###################################### # multi zookeeper & kafka cluster list # Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead ###################################### efak.zk.cluster.alias=cluster1,cluster2 cluster1.zk.list=tdn1:2181,tdn2:2181,tdn3:2181 cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
[2023-03-07 16:42:15] INFO: Starting EFAK( Eagle For Apache Kafka ) environment check ... [2023-03-07 16:42:15] Error: The KE_HOME environment variable is not defined correctly. [2023-03-07 16:42:15] Error: This environment variable is needed to run this program.
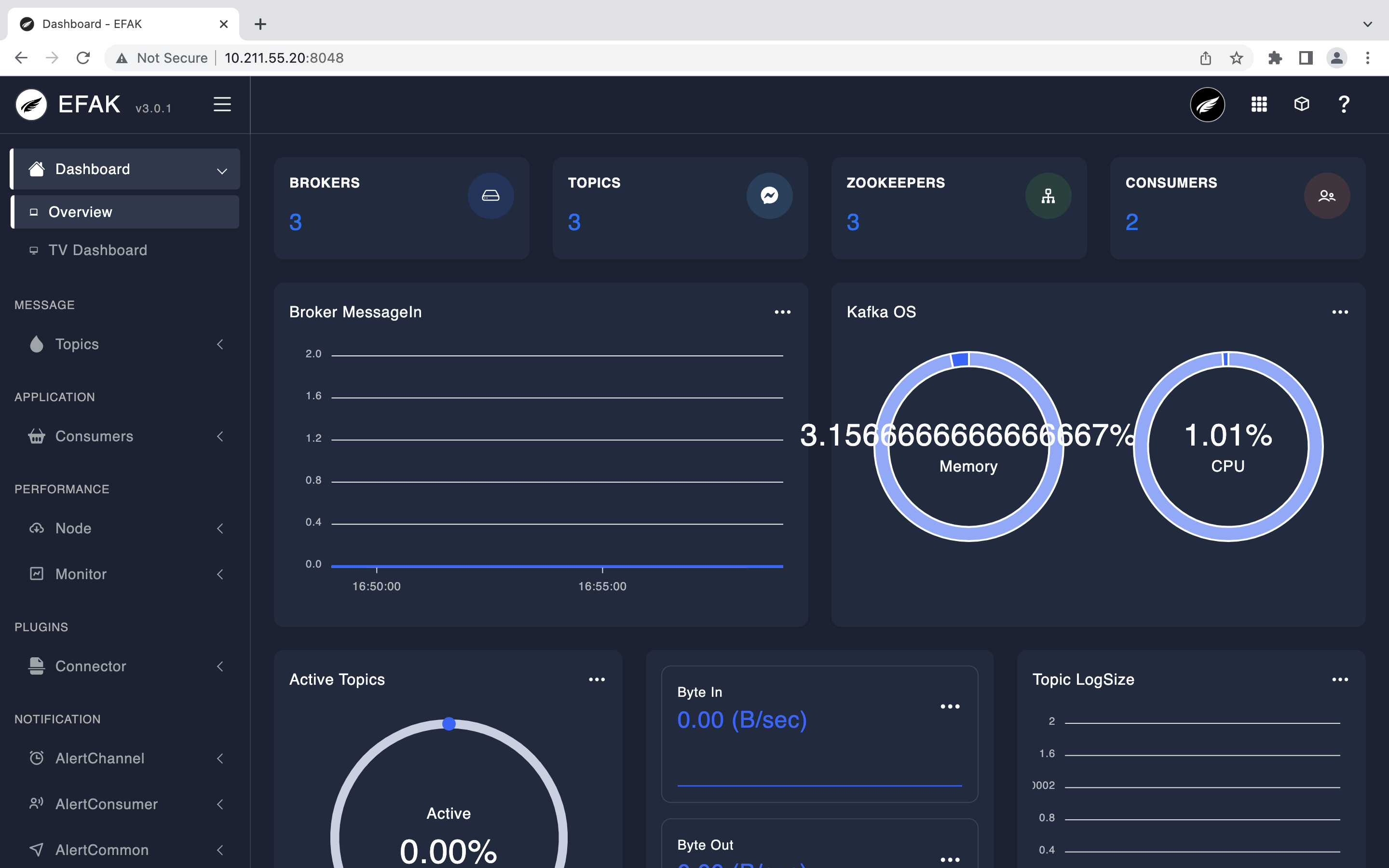
Version v3.0.1 -- Copyright 2016-2022 ******************************************************************* * EFAK Service has started success. * Welcome, Now you can visit 'http://10.211.55.20:8048' * Account:admin ,Password:123456 ******************************************************************* * <Usage> ke.sh [start|status|stop|restart|stats] </Usage> * <Usage> https://www.kafka-eagle.org/ </Usage> *******************************************************************
需要先启动Zookeeper和Kafka。
Welcome, Now you can visit 'http://10.211.55.20:8048',即访问地址。
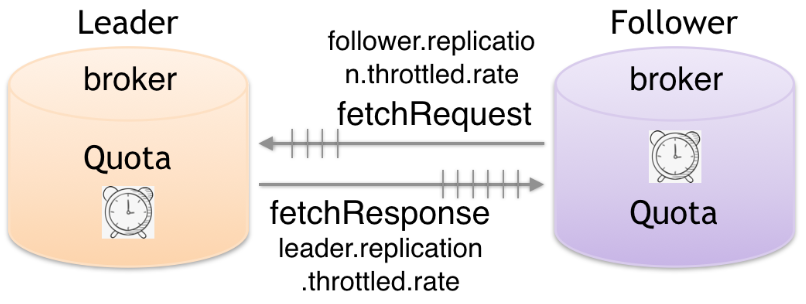
--add-config <String> Key Value pairs of configs to add. Square brackets can be used to group values which contain commas: 'k1=v1, k2=[v1,v2,v2],k3=v3'. The following is a list of valid configurations: For entity-type 'topics': 【部分运行结果略】 follower.replication.throttled.replicas leader.replication.throttled.replicas
【部分运行结果略】 For entity-type 'brokers': 【部分运行结果略】 follower.replication.throttled.rate leader.replication.throttled.rate
【部分运行结果略】
For entity-type 'users': 【部分运行结果略】 consumer_byte_rate producer_byte_rate 【部分运行结果略】 For entity-type 'clients':
【部分运行结果略】 consumer_byte_rate producer_byte_rate
【部分运行结果略】 For entity-type 'ips': 【部分运行结果略】
--add-config-file <String> Path to a properties file with configs to add. See add-config for a list of valid configurations. --all List all configs for the given topic, broker, or broker-logger entity (includes static configuration when the entity type is brokers) --alter Alter the configuration for the entity. --bootstrap-server <String: server to The Kafka server to connect to. This connect to> is required for describing and altering broker configs. --broker <String> The broker's ID. --broker-defaults The config defaults for all brokers. --broker-logger <String> The broker's ID for its logger config. --client <String> The client's ID. --client-defaults The config defaults for all clients. --command-config <String: command Property file containing configs to be config property file> passed to Admin Client. This is used only with --bootstrap-server option for describing and altering broker configs. --delete-config <String> config keys to remove 'k1,k2' --describe List configs for the given entity. --entity-default Default entity name for clients/users/brokers/ips (applies to corresponding entity type in command line) --entity-name <String> Name of entity (topic name/client id/user principal name/broker id/ip) --entity-type <String> Type of entity (topics/clients/users/brokers/broker- loggers/ips) --force Suppress console prompts --help Print usage information. --ip <String> The IP address. --ip-defaults The config defaults for all IPs. --topic <String> The topic's name. --user <String> The user's principal name. --user-defaults The config defaults for all users. --version Display Kafka version. --zk-tls-config-file <String: Identifies the file where ZooKeeper ZooKeeper TLS configuration> client TLS connectivity properties are defined. Any properties other than zookeeper.clientCnxnSocket, zookeeper.ssl.cipher.suites, zookeeper.ssl.client.enable, zookeeper.ssl.crl.enable, zookeeper. ssl.enabled.protocols, zookeeper.ssl. endpoint.identification.algorithm, zookeeper.ssl.keystore.location, zookeeper.ssl.keystore.password, zookeeper.ssl.keystore.type, zookeeper.ssl.ocsp.enable, zookeeper. ssl.protocol, zookeeper.ssl. truststore.location, zookeeper.ssl. truststore.password, zookeeper.ssl. truststore.type are ignored. --zookeeper <String: urls> DEPRECATED. The connection string for the zookeeper connection in the form host:port. Multiple URLS can be given to allow fail-over. Required when configuring SCRAM credentials for users or dynamic broker configs when the relevant broker(s) are down. Not allowed otherwise.
This tool is used to verify the producer performance.
optional arguments: -h, --help show this help message and exit --topic TOPIC produce messages to this topic --num-records NUM-RECORDS number of messages to produce --payload-delimiter PAYLOAD-DELIMITER provides delimiter to be used when --payload-file is provided. Defaults to new line. Note that this parameter will be ignored if --payload-file is not provided. (default: \n) --throughput THROUGHPUT throttle maximum message throughput to *approximately* THROUGHPUT messages/sec. Set this to -1 to disable throttling. --producer-props PROP-NAME=PROP-VALUE [PROP-NAME=PROP-VALUE ...] kafka producer related configuration properties like bootstrap.servers,client.id etc. These configs take precedence over those passed via --producer.config. --producer.config CONFIG-FILE producer config properties file. --print-metrics print out metrics at the end of the test. (default: false) --transactional-id TRANSACTIONAL-ID The transactionalId to use if transaction-duration-ms is > 0. Useful when testing the performance of concurrent transactions. (default: performance-producer-default-transactional- id) --transaction-duration-ms TRANSACTION-DURATION The max age of each transaction. The commitTransaction will be called after this time has elapsed. Transactions are only enabled if this value is positive. (default: 0)
either --record-size or --payload-file must be specified but not both.
--record-size RECORD-SIZE message size in bytes. Note that you must provide exactly one of --record-size or --payload-file. --payload-file PAYLOAD-FILE file to read the message payloads from. This works only for UTF-8 encoded text files. Payloads will be read from this file and a payload will be randomly selected when sending messages. Note that you must provide exactly one of --record-size or --payload-file.
41266 records sent, 8235.1 records/sec (8.04 MB/sec), 789.0 ms avg latency, 1091.0 ms max latency. 57287 records sent, 11450.5 records/sec (11.18 MB/sec), 402.0 ms avg latency, 1084.0 ms max latency. 51287 records sent, 10257.4 records/sec (10.02 MB/sec), 50.7 ms avg latency, 222.0 ms max latency. 40944 records sent, 8188.8 records/sec (8.00 MB/sec), 318.7 ms avg latency, 966.0 ms max latency. 51930 records sent, 10383.9 records/sec (10.14 MB/sec), 1149.5 ms avg latency, 1476.0 ms max latency. 57583 records sent, 11512.0 records/sec (11.24 MB/sec), 181.0 ms avg latency, 770.0 ms max latency. 47850 records sent, 9568.1 records/sec (9.34 MB/sec), 35.2 ms avg latency, 219.0 ms max latency. 48015 records sent, 9603.0 records/sec (9.38 MB/sec), 372.4 ms avg latency, 600.0 ms max latency. 50303 records sent, 10052.6 records/sec (9.82 MB/sec), 481.5 ms avg latency, 1015.0 ms max latency. 52117 records sent, 10421.3 records/sec (10.18 MB/sec), 273.3 ms avg latency, 647.0 ms max latency. 47205 records sent, 9435.3 records/sec (9.21 MB/sec), 355.9 ms avg latency, 543.0 ms max latency. 53550 records sent, 10707.9 records/sec (10.46 MB/sec), 229.9 ms avg latency, 483.0 ms max latency. 51242 records sent, 10248.4 records/sec (10.01 MB/sec), 29.5 ms avg latency, 133.0 ms max latency. 49613 records sent, 9922.6 records/sec (9.69 MB/sec), 39.8 ms avg latency, 138.0 ms max latency. 49287 records sent, 9857.4 records/sec (9.63 MB/sec), 102.0 ms avg latency, 317.0 ms max latency. 41748 records sent, 8349.6 records/sec (8.15 MB/sec), 292.2 ms avg latency, 956.0 ms max latency. 44730 records sent, 8946.0 records/sec (8.74 MB/sec), 1363.8 ms avg latency, 1542.0 ms max latency. 51390 records sent, 10278.0 records/sec (10.04 MB/sec), 1771.4 ms avg latency, 2096.0 ms max latency. 63375 records sent, 12675.0 records/sec (12.38 MB/sec), 600.1 ms avg latency, 1485.0 ms max latency. 47456 records sent, 9491.2 records/sec (9.27 MB/sec), 66.7 ms avg latency, 273.0 ms max latency. 1000000 records sent, 9964.923469 records/sec (9.73 MB/sec), 442.95 ms avg latency, 2096.00 ms max latency, 227 ms 50th, 1505 ms 95th, 1927 ms 99th, 2058 ms 99.9th.
Missing required option(s) [bootstrap-server] Option Description ------ ----------- --bootstrap-server <String: server to REQUIRED unless --broker-list connect to> (deprecated) is specified. The server (s) to connect to. --broker-list <String: broker-list> DEPRECATED, use --bootstrap-server instead; ignored if --bootstrap- server is specified. The broker list string in the form HOST1:PORT1, HOST2:PORT2. --consumer.config <String: config file> Consumer config properties file. --date-format <String: date format> The date format to use for formatting the time field. See java.text. SimpleDateFormat for options. (default: yyyy-MM-dd HH:mm:ss:SSS) --fetch-size <Integer: size> The amount of data to fetch in a single request. (default: 1048576) --from-latest If the consumer does not already have an established offset to consume from, start with the latest message present in the log rather than the earliest message. --group <String: gid> The group id to consume on. (default: perf-consumer-71970) --help Print usage information. --hide-header If set, skips printing the header for the stats --messages <Long: count> REQUIRED: The number of messages to send or consume --num-fetch-threads <Integer: count> DEPRECATED AND IGNORED: Number of fetcher threads. (default: 1) --print-metrics Print out the metrics. --reporting-interval <Integer: Interval in milliseconds at which to interval_ms> print progress info. (default: 5000) --show-detailed-stats If set, stats are reported for each reporting interval as configured by reporting-interval --socket-buffer-size <Integer: size> The size of the tcp RECV size. (default: 2097152) --threads <Integer: count> DEPRECATED AND IGNORED: Number of processing threads. (default: 10) --timeout [Long: milliseconds] The maximum allowed time in milliseconds between returned records. (default: 10000) --topic <String: topic> REQUIRED: The topic to consume from. --version Display Kafka version.
目前Kafka-Producer是异步发送消息的,也就是说如果我们调用的是producer.send(msg)这个API,会立即返回,但我们不能认为消息发送已成功完成。
这种发送方式有个有趣的名字,叫"fire and forget",翻译一下就是"发射后不管"。如果出现消息丢失,我们是无法知晓的。这个发送方式挺不靠谱,非常不建议使用。