , 'Zeppy' , 'Alina' , 'Jerry' ] df = pd.DataFrame({'JoinedDate' : pd.to_datetime(list_of_dates), 'JoinedDate2' : pd.to_datetime(list_of_dates_2)}, index=employees) print(df) df['Year' ] = df['JoinedDate' ].dt.year df['Month' ] = df['JoinedDate' ].dt.month df['Year2' ] = df['JoinedDate2' ].dt.year df['Month2' ] = df['JoinedDate2' ].dt.month print(df)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 JoinedDate JoinedDate2 Hisila 2010-11-20 2020-11-20 Shristi 2010-01-02 2020-01-02 Zeppy 2010-02-05 2020-02-05 Alina 2010-03-10 2020-03-10 Jerry 2010-04-16 2020-04-16 JoinedDate JoinedDate2 Year Month Year2 Month2 Hisila 2010-11-20 2020-11-20 2010 11 2020 11 Shristi 2010-01-02 2020-01-02 2010 1 2020 1 Zeppy 2010-02-05 2020-02-05 2010 2 2020 2 Alina 2010-03-10 2020-03-10 2010 3 2020 3 Jerry 2010-04-16 2020-04-16 2010 4 2020 4
解释说明:pd.to_datetime,对于数据不是Datetime类型,需要先将其转换为Datetime。
关于pd.to_datetime,在《用Python分析数据的方法和技巧:3.pandas》 的"时间序列"的"Pandas中的时间"部分,有更多讨论。
strftime()
strftime()方法使用Datetime,将格式代码作为输入,并返回表示输出中指定的特定格式的字符串。
strftime()的格式格式代码有很多,%Y四位数的年份表示(000-9999),%m月份(01-12);其格式和SQL中的格式类似,可以参考《MySQL从入门到实践:2.DQL(SELECT)》 部分的"日期的格式化与解析"。
示例代码:
1 2 3 4 5 6 7 8 9 import pandas as pdlist_of_dates = ['2019-11-20' , '2020-01-02' , '2020-02-05' , '2020-03-10' , '2020-04-16' ] employees = ['Hisila' , 'Shristi' , 'Zeppy' , 'Alina' , 'Jerry' ] df = pd.DataFrame({'Joined date' : pd.to_datetime(list_of_dates)}, index=employees) print(df) df['year' ] = df['Joined date' ].dt.strftime('%Y' ) df['month' ] = df['Joined date' ].dt.strftime('%m' ) print(df)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 Joined date Hisila 2019-11-20 Shristi 2020-01-02 Zeppy 2020-02-05 Alina 2020-03-10 Jerry 2020-04-16 Joined date year month Hisila 2019-11-20 2019 11 Shristi 2020-01-02 2020 01 Zeppy 2020-02-05 2020 02 Alina 2020-03-10 2020 03 Jerry 2020-04-16 2020 04
示例代码:
1 2 3 4 5 6 7 8 9 import pandas as pdlist_of_dates = ['2019-11-20' , '2020-01-02' , '2020-02-05' , '2020-03-10' , '2020-04-16' ] employees = ['Hisila' , 'Shristi' , 'Zeppy' , 'Alina' , 'Jerry' ] df = pd.DataFrame({'Joined date' : pd.to_datetime(list_of_dates)}, index=employees) print(df) df['year' ] = pd.DatetimeIndex(df['Joined date' ]).year df['month' ] = pd.DatetimeIndex(df['Joined date' ]).month print(df)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 Joined date Hisila 2019-11-20 Shristi 2020-01-02 Zeppy 2020-02-05 Alina 2020-03-10 Jerry 2020-04-16 Joined date year month Hisila 2019-11-20 2019 11 Shristi 2020-01-02 2020 1 Zeppy 2020-02-05 2020 2 Alina 2020-03-10 2020 3 Jerry 2020-04-16 2020 4
解释说明:pandas.DatetimeIndex.month和pandas.DatetimeIndex.year提取年份和月份。
离散字段重编码
离散和连续的判断
关于一个字段,到底是离散的,还是连续的。我们需要结合业务进行判断。
在技术上,有一个小技巧。
在本文开头,我们从csv文件读取的时候,打印t.info(),其中的Dtype一列,有些是object,有些不是。从技术上判断的话,object就是离散型字段。
所以,从技术上,我们也可以通过如下的方法找出离散型字段。
1 t.select_dtypes('object' ).columns
注意,是从技术上,能结合业务最好。
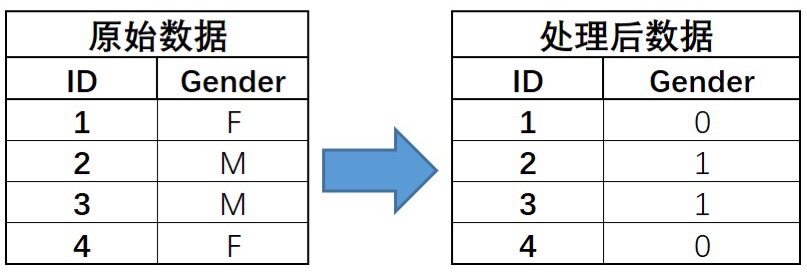
有序编码
编码规则
有序编码,也有资料称其为自然数排序。
需要注意的是,一般对于多分类(超过2),我们不会用有序编码。
例如:
OrdinalEncoder
我们利用pandas手动对离散字段进行有序编码,先找出某一列的所有离散字段,然后对其进行编号,之后就像我们把空格替换成np.nan一样,进行替换。
在这里,我们用sklearn中的OrdinalEncoder进行有序编码。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from sklearn import preprocessingimport numpy as nppreprocessing.OrdinalEncoder() x = np.array([['F' ], ['M' ], ['M' ], ['F' ]]) print(x) enc = preprocessing.OrdinalEncoder() enc.fit(x) x = enc.transform(x) print(x) print(enc.categories_)
运行结果:
1 2 3 4 5 6 7 8 9 [['F'] ['M'] ['M'] ['F']] [[0.] [1.] [1.] [0.]] [array(['F', 'M'], dtype='<U1')]
解释说明:
fit():从给定的数据中提取规律。enc.categories_,是映射关系,即0代表F,1代表M。
当我们训练好了一个转化器后,接下来我们就能使用该转化器进一步依照该规则对其他数据进行转化。示例代码:
1 2 x2 = np.array([['M' ], ['F' ]]) print(enc.transform(x2))
运行结果:
这样,我们可以在训练集上进行训练,然后可以直接用在测试集中。
两个思考
如果我们在训练集上做fit,在测试集上transform时出现了没有的标签,怎么办?
1 2 a = np.array([['A' ]]) enc.transform(a)
运行结果:
1 ValueError: Found unknown categories ['A'] in column 0 during transform
在实际工作中,如果发生了这种情况,说明"出大事了",说明我们的训练集和测试集的分布不均匀,这个会对模型的效果产生很大的影响。
为什么需要先fit,然后再对测试集进行transform?
因为在实际业务中,测试集的数据可能是之后来的。
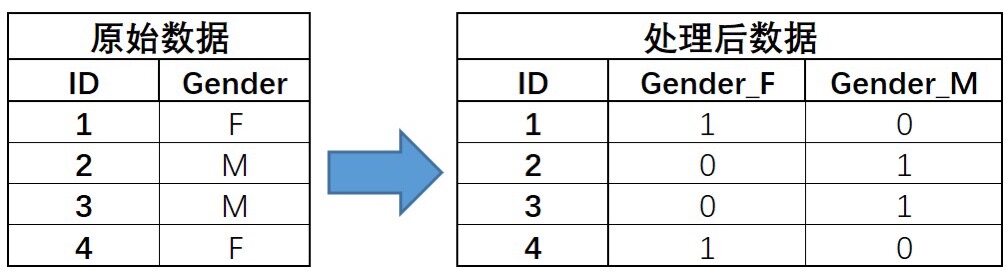
0-1编码
编码规则
0-1编码,也被称为独热编码。其编码过程如下:
需要注意的是,不是每一种模型下的离散字段,都需要进行0-1编码。对于逻辑回归需要,但是对于CatBoost,则明确要求不能对离散字段字段进行0-1编码。
OneHotEncoder
我们通过sklearn中OneHotEncoder进行0-1编码。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from sklearn import preprocessingimport numpy as nppreprocessing.OrdinalEncoder() x = np.array([['F' ], ['M' ], ['M' ], ['F' ]]) print(x) enc = preprocessing.OneHotEncoder() enc.fit(x) x = enc.transform(x) print(x) print(x.toarray())
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 [['F'] ['M'] ['M'] ['F']] (0, 0) 1.0 (1, 1) 1.0 (2, 1) 1.0 (3, 0) 1.0 [[1. 0.] [0. 1.] [0. 1.] [1. 0.]]
drop=‘if_binary’
对于0-1编码,我们需要注意的是,对于二分类离散字段来说,0-1编码往往是没有实际作用的。OneHotEncoder中drop参数调整为'if_binary',表示跳过二分类离散字段列,此时会自动利用有序编码。
示例代码:
1 2 3 4 5 6 7 8 9 from sklearn import preprocessingimport pandas as pdx = pd.DataFrame({'Gender' : ['F' , 'M' , 'M' , 'F' ], 'Income' : ['High' , 'Medium' , 'High' , 'Low' ]}) print(x) drop_enc = preprocessing.OneHotEncoder(drop='if_binary' ) x = drop_enc.fit_transform(x).toarray() print(x) print(drop_enc.categories_)
运行结果:
1 2 3 4 5 6 7 8 9 10 Gender Income 0 F High 1 M Medium 2 M High 3 F Low [[0. 1. 0. 0.] [1. 0. 0. 1.] [1. 1. 0. 0.] [0. 0. 1. 0.]] [array(['F', 'M'], dtype=object), array(['High', 'Low', 'Medium'], dtype=object)]
列名的处理
在上述的过程中,虽然进行了编码,但是每一列的含义,不容易知道。而在需要考察字段业务背景含义的场景中,我们需要知道每一列的实际名称。
处理方法
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from sklearn import preprocessingimport pandas as pdx = pd.DataFrame({'Gender' : ['F' , 'M' , 'M' , 'F' ], 'Income' : ['High' , 'Medium' , 'High' , 'Low' ]}) drop_enc = preprocessing.OneHotEncoder(drop='if_binary' ) cate_cols = x.columns.tolist() print(cate_cols) cate_cols_new = [] x = drop_enc.fit_transform(x).toarray() for i, j in enumerate(cate_cols): if len(drop_enc.categories_[i]) == 2 : cate_cols_new.append(j) else : for f in drop_enc.categories_[i]: feature_name = j + '_' + f cate_cols_new.append(feature_name) print(cate_cols_new) df = pd.DataFrame(x, columns=cate_cols_new) print(df)
运行结果:
1 2 3 4 5 6 7 ['Gender', 'Income'] ['Gender', 'Income_High', 'Income_Low', 'Income_Medium'] Gender Income_High Income_Low Income_Medium 0 0.0 1.0 0.0 0.0 1 1.0 0.0 0.0 1.0 2 1.0 1.0 0.0 0.0 3 0.0 0.0 1.0 0.0
cate_col_name
我们还可以吧上述方法抽象成一个函数,在本文进行应用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import numpy as npimport pandas as pdfrom sklearn import preprocessingpd.set_option('display.max_columns' , None ) pd.set_option('display.width' , 5000 ) t = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv' ) t['TotalCharges' ] = t['TotalCharges' ].apply(lambda x: x if x != ' ' else np.nan).astype(float) t['TotalCharges' ] = t['TotalCharges' ].fillna(0 ) def cate_col_name (transformer, category_cols, skip_binary: bool = False) : """ 离散字段One-Hot编码后,创建字段名 :param transformer: :param category_cols: :param skip_binary: 是否跳过二分类的字段 :return: """ cate_cols_new = [] col_value = transformer.categories_ for i, j in enumerate(category_cols): if skip_binary and (len(col_value[i]) == 2 ): cate_cols_new.append(j) else : for f in col_value[i]: feature_name = str(j) + '_' + str(f) cate_cols_new.append(feature_name) return cate_cols_new
示例代码:
1 2 3 4 5 6 7 8 enc = preprocessing.OneHotEncoder(drop='if_binary' ) category_cols = category_cols = ['gender' , 'SeniorCitizen' , 'Partner' , 'Dependents' , 'PhoneService' , 'MultipleLines' , 'InternetService' , 'OnlineSecurity' , 'OnlineBackup' , 'DeviceProtection' , 'TechSupport' , 'StreamingTV' , 'StreamingMovies' , 'Contract' , 'PaperlessBilling' , 'PaymentMethod' ] df_cate = t[category_cols] enc.fit(df_cate) df = pd.DataFrame(enc.transform(df_cate).toarray(), columns=cate_col_name(enc, category_cols), skip_binary=True ) print(df)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 gender SeniorCitizen Partner Dependents PhoneService MultipleLines_No MultipleLines_No phone service MultipleLines_Yes InternetService_DSL InternetService_Fiber optic InternetService_No OnlineSecurity_No OnlineSecurity_No internet service OnlineSecurity_Yes OnlineBackup_No OnlineBackup_No internet service OnlineBackup_Yes DeviceProtection_No DeviceProtection_No internet service DeviceProtection_Yes TechSupport_No TechSupport_No internet service TechSupport_Yes StreamingTV_No StreamingTV_No internet service StreamingTV_Yes StreamingMovies_No StreamingMovies_No internet service StreamingMovies_Yes Contract_Month-to-month Contract_One year Contract_Two year PaperlessBilling PaymentMethod_Bank transfer (automatic) PaymentMethod_Credit card (automatic) PaymentMethod_Electronic check PaymentMethod_Mailed check 0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 1 1.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 2 1.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 3 1.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 4 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 7038 1.0 0.0 1.0 1.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 1.0 7039 0.0 0.0 1.0 1.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 7040 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 7041 1.0 1.0 1.0 0.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 7042 1.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 1.0 0.0 0.0 0.0 [7043 rows x 37 columns]
有时候因为样本数的问题,不是二分类的变量,也会被错位的认为是二分类变量。所以skip_binary: bool = False,默认为False。
哑变量
在上文我们把离散变量MultipleLines,通过0-1编码,得到了三个变量MultipleLines_No、MultipleLines_No phone service和MultipleLines_Yes。
这三个变量,在统计学上被称为哑变量,Dummy Variable,也被称为虚拟变量、虚设变量或名义变量,通常取值为0或1,来反映某个变量的不同属性。
连续字段重编码
对连续变量而言,标准化和归一化,可以消除量纲影响并且加快梯度下降的迭代效率。
翻译上的歧义
该部分在名称翻译上存在歧义。
本文的 标准化 ,对应sklearn中的 StandardScalerZ-Score标准化 。
本文的 归一化 ,对应sklearn中的 MinMaxScaler0-1标准化 。
我个人观点,在"有些资料"中的"名称",确实比本文的要好,尤其是将MinMaxScaler翻译成0-1标准化,确实更好。
标准化(Z-Score标准化)
通过数学方法把原始数据映射到均值为0,方差为1的范围内。
x ′ = x − m e a n σ x' = \frac{x - mean}{\sigma}
x ′ = σ x − m e a n
其中
m e a n mean m e a n σ \sigma σ
示例代码:
1 2 3 4 5 import numpy as npfrom sklearn.preprocessing import StandardScalerscaler = StandardScaler() x = np.arange(15 ).reshape(5 , 3 )
进行数据分割,示例代码:
1 2 3 4 5 6 7 from sklearn.model_selection import train_test_splitx_train, x_test = train_test_split(x) print(x_train) print(x_test) scaler.fit(x_train)
运行结果:
1 2 3 4 5 [[3 4 5] [6 7 8] [0 1 2]] [[ 9 10 11] [12 13 14]]
查看训练数据各列的标准差,示例代码:
运行结果:
1 [2.44948974 2.44948974 2.44948974]
查看训练数据各列的均值,示例代码:
运行结果:
查看训练数据各列的方差,示例代码:
运行结果:
查看总共有效的训练数据条数,示例代码:
1 print(scaler.n_samples_seen_)
运行结果:
数据变换,示例代码:
1 2 x_train = scaler.transform(x_train) print(x_train)
运行结果:
1 2 3 [[ 0. 0. 0. ] [ 1.22474487 1.22474487 1.22474487] [-1.22474487 -1.22474487 -1.22474487]]
利用训练集的均值和方差对测试集进行标准化处理,示例代码:
1 2 x_test = scaler.transform(x_test) print(x_test)
运行结果:
1 2 [[2.44948974 2.44948974 2.44948974] [3.67423461 3.67423461 3.67423461]]
归一化(0-1标准化)
通过数学方法把原始数据映射到一定的区间之间,默认[0,1]。
x ′ = x − m i n m a x − m i n x' = \frac{x - min}{max - min}
x ′ = m a x − m i n x − m i n
x ′ ′ = x ′ ∗ ( m x − m i ) + m i x'' = x' * (mx - mi) + mi
x ′ ′ = x ′ ∗ ( m x − m i ) + m i
其中
m a x max m a x m i n min m i n m x mx m x m i mi m i
示例代码:
1 2 3 4 5 6 7 8 import numpy as npfrom sklearn.preprocessing import MinMaxScalerx = np.arange(15 ).reshape(5 , 3 ) print(x) scaler = MinMaxScaler() x = scaler.fit_transform(x)
运行结果:
1 2 3 4 5 6 7 8 9 10 [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11] [12 13 14]] [[0. 0. 0. ] [0.25 0.25 0.25] [0.5 0.5 0.5 ] [0.75 0.75 0.75] [1. 1. 1. ]]
查看每一列的最大值和最小值,即归一化的尺度标准。示例代码:
1 2 print(scaler.data_min_) print(scaler.data_max_)
运行结果:
1 2 [0. 1. 2.] [12. 13. 14.]
我们也可以指定范围,在构造方法MinMaxScaler()中传入参数feature_range,该参数的数据类型是元祖。示例代码:
1 2 3 scaler = MinMaxScaler(feature_range=(0 , 100 )) x = scaler.fit_transform(x) print(x)
运行结果:
1 2 3 4 5 [[ 0. 0. 0.] [ 25. 25. 25.] [ 50. 50. 50.] [ 75. 75. 75.] [100. 100. 100.]]
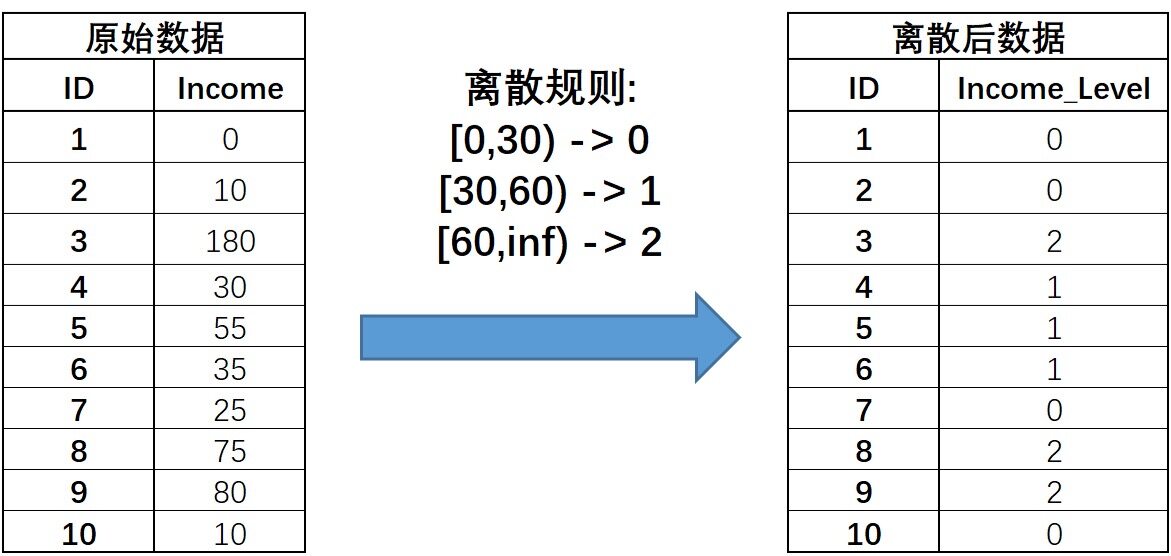
分箱(离散化)
分箱的作用
如图,是一个离散化的例子。
连续字段的离散化也可以理解为连续变量取值的重新编码过程。
为什么要这么做?本来用真实收入不是更好吗?现在用0、1和2来表示,还丢失了信息。
分箱的作用有:
能够消除特征量纲影响。
能够一定程度减少异常值的影响(例如Income取值为180的用户)。
对于线性模型来说,连续变量的分箱实际上相当于在线性方程中引入了非线性的因素。
需要注意的是,分箱过程会让连续字段损失一些信息,对于有些模型(例如树模型),分箱损失的信息,很可能会最终影响模型的效果。
根据业务进行分箱
在一些有明确业务背景的场景中,或许能够找到一些根据长期实践经验积累下来的业务指标来作为划分依据。
等宽分箱
分箱规则
先确定划分成几分,然后根据连续变量的取值范围划分对应数量的宽度相同的区间,并据此对连续变量进行分箱。
实现方法
我们利用sklearn中的KBinsDiscretizer进行等宽分箱,有三个关键参数:
n_bins参数位上输入需要分箱的个数。strategy参数位上输入等宽分箱、等频分箱还是聚类分箱
uniform:等宽分箱quantile:等频分箱KMeans:基于k-means的聚类分箱
encode参数位上输入分箱后的离散字段是否需要进一步进行0-1编码或者有序编码。
ordinal:有序编码onehot:0-1编码
示例代码:
1 2 3 4 5 6 7 8 import numpy as npfrom sklearn import preprocessingincome = np.array([0 , 10 , 180 , 30 , 55 , 35 , 25 , 75 , 80 , 10 ]).reshape(-1 , 1 ) print(income) dis = preprocessing.KBinsDiscretizer(n_bins=3 , encode='ordinal' , strategy='uniform' ) income = dis.fit_transform(income) print(income)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [[ 0] [ 10] [180] [ 30] [ 55] [ 35] [ 25] [ 75] [ 80] [ 10]] [[0.] [0.] [2.] [0.] [0.] [0.] [0.] [1.] [1.] [0.]]
解释说明:一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别,所以做了reshape(-1, 1)
在分箱结束后,可以通过bin_edges_查看分箱依据(箱体边界)。
示例代码:
运行结果:
1 [array([ 0., 60., 120., 180.])]
等频分箱
分箱规则
先确定划分成几分,然后选择能够让每一份包含样本数量相同的划分方式。
例子
示例代码:
1 2 3 4 5 dis = preprocessing.KBinsDiscretizer(n_bins=3 , encode='ordinal' , strategy='quantile' ) income = dis.fit_transform(income) print(income) print(dis.bin_edges_)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 [[0.] [0.] [2.] [1.] [1.] [1.] [0.] [2.] [2.] [0.]] [array([ 0., 25., 55., 180.])]
比较
通过分箱结果和分箱依据,我们发现:
等宽分箱容易受到异常值的影响
等频分箱容易完全忽略异常值信息,从而一定程度上导致特征信息损失
如果想兼顾变量原始数值分布,可以考虑使用聚类分箱。
聚类分箱
先对连续变量进行聚类(一般是k-means),然后用样本所属类别作为标记代替原始数值,从而完成分箱的过程。
在实际建模过程中,如无其他特殊要求,建议优先考虑聚类分箱。
我们利用KBinsDiscretizer进行聚类分箱,strategy='kmeans'。
(虽然聚类分箱,相对不容易受异常值的影响,如果直接对异常值进行处理,更好。)
(关于k-means聚类,可以参考《经典机器学习及其Python实现:14.k-means》 。)
有监督分箱
上述三种分箱方法,都属于无监督的分箱,在不考虑标签的情况下进行的分箱。
还有一种分箱方法,有监督分箱,即根据标签取值对连续变量进行分箱,典型代表就是决策树。
(关于决策树,可以参考我们在《集成学习概览及其Python实现:1.决策树》 的讨论。)
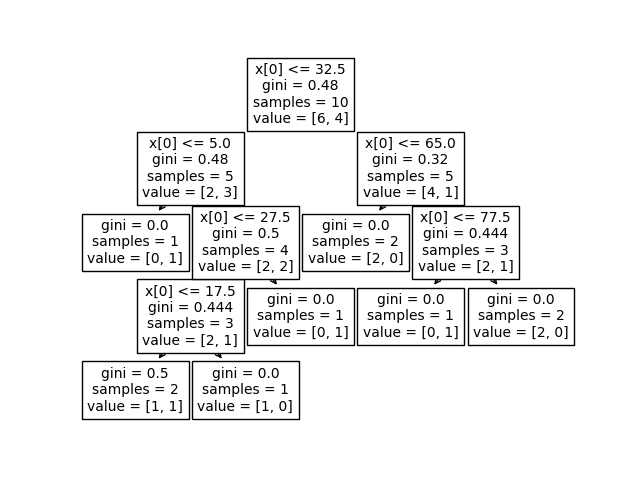
我们简单根据决策树的树桩(每一次划分数据集的切分点)来作为连续变量的切分依据,由于决策树的分叉过程总是会选择让整体不纯度降低最快的切分点,因此这些切分点就相当于是最大程度保留了有利于样本分类的信息。
1 2 3 4 5 6 7 8 9 10 import numpy as npfrom sklearn import treeimport matplotlib.pyplot as pltfrom sklearn.tree import DecisionTreeClassifierincome = np.array([0 , 10 , 180 , 30 , 55 , 35 , 25 , 75 , 80 , 10 ]).reshape(-1 , 1 ) y = np.array([1 , 1 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 ]) clf = DecisionTreeClassifier().fit(income, y) tree.plot_tree(clf) plt.show()
根据上述结果,如果需要对income进行三类分箱的话,则可以选择32.5和65作为切分点,对数据集进行切分。
这种基于决策树的有监督分箱有一个潜在问题,决策树容易过拟合。一个极端的例子,在训练数据集中,我们标签有0和1,然后在income这一列,恰好income=0的都对应标签0,income=1的都对应标签1,所以我们基于这种重编码方法构建出来的模型,在训练集上很可能是百分百准确。极端的例子,假如这是训练集中的噪音数据、是训练集和测试集划分不合理呢?那么,在训练集上的效果会非常不好。
这种根据标签对连续变量进行有监督的重编码的方式,属于"目标编码"。《特征工程-3.特征衍生 [2/2]》 进行讨论。
一个非常著名的模型,“GBDT+LR”,其实就是采用了一种非常特殊的方式对连续变量进行分箱。《集成学习概览及其Python实现:2.GBDT》 的最后一节"GBDT+LR"。)
对数转换
对数转换,即对连续型变量取对数,这样能让连续型变量一定程度恢复正态分布的分布特性,该方法有时会对部分线性模型起作用。
我们可以借助numpy中对数运算功能实现
注意,0 0 0 0 0 0 0 0 0
工作经验
对于离散变量,优先考虑One-Hot编码。
对于连续变量,优先考虑归一化。
在连续变量较多的情况下,可以考虑对连续变量进行分箱。
重编码后,不要马上用新的特征替换原始特征,暂时保留新的特征和旧的特征,在特征筛选环节,再进行选择。
ColumnTransformer,转换流水线。
作用
例如,现在有数据如下:
1 2 3 4 5 data = { 'age' : [10 , 15 , 12 , 45 , 36 ], 'gender' : ['男' , '女' , '男' , '男' , '女' ], 'major' : ['计算机' , '软件工程' , '物理' , '计算机' , '数学' ]} data = pd.DataFrame(data)
我们想先对gender字段进行有序编码,然后对major字段进行0-1编码,再对age字段进行分箱,最后还要对分箱后的age进行标准化。
那,我们需要写一段很长很长的代码了。
不用这么麻烦,有了ColumnTransformer,会很方便。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pdfrom sklearn.compose import ColumnTransformerfrom sklearn.preprocessing import OneHotEncoder, StandardScaler, KBinsDiscretizer, LabelEncoder, OrdinalEncoderdata = { 'age' : [10 , 15 , 12 , 45 , 36 ], 'gender' : ['男' , '女' , '男' , '男' , '女' ], 'major' : ['计算机' , '软件工程' , '物理' , '计算机' , '数学' ]} data = pd.DataFrame(data) ct = ColumnTransformer([ ('ordinal' , OrdinalEncoder(), ['gender' ]), ('onehot' , OneHotEncoder(sparse=False ), ['major' ]), ('discretizer' , KBinsDiscretizer(n_bins=3 ), ['age' ]), ('scale' , StandardScaler(), ['age' ]), ]) data = ct.fit_transform(data)
使用方法
构造方法,ColumnTransformer(),入参是一个list,list中的每一个元素是一个tuple,形式为(name, transformer, column_list)。
name:可以定义为任意的名字,自己看的明白就行,不影响特征构造。transformer:特征变换的方法,需要注意的是,这个方法必须支持fit和transform,所以pd.get_dummies构造onehot特征在这里是不能用的column_list:需要处理的特征列的列表
如果我们不想处理某些列,可以用passthrough,想删除哪些列可以用drop。示例代码:
1 2 3 4 5 6 7 8 ct = ColumnTransformer([ ('cate_feat' , OneHotEncoder(sparse=False ), ['gender' , 'major' ]), ...... ('pass' , 'passthrough' , ['gender' ,'major' ]), ...... ('drop' , 'drop' , ['age' ]) ]) ct.fit_transform(data)