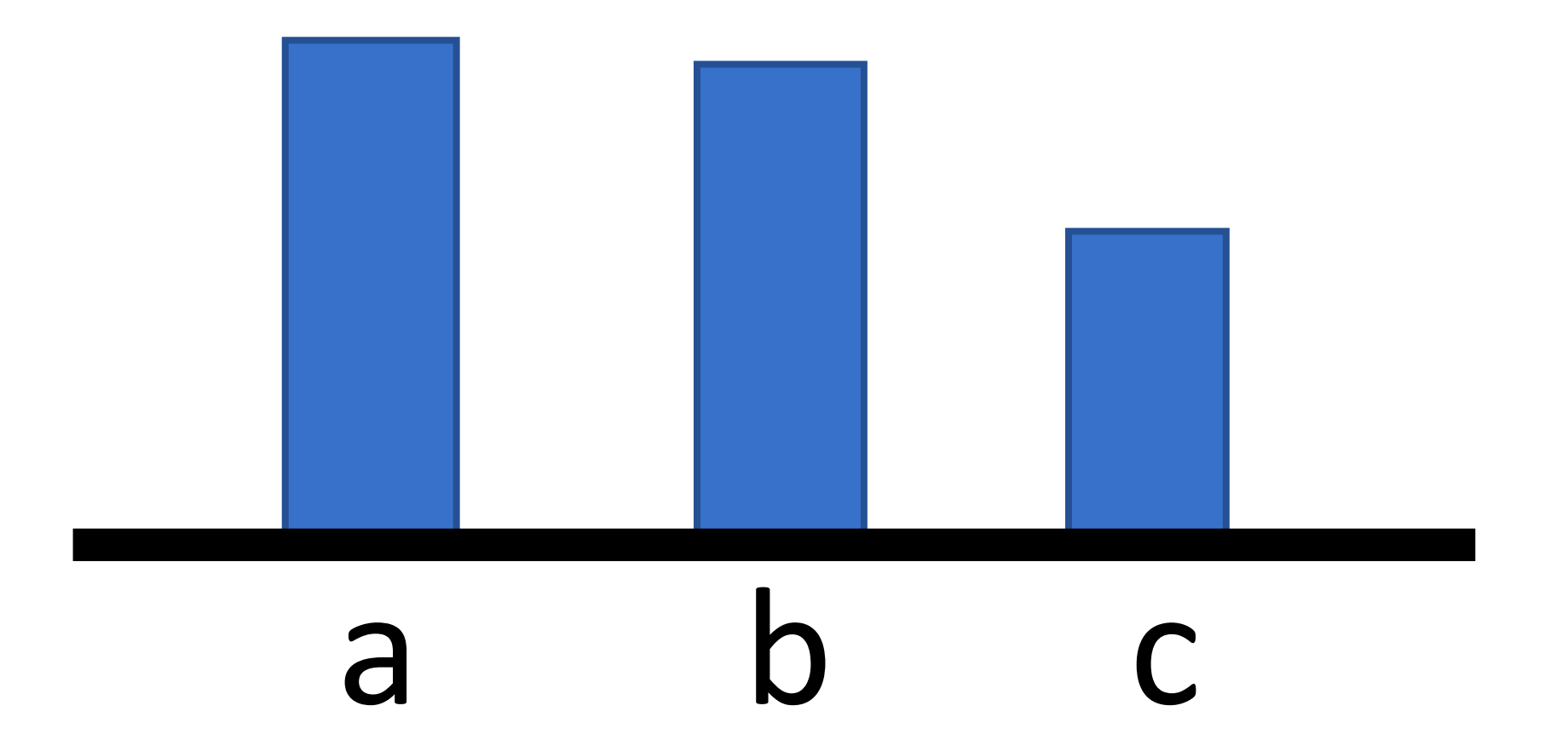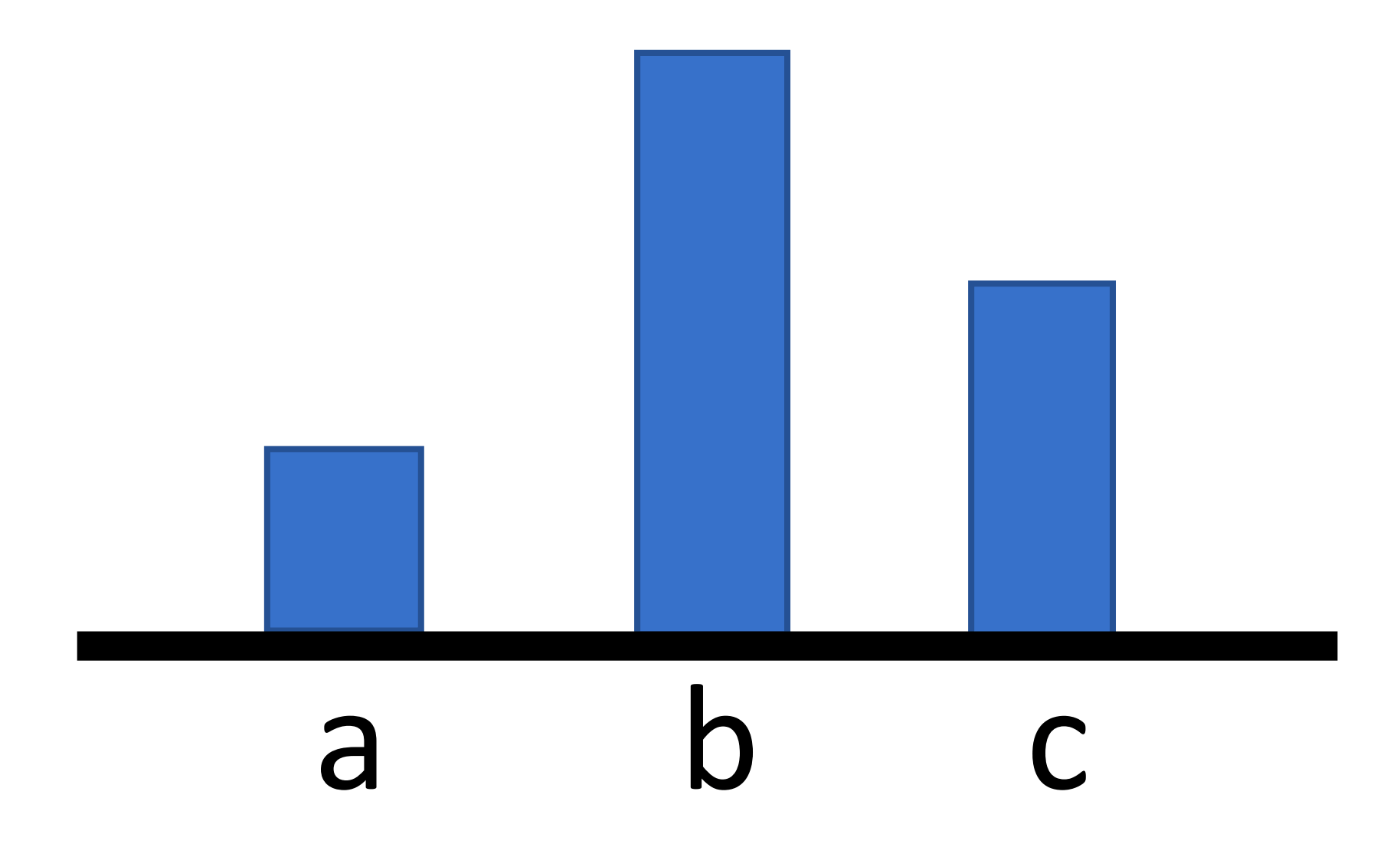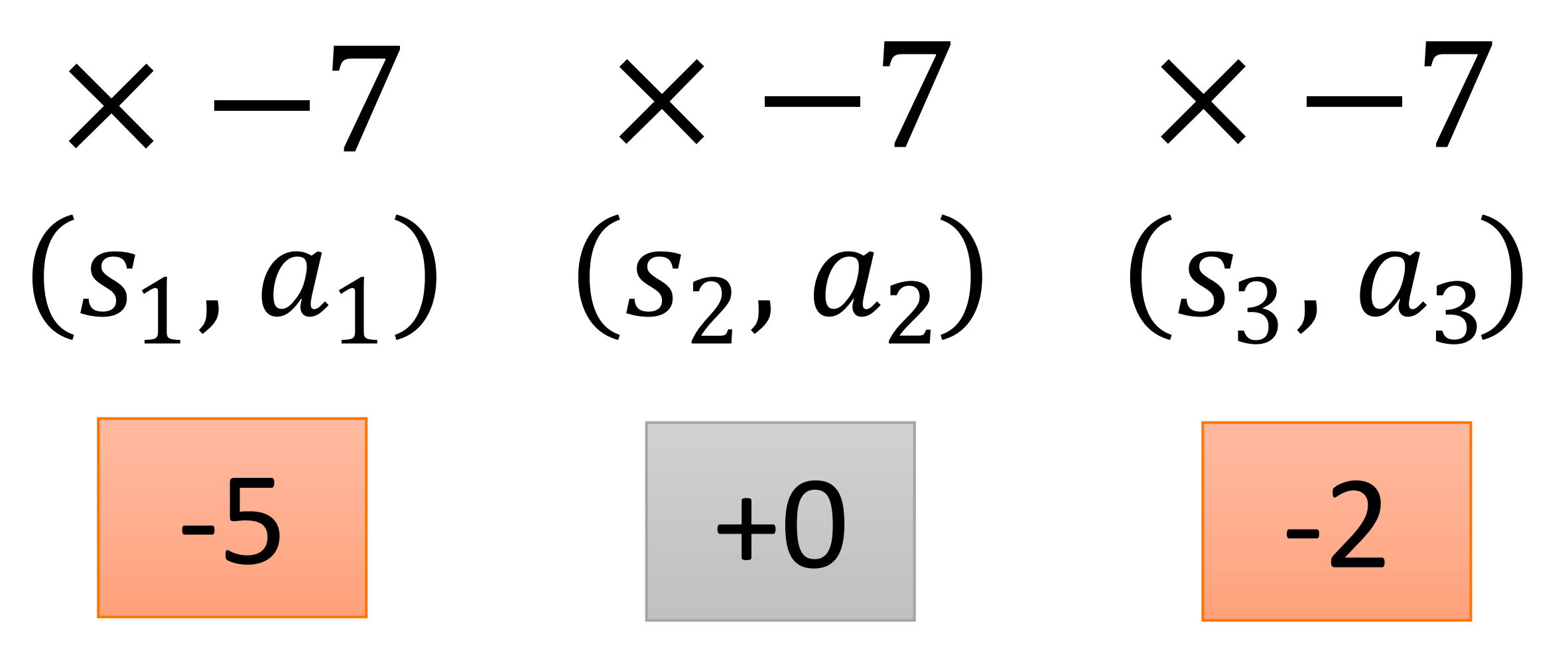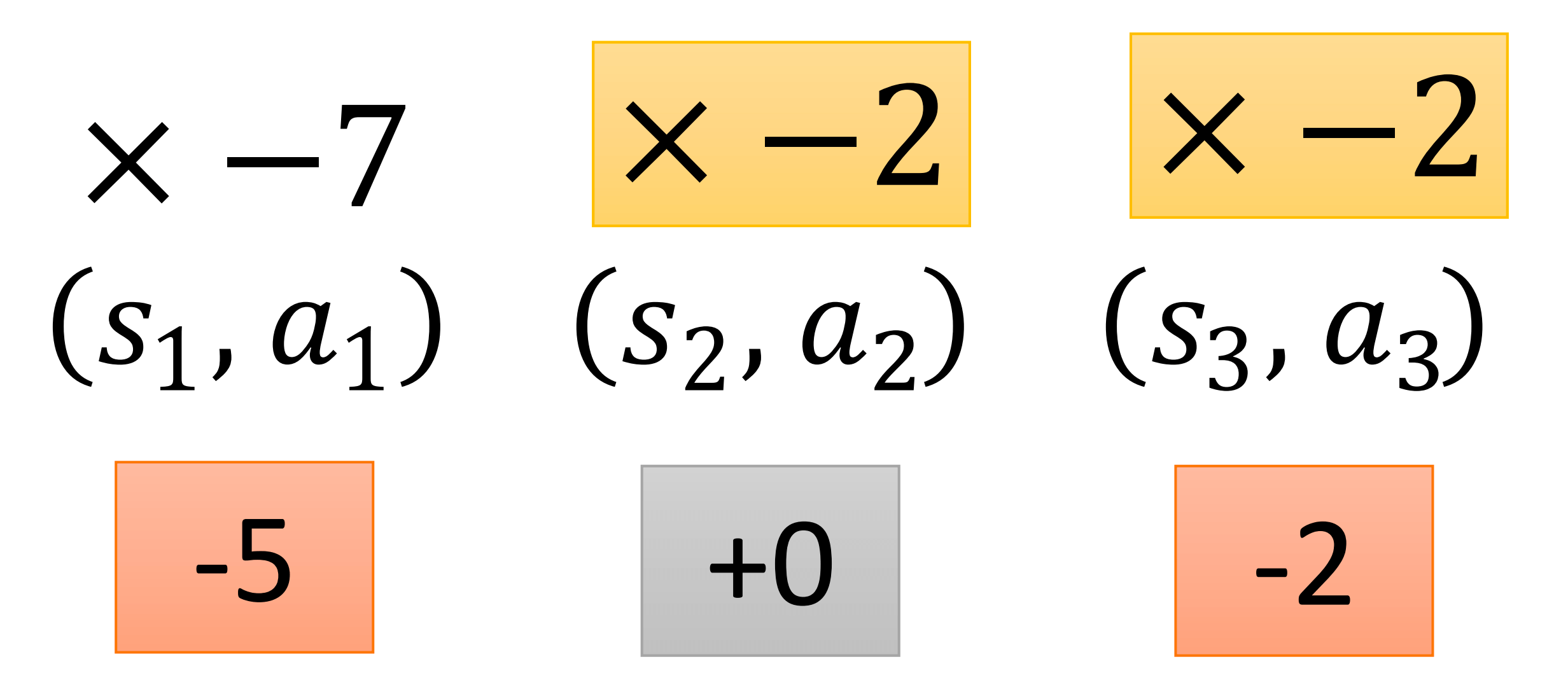随机策略简介
之前的章节,我们讨论的所有内容都是迭代最优的动作价值函数,然后我们在状态s下,选择动作价值最大的那个动作。
这一章,我们讨论一个新的方法,直接去迭代最优的策略,策略梯度方法。
直接迭代最优的策略,这个不是新方法,我们在我们这一系列笔记的第一个真正意义上的强化学习算法,《2.动态规划》中的第一种方法就是这么做的。但策略梯度是新的方法。
根据我们迭代的策略是随机策略还是确定性策略,又可以分为随机策略梯度(Stochastic Policy Gradient,SPG)和确定性策略梯度(Deterministic Policy Gradient,DPG)。
随机策略是在某个状态s下,做出某个动作a的概率。即
πθ(a∣s)=P(a∣s;θ)
而之前的所有基于价值函数的方法,得到的都是确定性策略。
相比之下,随机策略在进行博弈的时候更有优势。
比如,下围棋,如果智能体采取的是确定性策略的话,可能在若干局之后,就被高手掌握了规律。但是如果采取的随机策略的话,就不那么容易被掌握了。
(有些观点认为,在环境不是完全可观测的情况下,随机策略相比确定性策略更有优势,说实话,这个我不是很理解,金融市场就是一个不可完全观测的环境,但是我不认为在金融市场,随机策略一定会优于确定性策略。)
这一章,除非有特别说明,否则,我们所指的策略都是随机策略。
随机策略梯度同样有在线和离线两种方法,我们从在线开始。
在线策略方法
回报
现在,让我们来看看如何迭代最优策略。
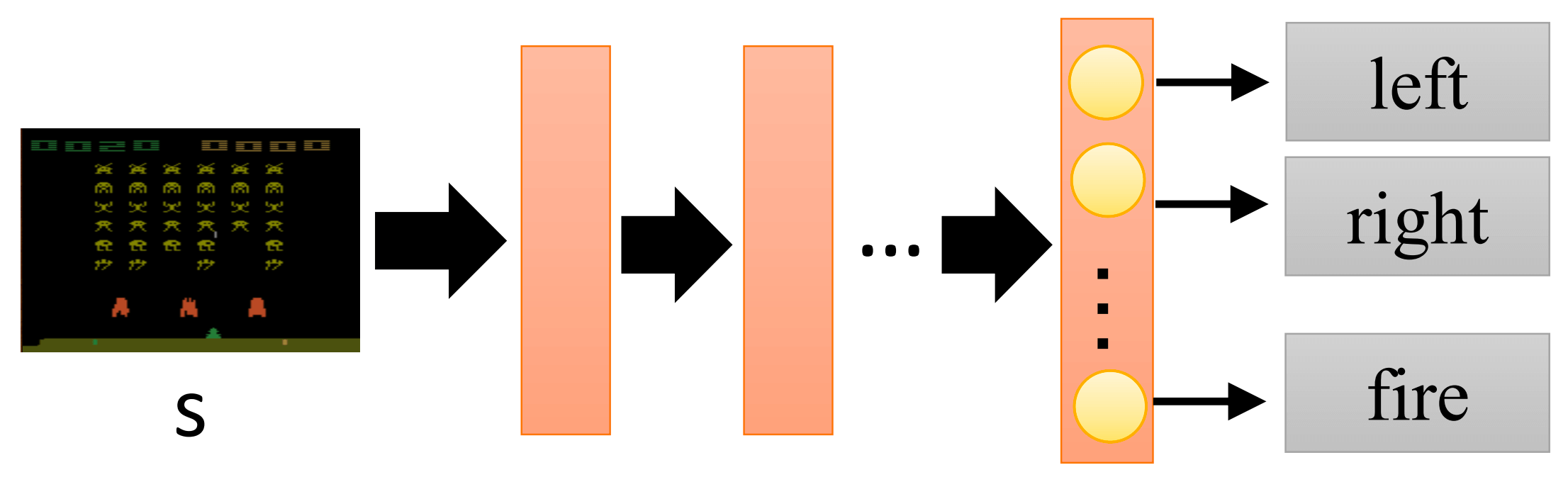
既然是迭代呢,那么我们就随便从一个策略出发。比如,现在有一个策略πθ,其中θ是这个策略网络的参数。(我们仿照上一章的DQN,用一个神经网络来作为我们的策略函数。)
如图

然后,我们用这个策略和环境交互。在状态s1,做出动作a1,环境给出奖励r1,状态转移至s2,做出动作a2,···,直到,在状态sT,做出动作aT,环境给出奖励rT。这就是我们第一章讨论的轨迹。
在策略πθ下,这个轨迹τ的回报是
Gθ=t=1∑Trt
但是,Gθ(τ)是不足以评估我们的策略πθ的,因为Gθ(τ)是一个随机变量,这个我们在第一章也讨论过,因为动作是随机的,状态转移也是随机的。
只有Gθ(τ)这个随机变量的期望Gˉθ才可以评估我们的策略πθ。
那么,Gˉθ是多少呢?让我们看看。
轨迹τ是{s1,a1,r1,s2,a2,r2,⋯,sT,aT,rT},这个轨迹发生的概率是
P(τ;θ)=P(s1)P(a1∣s1;θ)P(r1,s2∣s1,a1)P(a2∣s2;θ)P(r2,s3∣s2,a2)⋯P(aT∣sT;θ)P(rT,sT+1∣sT,aT)=P(s1)Πt=1TP(at∣st;θ)P(rt,st+1∣st,at)
- s1是初始化的时候,环境直接给定的。
- 严格意义上,当t=T时,没有状态sT+1。但这个不影响我们后续的讨论,因为我们更关心的是奖励r。
知道了轨迹τ的回报,知道了轨迹τ发生的概率,那么期望Gˉθ就非常简单了。
Gˉθ=τ∈所有的τ∑Gθ(τ)P(τ;θ)
根据我们之前讨论的蒙特卡洛,我们知道还有这么一个式子成立。
Gˉθ≈N1n=1∑NGθ(τn)
这个式子暂且先放这里,我们很快就会用到。
梯度和梯度上升
所以,接下来我们的目标就很明确了,我们要寻找一个θ⋆,使得Gˉθ的值最大。
即
θ⋆=θargmaxGˉθ
在之前的《经典机器学习及其Python实现》和《深度学习初步及其Python实现》,我们也有过类似的操作,我们要寻找一组参数,使损失函数的值最小,当时,采用的是梯度下降法。而在《集成学习概览及其Python实现》中,我们有大量用到"梯度上升"。
这里我们的目标使回报的值最大,采用的方法是梯度上升。
初始化θθ←θ+ηθGˉθθ←θ+ηθGˉθ⋯
其中:
θ={ω1,ω2,⋯,b1,⋯}
- θGˉθ是梯度
θGˉθ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂ω1∂Gˉθ∂ω2∂Gˉθ⋮∂b1∂Gˉθ⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
- η是学习率。(在强化学习中,绝大部分资料,梯度下降的学习率用α表示,梯度上升的学习率用η或者β表示)
所以,接下来我们的目标就很明确了,我们需要求θGˉθ。
在上文我们讨论过,Gˉθ=∑τ∈所有的τGθP(τ;θ),所以
∂θ∂Gˉθ=τ∈所有的τ∑G(τ)θP(τ;θ)
然后我们来做一个"迷"操作,乘以P(τ;θ)P(τ;θ),得到
∂θ∂Gˉθ=τ∈所有的τ∑G(τ)P(τ;θ)P(τ;θ)1∂θ∂P(τ;θ)
根据我们的导数公式和复合函数求导法则,我们知道下面这个等式是成立的。
dxdlog(f(x))=f(x)1dxdf(x)
看看f(x)1dxdf(x),再看看P(τ;θ)1∂θ∂P(τ;θ),立即推
∂θ∂Gˉθ=τ∈所有的τ∑G(τ)P(τ;θ)∂θ∂logP(τ;θ)
在上文,我们还留了一个式子。
Gˉθ≈N1n=1∑NGθ(τn)
我们说很快会用到,就在这里。
看看这个式子,再看看上式的∑τ∈所有的τG(τ)P(τ;θ)这一部分。
立即推
θ∂Gˉθ≈N1n=1∑NG(τn)∂θ∂logP(τn;θ)
所以,接下来我们的目标就很明确了,求∂θ∂logP(τn;θ)。
在上文我们讨论过
P(τ;θ)=P(s1)P(a1∣s1;θ)P(r1,s2∣s1,a1)P(a2∣s2;θ)P(r2,s3∣s2,a2)⋯P(aT∣sT;θ)P(rT,sT+1∣sT,aT)=P(s1)Πt=1TP(at∣st;θ)P(rt,st+1∣st,at)
所以
logP(τ;θ)=logP(s1)+t=1∑TlogP(at∣st;θ)+t=1∑TlogP(rt,st+1∣st,at)
所以
∂θ∂logP(τ;θ)=t=1∑T∂θ∂logP(at∣st;θ)
- 只要是不基于θ的,即θ不是自变量的,都看成常数。
综上所述
∂θGˉθ≈N1n=1∑NG(τn)∂θ∂logP(τn;θ)≈N1n=1∑NG(τn)t=1∑Tn∂θ∂logP(atn∣stn;θ)≈N1n=1∑Nt=1∑TnG(τn)∂θ∂logP(atn∣stn;θ)
最后一步,梯度上升
θ←θ+η∂θ∂Gˉθ
梯度的业务含义
在上文,我们通过数学推导,得到了梯度。
∂θ∂Gˉθ≈N1n=1∑Nt=1∑TnG(τn)∂θ∂logP(atn∣stn;θ)
现在,让我们来看看,这个梯度,到底在做什么,到底有什么业务含义。
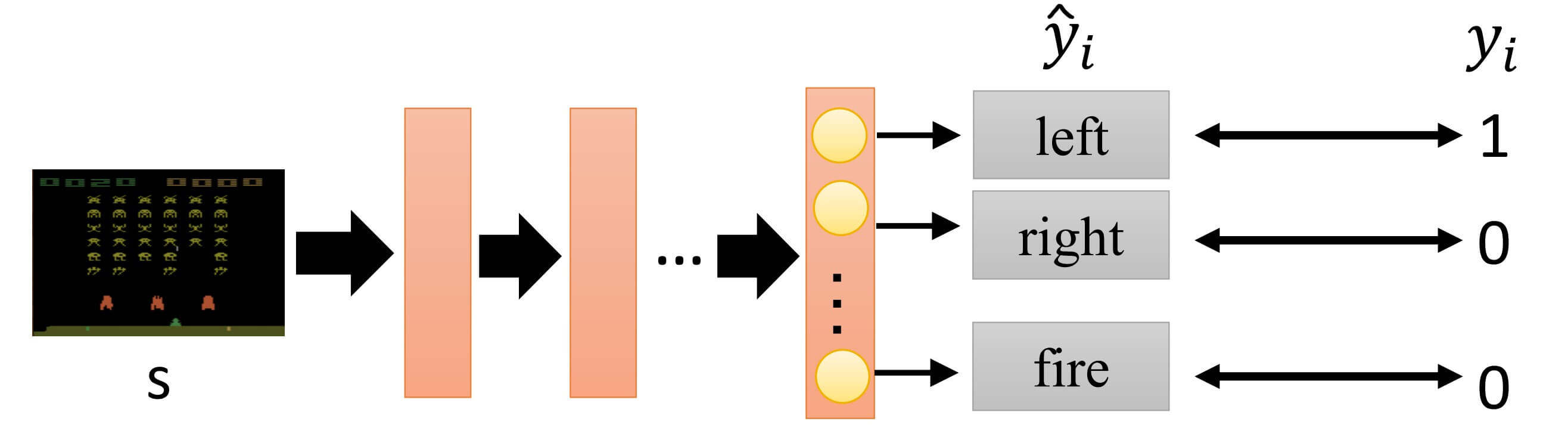
我们从一个很经典的分类问题开始,但是与以往不同的是,我们的类别是"应该向左"、“应该向右"和"应该开火”。
- yi^是输出的三种类别的概率,是模型的估计预测
- yi是真实值,也就是Label
在《深度学习初步及其Python实现:2.神经网络基础》我们讨论过,这种的分类问题,其损失函数是交叉熵损失。
H(p∣∣q)=−i∑pilog2qi
在这里,损失函数就是
−i=1∑3yilogy^i
- 需要注意的是,损失函数是−∑i=13yilogy^i,而不是−∑i=13y^ilogyi,因为交叉熵的不对称性,具体可以参考《深度学习初步及其Python实现:2.神经网络基础》。
当时,我们的目标是要最小化这个损失函数的值。
现在,我们把负号去掉,这时候我们的目标就是最大化∑i=13yilogy^i。
又因为,只有第一个yi的值为1。
所以,其实我们的目标也就最大化logy^1,即最大化logP(left∣s),即
MaxmizelogP(left∣s)
那么,怎么更新θ的值呢?
既然负号去掉了,那就梯度上升。
θ←θ+η∂θ∂logP(left∣s)
这个式子,∂θlogP(left∣s) 这一部分,和我们的上文中的∂θ∂logP(atn∣stn;θ)太像了。
但是,不一样!
在∂θ∂logP(left∣s)中,left是什么?是真实值。
在∂θ∂logP(atn∣stn;θ)中呢,atn不是真实值,是我们的那个不怎么样的策略,输出的动作。
那么,在分类问题中,我们梯度上升(或梯度下降,具体看目标函数的形式)是为了逼近真实值。现在呢?我们梯度上升,是为了去逼近我们之前那个不怎么样的策略输出的动作?
到底怎么回事?
注意看
∂θ∂Gˉθ≈N1n=1∑Nt=1∑TnG(τn)∂θ∂logP(atn∣stn;θ)
有一个G(τn),如果G(τn)大于0,就加大执行动作atn的概率。如果G(τn)小于0,就减小执行动作atn的概率。
也就是说,虽然我们得到的是一个不怎么样的策略,但是我们学习好的,同时规避不好。
要么说是强化学习呢,这就是强化啊!
添加基线
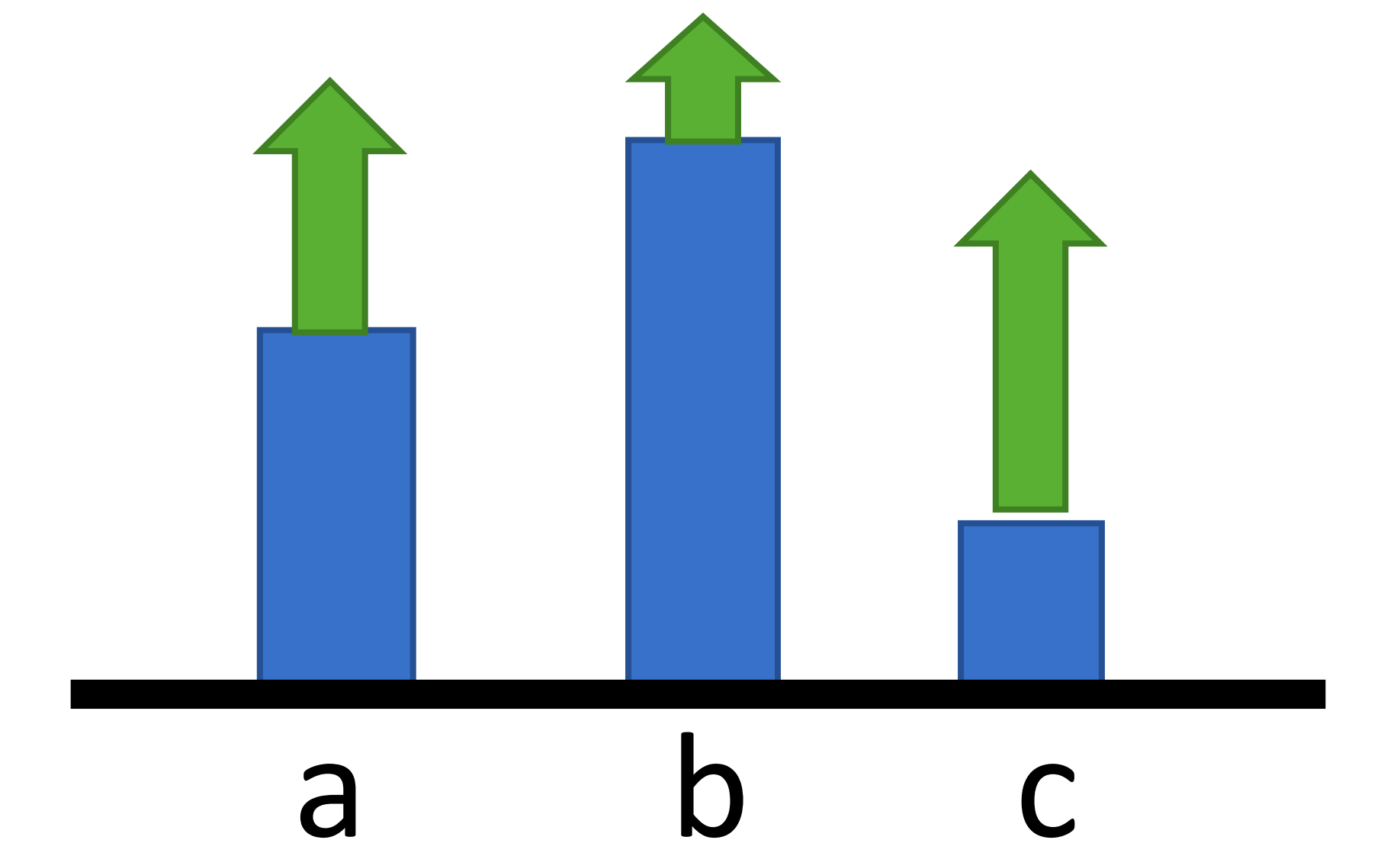
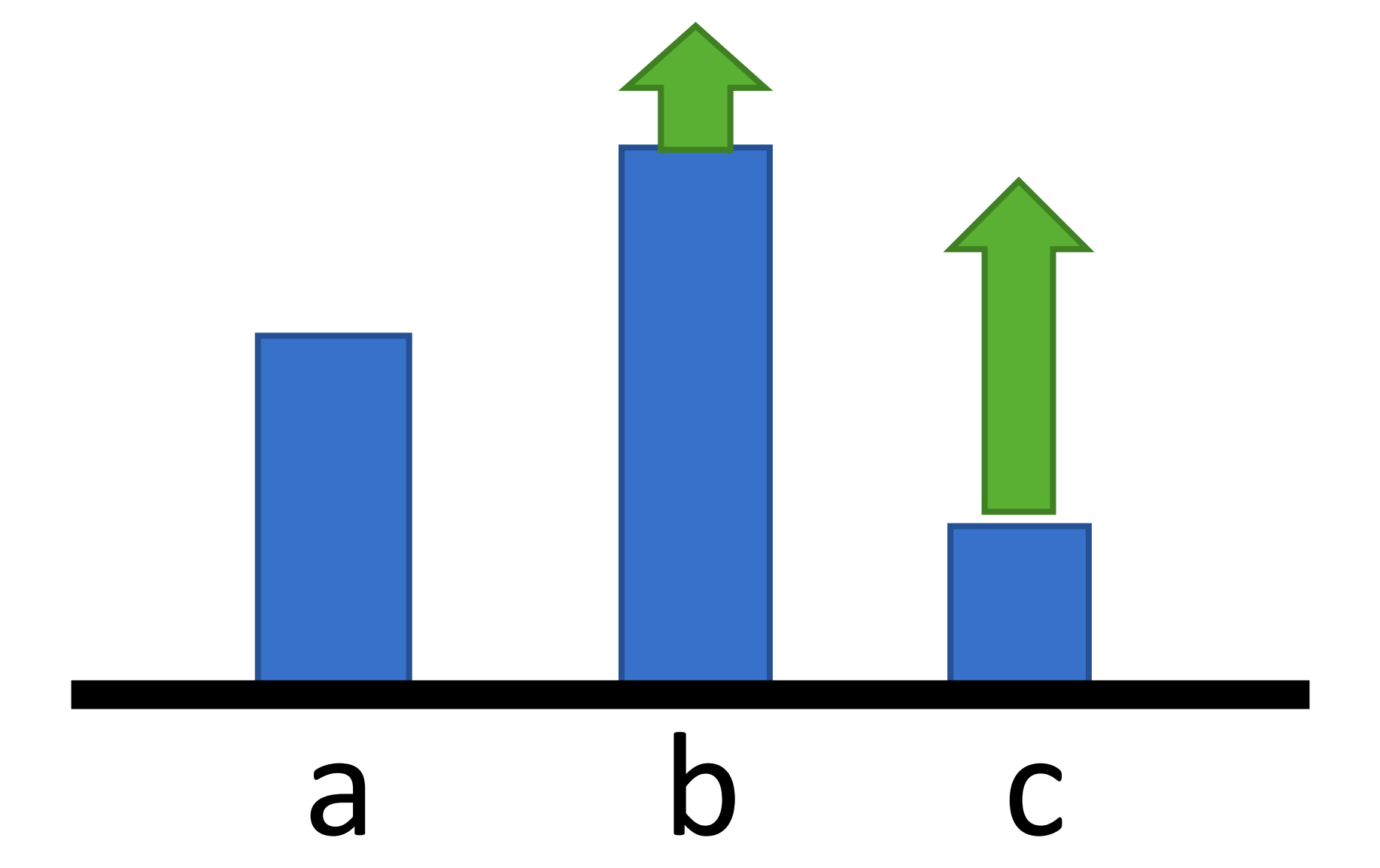
现在,我们来看一个问题,如果对于所有的τn,G(τn)都大于等于0,会怎么样?
比如,电玩城的投篮机,这个游戏只有得分或者不得分,没有丢分。G(τn)会永远大于等于0。
那么,会有什么问题吗?
比如说
有a、b、c三个动作,方框表示概率大小,箭头的长度表示回报。虽然回报都是大于0的,但是a和c的回报明显大于b的回报。所以经过迭代后,a、b、c的新的概率如图。
没问题啊,即使G(τn)永远大于等于0,看起来也没问题啊。
是没问题。
但是,别忘了一件事情,抽样。
举个例子,如果没有抽中a。
然后迭代之后,我们会得到
即,没有被抽中的动作,其概率会下降。
那么,怎么办?我们添加一个baseline(基线),这样比基线小的回报,即使回报大于0,其动作的概率还是会下降。
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(G(τn)−b)∂θ∂logP(atn∣stn;θ)
- 也有资料称b为bias(偏置),这么解释的话,就忽略了其业务作用,但是或许在数学上更通顺。
特别注意,b不一定就是常数,可以是一个函数,可以是一个神经网络。但一定是只和状态有关而和动作无关的量。
我们很快就会见到b不是一个常数。
Assign Suitable Credit
再来看看上面的式子
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(G(τn)−b)∂θ∂logP(atn∣stn;θ)
有这么一个部分
(G(τn)−b)∂θ∂logP(atn∣stn;θ)
上文,我们讨论了,虽然我们得到的是一个不怎么样的策略,但是我们学习好的,同时规避不好。我们的好坏是根据什么定义的?是G(τn),轨迹的回报。
不,我们还在轨迹回报的基础上加了基线。
G(τn)−b
在回报大的轨迹中,不一定所有的动作都是最佳动作。如果这个轨迹的回报非常大,那么其中滥竽充数,鱼目混珠的一些不好的动作也可能会不断的被加强。同理,如果轨迹的回报是较小,甚至是负数。那么,其中一些较好的动作,可能会被规避。
那么,怎么办?
那,要么这样好了,我们不用回报了,用每个动作的奖励。
把每一步都做当前的最佳决策,这是贪心算法。
贪心本身是没有问题的,不是说贪心算法就一定无效。几个经典的图算法"Kruskal"、"Prim"和"Dijkstra"都是贪心算法。(关于这部分,可以参考《算法入门经典(Java与Python描述):10.图》)
而且,我们之前的章节的模型,不都是贪心吗?我们每次选择价值最大的动作,即回报最大的那个动作。
之前贪心贪的是什么?是回报最大。现在呢?现在贪心奖励最大?
那不行,在《1.基础概念》我们就讨论过,强化学习的目标是最大化回报,而不是最大化当前的奖励。当时我们还举了一个例子,说我们应该着眼于解救公主,而不是眼前的这一两枚金币。
我们要追求整体回报最大,每个动作都是当前奖励最大的动作,不一定能保证整体回报最大。同理,可能在某个状态下,我们做了一个奖励不大,甚至奖励是负数的动作。但,为的是整体最优。
题外话
这就可以理解,为什么滴滴不把最近的车派给我们,因为滴滴的追求是整体最优。为了做到整体最优,可能会给我们派了一辆较远的车。
当然,滴滴的系统很复杂,其整体最优可能不是简单意义上的整体等车时间最短,还会考虑很多因素。
好了,题外话就聊到这里。
如果拳头收回去,是为了更好的出拳的话。那么我们似乎应该把下一步出拳的奖励也算给这一步把拳头收回去,最多打点折扣的算进去。
我们来看一个具体的例子。
在s1,做出动作a1,得到奖励−5;在s2,做出动作a2,得到奖励+0;在s3,做出动作a3,得到奖励−2。所以,回报是−7。然后我们对每一步都乘以−7。之前就是这样做的,但这样,是不是对(s2,a2)太不公平了?
冤有头,债有主
把(s3,a3)的−2算给(s2,a2)还可以接受,或许是在s2没做好,导致在s3遭受了−2。
但是把(s1,a1)的−5也算给(s2,a2)确实不应该。
所以,我们改成下图的形式。
综上所述,我们修改∂θ∂Gˉθ
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnrt′n−b)∂θ∂logP(atn∣stn;θ)
如果再乘上折扣因子γ,则是
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′n−b)∂θ∂logP(atn∣stn;θ)
离线策略方法
接下来,我们讨论离线策略方法,也就是近端策略优化(Proximal Policy Optimization)。
重要性采样
《4.时序差分》这一章,我们第一次真正意义上讨论离线策略。当时我们提到过,离线策略的理论基础就是重要性采样,很多资料先讨论"重要性采样",当时我们不讨论,是因为我认为,我们反过来,先弄明白什么是离线策略,再去讨论重要性采样,或许更容易理解重要性采样。
现在,我想,是时候讨论重要性采样了(Importance Sampling)。
我们从一个问题出发,假如随机变量x服从分布p(x),求Ex∼p[f(x)]。
Ex∼p[f(x)]=∫f(x)p(x)dx
一个"迷"操作,乘以q(x)q(x),得到
Ex∼p[f(x)]=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
通过上述,我们知道Ex∼p[f(x)]=Ex∼q[f(x)q(x)p(x)],那么现在提一个问题。
x∼p的f(x)和x∼q的f(x)q(x)p(x)会是一样的吗?
这个还真不一样。
我们分别计算一下Varx∼p[f(x)]和Varx∼q[f(x)q(x)p(x)]就可以知道。
方差计算公式为
Var(X)=E(X2)−E(X)2
计算过程和结果略,总之,就是不一样。
所以呢,p(x)和q(x),不能相差太多,这个我们之前讨论过,有一个东西可以衡量之间的距离,KL散度。
近端策略优化
在上文我们讨论了∂θ∂Gˉθ。
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′n−b)∂θ∂logP(atn∣stn;θ)
为了表述简单,我们把∑t′=tTnγt′−trt′n−b这部分写成Aθ(st,at)。
即
∂θ∂Gˉθ=E(st,at)∼πθ[Aθ(st,at)∂θ∂logP(at∣st;θ)]
然后,我们利用刚刚讨论的重要性采样,则有
∂θ∂Gˉθ=E(st,at)∼πθ′[Pθ′(st,at)Pθ(st,at)Aθ′(st,at)∂θ∂logP(at∣st;θ)]
Pθ(st,at)可以写成什么呢?
Pθ(st,at)=Pθ(at∣st)Pθ(st)
所以,上式又可以写成
∂θ∂Gˉθ=E(st,at)∼πθ′[Pθ′(at∣st)Pθ′(st)Pθ(at∣st)Pθ(st)Aθ′(st,at)∂θ∂logP(at∣st;θ)]
接下来,我们认为Pθ(st)和Pθ′(st)可以约去,总之,就是这么认为。
则有
∂θ∂Gˉθ=E(st,at)∼πθ[Pθ′(at∣st)Pθ(at∣st)Aθ′(st,at)∂θ∂logP(at∣st;θ)]
但,注意了,刚刚我们弄的一直是梯度,目标函数是什么?目标函数Jθ′是
Jθ′(θ)=E(st,at)∼πθ′[Pθ′(at∣st)Pθ(at∣st)Aθ′(st,at)]
- θ是需要去优化的参数
- θ′是环境互动的参数
那么,什么是近端策略优化(Proximal Policy Optimization)呢?
再加上KL散度。(至于为什么加KL散度,我们在讨论重要性采样的时候讨论过了。)
Jθ′PPO(θ)=Jθ′(θ)−βKL(θ,θ′)
以控制θ和θ′不能相差太远。
还有一种方法是信任域策略优化(Trust Region Policy Optimization,TRPO),这种方法是在额外添加对KL(θ,θ′)的限制。
即
Jθ′TRPO(θ)=Jθ′(θ)同时要求:KL(θ,θ′)<δ
这种方法实现起来极为不便,所以更多的还是用的近端策略优化。
剩下的内容,就和之前的在线策略方法一样了。我们用Jθ′PPO做梯度下降乘上学习率,去更新θ。
这就是离线策略方法。
AC
在上文,我们讨论了随机策略梯度方法。
在线策略的梯度是
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′n−b)∂θ∂logP(atn∣stn;θ)
离线策略的目标函数是
Jθ′PPO(θ)Jθ′(θ)Aθ′(st,at)=Jθ′(θ)−βKL(θ,θ′)=E(st,at)∼πθ′[Pθ′(at∣st)Pθ(at∣st)Aθ′(st,at)]=t′=t∑Tnγt′−trt′n−b
无论是在线策略还是离线策略,都有这么一个东西,∑t′=tTnγt′−trt′n,这个东西有一个问题,非常不稳定。
当然不稳定,这个我们讨论过很多次了,动作是随机的,状态转移是随机的,自然这个东西也是随机的,是不稳定的。
所以呢,我们会抽样很多次。如果抽样足够多次的话,那没问题,但是那就太慢了。
那么,有没有办法快一点呢?
我们再来仔细看这个式子
t′=t∑Tnγt′−trt′n−b
∑t′=tTnγt′−trt′n是什么?是回报,我们记作Gtn。
E[Gtn]是什么?就是我们的动作价值!Qπθ(stn,atn)。
那么,这时候再把b用状态价值Vπθ(stn)表示是绝佳的。这就是我们上文讨论的b不一定是常数。
所以,我们把∑t′=tTnγt′−trt′n−b替换成Qπθ(stn,atn)−Vπθ(stn)。
这就是大名鼎鼎的Actor-Critic。
我们不再用实际观测的回报近似Qπ,而用神经网络来近似Qπ,这是Actorl-Critic。
比如,对于在线方法
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(Qπθ(stn,atn)−Vπθ(stn))∂θ∂logP(atn∣stn;θ)
那么,现在问,谁是Actor,谁是Critic?
Qπθ(stn,atn)是Actor?Vπθ(stn)是Critic?不,错了!
这是策略梯度的估计!
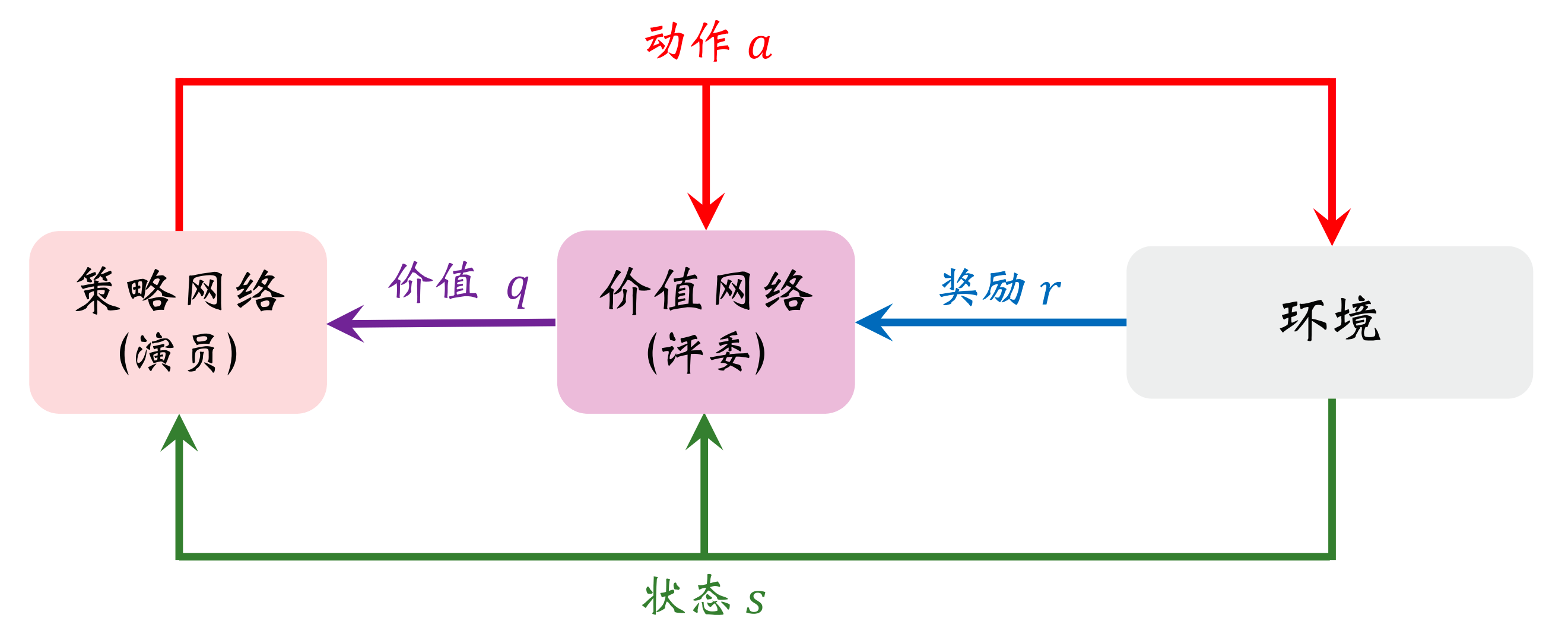
我们来看这张图。
解释一下,在上图中,我们策略网络的输入是状态s,输出是一个向量,向量中的每个元素表示一个动作的概率,然后会抽样出其中一个动作a并执行,并得到奖励r。价值网络的输入是状态s,和基于策略网络的输入而抽样得到的动作a。把r给价值网络呢,是因为价值网络也需要训练。
接下来,我们讨论具体训练过程。
训练价值网络
Actor-Critic方法中用一个神经网络近似动作价值函数Qπ(s,a),这个神经网络被称为"价值网络",我们记作Q(s,a;ω)。
用神经网络来近似价值函数?这个我们似乎见过?对,就是上一章的DQN。
但是两者的意义不同,训练算法也不同。
- 价值网络是对动作价值函数Qπ(s,a)的近似。而DQN则是对最优动作价值函数Q⋆(s,a)的近似。
- 价值网络的训练使用的是SARSA算法,它属于在线策略,不能用经验回放。对DQN的训练使用的是Q-Learning算法,它属于离线策略,可以用经验回放。
SARSA算法,我们已经讨论过了。接下来,我们来看看SARSA在训练价值网络中的具体应用。
在t时刻,价值网络输出q^t=Q(st,at;ω),是对动作价值函数Qπ(st,at)的估计。
在t+1时刻,实际观测到rt,st+1,at+1,于是可以计算TD目标y^t=rt+γQ(st+1,at+1;ω),它也是对动作价值函数Qπ(st,at)的估计。由于y^t部分基于实际观测到的奖励rt,我们认为y^t比q^t更接近事实真相。所以把y^t固定住,鼓励Q(st,at;ω)去接近y^t。
即,定义损失函数
L(ω)=21[Q(st,at;ω)−y^t]2
计算梯度
∂ω∂L(ω)=(q^t−y^t)∂ω∂Q(st,at;ω)
做一轮梯度下降
ω←ω−β∂ω∂L(ω)
训练策略网络
Actor利用当前状态s,自己的动作a,以及评委的打分Qπθ(stn,atn)−Vπθ(stn),来计算近似策略梯度∂θ∂Gˉθ,然后更新自己的参数θ。
即
θ←θ+η∂θ∂Gˉθ
A2C
A2C的梯度
但是呢,这个还有一点小问题。我们有两个网络,一个Qπθ(stn,atn)。一个Vπθ(stn)。
两个网络,也就意味着两倍的风险,两个中有一个没训练好,都可能结束。
那么,有没有办法只训练一个网络呢?
比如,我们只训练状态价值的,然后我们用状态价值来表示动作价值。
来,找到这篇文章《3.蒙特卡洛》,开篇我们就讨论了无模型和有模型的主要区别,无模型,我们只能用动作价值表示状态价值。
但是,我们这次说的是这个意思。
Qπ(stn,atn)=E[rtn+Vπ(st+1n)]
那没问题,要用蒙特卡洛抽样,求平均,那当然OK。
所以,我们把上文∂θ∂Gˉθ的表达式中的Qπθ(stn,atn)−Vπθ(stn)替换成rtn+Vπθ(st+1n)−Vπθ(stn)
比如,对于在线方法的策略梯度
∂θ∂Gˉθ≈N1n=1∑Nt=1∑Tn(rtn+Vπθ(st+1n)−Vπθ(stn))∂θ∂logP(atn∣stn;θ)
其中rtn+Vπθ(st+1n)−Vπθ(stn)又被称为优势函数(Advantage Function)。
这就是A2C,2的含义是两个A,Advantage Actor-Critic。
除此之外,和AC方法并无本质区别。
A2C的过程
A2C算法
输入:
环境
输出:
最优策略参数θ
参数:
θ的学习率η
ω的学习率β
初始化:
初始化θ为任意值(随机初始化)
初始化ω为任意值(随机初始化)
对每一条轨迹执行以下操作:
初始化累积折扣因子,I←1
初始化状态s0
t=1,2,⋯,T,轨迹内的每一个时间步执行以下操作:
在状态st下,根据π(⋅∣s;θ),执行动作at
环境给出奖励r,状态转移至st+1
估计回报,g←r+γV(st+1;ω)
策略改进,更新θ,θ←θ+ηI[g−V(s;ω)]∂θ∂lnπ(a∣s;θ)
更新价值,更新ω,ω←ω+β[g−V(s;ω)]∂ω∂V(s;ω)
更新累积折扣因子I←γI
A2C的实现
我们以双节倒立摆问题为例。
该例子来自《强化学习:原理与Python实现(肖智清著)》这本书的第八章。
双节倒立摆问题描述
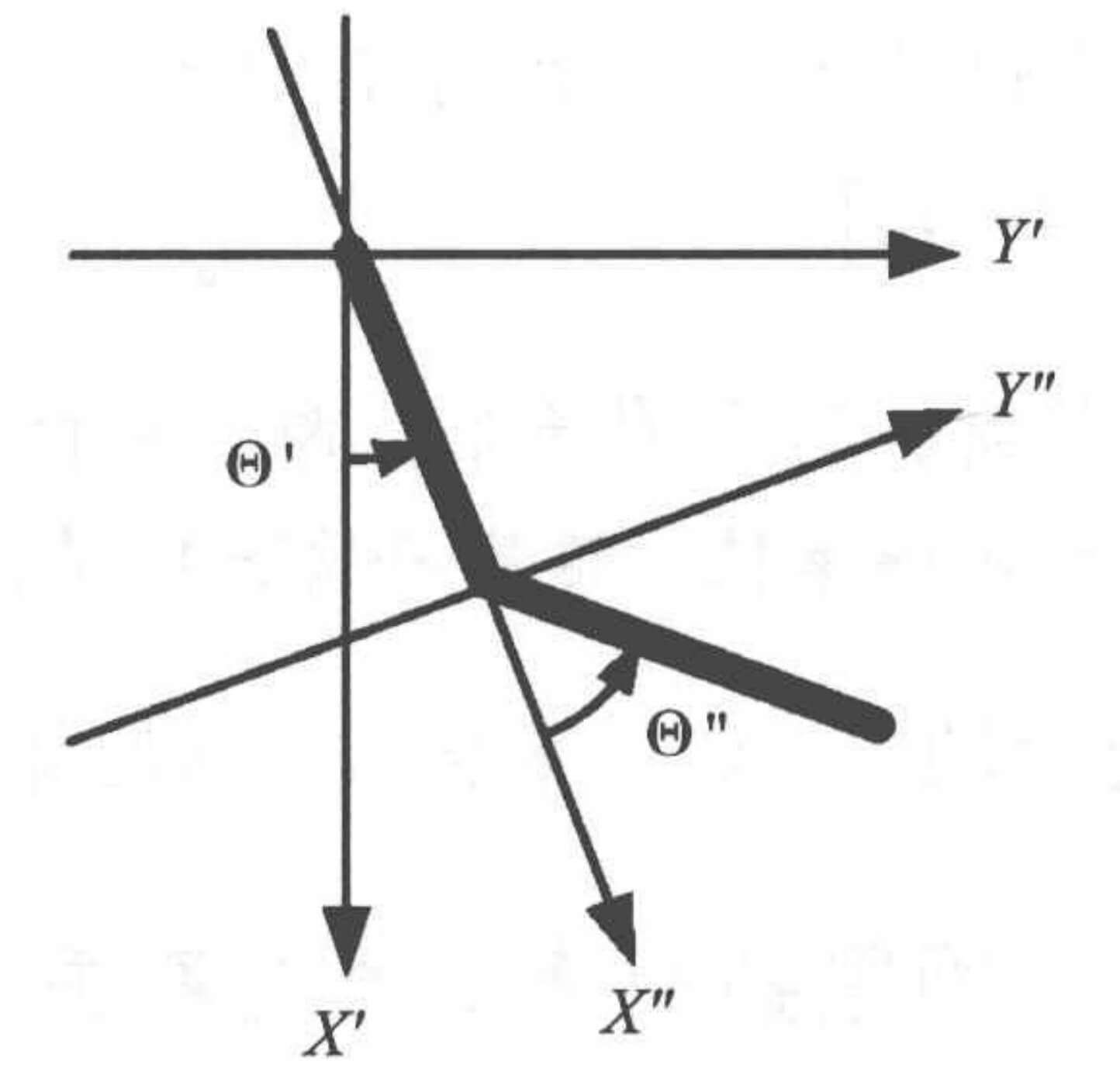
有两根在二维垂直面上活动的杆子首尾相接,一端固定在原点,另一端在二维垂直面上活动。基于原点可以在二维垂直面上建立一个绝对坐标系X′Y′,X′轴是垂直向下的,Y′轴是水平向右的;基于连接在原点的杆的位置可以建立另外一个相对的坐标系X′′Y′′,X′′轴向外,Y′′轴与X′′轴垂直。在任一时刻t(t=0,1,2,⋯),可以观测到棍子连接处在绝对坐标系的坐标(Xt′,Yt′)=(cosΘt′,sinΘt′)和活动端在相对坐标系上的坐标(Xt′′,Yt′′)=(cosΘt′′,sinΘt′′),还有当前的角速度Θ^t′和Θ^t′′。可以在两个杆子的连接处施加动作,动作取自动作空间A={0,1,2}。每过一步,惩罚奖励值−1。活动端在绝对坐标系中的X′坐标小于−1时,或回合达到500步,回合结束。我们希望回合步数尽量少。
与我们上一章的"小车上山问题"一样,这个环境其实也有其数学表示式的。但是我们不讨论,反之我们认为环境是未知的。
环境描述
示例代码:
1
2
3
4
5
6
7
8
| import numpy as np
np.random.seed(0)
import gym
env = gym.make('Acrobot-v1')
env.seed(0)
print('状态空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
|
运行结果:
1
2
| 状态空间 = Box(-28.274333953857422, 28.274333953857422, (6,), float32)
动作空间 = Discrete(3)
|
A2C的代码
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
import tensorflow as tf
tf.random.set_seed(0)
from tensorflow import keras
class AdvantageActorCriticAgent():
def __init__(self, env, actor_kwargs, critic_kwargs, gamma=0.99):
self.action_n = env.action_space.n
self.gamma = gamma
self.discount = 1.
self.actor_net = self.build_network(output_size=self.action_n,output_activation=tf.nn.softmax,loss=tf.losses.categorical_crossentropy,**actor_kwargs)
self.critic_net = self.build_network(output_size=1,**critic_kwargs)
def build_network(self, hidden_sizes, output_size, input_size=None,activation=tf.nn.relu, output_activation=None,loss=tf.losses.mse, learning_rate=0.01):
model = keras.Sequential()
for idx, hidden_size in enumerate(hidden_sizes):
kwargs = {}
if idx == 0 and input_size is not None:
kwargs['input_shape'] = (input_size,)
model.add(keras.layers.Dense(units=hidden_size,activation=activation, **kwargs))
model.add(keras.layers.Dense(units=output_size,activation=output_activation))
optimizer = tf.optimizers.Adam(learning_rate)
model.compile(optimizer=optimizer, loss=loss)
return model
def decide(self, observation):
probs = self.actor_net.predict(observation[np.newaxis])[0]
action = np.random.choice(self.action_n, p=probs)
return action
def learn(self, observation, action, reward, next_observation, done):
x = observation[np.newaxis]
u = reward + (1. - done) * self.gamma * self.critic_net.predict(next_observation[np.newaxis])
td_error = u - self.critic_net.predict(x)
x_tensor = tf.convert_to_tensor(observation[np.newaxis],dtype=tf.float32)
with tf.GradientTape() as tape:
pi_tensor = self.actor_net(x_tensor)[0, action]
logpi_tensor = tf.math.log(tf.clip_by_value(pi_tensor,1e-6, 1.))
loss_tensor = -self.discount * td_error * logpi_tensor
grad_tensors = tape.gradient(loss_tensor, self.actor_net.variables)
self.actor_net.optimizer.apply_gradients(zip(grad_tensors, self.actor_net.variables))
self.critic_net.fit(x, u, verbose=0)
if done:
self.discount = 1.
else:
self.discount *= self.gamma
|
play_qlearning
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def play_qlearning(env, agent, train=False, render=False):
episode_reward = 0
observation = env.reset()
step = 0
while True:
if render:
env.render()
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
if train:
agent.learn(observation, action, reward, next_observation,done)
if done:
break
step += 1
observation = next_observation
return episode_reward
|
训练
示例代码:
1
2
3
4
5
6
7
8
9
10
11
| actor_kwargs = {'hidden_sizes' : [100,], 'learning_rate' : 0.0001}
critic_kwargs = {'hidden_sizes' : [100,], 'learning_rate' : 0.0002}
agent = AdvantageActorCriticAgent(env, actor_kwargs=actor_kwargs,critic_kwargs=critic_kwargs)
episodes = 100
episode_rewards = []
for episode in range(episodes):
episode_reward = play_qlearning(env, agent, train=True)
episode_rewards.append(episode_reward)
print('{} {}'.format(episode,episode_reward))
|
运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
| 0 -419.0
1 -500.0
2 -500.0
3 -500.0
4 -500.0
【部分运行结果略】
95 -73.0
96 -81.0
97 -76.0
98 -107.0
99 -63.0
|
测试
示例代码:
1
2
3
|
episode_rewards = [play_qlearning(env, agent) for _ in range(100)]
print('平均回合奖励 = {} / {} = {}'.format(sum(episode_rewards),len(episode_rewards), np.mean(episode_rewards)))
|
运行结果:
1
| 平均回合奖励 = -9390.0 / 100 = -93.9
|
A3C
如果还想更快一点呢?
那就要开多线程了。
最后一种方法,Asynchronous Advantage Actor-Critic,A3C。Asynchronous的意思是异步。
如图所示
有一个Global Network和多个Worker。
首先,初始化Global Network的参数θ,每个Worker都从Global Network拷贝一份θ,然后开始训练,得到∇θ,再把∇θ传回给Global Netword,Global Network更新θ,θ←θ+η∇θ。然后Worker再拷贝一份新的θ,每个Worker都这么做。
就像我们平时编程中的多线程。比如,有一个线程,要做10件事情,原本要一件一件做。现在,我们把这个线程看作主线程,然后我们开10个子线程,让子线程去做,子线程完成之后,把结果返回给主线程。
或者,我们直接举生活中的例子,比如你在工作中,有10项任务,本来你要一件一件做;但是,现在你是领导了,你把这10项任务分给你手下的10个人去做,他们完成之后,把结果汇报给你。
这就是A3C。