JMeter,Apache基金会的一款测试工具,主要用于接口测试。
安装
Java环境
JMeter需要运行在Java环境上。
我们更多的时候,是在Windows或者MacOS上运行JMeter,关于Java环境的安装,可以参考《基于Java的后端开发入门:1.基础语法》的"环境与工具准备"部分,有讨论Windows和MacOS上怎么安装Java。
至于在Linux上安装Java,可以参考《ElasticSearch实战入门(6.X):1.工具、概念、集群和倒排索引》的"准备JDK"部分。
下载
我们通过官网下载JMeter,地址:https://jmeter.apache.org/
下载之后,直接进行解压即可,这是一款"绿色版"软件。
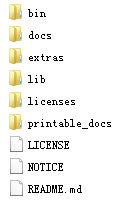
解压后内容如下:
修改字符集
首先,我们需要修改JMeter的默认字符集,否则可能会出现中文乱码。
打开bin目录下的jmeter.properties,找到如下部分
1 | # The encoding to be used if none is provided (default ISO-8859-1) |
修改字符集为UTF-8
1 | =UTF-8 |
启动
在bin目录下,有三个启动文件。分别是:
ApacheJMeter.jar:图形化启动jmeter.bat:Windows下的命令行启动jmeter.sh:Linux下的命令行启动
图形化启动后,界面如下:
快速开始
添加线程组
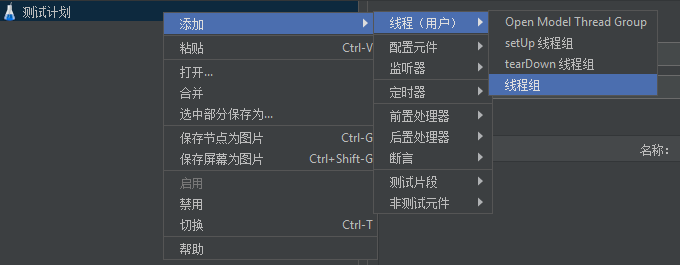
右键点击测试计划,依次选择线程、添加线程组。
HTTP请求
右键点击线程组,依次选择取样器、HTTP请求。

例如,对于GET请求"http://127.0.0.1:8080/ssm/books/1",填写如下:

查看结果树
右键点击测试计划,依次选择添加监听器、查看结果树。

运行,查看结果
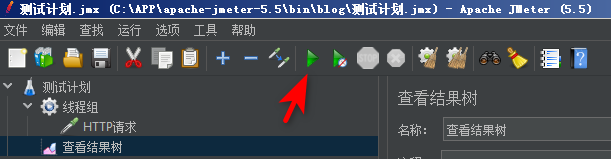
我们点击箭头所示的地方,运行。
然后点击查看结果树。对于响应结果,如果是JSON格式的话,点击图示的JSON,可以看得更清楚。

对于结果记录,可以通过点击箭头所示的地方,进行清除。
重命名
当然,我们可以对"测试计划"、“线程组”、"HTTP请求"等进行重命名。
线程组
线程
关于什么是线程,可以参考我们在《基于Java的后端开发入门:7.多线程 [1/2]》的"什么是多线程"部分。
在这里,结合Jmeter的实际操作及其应用场景等,更直观的是把线程看成用户。
那么什么是线程组呢?
一个进程中有许多线程,为了方便管理,我们对线程按照性质分组,分组的结果就是线程组。
即,一个进程可以包含多个线程组,一个线程组可以包含多个线程。
并发和顺序
- 并发执行:多个线程同时执行。
- 顺序执行:多个线程顺序执行。
我们创建一个测试计划如下
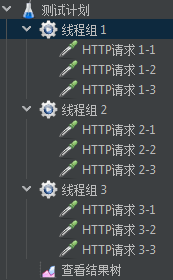
在创建过程中,可以用复制粘贴的方式。需要注意的是,我们需要选中父级进行粘贴。
例如,我们在选中HTTP请求进行复制,需要选中线程组进行粘贴。
然后我们点击执行。
结果如下:

这是并发执行。
同时我们看到,线程组是并发,但是线程组中的每个线程是顺序。
如果我们勾选独立运行每个线程组,则线程组也是顺序了。
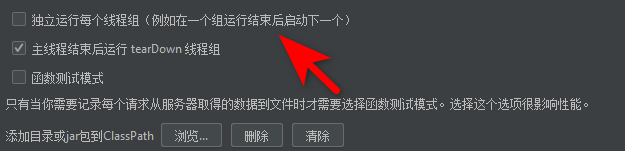
(独立运行线程组的功能,不仅仅是设置线程组顺序执行。)
特殊的线程组
在我们创建线程组的时候,还会发现两个特殊的线程组。

setup线程组,一定会首先执行。teadDown线程组,一定会最后执行。
线程组的设置
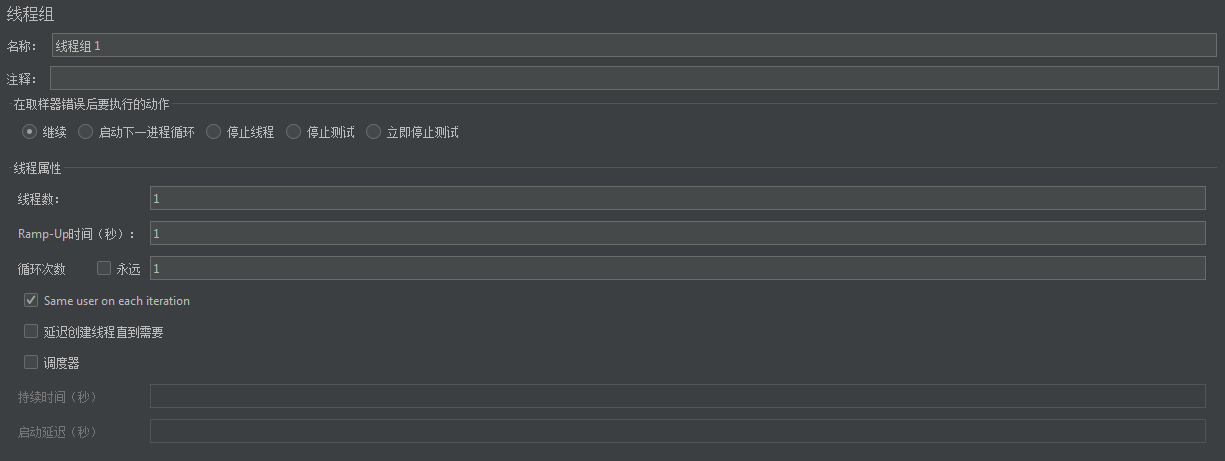
- 线程数:模拟的用户个数。
- Ramp-Up时间:循环在多久完成。
- 循环次数:这个就是循环次数。
如果我们循环次数勾选永远,但是我们只想在一分钟内永远。怎么配置?
我们勾选调度器,并在持续时间处填60。
调度器中,还有一个参数,启动延迟,这个很好理解,我们启动之后,先延迟指定的时间,
HTTP相关
HTTP请求默认值
在上文,我们设置了很多HTTP请求,这些HTTP请求的协议、端口等都是一样的。
我们可以配置默认值,按照如下的方式,打开"HTTP请求默认值"。
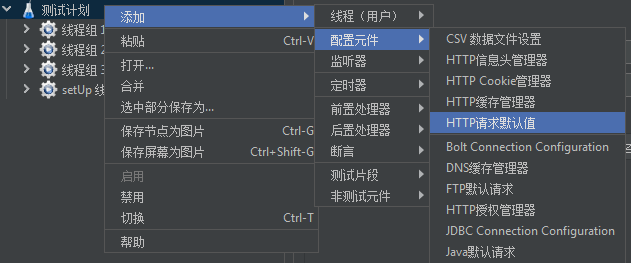
在配置HTTP请求的默认值,如果新建的HTTP请求,有没配置的值,会利用默认值。
HTTP信息头管理器
按照如下的方式,打开HTTP信息头管理器
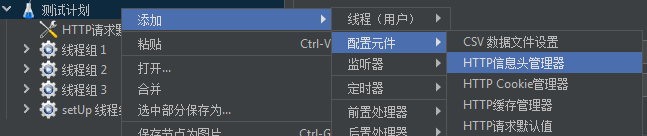
关于HTTP的header的参数,我们不做太多讨论,有部分重要的HTTP的header,可以参考我们在《基于Java的后端开发入门:14.HttpClient》的讨论。
配参数
常见的配参数方式有四种
1、用户定义的变量
2、CSV数据文件设置
3、用户参数
4、函数
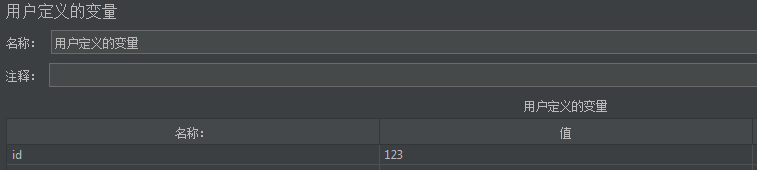
用户定义的变量
配置元件,用户自定义变量。
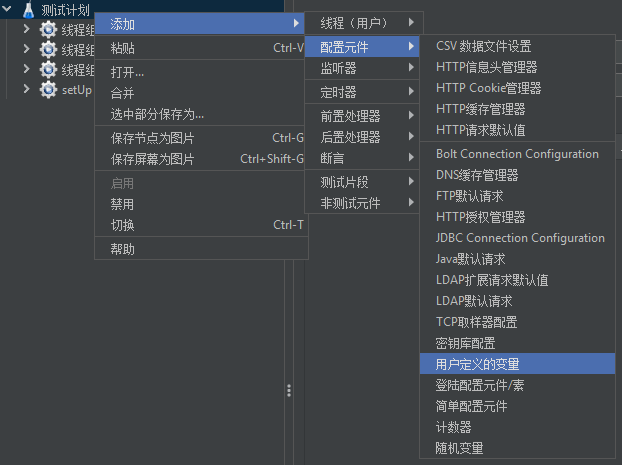
例如,我们配置变量名id,值为123。
然后我们在路径中配置${id}

试一下

CSV数据文件设置
设置方法
配置元件,CSV数据文件设置。
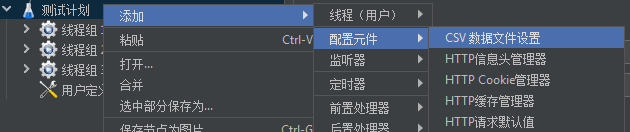
弹出窗体,我们配置变量名为id,如果我们的CSV文件有多列,则配置多个变量名。
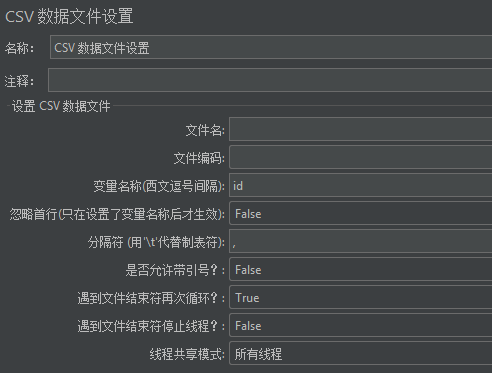
线程共享模式
在上图,我们注意到,还有一个线程共享模式。
假设数据内容为:1,2,3,4,5,6。
所有线程
所有线程组的每个线程每次循环都将读取一条新的数据。
当前线程
线程在每次循环时才读取一条新的数据。
当前线程组
数据读取情况与设置为"所有线程"一致,只是测试计划中有多个线程组时,每个线程组都从数据文件第一条数据开始读取。设置为"所有线程"时,后面线程组是接着前面线程组读取完数据的位置接着往下读取。
用户参数
前置处理器,用户参数:
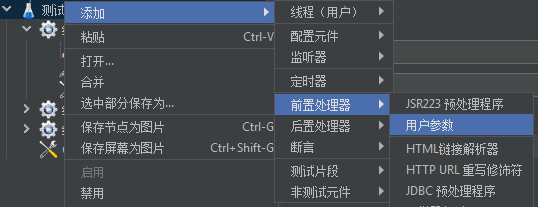
例如,我们设置了3个用户,如下:

当线程组的线程数为2,循环次数为2,则结果是:用户一、用户二、用户一、用户二。
当线程组的线程数为3,循环次数为1。则三个用户都会有。
当线程组的线程数为5,循环次数为1。则:用户一、用户二、用户三、用户一、用户二。
函数
我们以counter函数为例,讨论函数的用法。
函数菜单:

选择函数,配置函数参数,点击生成。

生成的内容,复制粘贴,这样就可以直接调用了。
Jmeter的函数很多,例如:Random,随机数;time,获取当前时间。
断言
断言分很多种,这里我们以响应断言和断言持续时间为例。
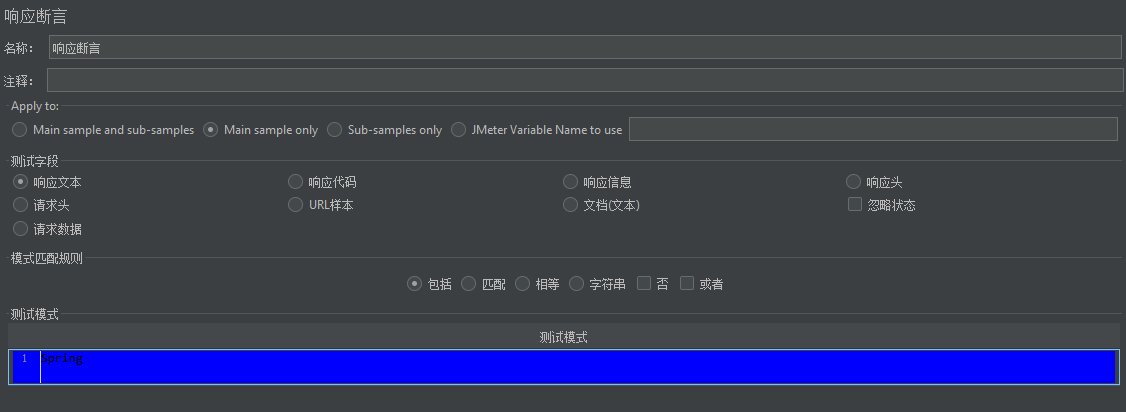
响应断言
断言,响应断言。

“响应文本”,包括,“Spring”。
如果断言为否,我们会看到标红。

此外,还有,响应代码,这种方式即匹配HTTP的状态码。
断言持续时间
断言、断言持续时间。
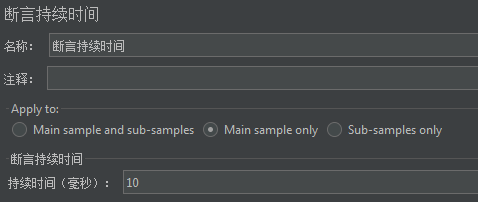
例如,我们设置持续时间为10毫秒。
则,大于10毫秒的会标红。

逻辑控制器
IF控制器
逻辑控制器,IF控制器。

类似于编程语言中的IF,IF为真时需要执行的内容,要在IF控制器的内部。
我们把箭头处的勾选去掉
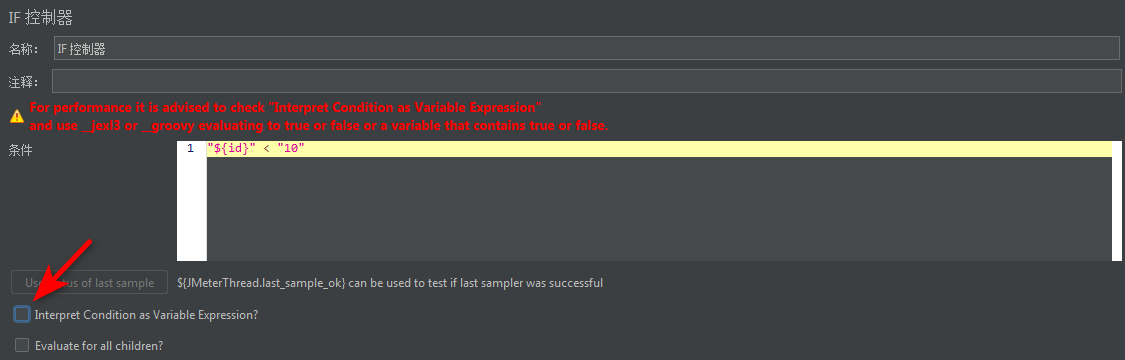
我们填写的逻辑是
1 | "${id}" < "10" |
其中双引号是固定格式,必须这么填。
循环控制器
逻辑控制器,循环控制器。

设置方法也很简单,设置循环次数即可。
那么,这个和线程组的循环有什么区别呢?
例如,我们在线程组中有两个HTTP请求,第一个我们想执行10次,第二个我们只想执行5次。
这时候就不能用线程组的循环了,线程组的循环是全局生效的,得用循环控制器。
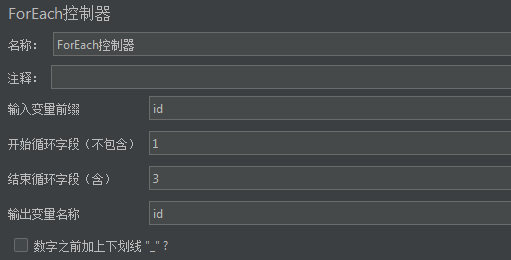
ForEach控制器
逻辑控制器,ForEach控制器。
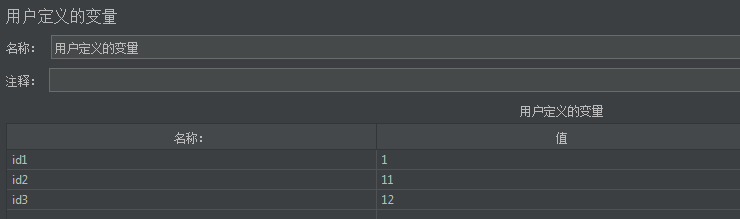
定义用户的变量,如下
ForEach控制器的设置如下
高并发
同步定时器
场景:100位用户同时访问系统,统计高并发情况下平均响应时间以及错误率等。
因为100位用户,所以线程组要配置100个线程。
那么,同时怎么办?
定时器,同步定时器。
因为是100位用户同时,所以"模拟用户组的数量",也填100。
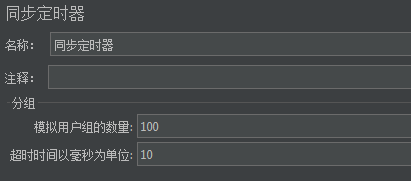
如果我们是100人,每次50次同时,则"默认用户组的数量"填50。
(“模拟用户组的数量”,这个名字让人容易看不懂,其含义实际就是 每组用户数。)
聚合报告
我们还需要统计平均响应时间以及错误率等。这时候不能再用之前的"查看结果树"这个监听器了,要用"聚合报告"。
监听器,聚合报告。
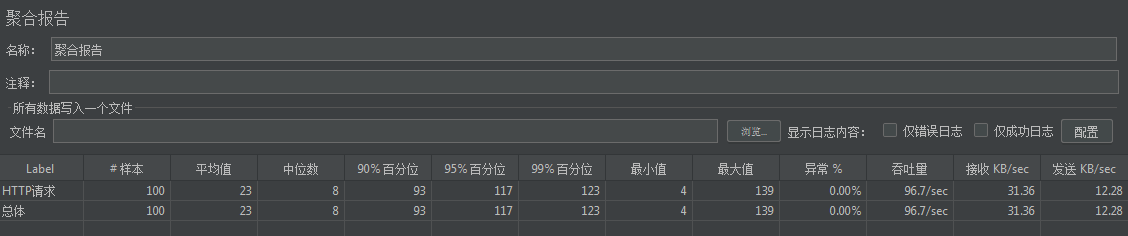
点击运行后,聚合报告内容如下
特别的,我们可以在HTTP请求的名字上加上参数。
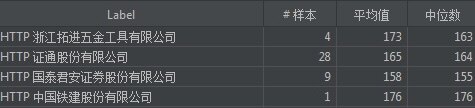
这样,我们更容易看到具体是哪一个参数查询较慢。
高频率
场景:一位用户以20QPS(20次/秒)的频率访问系统,持续15秒,统计服务器的平均响应时间。
高频率,需要用到 常数吞吐量定时器 。
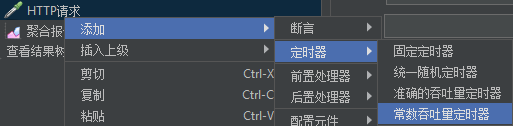
常数吞吐量定时器的设置:

因为我们是每秒20次,那么每分钟就是1200次,即目标吞吐量是1200。
那么,怎么控制15秒呢?
20次每秒,持续15秒,所以总次数是300次。
即在线程组设置循环次数:300。
测试结果,同样需要通过聚合报告看。
弱压力
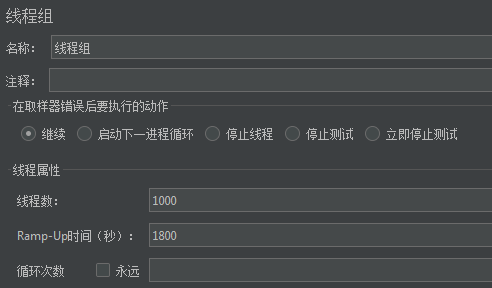
场景:半小时内,1000位用户访问系统。这就是所谓的弱压力测试。
1000个用户,所以线程组的线程数写1000。
那么半个小时怎么设计?线程组的Ramp-Up填1800。
测试数据库
最后一个话题,JMeter还可以直接对数据库进行测试。
加载JDBC驱动
和我们常见的Java程序一样,JMeter也是用JDBC去连接数据库的。
点击浏览,选择数据库的JDBC驱动。
连接数据库
配置元件,JDBC Connection Configuration。
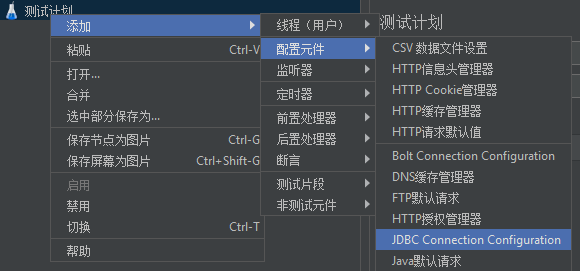
其中,Variable Name for created pool填写我们数据库连接池的名称。
其他的属性,可以参考我们在《基于Java的后端开发入门:10.JDBC》的讨论。

JDBC-Request
取样器,JDBC-Request。
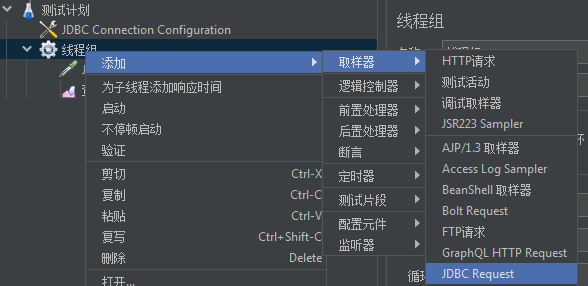
需要注意的是,在JDBC-Request的配置页面,有一个Query Type,我们选择对应的类型。
