PyTorch-TabNet
第一个问题?什么是TabNet?什么是tf-TabNet?什么是PyTorch-TabNet?
- TabNet是由谷歌发布的模型:
论文地址:https://arxiv.org/abs/1908.07442 - tf-TabNet是基于TensorFlow实现的TabNet。
Github:https://github.com/titu1994/tf-TabNet
安装:pip install tabnet
导包:import tabnet - PyTorch-TabNet是基于Pytorch实现的TabNet。
Github:https://github.com/dreamquark-ai/tabnet
官方文档:https://dreamquark-ai.github.io/tabnet/
安装:pip install pytorch-tabnet
导包:import pytorch_tabnet
PyTorch-TabNet更受欢迎,本文的讨论会基于PyTorch-TabNet。
入门案例
数据处理
我们以如下的数据为例
https://archive.ics.uci.edu/ml/machine-learning-databases/adult
这份数据是从美国1994年的人口普查数据库中提取的,其标签值是一个人的年收入是否会超过50K美元。
读取数据,示例代码:
1 | names=['age','workclass','fnlwgt','education','education-num','marital-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country','target'] |
运行结果:
1 | age workclass fnlwgt education education-num marital-status occupation relationship race sex capital-gain capital-loss hours-per-week native-country target |
我们对特征进行分类,分为数值型(连续)和类别型(离散)。在《机器学习实战方法(Python):特征工程-1.特征预处理》的"离散字段重编码"的"离散和连续的判断"部分,我们讨论过一种从技术上的判断方法,根据每一列的Dtype。如果Dtype是object,认为是离散的;如果Dtype不是object,认为是连续的。
1 | types = df.dtypes |
数值型(连续),有:
1 | numeric_feats |
1 | ['age', |
类别型(离散),有:
1 | category_feats |
1 | ['workclass', |
我们去除category_feats中的'target','target'是标签列,不作为特征。示例代码:
1 | category_feats.remove('target') |
处理数值型特征
1 | for feat in numeric_feats: |
处理类别型特征
1 | for feat in category_feats: |
对类别型特征进行one-hot编码
1 | one_hot_data = pd.get_dummies(df[category_feats], prefix=category_feats) |
将one-hot编码的类别型特征和数值型特征合并
1 | X = pd.concat([one_hot_data, df[numeric_feats]], axis=1) |
对目标值进行编码
1 | y = (df["target"] == ">50K").astype(int).values |
1 | array([0, 0, 0, ..., 0, 0, 0]) |
将数据集划分为训练集和测试集
1 | from sklearn.model_selection import train_test_split |
训练模型
1 | from pytorch_tabnet.tab_model import TabNetClassifier |
运行结果:
1 | epoch 0 | loss: 0.00095 | train_accuracy: 1.0 | valid_accuracy: 1.0 | 0:00:02s |
max_epochs:最大迭代的Epochspatience:模型的效果持续patience轮的epoch没有提升,就提前停止。eval_metric,评估指标。
学习率调度
相关参数
学习率调度,和两个参数有关:
scheduler_fn:torch.optim.lr_scheduler类型的调度器都可以使用scheduler_params:调度器的参数,是一个字典
示例一
1 | scheduler_fn=torch.optim.lr_scheduler.ReduceLROnPlateau |
torch.optim.lr_scheduler.ReduceLROnPlateau,在指标不再改善时降低学习率。PyTorch-TabNet将使用配置的提前停止指标(最后一个eval_metric)来衡量是否需要更新调度器。
scheduler_params={"mode":'max', "factor":0.1, "patience":1}
mode:调度器更新所基于的指标,'max'表示指标的最大值,'min'则代表最小值。factor:学习率衰减因子,当观测指标不再改善时,学习率将通过此衰减因子降低。
在此示例中,factor为0.1,如果使用的初始学习率为0.01,则当出现学习率下降时,新学习率将为0.001(0.01*0.1)。patience:等待patience个epoch。
在此示例中,patience = 1意味着如果模型在一个epoch后的性能没有改善,则会降低学习率。
示例二
1 | scheduler_fn=torch.optim.lr_scheduler.CyclicLR |
torch.optim.lr_scheduler.CyclicLR,在训练过程中逐渐增加学习率,并在达到一定最大值后再逐步降低学习率,这样有助于网络更快地收敛到最优解,并提高泛化能力。这种训练方法被称为triangular训练。
该调度器需要在批次级别上进行更新,所以在scheduler_params中添加is_batch_level为True。
scheduler_params={"is_batch_level":True, "base_lr":1e-3, "max_lr":1e-2, "step_size_up":100}
is_batch_level:是否在每个batch上更新学习率。base_lr:学习率的最低值。max_lr:学习率的最高值。step_size_up:定义增加学习率的步长,即经过多少个迭代步后将学习率增加到最大值。
在此示例中,step_size_up=100意味着学习率将在经过100个epoch之后达到最大值。
损失函数
默认损失函数
分类问题的默认损失函数是torch.nn.functional.cross_entropy。
回归问题的默认损失函数是torch.nn.functional.mse_loss。
自定义损失函数
我们可以自定义损失函数。例如,定义一个带有类别权重的二分类损失函数。示例代码:
1 | import torch.nn.functional as F |
使用示例,示例代码:
1 | from pytorch_tabnet.tab_model import TabNetClassifier |
重点关注如下的这一行
1 | tabnet_model.loss_fn=WeightedBinaryCrossEntropy(torch.tensor([2.0])) |
这一行在定义模型时将自定义的损失函数传递给了loss_fn参数;权重张量torch.tensor([2.0]),确保了正例的权重是2,负例的权重是1。
评估模型
相关参数
在调用fit方法时,可以指定以下参数,对模型进行评估
eval_set:元组,(X_valid,y_valid)。eval_name:列表,用于为每个评估集合指定名称,默认为val_0和val_1。eval_metric:列表,用于定义评估指标。需要注意,这个列表中的最后一个元素将用于提前停止。
Pytorch-TabNet内置了一些评估指标- 二分类:
'auc'、'accuracy'、'balanced_accuracy'、'logloss' - 多分类:
'accuracy'、'balanced_accuracy'、'logloss' - 回归:
'mse'、'mae'、'rmse'、'rmsle'
- 二分类:
自定义评估指标
我们创建一个CustomMetric类,该类继承自Metric 类。我们定义了自己的评估指标函数__call__,并重写了__init__方法,以便定义我们自己的名称和最大化方式。
然后,我们将CustomMetric类作为一个评估指标添加到了eval_metric列表中。
例如要求正样本更重要。示例代码:
1 | from pytorch_tabnet.metrics import Metric |
使用方法。示例代码:
1 | from pytorch_tabnet.tab_model import TabNetClassifier |
提前停止
在训练过程中,提前停止非常依赖评估指标。
如果我们没有给出评估集合eval_set,将不会执行提前停止(patience参数会被忽略),并且使用的模型的权重参数将是最后一次迭代的权重参数。
如果我们设置的patience小于等于0,则会禁用提前停止。
那么,如果我们又不想提前停止,又不想使用的模型的权重参数将是最后一次迭代的权重参数。
一个小技巧,将patience设置为等于max_epochs,这样不会提前停止,而且会使用最佳迭代时的模型权重参数,而不是最后一次迭代的模型权重参数。
RMSLE
对于PyTorch-TabNet中的RMSLE,需要特别提一下。
RMSLE,Root Mean Squared Logarithmic Error,均方根对数误差。
RMSLE的特点:
- 预测值比真实值小的情况,RMSLE会偏大,即对于预测值较小这种情况惩罚较大。
适用于某些需要欠预测损失更大的场景,如预测共享单车需求。假如真实值为1000,若预测值为600,那么RMSE=0.4,RMSLE=0.510,假如真实值为1000,若预测值为1400,那么RMSE=0.4,RMSLE=0.336。即,预测值比真实值小这种情况的RMSLE比较大,即对于预测值较小这种情况惩罚较大。 - 如果预测的值的范围很大,RMSE会被一些大的值主导,这样即使你很多小的值预测准了,但是有一个非常大的值预测的不准确,RMSE就会很大。同理,如果另外一个比较差的算法对这一个大的值准确一些,但是很多小的值都有偏差,可能RMSE会比前一个小。
RMSLE,先计算log再计算RMSE,可以在一定程度上克服这个问题。
特别需要注意的是,在Pytorh-TabNet中,'rmsle'会自动将负标签裁剪为。
所以,我们需要将我们的预测值,进行如下操作
1 | np.clip(clf.predict(X_predict), a_min=0, a_max=None) |
模型持久化
持久化,这个是数据库中的术语,是指将数据从内存持久化到磁盘。
在本文,模型持久化,即模型的保存和加载,以及模型加载后的继续训练和预测。
保存
保存模型。示例代码:
1 | saving_path_name = "./tabnet_model_test_1" |
运行结果:
1 | Successfully saved model at ./tabnet_model_test_1.zip |
加载
加载模型。示例代码:
1 | loaded_clf = TabNetClassifier() |
继续训练
继续训练,即继续调用fit方法。示例代码:
1 | # 继续训练 |
做预测
做预测,即调用predict方法。示例代码:
1 | test_preds = tabnet_model.predict(X_test.values) |
特征重要性
TabNet其实属于神经网络和树模型的合体,一样可以打印特征重要性。示例代码:
1 | # 获取特征重要性得分 |
运行结果:
1 | race_ White: 0.15654364047440564 |
参数详解
模型参数
n_d,int,默认8。
决策预测层的宽度。更大的值为模型提供更大的容量,但有过度拟合的风险。
范围:。n_a,int,默认8。
每个掩码的注意力嵌入的宽度。
建议:n_d = n_a。n_steps,int,默认3。
体系结构中的步数。
范围:。gamma:float,默认1.3。
这是掩码中特征重用的系数,越接近1,不同层之间的掩码选择越不相关。
范围:。cat_idxs:int列表,默认[]。
分类特征索引列表。cat_dims:int列表,默认[]。
分类特征数量的模态列表(分类特征的唯一值数量)cat_emb_dim:int列表,默认1。
每个分类特征的嵌入大小列表。n_independent:int,默认2。
每个步骤中独立的门控线性单元层数。
范围:。n_shared:int,默认2。
每个步骤中共享的门控线性单元数。
范围:。epsilon:float,默认1e-15。
不建议修改。seed:int,默认0。
随机数种子。momentum:float,默认0.02。
批量归一化的动量。
范围:。clip_value:float,默认None
梯度裁剪。当梯度值大于clip_value时,会将其裁剪为clip_value;当梯度值小于-clip_value时,会将其裁剪为-clip_value。如果没有设置clip_value,则梯度不会被裁剪。
即,是用来处理梯度爆炸的,不能用其来处理梯度弥散。lambda_sparse:float,默认1e-3。
这是原始论文中提出的额外的稀疏性损失系数。这个系数越大,你的模型在特征选择方面就会更稀疏。根据你的问题的难度,减小这个值可能会有所帮助。optimizer_fn:优化器,默认torch.optim.Adam。optimizer_params:dict,默认{lr:2e-2}
optimizer_fn的参数。
建议,初始学习率为0.02,然后进行衰减。scheduler_fn:学习率调度器,默认None。scheduler_params:dict。
scheduler_fn的参数。model_name:str,默认'DreamQuarkTabNet'
用于在磁盘上保存模型的模型名称。verbose:int,默认1。
打印训练过程的详细程度,1代表打印每个epoch;0代表不打印。device_name:str,默认'auto'
'cpu':用CPU进行训练;'gpu':用GPU进行训练;'auto':自动检测GPU。mask_type:str,默认'sparsemax'
用于选择特征的掩码函数。
范围:'sparsemax'或'entmax'。n_shared_decoder:int,默认1。
解码器中共享的GLU块的数量,只对TabNetPretrainer有用。n_indep_decoder:int,默认1。
解码器中独立GLU块的数量,只对TabNetPretrainer有用。
训练参数
X_train:np.array
训练特征y_train:np.array
训练目标eval_set:元组列表
评估元组集合(X,y)的列表,最后一个用于提前停止。eval_name:str 列表
评估集名称列表。eval_metric:str 列表
评估指标列表,最后一个指标用于提前停止。max_epochs:int,默认200
训练的最大epoch数。patience:int,默认10
提前停止,最多等待patience个epoch。weights:int,dict。默认0。
仅用于TabNet分类器采样参数
如果为int:0,不进行采样;1,使用反类发生率进行自动采样。
如果为dict,键为类,值为每个类的权重。loss_fn:训练的损失函数。batch_size:int,默认1024。
每个批次的样例数,建议使用大批量。virtual_batch_size:int,默认128。
用于"Ghost Batch归一化"的小批量的大小。num_workers:int,默认0。
使用的torch.utils.data.Dataloader中的工作程序数。drop_last:bool,默认False。
在训练期间是否舍弃最后一个批次。
有时候因为最后一个批次不完整,不想将其加入训练,所以有考虑丢弃的情况。callbacks:回调函数列表。pretraining_ratio:float
仅用于TabNetPretrainer,对输入特征进行屏蔽的百分比。warm_start:bool,默认False。
为了匹配scikit-learn API,将其设置为False。它允许对同一模型进行两次拟合,并从热启动开始。
回归
上文我们讨论的例子,都是处理分类问题的例子。这里再列举一个处理回归问题。示例代码:
1 | import pandas as pd |
自监督
什么是自监督
自监督,是在进行模型训练之前,用自编码器对特征进行自编码。我个人认为,自编码器对模型进行自编码,其实类似一个特征衍生的过程,自监督是把特征衍生也加入到模型的训练中了。
例子
数据处理
示例代码:
1 | import pandas as pd |
训练自监督模型
示例代码:
1 | from pytorch_tabnet.pretraining import TabNetPretrainer |
使用自监督模型
from_unsupervised=unsupervised_model,示例代码:
1 | from pytorch_tabnet.tab_model import TabNetClassifier |
论文解读
TabNet原文参考:https://arxiv.org/abs/1908.07442
在这里,对论文进行一些解读。不完全按照论文的行文顺序。
对于非原论文的内容,均以如下的方式标出。
非原论文的内容
介绍
论文第一章"INTRODUCTION"部分,主要论述了:
- 背景
在处理表格型问题中,树模型常常比神经网络受欢迎的原因。 - 意义
在表格型数据上,研究深度神经网络是有价值的。 - 主要贡献
TabNet继承了树方法的优点(可解释性和稀疏特征选择),又继承了深度神经网络的优点(表征学习和端对端训练)。此外,TabNet的设计考虑了两个需求:高模型表现和可解释性。
背景
在处理表格型问题中,树模型常常比神经网络受欢迎,原因有:
- 带有超平面的决策流形(Decision Manifolds)适用于表格数据。
- 可解释性强。
- 训练快。
- 深度神经网络(DNN),最初就不是针对表格数据进行设计的。
传统的深度神经网络依赖于堆叠网络层,导致过多参数,缺乏归纳偏差(Inductive Bias),即缺乏学习符合某个规则模型的假设,使得深度神经网络难以在表格决策流形上找到最优解。
意义
在表格型数据上,研究深度神经网络是有价值的,因为:
- 能有效地将数据当做图像进行编码。
- 能减轻或消除特征工程。
- 树学习采用了全局统计值去选择分裂点,相比于深度神经网络学习整个数据来说,树的准确性没那么高。
- 端对端的模型允许表征学习,能应用在有价值的新应用场景中,包括: 迁移学习(Data-efficient Domain Adaption)、生成模型(Generative Modeling)和半监督学习(Semi-supervised Learning)。
主要贡献
TabNet继承了树方法的优点(可解释性和稀疏特征选择),又继承了深度神经网络的优点(表征学习和端对端训练)。此外,TabNet的设计考虑了两个需求:高模型表现和可解释性。
总的来说,论文的模型TabNet做出了以下贡献:
- TabNet模型输入只需要原始表格特征,不需要任何特征预处理。
与此相对的是,树模型,通常需要实现进行特征衍生。 - TabNet在每各决策步上,采用序列关注(Sequential Attention)去选择哪些特征用于推理。特征选择是instance-wise的,即根据不同样本选择不同特征。
- TabNet在分类和回归问题上超过或比肩于其他表格学习模型。
TabNet模型有两个可解释性:局部和全局。局部是指可视化了输入特征的重要性和它们怎么合并,全局是指量化了每个输入特征对于训练模型的参与度。 - TabNet使用无监督预训练去预测掩码特征(Masked Features),训练得到的Encoder可以再用于有监督的分类和回归,能获得明显提升。
在实践中发现,TabNet不一定会比LightGBM等模型的模型效果好,但是训练时间长,训练需要更多的资源,却是不争的事实。
或许,TabNet的更多应用场景是在Kaggle等比赛中,做模型融合用。
整体思路
论文首先回顾了一下树模型的决策过程。
有两个特征和,并假设根据阈值和(分裂指标)进行样本划分,这样特征之间的阈值交互所构成的样本划分方法被看作决策过程。
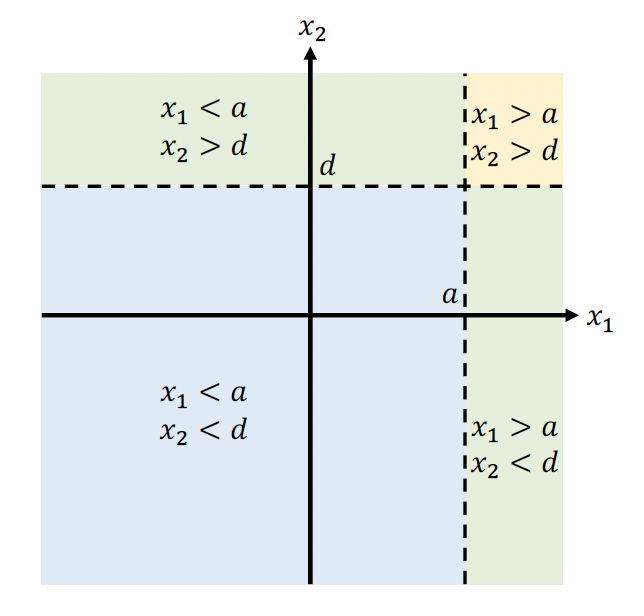
TabNet要模拟决策决策,就需要两个问题:特征挑选和条件判断。
然后,论文为了方便阐述其设计思想,提供的一个简化的结构示意图。
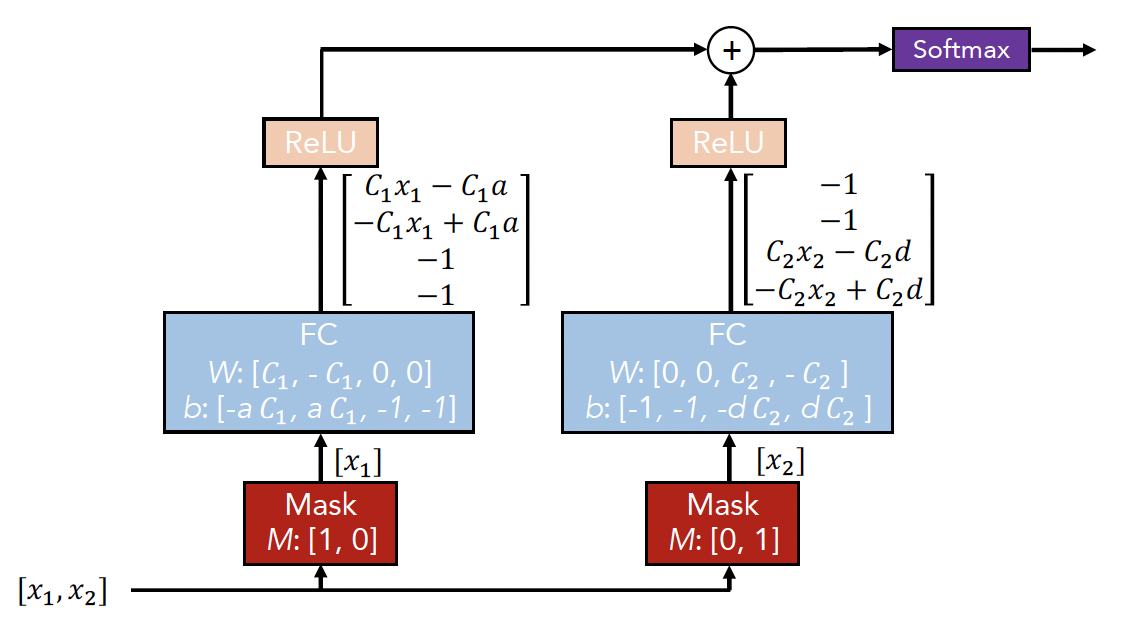
TabNet的特征挑选由Mask来负责,假设输入某个样本,它的特征有和,和会分别挑选把和特征出来。全链接(FC)和ReLU是为了确定条件判断,如果将全连接(FC)和ReLU记作,则两个分支出来的结果分别是和,然后会将两个结果相加,结果是,对应到树的决策过程,便是。然后再通过Softmax后,会得到四个条件判断对应的权重。
以图中的模型为例,对于输出向量,第1维就代表如果第一个条件成立的话,它对于最终决策的影响占权重,第3维就代表第三个条件成立占0.2权重。
但是,在决策树中,我们知道,如果某个条件成立的话,那么它的权重就是;对于决策树的加性模型,如果两个基本树的权重一样,若条件和成立,那么输出的向量就应该是。
因此,TabNet其实是一个"软"版本的决策树加性模型。
详细介绍
完整结构
上文论述了怎么进行特征挑选,根据Mask进行特征挑选。也论述了怎么进行条件判断,通过神经网络的前向计算,进行相加,再经过Softmax。
但,还有事情没说清楚,Mask怎么来的?"树"应该怎么生长?
完整的TabNet结构如下:
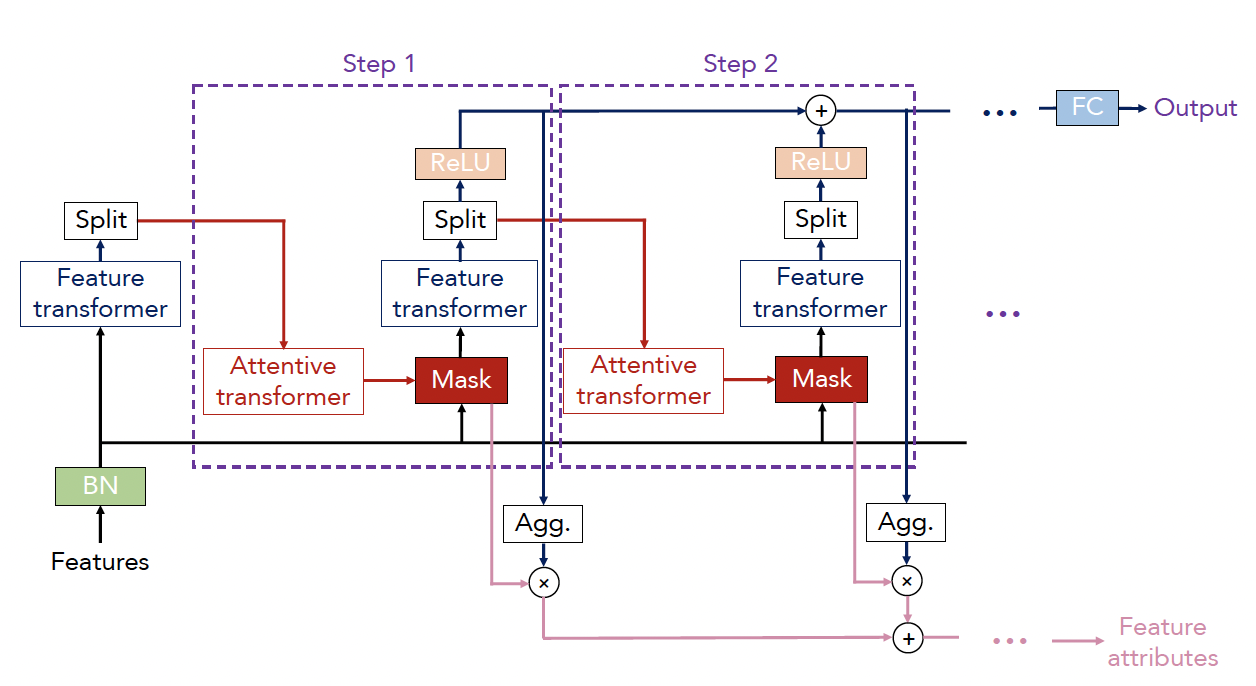
对于每轮决策,传入相同维度的特征,是batch size。
TabNet的编码是基于序列化多步处理,一共有轮决策,第轮决策的输入是来自第轮的信息去决定哪个特征被用,然后输出处理好的特征表征集成进总体决策里。
这一段,简单论述了一下"树"的生长过程,一共有轮决策,第轮决策的输入是来自第轮的信息去决定哪个特征被用。
但,还是不够详细。
Attentive Transformer
Attentive Transformer,用于做特征选择,决定哪个特征会被用。
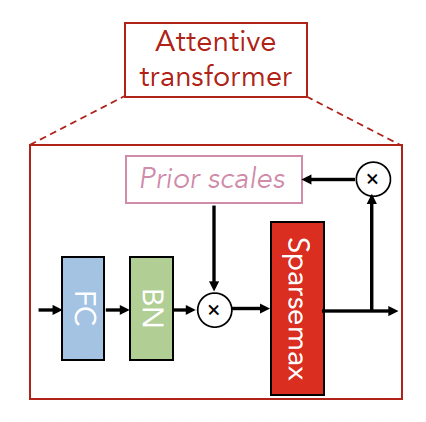
为了"软"选择重要特征,论文采用一个可学习的Mask,。
通过对重要特征的稀疏选择,每轮决策下的学习不再浪费在无关特征上,因此模型变得更有效率。
掩码是以乘法来做的:。
作者使用了一个关注转换器(Attentive Transformer)来获取Masks,它使用了来自历史决策下已处理好的特征:
Sparsemax Normalization,可以认为是Softmax的修改版。Softmax不会为0(除非原始值为0),Sparsemax会为0。所以,通过Sparsemax,会使得结果更稀疏。
这样的好处在于完全消除相关性不大的输出的影响。
Sparsemax在这扮演的决策就是让Mask稀疏化,使得特征挑选也变得稀疏化。
如图,是Sparsemax和Softmax的对比。
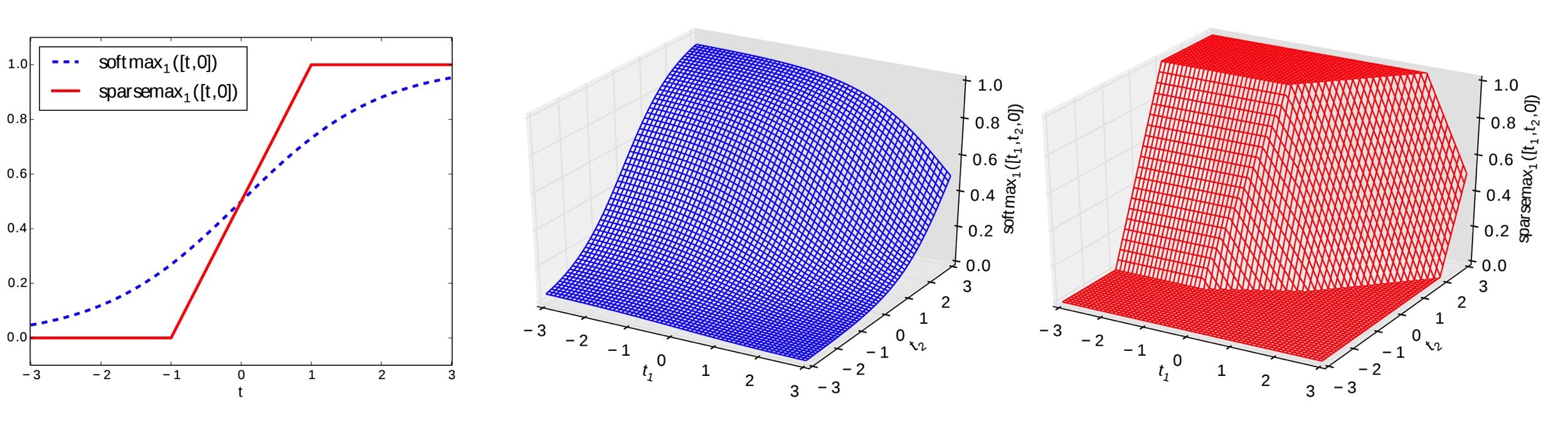
需要注意的是,即Batch下的每个样本都有一个(特征注意力权重分配Mask),因此Attentive Transformer是instance-wise。
是一个可训练的函数,这个可训练的函数就是Attentive Transformer结构中的FC+BN。
是先验尺度项,Prior Scale Term,用于告知模型某个特征在历史训练里被使用的程度。
其中是松弛参数,当时,一个特征只允许被使用一次。增加,一个特征可在多个决策轮数下被灵活使用。
在初始时刻,是为,即对掩码特征没有任何先验。
Feature Transformer
Feature Transformer,负责特征处理。
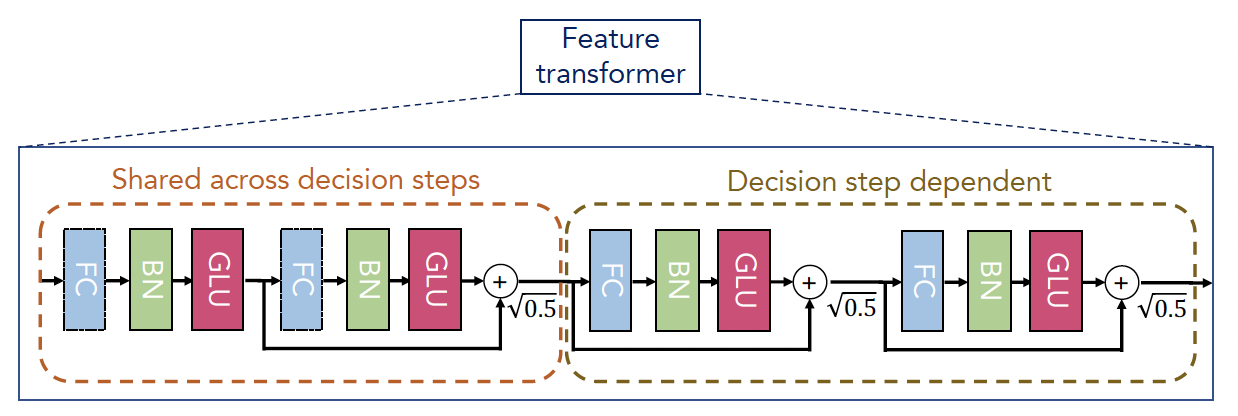
TabNet使用Feature Transformer处理已过滤的特征,然后拆分给总决策输出和下一步决策,即
其中拆分给总决策输出的是
拆分给下一步Attentive Transformer输入的是。
为了参数有效性和高性能的鲁棒性学习,Feature Transformer融合了两层:特征共享层(Shared across decision steps, 在所有轮决策中共享参数)和特征独立层(Decision step dependent, 非参数共享),前者计算特征共性,后者计算特征特性。
其中FC、BN和GLU(gated linear unit),组成一个Feature Block。
GLU的主要功能是允许隐藏单元更深入地传播到模型中并防止梯度爆炸或消失。
我们看到,作者还做了一个操作,定义了一个分支,直接参与到最后的加号合成。
这个操作,在《7.经典卷积神经网络》的GoogLeNet等模型中也出现过。
自监督的TabNet
最后还有一个话题,自监督的TabNet,联系特征衍生,就很好理解论文的设计了。
做特征衍生,不可能每一个衍生,都拿所有的特征,肯定是用部分特征进行衍生。
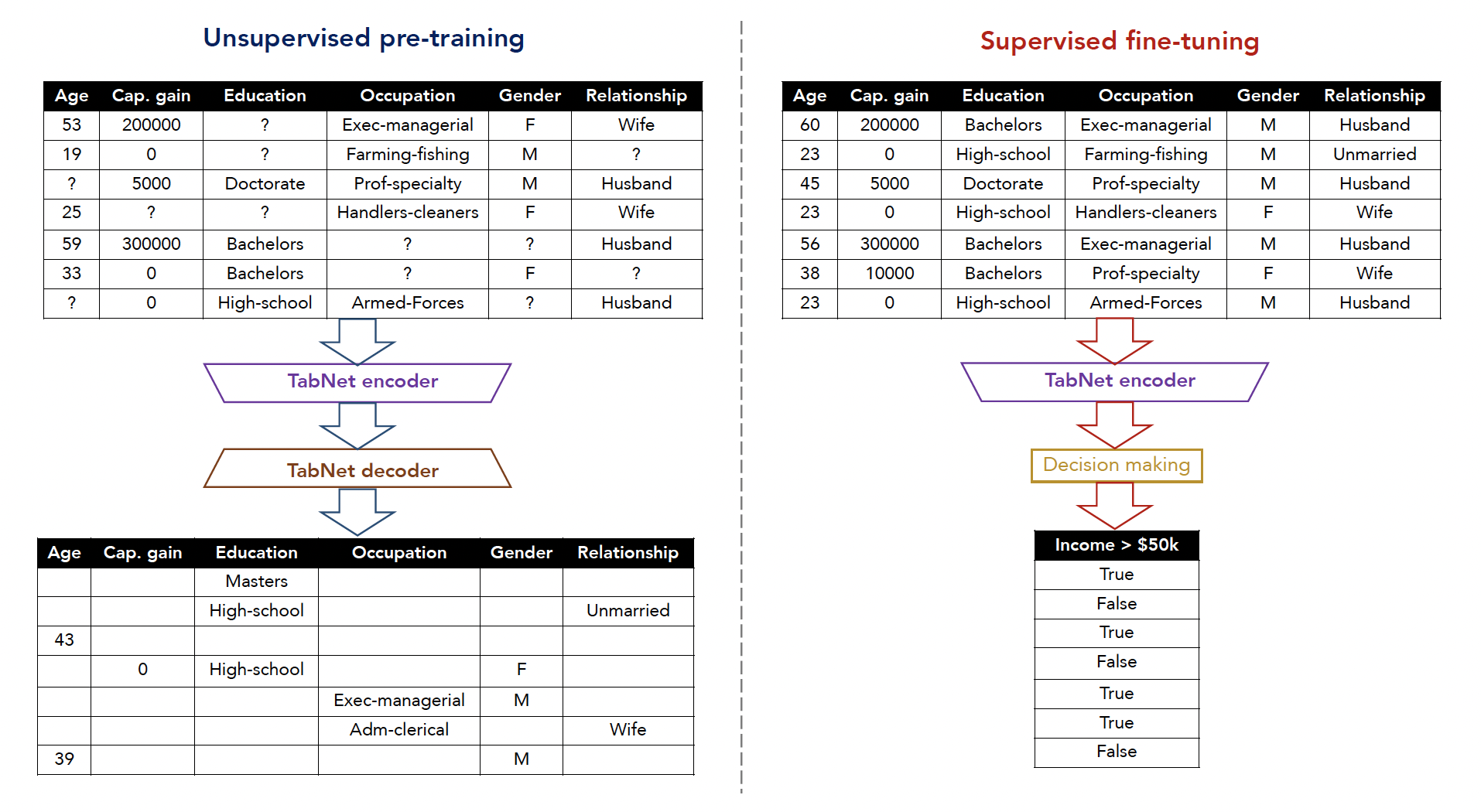
首先,表格数据会通过一个Binary Mask,得到缺失特征的表格数据,然后构建TabNet Encoder和Decoder。
参考资料:
https://github.com/dreamquark-ai/tabnet
https://github.com/dreamquark-ai/tabnet/blob/develop/customizing_example.ipynb
https://blog.csdn.net/qq_24671941/article/details/95868747
https://github.com/dreamquark-ai/tabnet/blob/develop/pretraining_example.ipynb
https://mp.weixin.qq.com/s/3AxbASjkWNqQZq3Gl-SCTQ