在上一章,我们讨论了HTTP中Request Headers和Response Headers,然后,我们讨论的所有的内容都是如何发出恰好好处的请求,以此拿到恰好好处的响应。
现在假设我们的已经成功的发出了恰好好处的请求,拿到了恰好好处的响应,但是响应中的内容肯定不会都是我们想要的。
比如,在猪价格网中。
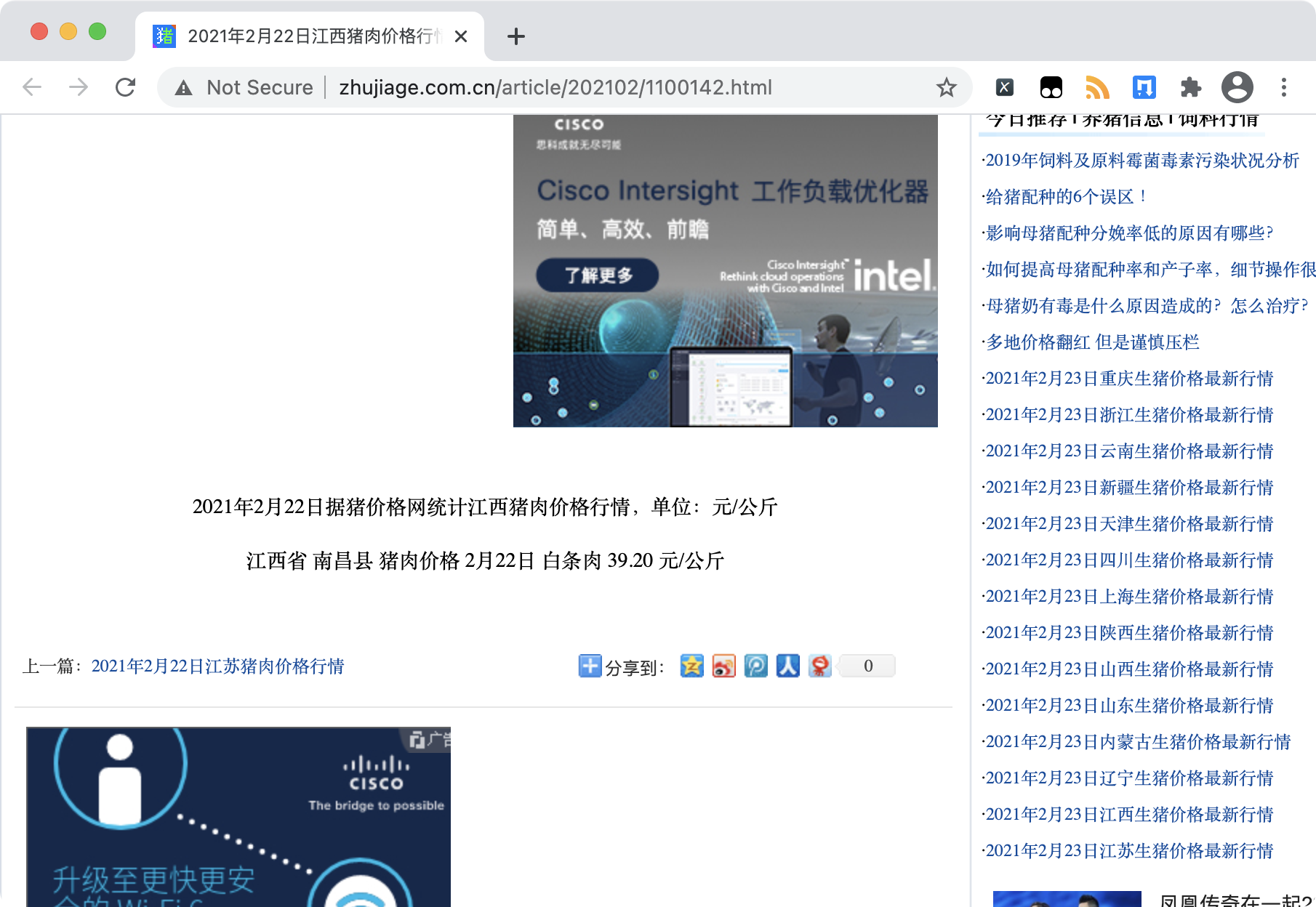
我们只想要时间、地点、种类和价格,但是这个网页呢,还给了许多我们不想要的内容,比如:广告。
接下来,我们讨论如何解析内容提取数据。
响应内容的分类
通常我们拿到的响应内容有四种:
jsonhtmlxmljpg、png、mp3等
其中jpg、png、mp3等,这些都不用解析内容提取数据,直接下载就行了。
示例代码:
1 | import requests |
我们主要讨论前面三种。
json
比如,我们这个博客,其中的评论数据,就是json格式的。
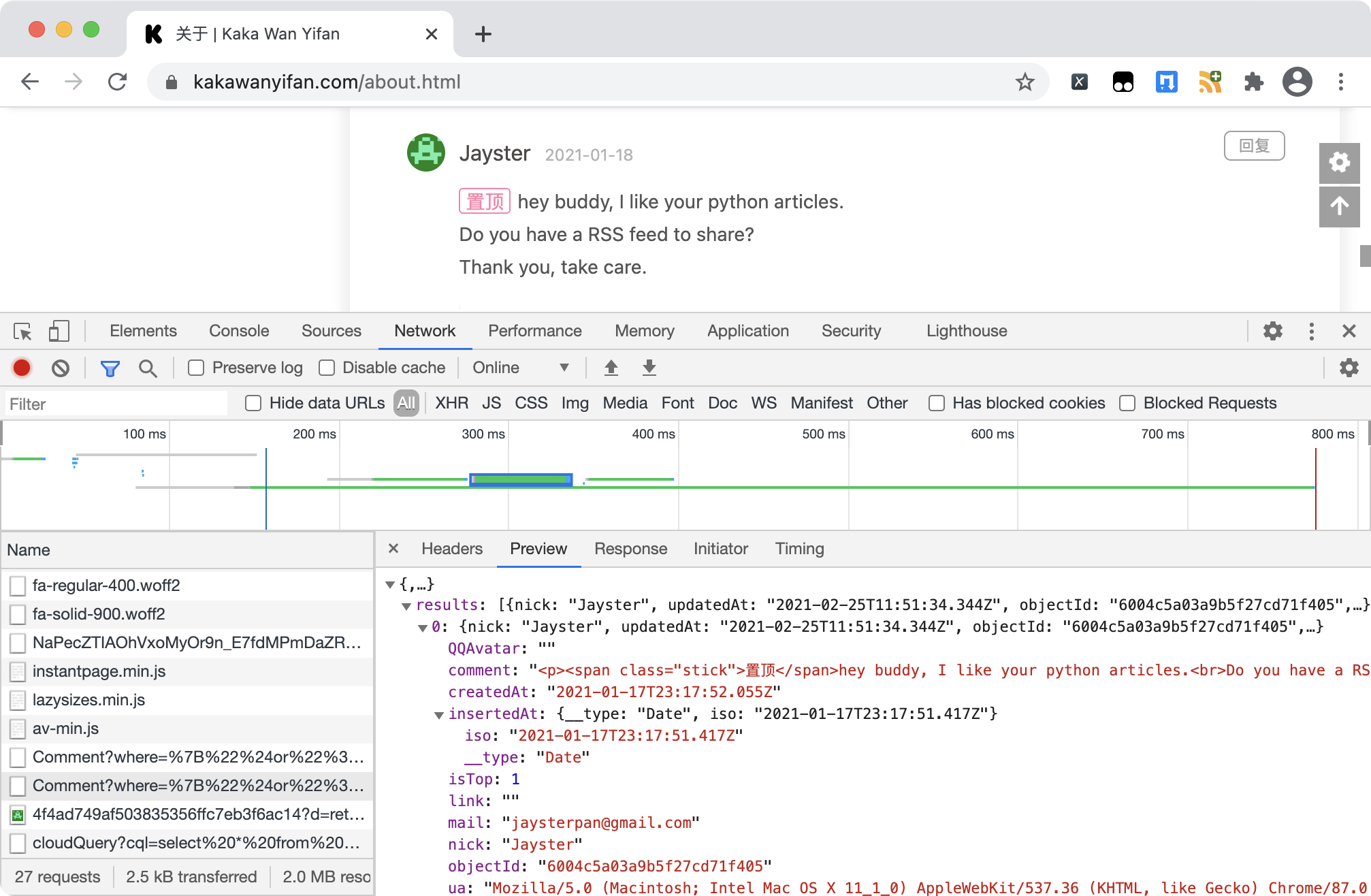
主要依赖的解析工具有:
jsonjsonpath
html
比如,我们这个博客的首页,就是html格式的。
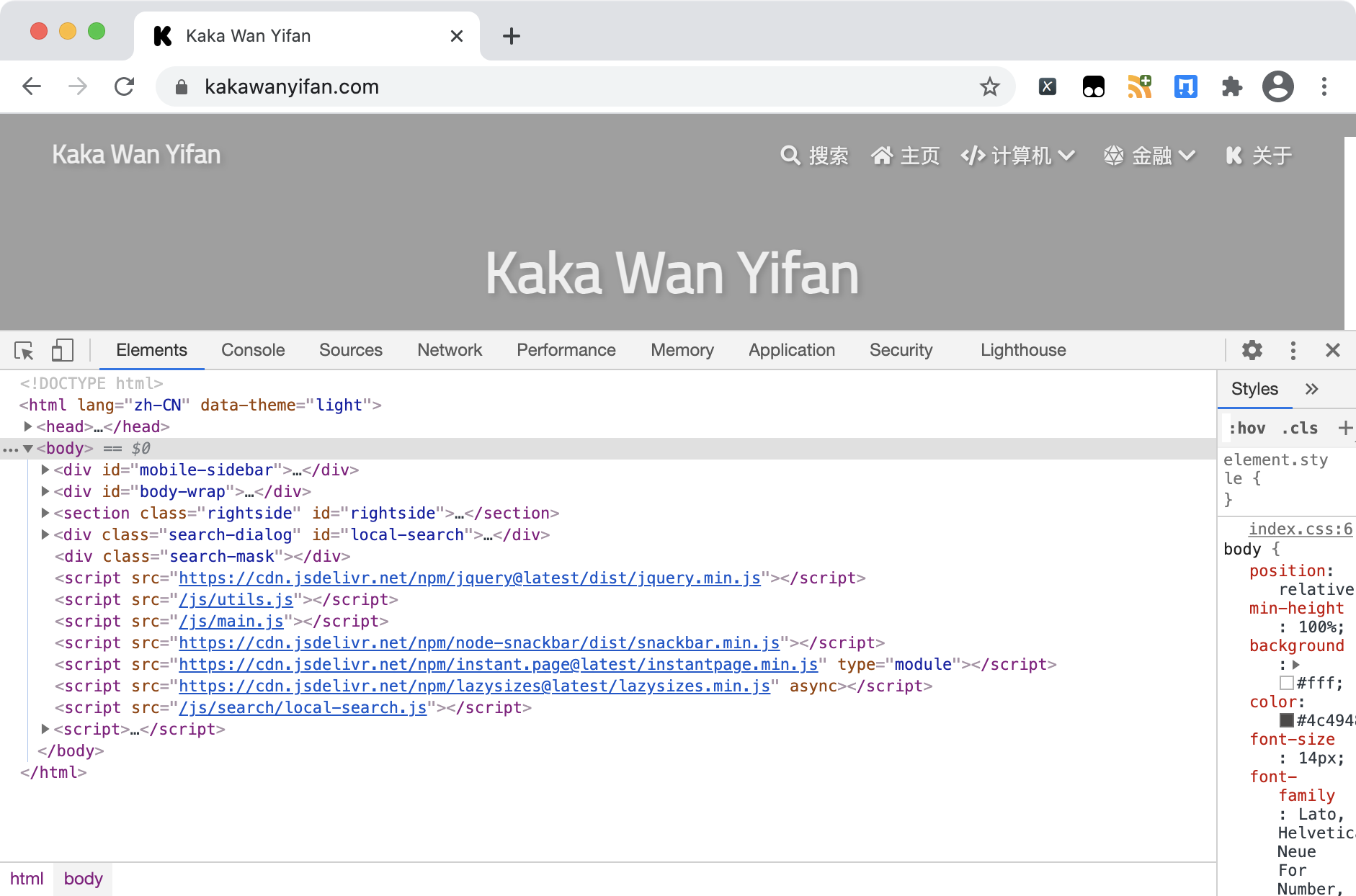
主要的解析工具有
re:正则lxml:xpath语法pyquery:css选择器beautiful:同时支持正则、xpath语法、css选择器,所以也因为不够专注,不够专业,在性能方面,不及前3种。
xml
还有一种是xml格式。
这种格式现在更多是用作配置文件,作为前后端交互的一种方式,已经很少见了。
在我们这个博客中,用于SEO优化的站点地图sitemap.xml,就是xml格式的。
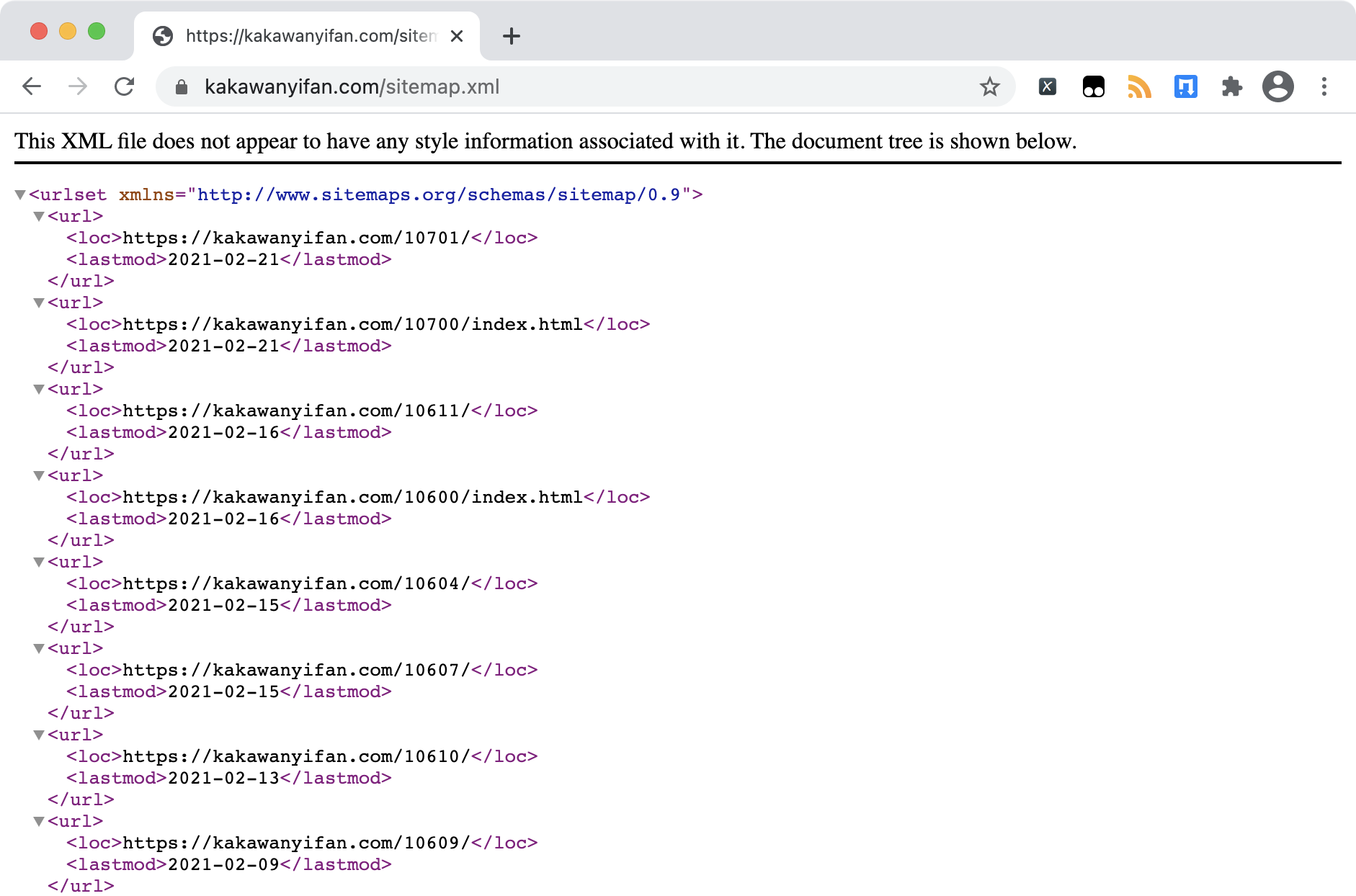
xml和html非常的相似。
xml是可扩展标记语言,为了传输和存储数据,侧重点是传输存储。在xml中,标签可以自行定义。
html是超文本标记语言,为了更好的显示数据,侧重点是为了显示。在html中,标签不可以自行定义,有特定的标签,具有特定的含义。
但两者都是以标签的形式进行存储,所以两者的具体解析工具有相通之处。
主要的解析工具有
re:正则lxml:xpath语法
所以,在接下来,我们不会单独讨论xml的解析。
JSON数据的解析提取
我们以豆瓣电影为例,讨论讨论JSON数据的解析提取。
分析
我们点开豆瓣的网站,选中到高分电影。观察请求,会发现这么一个请求
这个请求的返回就是电影数据,同时我们观察这个请求的Request Headers,特别的,我们发现有Referer,在上一章,我们讨论过,Referer用来表明Client客户端是从该Referer页面发起的请求,且Referer的值是https://movie.douban.com/explore,那么,这个字段极有可能被用作反爬虫的一个参考。
而且,我们发现似乎并没有类似签名的内容。所以,我们也不需要考虑签名的事情。
相反的,在我们博客的评论页面,我们发现为了评论数据的安全,居然还设置了一个id,一个sign。
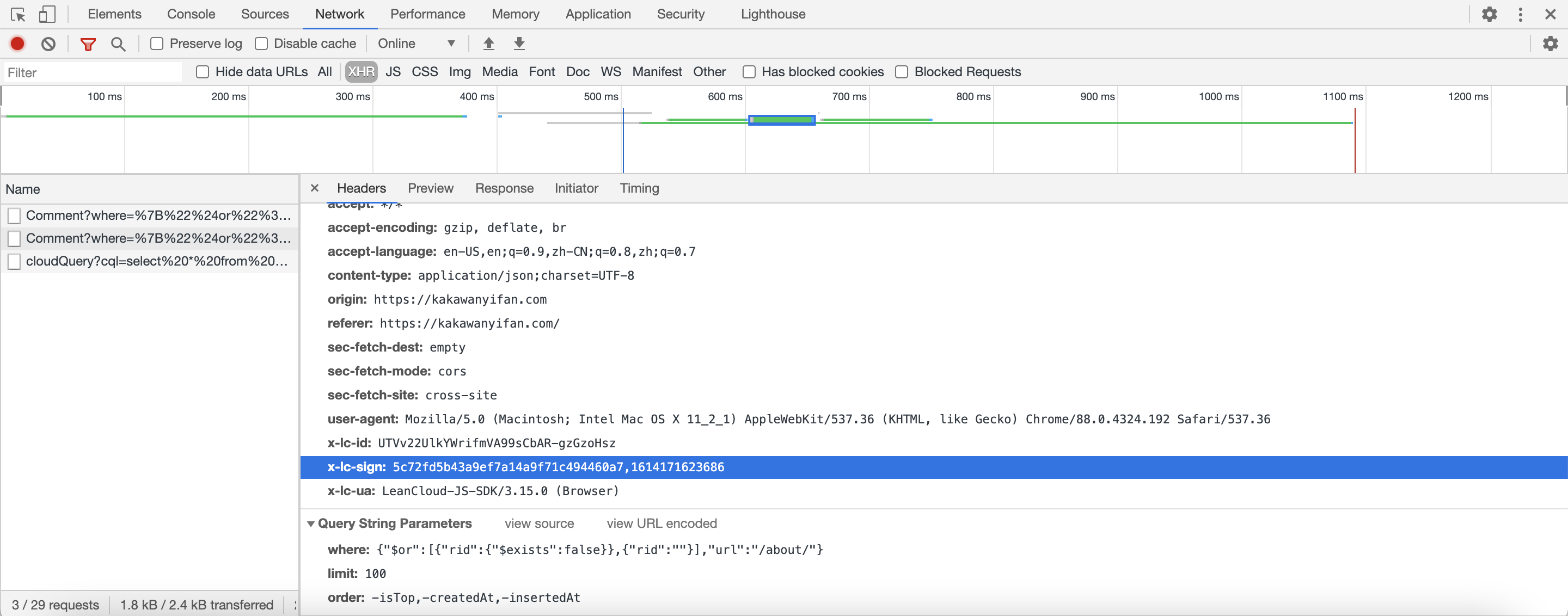
如果签名不对的话,返回的是
1 | {"code":401,"error":"Unauthorized."} |
所以,对于我们博客的评论数据,要爬取的难度就较大了,首先要先破解签名算法。但在豆瓣中,不需要。
此外,在豆瓣的请求中,我们发现有五个参数
1 | type: movie |
而且,如果我们在豆瓣的网页上点击加载更多更多的话

会发现参数变成了
1 | type: movie |
这样,我们就发现了豆瓣电影翻页的方法。
甚至,我们可以把page_limit设置大一点的话,这样我们可以少翻几页。但为了防止被反爬虫,我们要尽量装浏览器装得像一点,就设置成20。
特别的,我们发现,在整个翻页过程中,cookie也没有变化,我们把cookie也带上。
而且,我们发现,其他参数也没变化,所以索性都带上。
解析
接下来,我们就来解析内容提取数据
基于JSON解析
JSON的四个方法
如果要解析JSON,第一步就是把Response的返回,转换成json,这里介绍两个方法:
json.load()json.loads()
json.load()
官方介绍是
Deserialize ‘‘fp’’ (a ‘’.read()‘’-supporting file-like object containing a JSON document) to a Python object.
即:把类文件文件对象反序列化成Python对象
json.loads()
官方介绍是
Deserialize ‘‘s’’ (a ‘‘str’’, ‘‘bytes’’ or ‘‘bytearray’’ instance containing a JSON document) to a Python object.
即:把一个字符串对象反序列化成Python对象
与上面两个方法相对应的序列化方法是
- json.dump()
- json.dumps()
毫无疑问,我们这里应该用json.loads()
response.json()
特别的,我们还有一个方法:
1 | response.json() |
- 但是有些JSON可能用压缩算法进行了压缩,所以还是需要
json.loads()方法。
解析JSON
在Python中,json的类型是dict或list。
JSONObject的类似是dict,JSONArray的类型是list。
关于如何读取dict和list中的元素,我们不讨论。
我们以只爬取第一页的数据为例。翻页的话,只需要修改参数。此外,在翻页过程中,我们可以控制每次爬取间隔的时间,防止被反爬虫
示例代码:
1 | import requests |
运行结果:
1 | {'Date': 'Wed, 24 Feb 2021 14:24:27 GMT', 'Content-Type': 'application/json; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Vary': 'Accept-Encoding, Accept-Encoding', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'X-DAE-App': 'movie', 'X-DAE-Instance': 'default', 'Server': 'dae', 'X-Content-Type-Options': 'nosniff', 'Content-Encoding': 'br'} |
基于jsonpath的解析
在上面豆瓣的例子中,我们拿到了一个非常漂亮,非常容易解析的json。
但是,如果我们遇到一位技艺拙劣的程序员呢?拿到了一个非常不好解析的json。(虽然有时候是产品经历要求程序员这么做的)
示例代码:
1 | d = { |
运行结果:
1 | kaka |
如果这个json再复杂一点点,眼睛都要花掉。
所以,接下来,我们讨论jsonpath。
jsonpath的官方介绍是An XPath for Json。
那么什么是XPath呢?我们在讨论HTML和XML的解析方法的时候会讨论。
我们先直接看jsonpath中最常见的三个方法
$:跟节点.:子节点..:任意位置,符合条件的节点
关于更多的方法,大家可以参考如下的地址
示例代码:
1 | from jsonpath import jsonpath |
运行结果:
1 | ['kaka'] |
或许这个方法还是不够简洁,毕竟我们还是一层一层的数了,只是少写了点代码。
看这个
示例代码:
1 | from jsonpath import jsonpath |
运行结果:
1 | ['kaka'] |
jsonpath中,返回的都是list类型。
HTML数据的解析提取
我们以博客为例,讨论讨论HTML数据的解析提取。
我们请求我们的博客,发现文章的相关数据并不是以json形式进行传递的,而是原本就存在于html中。
分析
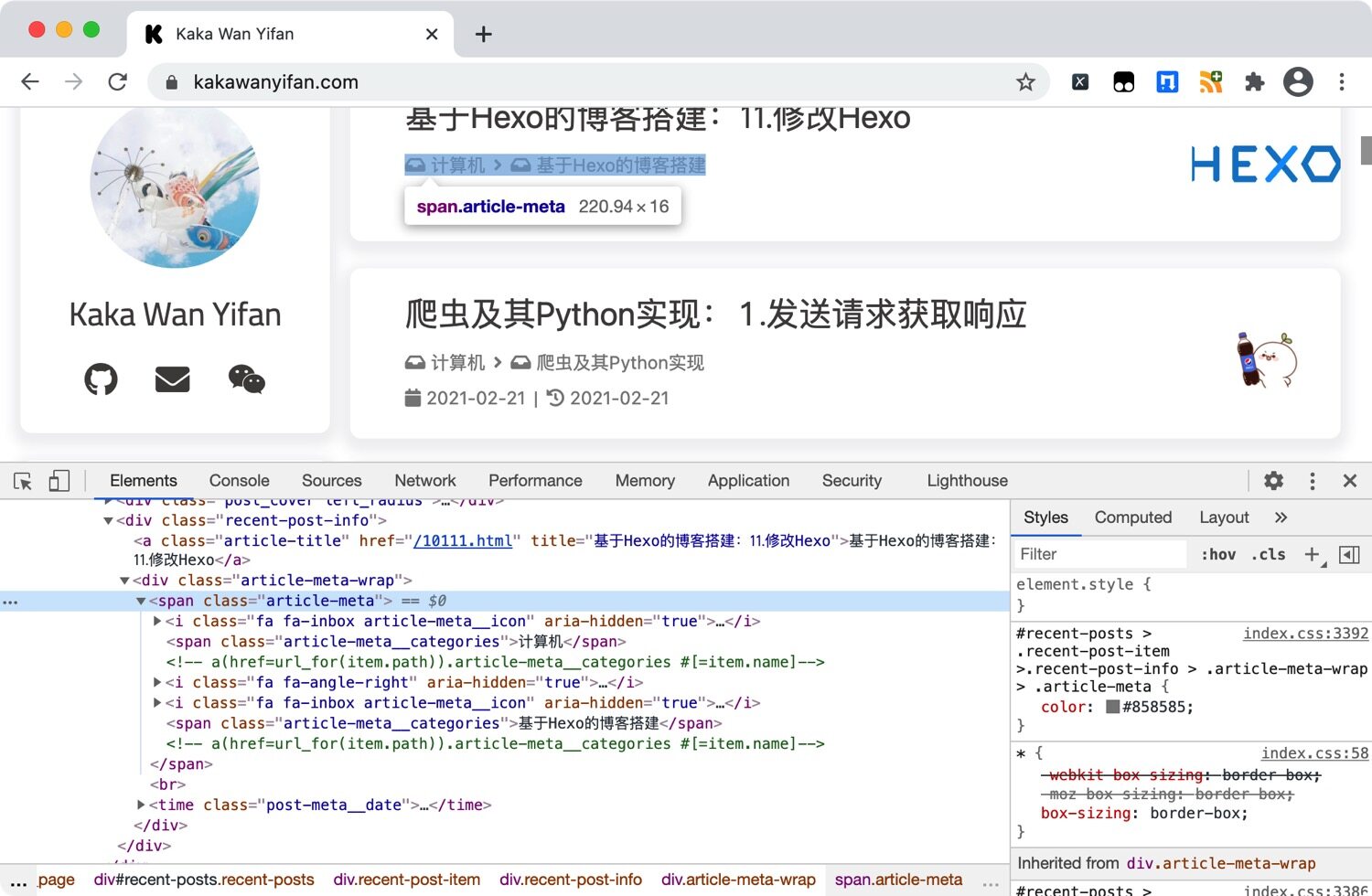
我们观察我们的网页,发现每一篇文章都在一个<div class="recent-post-item">中。
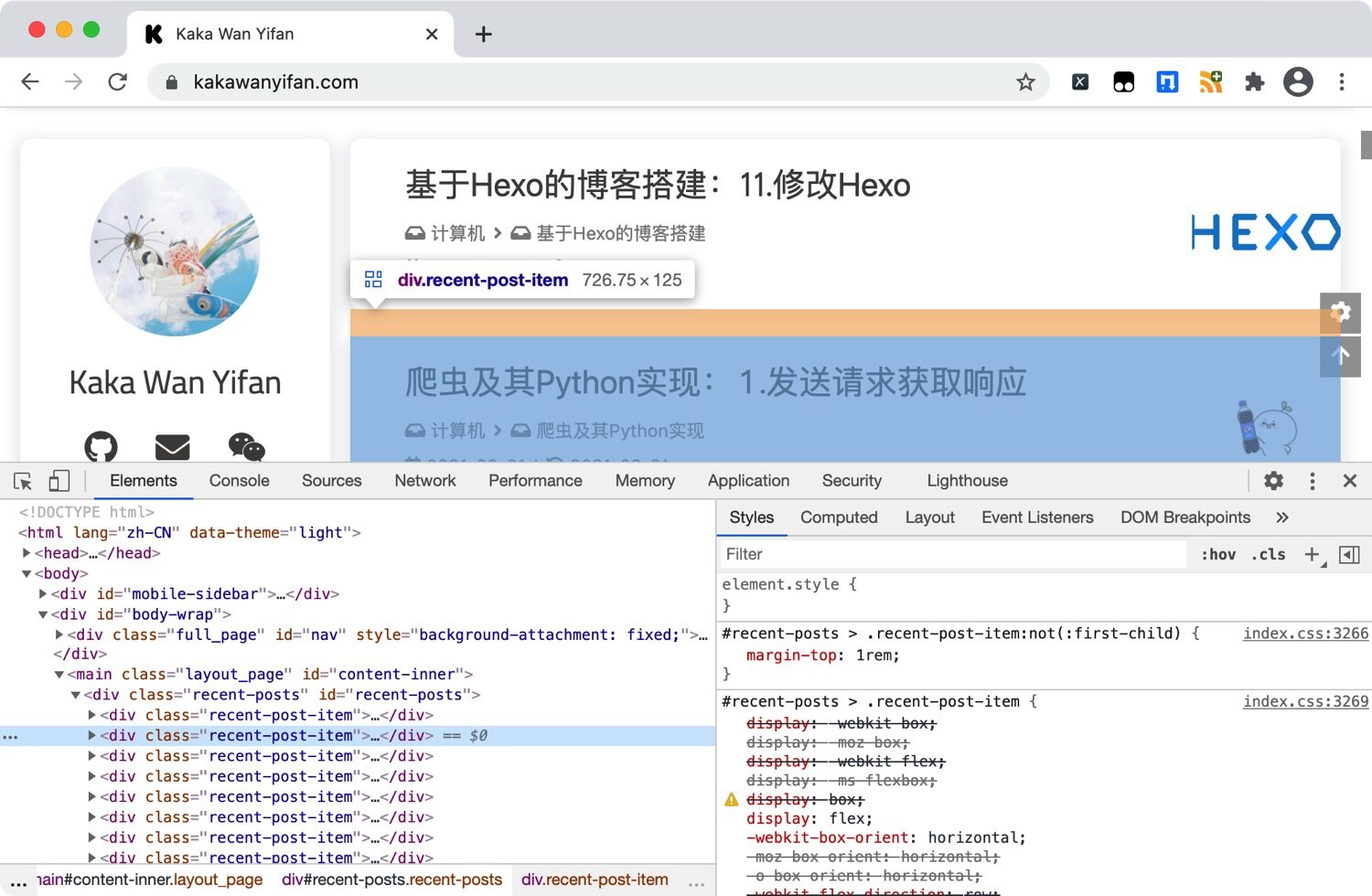
再观察,会发现<div class="recent-post-info">中的a标签,就有文章的标题和地址信息。
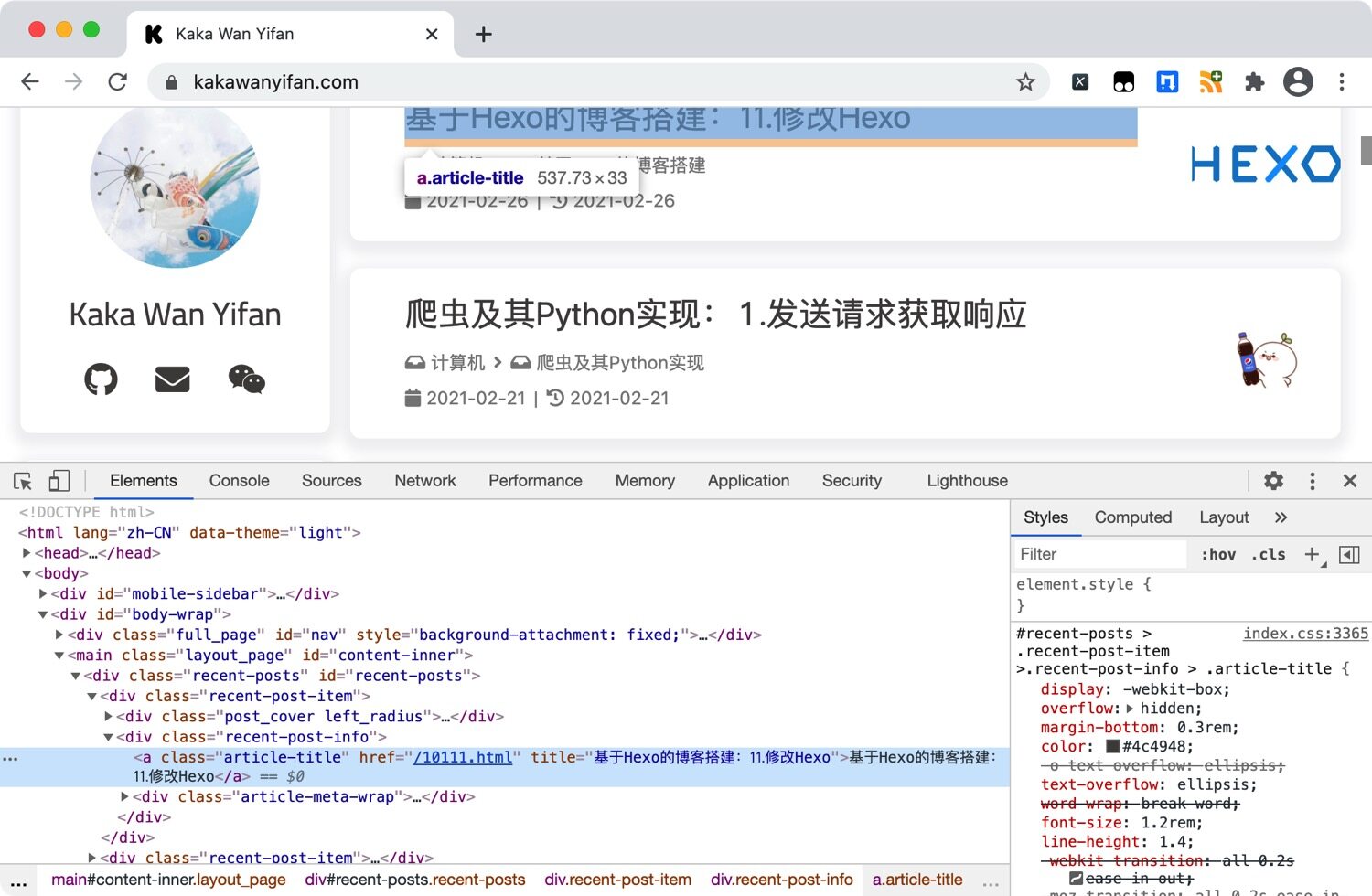
在<div class="article-meta-wrap">的<span class="article-meta">有文章的分类信息。
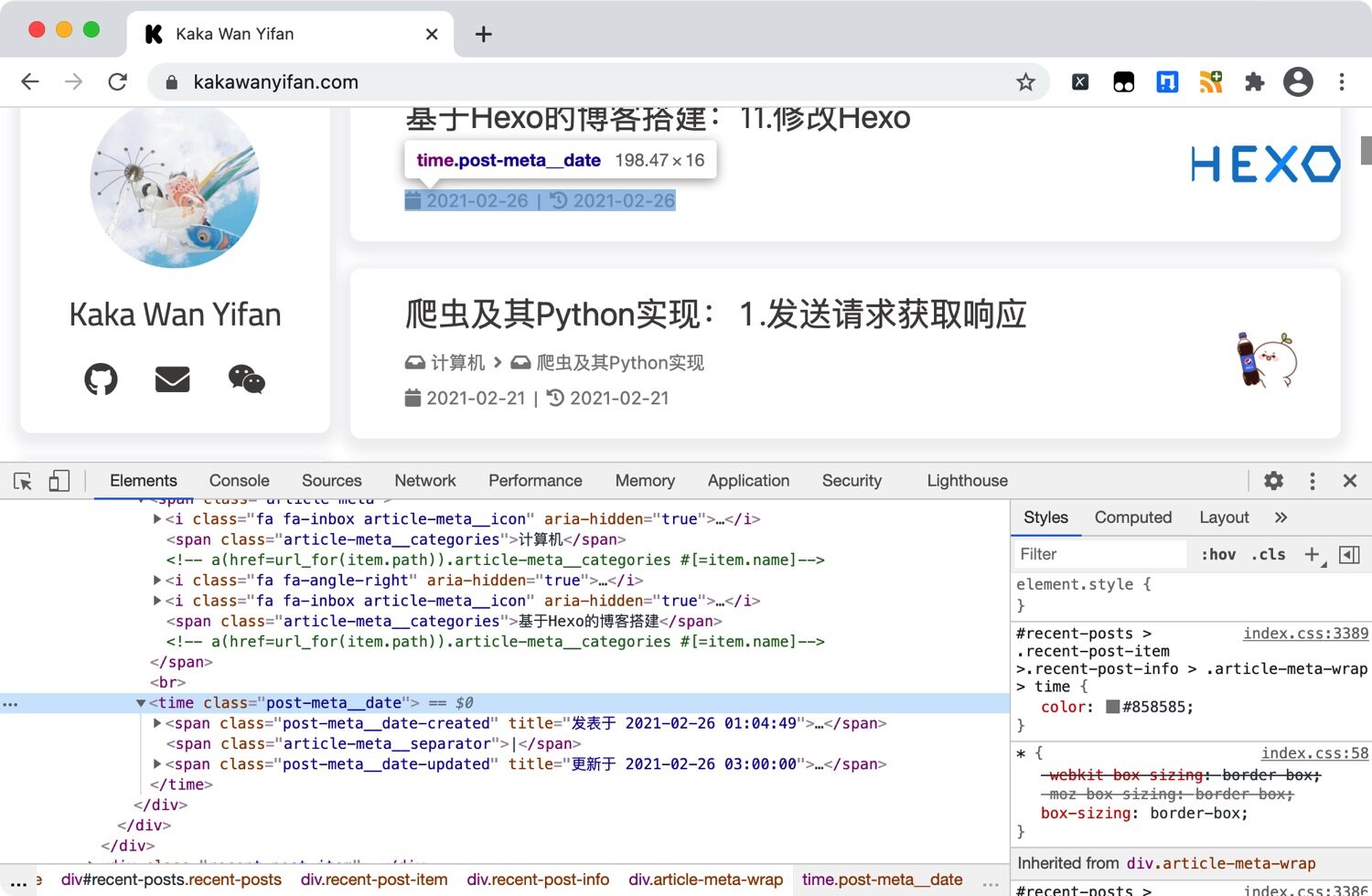
在<time class="post-meta__date">中有文章的发布以及更新时间。
XPath
所以,我们需要解析这个HTML。
怎么解析?
我们从根节点出发,一层一层get,最后获取到我们想要的内容。太麻烦了!
我们在上一章讨论jsonpath的时候,特别提到了其官方介绍An XPath for JSON。然后,我们也见识到了jsonpath的神奇魔力,快速定位到我们想要的元素。
现在,我们就来看看什么是XPath。
XPath Helper
工欲善其事,必先利其器。
首先,我们安装一个Chrome的插件,XPath Helper。
接下来,我们会利用这个插件讨论XPath,一边讨论,一边实践。
节点
首先,我们讨论什么是XPath中的节点。
每个html、xml的标签我们都称之为节点,其中最顶层的节点称为根节点。
以我们博客的首页为例,其根节点是html,然后还有两个子节点,分别是head和body。
节点选择语法
“人如其名”,XPath使用路径表达式(Path)来选取文档中的节点或者节点集。
| 表达式 | 描述 |
|---|---|
nodename |
选中该元素。 |
/ |
从根节点选取、或者是元素和元素间的过渡。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选取当前节点。 |
.. |
选取当前节点的父节点。 |
@ |
选取属性。 |
text() |
选取文本。 |
我们来看几个具体的例子。
/:从根节点选取、或者是元素和元素间的过渡。
例如,我们获取我们主页的浏览器标签的title。
我们从跟节点出发/,先选中html,再选中head,最后选中title。
示例代码:
1 | /html/head/title |

- 使用
XPath Helper选择标签时候,选中的标签会添加属性class="xh-highlight"。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
当然,我们也可以//开头。
实力代码:
1 | //title |

..:选取当前节点的父节点。
我们在上例中添加..,回到head节点,再添加..,回到html节点。
然后我们又//title,重新回到title。
示例代码:
1 | //title/../..//title |

text():选取文本。
特别注意这时候的意思是选取文本内容,之前title标签的class="xh-highlight"没有了。
示例代码:
1 | //title/../..//title/text() |

@:选取属性。
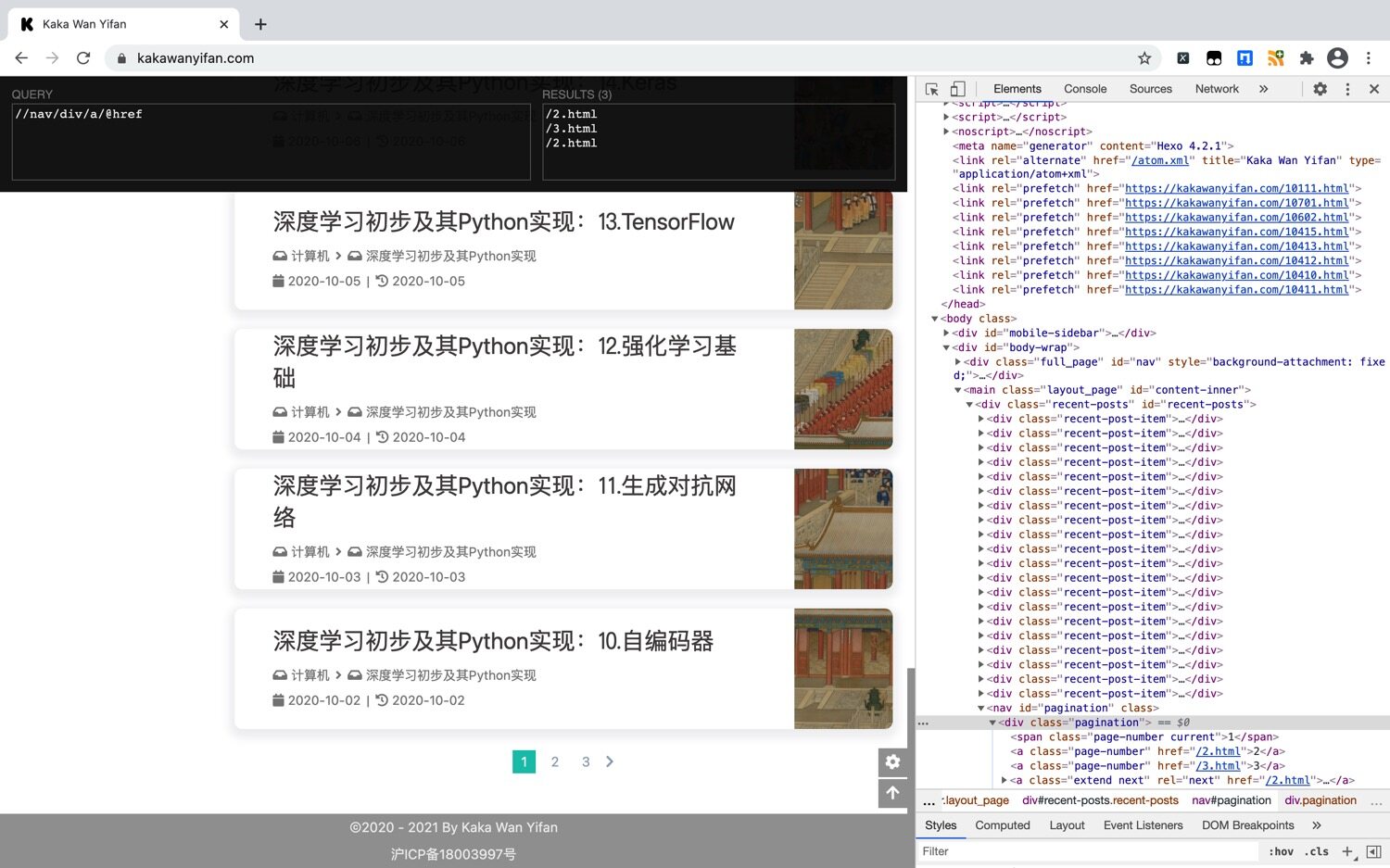
我们以获取翻页地址为例,讨论选取属性。
示例代码:
1 | //nav/div/a/@href |
节点修饰语法
讨论了那么多,我们来获取文章标题吧。
示例代码:
1 | //main/div/div |
运行结果:
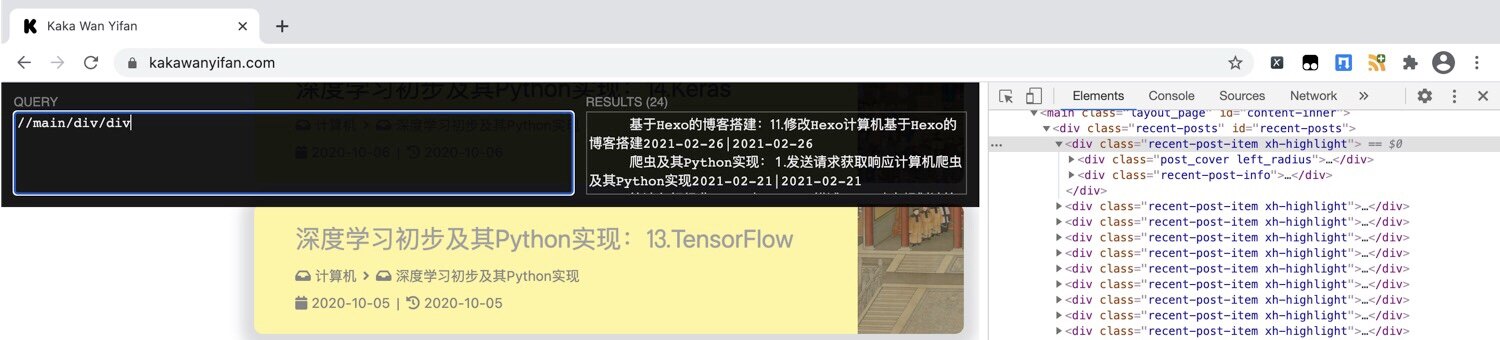
<div class="post_cover left_radius">和<div class="recent-post-info">都是div。
这时候久需要节点节点修饰语法了。
| 路径表达式 | 结果 |
|---|---|
//title[@lang="eng"] |
选择lang属性值为eng的所有title元素 |
/bookstore/book[1] |
选取属于bookstore子元素的第一个book元素。 |
/bookstore/book[last()] |
选取属于bookstore子元素的最后一个book元素。 |
/bookstore/book[last()-1] |
选取属于bookstore子元素的倒数第二个book元素。 |
/bookstore/book[position()>1] |
选择bookstore下面的book元素,从第二个开始选择。 |
//book/title[text()='Harry Potter'] |
选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
/bookstore/book[price>35.00]/title |
选取bookstore元素中的book元素的所有title元素,且其中的price元素的值须大于35.00。 |
注意:
- 在XPath中,第一个元素的位置是1
我们来看几个具体的例子。
通过索引修饰节点
示例代码:
1 | //main/div[1]/div/div[2]/a/text() |
![//main/div[1]/div/div[2]/a/text()](/-/1/13/02/021.jpg)
通过属性修饰节点
还可以通过通过属性修饰节点。
示例代码:
1 | //a[@class='article-title']/text() |
![//a[@class='article-title']/text()](/-/1/13/02/022.jpg)
通过多条件修饰节点
比如,我们把标题包含"爬虫及其Python实现"的文章选出来了。
用and多条件修饰。
1 | //a[@class='article-title' and contains(@title,'爬虫及其Python实现')] |
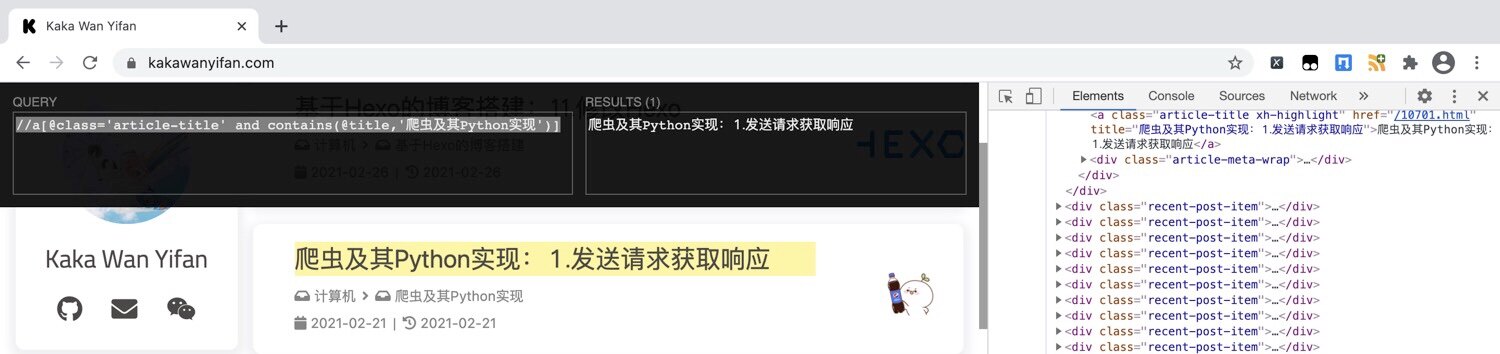
特别的,我们也可以在contains()中加text()。
1 | //a[@class='article-title' and contains(text(),'爬虫及其Python实现')] |
通配符
可以通过通配符来选取未知的html、xml的元素
| 通配符 | 描述 |
|---|---|
* |
匹配任何元素节点。 |
node() |
匹配任何类型的节点。 |
更多的XPath语法参考:https://www.w3school.com.cn/xpath/index.asp
lxml
在讨论了XPath之后,接下来就是应用了。
我们需要依赖lxml这个模块,这是一个第三方模块,需要额外按照。
方法
-
导入lxml 的 etree 库
from lxml import etree -
利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表
1
2html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串") -
xpath方法返回列表的三种情况
- 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
- 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
- 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
例子
我们以获取我们博客的所有文章名称、文章地址、类别、发布日期和更新日期为例。
示例代码:
1 | import requests |
运行结果:
1 | 基于Hexo的博客搭建:11.修改Hexo /10111 计算机 基于Hexo的博客搭建 2021-02-26 2021-02-26 |