这一系列的笔记我们讨论强化学习,在《深度学习初步及其Python实现:12.强化学习初探》 中,我们有简单的讨论过强化学习,但当时的讨论太浅显。这次,我们用七章的篇幅,试图较为深刻的讨论强化学习。
注意!
我在深度学习的系列笔记中讨论强化学习,容易让大家误会,认为强化学习属于深度学习的一种。实际上,这是两个独立的概念,但是深度学习的一些方法会被用来解决强化学习的问题,这个也被称为深度强化学习。 另外,强化学习其实是一个非常博大精深的话题,除了我们这系列会讨论的内容外,还有多智能体的强化学习、逆强化学习以及考虑方差的强化学习等内容。所以我们的标题是"强化学习浅谈及其Python实现"。
强化学习中最重要,最基础的数学模型是马尔可夫决策过程(Markov Decision Process)。
概率论
随机变量和观测值
随机变量是一个不确定的量,它的值取决于一次随机事件的结果。X X X X X X X X X x x x
x = 正面 x=\text{正面}
x = 正面
概率分布
强化学习中会反复用到概率分布函数(Probability Distribution Function)。
概率质量函数
概率质量函数,其实这并不是什么新东西,我们在高中数学就学过,只是那个时候我们称之为分布律,或者分布列。
正面
反面
概率
0.5 0.5 0 . 5 0.5 0.5 0 . 5
概率质量函数描述离散随机变量在各特定取值上的概率。
∑ x ∈ X 的所有可能取值 p ( x ) = 1 \sum_{x \in X\text{的所有可能取值}} p(x) = 1
x ∈ X 的所有可能取值 ∑ p ( x ) = 1
概率密度函数
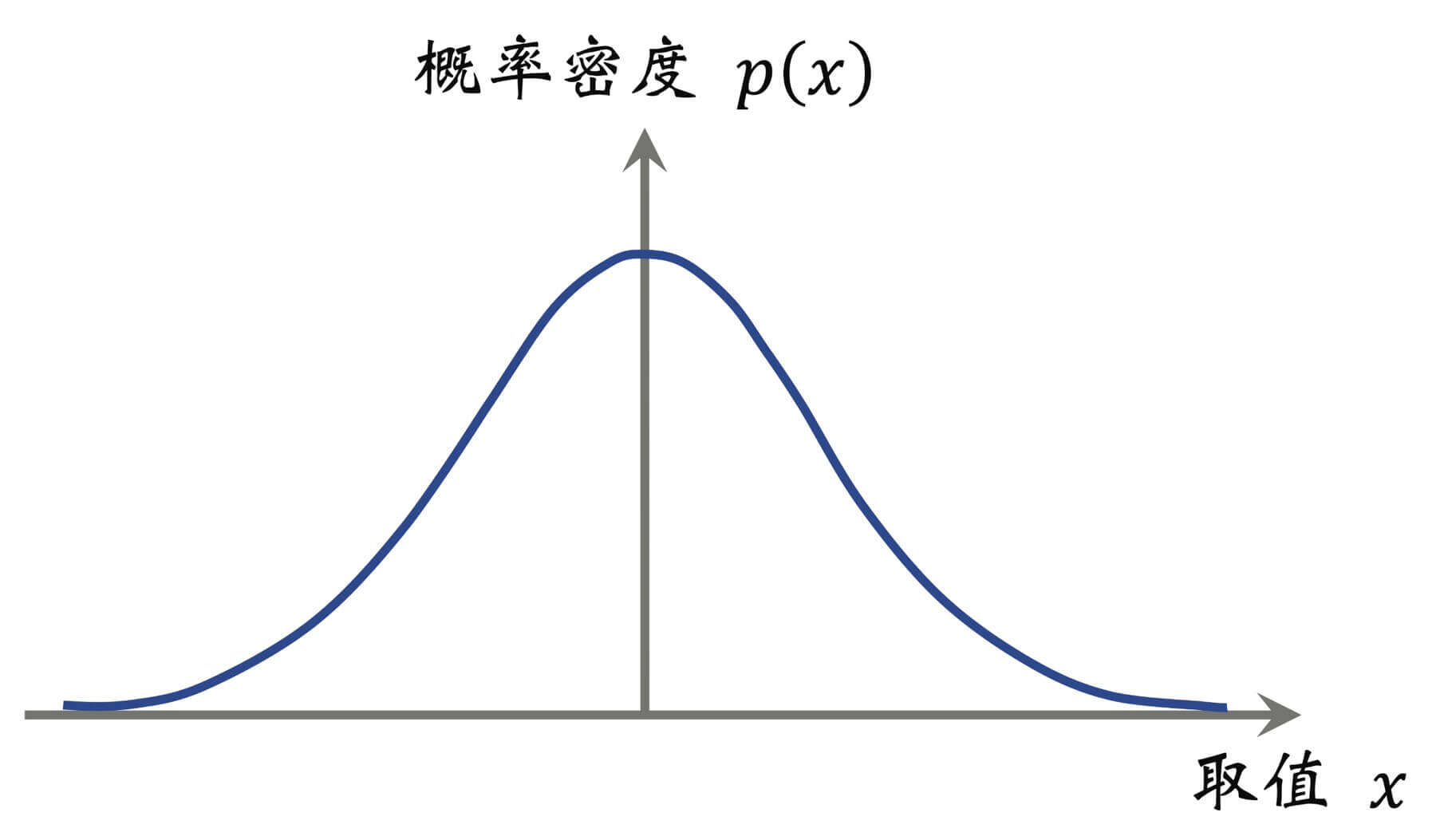
但是对于连续随机变量,其一切可能取值充满一个区间,在这个区间内有无穷多个实数。所以我们描述连续随机变量的概率分布就不能再用概率质量函数了,要用概率密度函数。
比如,正态分布,就是一种常见的连续概率分布,其概率密度函数如下:
p ( x ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) p(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\bigg(-\frac{(x-\mu)^2}{2\sigma^2}\bigg)
p ( x ) = 2 π σ 2 1 exp ( − 2 σ 2 ( x − μ ) 2 )
如图所示,X X X
∫ X 的值域 p ( x ) d x = 1 \int_{X\text{的值域}} p(x) dx = 1
∫ X 的值域 p ( x ) d x = 1
期望
离散随机变量
E [ f ( X ) ] = ∑ x ∈ X 的所有可能取值 p ( x ) f ( x ) \mathbb{E}[f(X)] = \sum_{x\in X\text{的所有可能取值}} p(x) f(x)
E [ f ( X ) ] = x ∈ X 的所有可能取值 ∑ p ( x ) f ( x )
连续随机变量
E [ f ( X ) ] = ∫ X 的值域 p ( x ) f ( x ) d x \mathbb{E}[f(X)] = \int_{X\text{的值域}} p(x) f(x) dx
E [ f ( X ) ] = ∫ X 的值域 p ( x ) f ( x ) d x
例子
我们再来举一个相关的例子,因为在讨论"价值函数"的时候,我们会大量用到与这个例子相近的思路。g ( X , Y ) = X Y g(X,Y) = XY g ( X , Y ) = X Y X X X Y Y Y X X X [ 0 , 10 ] [0,10] [ 0 , 1 0 ] p ( x ) = 1 10 p(x) = \frac{1}{10} p ( x ) = 1 0 1 g ( X , Y ) g(X,Y) g ( X , Y ) X X X
E X ∼ p ( ⋅ ) [ g ( X , Y ) ] = ∫ X 的值域 g ( x , Y ) ∗ p ( x ) d x = ∫ 0 10 x Y 1 10 d x = 5 Y \begin{aligned}
\mathbb{E}_{X \sim p(\cdot)}[g(X,Y)] &= \int_{X\text{的值域}} g(x,Y) * p(x) dx \\
&= \int_{0}^{10} xY \frac{1}{10} dx \\
&= 5Y
\end{aligned}
E X ∼ p ( ⋅ ) [ g ( X , Y ) ] = ∫ X 的值域 g ( x , Y ) ∗ p ( x ) d x = ∫ 0 1 0 x Y 1 0 1 d x = 5 Y
即:g ( X , Y ) g(X,Y) g ( X , Y ) X X X X X X
随机抽样
随机抽样,这个其实很好理解。
示例代码:
1 2 3 from numpy.random import choicesamples = choice(a=['正' , '反' ], size=100 , p=[0.5 , 0.5 ]) print(samples)
运行结果:
1 2 3 4 5 6 ['反' '正' '正' '正' '反' '反' '正' '正' '正' '正' '反' '反' '反' '正' '正' '反' '反' '反' '反' '正' '反' '正' '正' '正' '正' '反' '正' '反' '正' '反' '反' '正' '反' '正' '反' '正' '反' '正' '正' '正' '反' '反' '反' '正' '正' '正' '反' '反' '正' '反' '反' '反' '反' '反' '正' '正' '反' '正' '反' '反' '正' '反' '反' '正' '反' '正' '正' '反' '正' '反' '正' '正' '反' '正' '反' '反' '正' '正' '反' '反' '正' '反' '正' '反' '反' '反' '正' '正' '正' '正' '正' '正' '反' '反' '正' '正' '反' '反' '反' '正']
马尔可夫决策过程的基本概念
关于马尔可夫决策过程的基本概念,我们在《深度学习初步及其Python实现:12.强化学习初探》 有过简单的讨论,当时我们举了两个例子,电影《逃学威龙》和"在野外遇到熊"。这次,我们换一个例子,游戏《超级玛丽》。
现在,让我们来好好的拆解一下这款游戏。
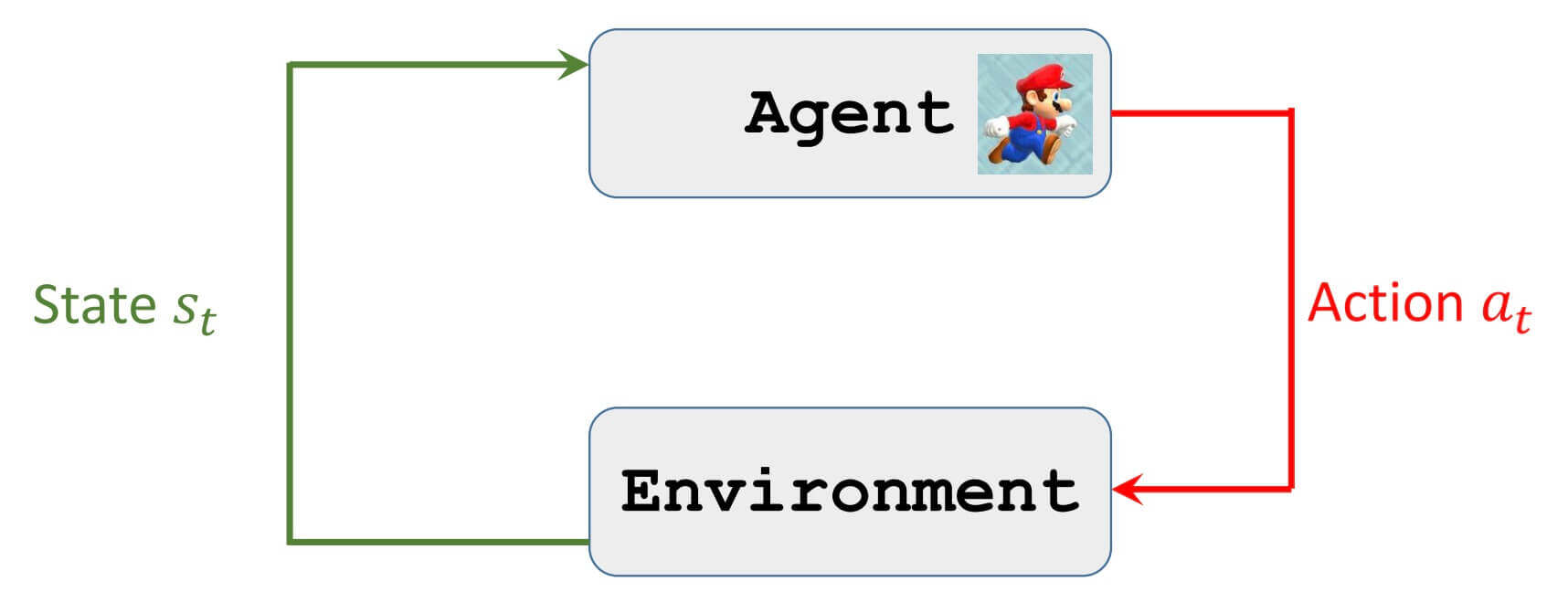
环境
《超级玛丽》这款游戏就是环境(Environment)。
状态
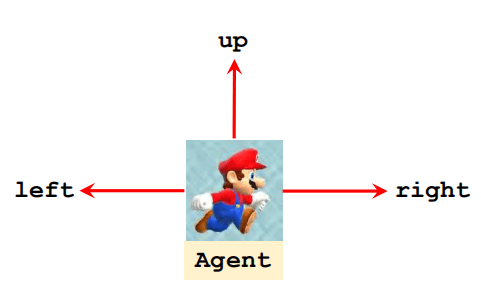
在这张图中,玛丽的上面有金币,右边有蘑菇,左边有乌龟,等等等等,总之就是这么个情况。这些共同构成了状态(State),用字母s s s
所有可能的状态的集合被称为状态空间(State Space),用花体字母S \mathcal{S} S
特别注意!在《超级玛丽》这款游戏中,我们可以说当前的画面就是状态,但是换一个游戏,就不一定。比如《王者荣耀》,因为在《王者荣耀》中,我们看到的画面并不是对当前情况的完整概括,毕竟总有时候,我们忽然就被偷塔了,这时候的我们看到的画面只是部分观测(Partial Observation)。
所以更为严格的说法是观察环境的状态s ( s ∈ S ) s(s \in \mathcal{S}) s ( s ∈ S ) o ( o ∈ O ) o(o \in \mathcal{O}) o ( o ∈ O ) s s s o o o
动作
我们回到游戏《超级玛丽》,在当前状态s s s
这就是动作(Action),用字母a a a 动作空间(Action Space),用花体字A \mathcal{A} A
智能体
做动作的主体就是智能体(Agent)。在这里,玛丽就是智能体。
策略
正如我们上文的讨论,状态是我们做决策的唯一依据。那么,我们怎么根据状态做出决策呢?π \pi π
π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a|s) = \mathbb{P}(A=a|S=s)
π ( a ∣ s ) = P ( A = a ∣ S = s )
比如,我们刚刚的例子中,当前的状态s s s
π ( l e f t ∣ s ) = 0.2 π ( r i g h t ∣ s ) = 0.1 π ( u p ∣ s ) = 0.7 \begin{aligned}
& \pi(left|s) = 0.2 \\
& \pi(right|s) = 0.1 \\
& \pi(up|s) = 0.7 \\
\end{aligned}
π ( l e f t ∣ s ) = 0 . 2 π ( r i g h t ∣ s ) = 0 . 1 π ( u p ∣ s ) = 0 . 7
那么,玛丽究竟会做什么动作呢?
这就是强化学习两个随机性来源中的一个,动作的随机性。
实际上,动作不一定是随机的。在我们这系列的笔记中,我们会见到大量的确定性策略,即在给定的状态下,智能体做出的动作也是固定的。
奖励
智能体执行一个动作之后,环境返回给智能体一个奖励(Reward)。
在《生活大爆炸》中,我们可以看到一个非常形象的过程。
收集金币:奖励 = +1
解救公主:奖励 = +10000
触碰蘑菇:奖励 = -10000
没有事情:奖励 = 0
特别的,我们还可以把收集金币设置大一些,解救公主设置小一些。(我只想捡金币,救公主只是顺带的。)
状态转移
状态转移(State Transition),顾名思义,由当前状态s s s s ′ s' s ′ s s s a a a s ′ s' s ′ s s s a a a s ′ s' s ′
比如在电影《大话西游》中,当前的状态s s s a a a
然后,状态就从s s s s ′ s' s ′ a a a
但更多情况下,状态转移函数不是确定的,而是服从某一个概率分布,毕竟不是每一次表白都会成功。
当玛丽在当前状态s s s a a a
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) p(s'|s,a) = \mathbb{P}(S' = s'|S = s,A = a)
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a )
这就是强化学习随机性的第二个来源,状态转移的随机性。
小结一下,在强化学习中,随机性有两个来源:
动作的随机性
状态转移的随机性
马尔可夫模型
最后,我们讨论一下,什么是马尔可夫模型(Markov Model),和马尔可夫决策过程(Markov Decision Process, MDP)有什么关系。
马尔可夫模型的特点是,当前的状态仅依赖于上一个状态。
p ( s t ∣ s t − 1 ) p(s_t|s_{t-1})
p ( s t ∣ s t − 1 )
而,现在我们假设,当前状态依赖于上一个状态和我们在上一个状态做的动作,这就是马尔可夫决策过程了。
p ( s t ∣ s t − 1 , a t − 1 ) p(s_t|s_{t-1},a_{t-1})
p ( s t ∣ s t − 1 , a t − 1 )
回报
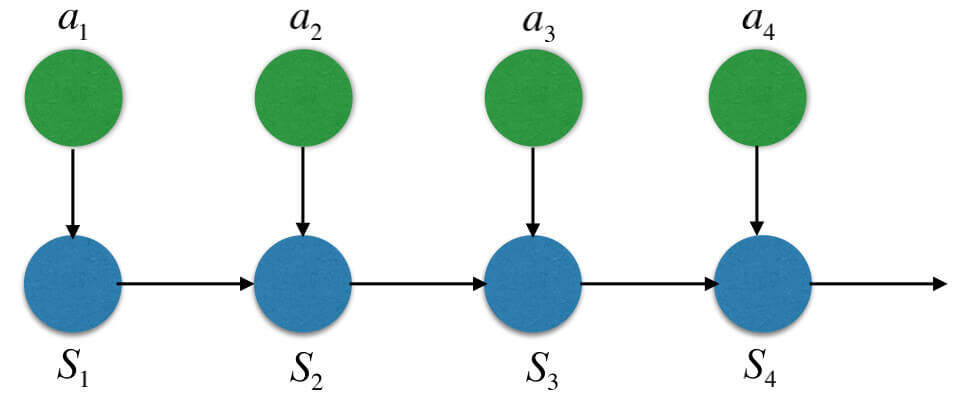
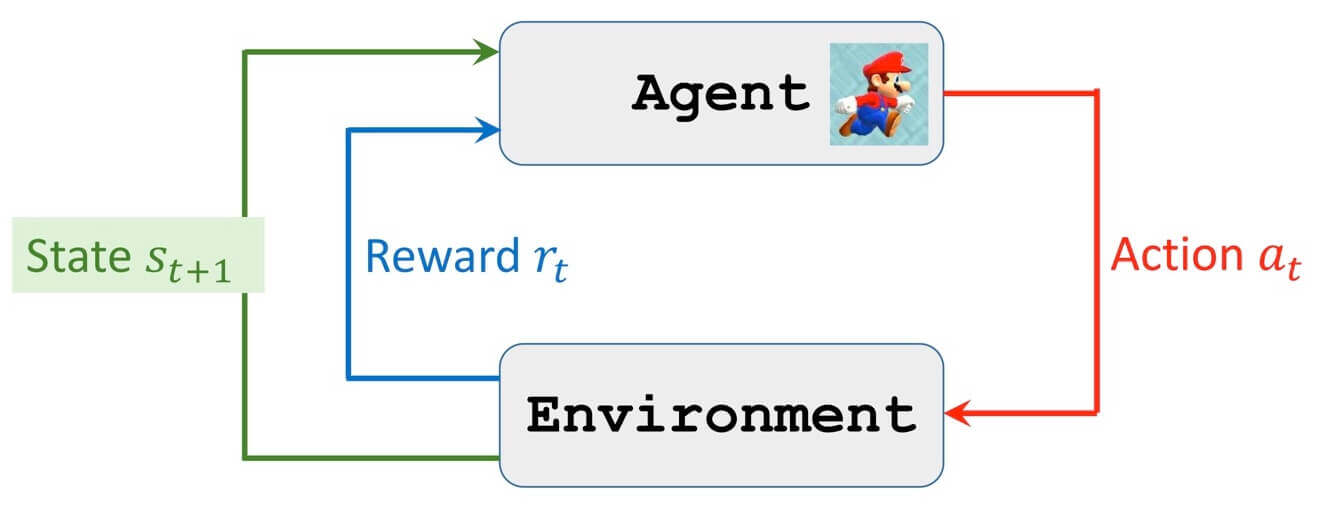
接下来,我们讨论回报(Return)。但在这之前,我们先看看智能体和环境的交互。
智能体和环境的交互
首先,智能体观测到环境给的状态s t s_t s t s t s_t s t a t a_t a t
然后,环境会根据s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1 r t r_{t} r t
上述过程循环往复,最后我们会得到:
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , s 3 , ⋯ s_1,a_1,r_1,s_2,a_2,r_2,s_3,\cdots
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , s 3 , ⋯
这就是轨迹(Trajectory),指一个回合(Episode)游戏中,智能体观测到的所有状态、做出的所有动作、收到的所有奖励。
提一个问题,在上文,我们还特别讨论了完全可观测的环境和部分可观测的环境,那么在一个部分可观测的环境中,轨迹应该是怎样的呢?
s 1 , o 1 , a 1 , r 1 , s 2 , o 2 , a 2 , r 2 , s 3 , ⋯ s_1,o_1,a_1,r_1,s_2,o_2,a_2,r_2,s_3,\cdots
s 1 , o 1 , a 1 , r 1 , s 2 , o 2 , a 2 , r 2 , s 3 , ⋯
也有一些资料把动作a t a_t a t r t + 1 r_{t+1} r t + 1 t t t s t s_t s t t t t a t a_t a t t + 1 t+1 t + 1 s t + 1 s_{t+1} s t + 1 t + 1 t+1 t + 1 r t + 1 r_{t+1} r t + 1
但我们还是把动作a t a_t a t r t r_{t} r t
回报
把未来的奖励累积起来,就是回报。R R R r r r G G G t t t
G t = R t + R t + 1 + R t + 2 + R t + 3 + ⋯ G_t = R_{t} + R_{t+1} + R_{t+2} + R_{t+3} + \cdots
G t = R t + R t + 1 + R t + 2 + R t + 3 + ⋯
但,就像在金融中,货币都有时间价值,今天的一块钱和明天的一块钱是不一样的,在这里奖励也有"时间价值"。γ \gamma γ γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ ∈ [ 0 , 1 ]
G t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ⋯ G_t = R_{t} + \gamma R_{t+1} + \gamma^2 R_{t+2} + \gamma^3 R_{t+3} + \cdots
G t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ⋯
而强化学习的目标是最大化回报,而不是最大化当前的奖励。毕竟,我们应该着眼于解救公主,而不是眼前的这一两枚金币。
回报的随机性
我们再来看看回报来源于什么?来源于未来的累积奖励。0 0 0 0 0 0 《2.动态规划》 的例子,冰面滑行。但是,每做一个动作,都有会收到一个奖励,只是有时候奖励的值为0 0 0
奖励是关于状态和动作的函数。G t G_t G t
A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n A_t,S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n}
A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n
当然没有S t S_t S t t t t s t s_t s t
如果动作还没做的话,A t A_t A t G t G_t G t A t A_t A t G t G_t G t
价值函数
动作价值函数
假设我们已经观测到了状态s t s_t s t a t a_t a t G t G_t G t G t G_t G t
S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n , ⋯ S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n},\cdots
S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n , ⋯
没关系,我们对这个随机变量求期望。g ( X , Y ) = X Y g(X,Y) = XY g ( X , Y ) = X Y X X X Y Y Y g ( X , Y ) g(X,Y) g ( X , Y ) X X X X X X G t G_t G t S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n} S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n
E S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n [ G t ∣ S t = s t , A t = a t ] \mathbb{E}_{S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n}}[G_t|S_t=s_t,A_t=a_t]
E S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n [ G t ∣ S t = s t , A t = a t ]
更多的时候,写作:
E [ G t ∣ S t = s t , A t = a t ] \mathbb{E}[G_t|S_t=s_t,A_t=a_t]
E [ G t ∣ S t = s t , A t = a t ]
这就是我们的动作价值函数(Action-Value Function),记做Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Q π ( s t , a t ) s t s_t s t a t a_t a t
Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Q π ( s t , a t ) s t s_t s t a t a_t a t t + 1 t+1 t + 1 S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n} S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n
状态价值函数
在讨论了什么是动作价值函数之后,状态价值函数(State-Value Function)就非常的简单。s t s_t s t s t s_t s t G t G_t G t
A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n A_t,S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n}
A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n
同样,我们对其求期望
E A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n [ G ∣ S t = s t ] \mathbb{E}_{A_t,S_{t+1},A_{t+1},S_{t+2},A_{t+2},\cdots,S_{n},A_{n}}[G|S_t=s_t]
E A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n [ G ∣ S t = s t ]
更多的时候,写作:
E [ G t ∣ S t = s t ] \mathbb{E}[G_t|S_t=s_t]
E [ G t ∣ S t = s t ]
这就是我们的状态价值函数,记做V π ( s t ) V_{\pi}(s_t) V π ( s t )
价值函数的性质
价值函数的性质,也就是Bellman期望方程(Bellman Expectation Equations),刻画的是状态价值函数和动作价值函数之间的关系。
可以用t t t t t t
可以用t + 1 t+1 t + 1 t t t
接下来,我们分别讨论。
可以用t t t t t t
状态价值函数是在当前状态s t s_t s t s t s_t s t a t a_t a t a t a_t a t t t t
V π ( s t ) = ∑ a t π ( a t ∣ s t ) Q π ( s t , a t ) V_{\pi}(s_t) = \sum_{a_t} \pi(a_t|s_t)Q_{\pi}(s_t,a_t) V π ( s t ) = a t ∑ π ( a t ∣ s t ) Q π ( s t , a t )
π ( a t ∣ s t ) \pi(a_t|s_t) π ( a t ∣ s t ) ∑ \sum ∑ 1 1 1
可以用t + 1 t+1 t + 1 t t t
这个也很好理解,在t t t s t s_t s t a t a_t a t r t r_{t} r t s t s_t s t s t + 1 s_{t+1} s t + 1
Q π ( s t , a t ) = r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) Q_{\pi}(s_t,a_t) = r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{\pi}(s_{t+1}) Q π ( s t , a t ) = r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 )
r ( s t , a t ) r(s_t,a_t) r ( s t , a t ) p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1
通过上述两个基本性质,又可以衍生出两个性质:
可以用t + 1 t+1 t + 1 t t t
可以用t + 1 t+1 t + 1 t t t
可以用t + 1 t+1 t + 1 t t t
正如我们上文的讨论,可以用t + 1 t+1 t + 1 t t t t t t t t t t + 1 t+1 t + 1 t t t
V π ( s t ) = ∑ a t π ( a t ∣ s t ) [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) ] V_{\pi}(s_t) = \sum_{a_t}\pi(a_t|s_t)\bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{\pi}(s_{t+1}) \bigg] V π ( s t ) = a t ∑ π ( a t ∣ s t ) [ r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) ]
可以用t + 1 t+1 t + 1 t t t
这个也很好理解,我们可以用t + 1 t+1 t + 1 t + 1 t+1 t + 1 t + 1 t+1 t + 1 t t t t + 1 t+1 t + 1 t t t
Q π ( s t , a t ) = ∑ s t + 1 , r p ( s t + 1 , r ∣ s t , a t ) [ r + γ ∑ a t + 1 π ( a t + 1 ∣ s t + 1 ) Q π ( s t + 1 , a t + 1 ) ] Q_{\pi}(s_t,a_t) = \sum_{s_{t+1},r} p(s_{t+1},r|s_t,a_t) \bigg[ r+ \gamma \sum_{a_{t+1}} \pi(a_{t+1}|s_{t+1})Q_{\pi}(s_{t+1},a_{t+1}) \bigg] Q π ( s t , a t ) = s t + 1 , r ∑ p ( s t + 1 , r ∣ s t , a t ) [ r + γ a t + 1 ∑ π ( a t + 1 ∣ s t + 1 ) Q π ( s t + 1 , a t + 1 ) ]
这也就是Bellman期望方程
也有资料认为:用动作价值表示状态价值、用状态价值表示动作价值不能称为Bellman方程,只有用动作价值表示动作价值、用状态价值表示状态价值才能称为Bellman方程。
求解价值函数
那么,上述的四个性质,都有什么用呢?
举个例子。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第二章。
假设,我们已知环境的状态转移如下:
s t s_t s t a t a_t a t r t r_{t} r t s t + 1 s_{t+1} s t + 1 p ( s t + 1 , r t ∣ s t , a t ) p(s_{t+1},r_{t} \mid s_t,a_t) p ( s t + 1 , r t ∣ s t , a t )
饿
不吃
− 2 -2 − 2 饿
1 1 1
饿
吃
2 2 2 饱
α \alpha α
饿
吃
1 1 1 饿
1 − α 1-\alpha 1 − α
饱
不吃
2 2 2 饱
β \beta β
饱
不吃
1 1 1 饿
1 − β 1-\beta 1 − β
饱
吃
0 0 0 饱
1 1 1
而我们的策略函数如下:
s s s a a a π ( a ∣ s ) \pi(a\mid s) π ( a ∣ s )
饿
不吃
1 − x 1-x 1 − x
饿
吃
x x x
饱
不吃
y y y
饱
吃
1 − y 1-y 1 − y
根据状态价值函数的定义,我们有
V π ( 饿 ) = E π [ G ∣ S = 饿 ] V π ( 饱 ) = E π [ G ∣ S = 饱 ] Q π ( 饿 , 吃 ) = E π [ G ∣ S = 饿 , A = 吃 ] Q π ( 饿 , 不吃 ) = E π [ G ∣ S = 饿 , A = 不吃 ] Q π ( 饱 , 吃 ) = E π [ G ∣ S = 饱 , A = 吃 ] Q π ( 饱 , 不吃 ) = E π [ G ∣ S = 饱 , A = 不吃 ] \begin{aligned}
& V_{\pi}(\text{饿}) = \mathbb{E}_{\pi}[G|S=\text{饿}] \\
& V_{\pi}(\text{饱}) = \mathbb{E}_{\pi}[G|S=\text{饱}] \\
& Q_{\pi}(\text{饿},\text{吃}) = \mathbb{E}_{\pi}[G|S=\text{饿},A=\text{吃}] \\
& Q_{\pi}(\text{饿},\text{不吃}) = \mathbb{E}_{\pi}[G|S=\text{饿},A=\text{不吃}] \\
& Q_{\pi}(\text{饱},\text{吃}) = \mathbb{E}_{\pi}[G|S=\text{饱},A=\text{吃}] \\
& Q_{\pi}(\text{饱},\text{不吃}) = \mathbb{E}_{\pi}[G|S=\text{饱},A=\text{不吃}]
\end{aligned}
V π ( 饿 ) = E π [ G ∣ S = 饿 ] V π ( 饱 ) = E π [ G ∣ S = 饱 ] Q π ( 饿 , 吃 ) = E π [ G ∣ S = 饿 , A = 吃 ] Q π ( 饿 , 不吃 ) = E π [ G ∣ S = 饿 , A = 不吃 ] Q π ( 饱 , 吃 ) = E π [ G ∣ S = 饱 , A = 吃 ] Q π ( 饱 , 不吃 ) = E π [ G ∣ S = 饱 , A = 不吃 ]
根据Bellman期望方程,用动作价值表示状态价值
V π ( s t ) = ∑ a t π ( a t ∣ s t ) Q π ( s t , a t ) V_{\pi}(s_t) = \sum_{a_t} \pi(a_t|s_t)Q_{\pi}(s_t,a_t)
V π ( s t ) = a t ∑ π ( a t ∣ s t ) Q π ( s t , a t )
我们有
V π ( 饿 ) = ( 1 − x ) Q π ( 饿 , 不吃 ) + x Q π ( 饿 , 吃 ) V π ( 饱 ) = y Q π ( 饱 , 不吃 ) + ( 1 − y ) Q π ( 饱 , 吃 ) \begin{aligned}
& V_{\pi}(\text{饿}) = (1-x)Q_{\pi}(\text{饿},\text{不吃}) + xQ_{\pi}(\text{饿},\text{吃}) \\
& V_{\pi}(\text{饱}) = yQ_{\pi}(\text{饱},\text{不吃}) + (1-y)Q_{\pi}(\text{饱},\text{吃}) \\
\end{aligned}
V π ( 饿 ) = ( 1 − x ) Q π ( 饿 , 不吃 ) + x Q π ( 饿 , 吃 ) V π ( 饱 ) = y Q π ( 饱 , 不吃 ) + ( 1 − y ) Q π ( 饱 , 吃 )
根据Bellman期望函数,用状态价值表示动作价值
Q π ( s t , a t ) = r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) Q_{\pi}(s_t,a_t) = r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{\pi}(s_{t+1})
Q π ( s t , a t ) = r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 )
比如:s t = 饿 s_t=\text{饿} s t = 饿 a = 不吃 a=\text{不吃} a = 不吃 s t + 1 s_{t+1} s t + 1 饿 \text{饿} 饿
Q π ( 饿 , 不吃 ) = − 2 + γ V π ( 饿 ) + 0 Q_{\pi}(\text{饿},\text{不吃}) = -2 + \gamma V_{\pi}(\text{饿}) + 0
Q π ( 饿 , 不吃 ) = − 2 + γ V π ( 饿 ) + 0
当s t = 饿 s_t = \text{饿} s t = 饿 a = 吃 a=\text{吃} a = 吃 α \alpha α s t + 1 = 饱 s_{t+1} = \text{饱} s t + 1 = 饱 1 − α 1-\alpha 1 − α s t + 1 = 饿 s_{t+1} = \text{饿} s t + 1 = 饿
Q π ( 饿 , 吃 ) = α ( 2 + γ V π ( 饱 ) ) + ( 1 − α ) ( 1 + γ V π ( 饿 ) ) Q_{\pi}(\text{饿},\text{吃}) = \alpha (2 + \gamma V_{\pi}(\text{饱})) + (1-\alpha)(1 + \gamma V_{\pi}(\text{饿}))
Q π ( 饿 , 吃 ) = α ( 2 + γ V π ( 饱 ) ) + ( 1 − α ) ( 1 + γ V π ( 饿 ) )
同理,我们有如下的式子
Q π ( 饱 , 不吃 ) = β ( 2 + γ V π ( 饱 ) ) + ( 1 − β ) ( 1 + γ V π ( 饿 ) ) Q π ( 饱 , 吃 ) = 0 + γ V π ( 饱 ) + 0 \begin{aligned}
& Q_{\pi}(\text{饱},\text{不吃}) = \beta (2 + \gamma V_{\pi}(\text{饱})) + (1 - \beta)(1 + \gamma V_{\pi}(\text{饿})) \\
& Q_{\pi}(\text{饱},\text{吃}) = 0 + \gamma V_{\pi}(\text{饱}) + 0
\end{aligned}
Q π ( 饱 , 不吃 ) = β ( 2 + γ V π ( 饱 ) ) + ( 1 − β ) ( 1 + γ V π ( 饿 ) ) Q π ( 饱 , 吃 ) = 0 + γ V π ( 饱 ) + 0
通过这个,我们就构建了一个方程组,然后其中未知数就是状态价值和动作价值,六个方程,六个未知数(暂时把α , β , γ , x , y \alpha,\beta,\gamma,x,y α , β , γ , x , y
在这里介绍一个Python的包:sympy。C = 0 C=0 C = 0
但是我想解方程组还是没问题的。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import sympyfrom sympy import symbolsfrom sympy import solvefrom sympy import Eqfrom sympy import latexv_hungry = symbols('v_hungry' ) v_full = symbols('v_full' ) q_hungry_eat = symbols('q_hungry_eat' ) q_hungry_dont_eat = symbols('q_hungry_dont_eat' ) q_full_eat = symbols('q_full_eat' ) q_full_dont_eat = symbols('q_full_dont_eat' ) alpha = symbols('alpha' ) beta = symbols('beta' ) gamma = symbols('gamma' ) x = symbols('x' ) y = symbols('y' ) ans = solve([Eq((1 - x) * q_hungry_dont_eat + x * q_hungry_eat, v_hungry), Eq(y * q_full_dont_eat + (1 - y) * q_full_eat, v_full), Eq(-2 + gamma * v_hungry, q_hungry_dont_eat), Eq(alpha * (2 + gamma * v_full) + (1 - alpha) * (1 + gamma * v_hungry), q_hungry_eat), Eq(beta * (2 + gamma * v_full) + (1 - beta) * (1 + gamma * v_hungry), q_full_dont_eat), Eq(gamma * v_full, q_full_eat)], [v_hungry, v_full, q_hungry_eat, q_hungry_dont_eat, q_full_eat, q_full_dont_eat]) for k,v in ans.items(): print(k) print(v) print(latex(v))
运行结果:
1 2 v_hungry (-2*alpha*gamma*x*y + alpha*gamma*x - alpha*x + 3*beta*gamma*x*y - 2*beta*gamma*y - 3*gamma*x*y + 3*gamma*x + 2*gamma*y - 2*gamma - 3*x + 2)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ x y + α γ x − α x + 3 β γ x y − 2 β γ y − 3 γ x y + 3 γ x + 2 γ y − 2 γ − 3 x + 2 α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma x y + \alpha \gamma x - \alpha x + 3 \beta \gamma x y - 2 \beta \gamma y - 3 \gamma x y + 3 \gamma x + 2 \gamma y - 2 \gamma - 3 x + 2}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ x y + α γ x − α x + 3 β γ x y − 2 β γ y − 3 γ x y + 3 γ x + 2 γ y − 2 γ − 3 x + 2
1 2 v_full (-2*alpha*gamma*x*y + 3*beta*gamma*x*y - beta*gamma*y - beta*y - 3*gamma*x*y + 3*gamma*y - y)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ x y + 3 β γ x y − β γ y − β y − 3 γ x y + 3 γ y − y α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma x y + 3 \beta \gamma x y - \beta \gamma y - \beta y - 3 \gamma x y + 3 \gamma y - y}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ x y + 3 β γ x y − β γ y − β y − 3 γ x y + 3 γ y − y
1 2 q_hungry_eat (-2*alpha*gamma**2*x*y - alpha*gamma**2*x + 2*alpha*gamma**2*y + alpha*gamma**2 + alpha*gamma*x - 2*alpha*gamma*y - alpha + 3*beta*gamma**2*x*y - 3*beta*gamma**2*y + beta*gamma*y - 3*gamma**2*x*y + 3*gamma**2*x + 3*gamma**2*y - 3*gamma**2 - 3*gamma*x - gamma*y + 4*gamma - 1)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ 2 x y − α γ 2 x + 2 α γ 2 y + α γ 2 + α γ x − 2 α γ y − α + 3 β γ 2 x y − 3 β γ 2 y + β γ y − 3 γ 2 x y + 3 γ 2 x + 3 γ 2 y − 3 γ 2 − 3 γ x − γ y + 4 γ − 1 α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma^{2} x y - \alpha \gamma^{2} x + 2 \alpha \gamma^{2} y + \alpha \gamma^{2} + \alpha \gamma x - 2 \alpha \gamma y - \alpha + 3 \beta \gamma^{2} x y - 3 \beta \gamma^{2} y + \beta \gamma y - 3 \gamma^{2} x y + 3 \gamma^{2} x + 3 \gamma^{2} y - 3 \gamma^{2} - 3 \gamma x - \gamma y + 4 \gamma - 1}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ 2 x y − α γ 2 x + 2 α γ 2 y + α γ 2 + α γ x − 2 α γ y − α + 3 β γ 2 x y − 3 β γ 2 y + β γ y − 3 γ 2 x y + 3 γ 2 x + 3 γ 2 y − 3 γ 2 − 3 γ x − γ y + 4 γ − 1
1 2 q_hungry_dont_eat (-2*alpha*gamma**2*x*y - alpha*gamma**2*x + alpha*gamma*x + 3*beta*gamma**2*x*y - 2*beta*gamma*y - 3*gamma**2*x*y + 3*gamma**2*x - 3*gamma*x + 2*gamma*y - 2*gamma + 2)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ 2 x y − α γ 2 x + α γ x + 3 β γ 2 x y − 2 β γ y − 3 γ 2 x y + 3 γ 2 x − 3 γ x + 2 γ y − 2 γ + 2 α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma^{2} x y - \alpha \gamma^{2} x + \alpha \gamma x + 3 \beta \gamma^{2} x y - 2 \beta \gamma y - 3 \gamma^{2} x y + 3 \gamma^{2} x - 3 \gamma x + 2 \gamma y - 2 \gamma + 2}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ 2 x y − α γ 2 x + α γ x + 3 β γ 2 x y − 2 β γ y − 3 γ 2 x y + 3 γ 2 x − 3 γ x + 2 γ y − 2 γ + 2
1 2 q_full_eat (-2*alpha*gamma**2*x*y + 3*beta*gamma**2*x*y - beta*gamma**2*y - beta*gamma*y - 3*gamma**2*x*y + 3*gamma**2*y - gamma*y)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ 2 x y + 3 β γ 2 x y − β γ 2 y − β γ y − 3 γ 2 x y + 3 γ 2 y − γ y α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma^{2} x y + 3 \beta \gamma^{2} x y - \beta \gamma^{2} y - \beta \gamma y - 3 \gamma^{2} x y + 3 \gamma^{2} y - \gamma y}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ 2 x y + 3 β γ 2 x y − β γ 2 y − β γ y − 3 γ 2 x y + 3 γ 2 y − γ y
1 2 q_full_dont_eat (-2*alpha*gamma**2*x*y + 2*alpha*gamma**2*x - 2*alpha*gamma*x + 3*beta*gamma**2*x*y - 3*beta*gamma**2*x - beta*gamma**2*y + beta*gamma**2 + 3*beta*gamma*x - beta*gamma*y - beta - 3*gamma**2*x*y + 3*gamma**2*x + 3*gamma**2*y - 3*gamma**2 - 3*gamma*x - gamma*y + 4*gamma - 1)/(alpha*gamma**2*x - alpha*gamma*x - beta*gamma**2*y + beta*gamma*y + gamma**2*y - gamma**2 - gamma*y + 2*gamma - 1)
− 2 α γ 2 x y + 2 α γ 2 x − 2 α γ x + 3 β γ 2 x y − 3 β γ 2 x − β γ 2 y + β γ 2 + 3 β γ x − β γ y − β − 3 γ 2 x y + 3 γ 2 x + 3 γ 2 y − 3 γ 2 − 3 γ x − γ y + 4 γ − 1 α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 \frac{- 2 \alpha \gamma^{2} x y + 2 \alpha \gamma^{2} x - 2 \alpha \gamma x + 3 \beta \gamma^{2} x y - 3 \beta \gamma^{2} x - \beta \gamma^{2} y + \beta \gamma^{2} + 3 \beta \gamma x - \beta \gamma y - \beta - 3 \gamma^{2} x y + 3 \gamma^{2} x + 3 \gamma^{2} y - 3 \gamma^{2} - 3 \gamma x - \gamma y + 4 \gamma - 1}{\alpha \gamma^{2} x - \alpha \gamma x - \beta \gamma^{2} y + \beta \gamma y + \gamma^{2} y - \gamma^{2} - \gamma y + 2 \gamma - 1}
α γ 2 x − α γ x − β γ 2 y + β γ y + γ 2 y − γ 2 − γ y + 2 γ − 1 − 2 α γ 2 x y + 2 α γ 2 x − 2 α γ x + 3 β γ 2 x y − 3 β γ 2 x − β γ 2 y + β γ 2 + 3 β γ x − β γ y − β − 3 γ 2 x y + 3 γ 2 x + 3 γ 2 y − 3 γ 2 − 3 γ x − γ y + 4 γ − 1
这样的话,我们可以知道每一个状态的价值,每一个动作的价值。
最优价值函数
为什么需要最优价值函数
通过上文的讨论,我们可以知道每一个状态的价值,每一个动作的价值。那么,我们就在每次做决策的时候,选择价值最大的一个动作。Q π ( 饿 , 吃 ) Q_{\pi}(\text{饿},\text{吃}) Q π ( 饿 , 吃 ) Q π ( 饿 , 不吃 ) Q_{\pi}(\text{饿},\text{不吃}) Q π ( 饿 , 不吃 ) α , β , γ , x , y \alpha,\beta,\gamma,x,y α , β , γ , x , y α , β , γ , x , y \alpha,\beta,\gamma,x,y α , β , γ , x , y π \pi π s s s a = 撤退 a=\text{撤退} a = 撤退 A A A S S S A A A s s s a a a π \pi π π \pi π a a a π \pi π 最优状态价值函数(optimal state value function):
V ⋆ ( s ) = max π V π ( s ) , s ∈ S V_{\star}(s) = \max_{\pi}V_{\pi}(s),\ s\in\mathcal{S}
V ⋆ ( s ) = π max V π ( s ) , s ∈ S
最优动作价值函数(optimal action value function):
Q ⋆ ( s , a ) = max π Q π ( s , a ) , s ∈ S , a ∈ A Q_{\star}(s,a) = \max_{\pi}Q_{\pi}(s,a),\ s\in\mathcal{S},a\in\mathcal{A}
Q ⋆ ( s , a ) = π max Q π ( s , a ) , s ∈ S , a ∈ A
所以,我们每次依据最优价值函数,来选择动作,这样实际上也就得到了一个最优的策略。
最优价值函数的性质
与价值函数一样,最优价值函数的性质也就是Bellman方程。
可以用t t t t t t
可以用t + 1 t+1 t + 1 t t t
可以用t t t t t t
在上一小节,我们是求期望,因为动作是抽样出来的,但是现在我们直接选择最佳动作,就不抽样了。
V s t = max a ∈ A Q ∗ ( s t , a t ) V_{s_t} = \max_{a\in\mathcal{A}}Q_{*}(s_t,a_t) V s t = a ∈ A max Q ∗ ( s t , a t )
可以用t + 1 t+1 t + 1 t t t
在上一小节中,我们是求期望,因为状态转移方程其实是一个概率质量函数(或概率密度函数),这次我们直接选择最佳的状态,就不抽样了。
错了! \bold{\text{错了!}} 错了!
状态转移是由环境所控制的,我们并不能直接控制状态转移。
Q ⋆ ( s t , a t ) = r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 ) Q_{\star}(s_t,a_t) = r(s_t,a_t) + \gamma \sum_{s_{t+1}}p(s_{t+1|s_t,a_t})V_{\star}(s_{t+1}) Q ⋆ ( s t , a t ) = r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 )
与上文一样,我们可以用t + 1 t+1 t + 1 t t t t t t t t t
可以用t + 1 t+1 t + 1 t t t
V ⋆ ( s t ) = max a ∈ A [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 ) ] V_{\star}(s_t) = \max_{a\in\mathcal{A}} \bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_{t},a_{t}) V_{\star}(s_{t+1}) \bigg] V ⋆ ( s t ) = a ∈ A max [ r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 ) ]
同理
可以用t + 1 t+1 t + 1 t t t
Q ⋆ ( s t , a t ) = r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) max a t + 1 Q ⋆ ( s t + 1 , a t + 1 ) Q_{\star}(s_t,a_t) = r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) \max_{a_{t+1}}Q_{\star}(s_{t+1},a_{t+1}) Q ⋆ ( s t , a t ) = r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) a t + 1 max Q ⋆ ( s t + 1 , a t + 1 )
求解最优价值函数
我们同样可以列出方程组:
V ⋆ ( 饿 ) = max { Q ⋆ ( 饿 , 不吃 ) , Q ⋆ ( 饿 , 吃 ) } V ⋆ ( 饱 ) = max { Q ⋆ ( 饱 , 不吃 ) , Q ⋆ ( 饱 , 吃 ) } Q ⋆ ( 饿 , 不吃 ) = − 2 + γ V ⋆ ( 饿 ) + 0 Q ⋆ ( 饿 , 吃 ) = α ( 2 + γ V ⋆ ( 饱 ) ) + ( 1 − α ) ( 1 + γ V ⋆ ( 饿 ) ) Q ⋆ ( 饱 , 不吃 ) = β ( 2 + γ V ⋆ ( 饱 ) ) + ( 1 − β ) ( 1 + γ V ⋆ ( 饿 ) ) Q ⋆ ( 饱 , 吃 ) = 0 + γ V ⋆ ( 饱 ) + 0 \begin{aligned}
V_{\star}(\text{饿}) &= \max\{Q_{\star}(\text{饿},\text{不吃}),Q_{\star}(\text{饿},\text{吃})\} \\
V_{\star}(\text{饱}) &= \max\{Q_{\star}(\text{饱},\text{不吃}),Q_{\star}(\text{饱},\text{吃})\} \\
Q_{\star}(\text{饿},\text{不吃}) &= -2 + \gamma V_{\star}(\text{饿}) + 0 \\
Q_{\star}(\text{饿},\text{吃}) &= \alpha (2 + \gamma V_{\star}(\text{饱})) + (1-\alpha)(1 + \gamma V_{\star}(\text{饿})) \\
Q_{\star}(\text{饱},\text{不吃}) &= \beta (2 + \gamma V_{\star}(\text{饱})) + (1 - \beta)(1 + \gamma V_{\star}(\text{饿})) \\
Q_{\star}(\text{饱},\text{吃}) &= 0 + \gamma V_{\star}(\text{饱}) + 0
\end{aligned}
V ⋆ ( 饿 ) V ⋆ ( 饱 ) Q ⋆ ( 饿 , 不吃 ) Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饱 , 不吃 ) Q ⋆ ( 饱 , 吃 ) = max { Q ⋆ ( 饿 , 不吃 ) , Q ⋆ ( 饿 , 吃 ) } = max { Q ⋆ ( 饱 , 不吃 ) , Q ⋆ ( 饱 , 吃 ) } = − 2 + γ V ⋆ ( 饿 ) + 0 = α ( 2 + γ V ⋆ ( 饱 ) ) + ( 1 − α ) ( 1 + γ V ⋆ ( 饿 ) ) = β ( 2 + γ V ⋆ ( 饱 ) ) + ( 1 − β ) ( 1 + γ V ⋆ ( 饿 ) ) = 0 + γ V ⋆ ( 饱 ) + 0
对于这个方程组,同样可以用sympy求解,求解方法与上文的基本相同,但是需要注意的是。
Q ⋆ ( 饿 , 不吃 ) ≥ Q ⋆ ( 饿 , 吃 ) Q_{\star}(\text{饿},\text{不吃}) \geq Q_{\star}(\text{饿},\text{吃}) Q ⋆ ( 饿 , 不吃 ) ≥ Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饱 , 不吃 ) ≥ Q ⋆ ( 饱 , 吃 ) Q_{\star}(\text{饱},\text{不吃}) \geq Q_{\star}(\text{饱},\text{吃}) Q ⋆ ( 饱 , 不吃 ) ≥ Q ⋆ ( 饱 , 吃 ) Q ⋆ ( 饿 , 不吃 ) ≥ Q ⋆ ( 饿 , 吃 ) Q_{\star}(\text{饿},\text{不吃}) \geq Q_{\star}(\text{饿},\text{吃}) Q ⋆ ( 饿 , 不吃 ) ≥ Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饱 , 不吃 ) < Q ⋆ ( 饱 , 吃 ) Q_{\star}(\text{饱},\text{不吃}) < Q_{\star}(\text{饱},\text{吃}) Q ⋆ ( 饱 , 不吃 ) < Q ⋆ ( 饱 , 吃 ) Q ⋆ ( 饿 , 不吃 ) < Q ⋆ ( 饿 , 吃 ) Q_{\star}(\text{饿},\text{不吃}) < Q_{\star}(\text{饿},\text{吃}) Q ⋆ ( 饿 , 不吃 ) < Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饱 , 不吃 ) ≥ Q ⋆ ( 饱 , 吃 ) Q_{\star}(\text{饱},\text{不吃}) \geq Q_{\star}(\text{饱},\text{吃}) Q ⋆ ( 饱 , 不吃 ) ≥ Q ⋆ ( 饱 , 吃 ) Q ⋆ ( 饿 , 不吃 ) < Q ⋆ ( 饿 , 吃 ) Q_{\star}(\text{饿},\text{不吃}) < Q_{\star}(\text{饿},\text{吃}) Q ⋆ ( 饿 , 不吃 ) < Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饱 , 不吃 ) < Q ⋆ ( 饱 , 吃 ) Q_{\star}(\text{饱},\text{不吃}) < Q_{\star}(\text{饱},\text{吃}) Q ⋆ ( 饱 , 不吃 ) < Q ⋆ ( 饱 , 吃 )
比如,对于第一种情况,我们的求解代码如下:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from sympy import symbolsfrom sympy import solvefrom sympy import Eqfrom sympy import latexv_hungry = symbols('v_hungry' ) v_full = symbols('v_full' ) q_hungry_eat = symbols('q_hungry_eat' ) q_hungry_dont_eat = symbols('q_hungry_dont_eat' ) q_full_eat = symbols('q_full_eat' ) q_full_dont_eat = symbols('q_full_dont_eat' ) alpha = symbols('alpha' ) beta = symbols('beta' ) gamma = symbols('gamma' ) ans = solve([Eq(q_hungry_dont_eat, v_hungry), Eq(q_full_dont_eat, v_full), Eq(-2 + gamma * v_hungry, q_hungry_dont_eat), Eq(alpha * (2 + gamma * v_full) + (1 - alpha) * (1 + gamma * v_hungry), q_hungry_eat), Eq(beta * (2 + gamma * v_full) + (1 - beta) * (1 + gamma * v_hungry), q_full_dont_eat), Eq(gamma * v_full, q_full_eat)], [v_hungry, v_full, q_hungry_eat, q_hungry_dont_eat, q_full_eat, q_full_dont_eat]) for k, v in ans.items(): print(k) print(v) print(latex(v))
运行结果:
2 γ − 1 \frac{2}{\gamma - 1}
γ − 1 2
1 2 v_full (beta*gamma + beta - 3*gamma + 1)/(beta*gamma**2 - beta*gamma - gamma + 1)
β γ + β − 3 γ + 1 β γ 2 − β γ − γ + 1 \frac{\beta \gamma + \beta - 3 \gamma + 1}{\beta \gamma^{2} - \beta \gamma - \gamma + 1}
β γ 2 − β γ − γ + 1 β γ + β − 3 γ + 1
1 2 q_hungry_eat (-3*alpha*gamma**2 + 2*alpha*gamma + alpha + 3*beta*gamma**2 - beta*gamma - 3*gamma + 1)/(beta*gamma**2 - beta*gamma - gamma + 1)
− 3 α γ 2 + 2 α γ + α + 3 β γ 2 − β γ − 3 γ + 1 β γ 2 − β γ − γ + 1 \frac{- 3 \alpha \gamma^{2} + 2 \alpha \gamma + \alpha + 3 \beta \gamma^{2} - \beta \gamma - 3 \gamma + 1}{\beta \gamma^{2} - \beta \gamma - \gamma + 1}
β γ 2 − β γ − γ + 1 − 3 α γ 2 + 2 α γ + α + 3 β γ 2 − β γ − 3 γ + 1
1 2 q_hungry_dont_eat 2/(gamma - 1)
2 γ − 1 \frac{2}{\gamma - 1}
γ − 1 2
1 2 q_full_eat (beta*gamma**2 + beta*gamma - 3*gamma**2 + gamma)/(beta*gamma**2 - beta*gamma - gamma + 1)
β γ 2 + β γ − 3 γ 2 + γ β γ 2 − β γ − γ + 1 \frac{\beta \gamma^{2} + \beta \gamma - 3 \gamma^{2} + \gamma}{\beta \gamma^{2} - \beta \gamma - \gamma + 1}
β γ 2 − β γ − γ + 1 β γ 2 + β γ − 3 γ 2 + γ
1 2 q_full_dont_eat (beta*gamma + beta - 3*gamma + 1)/(beta*gamma**2 - beta*gamma - gamma + 1)
β γ + β − 3 γ + 1 β γ 2 − β γ − γ + 1 \frac{\beta \gamma + \beta - 3 \gamma + 1}{\beta \gamma^{2} - \beta \gamma - \gamma + 1}
β γ 2 − β γ − γ + 1 β γ + β − 3 γ + 1
对于其他情况,代码类似,主要区别在与
V ⋆ ( 饿 ) = max { Q ⋆ ( 饿 , 不吃 ) , Q ⋆ ( 饿 , 吃 ) } V ⋆ ( 饱 ) = max { Q ⋆ ( 饱 , 不吃 ) , Q ⋆ ( 饱 , 吃 ) } \begin{aligned}
V_{\star}(\text{饿}) &= \max\{Q_{\star}(\text{饿},\text{不吃}),Q_{\star}(\text{饿},\text{吃})\} \\
V_{\star}(\text{饱}) &= \max\{Q_{\star}(\text{饱},\text{不吃}),Q_{\star}(\text{饱},\text{吃})\}
\end{aligned}
V ⋆ ( 饿 ) V ⋆ ( 饱 ) = max { Q ⋆ ( 饿 , 不吃 ) , Q ⋆ ( 饿 , 吃 ) } = max { Q ⋆ ( 饱 , 不吃 ) , Q ⋆ ( 饱 , 吃 ) }
即,主要区别在于这两行:
1 2 q_hungry_dont_eat - v_hungry, q_full_dont_eat - v_full,
如果直接给出了α \alpha α β \beta β γ \gamma γ
α = 2 3 β = 3 4 γ = 4 5 \alpha=\frac{2}{3} \quad \beta=\frac{3}{4} \quad \gamma=\frac{4}{5}
α = 3 2 β = 4 3 γ = 5 4
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from sympy import symbolsfrom sympy import solvefrom sympy import Eqfrom sympy import maximumv_hungry = symbols('v_hungry' ) v_full = symbols('v_full' ) q_hungry_eat = symbols('q_hungry_eat' ) q_hungry_dont_eat = symbols('q_hungry_dont_eat' ) q_full_eat = symbols('q_full_eat' ) q_full_dont_eat = symbols('q_full_dont_eat' ) alpha = 2.0 /3.0 beta = 3.0 /4.0 gamma = 4.0 /5.0 ans = solve([Eq(maximum(q_hungry_eat, q_hungry_dont_eat), v_hungry), Eq(maximum(q_full_eat, q_full_dont_eat), v_full), Eq(-2 + gamma * v_hungry, q_hungry_dont_eat), Eq(alpha * (2 + gamma * v_full) + (1 - alpha) * (1 + gamma * v_hungry), q_hungry_eat), Eq(beta * (2 + gamma * v_full) + (1 - beta) * (1 + gamma * v_hungry), q_full_dont_eat), Eq(gamma * v_full, q_full_eat)], [v_hungry, v_full, q_hungry_eat, q_hungry_dont_eat, q_full_eat, q_full_dont_eat]) for k, v in ans.items(): print(k) print(v)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 v_hungry 2.27272727272727 v_full 0.0 q_hungry_eat 2.27272727272727 q_hungry_dont_eat -0.181818181818182 q_full_eat 0.0 q_full_dont_eat 2.20454545454545
即:
Q ⋆ ( 饿 , 吃 ) ≈ 2.2 Q ⋆ ( 饿 , 不吃 ) ≈ − 0.2 Q ⋆ ( 饱 , 吃 ) ≈ 0.0 Q ⋆ ( 饿 , 不吃 ) ≈ 2.2 \begin{aligned}
Q_{\star}(\text{饿},\text{吃}) &\approx 2.2 \\
Q_{\star}(\text{饿},\text{不吃}) &\approx -0.2 \\
Q_{\star}(\text{饱},\text{吃}) &\approx 0.0 \\
Q_{\star}(\text{饿},\text{不吃}) &\approx 2.2 \\
\end{aligned}
Q ⋆ ( 饿 , 吃 ) Q ⋆ ( 饿 , 不吃 ) Q ⋆ ( 饱 , 吃 ) Q ⋆ ( 饿 , 不吃 ) ≈ 2 . 2 ≈ − 0 . 2 ≈ 0 . 0 ≈ 2 . 2
即:
π ( 吃 ∣ 饿 ) = 1 π ( 不吃 ∣ 饿 ) = 0 π ( 吃 ∣ 饱 ) = 0 π ( 不吃 ∣ 饱 ) = 1 \begin{aligned}
\pi(\text{吃}\mid\text{饿}) &= 1 \\
\pi(\text{不吃}\mid\text{饿}) &= 0 \\
\pi(\text{吃}\mid\text{饱}) &= 0 \\
\pi(\text{不吃}\mid\text{饱}) &= 1 \\
\end{aligned}
π ( 吃 ∣ 饿 ) π ( 不吃 ∣ 饿 ) π ( 吃 ∣ 饱 ) π ( 不吃 ∣ 饱 ) = 1 = 0 = 0 = 1
关于风险的讨论
再回过头看看我们讨论的价值函数和最优价值函数,其实我们都在做一件事情:对回报求期望。
我们这一系列的笔记,讨论的都是"风险中性的强化学习"。