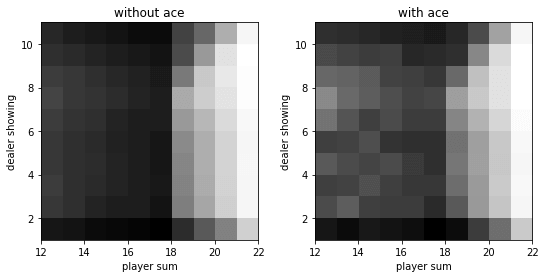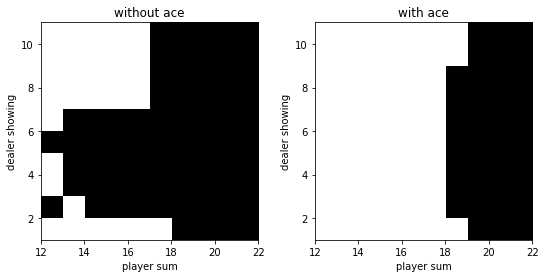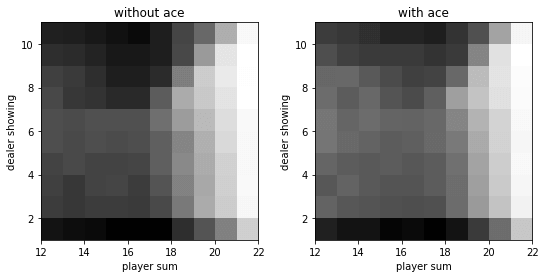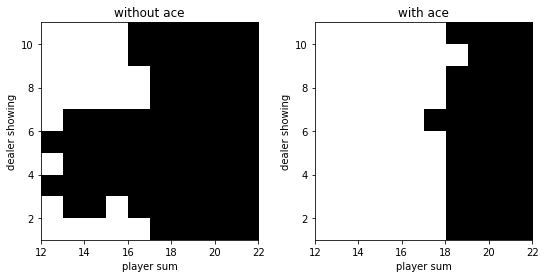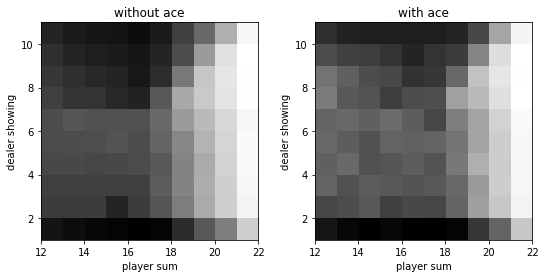上一章,我们讨论了动态规划。有策略迭代和价值迭代两种。
V k ( s t ) ← ∑ a t π ( a t ∣ s t ) [ r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) ] V_k(s_t) \leftarrow \sum_{a_t}\pi(a_t|s_t)\bigg[ r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{k-1}(s_{t+1}) \bigg]
V k ( s t ) ← a t ∑ π ( a t ∣ s t ) [ r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) ]
在价值迭代中,我们每一轮更新更新状态价值是这样的
V k ( s t ) ← max a t { r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) } V_k(s_t)\leftarrow\max_{a_t}\{r(s_t,a_t)+\gamma\sum_{s_{t+1}}p(s_{t+1}|s_t,a_t)V_{k-1}(s_{t+1})\}
V k ( s t ) ← a t max { r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V k − 1 ( s t + 1 ) }
无论是哪一种方法,其实都用到了p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t )
无模型和有模型的主要区别
让我们再回到第一章《1.基础概念》 ,我们可以用动作价值表示状态价值,用状态价值表示动作价值。
可以用t t t t t t
V π ( s t ) = ∑ a t π ( a t ∣ s t ) Q π ( s t , a t ) V_{\pi}(s_t) = \sum_{a_t} \pi(a_t|s_t)Q_{\pi}(s_t,a_t)
V π ( s t ) = a t ∑ π ( a t ∣ s t ) Q π ( s t , a t )
可以用t + 1 t+1 t + 1 t t t
Q π ( s t , a t ) = r ( s t , a t ) + γ ∑ s t + 1 p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 ) Q_{\pi}(s_t,a_t) = r(s_t,a_t) + \gamma \sum_{s_{t+1}} p(s_{t+1}|s_t,a_t) V_{\pi}(s_{t+1})
Q π ( s t , a t ) = r ( s t , a t ) + γ s t + 1 ∑ p ( s t + 1 ∣ s t , a t ) V π ( s t + 1 )
r ( s t , a t ) r(s_t,a_t) r ( s t , a t ) p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1
有了这两个,又可以衍生出:
可以用t + 1 t+1 t + 1 t t t 可以用t + 1 t+1 t + 1 t t t
但其实,上述过程,基于了一个假设。我们假设状态转移函数p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) 有模型 。
但更多的时候,我们的环境是未知的,即无模型 。p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p ( s t + 1 ∣ s t , a t ) 只能用动作价值表示状态价值。
那怎么办?
蒙特卡洛方法
我们先讨论什么是蒙特卡洛方法。抽样调查 ,这就是蒙特卡洛。
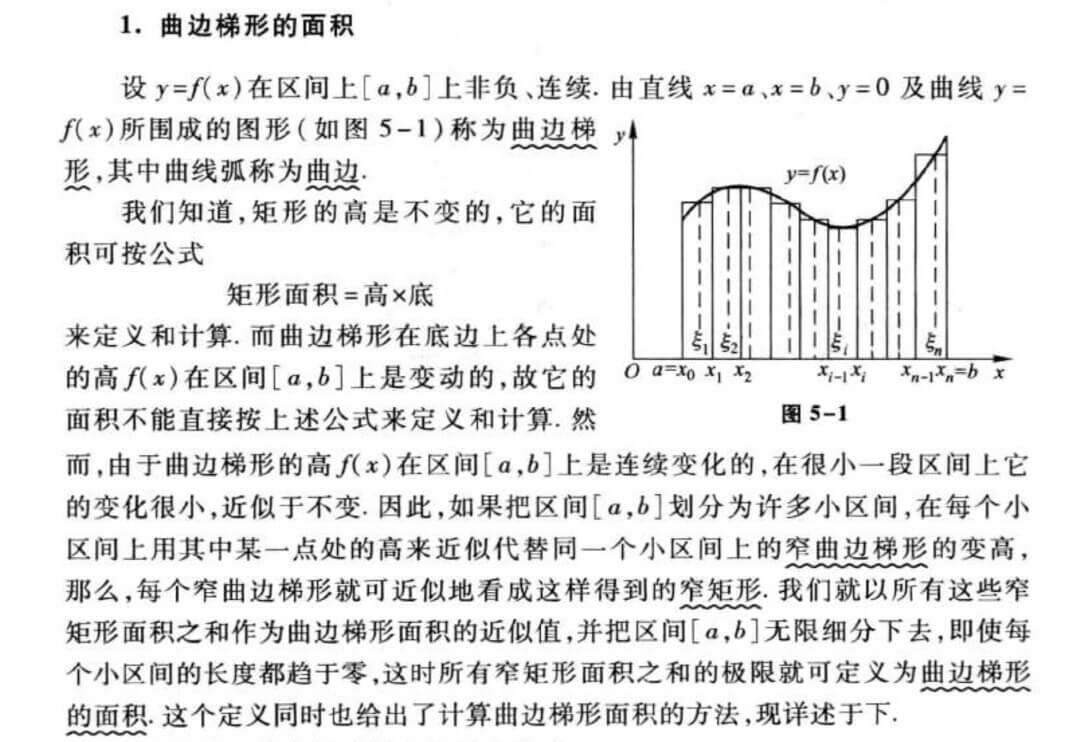
求不规则图形的面积
比如,求校徽的面积。
我们随机的抽足够多的点,比如100000个点,然后我们统计一下有多少点恰好落在校徽中。落在校徽中的点的个数除以样本总数100000,再乘以图片的大小,就是校徽的面积。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import randomfrom PIL import Imageimg = Image.open('TongjiLogo.jpg' ) total = 100000 inCount = 0 for i in range(total): x = random.randint(0 , img.width - 1 ) y = random.randint(0 , img.height - 1 ) color = img.getpixel((x, y)) if color != (255 , 255 , 255 ): inCount = inCount + 1 print('蒙特卡洛求校徽面积:' ) print(img.width * img.height * inCount / total)
运行结果:
近似定积分
在《高等数学(同济7版)》这本书的《第五章 定积分》,用多个矩形的面积去拟合曲边梯形的面积,通过这么一个例子引入定积分。
而用蒙特卡洛去近似定积分与这个有异曲同工之妙,只是我们是用一个矩形去拟合曲边梯形的面积。所以,我们要找到这一个矩形的恰到好处的高。
一元函数的定积分
例如,求函数在a a a b b b
I = ∫ a b f ( x ) d x I = \int_a^b f(x) dx
I = ∫ a b f ( x ) d x
方法如下:
我们在[ a , b ] [a,b] [ a , b ] 均匀 随机抽样足够多的样本:x 1 x_1 x 1 x 2 x_2 x 2 x 3 ⋯ x n x_3\ \cdots \ x_n x 3 ⋯ x n
对函数值f ( x 1 ) f(x_1) f ( x 1 ) f ( x 2 ) f(x_2) f ( x 2 ) f ( x 3 ) ⋯ f ( x n ) f(x_3) \ \cdots \ f(x_n) f ( x 3 ) ⋯ f ( x n ) b − a b-a b − a q n = ( b − a ) ∗ 1 n ∑ i = 1 n f ( x i ) q_n = (b-a) * \frac{1}{n} \sum_{i=1}^{n}f(x_i)
q n = ( b − a ) ∗ n 1 i = 1 ∑ n f ( x i )
q n q_n q n I I I
多元函数的定积分
在高中时候,我们就学过多元函数。多元函数是指自变量的个数是两个或两个以上的函数。多元函数的自变量x x x n n n
I = ∫ Ω f ( x ) d x I = \int_{\Omega} f(x)dx
I = ∫ Ω f ( x ) d x
方法如下:
在集合Ω \Omega Ω 均匀 随机抽样足够多的样本:x 1 ⃗ \vec{x_1} x 1 x 2 ⃗ \vec{x_2} x 2 x 3 ⃗ ⋯ x n ⃗ \vec{x_3}\ \cdots \ \vec{x_n} x 3 ⋯ x n
计算集合Ω \Omega Ω v = ∫ Ω d x v = \int_{\Omega}dx
v = ∫ Ω d x
对函数值f ( x 1 ⃗ ) f(\vec{x_1}) f ( x 1 ) f ( x 2 ⃗ ) f(\vec{x_2}) f ( x 2 ) f ( x 3 ⃗ ) ⋯ f ( x n ⃗ ) f(\vec{x_3}) \ \cdots \ f(\vec{x_n}) f ( x 3 ) ⋯ f ( x n ) v v v q n = v ∗ 1 n ∑ i = 1 n f ( x i ⃗ ) q_n = v * \frac{1}{n} \sum_{i=1}^n f(\vec{x_i})
q n = v ∗ n 1 i = 1 ∑ n f ( x i )
q n q_n q n I I I
提个问题,第二步,计算集合Ω \Omega Ω Ω \Omega Ω Ω \Omega Ω 参考:蒙特卡洛的应用之求不规则图形(校徽)的面积。
近似期望
随机变量的期望,这个我们知道。比如对于连续随机变量,我们有:
E [ f ( X ) ] = ∫ X 的值域 p ( x ) f ( x ) d x \mathbb{E}[f(X)] = \int_{X\text{的值域}} p(x) f(x) dx
E [ f ( X ) ] = ∫ X 的值域 p ( x ) f ( x ) d x
此外,我们还讨论了蒙特卡洛去近似定积分。均匀 抽样,这次要根据概率分布函数p ( x ) p(x) p ( x ) 非均匀 抽样了。
根据概率分布函数p ( x ) p(x) p ( x ) Ω \Omega Ω 非均匀 随机抽样足够多的样本:x 1 x_1 x 1 x 2 x_2 x 2 x 3 ⋯ x n ∼ p ( ⋅ ) x_3\ \cdots \ x_n \sim p(\cdot) x 3 ⋯ x n ∼ p ( ⋅ )
对函数值f ( x 1 ) f(x_1) f ( x 1 ) f ( x 2 ) f(x_2) f ( x 2 ) f ( x 3 ) ⋯ f ( x n ) f(x_3) \ \cdots \ f(x_n) f ( x 3 ) ⋯ f ( x n ) q n = 1 n ∑ i = 1 n f ( x i ) q_n = \frac{1}{n} \sum_{i=1}^n f(x_i)
q n = n 1 i = 1 ∑ n f ( x i )
q n q_n q n
提个问题,在讨论多元函数的定积分的时候,我们乘以了集合Ω \Omega Ω v v v
再提一个问题,如果让我们来编程实现,我们会怎么做?
方案一:定义一个list,在for循环求f ( x ) f(x) f ( x )
方案二:定义一个变量sum=0,在for循环的每一个循环中,更新sum的值,sum = sum + f ( x ) f(x) f ( x )
问,那种方案更省内存?《算法入门经典(Java与Python描述):4.递归》 讨论空间复杂度的时候讨论过。O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
而Robbins-Monro 算法的思路,就和我们的方案二非常的相似。q 0 = 0 q_0 = 0 q 0 = 0 t t t 1 1 1 n n n
q t = ( 1 − 1 t ) q t − 1 + 1 t f ( x t ) q_t = (1 - \frac{1}{t}) q_{t-1} + \frac{1}{t}f(x_t)
q t = ( 1 − t 1 ) q t − 1 + t 1 f ( x t )
即:
q 1 = q 0 + f ( x 1 ) = f ( x 1 ) q 2 = 1 2 q 1 + 1 2 f ( x 2 ) = 1 2 f ( x 1 ) + 1 2 f ( x 2 ) q 3 = 2 3 q 2 + 1 3 f ( x 3 ) = 1 3 f ( x 1 ) + 1 3 f ( x 2 ) + 1 3 f ( x 3 ) ⋯ \begin{aligned}
q_1 &= q_0 + f(x_1) \\
&= f(x_1) \\
q_2 &= \frac{1}{2} q_1 + \frac{1}{2}f(x_2) \\
&= \frac{1}{2} f(x_1) + \frac{1}{2}f(x_2) \\
q_3 &= \frac{2}{3} q_2 + \frac{1}{3}f(x_3) \\
&= \frac{1}{3}f(x_1) + \frac{1}{3}f(x_2) + \frac{1}{3}f(x_3) \\
\cdots
\end{aligned}
q 1 q 2 q 3 ⋯ = q 0 + f ( x 1 ) = f ( x 1 ) = 2 1 q 1 + 2 1 f ( x 2 ) = 2 1 f ( x 1 ) + 2 1 f ( x 2 ) = 3 2 q 2 + 3 1 f ( x 3 ) = 3 1 f ( x 1 ) + 3 1 f ( x 2 ) + 3 1 f ( x 3 )
如果我们把1 t \frac{1}{t} t 1 a t a_t a t
q t = ( 1 − a t ) q t − 1 + a t f ( x t ) q_t = (1 - a_t) q_{t-1} + a_t f(x_t)
q t = ( 1 − a t ) q t − 1 + a t f ( x t )
同时a t a_t a t
lim n → ∞ ∑ t = 1 n a t = ∞ \lim_{n \rightarrow \infty} \sum_{t=1}^n a_t = \infty lim n → ∞ ∑ t = 1 n a t = ∞ lim n → ∞ ∑ t = 1 n a t 2 = ∞ \lim_{n \rightarrow \infty} \sum_{t=1}^n a_t^2 = \infty lim n → ∞ ∑ t = 1 n a t 2 = ∞
这里就是Robbins-Monro 算法,a t a_t a t
随机梯度
刚刚,我们讨论了用蒙特卡洛去近似期望。现在,回忆一下,在机器学习中,我们什么时候需要去求期望?所有 的训练数据集,尤其是训练数据还特别多的时候,就会很慢。随机梯度下降 。
根据概率分布函数p ( x ) p(x) p ( x ) 非均匀 随机抽样,得到b个样本,记作x ~ 1 \tilde{x}_1 x ~ 1 x ~ 2 \tilde{x}_2 x ~ 2 x ~ 3 ⋯ x ~ b \tilde{x}_3 \ \cdots \ \tilde{x}_b x ~ 3 ⋯ x ~ b
求随机梯度g ~ \tilde{g} g ~ g ~ = 1 b ∑ j = 1 b ∇ ω L ( x ~ j ; ω ) \tilde{g} = \frac{1}{b} \sum_{j=1}^b \nabla_\omega L(\tilde{x}_j;\omega)
g ~ = b 1 j = 1 ∑ b ∇ ω L ( x ~ j ; ω )
用随机梯度g ~ \tilde{g} g ~ ω \omega ω ω ← ω − α g ~ \omega \leftarrow \omega - \alpha \tilde{g}
ω ← ω − α g ~
策略评估
通过上文的讨论,我们知道了在环境未知的情况下,我们的Bellman期望方程和我们的动态规划方法不再有效,因为我们再也不能用t + 1 t+1 t + 1 t t t
策略评估的方法
那么既然是抽样调查呢,首先回答第一个问题,“样本"是什么?s t s_t s t s t s_t s t a t a_t a t s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1 r t r_{t} r t
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , s 3 , ⋯ s_1,a_1,r_1,s_2,a_2,r_2,s_3,\cdots
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , s 3 , ⋯
这就是轨迹(Trajectory)。
假设现在给定一个策略,然后我们根据这个策略,智能体和环境交互足够多的次数,就会得到足够多的轨迹,也就是足够多的样本,那么就可以基于蒙特卡洛评估我们的策略了。
比如说现在给定了一个策略,然后我们根据这个策略,让智能体和环境交互,得到了一个轨迹(样本):s 0 , a 0 , r 0 , s 1 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T s_0,a_0,r_0,s_1,\cdots,s_{T-1},a_{T-1},r_{T-1},s_T s 0 , a 0 , r 0 , s 1 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T t t t t = T − 1 , T − 2 , T − 3 , ⋯ , 2 , 1 , 0 t=T-1,T-2,T-3,\cdots,2,1,0 t = T − 1 , T − 2 , T − 3 , ⋯ , 2 , 1 , 0 t = T − 1 t=T-1 t = T − 1 G T − 1 = r T − 1 G_{T-1} = r_{T-1} G T − 1 = r T − 1 t = T − 2 t=T-2 t = T − 2 G T − 2 = r T − 2 + γ r T − 1 G_{T-2} = r_{T-2} + \gamma r_{T-1} G T − 2 = r T − 2 + γ r T − 1
Q ( s t , a t ) ← 0 + G t Q(s_t,a_t) \leftarrow 0 + G_t
Q ( s t , a t ) ← 0 + G t
对于第二个样本:
Q ( s t , a t ) ← Q ( s t , a t ) + 1 2 [ G t − Q ( s t , a t ) ] Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \frac{1}{2} [G_t - Q(s_t,a_t)]
Q ( s t , a t ) ← Q ( s t , a t ) + 2 1 [ G t − Q ( s t , a t ) ]
道理是这么一个道理,一般情况下也就这样的,但有特例。
每次访问和首次访问
现在,我们来看一个特例。在电影《大话西游》中,有这么一段。
同一个状态在一个轨迹中多次出现 \text{同一个状态在一个轨迹中多次出现}
同一个状态在一个轨迹中多次出现
那么,对于这种情况,怎么办?
两种方法:
每次访问蒙特卡洛更新(Every Visit Mente Carlo Update)
首次访问蒙特卡洛更新(First Visit Mente Carlo Update)
我们以动作价值为例,来看具体的做法。
每次访问蒙特卡洛更新 输入 :π \pi π 输出 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a)\leftarrow\text{任意值},s\in\mathcal{S},a\in\mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A 初始化 :初始化计数器,C ( s , a ) ← 0 , s ∈ S , a ∈ A C(s,a)\leftarrow 0,s\in\mathcal{S},a\in\mathcal{A} C ( s , a ) ← 0 , s ∈ S , a ∈ A 蒙特卡洛 :(对于每个轨迹样本执行以下操作)π \pi π s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 ⋯ , s T − 1 , a T − 1 , r T − 1 , s T s_0,a_0,r_0,s_1,a_1,r_1,s_2\cdots,s_{T-1},a_{T-1},r_{T-1},s_T s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 ⋯ , s T − 1 , a T − 1 , r T − 1 , s T G ← 0 G\leftarrow 0 G ← 0 t = T − 1 , T − 2 , ⋯ , 0 t=T-1,T-2,\cdots,0 t = T − 1 , T − 2 , ⋯ , 0 G ← γ G + r t G\leftarrow\gamma G+r_{t} G ← γ G + r t C ( s , a ) ← C ( s , a ) + 1 C(s,a)\leftarrow C(s,a)+1 C ( s , a ) ← C ( s , a ) + 1 Q ( s , a ) ← Q ( s , a ) + 1 C ( s , a ) [ G − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\frac{1}{C(s,a)}[G-Q(s,a)] Q ( s , a ) ← Q ( s , a ) + C ( s , a ) 1 [ G − Q ( s , a ) ]
首次访问蒙特卡洛更新 输入 :π \pi π 输出 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a)\leftarrow\text{任意值},s\in\mathcal{S},a\in\mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A 初始化 :初始化计数器,C ( s , a ) ← 0 , s ∈ S , a ∈ A C(s,a)\leftarrow 0,s\in\mathcal{S},a\in\mathcal{A} C ( s , a ) ← 0 , s ∈ S , a ∈ A 蒙特卡洛 :(对于每个轨迹样本执行以下操作)π \pi π s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T s_0,a_0,r_0,s_1,a_1,r_1,s_2,\cdots,s_{T-1},a_{T-1},r_{T-1},s_T s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T G ← 0 G\leftarrow 0 G ← 0 f ( s , a ) ← − 1 , s ∈ S , a ∈ A f(s,a)\leftarrow -1,s\in\mathcal{S},a\in\mathcal{A} f ( s , a ) ← − 1 , s ∈ S , a ∈ A t = 0 , 1 , 2 , ⋯ , T − 1 t=0,1,2,\cdots,T-1 t = 0 , 1 , 2 , ⋯ , T − 1 f ( s , a ) < 0 f(s,a)<0 f ( s , a ) < 0 f ( s , a ) ← t f(s,a)\leftarrow t f ( s , a ) ← t t = T − 1 , T − 2 , ⋯ , 0 t=T-1,T-2,\cdots,0 t = T − 1 , T − 2 , ⋯ , 0 G ← γ G + r t G\leftarrow\gamma G+r_{t} G ← γ G + r t f ( s , a ) = t f(s,a)=t f ( s , a ) = t C ( s , a ) ← C ( s , a ) + 1 C(s,a)\leftarrow C(s,a)+1 C ( s , a ) ← C ( s , a ) + 1 Q ( s , a ) ← Q ( s , a ) + 1 C ( s , a ) [ G − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\frac{1}{C(s,a)}[G-Q(s,a)] Q ( s , a ) ← Q ( s , a ) + C ( s , a ) 1 [ G − Q ( s , a ) ]
那么,对于状态价值呢?无模型 了,但是只是不知道状态转移函数而已,只是不能用状态价值来表示动作价值了。但是,策略还是知道的,策略还是牢牢的掌握在我们自己的手中。
策略评估的实现
接下来,我们就来看实现。
21点游戏介绍
我们以一个知名的纸牌游戏"21点"为例。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第四章。
游戏规则是这样的:游戏里有一个玩家(player)和一个庄家(dealer),每个回合的结果可能是玩家获胜、庄家获胜或打成平手。回合开始时,玩家和庄家各有两张牌,玩家可以看到玩家的两张牌和庄家的其中一张牌。接着,玩家可以选择是不是要更多的牌。如果选择要更多的牌,玩家可以再得到一张牌,并统计玩家手上所有牌的点数之和。
牌面
点数
A
1或11
2
2
3
3
···
···
9
9
10,J,Q,K
10
如果点数和大于21则称玩家输掉这一回合,庄家获胜;如果点数和小等于21,那么玩家可以再次决定是否要更多的牌,直到玩家不再要更多的牌。如果玩家在总点数小等于21的情况下不要更多的牌,那么这时候玩家手上的总点数就是最终玩家的点数。接下来,庄家展示其没有显示的那张牌,并且在其点数小于17的情况下抽取更多的牌。如果庄家在抽取的过程中总点数超过21,则庄家输掉这一回合,玩家获胜;如果最终庄家的总点数小于等于21,则比较玩家的总点数和庄家的总点数。如果玩家的总点数大于庄家的总点数,则玩家获胜;如果玩家和庄家的总点数相同,则为平局;如果玩家的总点数小于庄家的总点数,则庄家获胜。
提起这个纸牌游戏,大家可能还都会想到一部电影。《决胜21点》。
影片讲述了一个由MIT的教授和学生组成的团队,靠数学在拉斯维加斯的赌场上,通过21点纸牌游戏赚钱的故事。这个过程和量化投资极为相似(当然,金融市场不是赌场,但同样充满了不确定性),因此这部电影也被看作是一部和量化投资有关的电影。
总之,这一章,我们要做的是一件很酷的事情。设计并开发一个人工智能,来玩"21点"这个纸牌游戏。
环境及其使用
首先,我们介绍环境,并用一个策略来试一下。
1 2 3 4 5 6 7 8 9 10 import gymimport numpy as npenv = gym.make("Blackjack-v0" ) env = env.unwrapped env.seed(0 ) print('观察空间 = {}' .format(env.observation_space)) print('动作空间 = {}' .format(env.action_space)) print('动作数量 = {}' .format(env.action_space.n))
运行结果:
1 2 3 观察空间 = Tuple(Discrete(32), Discrete(11), Discrete(2)) 动作空间 = Discrete(2) 动作数量 = 2
我们的策略很简单,只要点数之和小于18,就继续摸牌。否则,不摸。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def ob2state (observation) : return observation[0 ], observation[1 ], int(observation[2 ]) def play_once (env,policy) : total_reward = 0 observation = env.reset() print('观测 = {}' .format(observation)) while True : print('玩家 = {}, 庄家 = {}' .format(env.player, env.dealer)) state = ob2state(observation) action = np.random.choice(env.action_space.n, p=policy[state]) print('动作 = {}' .format(action)) observation, reward, done, _ = env.step(action) print('观测 = {}, 奖励 = {}, 结束指示 = {}' .format( observation, reward, done)) total_reward += reward if done: return total_reward policy = np.zeros((22 , 11 , 2 , 2 )) policy[18 :, :, :, 0 ] = 1 policy[:18 , :, :, 1 ] = 1 print("奖励:{}" .format(play_once(env,policy)))
运行结果:
1 2 3 4 5 观测 = (18, 1, False) 玩家 = [10, 8], 庄家 = [1, 7] 动作 = 0 观测 = (18, 1, False), 奖励 = 0.0, 结束指示 = True 奖励:0.0
策略评估的代码
在上文,我们讨论了"每次访问和首次访问"。同一个状态在一个轨迹中多次出现。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import matplotlib.pyplot as pltdef evaluate_action_monte_carlo (env, policy, episode_num=500000 ) : q = np.zeros_like(policy) c = np.zeros_like(policy) for _ in range(episode_num): state_actions = [] observation = env.reset() while True : state = ob2state(observation) action = np.random.choice(env.action_space.n, p=policy[state]) state_actions.append((state, action)) observation, reward, done, _ = env.step(action) if done: break g = reward for state, action in state_actions: c[state][action] += 1. q[state][action] += (g - q[state][action]) / c[state][action] return q q = evaluate_action_monte_carlo(env, policy) v = (q * policy).sum(axis=-1 ) def plot (data) : fig, axes = plt.subplots(1 , 2 , figsize=(9 , 4 )) titles = ['without ace' , 'with ace' ] have_aces = [0 , 1 ] extent = [12 , 22 , 1 , 11 ] for title, have_ace, axis in zip(titles, have_aces, axes): dat = data[extent[0 ]:extent[1 ], extent[2 ]:extent[3 ], have_ace].T axis.imshow(dat, cmap='gray' ,extent=extent, origin='lower' ) axis.set_xlabel('player sum' ) axis.set_ylabel('dealer showing' ) axis.set_title(title) plot(v)
extent = [12, 22, 1, 11]因为动作价值是一个四维的数组,而状态价值是一个三维的数组。所以,我们绘制的是状态价值。
运行结果:
策略迭代
起始探索法
在上文,我们先估计了动作价值,然后为了画图方便,我们还计算了状态价值。
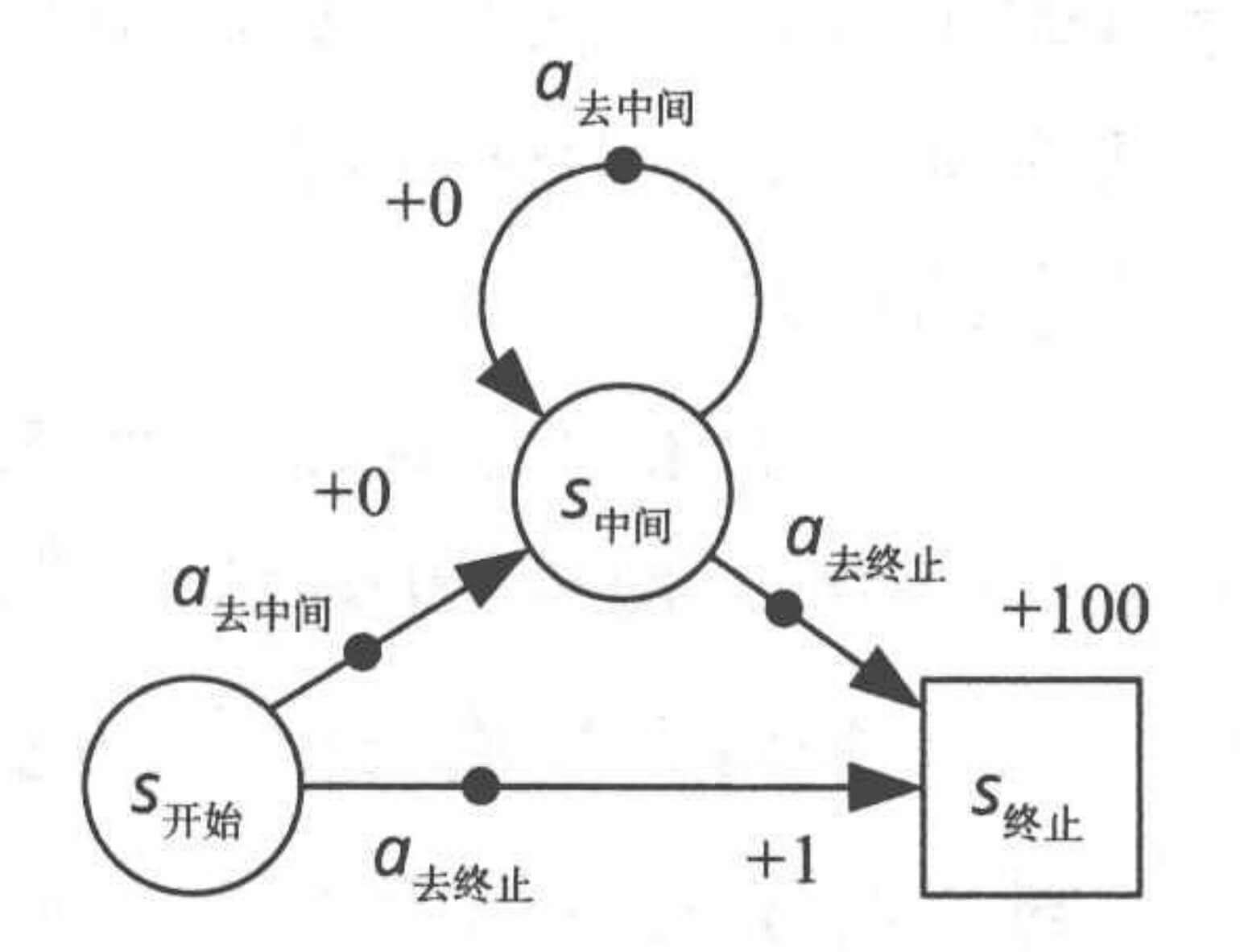
很明显,我们的最优策略是
π ( s 开始 ) = a 去中间 π ( s 中间 ) = a 去终止 \begin{aligned}
\pi(s_{\text{开始}}) &= a_{\text{去中间}} \\
\pi(s_{\text{中间}}) &= a_{\text{去终止}}
\end{aligned}
π ( s 开始 ) π ( s 中间 ) = a 去中间 = a 去终止
现在,我们把所有的动作价值和状态价值均初始化为0,并且随机从一个策略出发。
π ( s 开始 ) = a 去终止 π ( s 中间 ) = a 去终止 \begin{aligned}
\pi(s_{\text{开始}}) &= a_{\text{去终止}} \\
\pi(s_{\text{中间}}) &= a_{\text{去终止}}
\end{aligned}
π ( s 开始 ) π ( s 中间 ) = a 去终止 = a 去终止
根据我们随机出来的这个倒霉的策略,如果我们从s 开始 s_{\text{开始}} s 开始
s 0 = s 开始 , a 0 = a 去终止 , r 0 = + 1 , s 1 = s 终止 s_0 = s_{\text{开始}},a_0 = a_{\text{去终止}},r_{0}=+1,s_1=s_{\text{终止}}
s 0 = s 开始 , a 0 = a 去终止 , r 0 = + 1 , s 1 = s 终止
然后我们更新我们的动作价值函数。
Q ( s 开始 , a 去终止 ) = 1 Q(s_{\text{开始}},a_{\text{去终止}}) = 1
Q ( s 开始 , a 去终止 ) = 1
之后,再迭代,再评估,永远得不到最优策略。
因为,我们一开始随机初始化的那个策略就不太好。
我们让所有可能的状态动作对都成为可能的回合起点,这样就不会遗漏任何状态动作对。这就是起始探索(exploring start) 。
起始探索蒙特卡洛更新 同样存在每次访问和首次访问的问题,我们这里暂且以每次访问为例。
带起始探索的每次访问蒙特卡洛更新 输入 :π \pi π 初始化 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a)\leftarrow\text{任意值},s\in\mathcal{S},a\in\mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A C ( s , a ) ← 0 , s ∈ S , a ∈ A C(s,a)\leftarrow 0,s\in\mathcal{S},a\in\mathcal{A} C ( s , a ) ← 0 , s ∈ S , a ∈ A π ( s ) ← 任意动作 \pi(s)\leftarrow\text{任意动作} π ( s ) ← 任意动作 s ∈ S s\in\mathcal{S} s ∈ S 蒙特卡洛 :(对于每个轨迹样本执行以下操作)s 0 ∈ S s_0\in\mathcal{S} s 0 ∈ S a 0 ∈ A a_0\in\mathcal{A} a 0 ∈ A ( s 0 , a 0 ) (s_0,a_0) ( s 0 , a 0 ) π \pi π s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T s_0,a_0,r_0,s_1,a_1,r_1,s_2,\cdots,s_{T-1},a_{T-1},r_{T-1},s_T s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , s 2 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T G ← 0 G\leftarrow 0 G ← 0 t = T − 1 , T − 2 , ⋯ , 0 t=T-1,T-2,\cdots,0 t = T − 1 , T − 2 , ⋯ , 0 G ← γ G + r t G\leftarrow\gamma G+r_{t} G ← γ G + r t C ( s , a ) ← C ( s , a ) + 1 C(s,a)\leftarrow C(s,a)+1 C ( s , a ) ← C ( s , a ) + 1 Q ( s , a ) ← Q ( s , a ) + 1 C ( s , a ) [ G − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\frac{1}{C(s,a)}[G-Q(s,a)] Q ( s , a ) ← Q ( s , a ) + C ( s , a ) 1 [ G − Q ( s , a ) ] π ( s t ) ← arg max a Q ( s t , a ) \pi(s_t)\leftarrow\argmax_aQ(s_t,a) π ( s t ) ← a r g m a x a Q ( s t , a ) 需要特别注意的是这一行:起始探索,选择s 0 ∈ S s_0\in\mathcal{S} s 0 ∈ S a 0 ∈ A a_0\in\mathcal{A} a 0 ∈ A ( s 0 , a 0 ) (s_0,a_0) ( s 0 , a 0 ) 这是我们起始探索算法的核心。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def monte_carlo_with_exploring_start (env, episode_num=500000 ) : policy = np.zeros((22 , 11 , 2 , 2 )) policy[:, :, :, 1 ] = 1. q = np.zeros_like(policy) c = np.zeros_like(policy) for _ in range(episode_num): state = (np.random.randint(12 , 22 ), np.random.randint(1 , 11 ), np.random.randint(2 )) action = np.random.randint(2 ) env.reset() if state[2 ]: env.player = [1 , state[0 ] - 11 ] else : if state[0 ] == 21 : env.player = [10 , 9 , 2 ] else : env.player = [10 , state[0 ] - 10 ] env.dealer[0 ] = state[1 ] state_actions = [] while True : state_actions.append((state, action)) observation, reward, done, _ = env.step(action) if done: break state = ob2state(observation) action = np.random.choice(env.action_space.n, p=policy[state]) g = reward for state, action in state_actions: c[state][action] += 1. q[state][action] += (g - q[state][action]) / c[state][action] a = q[state].argmax() policy[state] = 0. policy[state][a] = 1. return policy, q policy, q = monte_carlo_with_exploring_start(env) v = q.max(axis=-1 ) plot(policy.argmax(-1 )) plot(v)
运行结果:
epsilon探索法
起始探索法在实际中存在一个很严重的限制,要求能指定任意一个状态作为回合的起始状态。但是实际中,很难做到,比如我们开发玩游戏的强化学习程序。S 开始 S_{\text{开始}} S 开始 a 去中间 a_{\text{去中间}} a 去中间
可是,问题就在,初始策略到底哪个,谁也不知道。我们运气不太好,在一开始初始化得到了一个不好的策略,π ( s 开始 ) = a 去终止 \pi(s_{\text{开始}}) = a_{\text{去终止}} π ( s 开始 ) = a 去终止
为什么要严格遵守策略呢?
π ( a ∣ s ) = { 1 , a = a ⋆ 0 , a ≠ a ⋆ \pi(a|s) = \begin{cases}
1, & a=a_{\star} \\
0, & a\neq a_{\star}
\end{cases}
π ( a ∣ s ) = { 1 , 0 , a = a ⋆ a = a ⋆
修改为
π ( a ∣ s ) = { 1 − ε + ε ∣ A ( s ) ∣ , a = a ⋆ ε ∣ A ( s ) ∣ , a ≠ a ⋆ ( ε > 0 ) \pi(a|s) = \begin{cases}
1 - \varepsilon + \frac{\varepsilon}{|\mathcal{A}(s)|}, & a=a_{\star} \\
\frac{\varepsilon}{|\mathcal{A}(s)|}, & a\neq a_{\star}
\end{cases}\quad(\varepsilon > 0)
π ( a ∣ s ) = { 1 − ε + ∣ A ( s ) ∣ ε , ∣ A ( s ) ∣ ε , a = a ⋆ a = a ⋆ ( ε > 0 )
A ( s ) \mathcal{A}(s) A ( s ) s s s ∣ A ( s ) ∣ |\mathcal{A}(s)| ∣ A ( s ) ∣
这就是ε \varepsilon ε ε \varepsilon ε ε \varepsilon ε ε \varepsilon ε ε \varepsilon ε
ε \varepsilon ε 输入 :π \pi π 初始化 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a)\leftarrow\text{任意值},s\in\mathcal{S},a\in\mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A C ( s , a ) ← 0 , s ∈ S , a ∈ A C(s,a)\leftarrow 0,s\in\mathcal{S},a\in\mathcal{A} C ( s , a ) ← 0 , s ∈ S , a ∈ A π ( ⋅ ∣ ⋅ ) \pi(\cdot|\cdot) π ( ⋅ ∣ ⋅ ) ε \varepsilon ε 蒙特卡洛 :(对于每个轨迹样本执行以下操作)π \pi π s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T s_0,a_0,r_0,s_1,a_1,r_1,\cdots,s_{T-1},a_{T-1},r_{T-1},s_T s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , ⋯ , s T − 1 , a T − 1 , r T − 1 , s T G ← 0 G\leftarrow 0 G ← 0 t = T − 1 , T − 2 , ⋯ , 0 t=T-1,T-2,\cdots,0 t = T − 1 , T − 2 , ⋯ , 0 G ← γ G + r t G\leftarrow\gamma G+r_{t} G ← γ G + r t C ( s , a ) ← C ( s , a ) + 1 C(s,a)\leftarrow C(s,a)+1 C ( s , a ) ← C ( s , a ) + 1 Q ( s , a ) ← Q ( s , a ) + 1 C ( s , a ) [ G − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\frac{1}{C(s,a)}[G-Q(s,a)] Q ( s , a ) ← Q ( s , a ) + C ( s , a ) 1 [ G − Q ( s , a ) ] a ⋆ ← arg max a Q ( s t , a ) a_{\star}\leftarrow\argmax_aQ(s_t,a) a ⋆ ← a r g m a x a Q ( s t , a ) π ( ⋅ ∣ s t ) \pi(\cdot|s_t) π ( ⋅ ∣ s t ) ε \varepsilon ε
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def monte_carlo_with_soft (env, episode_num=500000 , epsilon=0.1 ) : policy = np.ones((22 , 11 , 2 , 2 )) * 0.5 q = np.zeros_like(policy) c = np.zeros_like(policy) for _ in range(episode_num): state_actions = [] observation = env.reset() while True : state = ob2state(observation) action = np.random.choice(env.action_space.n, p=policy[state]) state_actions.append((state, action)) observation, reward, done, _ = env.step(action) if done: break g = reward for state, action in state_actions: c[state][action] += 1. q[state][action] += (g - q[state][action]) / c[state][action] a = q[state].argmax() policy[state] = epsilon / 2. policy[state][a] += (1. - epsilon) return policy, q policy, q = monte_carlo_with_soft(env) v = q.max(axis=-1 ) plot(policy.argmax(-1 )) plot(v)
运行结果:
离线策略蒙特卡洛
在上文,我们讨论的都是在线策略蒙特卡洛的情况,其特点是当前遵循的策略就是智能体学习改进的策略。即"在线策略蒙特卡洛",也有资料称其为"固定策略回合更新"、“同策回合更新”等。
不过,需要注意的是,离线策略蒙特卡洛仅有理论上的研究价值,在实际任务中的效果并不明显,难以获得最优策略或者最优动作值函数,所以,我们不做太多的讨论。
但,离线策略方法在接下来的四个章节中,都会有重要的应用!