ElasticSearch是什么
ElasticSearch,一款搜索数据库,基于Lucene。
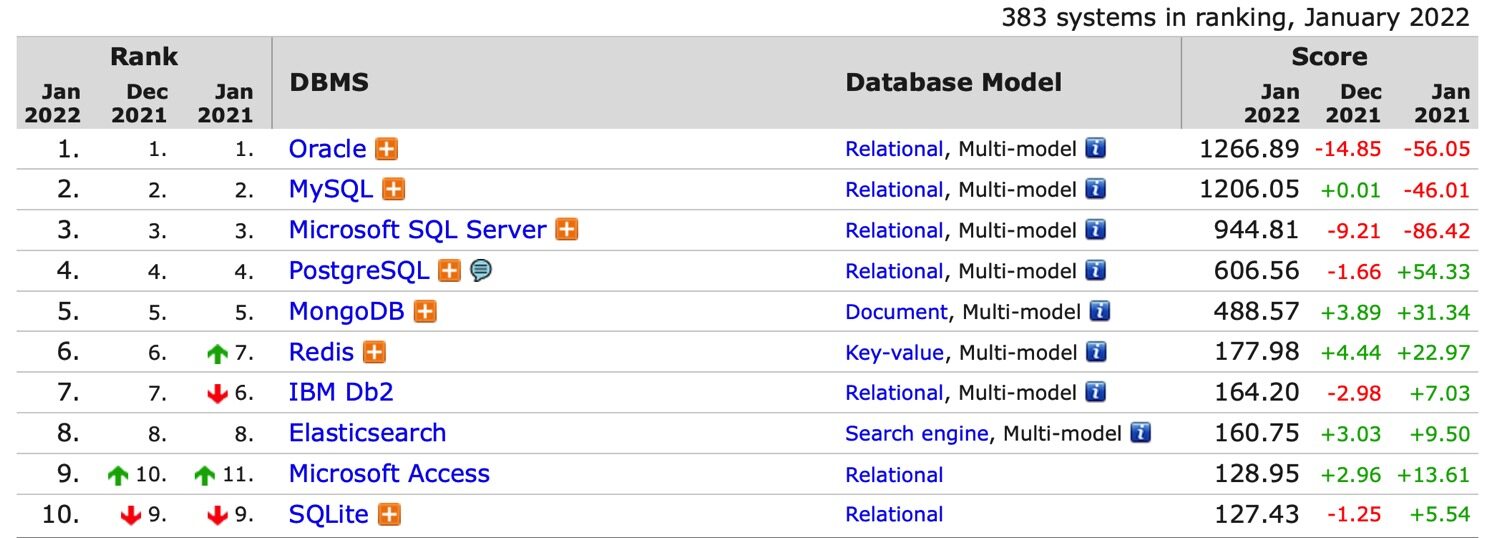
也有资料称ElasticSearch是搜索引擎,我的个人观点,更好的理解是认为其是搜索数据库,毕竟在著名的DB-Engines Ranking是榜上有名的,而且通过我们下文的讨论,认为其是数据库的确是更好的理解。
如图是2022年1月的数据库排行,ElasticSearch排第八名。
ElasticSearch,通常简称为ES,目前有两个重要的版本,6.X和7.X。
除了ElasticSearch,还有一项也很重要的技术,也被简称为ES,ECMAScript,编程语言JavaScript三部分中的一部分,是JavaScript的语法。其比较重要的版本也是6。(关于ECMAScript,我们在《基于JavaScript的前端开发入门:2.基础语法》有详细讨论)。
所以,有时候,我们遇到一些关于ElasticSearch的问题,需要谷歌百度搜索的时候,输入ES或者ES6,不一定能搜到ElasticSearch相关的,这时候可以考虑输入全称ElasticSearch。
安装ElasticSearch
准备JDK
ElasticSearch需要依赖JVM,且必须为8及8以上的版本,一般我们需要先安装好JDK。
为什么说是一般?
1、对于7.X等较高版本的,通过rpm的方式安装ElasticSearch的话,不需要事先安装好JDK。
2、ElasticSearch现在也有No JDK的,但只在7及7版本以上才有。
安装JDK有两种方法,rpm和tar。
通过rpm安装JDK
- 通过ORACLE官网下载JDK的rpm包,并上传至Linux服务器
地址:https://www.oracle.com/java/technologies/downloads - 通过命令
rpm -ivh jdk-8u321-linux-x64.rpm,安装JDK。
默认安装路径为/usr/java/jdk1.8.0_321-amd64/ - 配置环境变量,修改
/etc/profile,在文件末尾添加如下内容:1
2export JAVA_HOME=/usr/java/jdk1.8.0_321-amd64
export PATH=$PATH:$JAVA_HOME/bin - 重载环境变量
source /etc/profile。 - 测试,
java -version,如果显示Java 版本信息,则说明 JDK 安装成功。
通过tar包安装JDK
- 下载
jdk-8u311-linux-x64.tar。 - 创建目录,
mkdir /usr/local/java。 - 将文件
jdk-8u311-linux-x64.tar传输至/usr/local/java/。 - 解压JDK,
tar -xvf jdk-8u311-linux-x64.tar。 - 配置环境变量,修改
/etc/profile,添加如下内容并保存:1
2
3
4
5
6set java environment
JAVA_HOME=/usr/local/java/jdk1.8.0_311
JRE_HOME=/usr/local/java/jdk1.8.0_311/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH - 重载环境变量,
source /etc/profile - 测试,
java -version。
安装ElasticSearch
一、创建用户
ElasticSearch不能以root用户身份启动,必须是普通用户。所以,我们首先为ElasticSearch创建用户。
第一步、在Linux中创建新的组。
1 | groupadd es |
第二步、创建新的用户esu,并将其放入es组中
1 | useradd esu -g es |
第三步、修改用户esu的密码
1 | passwd esu |
第四步、切换为用户esu。
二、上传安装包并解压
上传安装包,然后解压。解压代码如下:
1 | tar -zxvf elasticsearch-6.8.23.tar.gz |
- 在通过tar安装JDK的时候,我们的命令是
tar -xvf,在这里是tar -zxvf,本质上都可以。(关于tar命令,可以参考《Linux操作系统使用入门:2.命令》关于"压缩和解压"部分的讨论。)
解压之后,我们通过cd进入目录,再ll,查看内容。
1 | bin |
解释一下:
bin:可执行的二进制文件的目录config:配置文件的目录lib:运行时依赖的库logs:运行时日志文件modules:运行时依赖的模块plugins:官方以及第三方插件
特别的,我们还可以cd进入lib目录,通过ll看看lib目录中都有什么。
1 |
|
- 这么多
lucene的包,似乎也说明了ElasticSearch是基于lucene的。 - 还有
log4j的包,而且是2.X版本的,所以大概在21年12月的一个log4j的安全问题,对ElasticSearch可能也会有影响。
三、启动ElasticSearch
通过cd进入bin目录,启动ElasticSearch。
示例代码:
1 | ./elasticsearch -d |
- 注意
-d,后台运行。
四、测试
示例代码:
1 | curl http://localhost:9200 |
运行结果:
1 | { |
- 可能会返回如下的内容,因为启动需要一定的时间。
1
curl: (7) Failed connect to localhost:9200; Connection refused
- ElasticSearch会占用两个端口
9200:HTTP端口。
9300:TCP端口,ELasticSearch集群之间通过该端口进行通讯,Java客户端中的TransportClient也是基于TCP协议通过该端口进行通讯。
五、允许远程连接
ElasticSearch默认只允许本地客户端连接,如果想要通过远程客户端访问,必须允许远程连接。
一、修改elasticsearch.yml
修改ElasticSearch目录下的config/elasticsearch.yml,在相应的位置添加如下内容。
1 | network.host: 0.0.0.0 |
0.0.0.0,表示允许所有IP的客户端访问。
二、重启服务
我们输入命令./elasticsearch -d,然后通过tail -100f logs/elasticsearch.log查看日志。
可能会有如下三个错误
1 | - ERROR: [3] bootstrap checks failed |
这是因为当我们开启允许远程连接后,ElasticSearch就会进行性能配置检查,如果检查不通过就关闭。
配置要求如下:
- 最大进程数大于等于65535
- ElasticSearch所在用户在线程数大于等于4096
- 虚拟内存大于等于262144
六、修改系统配置
为了解决上述的错误,我们需要修改系统配置。
最大进程数大于等于65535
使用root用户,修改/etc/security/limits.conf,在文件最后添加如下内容
1 | * soft nofile 65535 |
解释说明:
- 第一列,配置用户和用户组,
*表示所有。 - 第二列,
soft是软限制,hard硬限制。 - 第三列,
nofile文件数量,nproc进程数。
重新登录,通过如下的命令,检查配置是否生效。如果返回的数字和我们配置的数字一致的话,说明生效了。
1 | ulimit -Hn |
ElasticSearch所在用户在线程数大于等于4096
使用root用户,修改/etc/security/limits.d/20-nproc.conf,在文件最后添加如下内容:
1 | esu soft nproc 4096 |
- 如果保存失败,在命令的
vim前面添加sudo。 - esu为ElasticSearch的用户
注意:通过/etc/security/limits.d/20-nproc.conf文件的配置,会覆盖/etc/security/limits.conf的配置。
虚拟内存大于等于262144
使用root用户,修改/etc/sysctl.conf,在文件最后添加如下内容
1 | vm.max_map_count=262144 |
可以通过sysctl -p,检测是否生效。
七、检查
通过Postman,Get请求8.130.14.239:9200,收到如下内容,说明成功了。
1 | { |
如果还是不行的话,可能是防火墙打开了,或者网络安全组策略需要调整(开放端口等)。
如何判断是否有相关进程
ps -ef
现在,假设我们登录一台服务器,我们不知道关于该服务的任何历史信息,如何判断这台服务器上是否有ElasticSearch的进程呢?
1 | ps -ef|grep el |
jps
另外,一般ElasticSearch是需要基于JVM的,所有还有一个命令jps。
示例代码:
1 | jps |
运行结果:
1 | 2006 Elasticsearch |
安装Kibana
如果把ElasticSearch比作是MySQL的话。那么Kibana相对于ElasticSearch,就像DataGrip/Navicat相对于MySQL。
是一个图形化的,方便我们操作的客户端。
下载
下载地址:https://www.elastic.co/downloads/kibana
需要注意的是,Kibana要和ElasticSearch,版本要严格对应。
安装
安装命令:
1 | rpm -ivh kibana-6.8.23-x86_64.rpm |
安装目录
那么,Kibana被安装到哪里去了呢?
我们可以通过find / -name kibana找一下。
示例代码:
1 | find / -name kibana |
运行结果:
1 | /etc/kibana |
Kibana被安装在/usr/share/kibana
修改配置
Kibana的配置文件在/etc/kibana/kibana.yml。
一般需要修改两个配置。
server.host,默认为localhost,表示不允许远程访问,可以修改为0.0.0.0。elasticsearch.hosts: ["http://8.130.14.239:9200"],ElasticSearch服务的地址。
启动
启动Kibana:systemctl start kibana
另:
- 停止Kibana:
systemctl stop kibana - 查看状态:
systemctl status kibana
访问
Kibana有很多功能,在这里,我们只使用其DevTools功能。
基本概念
在准备好工具之后,我们来讨论ElasticSearch中的基本概念。
index
index,译作索引。
一个索引就是一个拥有相似特征的文档的集合,比如说,客户信息的索引,产品目录的索引,订单数据的索引。
我们可以把index理解为MySQL中的表。
所有的index名称的字母必须小写。
type
type,译作类型。
关于类型,在不同版本的ES中区别较大。
在5版本中
在5.6.0中,通过对index设置参数index.mapping.single_type: true,启用 【一个index一个type的限制】。
在6版本中
在6版本中,【一个index一个type】 会被强制启用,且建议设置type名为_doc,以兼容7版本。
但在5版本中创建的有多个type的index,在6版本中能正常工作。
在6.8.0中,引入了一个参数include_type_name,以控制是否包含type。默认为true,表示包含type。如果设置为false,将使用7版本风格的/{index}/_doc/{id}调用API。
在7版本中
在7版本中,include_type_name被默认置为false。
新的格式为/{index}/_doc/{id},需要注意的是,这里的_doc并不是一个type,而只是请求路径中永久的一部分。
在8版本中
include_type_name将会被删除。
mapping
mapping,译作映射。
mapping中主要包括字段名、字段数据类型和字段索引类型等。
我们可以把mapping理解为MySQL中的表结构。
document
document,译作文档,采用JSON来表示。
我们可以把document理解为MySQL中的一行数据。
和MySQL的比拟
| MySQL | ElasticSearch |
|---|---|
| 库 | 无 |
| 表 | index |
| 数据行 | document |
| 数据列 | field |
| 表结构 | mapping |
- 也有些资料认为ElasticSearch中的index对应的是MySQL的库,type对应的是MySQL中的表。这是在5版本中的对应关系。
集群
集群和节点
cluster,译作集群。
集群由一个或多个节点组成,共同持有整个数据,并共同提供索引和搜索功能。
一个集群,由一个唯一的名字标识,默认是"elasticsearch",一个节点只能通过指定某个集群的名字,来加入这个集群。建议我们自定义名称,不要用默认的名字。
节点是你集群中的一个服务器,作为集群的一部分,存储数据、提供搜索功能等。
分片和副本
shards译作分片。
replicas译作副本。
一个索引可以被分为多个分片,一个分片可以有多个副本。
为什么这么做呢?
我们在《关于弹幕视频网站的例子:基于Serverless的弹幕视频网站实现方案》中,也有过类似的操作。我们把一个完整的视频,切成了多个切片,然后我们还可以为每一个切片备份多个副本,比如GitHub一份、OSS一份。这么做的目的是,提高视频的加载速度,每次只需要读取一个切片,而不用读取完整的视频。当某个切片故障后,其备份的切片能立马顶上。
那么现在一样的,一个索引被分成多个分片,这些分片可能分布在不同的节点上,降低了单一节点的压力,有利于性能的提升,这个被称为高性能;一个分片有多个副本,如果某个分片挂了,其副本依旧能稳定的提供服务,这个被称为高可用。
这就是分片和副本的作用。
集群架构
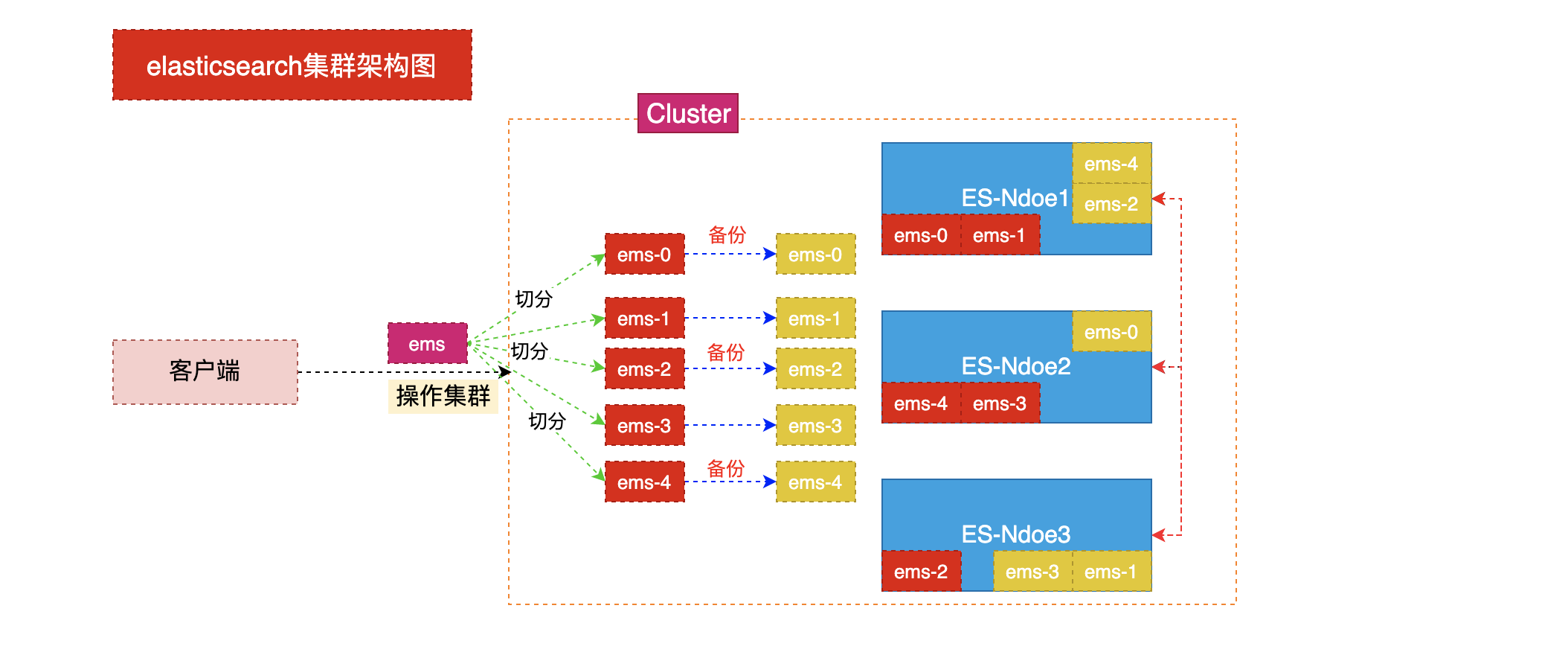
如图所示,"ems"为index的名称,该index有个分片,每个分片还有个多个备份。而分片和备份又在不同的节点上。这就是集群的架构。
搭建集群
奇数个节点
首先,我们需要准备三台机器。
为什么三台?这和ElasticSearch的分布式的算法有关,具体原因我不太清楚,但是ElasticSearch官方建议奇数个节点。
搭建步骤
对集群中的每一台机器的ElasticSearch的elasticsearch.yml配置文件。
-
cluster.name,集群名称,每一台机器的集群名称必须一致。例如:1
cluster.name: kakawanyifan
-
node.name,节点名称,每一台机器的节点名称必须不一致。例如1
node.name: kakawanyifan-1
1
node.name: kakawanyifan-2
1
node.name: kakawanyifan-3
-
network.host,设置为0.0.0.0,允许公共访问。 -
discovery.zen.ping.unicast.hosts,其它节点的IP。例如:1
discovery.zen.ping.unicast.hosts: ["172.23.2.72:9300", "172.23.2.73:9300"]
1
discovery.zen.ping.unicast.hosts: ["172.23.2.70:9300", "172.23.2.73:9300"]
1
discovery.zen.ping.unicast.hosts: ["172.23.2.70:9300", "172.23.2.72:9300"]
-
gateway.recover_after_nodes,集群可做master的最小节点数。例如:1
gateway.recover_after_nodes: 3
然后启动每一个节点。
并通过地址:8.130.25.160:9200/_cat/health?v,查看节点的健康状态。
(任意一个节点的地址均可。)
1 | epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent |
集群中的Kibana
那么,怎么在集群中用Kibana呢?
修改elasticsearch.hosts即可。
例如:
1 | elasticsearch.hosts: ["http://172.23.2.70:9200", "http://172.23.2.72:9200", "http://172.23.2.73:9200"] |
elasticsearch-head-chrome
elasticsearch-head-chrome,一个查看集群状态的软件,很多资料会推荐elasticsearch-head。
相较于elasticsearch-head,elasticsearch-head-chrome省去了繁琐的安装过程,是一个Chrome插件。
elasticsearch-head-chrome:https://github.com/TravisTX/elasticsearch-head-chromeelasticsearch-head:https://github.com/mobz/elasticsearch-head
根据GitHub网站的内容进行安装即可。
需要注意的是,我们需要修改elastsearch.yml配置文件,才可以访问。
添加如下内容:
1 | http.cors.enabled: true |
允许跨域。
关于跨域,我们在《关于弹幕视频网站的例子:基于Serverless的弹幕视频网站实现方案》中,有过简单的讨论。
如图,elasticsearch-head-chrome的页面,我们看到名称为est的index,被分为了5个分片,每个分片还有备份。
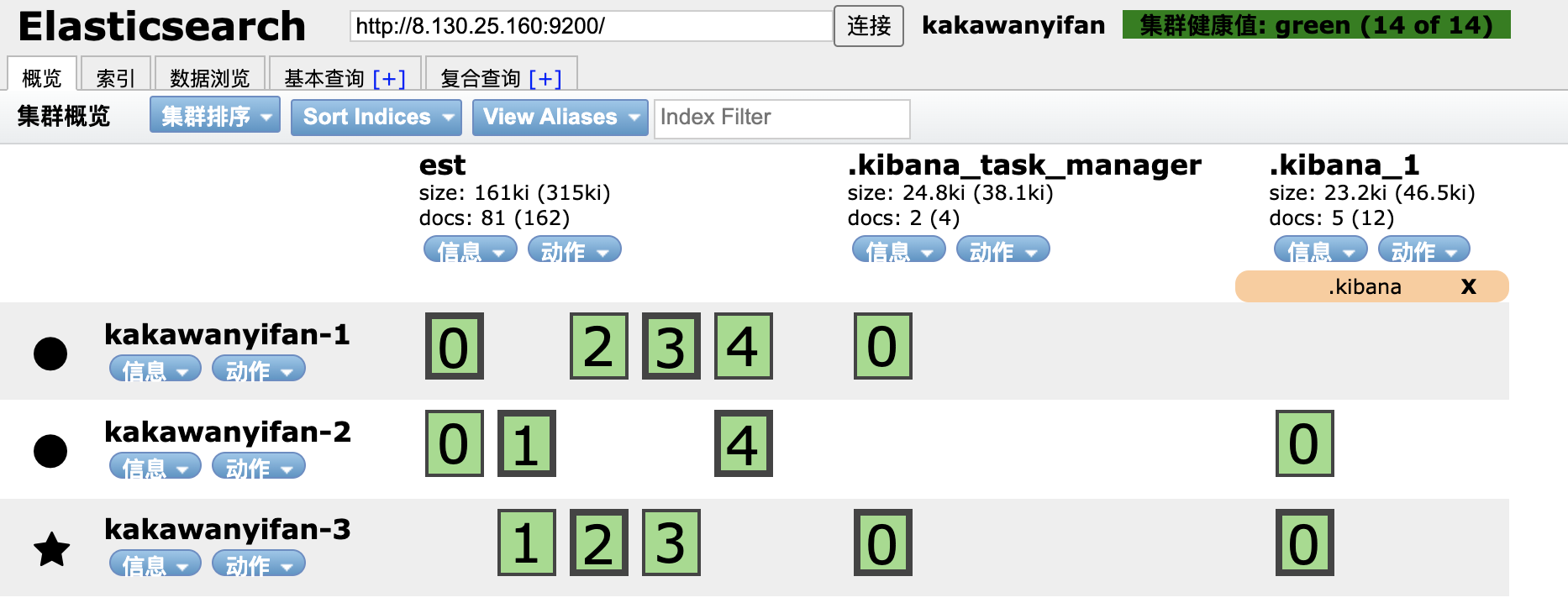
这样印证了我们上文的论述,一个index有多个分片,一个分片有多个备份。
倒排索引
什么是倒排索引
倒排索引,Inverted Index。个人观点,这个翻译的确不妥,很容易让人理解为从A-Z颠倒成Z-A。
更好的翻译,或许是反向索引。
Inverted Index指的是将单词或记录作为索引,将文档ID作为记录,这样可以方便地通过单词或记录查找到其所在的文档。
与此相对的是,Forward Index,正向索引。
比如,现在给你一本《唐诗三百首》,让你找出骆宾王的《咏鹅》。
这个很简单,你翻开目录,找到《咏鹅》的页码,然后翻到对应的页,搞定。
但如果让你找出有"清波"两个字的唐诗,你就需要一篇一篇的遍历。这就是Forward Index。
但,假如说,现在目录是每个词对应的唐诗呢?
你翻开目录,找到"清波",然后目录会告诉你名字为《咏鹅》的这首诗有"清波",这就是Inverted Index。
ElasticSearch中的倒排索引
分词
第一步,分词。
关于分词,我们在下一章《2.基本操作》会进行更多的讨论。
- 不是所有的数据类型都会被分词,只有数据类型为
text的会被分词。 - 不同的分词器,对分词效果差异较大。
单词-文档矩阵
单词-文档矩阵是一种数据结构,如下:
| 单词一 | 单词二 | 单词三 | 单词四 | |
|---|---|---|---|---|
| 文档一 | ✔ | ✔ | ||
| 文档二 | ✔ | |||
| 文档三 | ✔ | |||
| 文档四 | ✔ | ✔ | ✔ |
该数据结构描述了单词和文档两者之间的包含关系。每行代表文档包含了哪些单词,每列代表了某个单词存在于哪些文档。
倒排索引
倒排索引是实现"单词-文档矩阵"这种数据结构的具体方式。
由两部分组成:
- 单词词典
- 倒排列表
单词词典
单词词典的特性:
- 索引的最小单位
- 文档集合中所有单词的集合
- 记录着指向倒排列表的指针
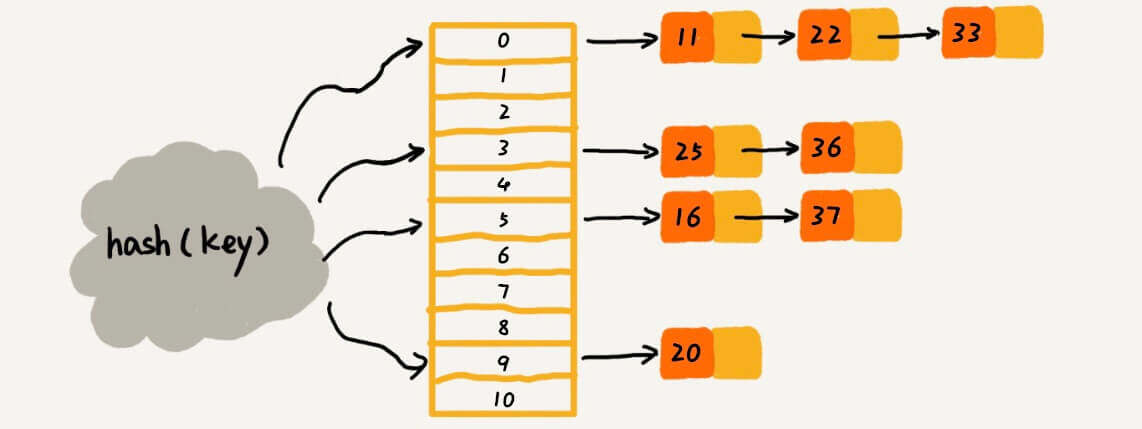
单词词典有两种数据结构实现:Hash表和B+树和。
关于Hash表,我们在《算法入门经典(Java与Python描述):7.哈希表》中有过讨论。结构如图:
关于B+树,我们在《算法入门经典(Java与Python描述):8.二叉树》中有过讨论。结构如图:
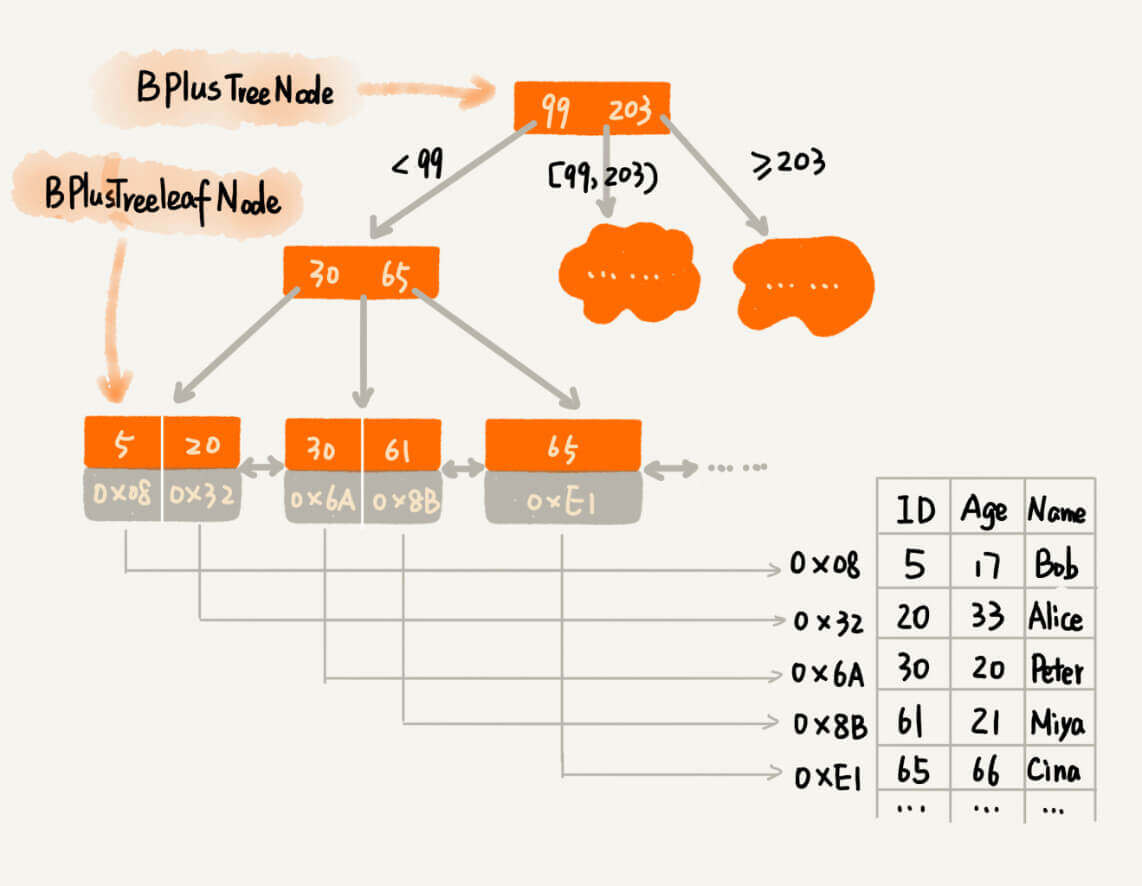
特点有:
- 一个节点可以存储两个值。
用以降低树的高度。 - 叶子节点通过指针串成了一个链表,而且是有序链表。
从而解决了区间查找时候的"回旋问题"。 - 非叶子节点只存储key,不存储具体内容。
具体内容通过叶子节点中的一个指针指向。
倒排列表
倒排列表特性:
- 记录出现过某个单词的文档列表
- 记录单词在所有文档中的出现次数和偏移位置
倒排列表元素数据结构:(DocID;TF;<POS>)
DocID:出现某单词的文档IDTF(Term Frequency):单词在文档中出现的次数<POS>:单词在文档中的位置
例子
例如,假设存在五份文档如下:
| 文档ID | 内容 |
|---|---|
| 1 | 32岁的亨利就在那里,深情的目光望过去都是自己22岁的影子。 |
| 2 | 33岁的亨利就在那里,深情的目光望去依稀浮现自己25岁的模样。 |
| 3 | 35岁的亨利就在那里,深情的目光望去勾勒出自己29岁的动人画面。 |
| 4 | 33岁的亨利就在那里,深情的目光望去依稀浮现自己25岁的模样。 |
| 5 | 37岁的亨利就在那里,深情的目光望过去试图回到原点,那个出发的站台记起自己背起行囊时,那17岁的样子。 |
且,我们假设深情的目光被分为了一个词,岁也被分为了一个词。
则有倒排索引如下:
| 单词 | TF | 倒排列表 |
|---|---|---|
| 深情的目光 | 5 | (1;1;<12>),(2;1;<12>),(3;1;<12>),(4;1;<12>),(5;1;<12>) |
| 岁 | 10 | (1;1;<2>),(1;1;<26>),(2;1;<2>),(2;1;<27>),(3;1;<2>),(3;1;<26>),(4;1;<2>),(4;1;<27>),(5;1;<2>),(5;1;<47>) |
| 略 | 略 | 略 |
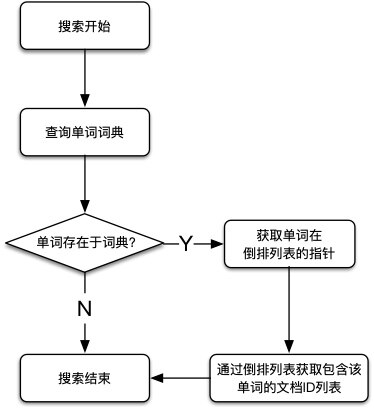
搜索过程
最后,搜索过程,如图所示: