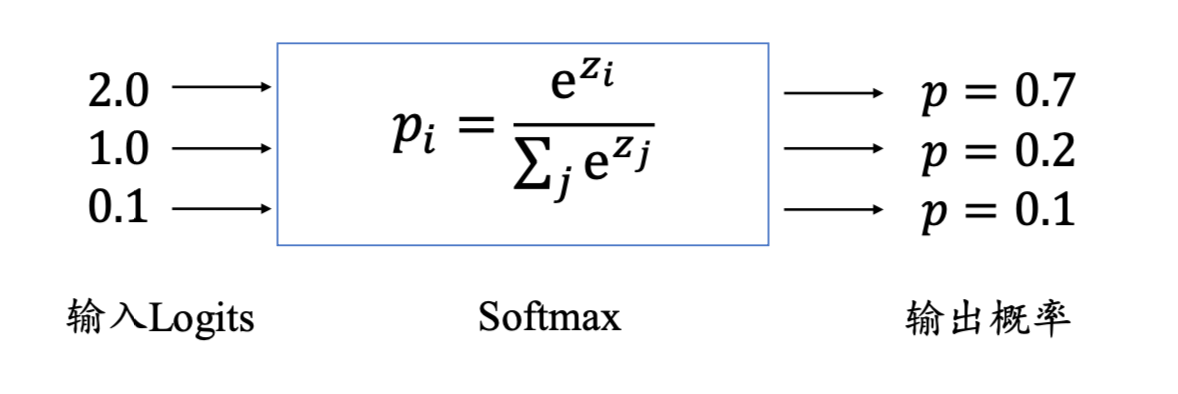逻辑回归虽然被称为回归,但并不是用来处理回归问题。不过既然被称为回归,这里面肯定还是有故事的,这就不得不从逻辑回归和线性回归的关系讲起。
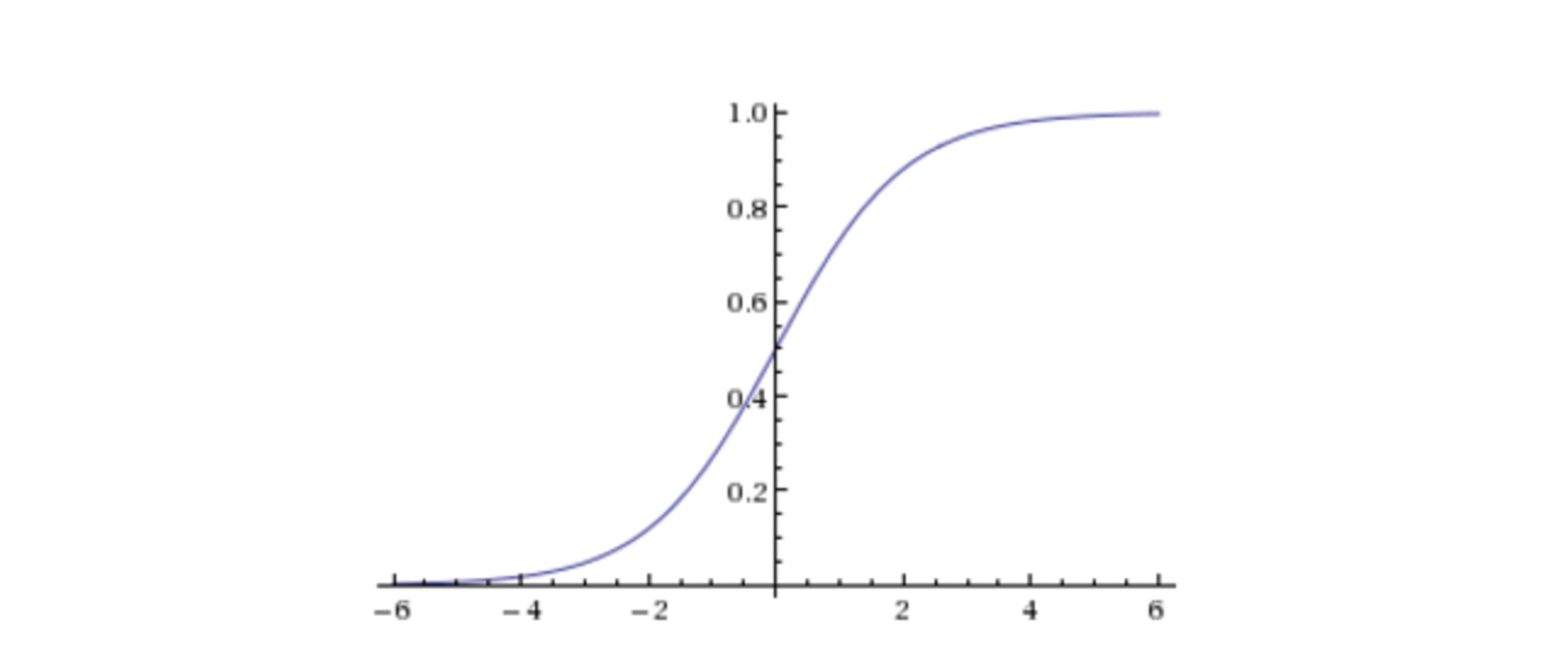
sigmoid函数
sigmoid的函数表达式
s i g m o i d ( x ) = 1 1 + e x sigmoid(x) = \frac{1}{1 + e^x}
s i g m o i d ( x ) = 1 + e x 1
x x x y y y y y y
y = w 0 + w 1 x 1 + w 2 x 2 + ⋅ ⋅ ⋅ + w d x d = w T x \begin{aligned}
y = w_0 + w_1x_1 + w_2x_2 + ··· + w_dx_d = \bold{w}^T \bold{x}
\end{aligned}
y = w 0 + w 1 x 1 + w 2 x 2 + ⋅ ⋅ ⋅ + w d x d = w T x
那么,我们得到整个逻辑回归的形式
l o g i s t i c s ( w ) = 1 1 + e w T x logistics(\bold{w}) = \frac{1}{1 + e^{\bold{w}^T \bold{x}}}
l o g i s t i c s ( w ) = 1 + e w T x 1
即,逻辑回归和线性的关系是:逻辑回归是线性回归再包装了一层。
损失函数
定义
对于单个样本,损失函数
j ( h w ( x ) , y ) = { − log 10 ( h w ( x ) ) if y = 1 , − log 10 ( 1 − h w ( x ) ) if y = 0 j(h_w(x),y) = \Bigg\{\begin{array}{l} -\log_{10} (h_w(x)) & \text{if } y = 1,\\ -\log_{10}(1-h_w(x)) & \text{if } y = 0
\end{array}
j ( h w ( x ) , y ) = { − log 1 0 ( h w ( x ) ) − log 1 0 ( 1 − h w ( x ) ) if y = 1 , if y = 0
其中
h w ( x ) h_w(x) h w ( x )
将所有的样本进行求和,就是完整的损失函数
J ( w ) = ∑ i = 1 m − y i log 10 ( h w ( x ) ) − ( 1 − y i ) log 10 ( 1 − h w ( x ) ) J(\bold{w}) = \sum_{i=1}^m -y_i\log_{10} (h_w(x)) - (1-y_i)\log_{10}(1-h_w(x))
J ( w ) = i = 1 ∑ m − y i log 1 0 ( h w ( x ) ) − ( 1 − y i ) log 1 0 ( 1 − h w ( x ) )
计算 1 0 0 1。0.6 0.1 0.51 0.7。
J ( w ) = ( − 1 ∗ log 10 0.6 − 0 ∗ l o g 10 ( 1 − 0.6 ) ) + ( − 0 ∗ log 10 0.1 − 1 ∗ l o g 10 ( 1 − 0.1 ) ) + ( − 0 ∗ log 10 0.51 − 1 ∗ l o g 10 ( 1 − 0.51 ) ) + ( − 1 ∗ log 10 0.7 − 0 ∗ l o g 10 ( 1 − 0.7 ) ) \begin{aligned}
J(\bold{w}) & = (- 1 * \log_{10}0.6 - 0 * log_{10} (1-0.6) ) \\
& + ( - 0 * \log_{10}0.1 - 1 * log_{10} (1-0.1) ) \\
& + ( - 0 * \log_{10}0.51 - 1 * log_{10} (1-0.51) ) \\
& + ( - 1 * \log_{10}0.7 - 0 * log_{10} (1-0.7) ) \\
\end{aligned}
J ( w ) = ( − 1 ∗ log 1 0 0 . 6 − 0 ∗ l o g 1 0 ( 1 − 0 . 6 ) ) + ( − 0 ∗ log 1 0 0 . 1 − 1 ∗ l o g 1 0 ( 1 − 0 . 1 ) ) + ( − 0 ∗ log 1 0 0 . 5 1 − 1 ∗ l o g 1 0 ( 1 − 0 . 5 1 ) ) + ( − 1 ∗ log 1 0 0 . 7 − 0 ∗ l o g 1 0 ( 1 − 0 . 7 ) )
这个损失函数就是交叉熵损失,在《深度学习初步及其Python实现:2.神经网络基础》 中,我们有关于交叉熵损失更详细的讨论。
优化
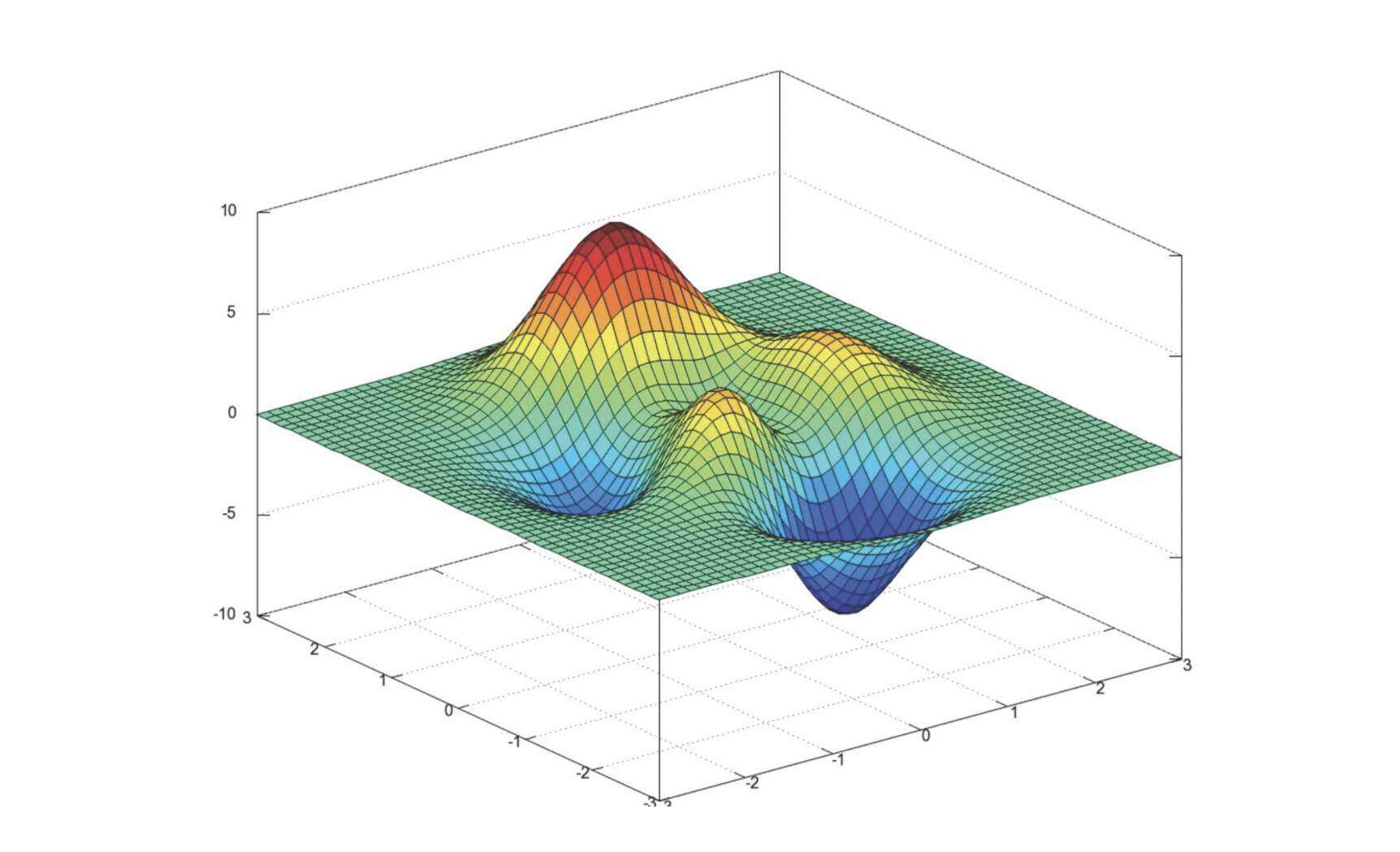
同线性回归的优化,就是寻找一个w \bold{w} w
就像这张图
该问题截至目前,无解。
只有一些尽量改善的方法
多次随机初始化,比较最小值结果
求解过程中,调整学习率
这样虽然找不到全局最优点,但是局部最优点有时候效果也不错。
实现
1 from sklearn.linear_model import LogisticRegression
参数:
penalty:正则化形式,如l2
C:正则化力度
方法:
我们以《充电桩故障分类与检测》为例。
这也是百度曾经举办的一个比赛,但是比赛的数据已经不提供下载了。不过我的GitHub中还有数据。
赛题介绍:https://dianshi.bce.baidu.com/competition/19/question https://github.com/KakaWanYifan/BaiduPower
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportimport pandas as pddata = pd.read_csv('../data/data_train.csv' ,names = ['id' ,'k1k2' ,'lock' ,'stop' ,'gate' ,'thdv' ,'thdi' ,'label' ]) y = data['label' ] x = data.drop(['label' ,'id' ],axis=1 ) x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25 ) ss = StandardScaler() x_train = ss.fit_transform(x_train) x_test = ss.transform(x_test) lr = LogisticRegression(C=1.0 , penalty='l2' , tol=0.01 ) lr.fit(x_train,y_train) print(lr.predict(x_test)) print(lr.score(x_test,y_test)) print(classification_report(y_test,lr.predict(x_test)))
运行结果:
1 2 3 4 5 6 7 8 9 10 [0 1 1 ... 0 0 1] 0.8746198830409356 precision recall f1-score support 0 0.93 0.81 0.87 10684 1 0.83 0.94 0.88 10691 accuracy 0.87 21375 macro avg 0.88 0.87 0.87 21375 weighted avg 0.88 0.87 0.87 21375
完整的代码已经PUSH到了我的GitHub上https://github.com/KakaWanYifan/BaiduPower
优缺点
优点
对于二分类问题,简单快速
缺点
只适合二分类问题
当然,实际上如果进行一些改进。逻辑回归也可以解决多分类问题。
One VS REST
softmax方法-逻辑回归
如图:softmax方法-逻辑回归。
逻辑回归和朴素贝叶斯
逻辑回归
朴素贝叶斯
解决问题
二分类
多分类
应用场景
二分类都可以用逻辑回归
一般用于文本分类
超参数
正则化力度
没有超参数
先验概率
无
有
判别或生成
判别模型
生成模型
朴素贝叶斯的先验概率是P ( F 1 , F 2 , F 3 ⋅ ⋅ ⋅ ∣ C ) P ( C ) P(F_1,F_2,F_3···|C)P(C) P ( F 1 , F 2 , F 3 ⋅ ⋅ ⋅ ∣ C ) P ( C ) P ( C ) P(C) P ( C )
依据有无先验概率,又可分为判别模型和生成模型
逻辑回归没有先验概率,属于判别模型
朴素贝叶斯有先验概率,属于生成模型
常见的判别模型还有kNN、决策树、随机森林。朴素贝叶斯、隐马尔可夫模型。
版权声明: 本博客所有文章版权为文章作者所有,未经书面许可,任何机构和个人不得以任何形式转载、摘编或复制。