统计量
什么是统计量
统计量,我们在《1.概括性度量》就有提到过,只不过当时我们没说,这是统计量。
统计量的严格定义如下:
设X1,X2,X3,⋯,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,X3,⋯,Xn),不依赖于任何未知参数,则称函数T(X1,X2,X3,⋯,Xn)是一个统计量。
注意,上文的定义,有两个重点:
- 由样本构造函数
- 不依赖于任何未知参数
通常,T(X1,X2,X3,⋯,Xn)也被称为样本统计量。
统计量也是一个随机变量,只有通过抽样,获得样本的一组具体观测值x1,x2,x3,⋯,xn时,代入T,计算得到T(x1,x2,x3,⋯,xn)的数值,这时候,才会得到一个具体的统计量值。
例如,X1,X2,X3,⋯,Xn是从某总体X中抽取的一个样本,以下两个都是统计量。
XˉS2=n1i=1∑nXi=n−11i=1∑n(Xi−Xˉ)2
但是,∑i=1n[Xi−E(X)]2,[Xi−E(X)]/D(X)都不是统计量,因为其中的E(X)和D(X)都是依赖于总体分布的未知参数。
常用统计量
通常,我们把数学期望及方差等概念用所谓"矩"的概念来描述。当n充分大时,有定理可以保证经验分布函数Fn(x)很靠近总体分布函数F(X)。因此,经验分布函数Fn(x)的各阶矩就反映了总体各阶矩的信息。
经验分布函数的各阶矩也被称为样本各阶矩。
常用的样本各阶矩及其函数就是实际应用中的具体统计量,例如:
- Xˉ=n1∑i=1nXi,样本均值,反映总体X的数学期望的信息。
- S2=n−11∑i=1n(Xi−Xˉ)2,样本方差,反映总体X的方差的信息。
- V=XˉS,样本变异系数,反映总体变异系数C的信息,C=E(X)D(X),反映出随机变量在以它的均值为单位时取值的离散程度。
此统计量消除了均值不同对不同总体的离散程度的影响,常用来刻画均值不同时不同总体的离散程度。
- mk=n1∑i=1nXik,mk被称为样本的k阶矩,反映总体的k阶矩。
对于m1,有m1=n1∑i=1nXi,即m1就是样本均值。
- vk=n−11∑i=1n(Xi−Xˉ)k,vk被称为样本的k阶中心矩,反映总体的k阶中心矩。
对于v2,有v2=n−11∑i=1n(Xi−Xˉ)2,即v2就是样本方差。
- 样本偏度,关于样本偏度的计算方法有三种,具体可以参考《1.概括性度量》。
样本偏度反映总体的偏度。
偏度描述了随机变量密度函数曲线在众数(密度函数在这一点达到最大值)两边的偏斜性。
正态随机变量X∼N(μ,σ2)的偏度等于0。
- 样本峰度,关于样本峰度的计算方法有三种,具体可以参考《1.概括性度量》。
样本峰度反映总体的峰度。
峰度反映了密度函数曲线在众数附近的"峰"的尖峭程度。
正态随机变量X∼N(μ,σ2)的峰度等于0。
三个重要分布
卡方分布
什么是卡方分布
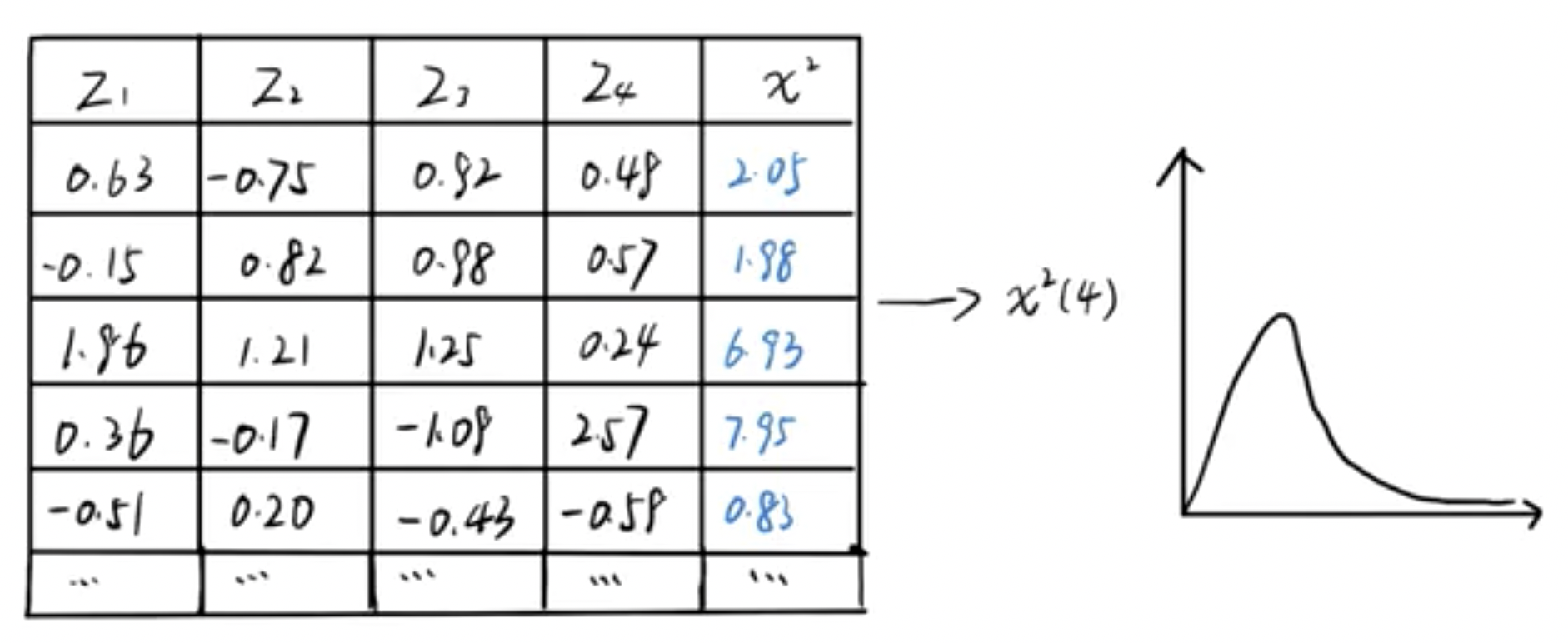
设随机变量X1,X2,X3,⋯,Xn相互独立,且X(i=1,2,3,⋯,n)服从标准正态分布N(0,1),则它们的平方和∑i=0nXi2服从自由度为n的χ2分布(卡方分布)。
自由度,我们可以理解为独立变量的个数。

例如,如果我们认为Z1、Z2、Z3、Z4是4个独立的变量,则我们认为其构成的chi2分布的自由度为4,即chi2(4)。
关于χ2分布的密度函数较为复杂,本文不讨论。
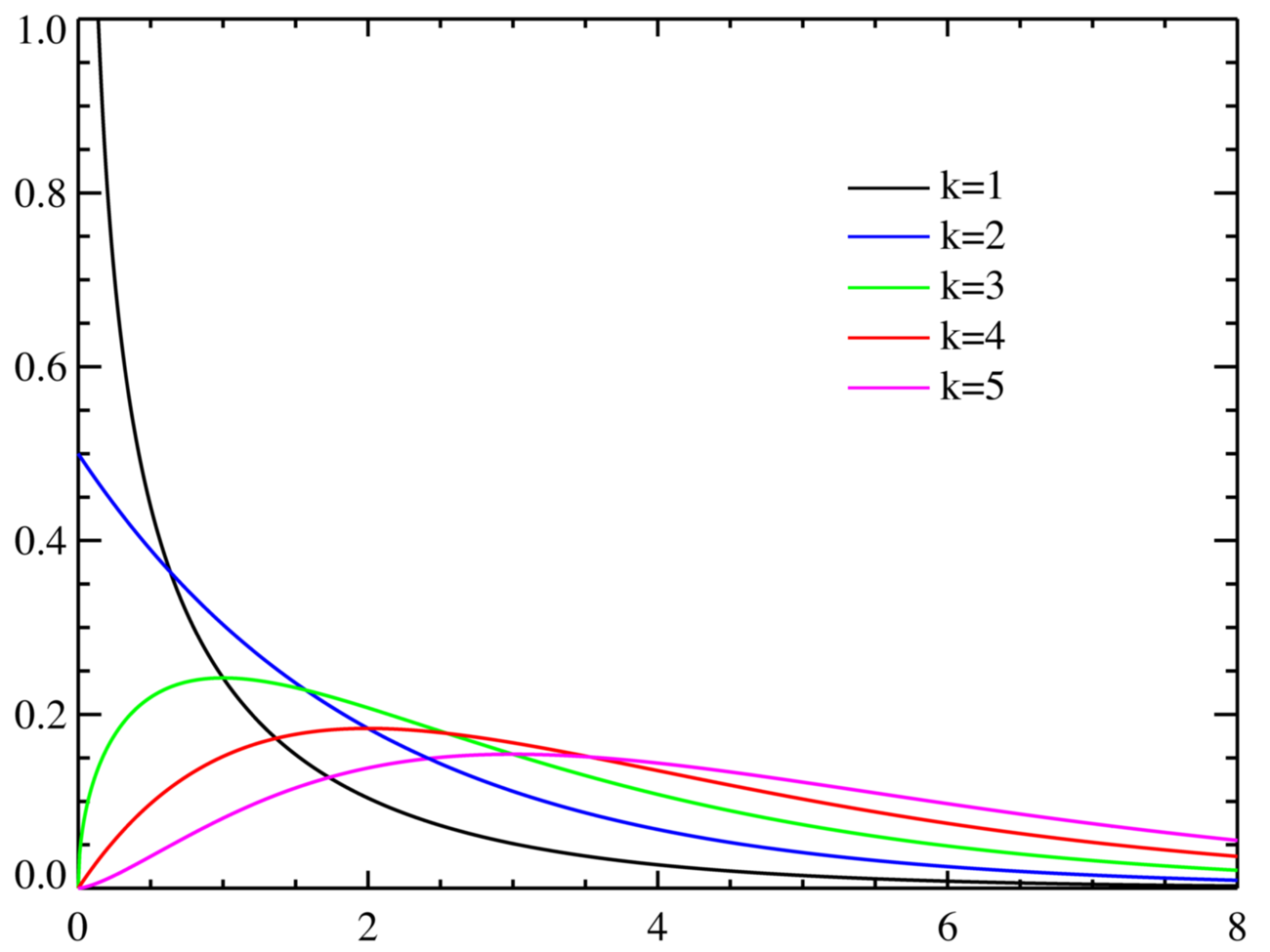
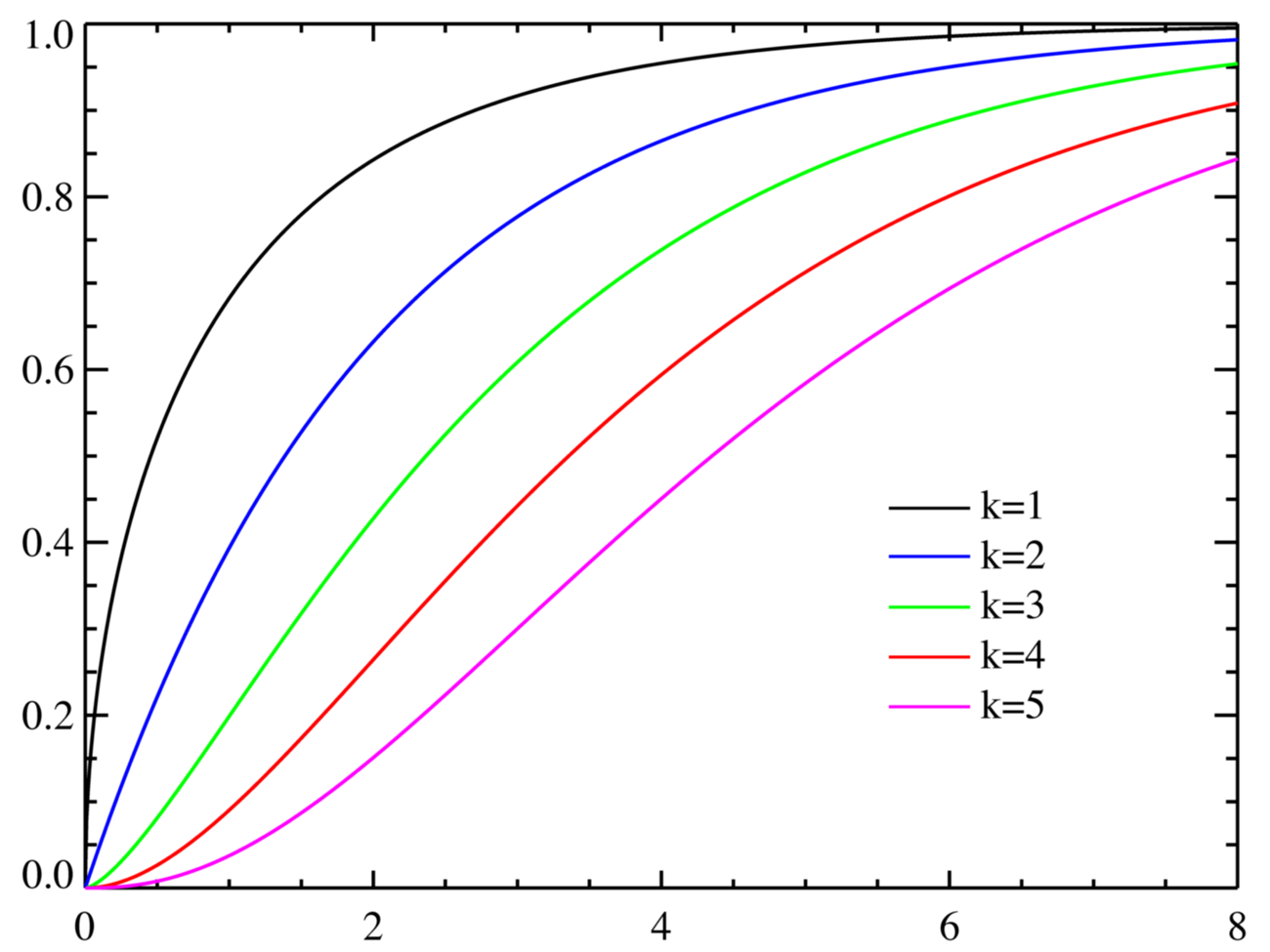
下面给出当n=1,n=2,n=3,n=4,n=5时,χ2分布的概率密度函数曲线和累积分布函数曲线。
概率密度函数曲线
累积分布函数曲线
性质
数学期望
χ2分布的数学期望:E(χ2)=n。
方差
χ2分布的方差:D(χ2)=2n。
可加性
χ2分布具有可加性,即若χ12∼χ2(n1),χ22∼χ2(n2),且独立,则有
χ12+χ22∼χ2(n1+n2)
自由度趋近于无穷时
当n→+∞时,χ2分布的极限分布是正态分布。
推论
设X1,X2,X3,⋯,Xn是来自正态总体N(μ,σ2)的一个样本,其样本均值和样本方差分别为
XˉS2=n1i=1∑nXi=n−11i=1∑n(X1−Xˉ)2
则有:
- Xˉ与S2相互独立
- Xˉ∼N(μ,nσ2)
- σ2(n−1)S2∼χ2(n−1)
t分布
什么是t分布
t分布(t distribution),也被称为学生氏分布,是戈塞特(W.S.Gosset)于1908年在一篇以"Student"(学生)为笔名的论文中首次提出的。
设随机变量X∼N(0,1),Y∼χ2(n),且X与Y独立,则
t=nYX
该分布称为t分布,记为t(n),其中,n为自由度。
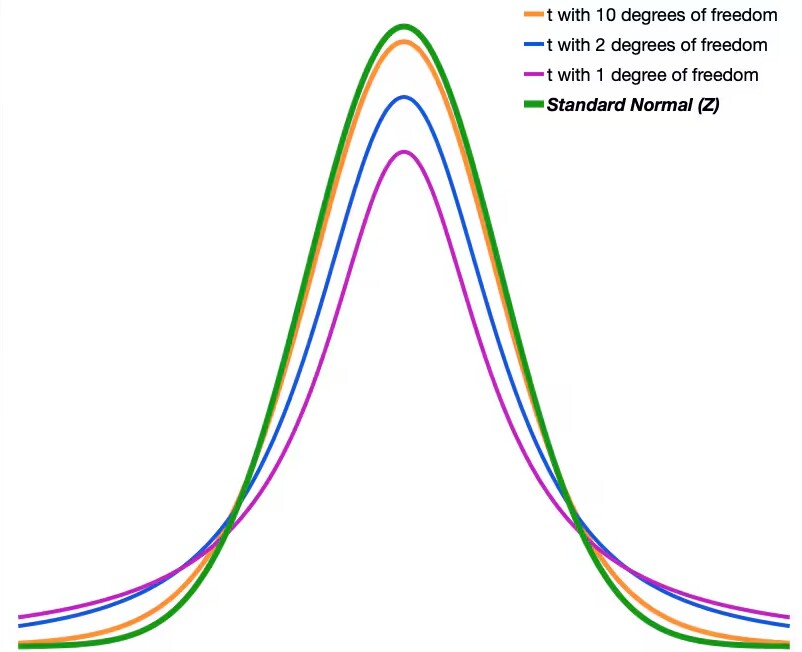
t分布的密度函数曲线如图。
与标准正态分布N(0,1)的密度函数曲线非常相似,都是单峰偶函数。只是t(n)的密度函数的两侧尾部要比N(O,1)的两侧尾部粗一些。t(n)的方差比N(0,1)的方差大一些。
性质
数学期望
当n≥2时,t分布的数学期望E(t)=0。
方差
当n≥3时,t分布的方差D(t)=n−2n
自由度趋近于无穷时
随着自由度n的增加,t分布的密度函数越来越接近标准正态分布N(0,1)的密度函数。
在实际应用中,一般当n≥30时,t分布与标准正态分布N(0,1)就非常接近。
推论
设X1,X2,X3,⋯,Xn是来自正态分布N(μ,σ2)的一个样本,Xˉ和S2分别是该样本的样本均值与样本方差,
Xˉ=n1∑i=1nXi,
S2=n−11∑i=1n(Xi−Xˉ)2,
则
Sn(Xˉ−μ)∼t(n−1)
称为服从自由度为(n−1)的t分布。
案例
设X和Y是两个相互独立的总体,X∼N(μ1,σ2),Y∼N(μ2,σ2),X1,X2,X3,⋯,Xn是来自X的一个样本,Y1,Y2,Y3,⋯,Ym是来自Y的一个样本,记
XˉYˉSx2Sy2Sxy2=n1i=1∑nXi=m1i=1∑mYi=n−11i=1∑n(Xi−Xˉ)2=m−11i=1∑m(Yi−Yˉ)2=n+m−2(n−1)Sx2+(m−1)Sy2
则
Sxy(Xˉ−Yˉ)−(μ1−μ2)m+nmn∼t(n+m−2)
F分布
什么是F分布
F分布(F distribution)是统计学家费希尔首先提出的。F分布有着广泛的应用,在方差分析、回归方程的显著性检验中有重要的地位。
设随机变量Y与Z相互独立,且Y和Z分别服从自由度为m和n的χ2分布,随机变量X有如下表达式:
X=(nZ)(mY)=mZnY
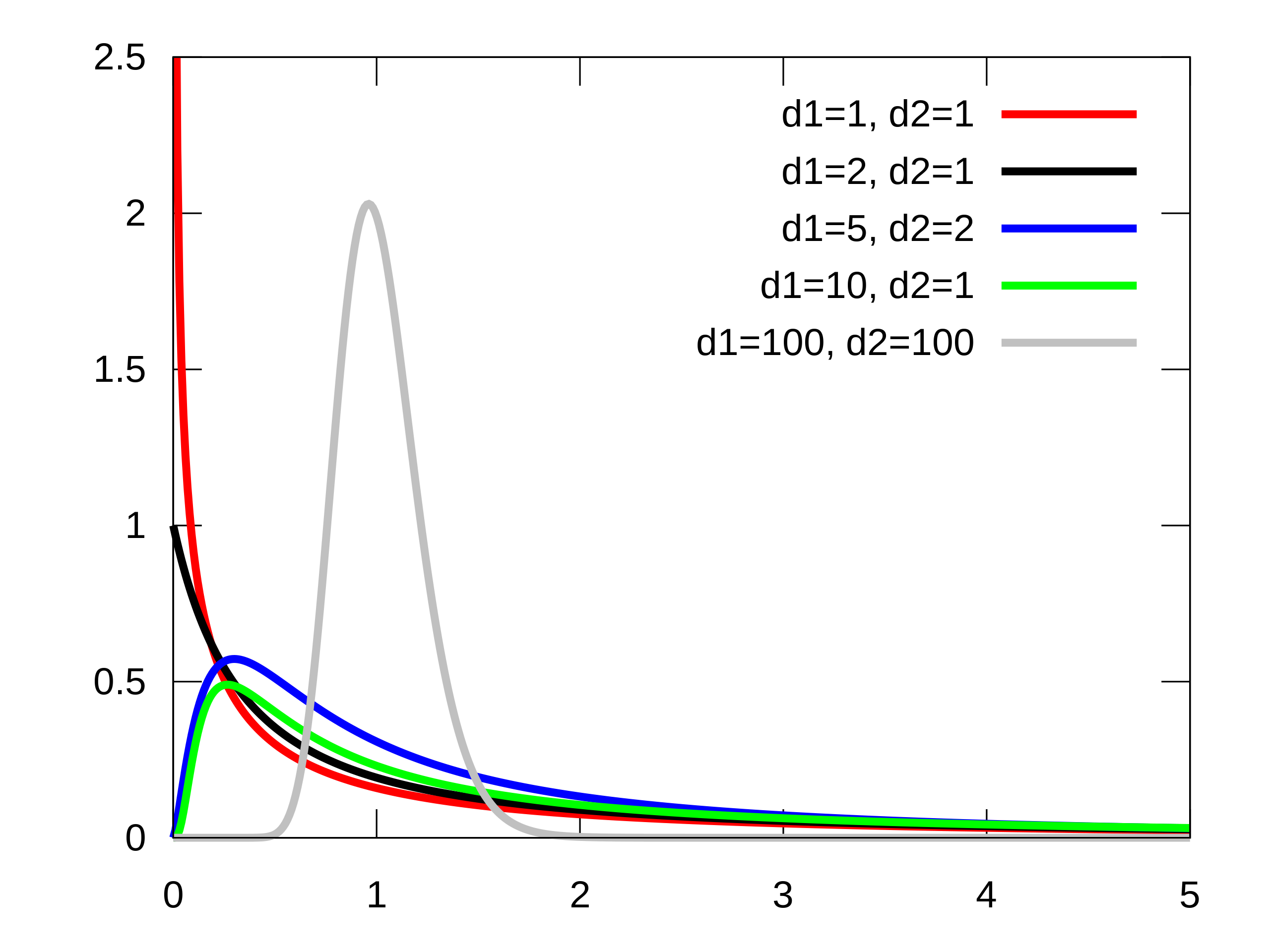
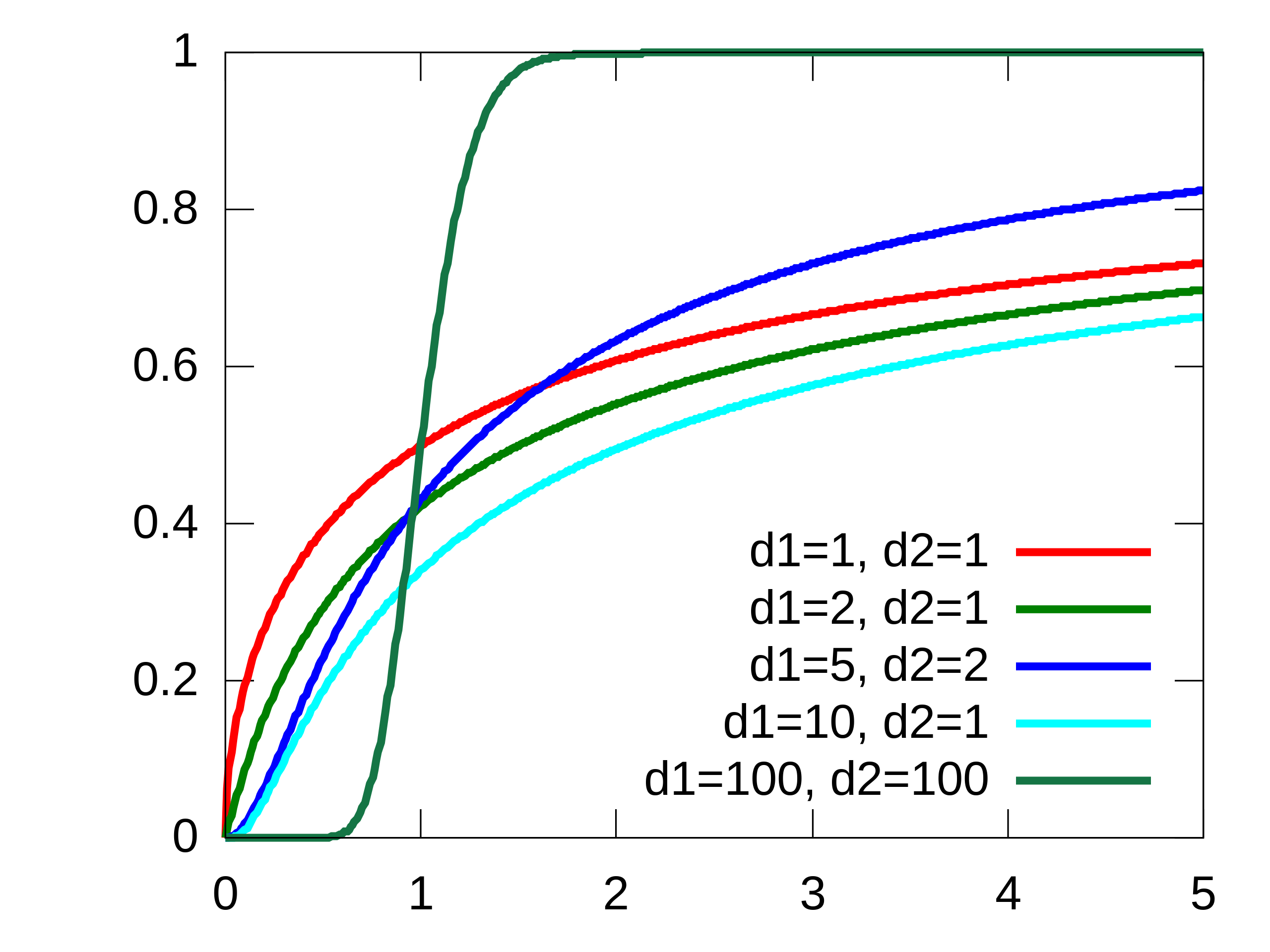
则称X服从第一自由度为m,第二自由度为n的F分布,记为F(m,n),简记X∼F(m,n)。F分布的密度函数的图形如图所示。
性质
期望和方差
设随机变量X服从F(m,n)分布,则数学期望和方差分别为:
E(X)D(X)=n−2n,n>2=m(n−2)(n−4)2n2(m+n−2),n>4
两个自由度的位置
若X∼F(m,n),则X1∼F(n,m)
和t分布的关系
F分布与t分布还存在如下关系:如果随机变量X∼t(n),则X2∼F(1,n)。
推论
设X1,X2,X3,⋯,Xm是来自正态分布N(μ1,σ12)的样本,Y1,Y2,Y3,⋯,Yn是来自正态分布N(μ2,σ22)的样本,且这两个样本相互独立,记
SX2SY2=m−11i=1∑m(Xi−Xˉ)2=n−11i=1∑n(Yi−Yˉ)2
其中
XˉYˉ=m1i=1∑mXi=n1i=1∑nYi
则有
F=(σ22SY2)(σ12SX2)∼F(m−1,n−1)
特别的,若σ12=σ22,则
F=SY2SX2∼F(m−1,n−1)
中心极限定理
抽样分布
- 抽样分布
抽样分布(sampling distribution),重复抽样条件下,样本统计量的所有可能取值及概率分布。是样本统计自身的分布量的分布。
- 精确的抽样分布
在总体X的分布类型已知时,若对任一自然数n,都能导出统计量T=T(X1,X2,X3,⋯,Xn)的分布的数学表达式,这种分布称为精确的抽样分布。
精确的抽样分布大多是在正态总体情况下得到的,例如上文我们讨论的χ2分布、t分布和F分布,都属于精确的抽样分布。
- 浙近分布
样本容量无限增大时,统计量T(X1,X2,X3,⋯,Xn)的极限分布。
在实际应用中,是n较大时抽样分布的一种近似。
- 随机模拟获得的近似分布
针对复杂问题,利用计算机的随机模拟技术获得的近似抽样分布。
(这个思路,我们在强化学习中有用到。关于强化学习,可以参考《强化学习浅谈及其Python实现》)。
总体分布为正态分布
设X1,X2,X3,⋯,Xn为从某一总体中抽出的随机样本,即X1,X2,X3,⋯,Xn为互相独立且与总体有相同分布的随机变量。
当总体分布为正态分布N(μ,σ2)时,可以得到下面的结果:
Xˉ的抽样分布(sampling distribution)仍为正态分布,Xˉ的数学期望为μ,方差为nσ2,即
Xˉ∼N(μ,nσ2)
Xˉ的期望值与总体均值相同,而方差则缩小为总体方差的n1。也就是说当用样本均值Xˉ去估计总体均值μ时,平均来说没有偏差(这一点称为无偏性);当n越来越大时,Xˉ的离散程度越来越小,即用Xˉ估计μ越来越准确。
什么是中心极限定理
上文我们是假定总体的分布是正态分布,那么对于非正态分布呢?
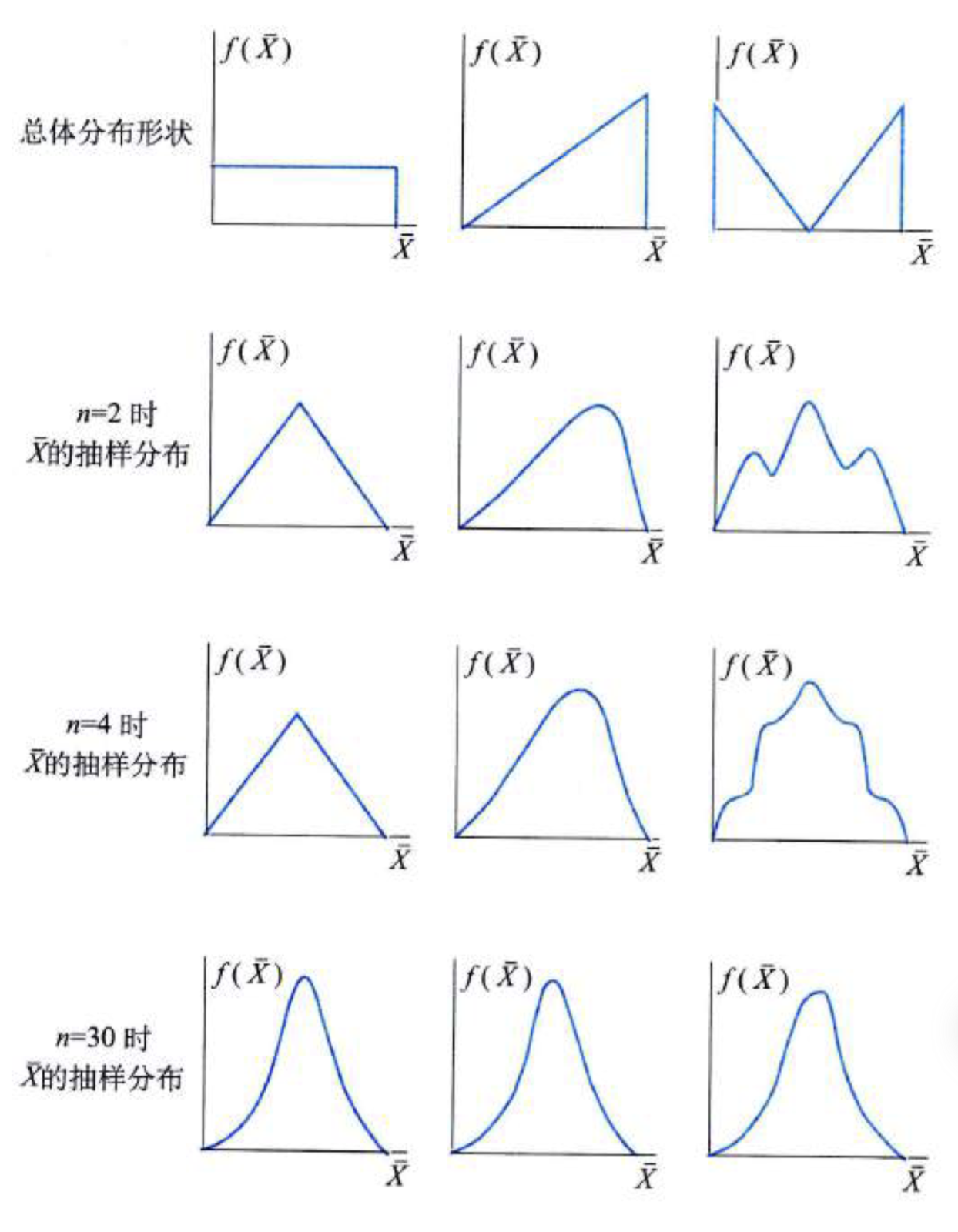
中心极限定理(central limit theorem):设从均值为μ、方差为σ2(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值Xˉ的抽样分布近似服从均值为μ,方差为nσ2的正态分布。
如图描述Xˉ的抽样分布趋于正态分布的过程。
中心极限定理要求n必须充分大,那么多大才叫充分大呢?
这与总体的分布形状有关。总体偏离正态越远,则要求n越大。
然而在实际应用中,总体的分布未知。一般,我们常要求n≥30。需要注意的是,30只是一个经验值。
案例
案例一
设从一个均值μ=10、标准差σ=0.6的总体中随机选取容量n=36的样本。假定该总体不是很偏,则有:
根据中心极限定理,不论总体的分布是什么形状,在假定总体分布不是很偏的情形下,当从总体中随机选取n=36的样本时,样本均值Xˉ近似服从均值为10、方差为nσ2=360.62=0.01的正态分布,即Xˉ∼N(10,0.01)。
案例二
某汽车电瓶生产厂声称其生产的电瓶具有均值为60个月、标准差为6个月的寿命分布。现假设质检部门决定检验该厂的说法是否准确,为此随机抽取了50个该厂生产的电瓶进行寿命试验。
- 假定厂方说法是正确的,试描述50个电瓶的平均寿命的抽样分布。
- 假定厂方说法是正确的,则50个样品组成的样本的平均寿命不超过57个月的概率为多少?
根据中心极限定理可以推出,50个电瓶的平均寿命近似服从正态分布,其均值为60,方差为nσ2=n62=5036=0.72的正态分布。即Xˉ∼N(60,0.72)。
如果厂方说法是正确的,则观察到50个电瓶的平均寿命不超过57个月的概率为:
P(Xˉ≤57)=P(0.72Xˉ−60≤0.7257−60)=P(Z≤0.7257−60)=P(Z≤−3.529)=1−P(Z≤3.529)=1−Φ(3.529)=1−0.9998=0.0002
其他抽样分布
样本比例的抽样分布
例如,我们假定总体中对具有某一产品的喜好比例为pi,在此条件下去研究从总体中随机抽取n个个体进行调查时,喜好某一产品的个体数X的概率。
例如,我们要估计在总体中,喜好某一产品的比例π。我们抽取了n个样本,即样本数为n,其中喜好某一产品的数量为X。所以,我们用样本比p^=nX,来估计总体的比例π。
根据二项分布的原理和渐近分布的理论,我们知道,当n充分大时,p^的分布近似服从均值为π、方差为nπ(1−π)的正态分布,即
p^∼N(π,nπ(1−π))
- 一般认为,当np≥5,并且n(1−p)≥5,认为n充分大。
两样本均值差的抽样分布
设Xˉ1是独立抽样自总体X1∼N(μ1,σ12)的一个样本容量为n1的样本均值,Xˉ2是独立抽样自总体X2∼N(μ2,σ22)的一个样本容量为n2的样本均值,则有
E(Xˉ1−Xˉ2)D(Xˉ1−Xˉ2)=E(Xˉ1)−E(Xˉ2)=μ1−μ2=D(Xˉ1)+D(Xˉ2)=n1σ12+n2σ22
如果两个样本均为正态分布,则Xˉ1−Xˉ2也为正态分布,其均值和方差就符合上述均值和方差的计算公式,即
Xˉ1−Xˉ2∼N(μ1−μ2,n1σ12+n2σ22)
假设:甲、乙两所著名高校在某年录取新生时,甲校的平均分为655分,且服从正态分布,标准差为20分;乙校的平均分为625分,也是正态分布,标准差为25分。现从甲、乙两校各随机抽取8名新生计算其平均分数,出现甲校比乙校的平均分低的可能性有多大?
因为两个总体均为正态分布,所以8名新生的平均成绩Xˉ1和Xˉ2也分别为正态分布,Xˉ1−Xˉ2也为正态分布,且
Xˉ1−Xˉ2∼N(μ1−μ2,n1σ12+n2σ22)
甲校比乙校的平均分低,即Xˉ1−Xˉ2≤0,即求P((Xˉ1−Xˉ2)≤0)。
两样本比例差的抽样分布
设分别从具有参数为π1和参数π2的二项总体中抽取包含n1个观测值和n2个观测值的独立样本,则两个样本比例差的抽样分布为
p^1−p^2=n1X1−n2X2
具有以下性质:
- E(p^1−p^2)=π1−π2
- D(p^1−p^2)=n1π1(1−π1)+n2π2(1−π2)
- 当n1和n2很大时,(p^1−p^2)的抽样分布近似为正态分布,其均值与方差为上述计算公式,即:
p1−p2∼N(π1−π2,n1π1(1−π1)+n2π2(1−π2))
样本方差的抽样分布
样本方差的抽样分布,也就是上文讨论的χ2分布的推论中的σ2(n−1)S2∼χ2(n−1)。
两样本方差比的抽样分布
两样本方差比的抽样分布,也就是上文讨论的F分布的推论。
Python计算
卡方分布
计算:
- 自由度为15,χ2值小于等于15的概率
- 自由度为25,χ2值大于15的概率
- 自由度为10,χ2分布右尾概率为0.05时的分位数
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
| from scipy.stats import chi2
p1 = chi2.cdf(10, df=15)
p2 = 1 - chi2.cdf(15, df=25)
q = chi2.ppf(0.95, df=10)
print(p1)
print(p2)
print(q)
|
运行结果:
1
2
3
| 0.18026008049639844
0.9413825679762463
18.307038053275146
|
t分布
计算:
- 自由度为10,t值小于−2的概率
- 自由度为15,t值大于3的概率
- 自由度为25,t分布右尾概率0.025时的t值。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
| from scipy.stats import t
p1 = t.cdf(-2, df=10)
p2 = 1 - t.cdf(3, df=15)
q = t.ppf(0.975, df=25)
print(p1)
print(p2)
print(q)
|
运行结果:
1
2
3
| 0.036694017385370196
0.004486368738611635
2.059538552753294
|
F分布
计算:
- 分子自由度为10,分母自由度为8,F值小于3的概率
- 分子自由度为18,分母自由度为15,F值大于2.5的概率
- 分子自由度为25,分母自由度为20,F分布累积概率为0.95时的F值
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
| from scipy.stats import f
p1 = f.cdf(3, dfn=10, dfd=8)
p2 = 1 - f.cdf(2.5, dfn=18, dfd=15)
q = f.ppf(0.95, dfn=25, dfd=20)
print(p1)
print(p2)
print(q)
|
运行结果:
1
2
3
| 0.9335491372878875
0.03944962943005237
2.073920163193128
|