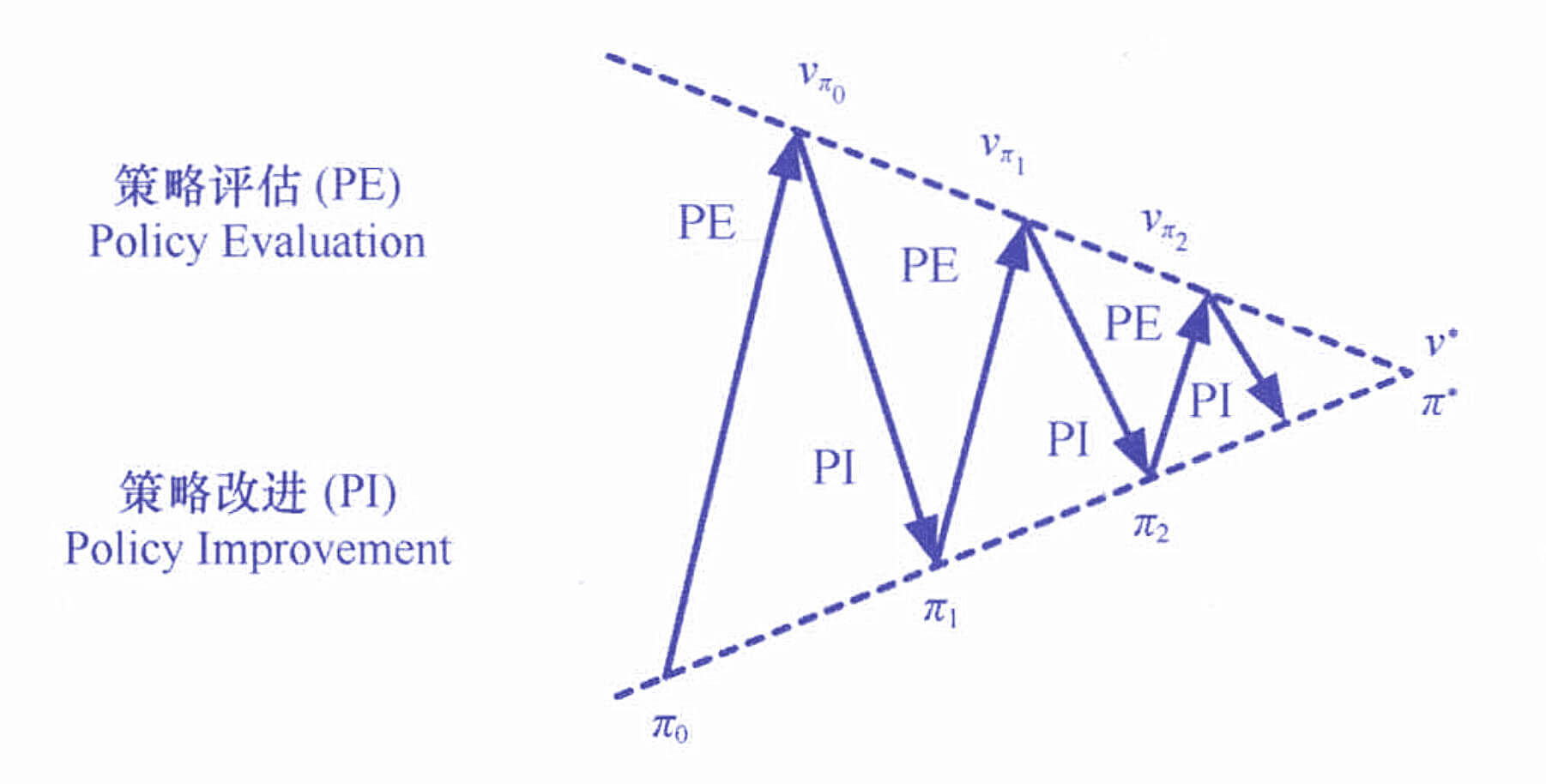
在上一章,我们通过Bellman最优方程求解了最优策略。但我们也看到我们只有两个状态,两个动作。而且,其实我们考虑的只是s 1 , a 1 , r 1 , s 2 s_1,a_1,r_1,s_2 s 1 , a 1 , r 1 , s 2 动态规划 《算法入门经典(Java与Python描述):11.动态规划》 中,我们也讨论过动态规划,当时主要是讨论了一种把代码从递归改成动态规划的技巧。这次我们讨论利用动态规划的方法求解强化学习。
动态规划的前提是环境已知,在强化学习中,被称为"模型已知"或"有模型"。是强化学习中的Planning问题。
我们的思路是"迭代出一个最优策略",我们从任意一个策略出发,一步一步逼近最优策略。
当前策略到底怎么样?策略评估
如果当前策略不行,怎么改进?策略改进
上述两步,循环往复,迭代。策略迭代
策略评估
策略评估的方法
怎么评估一个策略的好坏?
在上一章,我们讨论了两个东西,状态价值和动作价值。而且我们当时还举了这么一个例子:在相同的状态s s s a = 撤退 a=\text{撤退} a = 撤退 π \pi π s s s a = 撤退 a=\text{撤退} a = 撤退 A A A
在上一章,我们讨论了可以用t + 1 t+1 t + 1 t t t
V π ( s t ) = ∑ a t π ( a t ∣ s t ) [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) ] V_{\pi}(s_t) = \sum_{a_t}\pi(a_t|s_t)\bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{\pi}(s_{t+1}) \bigg]
V π ( s t ) = a t ∑ π ( a t ∣ s t ) [ r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) ]
r ( s t , a t ) r(s_t,a_t) r ( s t , a t ) p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1 π ( a t ∣ s t ) \pi(a_t|s_t) π ( a t ∣ s t ) s t s_t s t a t a_t a t
知道了用状态价值评估策略,也知道了状态价值函数之间的关系,接下来,就可以评估策略了。0 0 0 s ∈ S s\in\mathcal{S} s ∈ S s t = s 1 , s 2 , s 3 , ⋯ , s T s_t = s_1,s_2,s_3,\cdots,s_T s t = s 1 , s 2 , s 3 , ⋯ , s T V ( s t ) = 0 V(s_t)=0 V ( s t ) = 0 k k k V k ( s t ) V_{k}(s_t) V k ( s t ) k − 1 k-1 k − 1 V k − 1 ( s t + 1 ) V_{k-1}(s_{t+1}) V k − 1 ( s t + 1 ) V k ( s t ) V_{k}(s_t) V k ( s t ) t + 1 t+1 t + 1 t t t
整个算法的过程描述如下:
策略评估算法 输入 :p p p π \pi π s ∈ S s\in\mathcal{S} s ∈ S V ( s ) = 0 V(s)=0 V ( s ) = 0 输出 :V π V_{\pi} V π 参数 :θ \theta θ K max K_{\max} K m a x 迭代 ,对于k = 1 , 2 , 3 , ⋯ , K max k=1,2,3,\cdots,K_{\max} k = 1 , 2 , 3 , ⋯ , K m a x Δ ← 0 \Delta\leftarrow0 Δ ← 0 遍历 s ∈ S s\in\mathcal{S} s ∈ S s t = s 1 , s 2 , s 3 , ⋯ , s T s_t = s_1,s_2,s_3,\cdots,s_T s t = s 1 , s 2 , s 3 , ⋯ , s T V V V V ← V k − 1 ( s t ) V\leftarrow V_{k-1}(s_t) V ← V k − 1 ( s t ) V k ( s t ) V_k(s_t) V k ( s t ) V k ( s t ) ← ∑ a t π ( a t ∣ s t ) [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) ] V_k(s_t) \leftarrow \sum_{a_t}\pi(a_t|s_t)\bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{k-1}(s_{t+1}) \bigg] V k ( s t ) ← ∑ a t π ( a t ∣ s t ) [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) ] Δ \Delta Δ Δ ← max ( Δ , ∣ V − V k ( s t ) ∣ ) \Delta\leftarrow\max(\Delta,|V-V_{k}(s_t)|) Δ ← max ( Δ , ∣ V − V k ( s t ) ∣ )
如果Δ \Delta Δ Δ < θ \Delta<\theta Δ < θ k = k max k=k_{\max} k = k m a x k k k s t = s 1 , s 2 , s 3 , ⋯ , s T s_t = s_1,s_2,s_3,\cdots,s_T s t = s 1 , s 2 , s 3 , ⋯ , s T θ \theta θ k + 1 k+1 k + 1
策略评估的实现
接下来,我们就实现一个策略评估,我们以"冰面滑行"为例。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第三章。
冰面滑行背景
冰面滑行问题(FrozenLake-v0)是Gym里内置的一个文本环境任务。该问题的背景是这样的:在一个大小为4 ∗ 4 4*4 4 ∗ 4
S F F F F H F H F H F H H F F G \begin{matrix}
S & F & F & F \\
F & H & F & H \\
F & H & F & H \\
H & F & F & G
\end{matrix}
S F F H F H H F F F F F F H H G
其中字母"F"(Frozen)表示结冰的区域,字母"H"(Hole)表示未结冰的冰窟窿,字母"S"(Start)和字母"G"(Goal)分别表示移动任务的起点和目标。在这个湖面上要执行以下移动任务:要从"S"处移动到"G"处。每一次移动,可以选择"左"、“下”、“右”、"上"4个方向之一进行移动,每次移动一格。如果移动到"G"处,回合结束,获得1个单位的奖励;如果移动到"H"处,回合结束,没有获得奖励;如果移动到其他字母,不获得奖励,可以继续。由于冰面滑,所以实际移动的方向和想要移动的方向并不一定完全一致。例如,如果在某个地方想要左移,但是由于冰面滑,实际也可能下移、右移和上移。任务的目标是尽可能达到"G"处,以获得奖励。
环境及其使用
示例代码:
1 2 3 4 5 6 7 8 9 import gymenv = gym.make('FrozenLake-v0' ) env = env.unwrapped env.seed(0 ) print('观察空间 = {}' .format(env.observation_space)) print('动作空间 = {}' .format(env.action_space)) print('状态空间大小 = {}' .format(env.unwrapped.nS)) print('动作空间大小 = {}' .format(env.unwrapped.nA)) env.render()
关于env = env.unwrapped这段代码的作用,网上有三种解释:gym的多数环境都用TimeLimit包装了,以限制Epoch。用env.unwrapped可以得到原始的类,不会有限制。
运行结果:
1 2 3 4 5 6 7 8 观察空间 = Discrete(16) 动作空间 = Discrete(4) 状态空间大小 = 16 动作空间大小 = 4 FHFH FFFH HFFG
这个环境的状态空间有16个不同的状态{ s 0 , s 1 , ⋯ , s 15 } \{s_0,s_1,\cdots,s_{15}\} { s 0 , s 1 , ⋯ , s 1 5 } { a 0 , a 1 , a 2 , a 3 } \{a_0,a_1,a_2,a_3\} { a 0 , a 1 , a 2 , a 3 }
特别的,我们可以看看环境的状态转移方程。
运行结果:
1 [(0.3333333333333333, 0, 0.0, False), (0.3333333333333333, 4, 0.0, False), (0.3333333333333333, 1, 0.0, False)]
这是一个元组列表,每个元组包括概率、下一状态、奖励值、回合结束指示这4个部分。s 0 s_0 s 0 a 1 a_1 a 1
P ( s 0 , 0 ∣ s 0 , a 1 ) = 1 3 P ( s 4 , 0 ∣ s 0 , a 1 ) = 1 3 P ( s 1 , 0 ∣ s 0 , a 1 ) = 1 3 \begin{aligned}
P(s_0,0 | s_0,a_1) &= \frac{1}{3} \\
P(s_4,0 | s_0,a_1) &= \frac{1}{3} \\
P(s_1,0 | s_0,a_1) &= \frac{1}{3}
\end{aligned}
P ( s 0 , 0 ∣ s 0 , a 1 ) P ( s 4 , 0 ∣ s 0 , a 1 ) P ( s 1 , 0 ∣ s 0 , a 1 ) = 3 1 = 3 1 = 3 1
然后,我们还可以用一个随机策略,试一试。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import numpy as npdef play_policy (env, policy, render=False) : total_reward = 0. observation = env.reset() while True : if render: env.render() action = np.random.choice(env.action_space.n,p=policy[observation]) observation, reward, done, _ = env.step(action) total_reward += reward if done: break return total_reward random_policy = np.ones((env.nS, env.nA)) / env.nA episode_rewards = [play_policy(env, random_policy) for _ in range(100 )] print("随机策略 平均奖励:{}" .format(np.mean(episode_rewards)))
运行结果:
策略评估的代码
接下来,就是代码实现策略评估算法,在具体的代码实现方面有两个技巧:
可以用矩阵相乘代替循环累加
如果知道了状态价值,就可以知道动作价值
就以我们上文的随机策略为例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def v2q (env, v, s=None, gamma=1. ) : """ 根据状态价值函数计算动作价值函数 :param env: 环境 :param v: 状态价值 :param s: 状态 :param gamma: 衰减率 :return: 动作价值 """ if s is not None : q = np.zeros(env.unwrapped.nA) for a in range(env.unwrapped.nA): for prob, next_state, reward, done in env.unwrapped.P[s][a]: q[a] += prob * (reward + gamma * v[next_state] * (1. - done)) else : q = np.zeros((env.unwrapped.nS, env.unwrapped.nA)) for s in range(env.unwrapped.nS): q[s] = v2q(env, v, s, gamma) return q def evaluate_policy (env, policy, gamma=1. , theta=1e-6 ,kmax=1000000 ) : """ 评估策略的状态价值 :param env: 环境 :param policy: 策略 :param gamma: 衰减率 :param theta: 最小更新值 :param kmax: 最大迭代次数 :return: """ v = np.zeros(env.unwrapped.nS) for k in range(kmax): delta = 0 for s in range(env.unwrapped.nS): vs = sum(policy[s] * v2q(env, v, s, gamma)) delta = max(delta, abs(v[s]-vs)) v[s] = vs if delta < theta: break return v print('状态价值函数:' ) v_random = evaluate_policy(env, random_policy) print(v_random.reshape(4 , 4 )) print('动作价值函数:' ) q_random = v2q(env, v_random) print(q_random)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 状态价值函数: [[0.0139372 0.01162942 0.02095187 0.01047569] [0.01624741 0. 0.04075119 0. ] [0.03480561 0.08816967 0.14205297 0. ] [0. 0.17582021 0.43929104 0. ]] 动作价值函数: [[0.01470727 0.01393801 0.01393801 0.01316794] [0.00852221 0.01162969 0.01086043 0.01550616] [0.02444416 0.0209521 0.02405958 0.01435233] [0.01047585 0.01047585 0.00698379 0.01396775] [0.02166341 0.01701767 0.0162476 0.01006154] [0. 0. 0. 0. ] [0.05433495 0.04735099 0.05433495 0.00698396] [0. 0. 0. 0. ] [0.01701767 0.04099176 0.03480569 0.04640756] [0.0702086 0.11755959 0.10595772 0.05895286] [0.18940397 0.17582024 0.16001408 0.04297362] [0. 0. 0. 0. ] [0. 0. 0. 0. ] [0.08799662 0.20503708 0.23442697 0.17582024] [0.25238807 0.53837042 0.52711467 0.43929106] [0. 0. 0. 0. ]]
策略改进
策略改进的方法
现在,我们已经知道了,我们的这个随机策略不怎么样。接下来,我们就要想办法对策略进行改进。《算法入门经典(Java与Python描述):10.图》 这一章,我们讨论了最小生成树的算法:“Kruskal"和"Prim”,"Kruskal"是每次选择所有的边中权重最小的边,"Prim"是每次选择当前能选择的边中权重最小的边。这两种算法都属于贪心算法 。
贪心不一定有效,但是在这里,我们的贪心算法是有效的。
策略改进算法 输入 :p p p π \pi π V V V 输出 :π \pi π o o o
初始化o o o True \text{True} True 遍历 s ∈ S s\in\mathcal{S} s ∈ S s t = s 1 , s 2 , s 3 , ⋯ , s T s_t = s_1,s_2,s_3,\cdots,s_T s t = s 1 , s 2 , s 3 , ⋯ , s T a t ∈ A a_t\in\mathcal{A} a t ∈ A Q ( s t , a t ) ← r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ( s t + 1 ) Q(s_t,a_t) \leftarrow r(s_t,a_t) + \gamma\sum_{s_{t+1}}p(s_{t+1}|s_t,a_t)V(s_{t+1}) Q ( s t , a t ) ← r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ( s t + 1 ) Q ( s t , a t ) Q(s_t,a_t) Q ( s t , a t ) a ⋆ a_{\star} a ⋆ a ⋆ = arg max a t Q ( s t , a t ) a_{\star}=\argmax_{a_t} Q(s_t,a_t) a ⋆ = a r g m a x a t Q ( s t , a t ) π ( s ) ≠ a ⋆ \pi(s)\neq a_{\star} π ( s ) = a ⋆ π ( s ) ← a ⋆ \pi(s) \leftarrow a_{\star} π ( s ) ← a ⋆ o ← False o\leftarrow\text{False} o ← False o ← True o\leftarrow\text{True} o ← True
策略改进的实现
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def improve_policy (env, v, policy, gamma=1. ) : optimal = True for s in range(env.nS): q = v2q(env, v, s, gamma) a = np.argmax(q) if policy[s][a] != 1. : optimal = False policy[s] = 0. policy[s][a] = 1. return optimal policy = random_policy.copy() optimal = improve_policy(env, v_random, policy) if optimal: print('无更新,最优策略为:' ) else : print('有更新,更新后的策略为:' ) print(np.argmax(policy, axis=1 ).reshape(4 , 4 ))
运行结果:
1 2 3 4 5 有更新,更新后的策略为: [[0 3 0 3] [0 0 0 0] [3 1 0 0] [0 2 1 0]]
策略迭代
策略迭代的方法
有了策略评估的方法,又有了策略改进的方法,把这几个串起来,就是策略迭代了。
策略迭代的实现
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def iterate_policy (env, gamma=1. , tolerant=1e-6 ) : policy = np.ones((env.unwrapped.nS, env.unwrapped.nA)) / env.unwrapped.nA while True : v = evaluate_policy(env, policy, gamma, tolerant) if improve_policy(env, v, policy): break return policy, v policy_pi, v_pi = iterate_policy(env) print('状态价值函数 =' ) print(v_pi.reshape(4 , 4 )) print('最优策略 =' ) print(np.argmax(policy_pi, axis=1 ).reshape(4 , 4 ))
运行结果:
1 2 3 4 5 6 7 8 9 10 状态价值函数 = [[0.82351246 0.82350689 0.82350303 0.82350106] [0.82351416 0. 0.5294002 0. ] [0.82351683 0.82352026 0.76469786 0. ] [0. 0.88234658 0.94117323 0. ]] 最优策略 = [[0 3 3 3] [0 0 0 0] [3 1 0 0] [0 2 1 0]]
看看效果
示例代码:
1 2 3 episode_rewards = [play_policy(env, policy_pi) for _ in range(100 )] print("平均奖励:{}" .format(np.mean(episode_rewards)))
运行结果:
价值迭代
价值迭代的方法
在讨论价值迭代之前,再来看看我们的策略迭代方法。首先,我们初始化一个策略,然后先进行策略评估(计算策略的价值函数),看看这个策略到底怎么样,再进行策略改进,然后再评估(计算策略的价值函数),再改进。如此循环往复,最后迭代出一个策略。
多轮迭代导致效率下降
策略初始化的随机性π 0 \pi_0 π 0 π ⋆ \pi_{\star} π ⋆
那我们换一个思路,不去迭代策略,直接迭代最优价值函数。如果能迭代出最优价值函数,最优策略就知道了。
V ⋆ ( s t ) = max a ∈ A [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 ) ] V_{\star}(s_t) = \max_{a\in\mathcal{A}} \bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_{t},a_{t}) V_{\star}(s_{t+1}) \bigg]
V ⋆ ( s t ) = a ∈ A max [ r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V ⋆ ( s t + 1 ) ]
基本思路是,在第k k k s s s V ( s ) V(s) V ( s ) a a a a a a r ( s , a ) r(s,a) r ( s , a ) s t + 1 s_{t+1} s t + 1 s t + 1 s_{t+1} s t + 1 ∑ s t + 1 p ( s t + 1 ∣ s , a ) V ( s t + 1 ) \sum_{s_{t+1}}p(s_{t+1}|s,a)V(s_{t+1}) ∑ s t + 1 p ( s t + 1 ∣ s , a ) V ( s t + 1 ) V ( s t + 1 ) V(s_{t+1}) V ( s t + 1 ) s s s V ( s ) V(s) V ( s )
具体算法如下:
价值迭代算法 输入 :p p p s ∈ S s\in\mathcal{S} s ∈ S V ( s ) = 0 V(s)=0 V ( s ) = 0 输出 :π \pi π 参数 :θ \theta θ K max K_{\max} K m a x 迭代 ,对于k = 1 , 2 , 3 , ⋯ , K max k=1,2,3,\cdots,K_{\max} k = 1 , 2 , 3 , ⋯ , K m a x Δ ← 0 \Delta\leftarrow0 Δ ← 0 遍历 s ∈ S s\in\mathcal{S} s ∈ S s t = s 1 , s 2 , s 3 , ⋯ , s T s_t=s_1,s_2,s_3,\cdots,s_T s t = s 1 , s 2 , s 3 , ⋯ , s T V V V V ← V k ( s t ) V\leftarrow V_k(s_t) V ← V k ( s t ) V k ( s t ) ← max a t { r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) } V_k(s_t)\leftarrow\max_{a_t}\{r(s_t,a_t)+\gamma\sum_{s_{t+1}}p(s_{t+1}|s_t,a_t)V_{k-1}(s_{t+1})\} V k ( s t ) ← max a t { r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) } Δ ← max ( Δ , ∣ V k ( s t ) ∣ ) \Delta\leftarrow\max(\Delta,|V_{k}(s_t)|) Δ ← max ( Δ , ∣ V k ( s t ) ∣ )
如果Δ \Delta Δ Δ < θ \Delta<\theta Δ < θ k = k max k=k_{\max} k = k m a x 策略 :
π ( s t ) = arg max a t { r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V ( s t + 1 ) } \pi(s_t)=\argmax_{a_t}\{r(s_t,a_t)+\gamma\sum_{s_{t+1}}p(s_{t+1}|s_t,a_t)V(s_{t+1})\} π ( s t ) = a t a r g m a x { r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V ( s t + 1 ) }
价值迭代的实现
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def iterate_value (env, gamma=1 , tolerant=1e-6 ,kmax=1000000 ) : v = np.zeros(env.unwrapped.nS) for i in range(kmax): delta = 0 for s in range(env.unwrapped.nS): vmax = max(v2q(env, v, s, gamma)) delta = max(delta, abs(v[s]-vmax)) v[s] = vmax if delta < tolerant: break policy = np.zeros((env.unwrapped.nS, env.unwrapped.nA)) for s in range(env.unwrapped.nS): a = np.argmax(v2q(env, v, s, gamma)) policy[s][a] = 1. return policy, v policy_vi, v_vi = iterate_value(env) print('状态价值函数 =' ) print(v_vi.reshape(4 , 4 )) print('最优策略 =' ) print(np.argmax(policy_vi, axis=1 ).reshape(4 , 4 )) episode_rewards = [play_policy(env, policy_vi) for _ in range(100 )] print("价值迭代 平均奖励:{}" .format(np.mean(episode_rewards)))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 状态价值函数 = [[0.82351232 0.82350671 0.82350281 0.82350083] [0.82351404 0. 0.52940011 0. ] [0.82351673 0.82352018 0.76469779 0. ] [0. 0.88234653 0.94117321 0. ]] 最优策略 = [[0 3 3 3] [0 0 0 0] [3 1 0 0] [0 2 1 0]] 价值迭代 平均奖励:0.86