爬虫
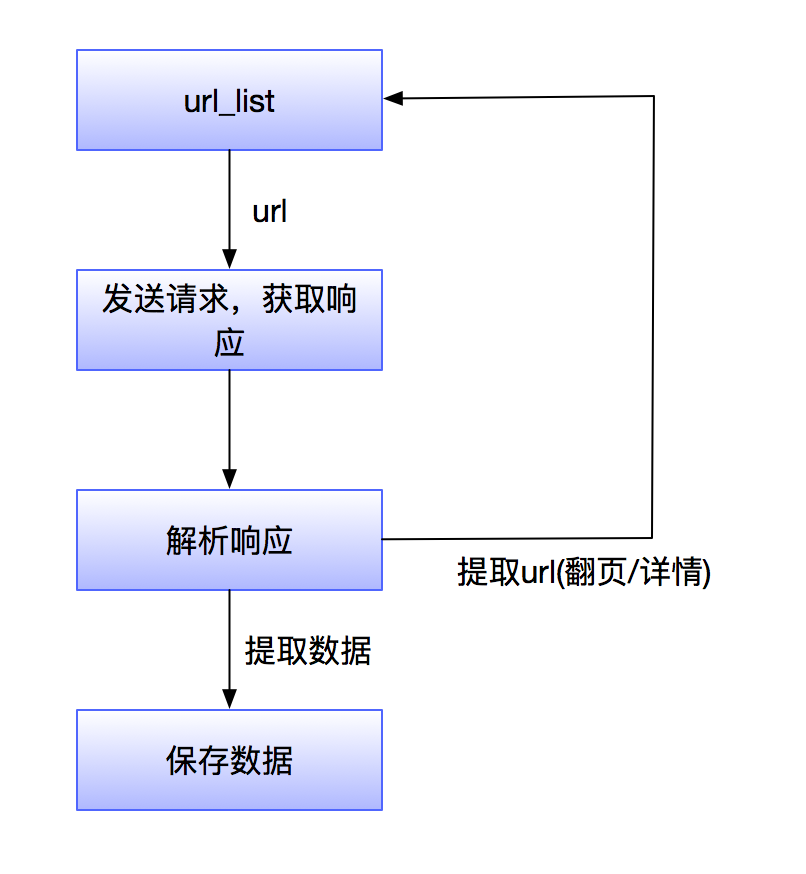
其实,爬虫能做的事情,我们用鼠标键盘也能做。我们打开浏览器,用鼠标点开一个又一个网页,然后再用键盘把网页的我们想要的内容一个一个的敲到Word文档中。
我们从第一步开始"发送请求获取响应"。
HTTP
那么,怎么去发送请求,获取响应呢?
在2012年伦敦奥运的开幕式上,第六章《弗兰克和琼恩说:感谢蒂姆》,弗兰克是指男孩,琼恩是指女孩,而蒂姆是指蒂姆·伯纳斯·李 ,他在舞台中央,坐在电脑前,敲出了那一句"This is for Everyone",意为把万维网(World Wide Web)献给所有人。他是英国人的骄傲,并在那一刻接受来自全世界的感谢。
蒂姆·伯纳斯·李 为万维网奠定了三大基石
HTTP:超文本传输协议(HyperText Transfer Protocol)
HTML:超文本标记语言(HyperText Markup Language)
URL:统一资源定位器(Uniform Resource Locator)
我们发送请求获取响应,所依赖的就是HTTP 。
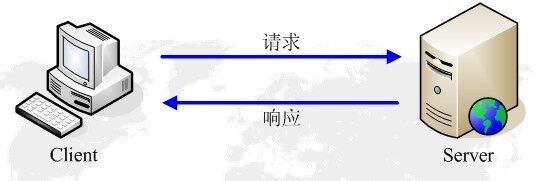
HTTP的请求过程
HTTP有所谓的三次握手,四次挥手。也有所谓的先去DNS服务器,请求域名对应的IP,再去请求IP。
但是,对于爬虫,我们可以理解成Client客户端发送请求,Server服务端返回响应,就这么简单。
不过,我们需要注意的是,我们通过爬虫请求到的页面,通常和我们浏览器上看到的页面,是不一样的。
当我们在浏览器上输入一个URL,比如 https://kakawanyifan.com ,浏览器发送一个Request去获取 https://kakawanyifan.com 的Response,服务器把Response返回给浏览器。浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如jpg文件、css文件、js文件等。然后浏览器会自动再次发送Request去获取jpg文件、css文件、js文件等,再进行渲染。这样,才是我们看到的kakawanyifan.com的主页。
所以呢,我们想要的数据,会在:
当前URL对应的响应中
其他URL对应的响应中
需要通过JS进行解析
其他URL对应的响应中
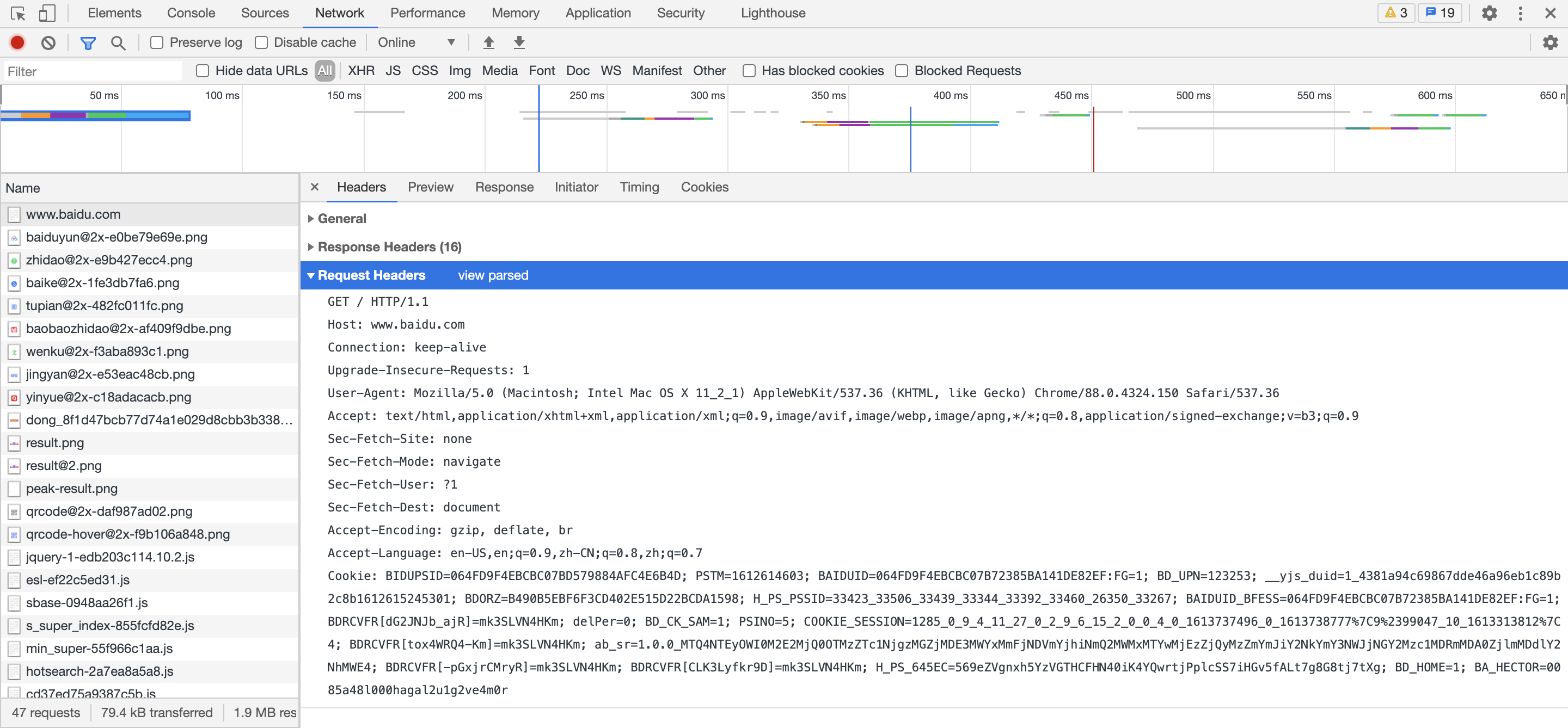
对于爬虫,我们还需要特别关注的是Request Headers和Response Headers。
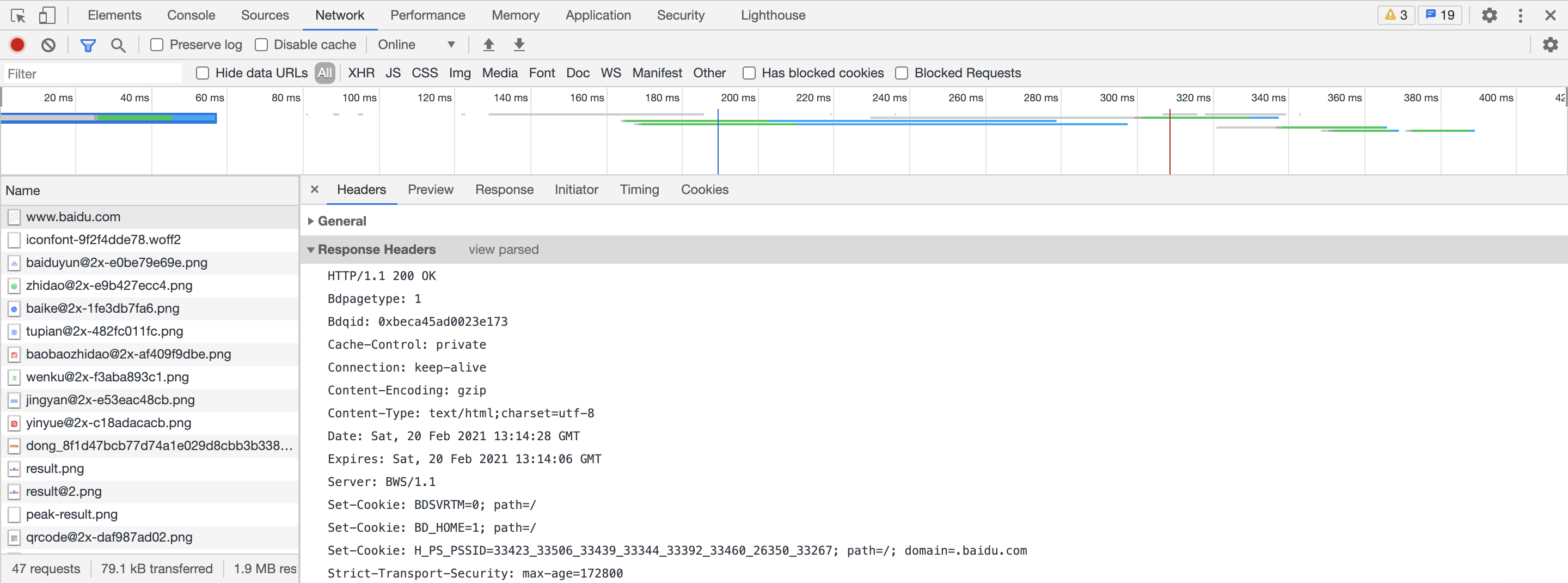
首先,Request Headers。www.baidu.com
这就是一个非常典型的Request Headers,覆盖了大部分我们要讨论的关于Request Headers的内容。
我们依次来讨论。
首行
请求方法和请求协议。
HOST
请求的域名(或IP地址)。www.baidu.com 。
Connection
客户端与服务连接类型。keep-alive,即Client客户端告诉Server服务端,我支持长连接。Response Headers包含一个Connection:keep-alive,反之,则是Connection:close。
Upgrade-Insecure-Requests
升级不安全的请求,意思是会在加载HTTP资源时自动替换成HTTPS的
User-Agent
浏览器名称。是Client客户端告诉Server服务端,是哪一个浏览器在请求。
Accept
Client客户端告诉Server服务端,我接收哪些类型的数据。
Accept: */*:表示什么都可以接收。Accept: text/html:表示客户端希望接收html文本。Accept: text/html,application/xhtml+xml,application/xml;q=0.9:表示html、xhtml和xml都支持。q的值默认是1,q=0.9则示优先级不高,即Client客户端告诉Server服务端:我优先接收html、xhtml,xml的话…也行吧。Application:用于传输应用程序数据或者二进制数据。
Accept-Encoding
浏览器可以接收的编码方式。
Accept-Langeuage
浏览器可以接收的语言种类,如en-us指英语,zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
Cookie
Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息。
Referer
表明Client客户端是从该Referer页面发起的请求,即用来跟踪Web请求来自哪个页面,是从什么网站来的等。
Content-Type
这个主要存在于POST请求中,指明该请求的消息体的数据类型。
(在上文的例子中没有出现)
X-Requested-With
XMLHttpRequest,说明是Ajax异步请求。
(在上文的例子中没有出现)
重点
User-Agent
Referer
Cookie
这三个在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要。
我们再看来Response Headers。
首行
响应状态码,这个是服务端发给客户端的。
200:成功
4**:客户端错误,请求包含语法错误或无法完成请求。
5**:服务器错误,服务器在处理请求的过程中发生了错误。
更多的状态码,可以参考《关于弹幕视频网站的例子:基于Serverless的弹幕视频网站实现方案》 的监控部分。
特别注意:有时候,我们收到某些错误的状态码,不是真的错了,只是被反爬虫了。 有时候,我们收到正确的状态码,也不是真的正确了,服务器已经识别出我们是爬虫了,但是为了让我们疏忽大意,所以照样返回状态码200,但是Response中并没有数据,甚至是假数据。
总之: 所有的状态码都不可信,一切以Response中的数据为准。
Content-Type
这里会有一个字段charset=utf-8,告诉我们如果要decode的时候,应该用哪种字符集。但不是所有的网站的Content-Type都有charset这个字段,甚至有些网站的这个字段并不准。
Set-Cookie
这个是设置Cookie,所以如果担心被反爬虫的话,可以在下一次发送请求之前,设置Cookie。
HTTPS
最后我们讨论HTTPS。
超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件。
传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
那么什么是HTTPS呢?
SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
GET请求
说了这么多,现在我们就来发送请求获取响应。从最简单的GET请求开始。
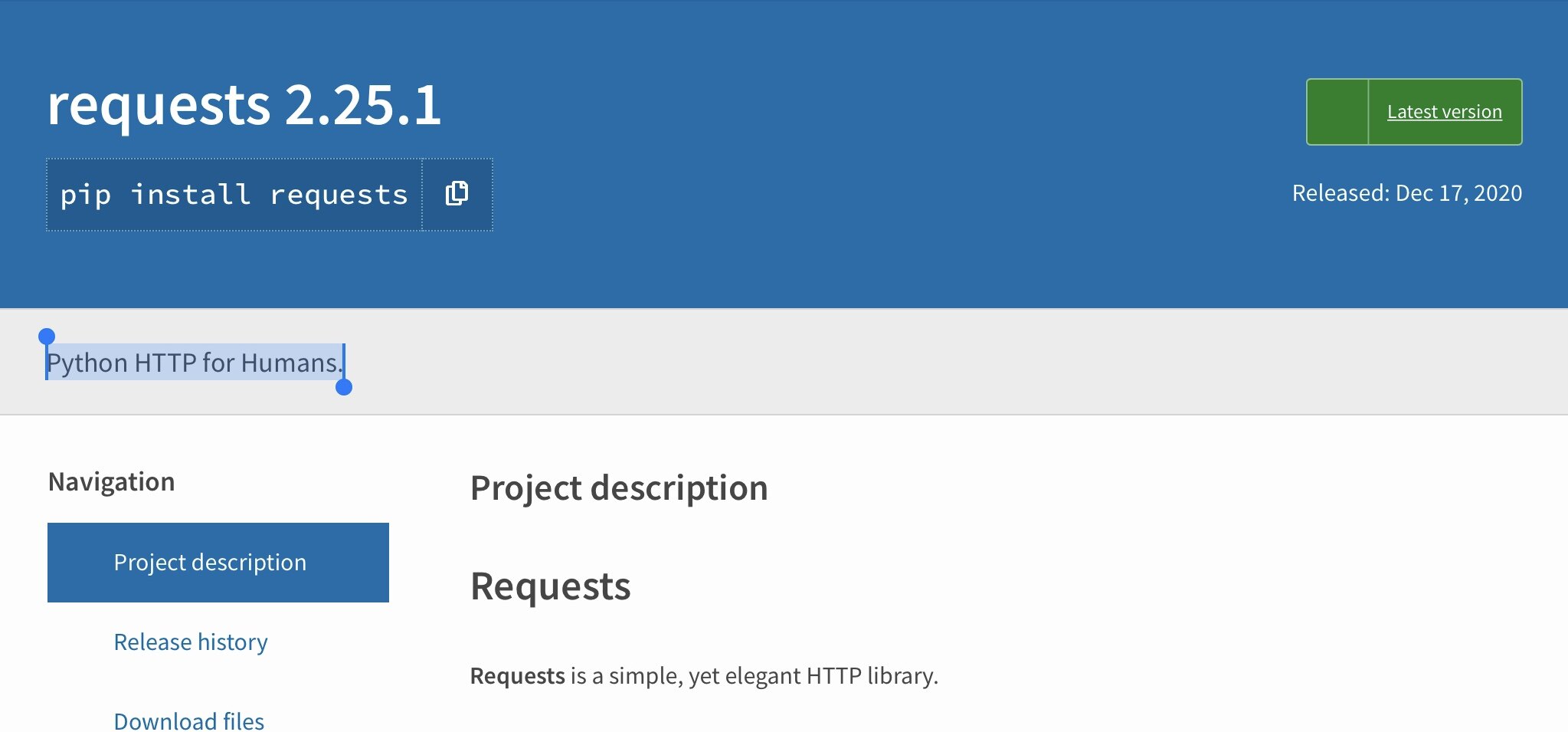
我们通过requests这个包实现,本章所有的请求也都通过这个包实现。这个包的官方介绍是"Python HTTP for Humans.",似乎透露着程序员的幽默。
但就像程序员都喜欢穿格子衬衫,有一个包的官方介绍透露着几乎一样的幽默,Keras,深度学习中的一个包。
GET请求的方法方法是:
获取请求头和响应头
现在我们就来打印我们刚刚讨论的Request Headers和Response Headers。
请求头:response.request.headers
响应头:response.headers
示例代码:
1 2 3 4 5 6 7 import requestsresponse = requests.get("https://kakawanyifan.com" ) print(response) print(response.request.headers) print(response.headers)
运行结果:
1 2 3 <Response [200]> {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} {'Server': 'Tengine', 'Content-Type': 'text/html', 'Content-Length': '6224', 'Connection': 'keep-alive', 'Date': 'Sun, 21 Feb 2021 05:46:30 GMT', 'x-oss-request-id': '6031F3B6A50D7734359552DE', 'x-oss-cdn-auth': 'success', 'Accept-Ranges': 'bytes', 'ETag': '"7BEA036E96E3B33C62A0AE1238C230DB"', 'Last-Modified': 'Fri, 19 Feb 2021 18:18:20 GMT', 'x-oss-object-type': 'Normal', 'x-oss-hash-crc64ecma': '9231358451180443004', 'x-oss-storage-class': 'Standard', 'Vary': 'Accept-Encoding', 'Content-MD5': 'e+oDbpbjszxioK4SOMIw2w==', 'x-oss-server-time': '16', 'Via': 'cache44.l2cn2655[366,304-0,H], cache19.l2cn2655[367,0], vcache1.cn2687[373,200-0,H], vcache31.cn2687[404,0]', 'Content-Encoding': 'gzip', 'Ali-Swift-Global-Savetime': '1613839330', 'Age': '0', 'X-Cache': 'HIT TCP_REFRESH_HIT dirn:6:106683182', 'X-Swift-SaveTime': 'Sun, 21 Feb 2021 05:46:30 GMT', 'X-Swift-CacheTime': '3600', 'Timing-Allow-Origin': '*', 'EagleId': 'dde751a116138863899937330e'}
特别的,我们发现request的默认User-Agent
1 'User-Agent': 'python-requests/2.24.0'
这似乎是在很嚣张的告诉我们访问的网站,爬虫来了,来反我啊。
获取响应内容
那么,我们怎么获取响应内容呢?
response.textresponse.content
response.text
示例代码:
1 2 3 4 5 import requestsresponse = requests.get("https://kakawanyifan.com/" ) print(type(response.text)) print(response.text)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 <class 'str'> 【部分运行结果略】 runtime_unit: '天', runtime: true, copyright: {"languages":{"author":"ä½è
: Kaka Wan Yifan","link":"é¾æ¥: ","source":"æ¥æº: Kaka Wan Yifan","info":"èä½æå½ä½è
ææãåä¸è½¬è½½è¯·èç³»ä½è
è·å¾ææï¼éåä¸è½¬è½½è¯·æ³¨æåºå¤ã"}}, ClickShowText: undefined, medium_zoom: false, 【部分运行结果略】
出现乱码了。
我们设置一下字符集就够了。response.encoding = "UTF-8",指定编码格式。
1 2 3 4 5 6 import requestsresponse = requests.get("https://kakawanyifan.com/" ) response.encoding = "UTF-8" print(type(response.text)) print(response.text)
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 <class 'str'> 【部分运行结果略】 runtime_unit: '天', runtime: true, copyright: {"languages":{"author":"作者: Kaka Wan Yifan","link":"链接: ","source":"来源: Kaka Wan Yifan","info":"著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。"}}, ClickShowText: undefined, medium_zoom: false, fancybox: false, 【部分运行结果略】
response.content
我们再来看第二种方法response.content。
1 2 3 4 5 import requestsresponse = requests.get("https://kakawanyifan.com/" ) print(type(response.content)) print(response.content)
运行结果:
1 2 3 4 5 6 7 8 <class 'bytes'> b'<!DOCTYPE html><html lang="zh-CN" data-theme="light"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"> 【部分运行结果略】 runtime_unit: \'\xe5\xa4\xa9\',\n runtime: true,\n copyright: {"languages":{"author":"\xe4\xbd\x9c\xe8\x80\x85: Kaka Wan Yifan","link":"\xe9\x93\xbe\xe6\x8e\xa5: ","source":"\xe6\x9d\xa5\xe6\xba\x90: Kaka Wan Yifan","info":"\xe8\x91\x97\xe4\xbd\x9c\xe6\x9d\x83\xe5\xbd\x92\xe4\xbd\x9c\xe8\x80\x85\xe6\x89\x80\xe6\x9c\x89\xe3\x80\x82\xe5\x95\x86\xe4\xb8\x9a\xe8\xbd\xac\xe8\xbd\xbd\xe8\xaf\xb7\xe8\x81\x94\xe7\xb3\xbb\xe4\xbd\x9c\xe8\x80\x85\xe8\x8e\xb7\xe5\xbe\x97\xe6\x8e\x88\xe6\x9d\x83\xef\xbc\x8c\xe9\x9d\x9e\xe5\x95\x86\xe4\xb8\x9a\xe8\xbd\xac\xe8\xbd\xbd\xe8\xaf\xb7\xe6\xb3\xa8\xe6\x98\x8e\xe5\x87\xba\xe5\xa4\x84\xe3\x80\x82"}},\n ClickShowText: undefined,\n medium_zoom: false,\n fancybox: false 【部分运行结果略】
又是乱码?
1 2 3 4 5 6 import requestsresponse = requests.get("https://kakawanyifan.com/" ) response.encoding = "UTF-8" print(type(response.content)) print(response.content)
运行结果:
1 2 3 4 5 6 7 8 <class 'bytes'> b'<!DOCTYPE html><html lang="zh-CN" data-theme="light"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"> 【部分运行结果略】 runtime_unit: \'\xe5\xa4\xa9\',\n runtime: true,\n copyright: {"languages":{"author":"\xe4\xbd\x9c\xe8\x80\x85: Kaka Wan Yifan","link":"\xe9\x93\xbe\xe6\x8e\xa5: ","source":"\xe6\x9d\xa5\xe6\xba\x90: Kaka Wan Yifan","info":"\xe8\x91\x97\xe4\xbd\x9c\xe6\x9d\x83\xe5\xbd\x92\xe4\xbd\x9c\xe8\x80\x85\xe6\x89\x80\xe6\x9c\x89\xe3\x80\x82\xe5\x95\x86\xe4\xb8\x9a\xe8\xbd\xac\xe8\xbd\xbd\xe8\xaf\xb7\xe8\x81\x94\xe7\xb3\xbb\xe4\xbd\x9c\xe8\x80\x85\xe8\x8e\xb7\xe5\xbe\x97\xe6\x8e\x88\xe6\x9d\x83\xef\xbc\x8c\xe9\x9d\x9e\xe5\x95\x86\xe4\xb8\x9a\xe8\xbd\xac\xe8\xbd\xbd\xe8\xaf\xb7\xe6\xb3\xa8\xe6\x98\x8e\xe5\x87\xba\xe5\xa4\x84\xe3\x80\x82"}},\n ClickShowText: undefined,\n medium_zoom: false,\n fancybox: false, 【部分运行结果略】
怎么还是乱码? 一定是打开方式不对!
我们来看看,在上面的代码中,我们特别的打印了type。response.text的type是str。而response.content的type居然是bytes二进制。bytes二进制解码为str,并指定编码格式是"UTF-8"。
示例代码:
1 2 3 4 5 import requestsresponse = requests.get("https://kakawanyifan.com/" ) print(type(response.content)) print(response.content.decode("UTF-8" ))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 <class 'bytes'> <!DOCTYPE html><html lang="zh-CN" data-theme="light"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width,initial-scale=1"><title>Kaka Wan Yifan</title><meta name="description" content=""><meta name="author" content="Kaka Wan Yifan,i@m.kakawanyifan.com"><meta name="copyright" content="Kaka Wan Yifan"><meta name="format-detection" content="telephone=no"><link rel="shortcut icon" href="/img/favicon.ico"><meta http-equiv="Cache-Control" content="no-transform"><meta http-equiv="Cache-Control" content="no-siteapp"><link rel="preconnect" href="//cdn.jsdelivr.net"/><link rel="preconnect" href="https://fonts.googleapis.com" crossorigin="crossorigin"/><meta name="google-site-verification" content="SzZHj5G5vHwv9JUmJD-bxmThc7a6YoZAsaNhwcD-BmM"/><meta name="msvalidate.01" content="1DD984606A0A3BC45A692A32685321AB"/><meta name="baidu-site-verification" content="99Pgg3yv8a"/><meta name="360-site-verification" content="273e85da5f4d732881979af78473b941"/><meta name="twitter:card" content="summary"><meta name="twitter:title" content="Kaka Wan Yifan"><meta name="twitter:description" content=""><meta name="twitter:image" content="https://kakawanyifan.com/img/avatar.png"><meta property="og:type" content="website"><meta property="og:title" content="Kaka Wan Yifan"><meta property="og:url" content="https://kakawanyifan.com/"><meta property="og:site_name" content="Kaka Wan Yifan"><meta property="og:description" content=""><meta property="og:image" content="https://kakawanyifan.com/img/avatar.png"><script src="https://cdn.jsdelivr.net/npm/js-cookie/dist/js.cookie.min.js"></script><script>var autoChangeMode = 'false' 【部分运行结果略】 runtime_unit: '天', runtime: true, copyright: {"languages":{"author":"作者: Kaka Wan Yifan","link":"链接: ","source":"来源: Kaka Wan Yifan","info":"著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。"}}, ClickShowText: undefined, medium_zoom: false, 【部分运行结果略】
区别
response.text
类型:str
解码字符集:requests模块自动根据response headers中的content-type作出有根据的推测。(在实际爬虫应用中,因为反爬的存在,不一定正确)
response.content
response的其它属性和方法
response.url:响应的url。response.request.url:请求的url。response.status_code:响应状态码。response.request._cookies:响应对应请求的cookie;返回cookieJar类型。response.cookies:响应的cookie(经过了set-cookie动作;返回cookieJar类型。response.json():自动将json字符串类型的响应内容转换为Python对象(dict或list)。
示例代码:
1 2 3 4 5 6 7 8 9 import requestsresponse = requests.get("https://kakawanyifan.com" ) print(response.url) print(response.request.url) print(response.status_code) print(response.request._cookies) print(response.cookies)
运行结果:
1 2 3 4 5 https://kakawanyifan.com/ https://kakawanyifan.com/ 200 <RequestsCookieJar[]> <RequestsCookieJar[]>
在我们讨论获取响应状态码等内容的时候,我们特别的提到了request的默认User-Agent默认是python-requests/2.24.0,并且说不要填python-requests/2.24.0,不要这么嚣张。
还是要设置User-Agent。User-Agent出现在哪里?Request Headers。
为了模拟浏览器,欺骗服务器,获取和浏览器一致的内容。我们设置headers。
1 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
直接以参数的形式传给requests.get(),就这么简单。
示例代码:
1 2 3 4 5 6 7 import requestsheaders = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/54.0.2840.99 Safari/537.36" } response = requests.get("https://baidu.com" , headers=headers) print(response.request.headers) print(response.content.decode("UTF-8" ))
发送带参数的GET请求
我们现在要搜索一个东西,比如搜索Python,那么我们是不是要发送一个带参数的请求?
参数以字典的形式,传参给requests.get()。
参数直接写入url的后缀中。
其实在GET请求中,这两种方法请求的URL是一样的。
1 2 3 4 5 6 7 8 9 10 import requestsheaders = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/54.0.2840.99 Safari/537.36" } params = {'wd' : '同济大学' } response = requests.get("https://www.baidu.com/s" , headers=headers, params=params) print(response.request.url) response = requests.get("https://www.baidu.com/s?wd=同济大学" , headers=headers) print(response.request.url)
运行结果:
1 2 https://www.baidu.com/s?wd=%E5%90%8C%E6%B5%8E%E5%A4%A7%E5%AD%A6 https://www.baidu.com/s?wd=%E5%90%8C%E6%B5%8E%E5%A4%A7%E5%AD%A6
发送POST请求
除了GET请求,我们还常见的一种请求是POST。
POST表单提交参数
参数:data。
方法:
1 response = requests.post("http://www.baidu.com/", data = data,headers=headers)
示例代码:
1 2 3 4 5 6 7 8 import requestsheaders = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/54.0.2840.99 Safari/537.36" } data = {'query' : 'helo' } response = requests.post("https://fanyi.baidu.com/langdetect" , headers=headers, data=data) print(response.content.decode("UTF-8" )) print(response.request.headers["Content-Type" ])
运行结果:
1 2 {"error":0,"msg":"success","lan":"may"} application/x-www-form-urlencoded
注意:Content-Type字段为application/x-www-form-urlencoded。
POST以请求体形式提交参数
参数:json。
示例代码:
1 2 3 4 5 6 7 8 import requestsheaders = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/54.0.2840.99 Safari/537.36" } data = {'query' : 'helo' } response = requests.post("https://fanyi.baidu.com/langdetect" , headers=headers, json=data) print(response.content.decode("UTF-8" )) print(response.request.headers["Content-Type" ])
运行结果:
1 2 {"error":0,"msg":"success","lan":"may"} application/json
POST上传字符串
有时候,需要发送的请求体比较复杂,我们可以把符合格式的数据做成字符串的形式上传,然后headers根据需要自己定义。
示例代码:
1 2 3 4 5 6 7 8 9 import requestsurl = "http://192.168.1.122" xml = "my xml\n" xml2 = """{"key":"value"}""" xml3 = xml + xml2 headers = {'Content-Type' : 'application/html' } r = requests.post(url, headers=headers, data=xml3)
POST上传文件
参数:files。
会以表单形式上传文件。
示例代码:
1 2 3 4 5 import requestsurl = "http://192.168.1.122" files = {'file' : open('test.txt' , 'rb' )} r = requests.post(url, files=files)
使用代理IP
为什么要使用代理IP?
代理IP的分类
使用代理IP,就是穿上马甲。但是呢,不是每一件马甲都有效。
根据匿名程度
根据代理IP的匿名程度,可以分为下面三类:
透明代理(Transparent Proxy)
1 2 3 REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
匿名代理(Anonymous Proxy)
1 2 3 REMOTE_ADDR = proxy IP HTTP_VIA = proxy IP HTTP_X_FORWARDED_FOR = proxy IP
高匿代理(Elite proxy或High Anonymity Proxy) 毫无疑问使用高匿代理效果最好 。目标服务器接收到的请求头如下:
1 2 3 REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
其实呢,这些都是代理技术上的。但除了代理技术,还有司法手段,真正触犯了党纪国法,根本就不存在所谓的"高匿代理"。 中国爬虫违法违规案例汇总
根据协议
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
http代理:目标url为http协议
https代理:目标url为https协议
socks隧道代理(例如socks5代理)等。
代理的实现
方法:
1 requests.get("http://www.baidu.com", proxies = proxies)
proxies的形式:字典
例如:
1 2 3 4 proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }
如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的代理ip
示例代码:
1 2 3 4 5 6 7 import requestsproxies = { "http" : "http://166.111.50.182:7890" } response = requests.get("https://kakawanyifan.com" , proxies=proxies) print(response.content.decode("UTF-8" ))
运行结果:
1 2 3 4 5 6 7 8 9 10 11 【部分运行结果略】 runtime_unit: '天', runtime: true, copyright: {"languages":{"author":"作者: Kaka Wan Yifan","link":"链接: ","source":"来源: Kaka Wan Yifan","info":"著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。"}}, ClickShowText: undefined, medium_zoom: false, fancybox: false, 【部分运行结果略】
cookie的处理
接下来,我们讨论cookie的处理。
利用headers参数添加cookie
利用专门的cookies参数
我们以github.com这个网站为例,cookie可以通过Chrome浏览的开发者工具获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requestsheaders_without_cookie = { 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' } headers_with_cookie = { 'cookie' : '_octo=GH1.1.920058066.1612922582; tz=Asia%2FShanghai; _device_id=2f0b1ec1e2c816a1f6b6e0cb5ac416a0; has_recent_activity=1; user_session=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; __Host-user_session_same_site=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; tz=Asia%2FShanghai; logged_in=yes; dotcom_user=KakaWanYifan; _gh_sess=dOmnqu8Pvxyadv8Ba7Y%2FpvMLi%2BJkJlJZKMXMfGADDOxe7flWRgzH880jF89uxdpCkMVAtFvtlBngQCgkuBr6lq3wduj5Y6LtgXYtTmT7IL9CBIpSSG7COWuKsYxsZmcHcKDGQsEkQO3hRQH4FmGrX1MMBLegGQkLi%2BnOwsARFmir3gMDMa15BMBI3AvX9fDIR3grW%2BS%2FNED2x4o0KIdByEdlYlGsWQyiCwGF3rNGBxpJagJz%2FK%2BhY%2FJhpQef8n2ut2JYEU%2Bjq0UMdesF8BPLw0AbgqE6gg%2FZbOSc4shk5WzK1shd8w2GJOYwncawB1Eo2yg5kN%2BI%2FdnCB%2F0LpvvcjFZC%2FGWs%2Frxys1fxNxjiCmP1qE9oe64jCYW86VJqVm0Hwf%2BQqhlwOznDkGX3ppj5z5nv3iFOER0HBDsMAoOT23V07rQ79tvoNk8BTFD5JTgvPe2%2BKtlfGeIRgGWIKiQGSo3NQM3khnoNCQ1%2FDDuUeC7aCofPRyxPmtNqfRuHwz6%2BgK7UOgv33mExugmADv27sawT865e0yhASpelAS%2BClwWgSAXytIPtMDcXEl4R7ZQUWxc1CnTNT3bBmHXNmDQYZWoY%2BSSGczXrn9diwKyQhnisJJ5FePB64lR8%2FfLD%2FubSuEAjilcLNUyLvcnKqTcTQPRkTwKScTtBYu4oEKznnLeY3oDXtBBMXOoo8nve8bWAQ4ldtwxNQEirbJKjBdNsysZOxbBziEIOOfOg4XxfadR7SIeKBvflsfuK3JLit6avuyfJqtOVJT08CtrgT15b8IC2CrqwRwOGGDB4QOYEby89ZXmTO%2Bi%2FQr80RqqsJB8LB31jkk4htcWuvl%2FjpT4gILPTOp9h%2FK%2F%2FF9p20SBRhwNKcZf0rNirkgxkEsX1YhgY2Uxx0lr%2B4vg2qYxmQpW5bMs49VlwWoyO196HPA%3D%3D--WQPylmKi7hlcvW4X--b71f6qOPPgWqtVTE2AvolA%3D%3D' , 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' } response = requests.get('https://github.com/' , headers=headers_without_cookie) print('kakawanyifan' in (response.content.decode("UTF-8" ).lower())) response = requests.get('https://github.com/' , headers=headers_with_cookie) print('kakawanyifan' in (response.content.decode("UTF-8" ).lower()))
运行结果:
很明显,在没有 cookie 的时候,访问https://github.com/,页面中并不包含kakawanyifan,但是如果带上 cookie 的话,就包含kakawanyifan了。这也说明,有 cookie 和没有 cookie ,拿到的响应并不一样。
利用专门的cookies参数
我们也可以利用专门的cookies参数,该参数的形式是字典。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 import requestsheaders_without_cookie = { 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' } cookies_str = "_octo=GH1.1.920058066.1612922582; tz=Asia%2FShanghai; _device_id=2f0b1ec1e2c816a1f6b6e0cb5ac416a0; has_recent_activity=1; user_session=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; __Host-user_session_same_site=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; tz=Asia%2FShanghai; logged_in=yes; dotcom_user=KakaWanYifan; _gh_sess=oKVNid%2Bajb4x2Co7tft%2FMy9YJnHvS7RoPPFSMKK5JJNOU39RyJpwcJO583sEXMvyVYRcENfWnZzyhO%2BI%2Fxfm6QrRLrgyHRIzveXvC8TmmASwyvZk6Sg2tH%2BaFGANDqPN2mKYF8dzN2ZZqonWIVFpxxz9rvpxXlsJ1kjmg6Yc4EkSJYbuD1V9jaBCahxTk7zhXNuzzUincBOfWC%2BUQrHWfOkOSFYFWh7WcdJ%2FNAv2b9f9F5%2FNUzCeWL9hTma2UEY%2F5gNdfCzB1hC23KSB8gylplXWcngEwbeq07LRNd5ZKCCTXxY%2BSJI6kW0PiJPrHQTQdrLHs677XM2B6RmIE7ouqL2D%2FLUEQ92QI5bOdi1FPXtzXl%2BEyjd0VN%2BABhXOFZXQvfC6m58LYdkZC9T9dged88dFhKaCYofDJZ7PNcAq1WSOmMXRMGaaNC5OyqB9dt4cohwVjLa4hGBLChbB33HPNM5Rtiw0cfTIXm1Vdpb%2FQpPo2T9pV2IZiFrdftzq7wgdhMM%2FEITFqqCpJEvjMIPdpeaKHBUnxPfo1flHPzl5vPhSh3Su1diMyMVz73gzewE7ub63bt6CBcsVwBUPEk0VMbWjpYA2hu2oYWoDeSSgzzoNjkwBPmCB6Wn2oY7Nryj5W4L0wiyU0S0QE%2FSBklPpVY4T1jiLZ%2B%2FpumgB4fuuIExCZC1in304cJfgbq0R0gQFEhVeGGLq%2B0q1uUKkkXX1dabEDf5MyedaToXbNF3RjvcyHdMoUzDaP6k93eiBA8XysQEN5EgZVZL4eieWXnhZYlDJ2vH0i0zCS8AMSCweahcHZm80hndGrSlq904ZQ6AiGL2j9r2bZdnO4anhKXy8lBz7sTLwEegamLgbrK21URJC%2F2Whm18j%2FhctuLSG%2Bb%2BctNMuPyL8iyZl0gdVQGrA3o2pBtAuPCml6LTHBQ%3D%3D--bL4%2FbRgWunTs5sxa--QH9XJXbDxrWhWkkvjYQ2Kw%3D%3D" cookies_dict = {cookie.split('=' )[0 ]: cookie.split('=' )[-1 ] for cookie in cookies_str.split('; ' )} response = requests.get('https://github.com/' , headers=headers_without_cookie, cookies=cookies_dict) print('kakawanyifan' in (response.content.decode("UTF-8" ).lower()))
运行结果:
cookieJar对象转换为cookies字典
截至目前,我们的cookies都是我们打开Chrome浏览器的开发者模式复制过来的。
任何东西都有一个日期。沙丁鱼会过期,罐头会过期,就连保鲜纸都会过期。
cookie过期了怎么办?
转换方法:
1 cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 import requestsheaders_without_cookie = { 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' } cookies_str = "_octo=GH1.1.920058066.1612922582; tz=Asia%2FShanghai; _device_id=2f0b1ec1e2c816a1f6b6e0cb5ac416a0; has_recent_activity=1; user_session=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; __Host-user_session_same_site=dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod; tz=Asia%2FShanghai; logged_in=yes; dotcom_user=KakaWanYifan; _gh_sess=oKVNid%2Bajb4x2Co7tft%2FMy9YJnHvS7RoPPFSMKK5JJNOU39RyJpwcJO583sEXMvyVYRcENfWnZzyhO%2BI%2Fxfm6QrRLrgyHRIzveXvC8TmmASwyvZk6Sg2tH%2BaFGANDqPN2mKYF8dzN2ZZqonWIVFpxxz9rvpxXlsJ1kjmg6Yc4EkSJYbuD1V9jaBCahxTk7zhXNuzzUincBOfWC%2BUQrHWfOkOSFYFWh7WcdJ%2FNAv2b9f9F5%2FNUzCeWL9hTma2UEY%2F5gNdfCzB1hC23KSB8gylplXWcngEwbeq07LRNd5ZKCCTXxY%2BSJI6kW0PiJPrHQTQdrLHs677XM2B6RmIE7ouqL2D%2FLUEQ92QI5bOdi1FPXtzXl%2BEyjd0VN%2BABhXOFZXQvfC6m58LYdkZC9T9dged88dFhKaCYofDJZ7PNcAq1WSOmMXRMGaaNC5OyqB9dt4cohwVjLa4hGBLChbB33HPNM5Rtiw0cfTIXm1Vdpb%2FQpPo2T9pV2IZiFrdftzq7wgdhMM%2FEITFqqCpJEvjMIPdpeaKHBUnxPfo1flHPzl5vPhSh3Su1diMyMVz73gzewE7ub63bt6CBcsVwBUPEk0VMbWjpYA2hu2oYWoDeSSgzzoNjkwBPmCB6Wn2oY7Nryj5W4L0wiyU0S0QE%2FSBklPpVY4T1jiLZ%2B%2FpumgB4fuuIExCZC1in304cJfgbq0R0gQFEhVeGGLq%2B0q1uUKkkXX1dabEDf5MyedaToXbNF3RjvcyHdMoUzDaP6k93eiBA8XysQEN5EgZVZL4eieWXnhZYlDJ2vH0i0zCS8AMSCweahcHZm80hndGrSlq904ZQ6AiGL2j9r2bZdnO4anhKXy8lBz7sTLwEegamLgbrK21URJC%2F2Whm18j%2FhctuLSG%2Bb%2BctNMuPyL8iyZl0gdVQGrA3o2pBtAuPCml6LTHBQ%3D%3D--bL4%2FbRgWunTs5sxa--QH9XJXbDxrWhWkkvjYQ2Kw%3D%3D" cookies_dict = {cookie.split('=' )[0 ]: cookie.split('=' )[-1 ] for cookie in cookies_str.split('; ' )} print(type(cookies_dict)) response = requests.get('https://github.com/' , headers=headers_without_cookie, cookies=cookies_dict) cookies_dict_get = requests.utils.dict_from_cookiejar(response.cookies) print(cookies_dict_get) print(type(cookies_dict_get))
运行结果:
1 2 3 <class 'dict'> {'__Host-user_session_same_site': 'dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod', '_gh_sess': 'EoekAFR2XqxbYq2QoennKctTxkcEqWhJJo4Ef1UqWHpQphu13Hu68tvbr9WxusGtJtqICKbturAXOpZMgZ6ypgddpCzawUHZAX4IIgIgIuLv3fQbwdzPBmtK91YbXDh2BE3G9OkRMx4mG%2F359Alc3ke7w3JxEDRMsZeWUyopzGBJhBjh0owEiiHOpzordEvr0%2Bx0WCctWOh1W2cCjnl6t3NgRv3NxjscvkzpO%2FQB6qXeSKe0fZhTyE%2FqDeHa4oVyLjo8vSfAI6r0uNbU36MBRYu3497wRS0nWbKDzkyevqfb4hwOV%2BRFlXpnF8zgAmpbJA0kcZNbdmWlShxT%2F0R0vu5adlpDnS%2BqqPe9Dne3nMhCLoGkzDdzv8%2FrA2lauY7Ihducnu9nNLv6kVGJ%2B9irEU4vGsmzIen7LSaWusmnNOVF8AbNlVd3b8I%2BiCov%2BxOQuI%2FkNkkdMtnvbvkd%2BVCzcRRUyaTfzj8SowW8qg0pRMBvVAAXr2ZLN9vrubXsbvuOWiPzj%2FOuLrEZFy0gFAFWu6DxdLJs4vDIEO2TBnScfCs5SGsLjt%2FMsY9bA1nSeKyHYznnma4gGmNCz3BlgLCO5KYFG1HsTkQ2xtUSXuh6aZhpBW%2B90H1O%2BTgWuQBQ%2FdE%2B%2FqBc%2BAWYldUOUCMMb9uZz54PtDZRptryI4UHYOhx%2BGf82xvXrbpPnroJaR50IxWDWq79LD6o8gRtfHqd%2FJy7g0vKYRppI3hrj0%2BcLm84biWDU8bco64bW%2BP%2FoyzHsZwH1niZdLQBDxciE9fxyziGIyKjvedQXtOluZL6Wq59XpXLp5Xb%2Fi%2FuR%2BbLtdgr8U5cuG2kbrF%2Bg1vFXz8Q%2FODiiSRz7yX0lcMv1oNk1S0kGXM4Wp7VTuJHwtNyKwFIKczfTmFHkKd08AObAIkLM0xV0x1UOqJnFn7Plaablg%3D%3D--XR1rS8NgCJCS9iGg--65xZ5t5BKxxE3wjIphT02w%3D%3D', 'has_recent_activity': '1', 'user_session': 'dSVXhZIHoWFbyksgBhbRS3LPAEmluYDKaOAncCYeJKZeQSod'} <class 'dict'>
session的处理
现在,我们来看这么一个现象。
1 2 3 4 5 6 7 import requestsheaders_without_cookie = { 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' } response = requests.get('https://github.com/' , headers=headers_without_cookie) print('Set-Cookie' in response.headers)
运行结果:
在响应头中有一个Set-Cookie,在上文我们提到了,Set-Cookie是告诉浏览器要添加cookie了。
1 session = requests.session()
后续的操作计划没有区别
1 2 response = session.get(url, headers, ...) response = session.post(url, data, ...)
其他技巧
超时参数timeout的使用
1 response = requests.get(url, timeout=3)
示例代码:
1 2 3 4 import requestsresponse = requests.get('https://google.com/' , timeout=3 ) print(response.content.decode())
运行结果:
1 2 3 4 5 6 7 8 Traceback (most recent call last): File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/urllib3/connection.py", line 159, in _new_conn conn = connection.create_connection( File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/urllib3/util/connection.py", line 84, in create_connection raise err File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/urllib3/util/connection.py", line 74, in create_connection sock.connect(sa) socket.timeout: timed out
参数忽略CA证书
方法
1 response = requests.get(url, verify=False)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 import requestsurl = "https://sam.huat.edu.cn:8443/selfservice/" try : response = requests.get(url) print(response.headers) except Exception as e: print(e) response = requests.get(url, verify=False ) print(response.headers)
运行结果:
1 2 3 4 HTTPSConnectionPool(host='sam.huat.edu.cn', port=8443): Max retries exceeded with url: /selfservice/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate (_ssl.c:1123)'))) /Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/urllib3/connectionpool.py:981: InsecureRequestWarning: Unverified HTTPS request is being made to host 'sam.huat.edu.cn'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings warnings.warn( {'Server': 'Apache-Coyote/1.1', 'X-Powered-By': 'Servlet 2.5; JBoss-5.0/JBossWeb-2.1', 'P3P': 'CP="CAO PSA OUR"', 'Pragma': 'no-cache, no-cache', 'Cache-Control': 'no-cache, no-cache', 'Expires': 'Thu, 01 Jan 1970 00:00:00 GMT', 'Set-Cookie': 'JSESSIONID=35C99232126734EE6E1E1C1C8300C56C; Path=/selfservice; Secure', 'Content-Type': 'text/html;charset=gbk', 'Content-Length': '5477', 'Date': 'Sun, 21 Feb 2021 07:56:18 GMT'}