时序差分简介
时序差分(Temporal Difference,TD),也有资料称其为时间差分。
现在,我们开车从"上海"去"南昌",然后我们打开导航软件,预估时间是8 8 8 Q ( s , d ; ω ) Q(s,d;\omega) Q ( s , d ; ω ) s s s d d d ω \omega ω Q ( s , d ; ω ) Q(s,d;\omega) Q ( s , d ; ω ) q = Q ( s , d ; ω ) = 8 q = Q(s,d;\omega) = 8 q = Q ( s , d ; ω ) = 8 y = 7 y=7 y = 7
L ( ω ) = 1 2 ( q − y ) 2 L(\omega) = \frac{1}{2}(q - y)^2
L ( ω ) = 2 1 ( q − y ) 2
梯度是:
∂ L ∂ ω = ( q − y ) ∂ Q ( s , d ; ω ) ω \frac{\partial L}{\partial \omega} = (q - y)\frac{\partial Q(s,d;\omega)}{\omega}
∂ ω ∂ L = ( q − y ) ω ∂ Q ( s , d ; ω )
梯度下降是:
ω ← ω − α ∂ L ∂ ω \omega \leftarrow \omega - \alpha \frac{\partial L}{\partial \omega}
ω ← ω − α ∂ ω ∂ L
我们的导航软件可以根据这种方法来更新预估时间,最后得到更准确的预估时间。
那么,假如我们现在到了"杭州",耗费的时间是3 3 3 3 3 3 4.5 4.5 4 . 5 7.5 7.5 7 . 5 TD目标(TD Target) 。
所以,我们有如下的式子
T 上海 → 南昌 ≈ T 上海 → 杭州 + T 杭州 → 南昌 T_{\text{上海}\rightarrow\text{南昌}} \approx \bold{T_{\text{上海}\rightarrow\text{杭州}}} + T_{\text{杭州}\rightarrow\text{南昌}}
T 上海 → 南昌 ≈ T 上海 → 杭州 + T 杭州 → 南昌
T 上海 → 杭州 \bold{T_{\text{上海}\rightarrow\text{杭州}}} T 上海 → 杭州
然后,我们再把我们刚刚的模型Q ( s , d ; ω ) Q(s,d;\omega) Q ( s , d ; ω )
Q ( s t , a t ; ω ) ≈ r t + Q ( s t + 1 , a t + 1 ; ω ) Q(s_t,a_t;\omega) \approx r_t + Q(s_{t+1},a_{t+1};\omega)
Q ( s t , a t ; ω ) ≈ r t + Q ( s t + 1 , a t + 1 ; ω )
时序差分应用
继续看上面的例子,我们再来梳理一遍。
V ← V + α ( G − V ) V \leftarrow V + \alpha(G - V)
V ← V + α ( G − V )
V V V G G G α \alpha α
这个是不是和上一章的蒙特卡洛非常相似?
V ( s t ) ← V ( s t ) + α ( G t − V ( s t ) ) V(s_t) \leftarrow V(s_t) + \alpha(G_t - V(s_t))
V ( s t ) ← V ( s t ) + α ( G t − V ( s t ) )
用图表示如下:
可是,如果不顺利呢?不顺利的话,导航软件只能收集到我们从"上海"到"杭州"所耗费的时间,那么这时候怎么更新预估时间呢?
V ← V + α ( H + V ′ − V ) V \leftarrow V + \alpha(H + V' - V)
V ← V + α ( H + V ′ − V )
V V V H H H V ′ V' V ′ α \alpha α
同样,我们把耗费的时间换成状态价值,则有:
V ( s t ) ← V ( s t ) + α ( r t + 1 + γ V ( s t + 1 ) − V ( s t ) ) V(s_t) \leftarrow V(s_t) + \alpha(r_{t+1} + \gamma V(s_{t+1}) - V(s_t))
V ( s t ) ← V ( s t ) + α ( r t + 1 + γ V ( s t + 1 ) − V ( s t ) )
用图表示如下:
除了这两种方法,在第二章我们还讨论了"动态规划",更新方法如下:
V ( s t ) ← E π [ r t + 1 + γ V ( s t + 1 ) ] V(s_t) \leftarrow \mathbb{E}_{\pi}[r_{t+1} + \gamma V(s_{t+1})]
V ( s t ) ← E π [ r t + 1 + γ V ( s t + 1 ) ]
用图表示如下:
SARSA:在线策略时序差分方法
所以呢,我们现在又有了一种评估策略的方法,时序差分。现在,我们把时序差分应用到强化学习中。
题外话,其实不仅是是动态规划、蒙特卡洛和这一章的时序差分,我们的整个强化学习,甚至包括我们之前深度学习,都蕴含着迭代的思想在其中,我们把迭代的过程称之为学习的过程。我在一本描写费马大定理的四百年的证明过程的书中,看到这么一段。
当时,我的第一感受是,欧拉没有把故事讲好啊,他那时候应该说这是"人工智能"。但,或许又是那时候,没人需要人工智能这个故事把。
SARSA的过程
回到主题。
SARSA的名字,来自于我们之前讨论的轨迹,在当前状态S S S A A A R R R S ′ S' S ′ A ′ A' A ′
那么,现在我们可以利用时序差分方法了,我们用动作价值Q ( s t + 1 , a t + 1 ) Q(s_{t+1},a_{t+1}) Q ( s t + 1 , a t + 1 ) Q ( s t , a t ) Q(s_t,a_t) Q ( s t , a t )
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r + \gamma Q(s_{t+1},a_{t+1}) - Q(s_t,a_t))
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) )
SARSA的更新方法就是这么一个更新方法,在具体实现方面,我们可以再利用我们上一章讨论的ε \varepsilon ε
具体算法流程如
SARSA算法 输入 :输出 :Q ( s , a ) , s ∈ S , a ∈ A ( s ) Q(s,a),s \in \mathcal{S},a \in \mathcal{A}(s) Q ( s , a ) , s ∈ S , a ∈ A ( s ) 参数 :α \alpha α γ \gamma γ 初始化 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a) \leftarrow \text{任意值},s \in \mathcal{S},a \in \mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q ( s 终止 , a ) ← 0 , a ∈ A Q(s_{\text{终止}},a) \leftarrow 0,a \in \mathcal{A} Q ( s 终止 , a ) ← 0 , a ∈ A 时序差分 :(对每一条轨迹执行以下操作)s 0 s_0 s 0 Q Q Q ε \varepsilon ε a 0 a_0 a 0 ( s 0 , a 0 ) (s_0,a_0) ( s 0 , a 0 ) t = 0 , 1 , 2 , ⋯ , T t=0,1,2,\cdots,T t = 0 , 1 , 2 , ⋯ , T t = T t=T t = T s t = s 终止 s_t=s_{\text{终止}} s t = s 终止 a t a_t a t r t r_t r t s t + 1 s_{t+1} s t + 1 s t + 1 s_{t+1} s t + 1 ε \varepsilon ε a t + 1 a_{t+1} a t + 1 s t + 1 , a t + 1 s_{t+1},a_{t+1} s t + 1 , a t + 1 Q ( s t , a t ) Q(s_t,a_t) Q ( s t , a t ) Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_t + \gamma Q(s_{t+1},a_{t+1}) - Q(s_t,a_t)) Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) r t + γ Q ( s t + 1 , a t + 1 r_t + \gamma Q(s_{t+1},a_{t+1} r t + γ Q ( s t + 1 , a t + 1
SARSA的实现
接下来,我们实现SARSA算法,以调度系统为例。调度系统在我们生活中非常的常见,比如外卖配送调度,网约车调度等。这些系统都极其的庞大复杂,我们只能以一个非常简单的DEMO为例,Gym中的出租车调度。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第五章。
出租车调度问题描述
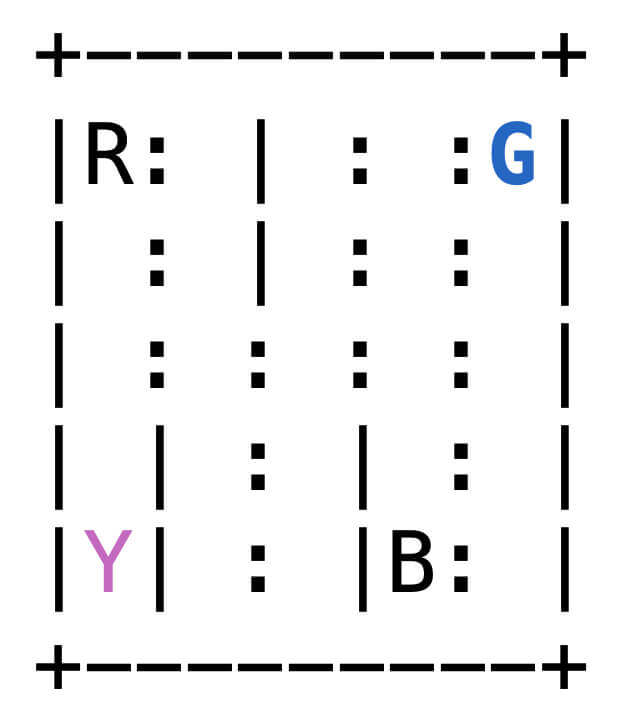
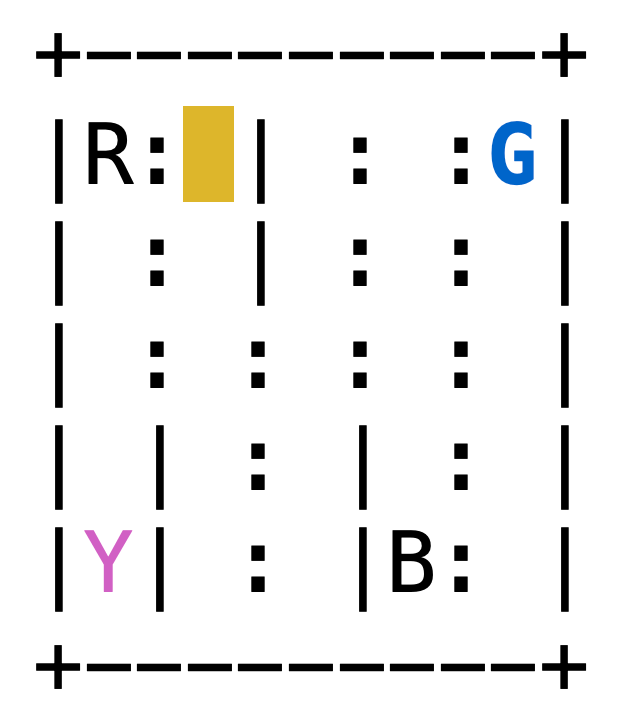
如图所示,是一个用5×5方格表示的地图,有4个出租车停靠点,分别是B、G、R、Y。在每个回合开始时,有一个乘客会随机出现在4个出租车停靠点中的一个,并想在任意一个出租车停靠点下车。出租车会随机出现在25个位置的任意一个位置。出租车需要通过移动自己的位置,到达乘客所在的位置,并将乘客接上车,然后移动到乘客想下车的位置,再让乘客下车。出租车只能在地图范围内上下左右移动一格,并且在有竖线阻拦地方不能横向移动。出租车完成一次任务可以得到20个奖励,每次试图移动得到-1个奖励,不合理地邀请乘客上车(例如目前车和乘客不在同一位置,或乘客已经上车)或让乘客下车(例如车不在目的地,或车上没有乘客)得到-10个奖励。希望调度出租车让总奖励的期望最大。
环境及其使用
示例代码:
1 2 3 4 5 6 7 8 9 10 11 import numpy as npnp.random.seed(0 ) import gymenv = gym.make('Taxi-v3' ) env = env.unwrapped env.seed(0 ) print('观察空间 = {}' .format(env.observation_space)) print('动作空间 = {}' .format(env.action_space)) print('状态数量 = {}' .format(env.observation_space.n)) print('动作数量 = {}' .format(env.action_space.n))
运行结果:
1 2 3 4 观察空间 = Discrete(500) 动作空间 = Discrete(6) 状态数量 = 500 动作数量 = 6
然后,我们试着来操作一下。
示例代码:
1 2 3 4 5 6 7 8 9 state = env.reset() taxirow, taxicol, passloc, destidx = env.unwrapped.decode(state) print(taxirow, taxicol, passloc, destidx) print('的士位置 = {}' .format((taxirow, taxicol))) print('乘客位置 = {}' .format(env.unwrapped.locs[passloc])) print('目标位置 = {}' .format(env.unwrapped.locs[destidx])) env.render()
运行结果:
1 2 3 4 0 1 1 2 的士位置 = (0, 1) 乘客位置 = (0, 4) 目标位置 = (4, 0)
解释一下,这个环境中的观测是一个范围为[ 0 , 500 ) [0,500) [ 0 , 5 0 0 ) env.decode()函数进行解码,得到长度为4的元组(tarrow,taxicab,passloc,destidx),其各元素含义如下:
taxirow和taxicol是取值为{0,1,2,3,4}的int型变量,表示当前出租车的位置。passloc是取值为{0,1,2,3,4}的int型数值,表示乘客的位置,其中{0,1,2,3}表示乘客在"出租车停靠点表"中对应的位置等待,4表示乘客在车上。destidx是取值为{0,1,2,3}的int型数值,表示目的地,目的地的位置同样由"出租车停靠点表"给出。乘客的位置、目地会用彩色字母显示、出租车的位置会高亮显示。
如果乘客不在车上,乘客等待地点(位置)的字母会显示为蓝色、目的地所在的字母会显示为洋红色、出租车所在的位置会用黄色高亮
如果乘客在车上,出租车所在的位置会用绿色高亮。
出租车停靠点表
passloc或destidx
字母
坐标
0
R
(0,0)
1
G
(0,4)
2
Y
(4,0)
3
B
(4,3)
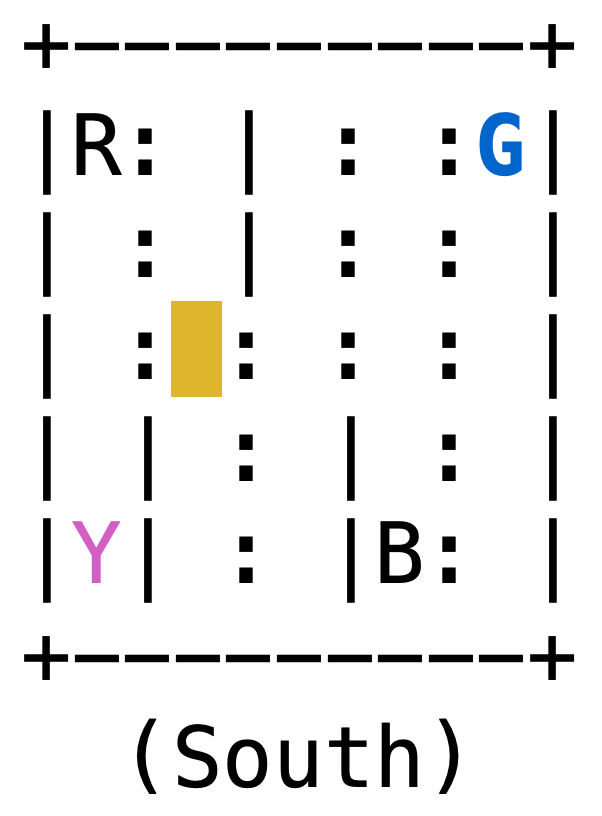
再移动一下出租车。
1 2 3 4 5 6 s = env.step(0 ) print(s) s = env.step(0 ) print(s) env.render()
运行结果:
1 2 (126, -1, False, {'prob': 1.0}) (226, -1, False, {'prob': 1.0})
env.step()传入动作,用{0,1,2,3,4,5}表示,具体含义参考"出租车动作表"。
出租车动作表
动作数值
含义
env.render()的提示
执行后的奖励
0
向下
South
-1
1
向上
North
-1
2
向右
East
-1
3
向左
West
-1
4
上车
Pickup
-1或-10
5
下车
Dropoff
+20或-10
SARSA的代码
首先,我们创建一个SARSA智能体类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class SARSAAgent : def __init__ (self, env, gamma=0.9 , learning_rate=0.2 , epsilon=.01 ) : ''' 初始化 :param env: 环境 :param gamma: 折扣因子 :param learning_rate: 学习率 :param epsilon: epsilon贪心策略 ''' self.gamma = gamma self.learning_rate = learning_rate self.epsilon = epsilon self.action_n = env.action_space.n self.q = np.zeros((env.observation_space.n, env.action_space.n)) def decide (self, state) : ''' epsilon贪心策略 :param state: 状态 :return: ''' if np.random.uniform() > self.epsilon: action = self.q[state].argmax() else : action = np.random.randint(self.action_n) return action def learn (self, state, action, reward, next_state, next_action ,done) : ''' 学习,也就是价值函数更新方法 :param state: 状态 :param action: 动作 :param reward: 奖励 :param next_state: 下一个状态 :param next_action: 下一个动作 :param done: 是否结束 :return: ''' u = reward + self.gamma * self.q[next_state, next_action] * (1. - done) td_error = u - self.q[state, action] self.q[state, action] += self.learning_rate * td_error
智能体负责决策和学习,决策就是我们上文提到的ε \varepsilon ε
接下来是SARSA算法,就是我们上文所讨论的SARSA的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def play_sarsa (env, agent, train=False, render=False) : ''' SARSA :param env: 环境 :param agent: 智能体 :param train: 是否训练 :param render: 是否render :return: ''' episode_reward = 0 observation = env.reset() action = agent.decide(observation) while True : if render: env.render() next_observation, reward, done, _ = env.step(action) episode_reward += reward next_action = agent.decide(next_observation) if train: agent.learn(observation, action, reward, next_observation, next_action, done) if done: break observation, action = next_observation, next_action return episode_reward
然后,我们可以实例化智能体,并进行训练,再试一试效果。
实例化智能体,并训练。
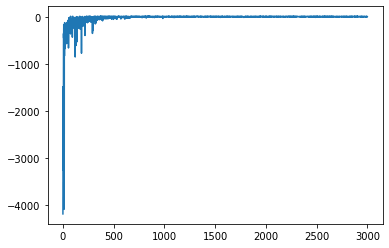
1 2 3 4 5 6 7 8 9 10 11 12 13 import matplotlib.pyplot as pltagent = SARSAAgent(env) episodes = 3000 episode_rewards = [] for episode in range(episodes): episode_reward = play_sarsa(env, agent, train=True ) episode_rewards.append(episode_reward) plt.plot(episode_rewards)
运行结果:
试一试效果。
1 2 3 4 5 agent.epsilon = 0. episode_rewards = [play_sarsa(env, agent) for _ in range(100 )] print('平均回合奖励 = {} / {} = {}' .format(sum(episode_rewards),len(episode_rewards), np.mean(episode_rewards)))
运行结果:
1 平均回合奖励 = 817 / 100 = 8.17
Q-Learning:离线策略时序差分方法
接下来,我们讨论离线策略方法。
Q-Learning的过程
离线策略是指产生数据的策略与评估改进的策略不是同一个策略。其基本思想是,虽然已有一个原始策略,但是并不针对这个原始策略进行采样,而是基于另一个策略进行采样。这另一个策略可以是先前学习到的策略,也可以是人类的策略等一些较为成熟的策略。观察这类策略的行为和回报,并根据这些回报评估和改进原始策略,以此达到学习的目的。
这么说或许略显晦涩难懂,我们来看具体的。
很多资料会在这时候讨论"重要性采样",因为离线策略的理论基础就是重要性采样。我们在这里不讨论,在《6.策略梯度》 这一章,再讨论"重要性采样",因为我认为,我们反过来,先弄明白什么是离线策略,再去讨论重要性采样,或许更容易理解。
在Q-Learning方法中,实际在与环境交互的时候,我们遵循的依旧是一个ε \varepsilon ε μ \mu μ π \pi π
π ( s ) = arg max a ∈ A ( s ) Q ( s , a ) \pi(s) = \argmax_{a\in\mathcal{A}(s)} Q(s,a)
π ( s ) = a ∈ A ( s ) a r g m a x Q ( s , a )
我们的更新方法是:
Q ( s , a ) ← Q ( s , a ) + α ( r + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s , a ) ) Q(s,a) \leftarrow Q(s,a) + \alpha(r + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s,a))
Q ( s , a ) ← Q ( s , a ) + α ( r + γ a t + 1 max Q ( s t + 1 , a t + 1 ) − Q ( s , a ) )
具体算法流程如下:
Q-Learning算法 输入 :输出 :Q ( s , a ) , s ∈ S , a ∈ A ( s ) Q(s,a),s \in \mathcal{S},a \in \mathcal{A}(s) Q ( s , a ) , s ∈ S , a ∈ A ( s ) 参数 :α \alpha α γ \gamma γ 初始化 :Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q(s,a) \leftarrow \text{任意值},s \in \mathcal{S},a \in \mathcal{A} Q ( s , a ) ← 任意值 , s ∈ S , a ∈ A Q ( s 终止 , a ) ← 0 , a ∈ A Q(s_{\text{终止}},a) \leftarrow 0,a \in \mathcal{A} Q ( s 终止 , a ) ← 0 , a ∈ A 时序差分更新 :(对每一条轨迹执行以下操作)s 0 s_0 s 0 t = 0 , 1 , 2 , ⋯ t=0,1,2,\cdots t = 0 , 1 , 2 , ⋯ s t = s 终止 s_t=s_{\text{终止}} s t = s 终止 s t s_t s t ε \varepsilon ε μ \mu μ a t a_t a t a t a_t a t r t r_t r t s t + 1 s_{t+1} s t + 1 Q ( s , a ) Q(s,a) Q ( s , a ) Q ( s , a ) ← Q ( s , a ) + α ( r + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s,a) \leftarrow Q(s,a) + \alpha(r + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s_t,a_t)) Q ( s , a ) ← Q ( s , a ) + α ( r + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) )
注意和SARSA的区别。s t + 1 s_{t+1} s t + 1 ε \varepsilon ε a t + 1 a_{t+1} a t + 1 s t + 1 , a t + 1 s_{t+1},a_{t+1} s t + 1 , a t + 1 Q ( s t , a t ) Q(s_t,a_t) Q ( s t , a t )
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_t + \gamma Q(s_{t+1},a_{t+1}) - Q(s_t,a_t))
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) )
而在Q-Learning中,不需要再去采取动作a t + 1 a_{t+1} a t + 1 s t + 1 , a t + 1 s_{t+1},a_{t+1} s t + 1 , a t + 1
Q ( s , a ) ← Q ( s , a ) + α ( r + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s,a) \leftarrow Q(s,a) + \alpha(r + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s_t,a_t))
Q ( s , a ) ← Q ( s , a ) + α ( r + γ a t + 1 max Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) )
Q-Learning的实现
接下来,我们来实现一个Q-Learning算法,继续以出租车调度为例。
首先,我们创建一个Q-Learning智能体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class QLearningAgent : def __init__ (self, env, gamma=0.9 , learning_rate=0.1 , epsilon=.01 ) : ''' 初始化 :param env: 环境 :param gamma: 折扣因子 :param learning_rate: 学习率 :param epsilon: epsilon贪心策略 ''' self.gamma = gamma self.learning_rate = learning_rate self.epsilon = epsilon self.action_n = env.action_space.n self.q = np.zeros((env.observation_space.n, env.action_space.n)) def decide (self, state) : ''' epsilon贪心策略 :param state: 状态 :return: ''' if np.random.uniform() > self.epsilon: action = self.q[state].argmax() else : action = np.random.randint(self.action_n) return action def learn (self, state, action, reward, next_state, done) : ''' 学习,也就是更新 :param state: 状态 :param action: 动作 :param reward: 奖励 :param next_state: 下一个状态 :param done: 是否完成 :return: ''' u = reward + self.gamma * self.q[next_state].max() * (1. - done) td_error = u - self.q[state, action] self.q[state, action] += self.learning_rate * td_error
接下来是Q-Learning算法,就是我们上文所讨论的Q-Learning的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def play_qlearning (env, agent, train=False, render=False) : ''' qlearning算法 :param env: 环境 :param agent: 智能体 :param train: 是否训练 :param render: 是否render :return: ''' episode_reward = 0 observation = env.reset() i = 0 while True : i = i+1 if i > 10000 : return 'drop' if render: env.render() action = agent.decide(observation) next_observation, reward, done, _ = env.step(action) episode_reward += reward if train: agent.learn(observation, action, reward, next_observation,done) if done: break observation = next_observation return episode_reward
然后,我们可以实例化智能体,并进行训练,再试一试效果。
实例化智能体,并训练。
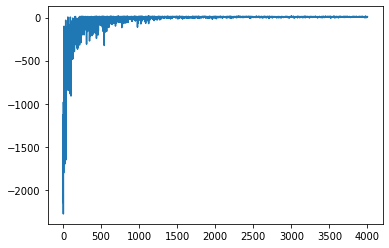
1 2 3 4 5 6 7 8 9 10 11 12 import matplotlib.pyplot as pltagent = QLearningAgent(env) episodes = 4000 episode_rewards = [] for episode in range(episodes): episode_reward = play_qlearning(env, agent, train=True ) episode_rewards.append(episode_reward) plt.plot(episode_rewards)
试一试效果。
1 2 3 4 5 6 7 agent.epsilon = 0. episode_rewards = [play_qlearning(env, agent) for _ in range(100 )] episode_rewards = [e for e in episode_rewards if e != 'drop' ] print('平均回合奖励 = {} / {} = {}' .format(sum(episode_rewards),len(episode_rewards), np.mean(episode_rewards)))
运行结果:
1 平均回合奖励 = 759 / 98 = 7.744897959183674
多步时序差分法
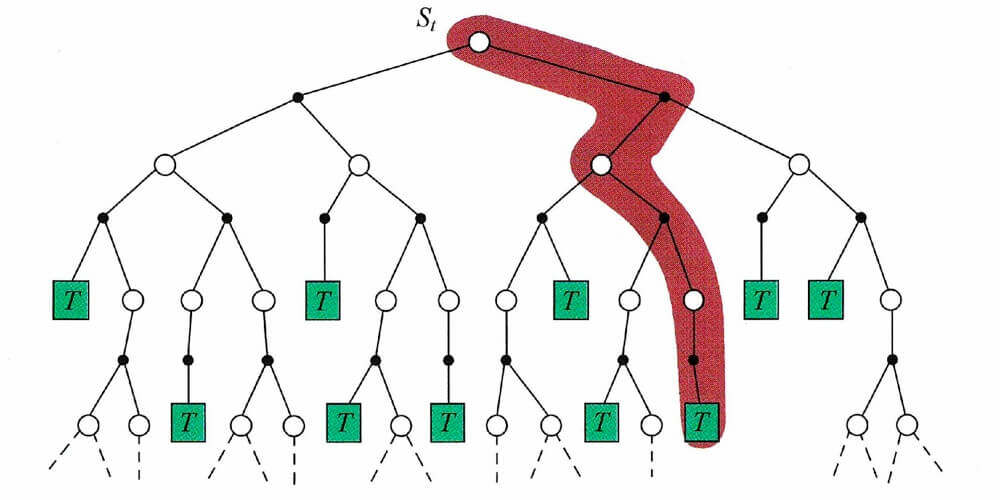
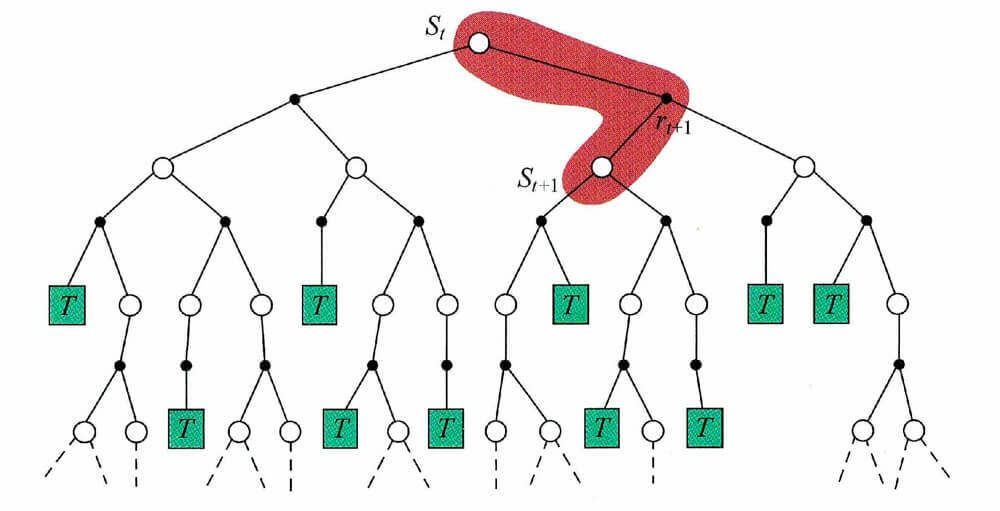
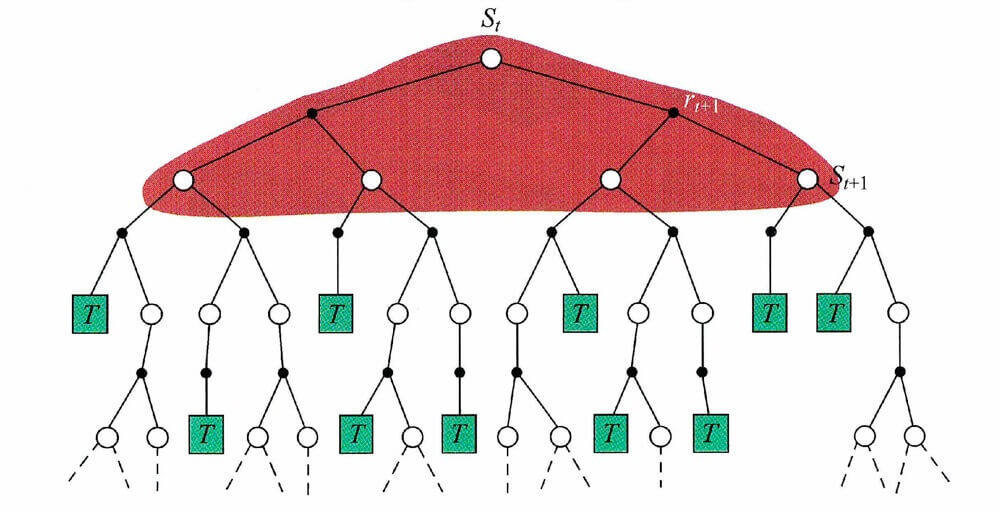
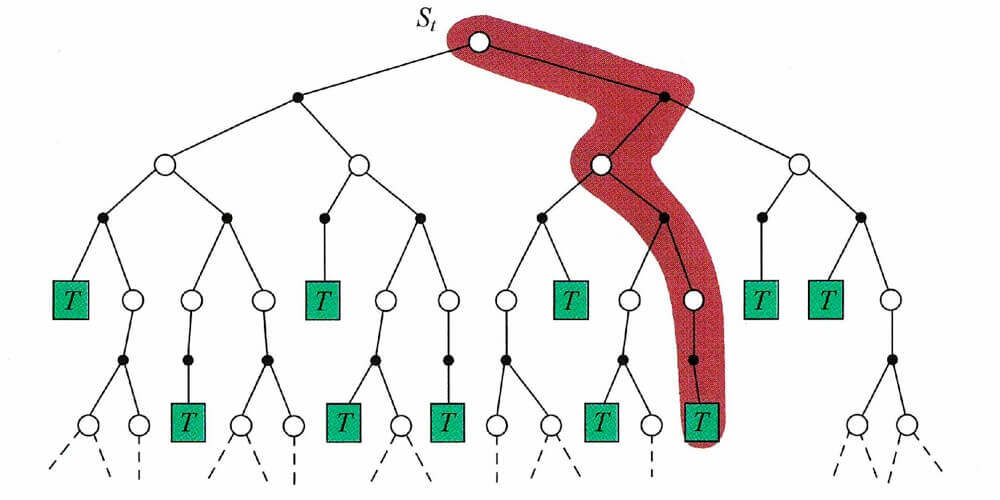
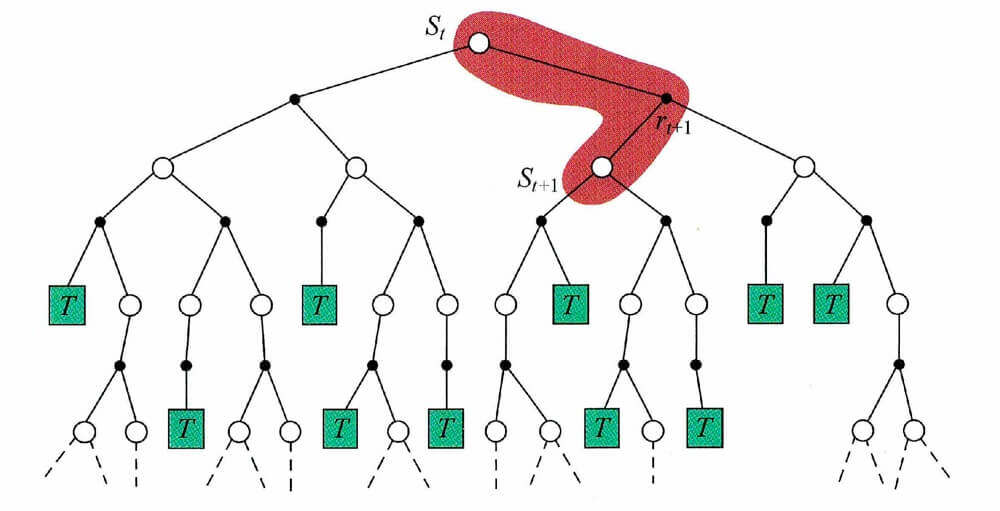
在上文,我们有这么两张图片。
第一张是蒙特卡洛的,第二张是时序差分的。这两张图片很好的反映了两种方法的关键不同点。N N N
V ( s t ) ← V ( s t ) + α ( G t − V ( s t ) ) V(s_t) \leftarrow V(s_t) + \alpha(G_t - V(s_t))
V ( s t ) ← V ( s t ) + α ( G t − V ( s t ) )
G t G_t G t
G t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ + γ T − t r T G_t = r_{t} + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots + \gamma^{T-t} r_T
G t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ + γ T − t r T
而在时序差分中,距离是1 1 1
G t = G t 1 = r t + γ V ( s t + 1 ) G_t = G_t^1 = r_{t} + \gamma V(s_{t+1})
G t = G t 1 = r t + γ V ( s t + 1 )
那么,如果在( 1 , N ) (1,N) ( 1 , N )
G t m = r t + γ r t + 1 + ⋯ + γ m − 1 r t + m − 1 + γ m G t + m = [ ∑ i = 0 m − 1 γ i r t + i ] + G t + m \begin{aligned}
G_t^m & = r_{t} + \gamma r_{t+1} + \cdots + \gamma^{m-1} r_{t+m-1} + \gamma^m G_{t+m} \\
& = \bigg[\sum_{i=0}^{m-1} \gamma^i r_{t+i}\bigg] + G_{t+m}
\end{aligned}
G t m = r t + γ r t + 1 + ⋯ + γ m − 1 r t + m − 1 + γ m G t + m = [ i = 0 ∑ m − 1 γ i r t + i ] + G t + m
在SARSA和Q-Learning中,γ m Q ( s t + m , a t + m ) \gamma^m Q(s_{t+m},a_{t+m}) γ m Q ( s t + m , a t + m )
在SARSA中,γ m Q ( s t + m , a t + m ) = Q ( s t + m , a t + m ) \gamma^m Q(s_{t+m},a_{t+m}) = Q(s_{t+m},a_{t+m}) γ m Q ( s t + m , a t + m ) = Q ( s t + m , a t + m )
在Q-Learning中,γ m Q ( s t + m , a t + m ) = max a t + m Q ( s t + m , a t + m ) \gamma^m Q(s_{t+m},a_{t+m}) = \max_{a_{t+m}}Q(s_{t+m},a_{t+m}) γ m Q ( s t + m , a t + m ) = max a t + m Q ( s t + m , a t + m )
多步时序差分比单步时序差分更准一些,毕竟"从上海到杭州的实际时间加上杭州到南昌的预估时间"总是比"从上海到嘉兴的实际时间加上嘉兴到南昌的预估时间"要准一些。但是呢,时序差分可每一步在线学习,不必等到回合结束,可以从不完整的序列中学习,虽然收敛性差,但是耗费的时间少。蒙特卡洛必须等到回合结束,虽然收敛性较好,但是耗费的时间多。