层级结构
分层
MySQL的层级如图所示:
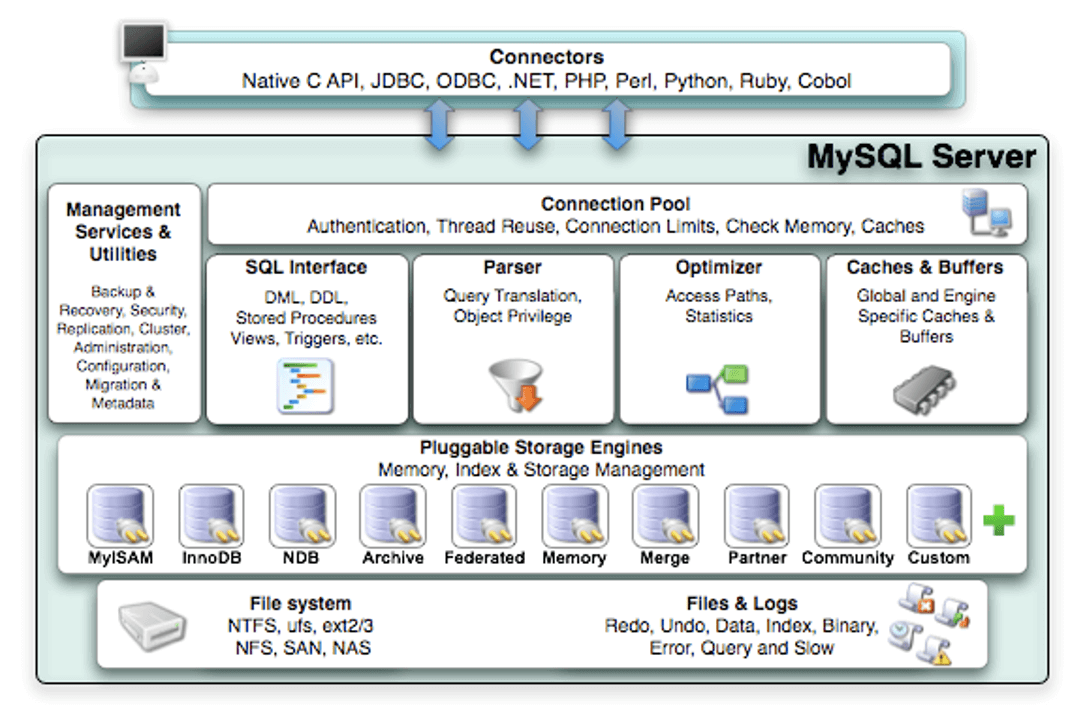
最外层的是Connectors,是各种连接MySQL的"客户端"。
在MySQL Server,又可以分为三层:
- 连接层,即
Connection Pool。 - 服务层,由
SQL Interface、Parser、Optimizer和Caches & Buffers组成。 - 引擎层,即
Pluggable Storage Engines。
在8版本中,已经没有Caches & Buffers了。
连接层
连接层Connection Pool会对客户端传输过来的账号密码进行身份认证、权限获取。
如果认证不通过,会拒绝连接;如果认证通过,会从权限表中查找该主机的该账号所拥有的权限,并与连接进行关联,之后的权限判断,都将依赖于此时读到的权限。
为了提高效率,节约创建和销毁线程的开销,连接层创建了线程池(Connection Pool)。
服务层
服务层由SQL Interface、Parser、Optimizer和Caches & Buffers组成。
SQL Interface
SQL Interface,接口,用于接收SQL,返回结果。
那么,能接收哪些SQL呢?
如图,有DML(Data Manipulation Language)、DDL(Data Definition Language)、Stored Procedures(存储过程)等。
是不是少了一个很重要的,DQL?
在《1.概述和工具准备》,我们说有一些资料会把DQL合并到DML,上文的那张图就是。
Parser
Parser,解析器,主要操作有:
- 词法分析
我们写的SQL语句,是由许多的字符串和空格组成的,词法分析就是识别出其中的字符串分别是什么。比如,需要把t识别成表t,把id识别成列名id。 - 语法分析
根据词法分析的结果,判断是否符合MySQL的语法规则,如果不符合语法规则,会返回错误。 - 生成语法树
最后,会通过一个被称为"分析机"的工具,生成语法树。
例如,SQL如下:生成的语法树如下:1
2
3
4
5SELECT username, ismale
FROM userinfo
WHERE age > 20
AND level > 5
AND 1 = 1;

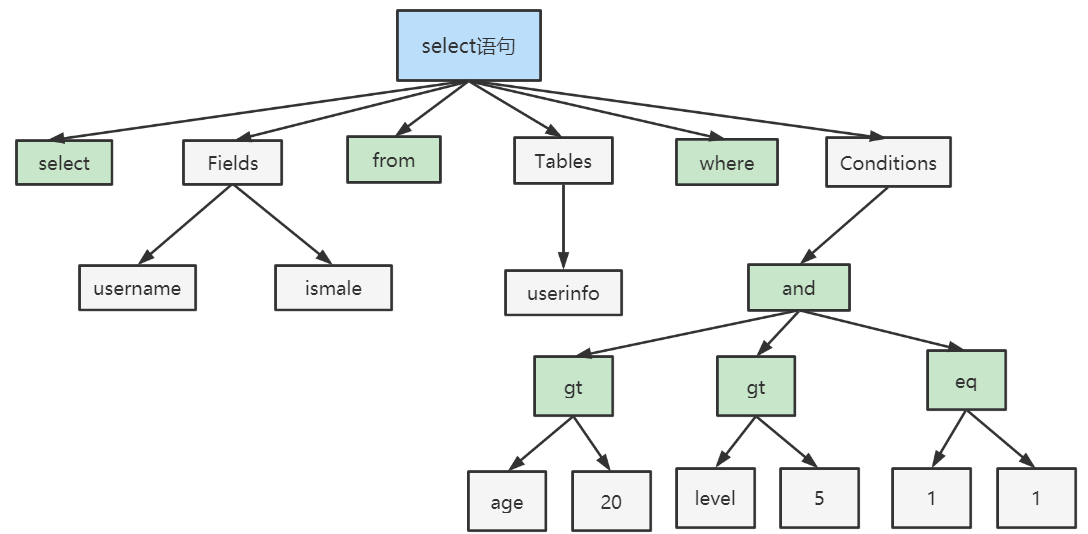
题外话,这个语法树的结构,像极了我们在《ElasticSearch实战入门(6.X):2.基本操作》,所讨论的ES语句的结构。
通过Parser,已经可以知道这个SQL要做什么了,那么就直接开干吧。
不,还要经过Optimizer,优化器。
Optimizer
为什么需要经过Optimizer,或者说,Optimizer是干啥的?
通过Parser,我们只是知道这个SQL要做什么了,但是却可能会有很多种的执行方式,最后都能得到结果,这时候需要选择一个最佳的方式,这就是Optimizer的工作。
举个例子,假设存在一个SQL如下:
1 | SELECT * |
对于这个SQL,我们有很多种方案:
- 先从
test1中取出name = '李华'的记录的id,再根据id关联到test2,再选取test2中name = '英语'的记录。 - 先从
test2中取出name = '英语'的记录的id,再根据id关联到test1,再选取test1中name = '李华'的记录。 - 先将
test1和test2通过id进行关联,然后再选取test1.name = '李华'且test2.name = '英语'的记录。 - 先选取
test1中name = '李华'的记录和test2中name = '英语'的记录,再将两者通过id进行关联。
这些都可以,那么怎么选择最佳的呢?通过Optimizer得到。
(关于Optimizer的更多内容,我们会在下一章《5.索引和优化》进行讨论。)
现在,我们已经得到执行计划了,那么,交给执行器去执行,具体就是各种的存储引擎,即引擎层。
引擎层,即Pluggable Storage Engines,插件式的存储引擎,负责数据的存储和提取。
Caches & Buffers
服务层的最后一个组件是Caches & Buffers,以Key-Value的方式缓存查询结果。
需要注意的是,这个组件在8版本中,已经被移除了,因为命中率极低。
原因有三:
- 如果两个查询,有任何字符上的不同,哪怕是多个或少了空格,大小写不一样等,都不会命中缓存。
比如,如下的两个查询,第二个只比第一个多了几个空格,但是不会命中。1
2
3
4# 第一个
SELECT * FROM t WHERE name = '张三'
# 第二个
SELECT * FROM t WHERE name = '张三' - 如果查询请求中包含某些系统函数(如
NOW())、某些系统表(如information_schema、performance_schema中的表)等,也不会利用缓存。 - 如果表被修改了,无论是表结构被修改了,还是表中的数据有变化,与该表相关的缓存都会被清除。
执行流程
执行流程图
通过上文的讨论,我们可以得到一个SQL的执行流程,如图:
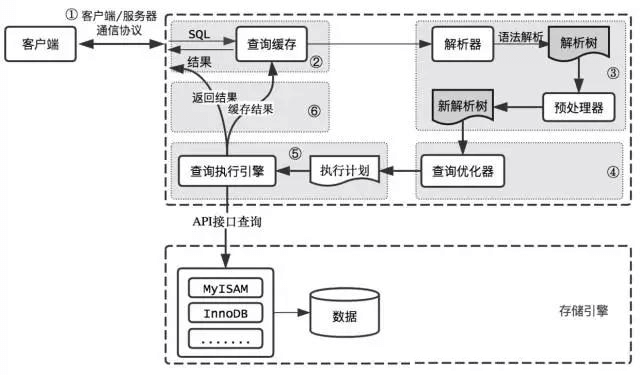
- 缓存已经在8版本中被移除了。
查看执行流程
那么,到底是不是上图所描绘的呢?
我们可以通过"profiling"看看。
检查profiling是否已经开启
两种方法:
select @@profilingshow variables like 'profiling'
示例代码:
1 | select @@profiling; |
运行结果:
1 | +-----------+ |
- 解释说明:
0,未开启;1,已开启。
示例代码:
1 | show variables like 'profiling'; |
运行结果:
1 | +-------------+-----+ |
开启profiling
示例代码:
1 | set profiling=1; |
- 注意,这个是session级别的。
开启完成后,我们执行几个SQL。
1 | select * from employees; |
查看最近几次的profiles
示例代码:
1 | show profiles; |
运行结果:
1 | +----------+------------+---------------------------------+ |
查看最近一次的profile
示例代码:
1 | show profile; |
运行结果:
1 | +--------------------------------+----------+ |
解释说明:
checking permissions:权限检查Opening tables:打开表System lock:系统锁optimizing:优化查询statistics:统计preparing:准备executing:执行
在5版本中,我们还会看到一个状态
checking query cache for query,检查缓存。
查看指定Query_ID的profile
示例代码:
1 | show profile for query 10; |
查看更多内容
示例代码:
1 | show profile cpu,block io for query 10; |
运行结果:
1 | +--------------------------------+----------+----------+------------+--------------+---------------+ |
存储引擎
概述
存储引擎,也被称为表处理器,因为其主要功能是对表中的数据进行提取和写入;也被称为表的类型,因为可以为每一张表指定存储引擎。
常见操作
查看存储引擎
通过SHOW ENGINES,我们可以查看存储引擎。
示例代码:
1 | SHOW ENGINES |
运行结果:
1 | +------------------+-------+--------------------------------------------------------------+------------+----+----------+ |
解释说明:
Engine:存储引擎名称。Support:MySQL是否支持该存储引擎,DEFAULT表示是默认的存储引擎。Comment:注释。Transactions:是否支持事务。XA:该存储引擎所支持的分布式是否符合XA规范,即是否支持分布式事务。Savepoints:该存储引擎是否支持事务处理的保存点,即是否支持部分事务回滚。
查看默认的存储引擎
通过上文的SHOW ENGINES,就可以查看默认的存储引擎,也有其他方法:
show variables like '%storage_engine%';SELECT @@default_storage_engine;
示例代码:
1 | show variables like '%storage_engine%'; |
运行结果:
1 | +-------------------------------+---------+ |
示例代码:
1 | SELECT @@default_storage_engine; |
运行结果:
1 | +------------------------+ |
修改默认的存储引擎
有两种方法:
SET DEFAULT_STORAGE_ENGINE=MyISAM;
这种方法是session级别的。- 修改
my.cnf:然后重启服务1
default-storage-engine=MyISAM
systemctl restart mysqld.service。
这种是持久的。
设置表的存储引擎
创建表时指定存储引擎
语法格式:
1 | CREATE TABLE 表名( |
示例代码:
1 | CREATE TABLE test_table( |
接下来,我们看看,在创建这张表后,服务器里都有啥。
通过show variables like 'datadir',查看数据文件目录。示例代码:
1 | show variables like 'datadir' |
运行结果:
1 | +-------------+---------------+ |
然后查看/var/lib/mysql/目录,并cd到相关的库。
1 | -rw-r----- 1 mysql mysql 1636 May 16 17:32 test_table_424.sdi |
修改表的存储引擎
语法格式:
1 | ALTER TABLE 表名 ENGINE = 存储引擎名称; |
示例代码:
1 | ALTER TABLE test_table ENGINE = InnoDB; |
然后,我们再看看/var/lib/mysql/中的内容。
1 | -rw-r----- 1 mysql mysql 114688 May 16 17:41 test_table.ibd |
文件也被修改了!
所以, 修改表的存储引擎,会非常消耗资源。
常见的存储引擎
接下来,我们讨论几种常见的存储引擎。
InnoDB和MyISAM
对于InnoDB和MyISAM,放在一起讨论会更好。
| InnoDB | MyISAM | |
|---|---|---|
| 是否默认 | 5.5及其之后默认 | 5.5之前默认 |
| 数据文件 | .ibd,用于存储数据和索引。 |
.MYD,用于存储数据;.MYI,用于存储索引。 |
| 事务 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 行表锁 | 行锁,操作时只锁某一行,不对其它行有影响。 | 表锁,即使操作一行记录也会锁住整个表。 |
| 缓冲池 | 不仅缓冲索引还缓冲了真实数据 | 只缓冲索引,不缓冲真实数据 |
- 在8版本之前的数据文件中,还有
.frm,用于存储表结构。 - 在《2.DQL(SELECT)》中,我们还讨论过,MyISAM,专门记录了表中的行数。
- 关于缓冲池,我们会在下文讨论索引的时候会讨论。
Merge
Merge是一组MyISAM表的组合,这些MyISAM表必须结构完全相同。Merge类型的表本身不存储数据,对Merge类型的表进行查询、更新、删除操作,实际上是对内部的MyISAM表进行的。
我们来看一个例子,首先创建order_2020、order_2021和order_all三张表。
示例代码:
1 | create table order_2020 |
注意:INSERT_METHOD为可以取三种值:FIRST,作用在第一张表;LAST:作用在最后一张表;NO:不允许插入,如果没有定义INSERT_METHOD,则不允许插入。
向order_2020和order_2021两张表中插入记录。
示例代码:
1 | insert into order_2020 |
分别查询三张表中的数据。
示例代码:
1 | select * |
运行结果:
1 | +--------+-----------+-------------+ |
示例代码:
1 | select * |
运行结果:
1 | +--------+-----------+-------------+ |
示例代码:
1 | select * |
运行结果:
1 | +--------+-----------+-------------+ |
往order_all中插入一条记录,由于INSERT_METHOD是LAST,所以会在最后一张表中插入。
示例代码:
1 | insert into order_all |
示例代码:
1 | select * |
运行结果:
1 | +--------+-----------+-------------+ |
示例代码:
1 | select * |
运行结果:
1 | +--------+-----------+-------------+ |
- 还可以对Merge表进行DROP操作,但是这个操作只是删除Merge表的定义,对内部的表是没有任何影响的。
- Merge表的优点在于可以突破对单个MyISAM表的大小限制,并且将不同的表分布在多个磁盘上。
Archive
Archive,顾名思义,用于数据存档。
其特点是:
- 仅支持插入和查询(在5.5之后支持索引),不支持删除和修改。
- 同样数据量下,Archive的表会更小。
根据英文的测试结论来看,Archive表比MyISAM表小75%,比支持事务处理的InnoDB表小83%。 - 数据文件的扩展名为
.ARZ。 - Archive适合数据归档,拥有很高的插入速度,但是对查询的支持较差。
CSV
CSV,其特点是数据文件是以CSV的格式存储的,不支持索引。
我们来看个例子。
示例代码:
1 | CREATE TABLE test_csv |
1 | INSERT INTO test_csv |
然后我们访问数据文件目录,会发现多了这三个文件。
1 | -rw-r----- 1 mysql mysql 2450 May 18 14:19 test_csv_426.sdi |
CSM,为相应的元文件,用于存储表的状态和表中存在的行数。
看看test_csv.CSV,都有哪些内容。
1 | cat test_csv.CSV |
运行结果:
1 | 1,"record one" |
Memory
概述
Memory采用的逻辑介质是 内存 ,所以响应速度很快,但是当mysqld守护进程崩溃的时候数据会丢失。
另外,要求存储的数据是数据长度不变的格式,比如,Blob和Text类型的数据不可用(长度不固定的)。
主要特征
- 支持哈希索引和B+树索引。
- 至少比MyISAM快一个数量级。
- 表的大小是受限制的。
表的大小主要取决于两个参数,分别是max_rows和max_heap_table_size。
其中,max_rows可以在创建表时指定,max_heap_table_size的大小默认为16MB,可以按需要进行扩大。 - 数据文件与表结构文件分开存储。
有些资料说是数据文件和索引文件分开存储,这个应该是有纰漏。应该是数据文件和表结构文件,Memory引擎的表的表结构,会以.sdi的形式保存在硬盘。
应用场景
数据量小,并且要求速度快。
索引结构
为什么使用索引
索引,是一种用于快速找到数据记录的数据结构。
举个例子,假如没有索引的话。

现在,我们要查询col2为3的数据,怎么办?
遍历,从第一条开始,检查其col2是否为3;如果不是的话,下一条;直到最后找到col2为3的。
假如有索引了,比如我们的索引是二叉树。
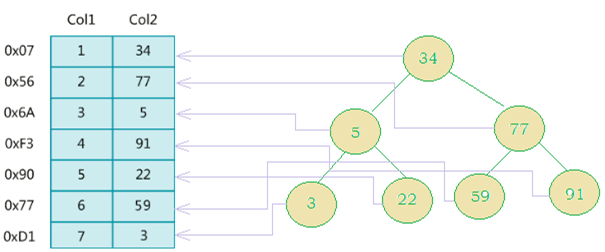
从根节点34出发,3比34小,所以从左边找;3比5小,再从左边找;最后,找到了二叉树的节点3,其指向的是col2为3的数据。
那么,这颗二叉树是怎么来的呢?
在存数据的时候构建的。比如:34、77、5等数据依次入库。先放34;77比34大,在右边;5比34小,在左边。如果期间还有数据被删除、或者修改的话,该二叉树同样需要更新。
更详细的过程,可以参考《算法入门经典(Java与Python描述):8.二叉树》中关于"二叉查找树"的讨论。
InnoDB中的B+树
页
首先,引入一个概念,页。
现在假如有一张表,比如,table_a,然后我们要从这张表中找出c = 'xxx'的数据。
1 | SELECT * FROM table_a WHERE c = 'xxx' |
根据我们上文的讨论,连接层校验用户名和密码、获取权限,然后经过SQL Interface,再经过Parser、Optimizer,最后来到了存储引擎。
如果c上没有任何索引,即需要全表扫描,那么,存储引擎会怎么做呢?
把整张table_a读到内存中?
那如果内存不够怎么办?
一个生活中常见的场景,我们用内存只有1G的手机或者电脑,可不可以打开文件大小超过1G的视频文件?
当然可以。
因为没有把整个视频文件读进内存中,每次只读一部分。
那么,现在一样的,不把整张表读进内存中,每次只读一部分。
这个一部分,就被称为 页 。
那么,如果我们UPDATE呢?比如
1 | UPDATE table_a SET c = 'hahaha' WHERE c = 'xxx' |
被更新的只是内存中的数据,磁盘中的数据没有更新啊。
MySQL会按照一定的规则,定时刷新磁盘的数据。
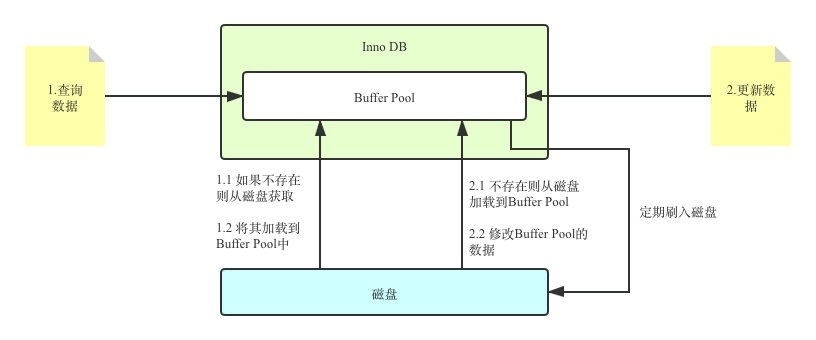
也正是因为这个,所以还有一个事务的概念,我们会在《6.事务》中,做更多的讨论。
推演
在一个数据页中查找
假设存在一张表如下:
1 | CREATE TABLE index_demo |
Compact,一种行格式,每一行的示意图如下:
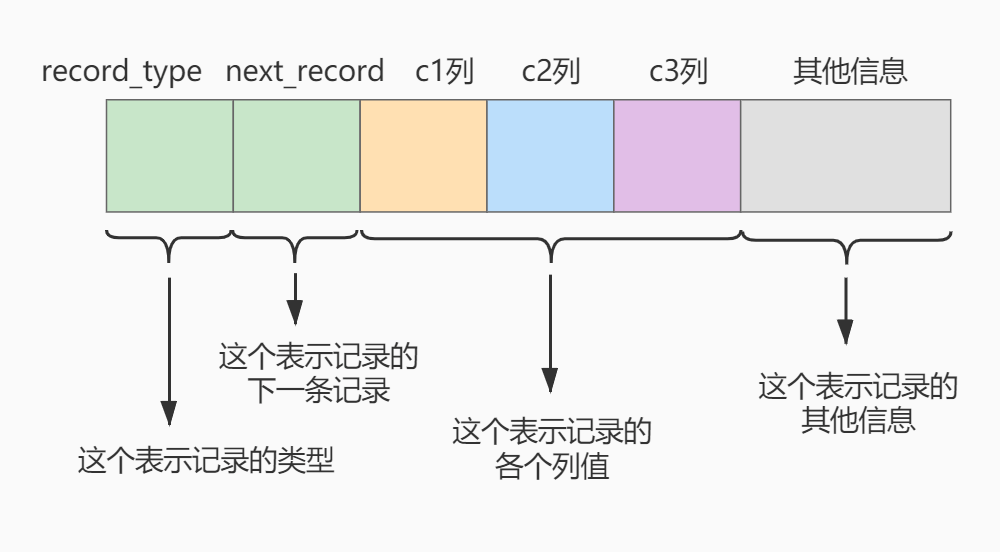
record_type:表示记录的类型,0表示普通记录、1表示目录项记录、2表示最小记录、3表示最大记录。
且,我们假设表的数据较少,例如,只有如下的数据:
1 | INSERT INTO index_demo |
所以,一页的内容,如下:
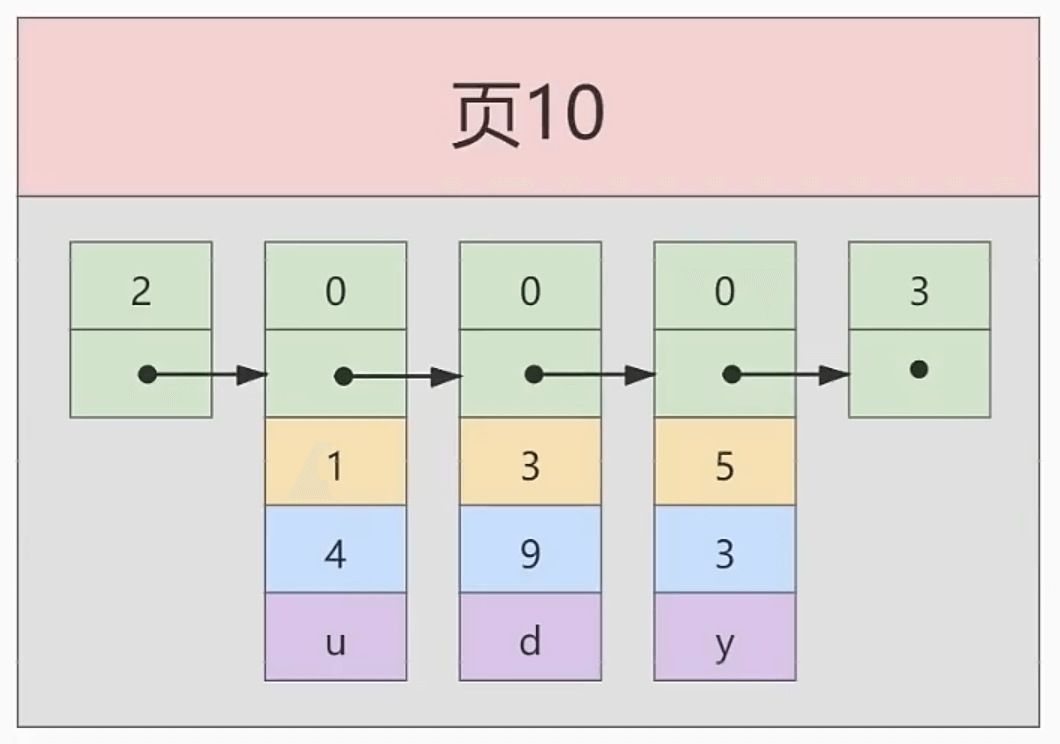
我们把这一页,称为数据页。
根据搜索条件的不同,搜索有两种情况:
- 以主键为搜索条件:二分法。
- 以其他列作为搜索条件:遍历。
在上文中,插入的数据,其主键是按照从小到大进行排序的。那么,如果是乱序的呢?乱序的话,那就需要调整,调整就需要耗费时间和资源,这也是为什么通常要求主键从小到大进行排序。
这也是为什么,对于InnoDB,主键尽量选择有序的ID。
在很多数据页中查找
那么,如果数据很多,比如,我们假设一个页只能塞3条数据,想再塞一条就需要新页,即页分裂。
比如,我们再插入一条数据。
1 | INSERT INTO index_demo |
那么,会是下图中的哪一种?
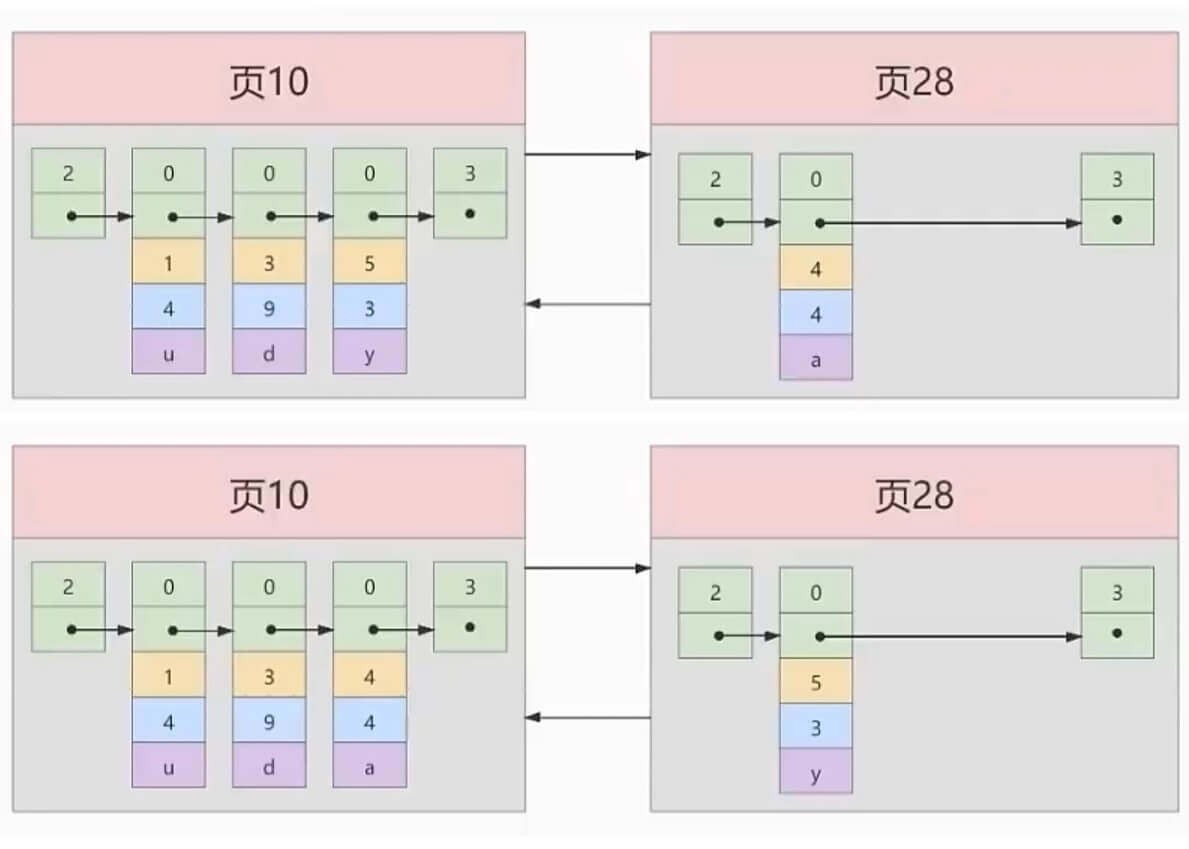
当然是第二种,因为我们要做到数据是有序的,这样才能实现快速查找,所以需要对数据进行调整。
那么,我们的数据有很多很多呢?

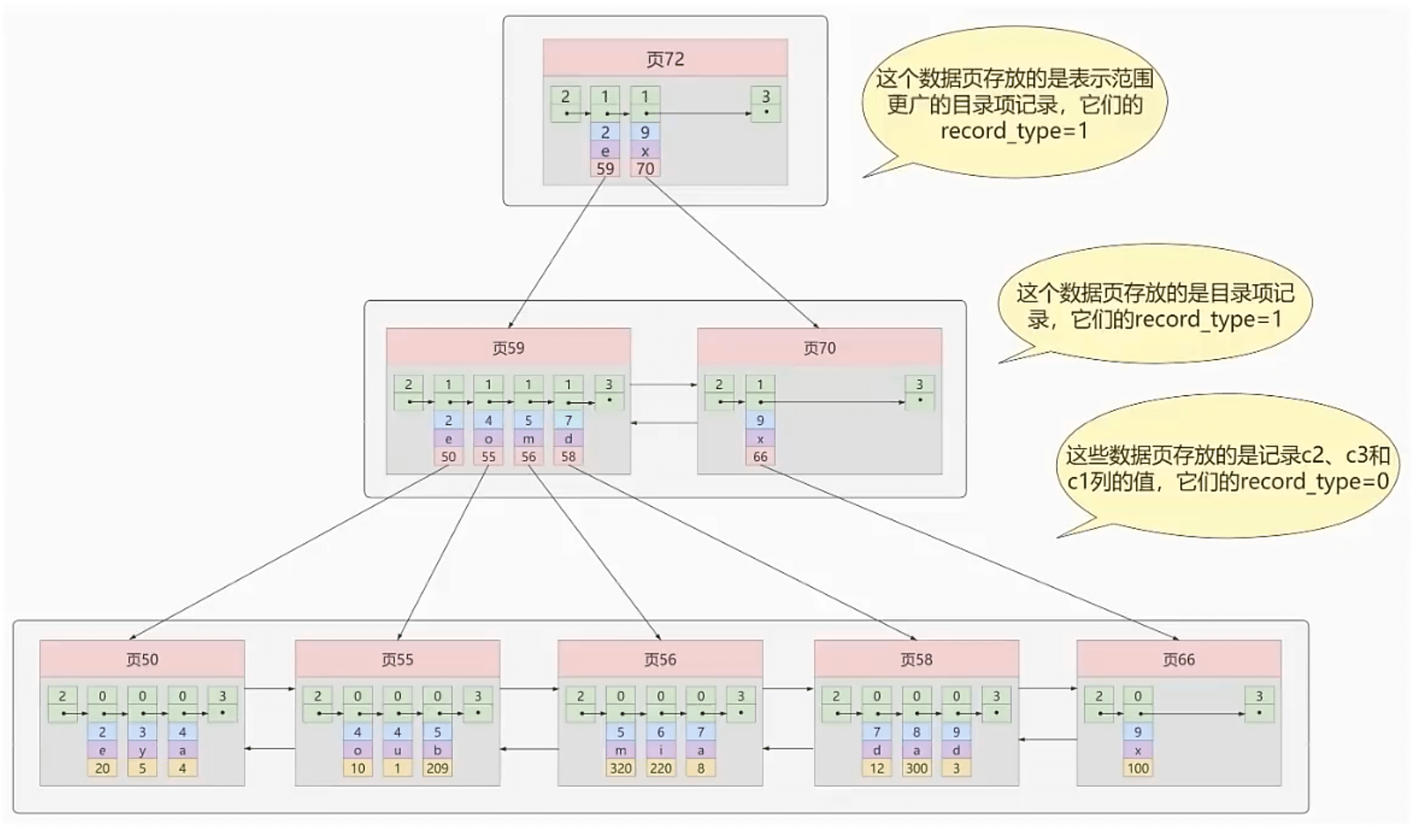
我们再为页,建立目录,这就是目录页,如图所示,页30就是一个目录页,其存储是最小主键值和所对应的数据页。
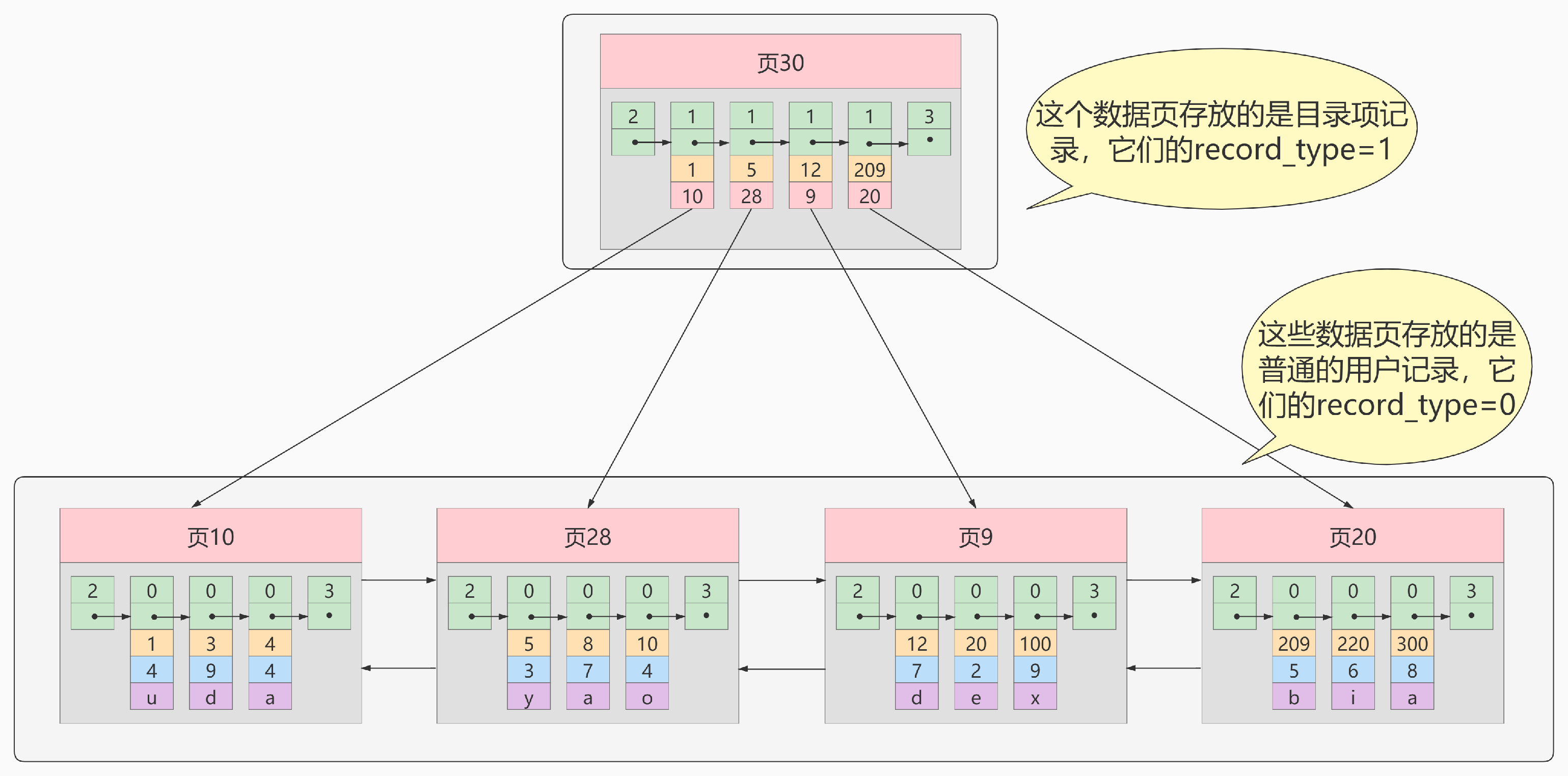
如果,我们的数据很多很多,以至于我们需要在目录页中查找呢?
那么,就再为目录页建立目录页。
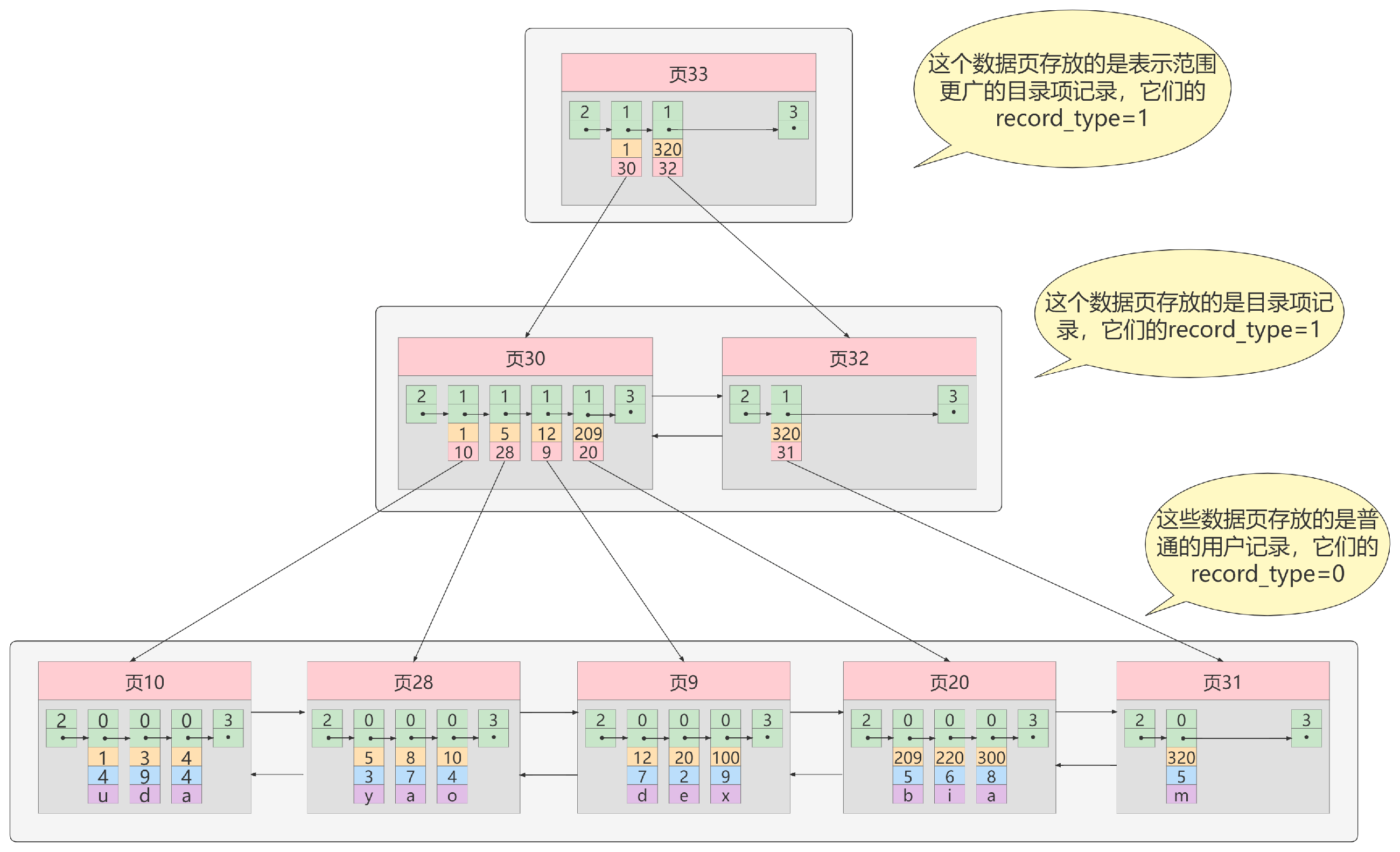
有些资料会说,MySQL的索引是三层的,这是因为对于一般数据量的表,B+树,确实是三层的。
根页面位置保持不动
上文我们讨论的推演,容易让大家误以为根页面是随着数据的增加,而逐步变化的。
实际上,先有根页面,在数据较少的时候,根页面是数据页,后期随着数据量的增加,根页面逐步升为目录页,目录页的目录页等。
聚簇索引和非聚簇索引
回表
在上文,我们讨论了InnoDB中的B+树,这样,我们根据主键查找的话,能快速查找到数据。
那么,如果我们不是根据主键查找呢?
这就涉及到聚簇索引和非聚簇索引了。
聚簇索引,是说用户记录就存储在叶子节点上,上文的索引就是聚簇索引。
非聚簇索引也被称为二级索引或者辅助索引。
比如,我们可以为非主键字段c2建立非聚簇索引,然后在查找之后,只能得到其主键是多少,要获取具体的数据,还需要回到聚簇索引中,再找一遍,这个过程也被称为 回表 。
结构
那么,非聚簇索引的结构是怎么样的呢?
假如我们现在有数据如下:
| c1 | c2 | c3 |
|---|---|---|
| 1 | 1 | ‘u’ |
| 3 | 1 | ‘d’ |
| 5 | 1 | ‘y’ |
| 7 | 1 | ‘a’ |
会是这种吗?
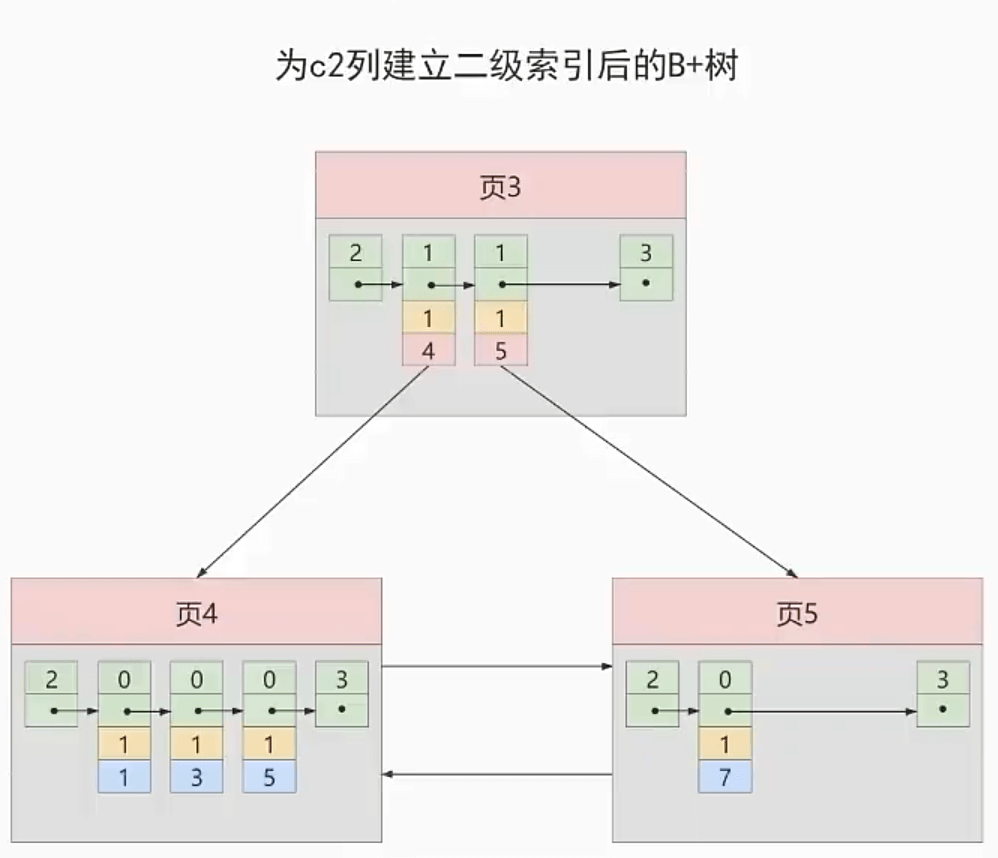
对于这种,如果我们想再插入一条数据,比如:
1 | INSERT INTO index_demo |
这时候,无法判断索引是应该建在页4,还是页5?
所以,索引结构应该是这样的:
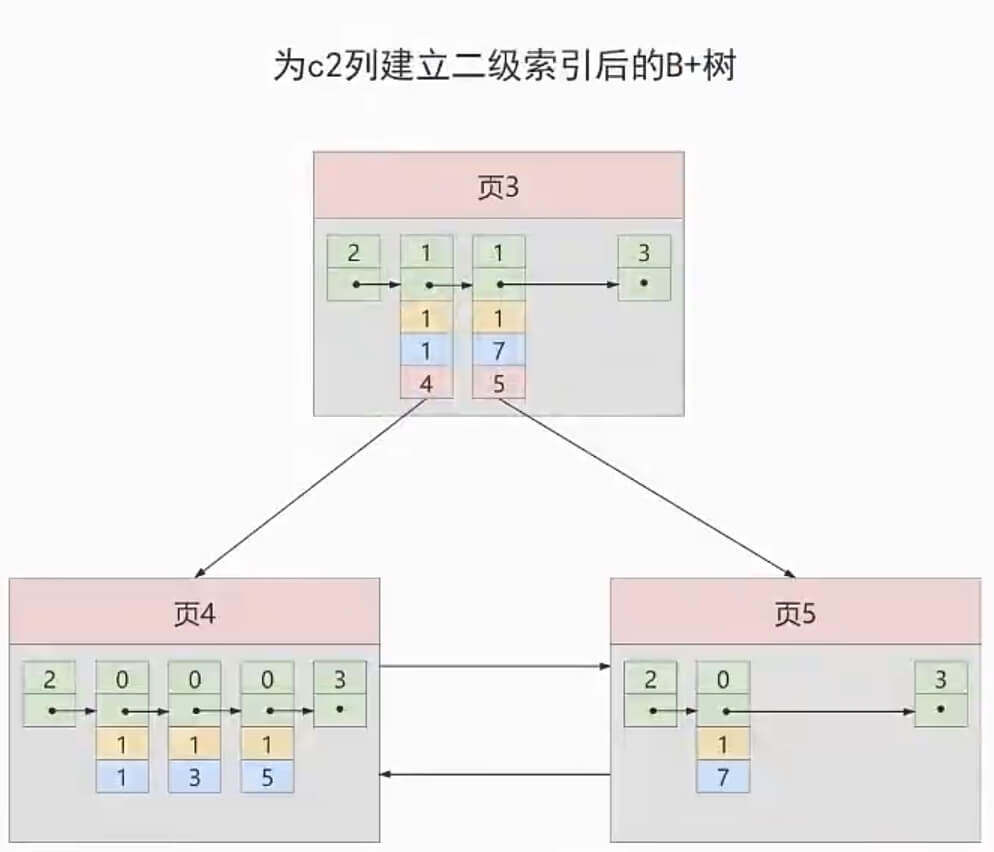
这也就是所谓的"内节点的唯一性"。
有些资料中,讨论的联合索引,结构是这样的。
这种结构,其实有待商榷。
非叶子结点的"内节点"中,应该也有主键信息,否则无法实现"内节点的唯一性"。
小结
- 聚簇索引的叶子节点存储的就是我们的数据记录,非聚簇索引的叶子节点存储的是数据位置。
- 一个表只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引。
- 在MySQL,目前只有InnoDB引擎支持聚簇索引。
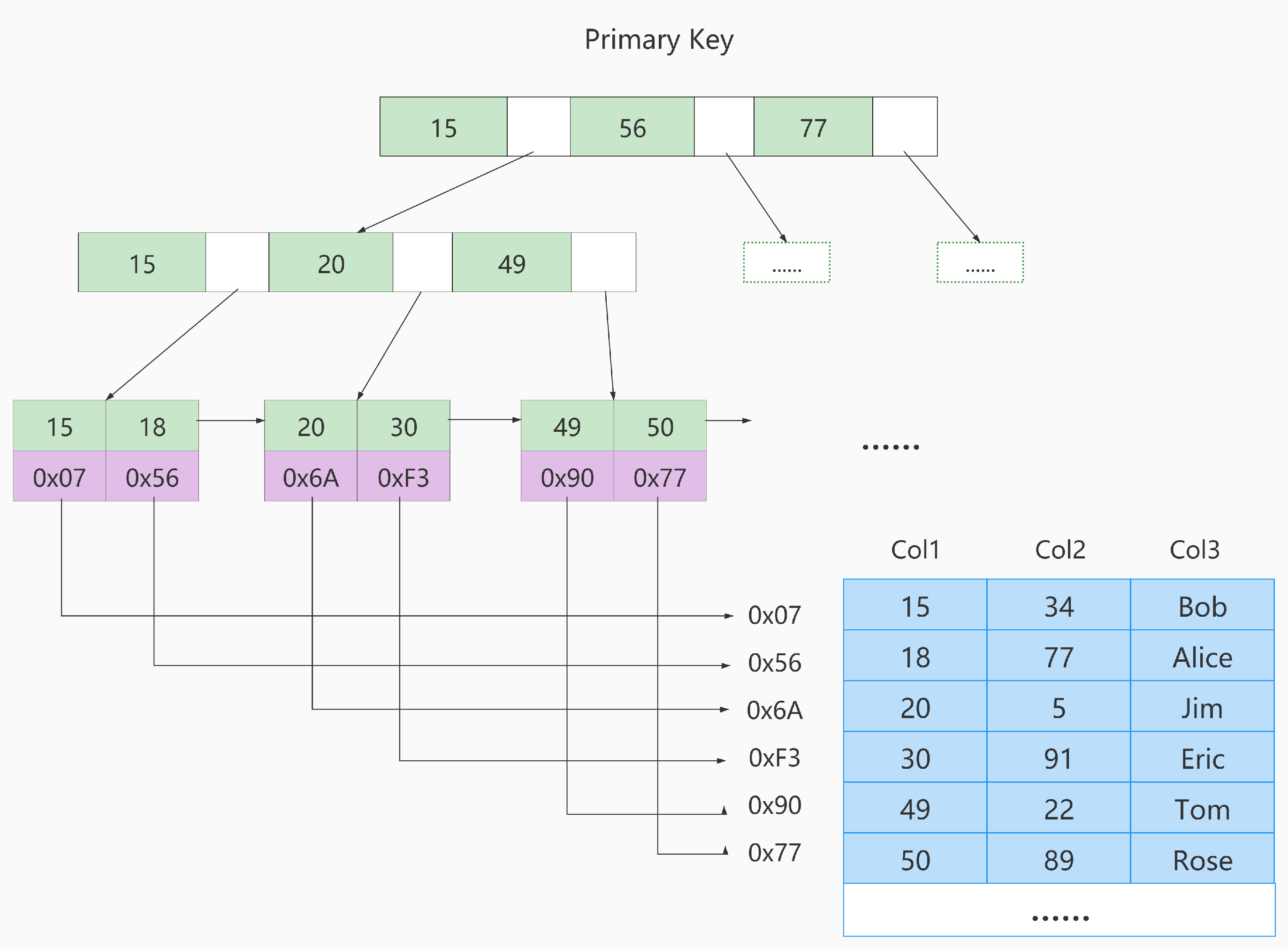
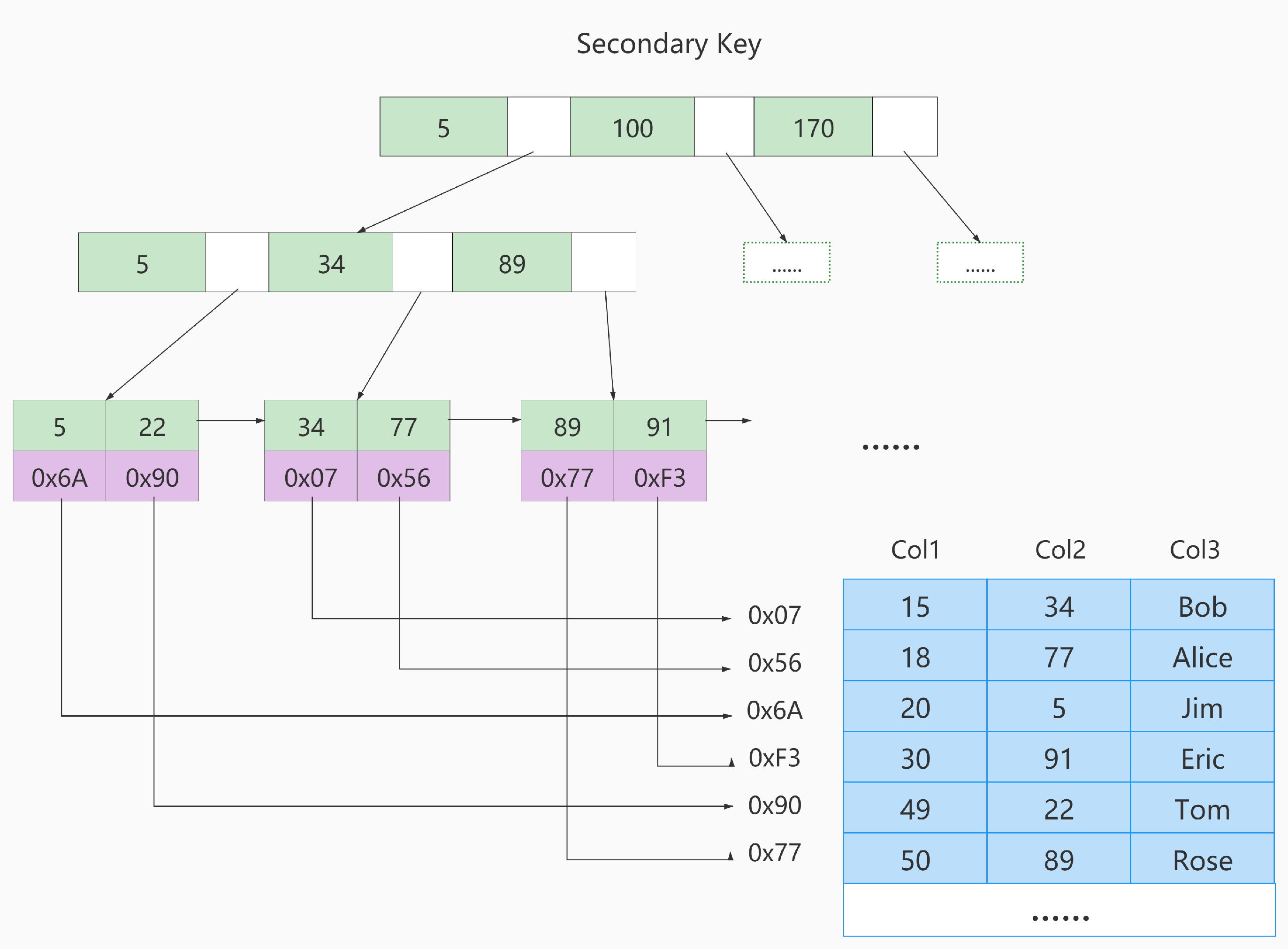
MyISAM中的索引
在MyISAM中,所有的索引都是非聚簇索引。
MyISAM中的主键索引如下:
MyISAM中的二级索引如下:
在上文,我们讨论InnoDB和MyISAM的区别的时候,说在缓冲池方面存在区别。
InnoDB不仅缓冲索引还缓冲了真实数据,而MyISAM只缓冲索引,不缓冲真实数据。在这里就有体现。
(当然,实际上,缓冲池内有很多东西,不仅仅是数据页和目录页。)