/** * A callback interface that the user can implement to allow code to execute when the request is complete. This callback * will generally execute in the background I/O thread so it should be fast. */ publicinterfaceCallback{
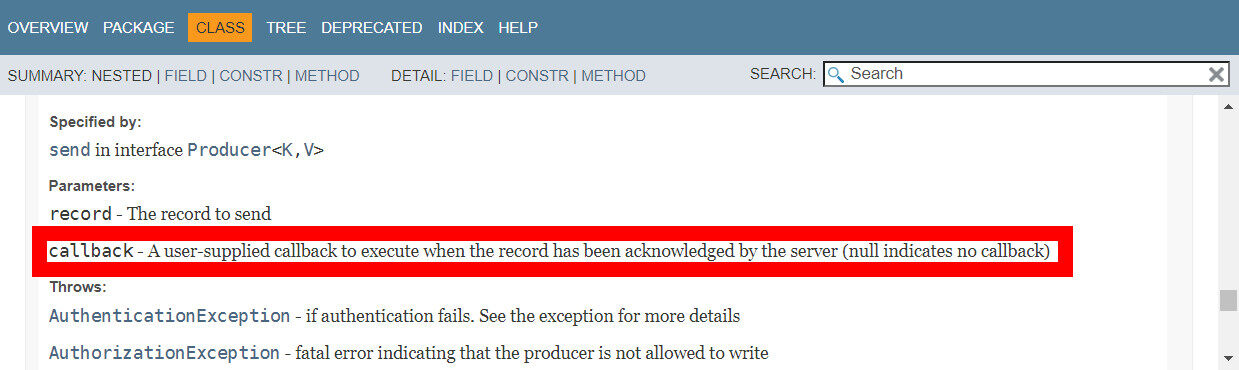
/** * A callback method the user can implement to provide asynchronous handling of request completion. This method will * be called when the record sent to the server has been acknowledged. When exception is not null in the callback, * metadata will contain the special -1 value for all fields. If topicPartition cannot be * choosen, a -1 value will be assigned. * * @param metadata The metadata for the record that was sent (i.e. the partition and offset). An empty metadata * with -1 value for all fields will be returned if an error occurred. * @param exception The exception thrown during processing of this record. Null if no error occurred. * Possible thrown exceptions include: * * Non-Retriable exceptions (fatal, the message will never be sent): * * InvalidTopicException * OffsetMetadataTooLargeException * RecordBatchTooLargeException * RecordTooLargeException * UnknownServerException * UnknownProducerIdException * InvalidProducerEpochException * * Retriable exceptions (transient, may be covered by increasing #.retries): * * CorruptRecordException * InvalidMetadataException * NotEnoughReplicasAfterAppendException * NotEnoughReplicasException * OffsetOutOfRangeException * TimeoutException * UnknownTopicOrPartitionException */ voidonCompletion(RecordMetadata metadata, Exception exception); }
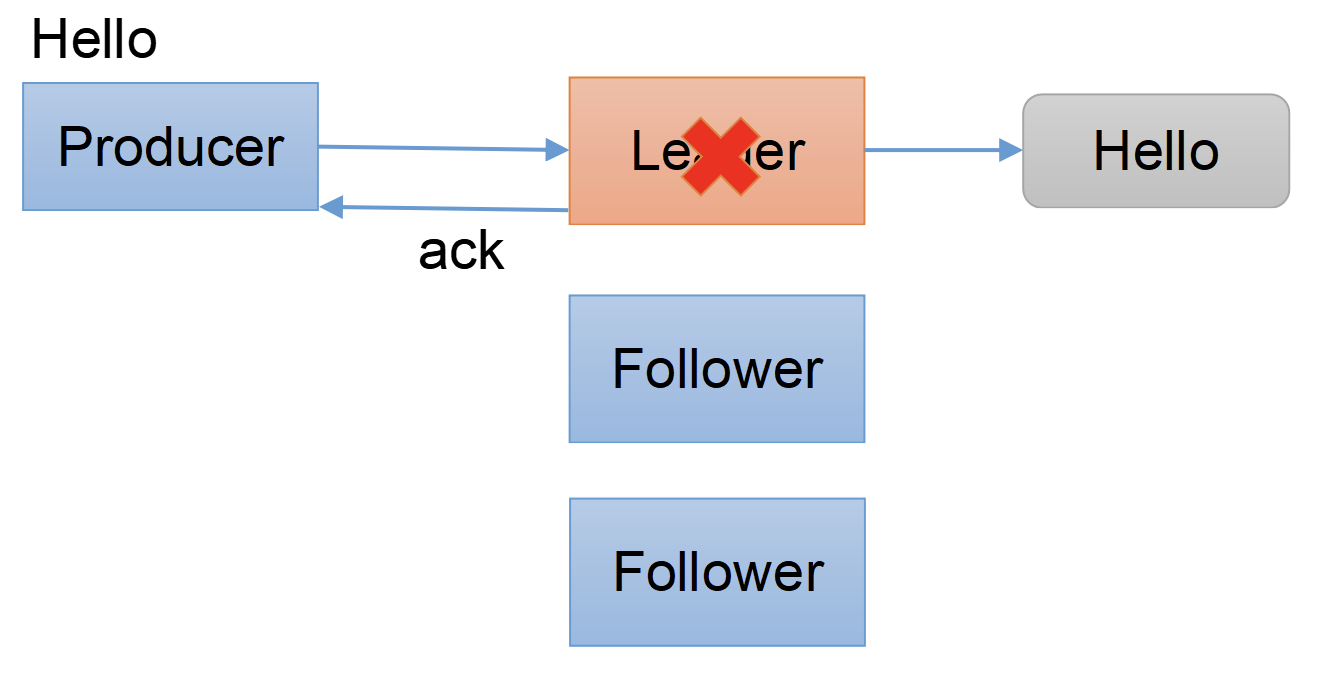
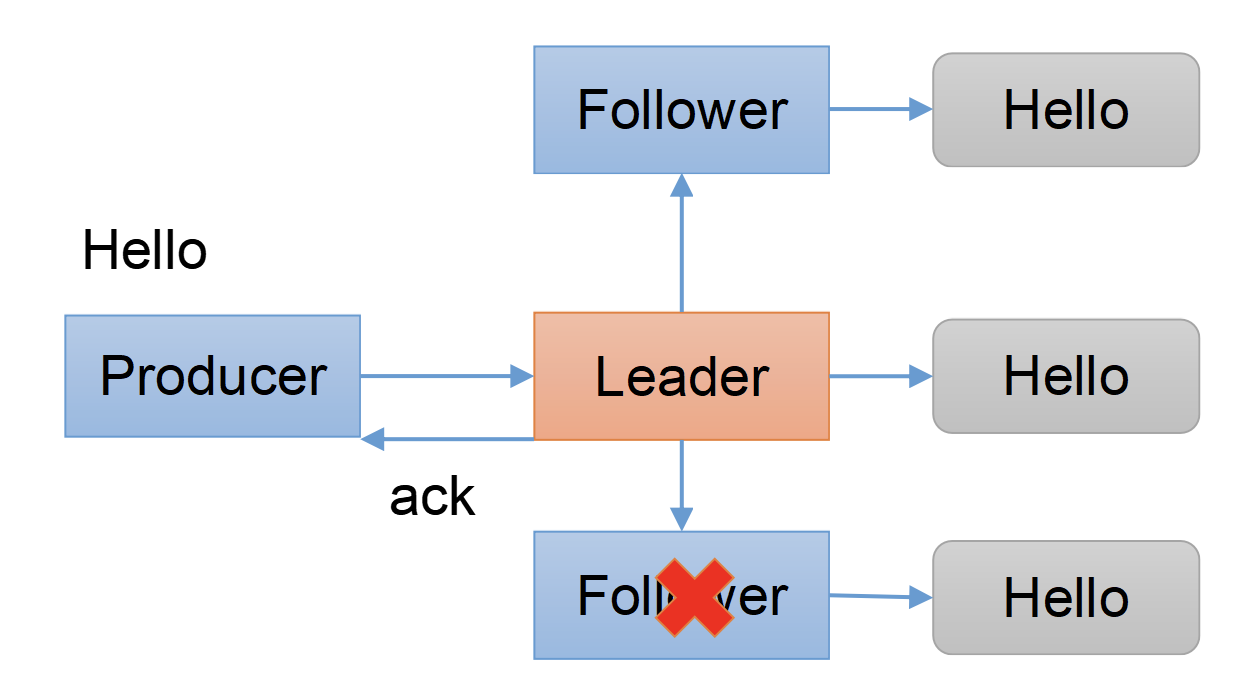
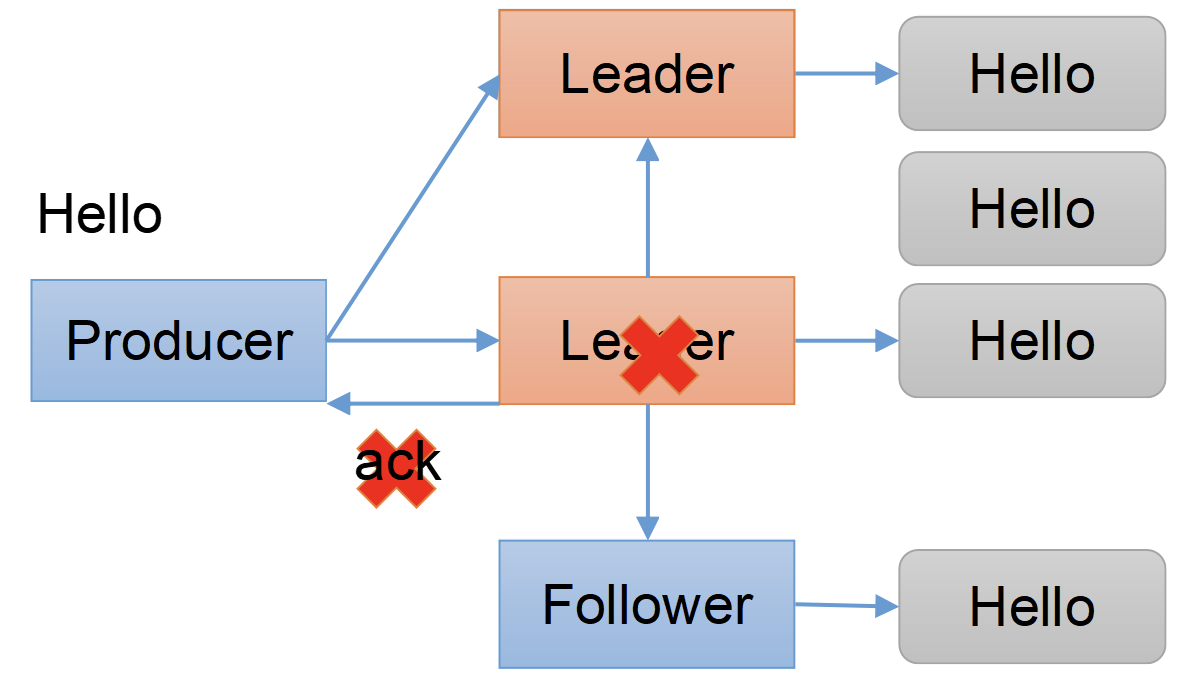
This method will be called when the record sent to the server has been acknowledged.
@Override public Future<RecordMetadata> send(ProducerRecord<K, V> record){ return send(record, null); }
再点进send方法:
1 2 3 4 5 6
@Override public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback){ // intercept the record, which can be potentially modified; this method does not throw exceptions ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); return doSend(interceptedRecord, callback); }
/** * Implementation of asynchronously send a record to a topic. */ private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback){
【部分代码略】
try { 【部分代码略】
byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { thrownew SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer", cce); }
【部分代码略】
// Try to calculate partition, but note that after this call it can be RecordMetadata.UNKNOWN_PARTITION, // which means that the RecordAccumulator would pick a partition using built-in logic (which may // take into account broker load, the amount of data produced to each partition, etc.). int partition = partition(record, serializedKey, serializedValue, cluster); 【部分代码略】
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster); assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION; if (result.abortForNewBatch) { int prevPartition = partition; onNewBatch(record.topic(), cluster, prevPartition); partition = partition(record, serializedKey, serializedValue, cluster); if (log.isTraceEnabled()) { log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition); } result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster); } 【部分代码略】
/** * Convert {@code data} into a byte array. * * @param topic topic associated with data * @param data typed data * @return serialized bytes */ byte[] serialize(String topic, T data);
我们以其实现类StringSerializer的serialize方法为例。
1 2 3 4 5 6 7 8 9 10 11
@Override publicbyte[] serialize(String topic, String data) { try { if (data == null) returnnull; else return data.getBytes(encoding); } catch (UnsupportedEncodingException e) { thrownew SerializationException("Error when serializing string to byte[] due to unsupported encoding " + encoding); } }
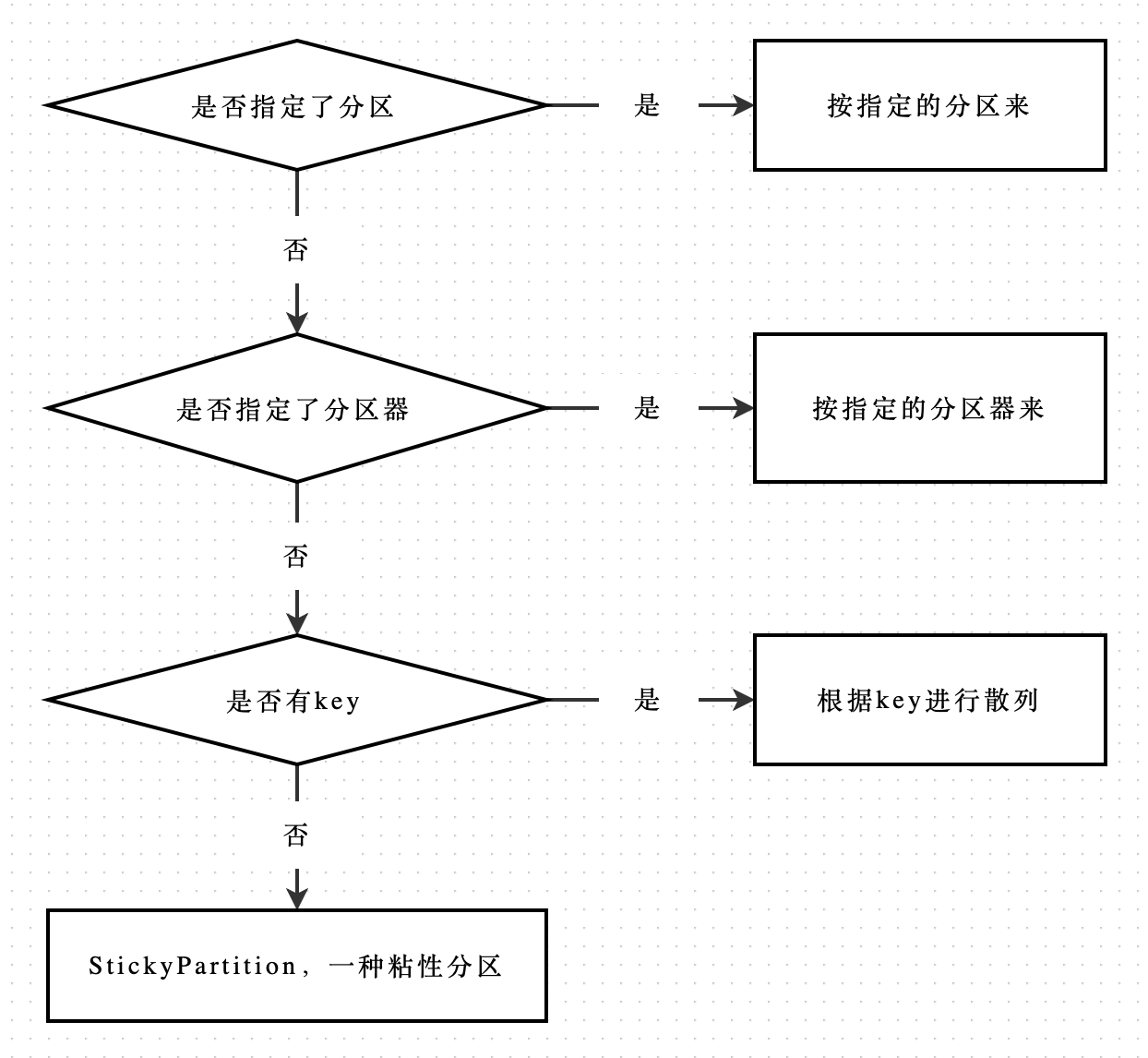
/** * computes partition for given record. * if the record has partition returns the value otherwise * if custom partitioner is specified, call it to compute partition * otherwise try to calculate partition based on key. * If there is no key or key should be ignored return * RecordMetadata.UNKNOWN_PARTITION to indicate any partition * can be used (the partition is then calculated by built-in * partitioning logic). */ privateintpartition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster){ if (record.partition() != null) return record.partition();
if (partitioner != null) { int customPartition = partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); if (customPartition < 0) { thrownew IllegalArgumentException(String.format( "The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition)); } return customPartition; }
if (serializedKey != null && !partitionerIgnoreKeys) { // hash the keyBytes to choose a partition return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size()); } else { return RecordMetadata.UNKNOWN_PARTITION; } }
publicProducerRecord(String topic, Integer partition, K key, V value){ this(topic, partition, (Long)null, key, value, (Iterable)null); }
BuiltInPartitioner.partitionForKey
点进BuiltInPartitioner.partitionForKey,是一个散列函数。
示例代码:
1 2 3 4 5 6
/* * Default hashing function to choose a partition from the serialized key bytes */ publicstaticintpartitionForKey(finalbyte[] serializedKey, finalint numPartitions){ return Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions; }
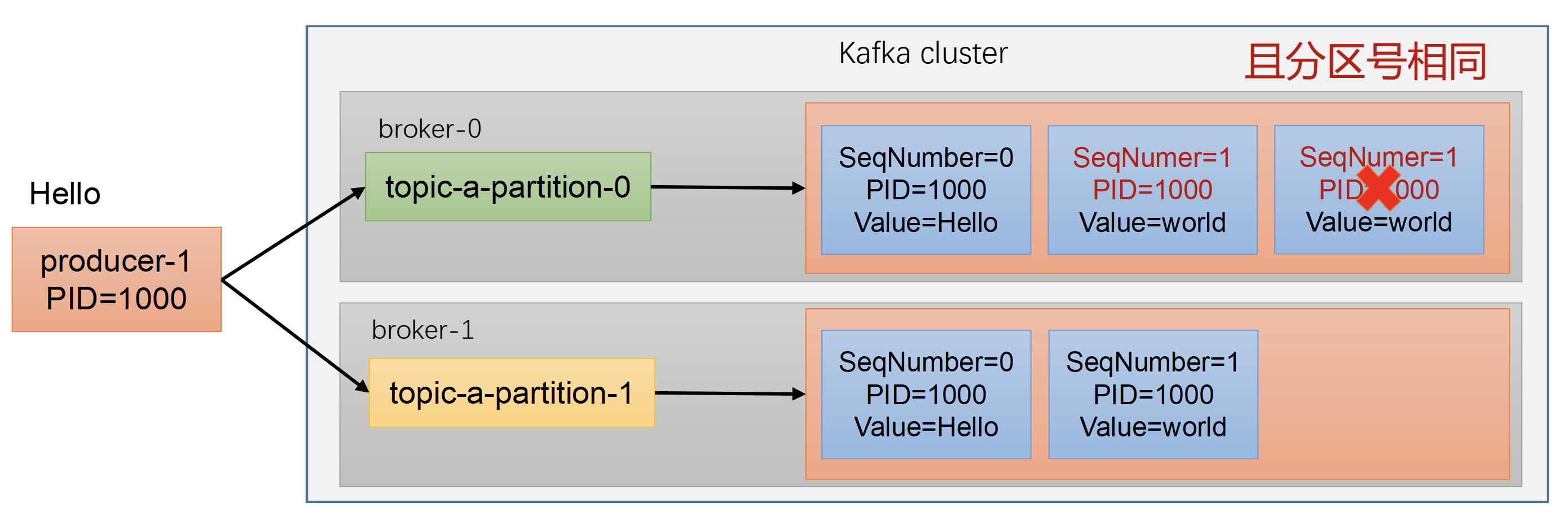
public RecordAppendResult append(String topic, int partition, long timestamp, byte[] key, byte[] value, Header[] headers, AppendCallbacks callbacks, long maxTimeToBlock, boolean abortOnNewBatch, long nowMs, Cluster cluster)throws InterruptedException { TopicInfo topicInfo = topicInfoMap.computeIfAbsent(topic, k -> new TopicInfo(logContext, k, batchSize));
【部分代码略】 try { // Loop to retry in case we encounter partitioner's race conditions. while (true) { // If the message doesn't have any partition affinity, so we pick a partition based on the broker // availability and performance. Note, that here we peek current partition before we hold the // deque lock, so we'll need to make sure that it's not changed while we were waiting for the // deque lock. final BuiltInPartitioner.StickyPartitionInfo partitionInfo; finalint effectivePartition; if (partition == RecordMetadata.UNKNOWN_PARTITION) { partitionInfo = topicInfo.builtInPartitioner.peekCurrentPartitionInfo(cluster); effectivePartition = partitionInfo.partition(); } else { partitionInfo = null; effectivePartition = partition; } // Now that we know the effective partition, let the caller know. setPartition(callbacks, effectivePartition); 【部分代码略】 } } finally { 【部分代码略】 } }
StickyPartitionInfo peekCurrentPartitionInfo(Cluster cluster){ StickyPartitionInfo partitionInfo = stickyPartitionInfo.get(); if (partitionInfo != null) return partitionInfo; // We're the first to create it. partitionInfo = new StickyPartitionInfo(nextPartition(cluster)); if (stickyPartitionInfo.compareAndSet(null, partitionInfo)) return partitionInfo; // Someone has raced us. return stickyPartitionInfo.get(); }