函数近似简介
在前面三章,我们讨论了"动态规划"、“蒙特卡洛"和"时序差分”,这三种方法,其实做的都是同样的事情,更新表格和查表。毕竟,状态和动作都是有限的。1 0 170 10^{170} 1 0 1 7 0
这时候,换一个思路,利用函数近似的方法对价值函数进行表示。
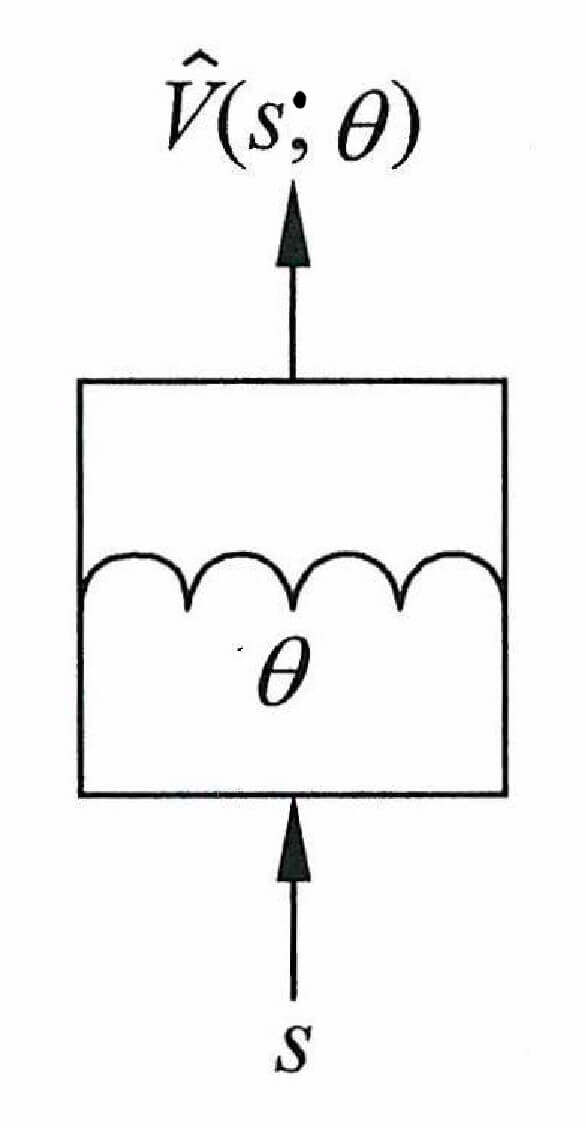
V ( s ) = V ^ ( s ; θ ) V(s) = \hat{V}(s;\theta)
V ( s ) = V ^ ( s ; θ )
其中,V ^ ( s ; θ ) \hat{V}(s;\theta) V ^ ( s ; θ ) θ \theta θ
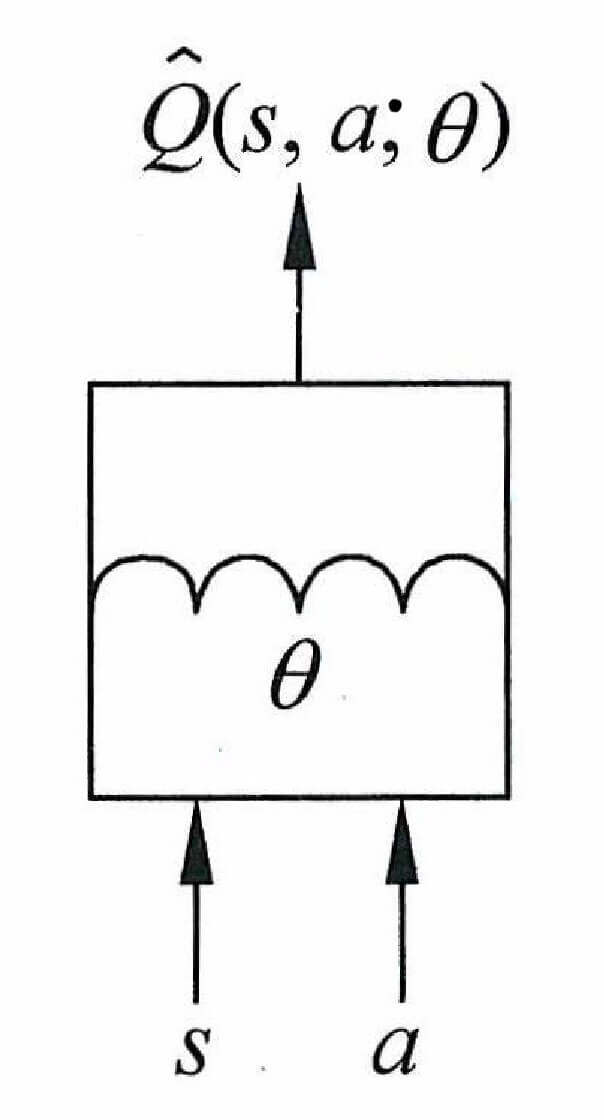
对于动作价值函数
Q ( s , a ) = Q ^ ( s , a ; θ ) Q(s,a) = \hat{Q}(s,a;\theta)
Q ( s , a ) = Q ^ ( s , a ; θ )
其中Q ^ ( s , a ; θ ) \hat{Q}(s,a;\theta) Q ^ ( s , a ; θ ) θ \theta θ
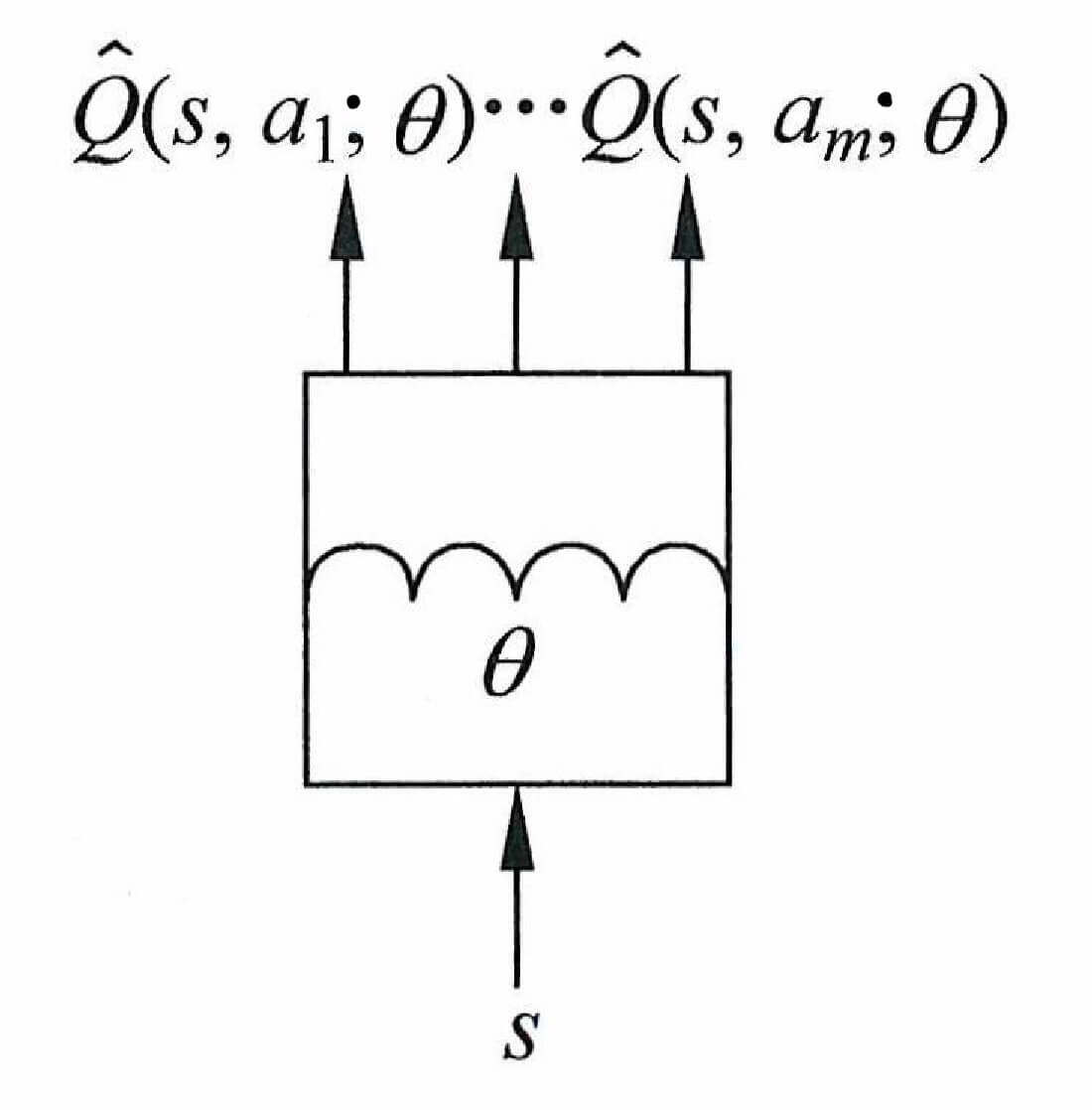
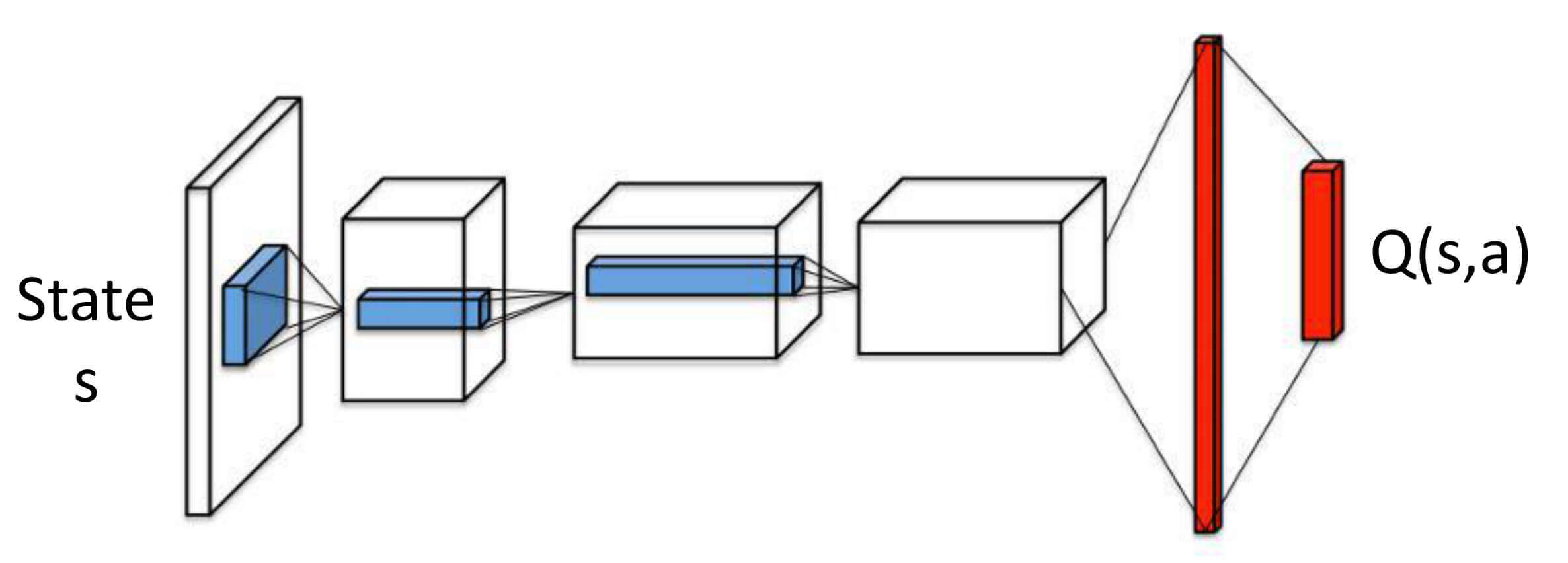
除了上述两种近似函数,还有一种,输入是状态s s s Q ^ ( s , a 1 , θ ) , Q ^ ( s , a 2 , θ ) , ⋯ , Q ^ ( s , a m , θ ) \hat{Q}(s,a_1,\theta),\hat{Q}(s,a_2,\theta),\cdots,\hat{Q}(s,a_m,\theta) Q ^ ( s , a 1 , θ ) , Q ^ ( s , a 2 , θ ) , ⋯ , Q ^ ( s , a m , θ )
函数近似方法可以分为两种:
线性近似
非线性近似
线性近似是指,用多个基函数的线性组合来表示近似函数,即:
V ^ ( s , θ ) = ∑ i d θ i x i ( s ) \hat{V}(\bold{s},{\theta}) = \sum_{i}^d {\theta}_i x_i(\bold{s})
V ^ ( s , θ ) = i ∑ d θ i x i ( s )
常见的基函数有多项式函数、傅立叶函数和径向函数。
傅立叶函数是将周期表现为不同频率的正弦函数和余弦函数的加权和
径向函数是一个取值仅仅依赖于距离远点距离的函数
线性近似的方法有可以分为两类,一类是"增量法",针对每一步(轨迹中的每一个状态转换序列),一旦有增量发生,则立即优化近似函数;另一类是"批量法",针对一批历史数据(如一段轨迹)集中进行近似。
近似的过程就是先确定基函数的个数和形式,然后调参。但是呢,因为基函数的个数和形式有限,又需要在近似之前确定,在近似过程中又无法改变,因此这种方法的近似能力非常有限。
线性近似有点类似与集成学习中的Boosting方法,基函数就像基学习器,但是又不完全一样,在集成学习中,我们的基学习器主要是决策树,而决策树的个数和决策树的深度、叶子节点的个数等,不需要在训练之前就确定。《集成学习概览及其Python实现》 。
线性近似的近似能力非常有限,但是一个东西,近似能力极强。
这篇论文,从理论上证明了,多层的神经网络可以逼近任何的数据分布,也就是说神经网络是"万能"的。
关于神经网络,可以参考《深度学习初步及其Python实现》 。
接下来,我们着重讨论一个非线性近似的代表,DQN(Deep Q-Network),深度Q学习
DQN的要点
DQN建立在Q-Learing的基础上,在上一章,我们讨论过Q-Learning。
Q-Learning是一种离线策略时序差分方法,使用ε \varepsilon ε μ \mu μ π \pi π r + γ max a t + 1 Q ( s t + 1 , a t + 1 ) r + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) r + γ max a t + 1 Q ( s t + 1 , a t + 1 )
DQN在Q-Learning上的改进有:
DQN使用神经网络来替换"表格"。
DQN利用经历回放对神经网络进行训练。
DQN设置了单独的目标网络来处理TD偏差。
接下来,我们来解释一下,为什么要做这些改进。
DQN使用神经网络来替换"表格"
这个很容易理解,我们在上文也有过讨论,因为状态空间很大或者连续,无法用查表法来求解每个状态的价值,因此考虑使用神经网络来表示价值函数,在这里,神经网络就是动作价值函数。参数为每层网络的权重及偏置,用θ {\theta} θ θ {\theta} θ s s s s s s s s s Q ^ ( s , a 1 , θ ) , Q ^ ( s , a 2 , θ ) , ⋯ , Q ^ ( s , a m , θ ) \hat{Q}(s,a_1,\theta),\hat{Q}(s,a_2,\theta),\cdots,\hat{Q}(s,a_m,\theta) Q ^ ( s , a 1 , θ ) , Q ^ ( s , a 2 , θ ) , ⋯ , Q ^ ( s , a m , θ )
DQN利用经历回放对神经网络进行训练
接下来,我们讨论第二个改进,DQN利用经历回放对神经网络进行训练,也有资料把"经历回放"称为"经验回放"。
在上一章,以出租车调度为例的Q-Learing的代码中,我们在play_qlearning这个函数中,专门写了这么两行:
1 2 3 i = i+1 if i > 10000: return 'drop'
因为我们可能会得到一个很不好的策略,这个策略可能一直在地图上转圈,一直不接乘客或者一直不放乘客下车。当时,我们处理这个问题的方法非常简单粗暴,直接把这个不好的轨迹drop,在100个轨迹中,出现了两次这样的轨迹,都被我们drop了。那么,这一章呢,我们并不打算改进,继续看看这个问题。出租车每移动一次,就会得到− 1 -1 − 1 《深度学习初步及其Python实现:8.循环神经网络》 中,我们专门讨论过梯度爆炸的解决方法:
直接对张量进行限幅
通过限制张量W \bold{W} W
全局范数裁剪
有些资料认为利用"经历回放"的原因是为了解决"梯度爆炸",我对这个略有疑虑,至少我感觉"经历回放"是充分但不是必要的方法。 我认为"经历回放"的主要作用是下面这个。
在《深度学习初步及其Python实现:5.过拟合》 中,我们有讨论过:“在训练集上表现很好的模型,在测试集中也会表现很好。这是基于一个假设,训练集和测试集是独立同分布的。”
类似的问题,我们在之前也遇到过。在《深度学习初步及其Python实现》 中,我们拿到的训练数据可能把有同一个标签的数据放在一块了,所以,当时,我们用多次用到这么一段代码:
1 db_train = db_train.shuffle()
利用这个方法,把训练数据打乱。
现在,同样的,我们的思路也是把训练数据打乱,使得数据更像是独立同分布。
接下来,我们讨论经历回放的具体操作。智能体跟环境不断交互,将在环境中学习积累的数据存储到记忆库中。存储的时候,是按照时间步为单元进行存储的,如< s 1 , a 1 , s 2 , a 2 > <s_1,a_1,s_2,a_2> < s 1 , a 1 , s 2 , a 2 >
利用"经历回放"还有一个好处,可以重复使用经历,对于数据获取困难的情况尤其适用。
小结一下,经历回放的作用:
使得数据更像是独立同分布
可以重复使用经历
DQN设置了单独的目标网络来处理TD偏差
TD偏差,这个并不是新的概念,只是在上一章我们讨论时序差分的时候没有提而已。r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) r_t + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) r_t + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s_t,a_t) r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t )
最后一个改进点是DQN设置了单独的目标网络来处理TD偏差。Q ( s , a ) Q(s,a) Q ( s , a )
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ) Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_t + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s_t,a_t))
Q ( s t , a t ) ← Q ( s t , a t ) + α ( r t + γ a t + 1 max Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) )
那么,现在呢?我们应该怎么更新神经网络中的参数θ {\theta} θ Q ( s ′ , a ′ ) Q(s',a') Q ( s ′ , a ′ ) Q ( s ′ , a ′ ; θ ) Q(s',a';\theta) Q ( s ′ , a ′ ; θ )
θ = θ + α ( r + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) − Q ( s , a ; θ ) ) ∂ Q ( s , a ; θ ) ∂ θ {\theta} = {\theta} + \alpha\bigg(r + \gamma \max_{a_{t+1}} Q(s_{t+1},a_{t+1};{\theta}) - Q(s,a;{\theta})\bigg) \frac{\partial Q(s,a;{\theta})}{\partial {\theta}}
θ = θ + α ( r + γ a t + 1 max Q ( s t + 1 , a t + 1 ; θ ) − Q ( s , a ; θ ) ) ∂ θ ∂ Q ( s , a ; θ )
但是,这样做的话,我们在更新θ \theta θ r + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) r + \gamma \max_{a_{t+1}} Q(s_{t+1},a_{t+1};{\theta}) r + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) Q ( s , a ; θ ) Q(s,a;{\theta}) Q ( s , a ; θ ) Q ( s , a ; θ ) Q(s,a;{\theta}) Q ( s , a ; θ ) r + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) r + \gamma \max_{a_{t+1}} Q(s_{t+1},a_{t+1};{\theta}) r + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ )
这样,更新权重时针对的目标不会在每次迭代都变化,是一个固定的目标。在完成一定次数的更新后,再将评估网络的权重值赋给目标网络,进而进行下一批更新。这样,目标网络也能得到更新。
这就像在户外徒步的时候,我们有对路线熟悉的同学走在前面,我们称之为向导或前锋(雇佣的当地人称之为向导,和我们一起来玩的称之为前锋)。向导前锋要负责把大家带到营地。但是如果大家走的太慢,向导前锋又一直在往前走的话,岂不是分分钟,这个队伍就丢了?所以,这时候,请向导前锋停下来,等一等。
由于在目标网络没有变化的一段时间内回报的估计是相对固定的,目标网络的引入增加了学习的稳定性。
除了DQN有两个神经网络,我们在《深度学习初步及其Python实现:11.生成对抗网络》 也讨论过拥有两个神经网络的模型,生成对抗网络。而且,在生成对抗网络中,我们有一个比较像的小技巧,在一个step中多次训练鉴别器。有点类似。
综上所述,我们把参数更新的方法修改为:
θ = θ + α ( r 1 + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ 目标 ) − Q ( s t , a t ; θ ) ) ∂ Q ( s t , a t ; θ ) ∂ θ {\theta} = {\theta} + \alpha\bigg(r_1 + \gamma \max_{a_{t+1}} Q(s_{t+1},a_{t+1};\bold{\theta_{\text{目标}}}) - Q(s_t,a_t;{\theta})\bigg) \frac{\partial Q(s_t,a_t;{\theta})}{\partial {\theta}}
θ = θ + α ( r 1 + γ a t + 1 max Q ( s t + 1 , a t + 1 ; θ 目标 ) − Q ( s t , a t ; θ ) ) ∂ θ ∂ Q ( s t , a t ; θ )
DQN的流程
DQN算法 输入 :输出 :θ \theta θ 初始化 :D \mathcal{D} D θ \theta θ Q θ Q_{\theta} Q θ θ 目标 ← θ \theta_{\text{目标}} \leftarrow \theta θ 目标 ← θ θ 目标 \theta_{\text{目标}} θ 目标 Q θ 目标 Q_{\theta_{\text{目标}}} Q θ 目标 对每一条轨迹执行以下操作 :s t s_t s t t = 1 t=1 t = 1 t = 1 , 2 , ⋯ , T t = 1,2,\cdots,T t = 1 , 2 , ⋯ , T 轨迹内的每一个时间步执行以下操作 :ε \varepsilon ε μ \mu μ a t a_t a t ε \varepsilon ε 1 − ε 1-\varepsilon 1 − ε r t + 1 r_{t+1} r t + 1 s t + 1 s_{t+1} s t + 1 s t , a t , r t + 1 , s t + 1 s_t,a_t,r_{t+1},s_{t+1} s t , a t , r t + 1 , s t + 1 D \mathcal{D} D D \mathcal{D} D k k k s j , a j , r j + 1 , s j + 1 s_j,a_j,r_{j+1},s_{j+1} s j , a j , r j + 1 , s j + 1 y j y_j y j s j + 1 s_{j+1} s j + 1 y j = r j + γ max a ′ Q ( s ′ , a ′ ; θ 目标 ) y_j = r_j + \gamma \max_{a'} Q(s',a';{\theta}_{\text{目标}}) y j = r j + γ max a ′ Q ( s ′ , a ′ ; θ 目标 ) s j + 1 s_{j+1} s j + 1 y j = r j y_j = r_j y j = r j k k k L o s s ( θ ) = 1 k ∑ i = 1 k ( y i − Q ( s i , a j ; θ ) ) 2 Loss(\theta) = \frac{1}{k} \sum^k_{i=1}(y_i - Q(s_i,a_j;\theta))^2 L o s s ( θ ) = k 1 ∑ i = 1 k ( y i − Q ( s i , a j ; θ ) ) 2 L o s s ( θ ) Loss(\theta) L o s s ( θ ) ∇ θ = ∂ L o s s ( θ ) ∂ θ \nabla \theta = \frac{\partial Loss(\theta)}{\partial \theta} ∇ θ = ∂ θ ∂ L o s s ( θ ) θ ← θ + α ∇ θ \theta \leftarrow \theta + \alpha \nabla \theta θ ← θ + α ∇ θ θ 目标 ← θ \theta_{\text{目标}} \leftarrow \theta θ 目标 ← θ
DQN的实现
我们以小车上山问题为例。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第六章。
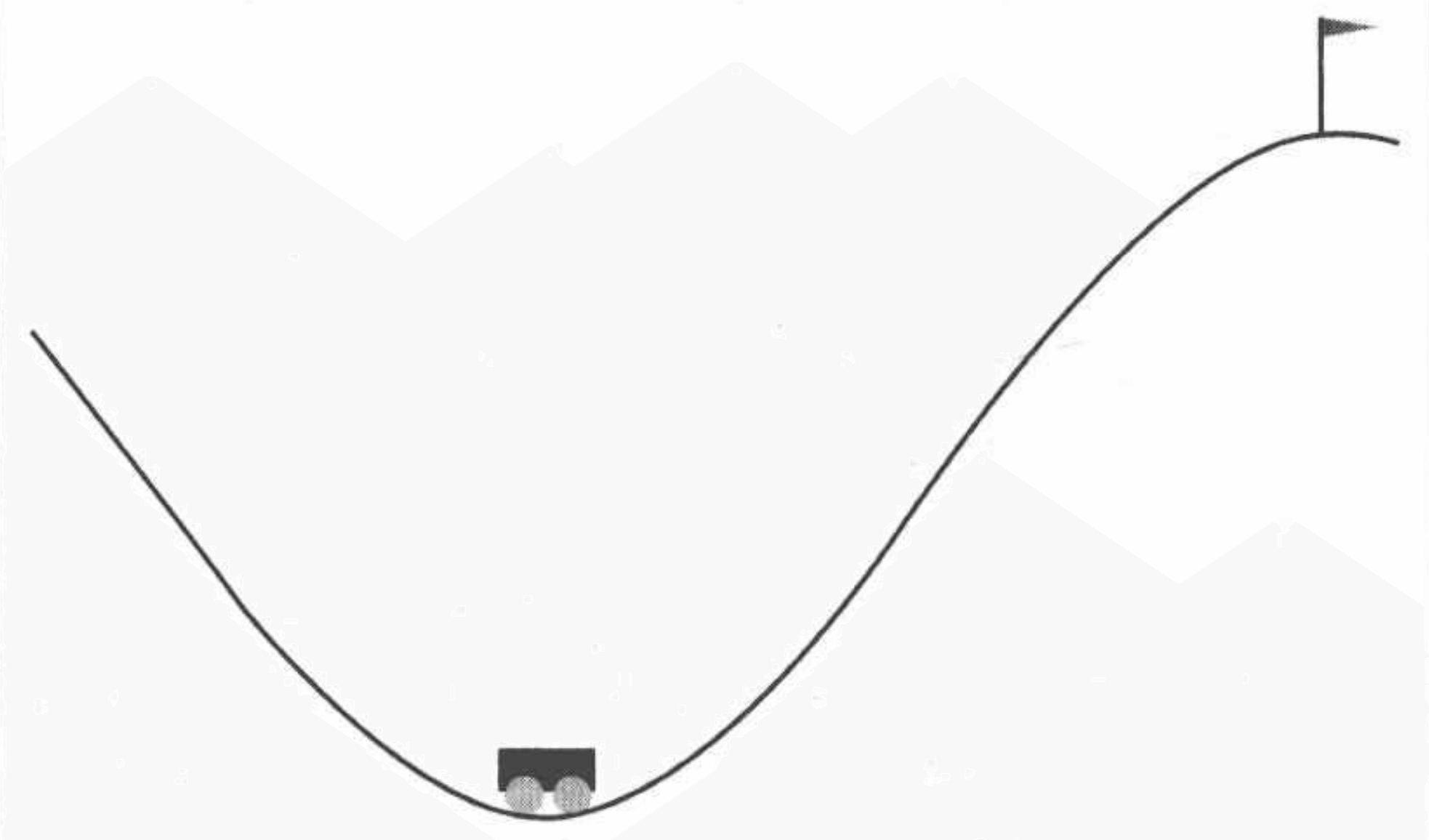
小车上山问题描述
如图所示,一辆小车在一段范围内行驶。在任一时刻,在水平方向看,小车位置的范围是[ − 1.2 , 0.6 ] [-1.2,0.6] [ − 1 . 2 , 0 . 6 ] [ − 0.07 , 0.07 ] [-0.07,0.07] [ − 0 . 0 7 , 0 . 0 7 ] 0.5 0.5 0 . 5
小车的位置和速度是有数学表达式的,记t t t ( t = 0 , 1 , 2 , ⋯ ) (t=0,1,2,\cdots) ( t = 0 , 1 , 2 , ⋯ ) X t X_t X t V t V_t V t A t ∈ { 0 , 1 , 2 } A_t \in \{0,1,2\} A t ∈ { 0 , 1 , 2 } X 0 ∈ [ − 0.6 , − 0.4 ) X_0 \in [-0.6,-0.4) X 0 ∈ [ − 0 . 6 , − 0 . 4 ) V 0 = 0 V_0 = 0 V 0 = 0 t t t t + 1 t+1 t + 1
X t + 1 = X t + V t V t + 1 = V t + 0.001 ( A t − 1 ) − 0.0025 cos ( 3 X t ) \begin{aligned}
X_{t+1} &= X_t + V_t \\
V_{t+1} &= V_t + 0.001(A_t - 1) - 0.0025 \cos (3 X_t)
\end{aligned}
X t + 1 V t + 1 = X t + V t = V t + 0 . 0 0 1 ( A t − 1 ) − 0 . 0 0 2 5 cos ( 3 X t )
注意!小车位置的范围是[ − 1.2 , 0.6 ] [-1.2,0.6] [ − 1 . 2 , 0 . 6 ] [ − 0.07 , 0.07 ] [-0.07,0.07] [ − 0 . 0 7 , 0 . 0 7 ] X t + 1 X_{t+1} X t + 1 V t + 1 V_{t+1} V t + 1
我们通过这个表达式也可以看到,总是向右施加力量的话,并不能使小车到达目的地。
而且!当然!这个表达式,只是为了描述问题用。
我们构造的智能体不知道环境确定小车位置速度的表达式。
环境及其使用
示例代码:
1 2 3 4 5 6 7 8 9 10 import gymenv = gym.make('MountainCar-v0' ) env.seed(0 ) print('状态空间 = {}' .format(env.observation_space)) print('动作空间 = {}' .format(env.action_space)) print('位置范围 = {}' .format((env.unwrapped.min_position, env.unwrapped.max_position))) print('速度范围 = {}' .format((-env.unwrapped.max_speed,env.unwrapped.max_speed))) print('目标位置 = {}' .format(env.unwrapped.goal_position))
运行结果:
1 2 3 4 5 状态空间 = Box(-1.2000000476837158, 0.6000000238418579, (2,), float32) 动作空间 = Discrete(3) 位置范围 = (-1.2, 0.6) 速度范围 = (-0.07, 0.07) 目标位置 = 0.5
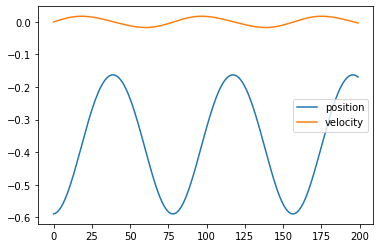
在上文,我们通过数学表达式发现,总是向右施加力量,并不能使小车成功抵达目的地。现在,我们来试一下,看看是不是这样。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import matplotlib.pyplot as pltpositions, velocities = [], [] observation = env.reset() while True : positions.append(observation[0 ]) velocities.append(observation[1 ]) next_observation, reward, done, _ = env.step(2 ) if done: break observation = next_observation if next_observation[0 ] > 0.5 : print('成功到达' ) else : print('失败退出' ) fig, ax = plt.subplots() ax.plot(positions, label='position' ) ax.plot(velocities, label='velocity' ) ax.legend()
运行结果:
DQN的代码
接下来,我们来实现一个DQN。
经历库
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import pandas as pdclass DQNReplayer : def __init__ (self, capacity) : ''' :param capacity: 经历库的大小 ''' self.memory = pd.DataFrame(index=range(capacity),columns=['observation' , 'action' , 'reward' ,'next_observation' , 'done' ]) self.i = 0 self.count = 0 self.capacity = capacity def store (self, *args) : self.memory.loc[self.i] = args self.i = (self.i + 1 ) % self.capacity self.count = min(self.count + 1 , self.capacity) def sample (self, size) : indices = np.random.choice(self.count, size=size) return (np.stack(self.memory.loc[indices, field]) for field in self.memory.columns)
DQN智能体
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import tensorflow as tftf.random.set_seed(0 ) from tensorflow import kerasclass DQNAgent : def __init__ (self, env, net_kwargs={}, gamma=0.99 , epsilon=0.001 ,replayer_capacity=10000 , batch_size=64 ) : ''' :param env: 环境 :param net_kwargs: :param gamma: 折扣因子 :param epsilon: epsilon探索策略 :param replayer_capacity: 经历库的大小 :param batch_size: batch ''' observation_dim = env.observation_space.shape[0 ] self.action_n = env.action_space.n self.gamma = gamma self.epsilon = epsilon self.batch_size = batch_size self.replayer = DQNReplayer(replayer_capacity) self.evaluate_net = self.build_network(input_size=observation_dim,output_size=self.action_n, **net_kwargs) self.target_net = self.build_network(input_size=observation_dim,output_size=self.action_n, **net_kwargs) self.target_net.set_weights(self.evaluate_net.get_weights()) def build_network (self, input_size, hidden_sizes, output_size,activation=tf.nn.relu, output_activation=None,learning_rate=0.01 ) : model = keras.Sequential() for layer, hidden_size in enumerate(hidden_sizes): kwargs = dict(input_shape=(input_size,)) if not layer else {} model.add(keras.layers.Dense(units=hidden_size,activation=activation, **kwargs)) model.add(keras.layers.Dense(units=output_size,activation=output_activation)) optimizer = tf.optimizers.Adam(lr=learning_rate) model.compile(loss='mse' , optimizer=optimizer) return model def learn (self, observation, action, reward, next_observation, done) : self.replayer.store(observation, action, reward, next_observation,done) observations, actions, rewards, next_observations, dones = self.replayer.sample(self.batch_size) next_qs = self.target_net.predict(next_observations) next_max_qs = next_qs.max(axis=-1 ) us = rewards + self.gamma * (1. - dones) * next_max_qs targets = self.evaluate_net.predict(observations) targets[np.arange(us.shape[0 ]), actions] = us self.evaluate_net.fit(observations, targets, verbose=0 ) if done: self.target_net.set_weights(self.evaluate_net.get_weights()) def decide (self, observation) : if np.random.rand() < self.epsilon: return np.random.randint(self.action_n) qs = self.evaluate_net.predict(observation[np.newaxis]) return np.argmax(qs)
play_qlearning
正如我们上文讨论的,DQN的训练过程和Q-Learning的训练过程并无主要区别,在这里,我们复用上一章的play_qlearning方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def play_qlearning (env, agent, train=False, render=False) : episode_reward = 0 observation = env.reset() while True : if render: env.render() action = agent.decide(observation) next_observation, reward, done, _ = env.step(action) episode_reward += reward if train: agent.learn(observation, action, reward, next_observation, done) if done: break observation = next_observation return episode_reward
训练
示例代码:
1 2 3 4 5 6 7 8 9 10 net_kwargs = {'hidden_sizes' : [64 , 64 ], 'learning_rate' : 0.001 } agent = DQNAgent(env, net_kwargs=net_kwargs) episodes = 500 episode_rewards = [] for episode in range(episodes): episode_reward = play_qlearning(env, agent, train=True ) episode_rewards.append(episode_reward) print('{} {}' .format(episode,episode_reward))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 0 -200.0 1 -200.0 2 -200.0 3 -200.0 4 -200.0 【部分运行结果略】 495 -172.0 496 -89.0 497 -113.0 498 -147.0 499 -149.0
测试
再来看看效果。
1 2 3 4 agent.epsilon = 0. episode_rewards = [play_qlearning(env, agent) for _ in range(100 )] print('平均回合奖励 = {} / {} = {}' .format(sum(episode_rewards),len(episode_rewards), np.mean(episode_rewards)))
运行结果:
1 平均回合奖励 = -13435.0 / 100 = -134.35
DoubleDQN
最大化偏差的缺点
在来看看我们的TD偏差
r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) r_t + \gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) - Q(s_t,a_t)
r t + γ a t + 1 max Q ( s t + 1 , a t + 1 ) − Q ( s t , a t )
我们要max a t + 1 Q ( s t + 1 , a t + 1 ) \max_{a_{t+1}}Q(s_{t+1},a_{t+1}) max a t + 1 Q ( s t + 1 , a t + 1 )
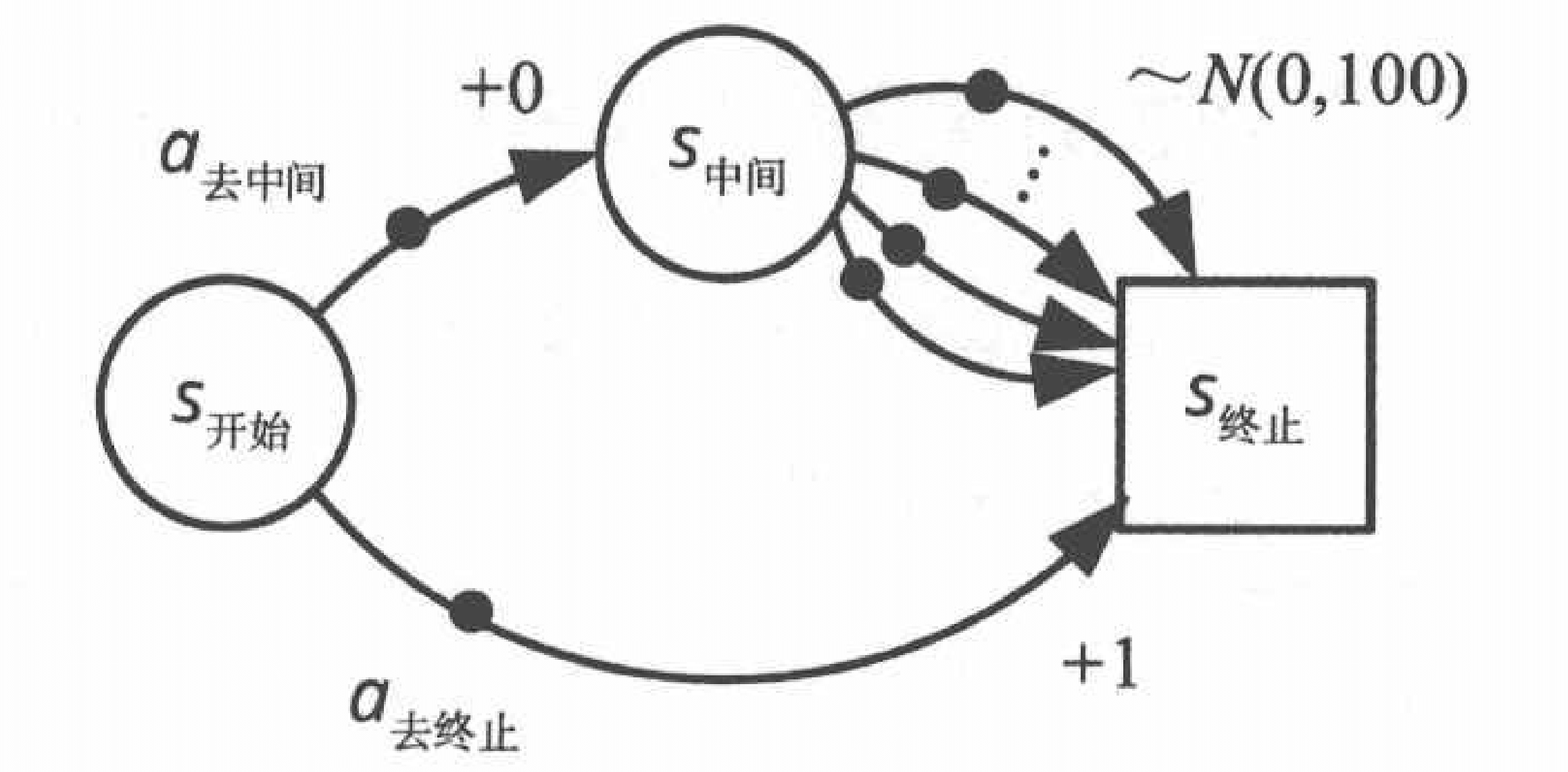
但!假设存在这么一个环境:
我们解释以下从S 中间 S_{\text{中间}} S 中间 S 终止 S_{\text{终止}} S 终止 S 中间 S_{\text{中间}} S 中间 S 终止 S_{\text{终止}} S 终止 S 终止 S_{\text{终止}} S 终止 0 0 0 1 1 1 V ⋆ ( S 中间 ) = 0 V_{\star}(S_{\text{中间}}) = 0 V ⋆ ( S 中间 ) = 0 V ⋆ ( S 开始 ) = 1 V_{\star}(S_{\text{开始}}) = 1 V ⋆ ( S 开始 ) = 1 π ⋆ ( S 开始 ) = a 去终止 \pi_{\star}(S_{\text{开始}})=a_{\text{去终止}} π ⋆ ( S 开始 ) = a 去终止 S 中间 S_{\text{中间}} S 中间 max a ∈ A ( S 中间 ) Q ( S 中间 , a ) \max_{a \in \mathcal{A}(S_{\text{中间}})} Q(S_{\text{中间}},a) max a ∈ A ( S 中间 ) Q ( S 中间 , a ) π ( S 开始 ) = a 去中间 \pi(S_{\text{开始}}) = a_{\text{去中间}} π ( S 开始 ) = a 去中间
为了在一定程度上克服这个问题,我们引进一个新的方法DoubleDQN。特别注意,其实DoubleDQN并没有完全解决估计的动作价值偏大的问题,只是在一定的程序上克服了。
DoubleDQN,顾名思义,两个DQN。在上文我们讨论过,一个DQN有两个神经网络,一个目标网络,一个评估网络。那么DoubleDQN有几个网络呢?还是两个。
我们用评估网络选择动作,网络参数为θ \theta θ
a ⋆ = arg max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) a_{\star} = \argmax_{a_{t+1}} Q(s_{t+1},{a_{t+1}};\theta)
a ⋆ = a t + 1 a r g m a x Q ( s t + 1 , a t + 1 ; θ )
然后,使用目标网络找到这个动作对应的Q Q Q θ 目标 \theta_{\text{目标}} θ 目标
Y D D Q N = r + γ Q ( s t + 1 , a ⋆ ; θ 目标 ) Y^{DDQN} = r + \gamma Q(s_{t+1},a_{\star};\theta_{\text{目标}})
Y D D Q N = r + γ Q ( s t + 1 , a ⋆ ; θ 目标 )
即
Y D D Q N = r + γ Q ( s t + 1 , arg max a t + 1 Q ( s t + 1 , a t + 1 ; θ ) ; θ 目标 ) Y^{DDQN} = r + \gamma Q(s_{t+1},\argmax_{a_{t+1}} Q(s_{t+1},{a_{t+1}};\theta);\theta_{\text{目标}})
Y D D Q N = r + γ Q ( s t + 1 , a t + 1 a r g m a x Q ( s t + 1 , a t + 1 ; θ ) ; θ 目标 )
和DQN对比一下,在DQN中,最佳动作来自于目标网络。即最佳动作a ⋆ = arg max a ( s , a ; θ 目标 ) a_{\star} = \argmax_a(s,a;\theta_{\text{目标}}) a ⋆ = a r g m a x a ( s , a ; θ 目标 )
DoubleDQN的过程
DoubleDQN算法 输入 :输出 :θ \theta θ 初始化 :D \mathcal{D} D θ \theta θ Q θ Q_{\theta} Q θ θ 目标 ← θ \theta_{\text{目标}} \leftarrow \theta θ 目标 ← θ θ 目标 \theta_{\text{目标}} θ 目标 Q θ 目标 Q_{\theta_{\text{目标}}} Q θ 目标 对每一条轨迹执行以下操作 :s t s_t s t t = 1 t=1 t = 1 t = 1 , 2 , ⋯ , T t = 1,2,\cdots,T t = 1 , 2 , ⋯ , T 轨迹内的每一个时间步执行以下操作 :ε \varepsilon ε μ \mu μ a t a_t a t ε \varepsilon ε 1 − ε 1-\varepsilon 1 − ε r t + 1 r_{t+1} r t + 1 s t + 1 s_{t+1} s t + 1 s t , a t , r t + 1 , s t + 1 s_t,a_t,r_{t+1},s_{t+1} s t , a t , r t + 1 , s t + 1 D \mathcal{D} D D D D k k k s j , a j , r j + 1 , s j + 1 s_j,a_j,r_{j+1},s_{j+1} s j , a j , r j + 1 , s j + 1 y j y_j y j s j + 1 s_{j+1} s j + 1 y j = r j + γ Q ( s t + 1 , arg max a ′ ( s t + 1 , a ′ ; θ ) ; θ 目标 ) y_j = r_j + \gamma Q(s_{t+1},\argmax_{a'}(s_{t+1},a';{\theta});{\theta}_{\text{目标}}) y j = r j + γ Q ( s t + 1 , a r g m a x a ′ ( s t + 1 , a ′ ; θ ) ; θ 目标 ) s j + 1 s_{j+1} s j + 1 y j = r j y_j = r_j y j = r j k k k L o s s ( θ ) = 1 k ∑ i = 1 k ( y i − Q ( s i , a j ; θ ) ) 2 Loss(\theta) = \frac{1}{k} \sum^k_{i=1}(y_i - Q(s_i,a_j;\theta))^2 L o s s ( θ ) = k 1 ∑ i = 1 k ( y i − Q ( s i , a j ; θ ) ) 2 L o s s ( θ ) Loss(\theta) L o s s ( θ ) ∇ θ = ∂ L o s s ( θ ) ∂ θ \nabla \theta = \frac{\partial Loss(\theta)}{\partial \theta} ∇ θ = ∂ θ ∂ L o s s ( θ ) θ ← θ + α ∇ θ \theta \leftarrow \theta + \alpha \nabla \theta θ ← θ + α ∇ θ θ 目标 ← θ \theta_{\text{目标}} \leftarrow \theta θ 目标 ← θ
DoubleDQN的实现
DoubleDQN
接下来,我们来实现一个DoubleDQN。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class DoubleDQNAgent (DQNAgent) : def learn (self, observation, action, reward, next_observation, done) : self.replayer.store(observation, action, reward, next_observation,done) observations, actions, rewards, next_observations, dones = self.replayer.sample(self.batch_size) next_eval_qs = self.evaluate_net.predict(next_observations) next_actions = next_eval_qs.argmax(axis=-1 ) next_qs = self.target_net.predict(next_observations) next_max_qs = next_qs[np.arange(next_qs.shape[0 ]), next_actions] us = rewards + self.gamma * next_max_qs * (1. - dones) targets = self.evaluate_net.predict(observations) targets[np.arange(us.shape[0 ]), actions] = us self.evaluate_net.fit(observations, targets, verbose=0 ) if done: self.target_net.set_weights(self.evaluate_net.get_weights())
训练
示例代码:
1 2 3 4 5 6 7 8 9 10 net_kwargs = {'hidden_sizes' : [64 , 64 ], 'learning_rate' : 0.001 } agent = DoubleDQNAgent(env, net_kwargs=net_kwargs) episodes = 500 episode_rewards = [] for episode in range(episodes): episode_reward = play_qlearning(env, agent, train=True ) episode_rewards.append(episode_reward) print('{} {}' .format(episode,episode_reward))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 0 -200.0 1 -200.0 2 -200.0 3 -200.0 4 -200.0 【部分运行结果略】 495 -144.0 496 -196.0 497 -151.0 498 -119.0 499 -94.0
测试
再来看看效果。
示例代码:
1 2 3 4 agent.epsilon = 0. episode_rewards = [play_qlearning(env, agent) for _ in range(100 )] print('平均回合奖励 = {} / {} = {}' .format(sum(episode_rewards),len(episode_rewards), np.mean(episode_rewards)))
运行结果:
1 平均回合奖励 = -12786.0 / 100 = -127.86
Deuling DQN
我们讨论的最后一种是Deuling DQN,这种算法对神经网络的结构进行了修改。
而Deuling DQNd的神经网络结构是
V ( s ) V(s) V ( s ) A ( s , a ) A(s,a) A ( s , a )
Q ( s , a ) = V ( s ) + A ( s , a ) Q(s,a) = V(s) + A(s,a)
Q ( s , a ) = V ( s ) + A ( s , a )
在实际中,我们还会对A ( s , a ) A(s,a) A ( s , a ) A ( s , a ) A(s,a) A ( s , a ) 0 0 0 V ( s ) V(s) V ( s ) Q ( s , a ) Q(s,a) Q ( s , a )