定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
官网:https://kafka.apache.org
官方文档:https://kafka.apache.org/documentation
传统的定义是这样的,当然Kafka这个组织的野心,不只有这么一点。
Kafka官方的最新定义是:Kafka是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
例如,我们可以将Kafka用于日志归档。

消息队列
概述
关于消息队列,我们在《基于Java的后端开发入门:22.SpringBoot [2/3]》,有过简单的讨论。
常见的消息队列协议有三种:JMS、AMQP、MQTT。
常见的消息队列产品有:Kafka、ActiveMQ(JMS)、RabbitMQ(AMQP)和RocketMQ(AMQP)等。
应用场景
消息队列的应用场景有:
消峰(缓冲)解耦异步通信
消峰(缓冲)
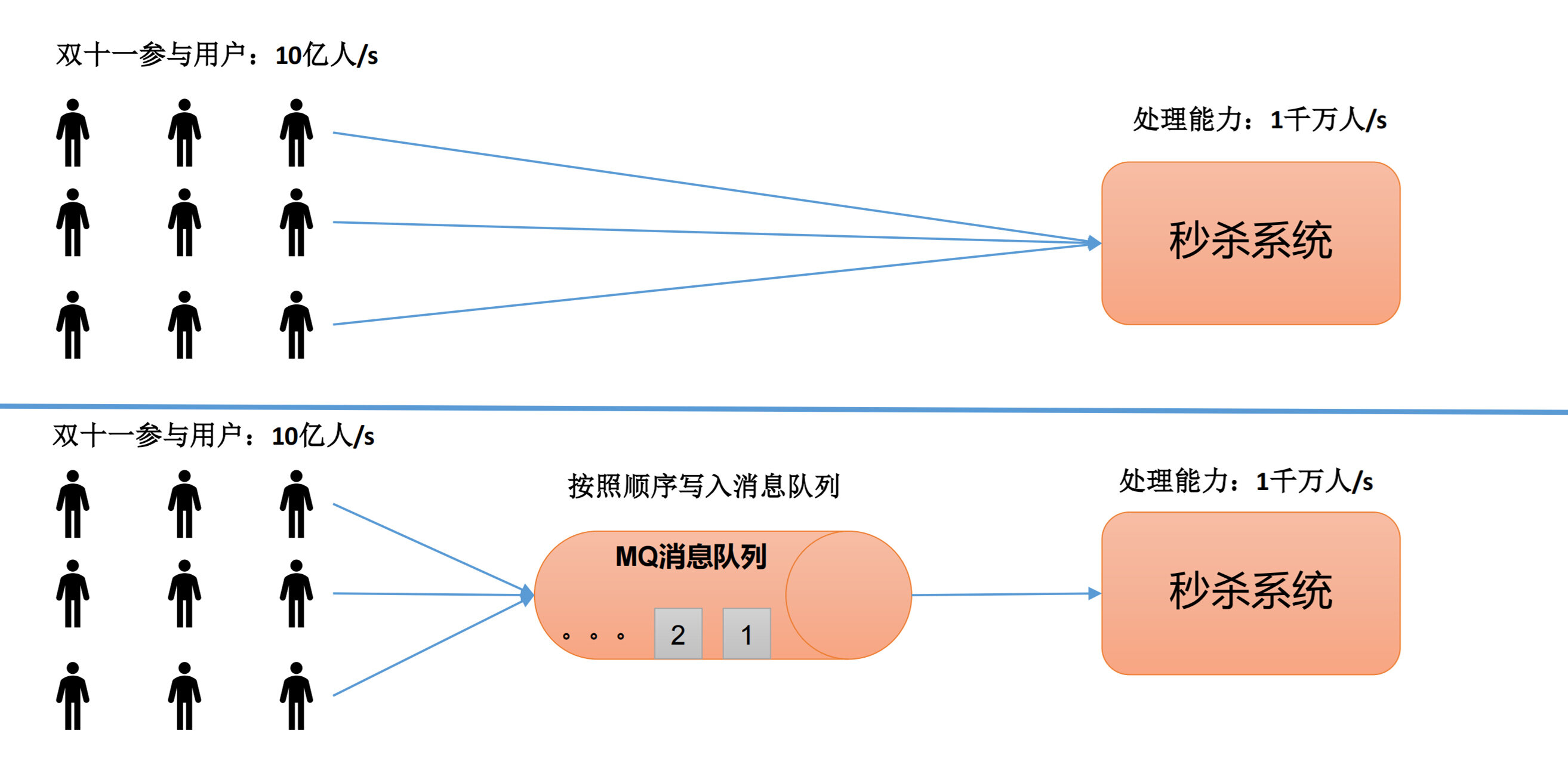
例如,我们的秒杀系统,每秒只能处理一千万人次的请求,但现在的访问量每秒有十亿人次。针对这种情况,我们可以先把所有的请求都保存在消息队列,然后由秒杀系统逐步进行处理。
解耦
允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
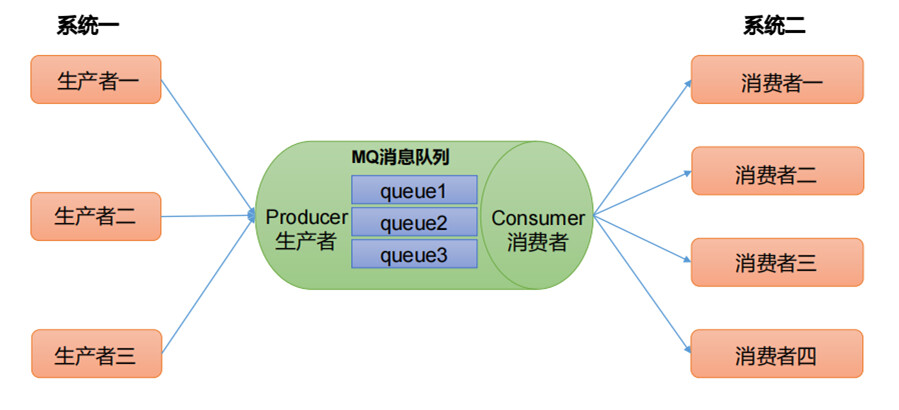
(在本文开头定义部分说的"日志归档",其实就是解耦,业务系统和日志存储系统是解耦的。)
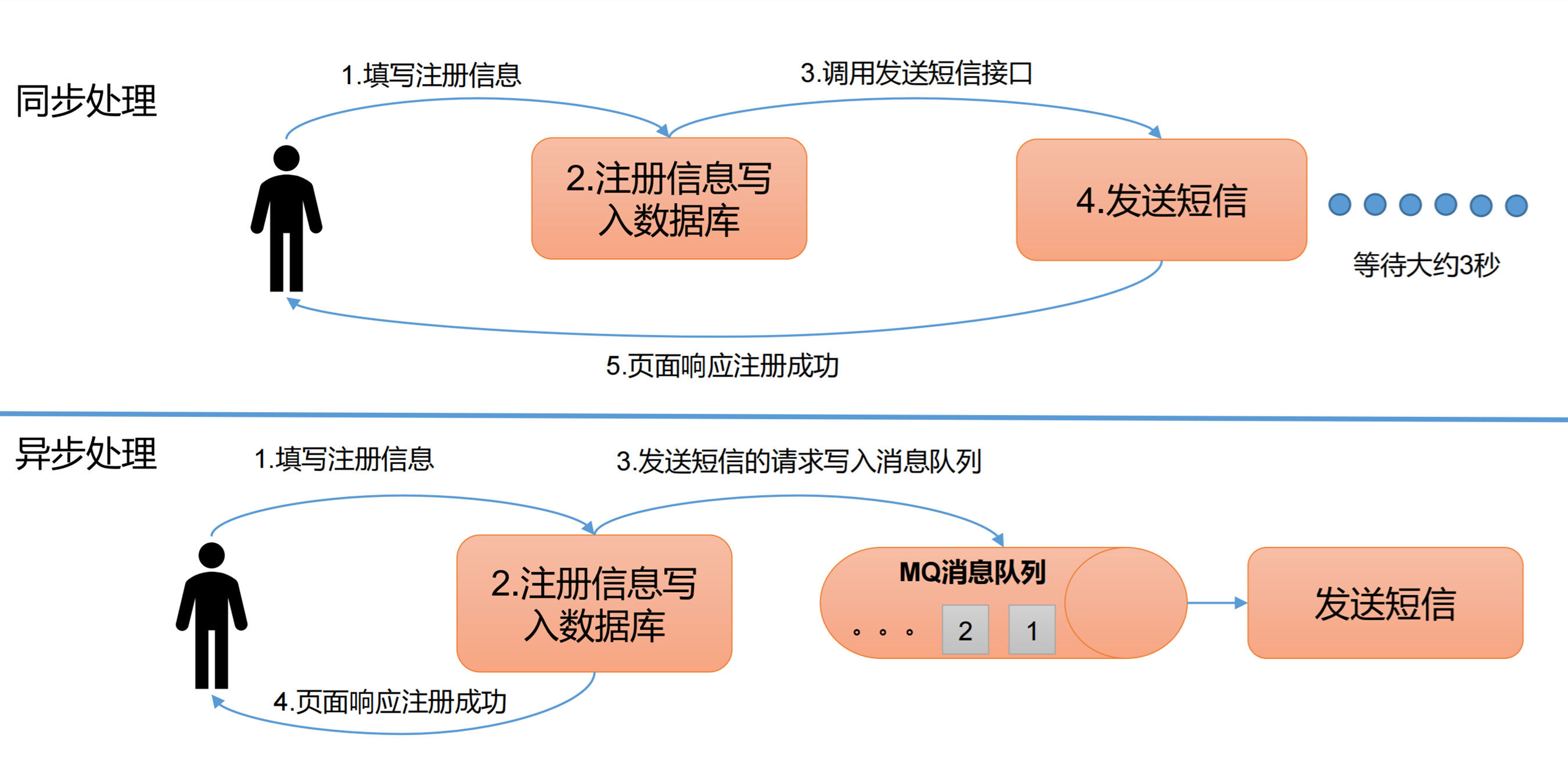
异步通信
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
两种模式
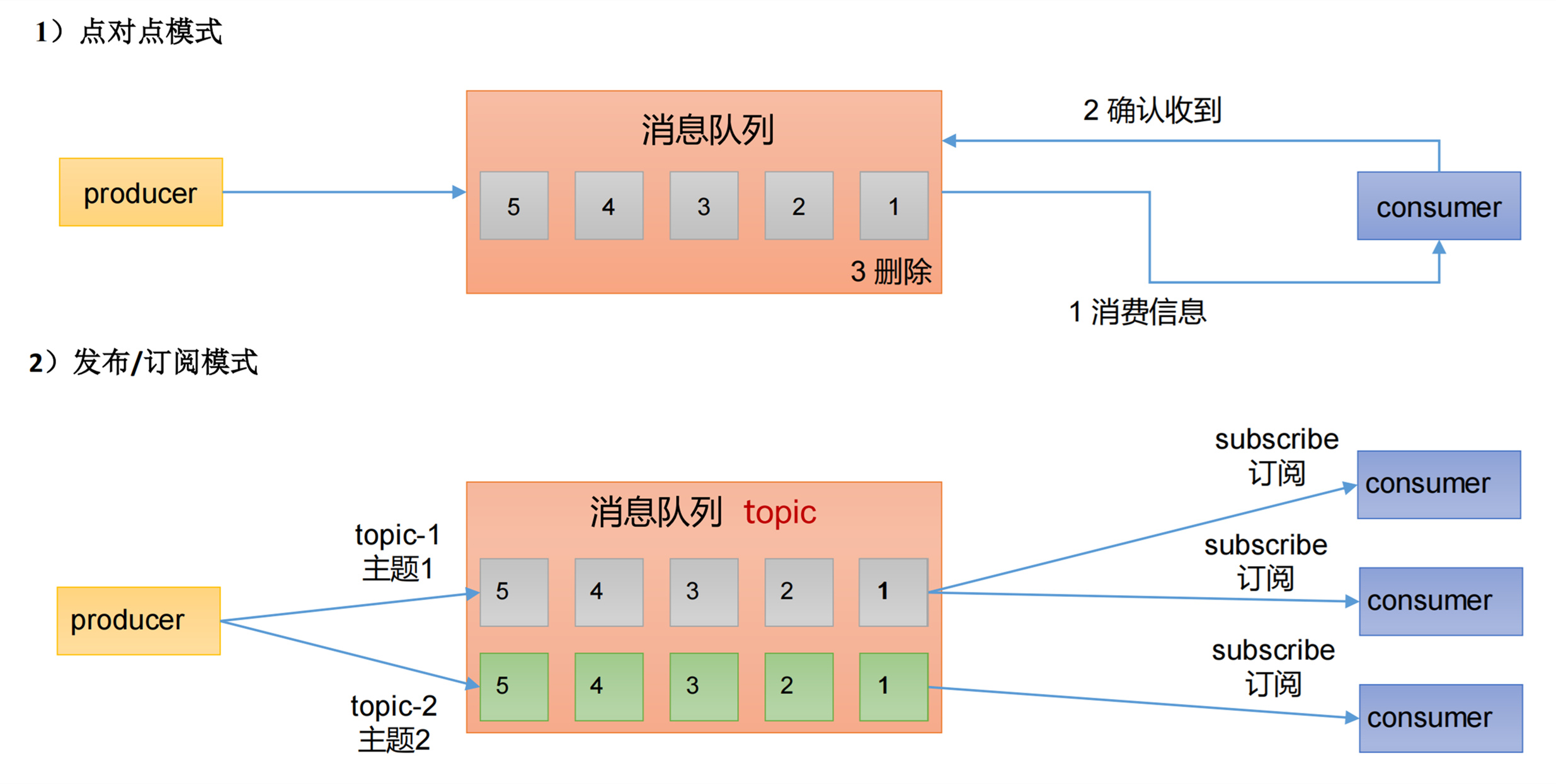
消息队列有两种模式:
- 点对点模式:
消费者主动拉取数据,消息收到后清除消息。 - 发布/订阅模式:
消费者消费数据之后,不删除数据。
每个消费者相互独立,都可以消费到数据。
可以有多个topic主题(浏览、点赞、收藏、评论等)。
Kafka基于的就是发布订阅模式。
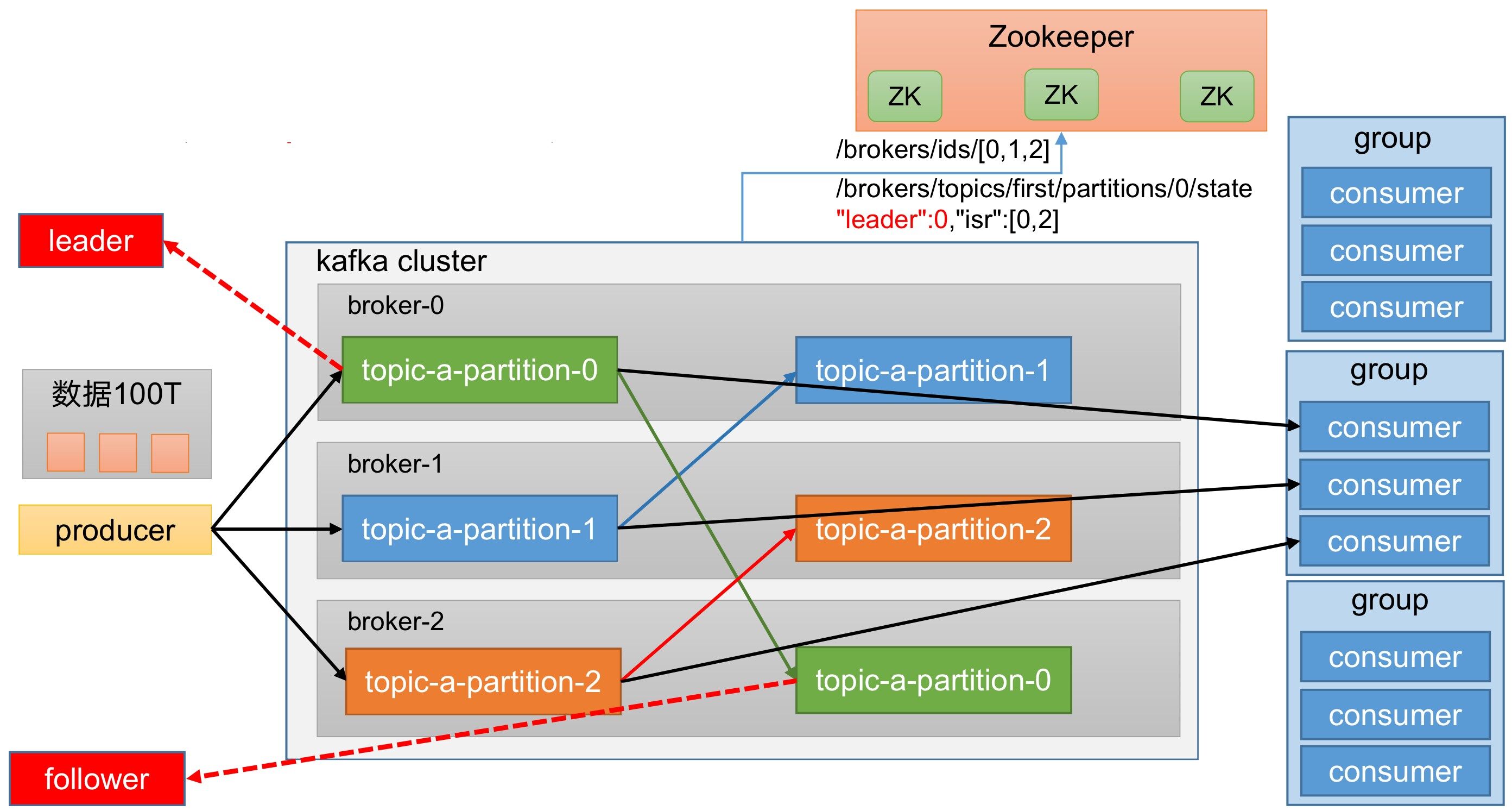
架构模型
整体架构
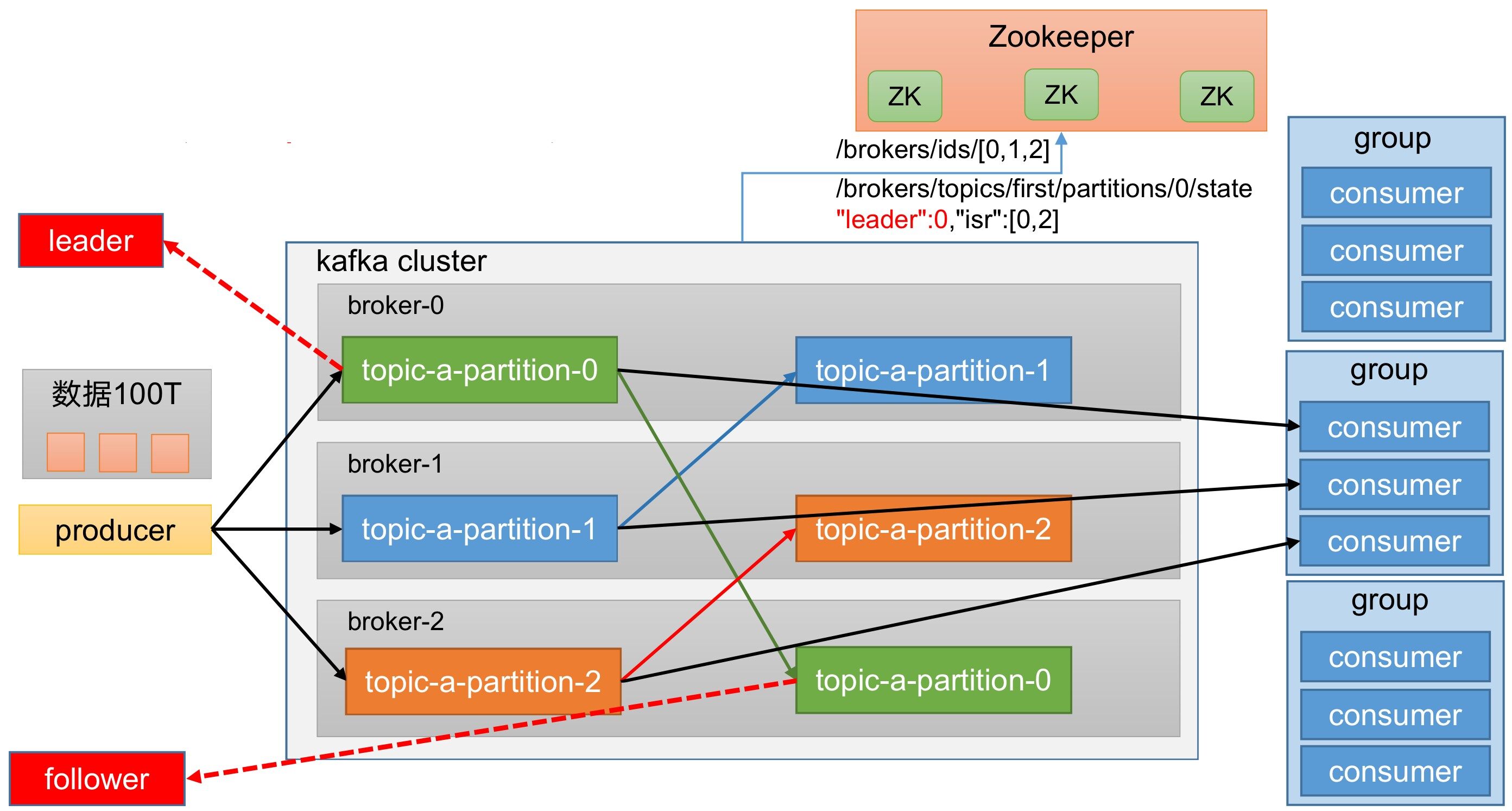
整体架构,如图所示。
接下来,我们会一步一步解析,这么设计的原因。
分区
从最简单的架构开始。
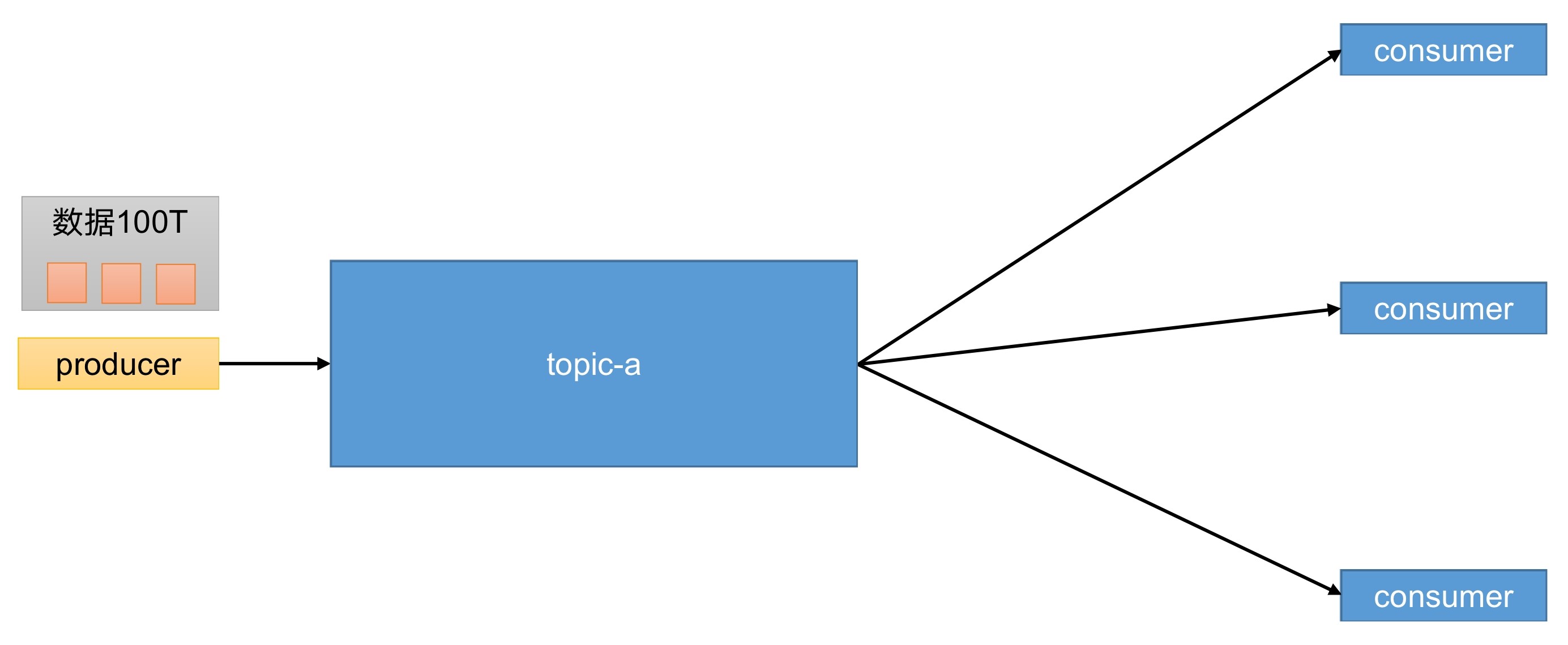
producer:消息生产者,向Kafka broker发消息的客户端。consumer:消息消费者,向Kafka broker收消息的客户端。topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
如果我们的数据有100T呢?
为了方便扩展、提高吞吐量,我们将一个topic分为多个partition。
同时,为了配合分区的设计,设计了消费者组,组内每个消费者并行消费。
一个分区的数据,只能由一个消费者进行消费。
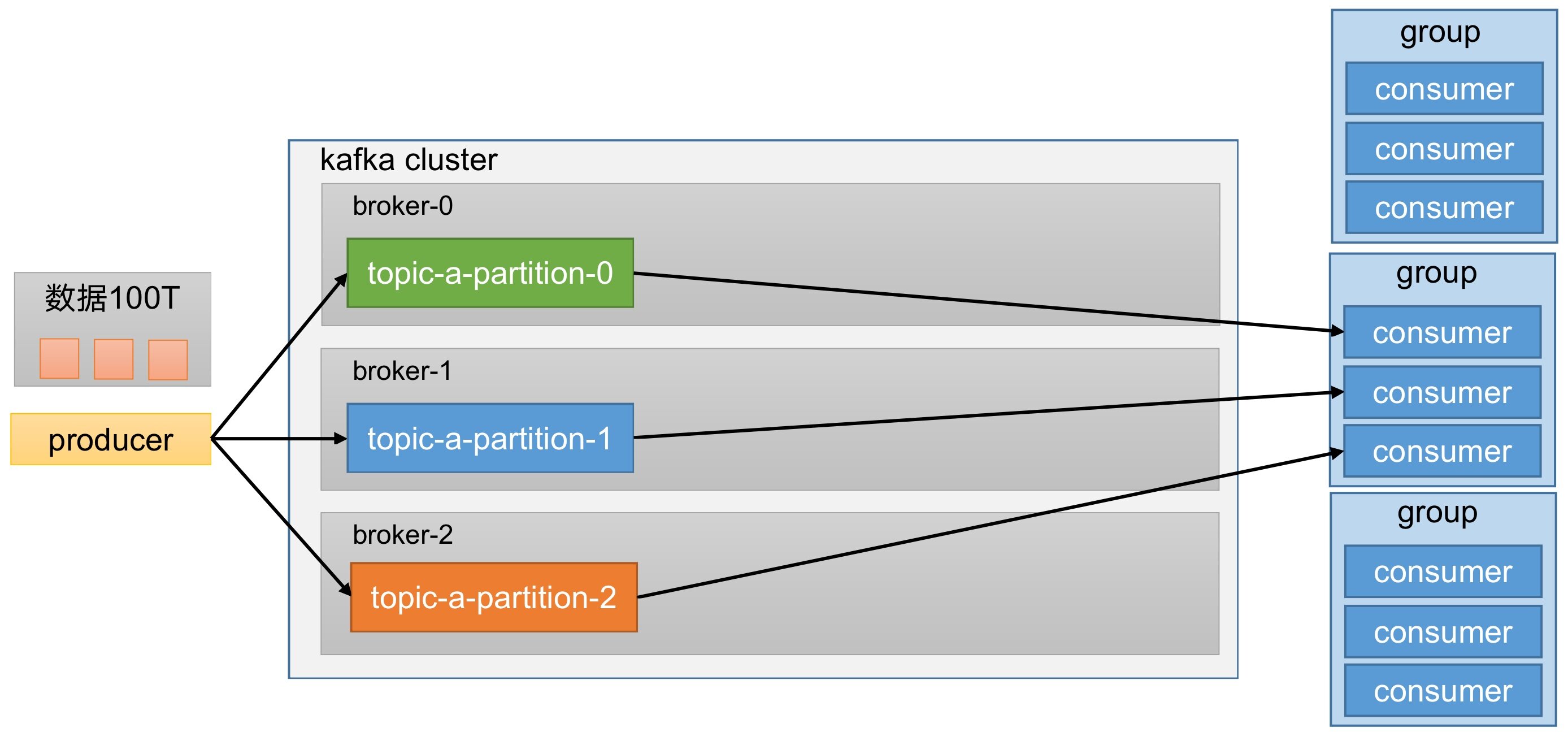
consumer group:消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由消费者组内的一个消费者消费;消费者组之间互不影响。消费者组是逻辑上的一个订阅者。broker:一台Kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。partition:为了实现扩展性,将一个非常大的topic可以分布到多个broker上。一个topic可以分为多个partition,每个partition是一个有序的队列。
分区的好处:
- 分区可以 合理使用存储资源 ,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。
- 可以 提高并行度 ,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
- 如果我们合理控制分区,还可以实现 负载均衡 。
副本
为提高可用性,为每个partition增加若干副本。
副本分为leader和follower。生产和消费只针对leader,在leader挂了之后,follower有条件成为leader。
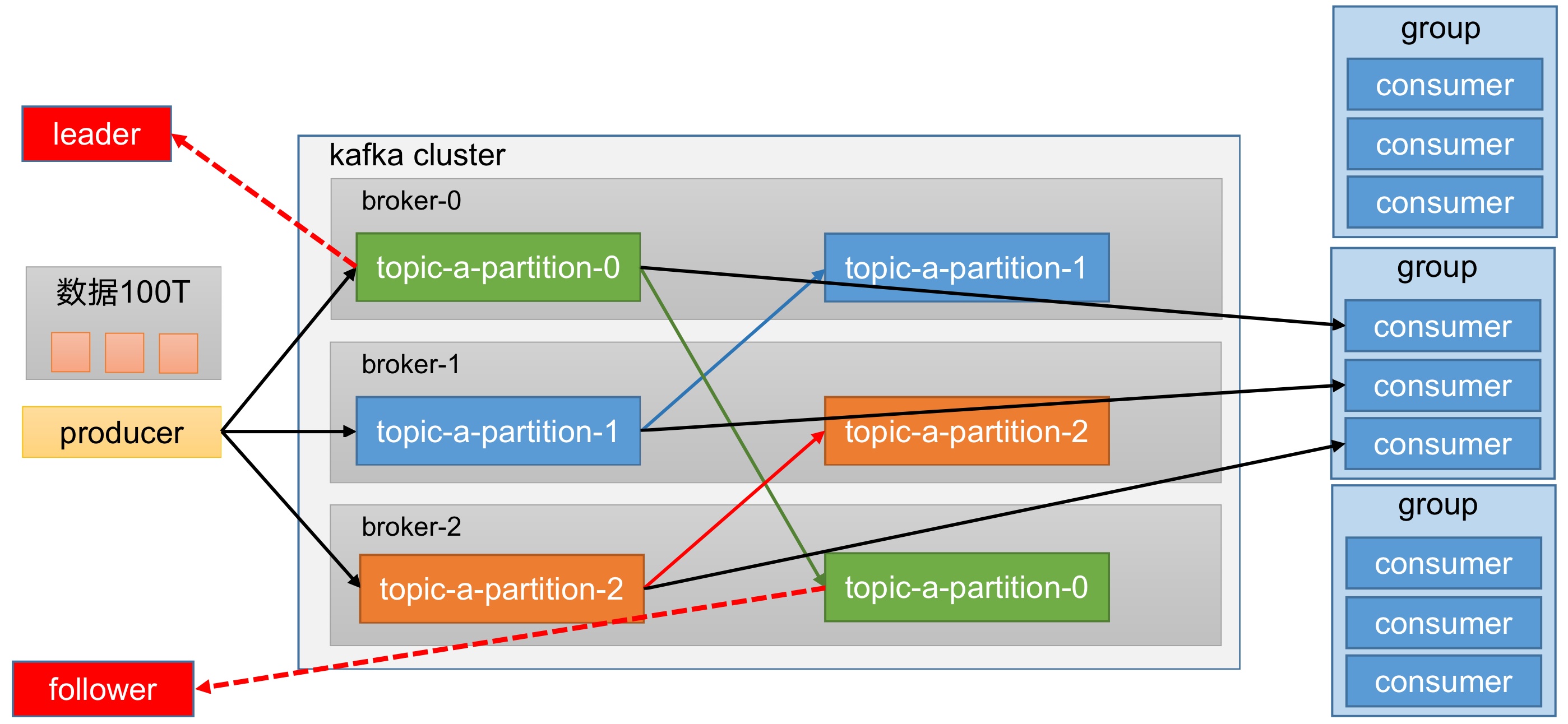
replica:副本。一个topic的每个分区都有若干个副本,分为一个leader和若干个follower。leader:每个分区多个副本的"主",生产者发送数据的对象,以及消费者消费数据的对象都是leader。follower:每个分区多个副本中的"从",实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
Zookeeper
Kafka中,还有一部分数据存储在Zookeeper,Zookeeper记录哪些服务器上线了,记录每一个分区中的leader、follower。
Kraft
在2.8.0以后也可以配置不采用Zookeeper,这个被称为Kraft模式。
Kraft模式,是未来的趋势,Zookeeper模式,是现在的主流。
在本文,我们对于两种模式都会讨论,但还是以Zookeeper模式为主。
安装部署
在《基于Java的后端开发入门:22.SpringBoot [2/3]》,我们已经讨论了Kafka的安装部署。
在这里我们更详细的讨论。
集群规划
| 01 | 02 | 03 |
|---|---|---|
| Zookeeper | Zookeeper | Zookeeper |
| Kafka | Kafka | Kafka |
在本文的示例中,我们所有的服务器(三台),都安装了Zookeeper和Kafka。
这并不是说都要这么规划(所有的服务器都安装Zookeeper和Kafka),比如我们有10台服务器,不一定需要10台服务器都安装Zookeeper和Kafka。
集群部署
下载地址
下载地址:http://kafka.apache.org/downloads.html
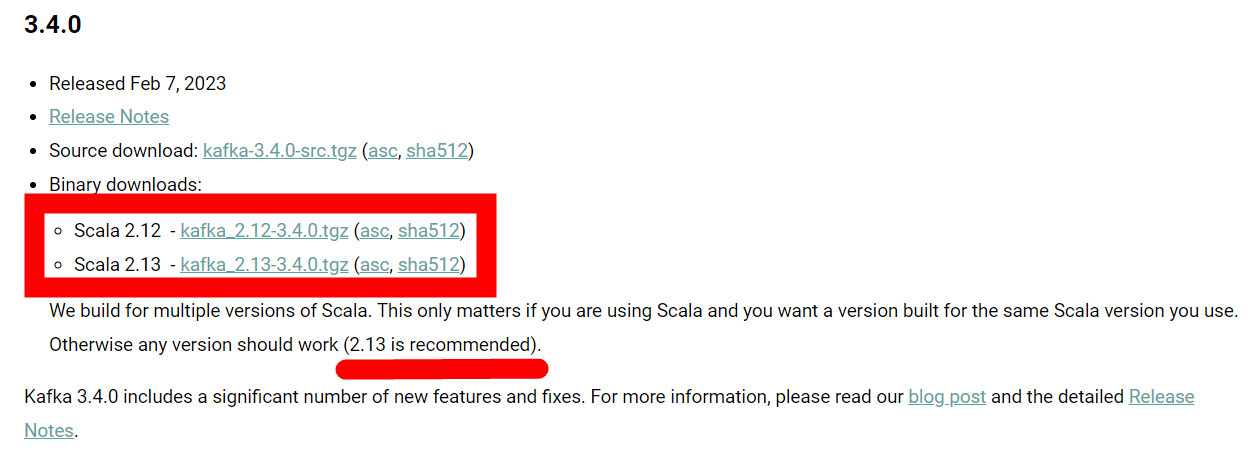
注意红框标出的部分。解释一下,Kafka是用Scala语言编写的;kafka_2.12-3.4.0.tgz的含义是,用Scala 2.12编写的,Kafka的版本是3.4.0;kafka_2.13-3.4.0.tgz的含义是,用Scala 2.13编写的,Kafka的版本是3.4.0;推荐用Scala 2.13编写的。
我们可以再关注一下2.8.0版本,有这么一句话:Early access of replace Zookeeper with a self-managed quorum
这就是Kraft模式。
JDK
注意,虽然Kafka是用Scala编写的,但是部分模块(Provider和Consumer相关的),是基于Java的,所以我们还是需要安装JDK。关于JDK的安装,可以参考《ElasticSearch实战入门(6.X):1.工具、概念、集群和倒排索引》。
如果没有安装JDK,在运行的过程中,可能会有如下的报错:
1 | /usr/kafka/kafka_2.13-3.4.0/bin/kafka-run-class.sh: line 346: exec: java: not found |
解压安装包
示例代码:
1 | tar -zxvf kafka_2.13-3.4.0.tgz |
server.properties
修改config目录下的server.properties。
zookeeper.properties
zookeeper.properties的内容如下:
1 | # the directory where the snapshot is stored. |
我们修改dataDir,改为/usr/kafka/kafka_2.13-3.4.0/zk/data
然后在dataDir定义的目录(/usr/kafka/kafka_2.13-3.4.0/zk/data)下创建一个myid文件,内容分别是1、2、3,记录每个服务器的ID。
Zookeeper集群配置,需要添加如下内容:
1 | =172.23.2.82:2287:3387 |
Zookeeper集群配置,还需要添加如下内容:
1 | initLimit=10 |
initLimit
leader和follow初始连接时能容忍的最多心跳数。syncLimit=2
leader和follower之间发送消息, 请求和应答的最大心跳数。
Zookeeper的一次心跳的时间由tickTime配置,默认该值为2000。
启动集群
先启动Zookeeper:
1 | ./zookeeper-server-start.sh -daemon ../config/zookeeper.properties |
再启动Kafka:
1 | ./kafka-server-start.sh -daemon ../config/server.properties |
关闭集群
先关闭Kafka:
1 | ./bin/kafka-server-stop.sh |
再关闭Zookeeper:
1 | ./bin/zookeeper-server-stop.sh |
问题排查
Kraft
关于下载、JDK以及解压部分,没有任何区别。
server.properties
注意,这里的server.properties,位于config/kraft/server.properties。
初始化集群数据目录
启动集群
不需要启动Zookeeper,只需要启动Kafka。
注意server.properties的地址。
1 | ./bin/kafka-server-start.sh -daemon config/kraft/server.properties |
命令行
主题命令行
查看参数
1 | ./bin/kafka-topics.sh |
运行结果:
1 | Create, delete, describe, or change a topic. |
| 参数 | 描述 |
|---|---|
--bootstrap-server <String: server toconnect to> |
连接的KafkaBroker主机名称和端口号 |
--topic <String: topic> |
操作的topic名称 |
--create |
创建主题 |
--delete |
删除主题 |
--alter |
修改主题 |
--list |
查看所有主题 |
--describe |
查看主题详细描述 |
--partitions <Integer: # of partitions> |
设置分区数 |
--replication-factor <Integer: replication factor> |
设置分区副本 |
--config <String: name=value> |
更新系统默认的配置。 |
查看所有的主题
1 | ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list |
创建主题
1 | ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --partitions 1 --replication-factor 3 --topic first |
选项说明:
--topic:定义topic名称--replication-factor:定义副本数--partitions:定义分区数
查看主题详情
1 | ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic first |
1 | Topic: first TopicId: Z4rDyAllS3OBmrZaVddP-Q PartitionCount: 1 ReplicationFactor: 3 Configs: |
修改分区数
注意,分区只能增加,不能减少。
1 | ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --alter --topic first --partitions 3 |
修改之后,我们再查看一下:
1 | Topic: first TopicId: Z4rDyAllS3OBmrZaVddP-Q PartitionCount: 3 ReplicationFactor: 3 Configs: |
删除主题
1 | ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --delete --topic first |
生产者命令行
查看参数
1 | ./bin/kafka-console-producer.sh |
运行结果:
1 | Missing required option(s) [bootstrap-server] |
| 参数 | 描述 |
|---|---|
--bootstrap-server <String: server toconnect to> |
连接的KafkaBroker主机名称和端口号 |
--topic <String: topic> |
操作的topic名称 |
发送消息
1 | ./bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic first |
消费者命令行
查看参数
1 | ./bin/kafka-console-consumer.sh |
| 参数 | 描述 |
|---|---|
--bootstrap-server <String: server toconnect to> |
连接的KafkaBroker主机名称和端口号 |
--topic <String: topic> |
操作的topic名称 |
--from-beginning |
从头开始消费 |
--group <String: consumer group id> |
指定消费者组名称 |
消费消息
消费first主题中的数据:
1 | ./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic first |
把主题中所有的数据都读取出来(包括历史数据):
1 | ./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic first |