定义
引例
为什么JavaScript可以在浏览器中被执行?
这个问题我们在《2.基础语法》的"浏览器的引擎"部分就讨论过,一个浏览器,通常由两个主要部分组成:渲染引擎和JavaScript引擎。
- 渲染引擎:用来解析HTML与CSS,俗称内核。
比如新版本Chrome浏览器的blink,以及旧版本Chrome浏览器的webkit。 - JavaScript引擎:也称为JavaScript解释器,读取网页中的JavaScript代码,逐行解释每一句JavaScript代码,将其翻译为机器语言,然后由计算机去执行。
比如Chrome浏览器的V8,Firefox浏览器的OdinMonkey,Safari浏览器的JSCore。其中,Chrome浏览器的V8引擎性能最好。
那么,JavaScript是怎么操作操作DOM和BOM的呢?
首先,浏览器提供了和DOM、BOM相关的API;然后,我们用JavaScript写location.replace('/')这种代码;浏览器才会在解析JavaScript调用相关的API。
即,在浏览器中的JavaScript运行环境如下:
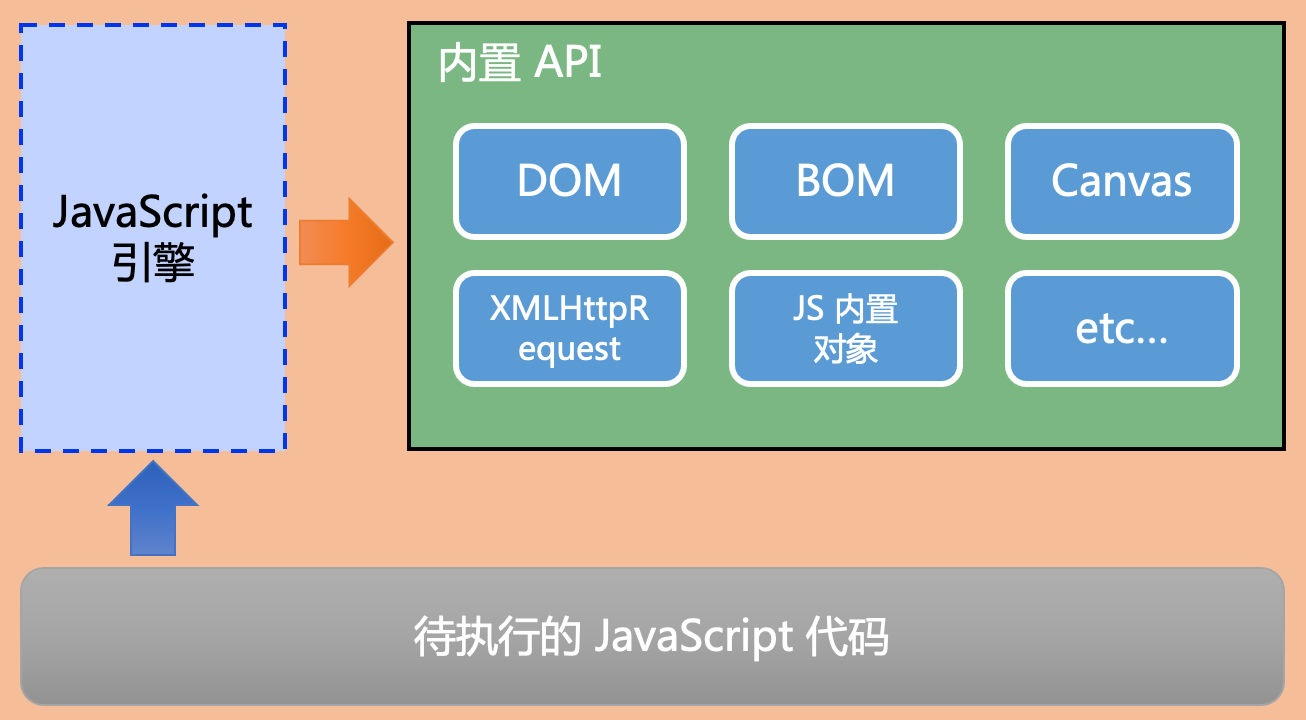
那么,如果说,内置的API,不仅仅是DOM和BOM,还包括读写文件、提供网络服务,调用操作系统资源在内的诸多API呢?
这就是Node.js。
Node.js
Node.js是一个基于Chrome的V8引擎的JavaScript运行环境。
官网:https://nodejs.org
其运行环境如下:
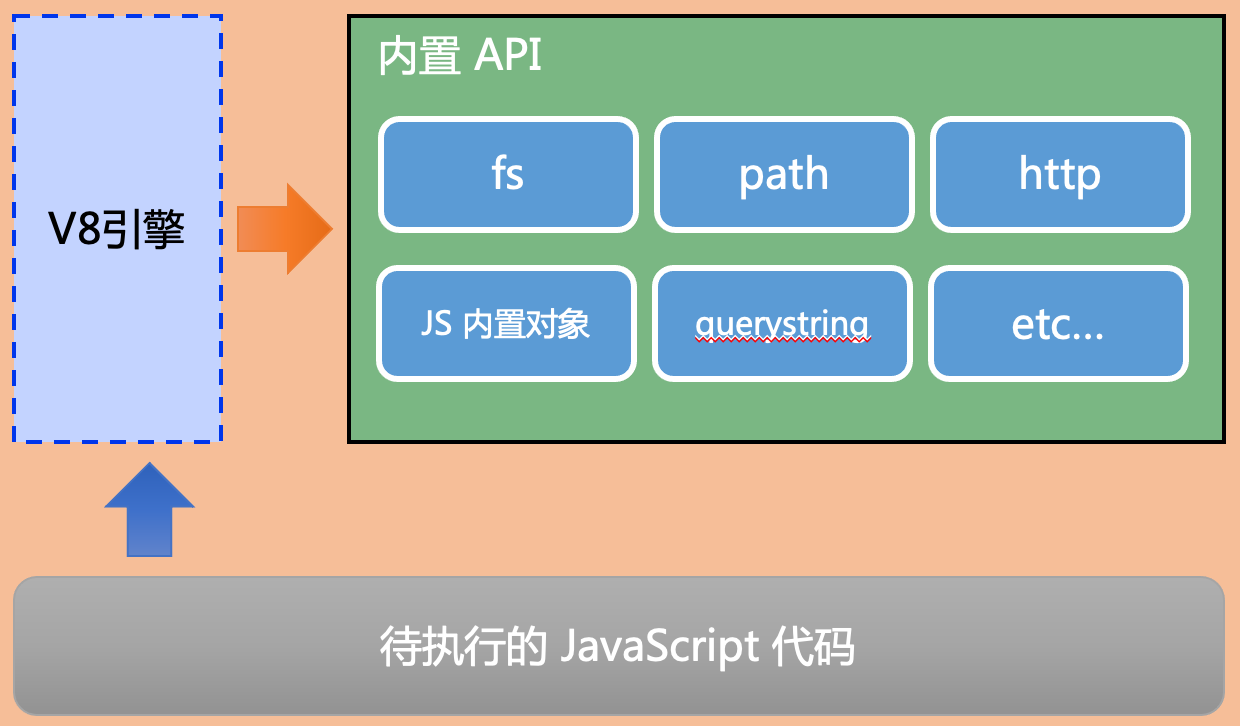
虽然Node.js只是提供了基础的功能和API,但是其拥有非常完善的生态,有诸多的框架和工具。例如:
- Hexo
基于Hexo,可以快速构建博客应用。 - Express
基于Express,可以快速构建Web应用。 - Electron
基于Electron,可以构建跨平台的桌面应用。 - Robot.js、Auto.js
基于Robot.js,可以构建自动化工具。
此外,还包括操作数据库、解析HTML、JS混淆等等。
环境,就没有DOM和BOM的API。
环境准备
LTS和Current
正如浏览器需要安装,Node.js的环境也需要安装。
我们会看到两个版本的Node.js。

LTS,长期稳定版,一般推荐安装改版本。Current,新特性版,可能存在隐藏的Bug或安全漏洞。
是不是有一个问题?
有18、有20,19呢?
19作为20的预备版本。在Node.js,是下一个偶数版的预备版本。
Windows
下载node-v18.16.0-x64.msi,然后直接进行安装即可。
MacOS
下载node-v18.16.0.pkg,然后直接进行安装即可。
Linux
Ubuntu
安装命令:apt install nodejs。
通过这个命令安装的,不一定是最新的,安装最新版的方法如下:
- 升级
apt1
sudo apt update && sudo apt upgrade
- 删除旧版本
1
2
3
4
5
6cd /etc/apt/sources.list.d
sudo rm nodesource.list
sudo apt --fix-broken install
sudo apt update
sudo apt remove nodejs
sudo apt remove nodejs-doc - 添加新版本的源
1
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
- 安装新版本
1
sudo apt-get install -y nodejs
- 在安装过程中,可能有如下告警:解决方法:
1
2
3
4
5
6Unpacking nodejs (18.16.0-deb-1nodesource1) ...
dpkg: error processing archive /var/cache/apt/archives/nodejs_18.16.0-deb-1nodesource1_amd64.deb (--unpack):
trying to overwrite '/usr/share/systemtap/tapset/node.stp', which is also in package libnode72:amd64 12.22.9~dfsg-1ubuntu3
Errors were encountered while processing:
/var/cache/apt/archives/nodejs_18.16.0-deb-1nodesource1_amd64.deb
E: Sub-process /usr/bin/dpkg returned an error code (1)1
sudo dpkg -i --force-overwrite /var/cache/apt/archives/nodejs_18.16.0-deb-1nodesource1_amd64.deb
CentOS
安装命令:yum install nodejs。
如果是在CentOS 7系统上,通过这个命令安装的,不是最新的(18版)。
目前18版,不支持CentOS 7。
如果不是CentOS 7,可以通过如下的方法安装
- 添加新版本的源注意,这里的地址是
1
curl -sL https://rpm.nodesource.com/setup_18.x | sudo bash -
rpm.nodesource - 安装
1
yum install nodejs
18版本的要求
18版要求的系统版本:
- CentOS,7以上
- RHEL,7以上
- Ubuntu,18.04以上
- MacOS,10.15及以上(包括10.15)
- Windows 10及以上
虽然网上能找到一些在不符合(较低版本)的操作系统上安装18版的方法;但我本人在实践过程中,发现不可行;而且不建议在不符合的操作系统上安装18版。
版本覆盖
在某些情况下,我们可能会有多版本的场景,而且经常需要切换node的版本,关于这个可以参考用n模型或者nvm模块进行管理。
这里我们不做太多讨论,我们讨论一般不切换node版本,版本覆盖的方式。
我们以12.22.12为例。
下载地址
找到一些大版本中的最后一个小版本。
通过https://nodejs.org/en/download/releases,可以找到大版本的最后一个小版本。
通过https://nodejs.org/download/release/,可以找到所有的历史版本。
Windows
先卸载旧版本,再安装新版本。
MacOS
直接下载旧版本,覆盖安装。
Linux
Ubuntu
通过=【版本号】的方式,指定版本,覆盖安装。
1 | apt install nodejs=12.22.12 |
如果提示找不到12.22.12,可能需要我们手动添加源
1 | curl -fsSL https://deb.nodesource.com/setup_12.x | sudo -E bash - |
CentOS
- 卸载旧版本
1
yum remove nodejs
- 清除 yum rpm 源
1
2cd /etc/yum.repos.d
rm -rf nodesource-el7.repo - 清除 yum rpm 源缓存
1
2yum clean all
rm -rf /var/cache/yum - 添加12到源
1
curl --silent --location https://rpm.nodesource.com/setup_12.x | bash -
- 安装
1
yum install -y nodejs
怎么运行
- 可以使用
node 文件名.js运行。 - 可以在VS Code直接运行。
- 可以通过Code Runner运行。
对于第一种方法,没什么好讨论的。
我们讨论第二种和第三种方法。
可以在VS Code直接运行
在如图所示之处,运行。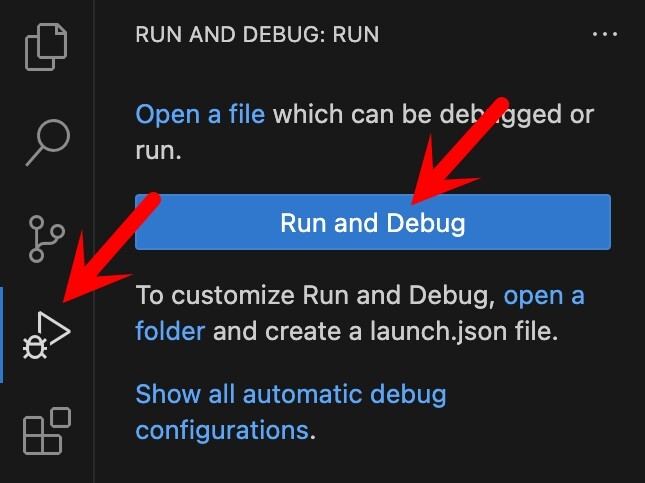
可以提前停止运行等。
可以通过Code Runner运行
下载Code Runner
右键,点击运行。

可以提前停止运行等。
模块
分类
Node.js中根据模块来源的不同,将模块分为了三大类,分别是:
- 内置模块
由Node.js官方提供,在Node.js中内置的。 - 自定义模块
用户创建的每个.js文件,就是自定义模块。 - 第三方模块
由第三方开发出来的模块,使用前需要先下载。
加载
require()方法
使用require()方法,可以加载模块。
- 内置模块
1
require(【内置模块的名称】)
- 加载用户自定义模块
1
require(【路径】)
- 加载第三方模块
1
require(【第三方模块的名称】)
示例代码:
1 | // 加载内置模块 |
被加载会被执行
使用require()方法加载其它模块时,会执行被加载模块中的代码。
我们举一个例子。
假设存在1.js,示例代码:
1 | console.log('1.js') |
我们在2.js中加载./1.js,示例代码:
1 | const m1 = require('./1.js') |
执行2.js,运行结果:
1 | 1.js |
执行了1.js中的console.log('1.js'),即被加载的模块中的代码被执行了。
关于模块加载过程,在"模块加载机制"这部分,有更多讨论。
作用域
模块级别的访问限制
在自定义模块中定义的变量,方法等成员,只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域。
1.js,示例代码:
1 | const username = 'Kaka' |
2.js,示例代码:
1 | const m1 = require('./1.js') |
运行结果:
1 | undefined |
全局变量污染
这么设计的好处是,防止了变量污染的问题。
什么是全局变量污染?
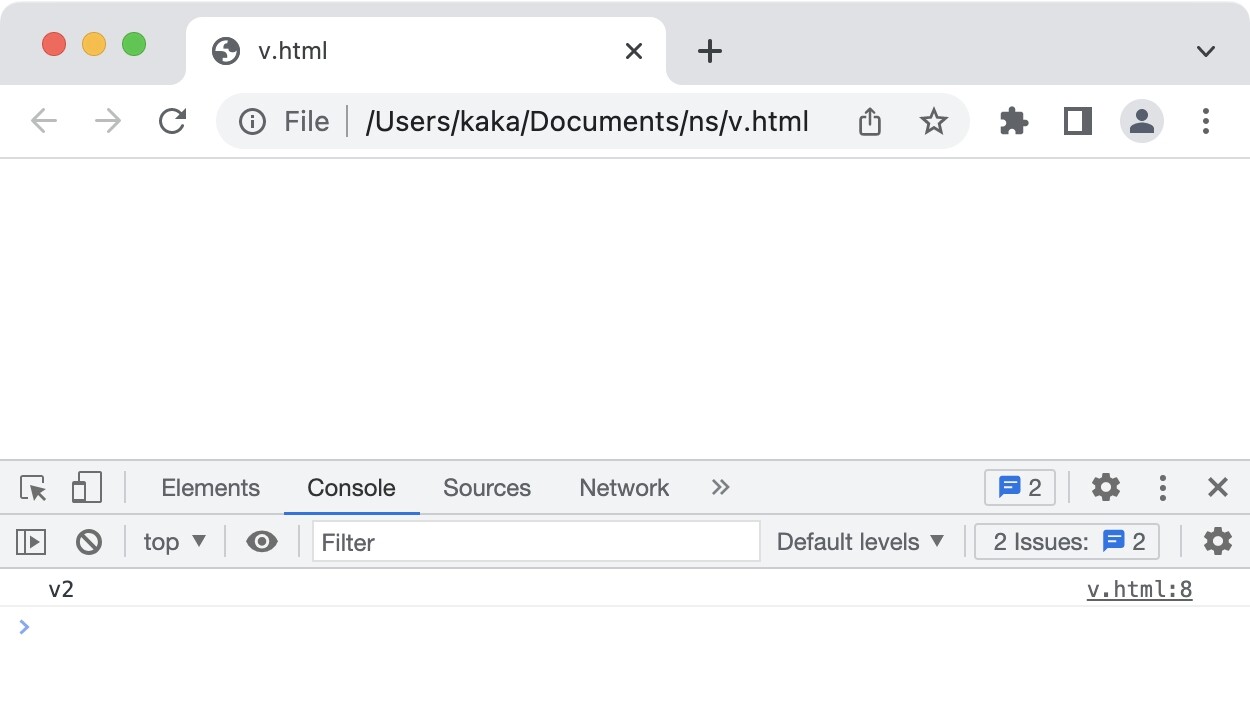
假设有一个HTML,内容如下:
1 | <html> |
v1.js的内容为:
1 | var v = 'v1' |
v2.js的内容为:
1 | var v = 'v2' |
我们执行,会发现打印的是v2。
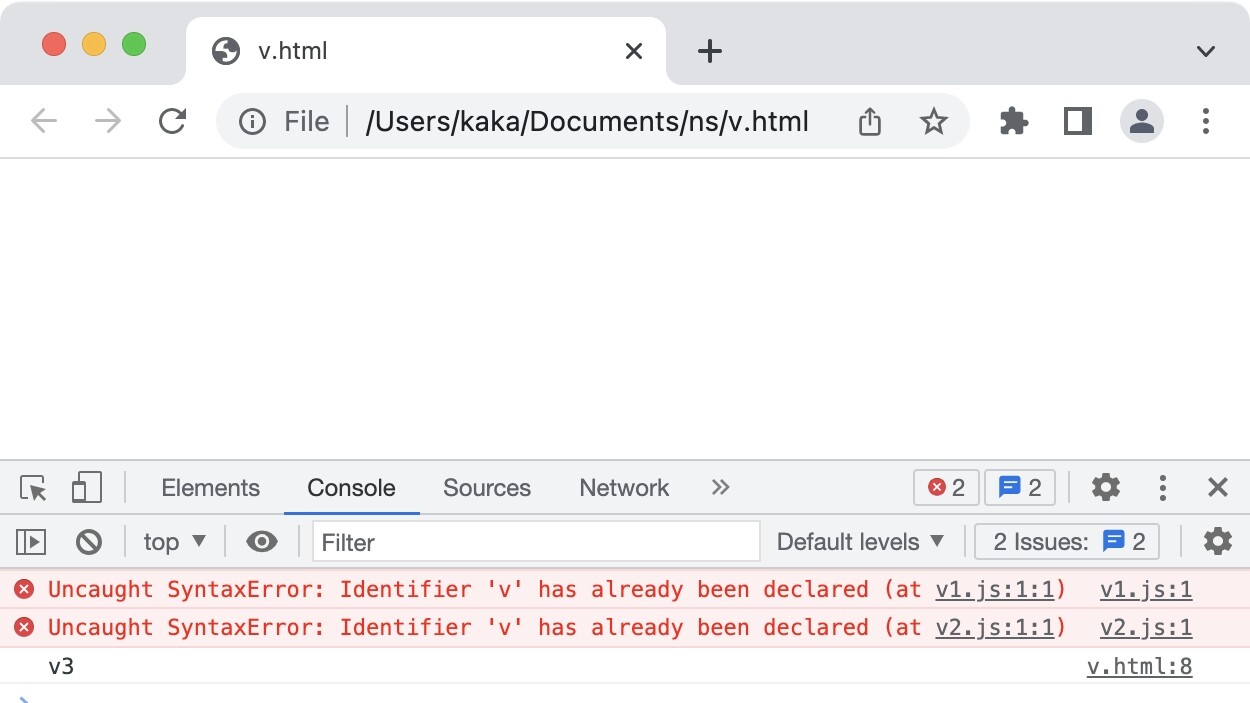
外部使用
module对象
在每个.js模块中都有一个module对象,存储了和当前模块有关的信息.
我们可以新建一个.js文件,然后打印module对象看看。示例代码:
1 | console.log(module) |
运行结果:
1 | Module { |
module.exports
可以使用module.exports对象,将模块内的成员暴露出去,供外部使用。
外部用require()方法导入自定义模块时,得到的是module.exports所指向的对象。
“exports”
Node.js还提供了另一种写法,exports。
exports的作用是什么?
是另一种写法,可以少写一个单词,和module.exports指向的是同一个内存区域。
exports和module都是node在执行js文件的时候生成的变量。
1.js,示例代码:
1 | const username = 'zs' |
2.js,示例代码:
1 | const m1 = require('./1.js') |
运行结果:
1 | { username: 'zs', age: 20, sayHello: [Function] } |
同时使用的现象
接下来,我们来看一个有趣的现象。
exports和module.exports,同时使用。
1.js,示例代码:
1 | exports.username = 'zs' |
2.js,示例代码:
1 | const m1 = require('./1.js') |
1 | undefined |
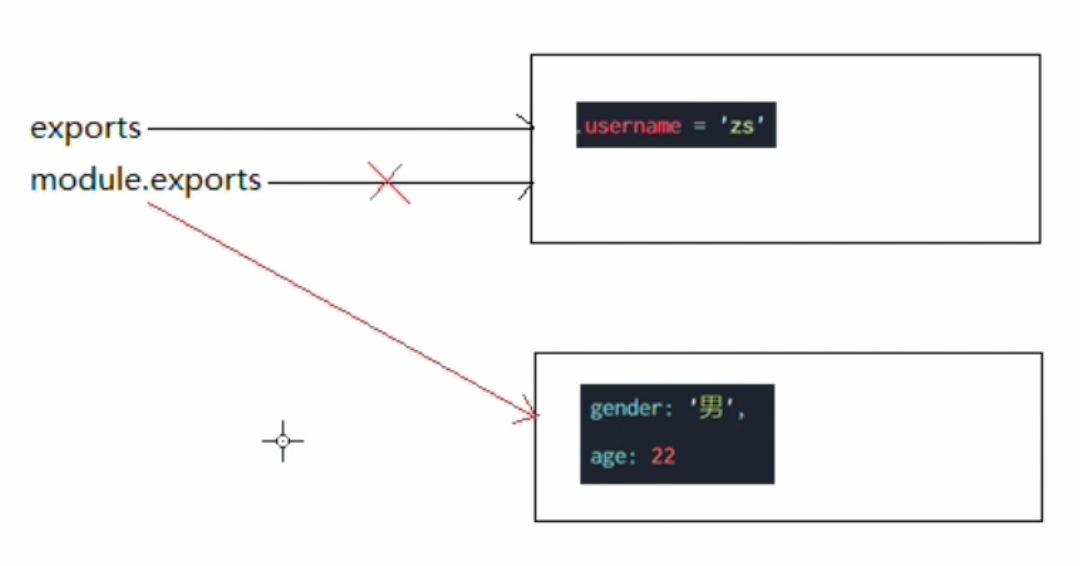
解释说明:
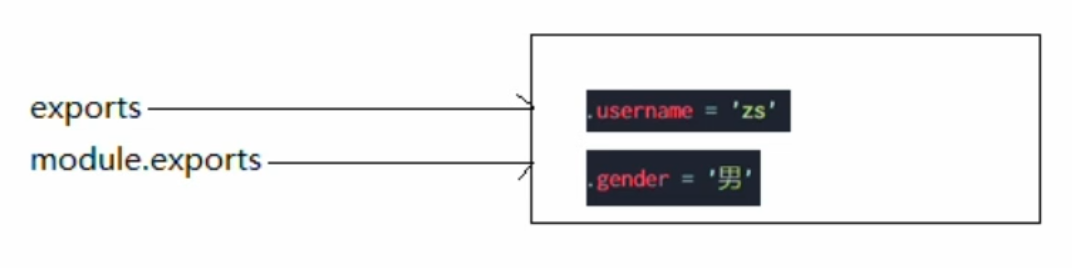
- 一开始,
exports和module.exports,指向同一块内存区域。 exports.username = 'zs'
此时,会申请一块新的内存区域,username = 'zs'module.exports = {gender: '男',age: 22}
再申请一块新的内存区域猫,module.exports指向新的内存区域。- 执行
2.js,会根据module.exports所指向的内存区域。
1.js,示例代码:
1 | module.exports.username = 'zs' |
2.js,示例代码:
1 | const m1 = require('./1.js') |
1 | zs |
解释说明:
- 一开始,
exports和module.exports,指向同一块内存区域。 module.exports.username = 'zs'
在内存区域存储username = 'zs'exports = {gender: '男',age: 22}
再申请一块内存区域,exports指向该区域。- 执行
2.js,会根据module.exports所指向的内存区域。
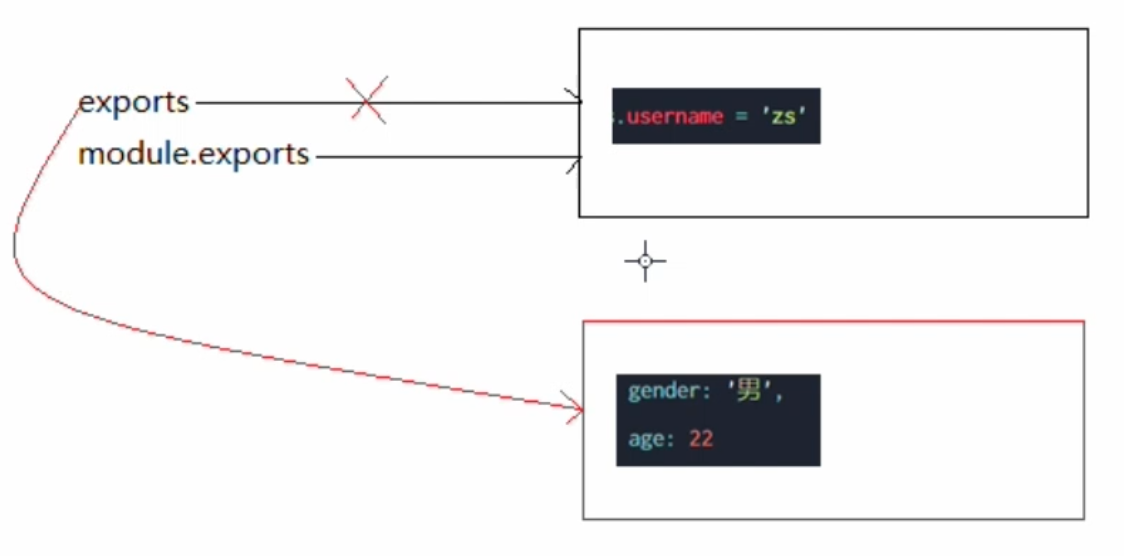
1.js,示例代码:
1 | exports.username = 'zs' |
2.js,示例代码:
1 | const m1 = require('./1.js') |
1 | zs |
分析过程略,内存结构如图
1.js,示例代码:
1 | exports = { |
2.js,示例代码:
1 | const m1 = require('./1.js') |
1 | zs |
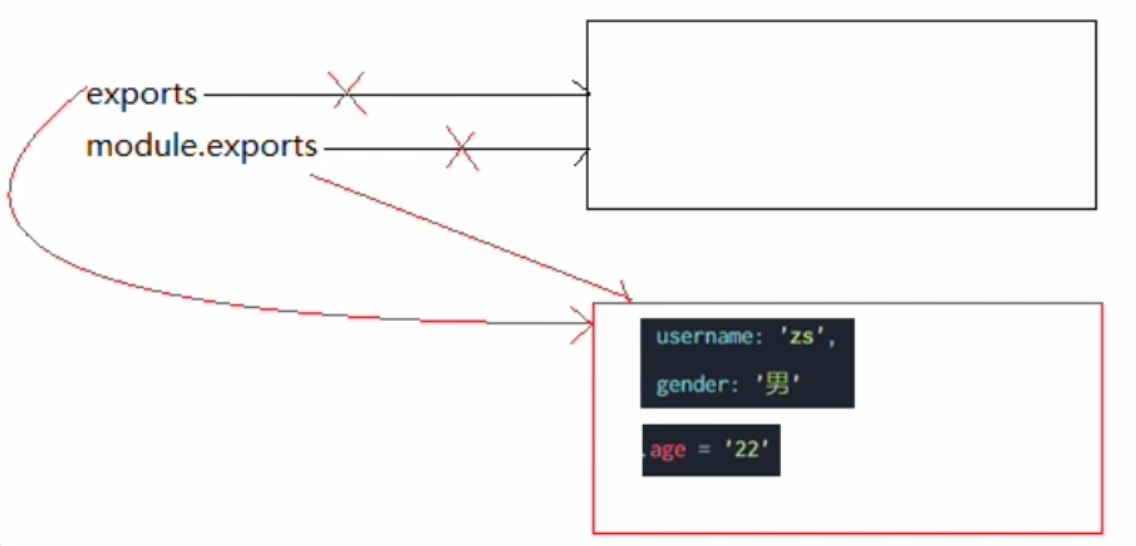
解释说明:
- 一开始,
exports和module.exports,指向同一块内存区域。 exports = {username:'zs',gender:'男'}
申请一块新的内存区域,exports指向该区域。module.exports = exportsmodule.exports指向exports所指向的区域。module.exports.age = 22
在内存区域存储age = 22- 执行
2.js,会根据module.exports所指向的内存区域。
建议不要同时使用
为了代码的可读性,不要同时使用exports和module.exports
内置模块
fs
概述
fs,Node.js官方提供的一个内置模块,用来操作文件。
导入模块
导入模块,示例代码:
1 | const fs = require('fs') |
读文件
读取文件通过readFile方法。
1 | fs.readFile(path [, options] callback) |
path,必填,字符串,文件路径。options,可选,编码格式,默认是二进制字节,可以指定为utf8,表示UTF-8编码。callback,必填,文件读取完成后的回调函数。
二进制字节,示例代码:
1 | const fs = require('fs') |
运行结果:
1 | null |
UTF-8编码,示例代码:
1 | const fs = require('fs') |
运行结果:
1 | null |
如果err不为空,说明读取失败。示例代码:
1 | const fs = require('fs') |
运行结果:
1 | [Error: ENOENT: no such file or directory, open '/Users/kaka/Desktop/mainXXX.py'] { |
写文件
写文件通过writeFile()方法。
1 | fs.writeFile(file, data[, options], callback) |
file,必选,文件路径。data,必选,写入的内容。options,可选,以什么格式写入文件内容,默认是utf8。callback,必选,文件写入完成后的回调函数。
示例代码:
1 | const fs = require('fs') |
运行结果:
1 | null |
文件内容:
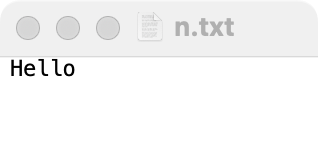
路径问题
Node.js在运行的时候,如果使用相对路径,会以执行node命令时所处的目录为基础。
在有些时候,在有些时候,可以考虑统一使用绝对路径。
path
path,Node.js官方提供一个内置模型,用来处理路径。
path.join()
path.join(),将多个路径片段拼接成一个完整的路径字符串。
例如,绝对路径/a的子目录/b/c/d的上级目录..的当前目录./d2的内部e.txt文件。示例代码:
1 | const path = require('path') |
运行结果:
1 | /a/b/c/d2/e.txt |
path.basename()
path.basename(),从路径字符串中,将文件名解析出来。示例代码:
1 | const path = require('path') |
运行结果:
1 | e.txt |
path.extname()
path.extname(),获取路径中的扩展名。示例代码:
1 | const path = require('path') |
运行结果:
1 | .txt |
__dirname
__dirname表示当前文件所处的目录。示例代码:
1 | const path = require('path') |
运行结果:
1 | /Users/kaka/Desktop |
__filename
__filename表示当前文件的完整路径。示例代码:
1 | const path = require('path') |
运行结果:
1 | /Users/kaka/Desktop/n.js |
http
争议
有些资料说,http,是Node.js官方提供的内置模块,用来创建web服务。
这么说,不够完整。
是Node.js官方提供的内置模块,这句话没有问题。
但是不仅仅用来创建web服务,还可以发送请求。
完整的论述是,提供了通过HTTP(超文本传输协议)传输数据这个功能的模块。
与之相对应的,还有一个模块,https,通过HTTP(TLS/SSL)协议传输数据。
发送请求
发送GET请求,通过https.get方法,示例代码:
1 | const https = require('https'); |
response.on('data'...,拼接返回。response.on('end'...,请求完成的时候触发。.on('error'...,处理异常。
发送POST请求。
- 定义需要发送的数据,
data。 - 定义发送地址,请求头等,
options。 - 定义回调方法,请求完成的回调,处理异常,
req。 - 发送请求,
write()。 - 结束,
end()。
1 | const https = require('https'); |
提供服务
导入http模块,示例代码:
1 | const http = require('http'); |
创建web服务器实例,示例代码:
1 | const server = http.createServer() |
为服务器绑定reqeust事件,示例代码:
1 | server.on('request', (req,res) => { |
req.url,请求地址。req.method,请求方法res.end('收到请求'),返回响应,并结束请求。
启动服务,调用服务器实例的.listen()方法,即可启动当前的web服务器实例,示例代码:
1 | server.listen(8080, () => { |
完整代码:
1 | const http = require('http'); |
然后我们发一个请求试一下。
运行结果:
1 | http server running 8080 |
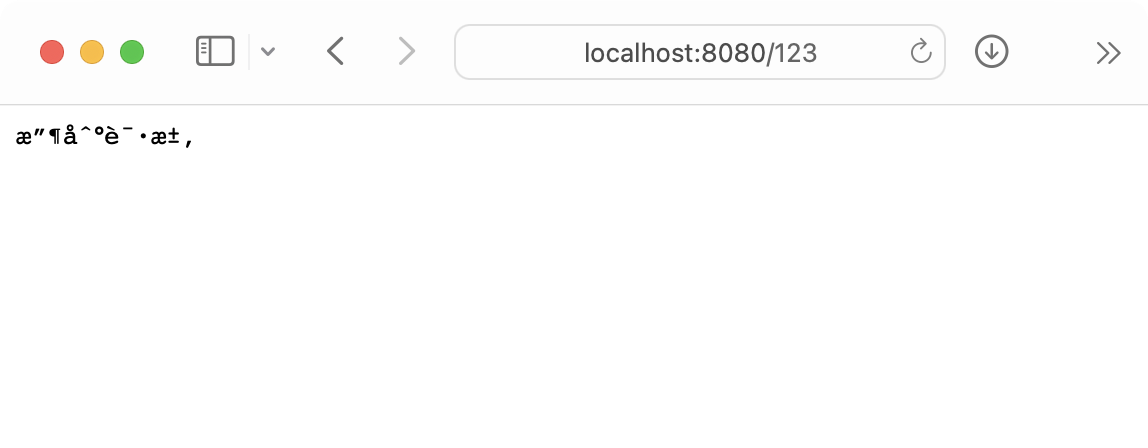
好,又乱码了。
这个我们已经处理太多次了。
设置响应头,告诉浏览器,要以utf-8',进行解析。
1 | res.setHeader('Content-Type','text/html; charset=utf-8') |
示例代码:
1 | const http = require('http'); |
运行结果:
npm
概述
Node.js中的第三方模块也被称为包。
我们可以通过npm的方式下载包。
npm官网:https://www.npmjs.com/
install
安装包的命令为:npm install 【包】。
也可以简写作:npm i 【包】。
默认会安装最新版本的,如果我们想制定版本,可以在包名之后,通过@符号指定具体的版本,npm install 【包】@【版本】。
package.json
必须要有package.json
npm规定,在项目根目录中,必须提供一个叫做package.json的包管理配置文件,用来记录与项目有关的一些配置信息。
例如,项目的名称、版本号、描述等,项目中都用到了哪些包,哪些包只在开发期间会用到,那些包在开发和部署时都需要用到。
创建package.json
可以通过npm init命令,初始化一个用npm管理的项目,该命令会创建package.json文件。
示例代码:
1 | npm init -y |
运行结果:
1 | Wrote to /Users/kaka/Documents/ns/npmns/package.json: |
-y,在执行npm init命令期间的所有选项,均采用默认。- 上述命令只能在英文的目录下成功运行,所以,项目文件夹的名称一定要使用英文命名,不要使用中文,不能出现空格。
dependencies
我们执行npm install hexo,再观察一下package.json,内容如下:
1 | { |
npm会自动把包的名称和版本号,记录到package.json中。其中dependencies节点,记录的是安装了哪些包。
devDependencies
如果某些包只在项目开发阶段会用到,在项目上线之后不会用到,则建议把这些包记录到devDependencies节点中。
命令如下:
1 | npm install moment --save-dev |
或者
1 | npm install moment -D |
此时package.json的内容如下:
1 | { |
node_modules和package-lock.json

我们会发现,还多了一个文件夹node_modules和一个文件package-lock.json。
node_modules文件夹,用来存放所有已安装到项目中的包。require()导入第三方包时,就是从这个目录中查找并加载包。
package-lock.json配置文件用来记录node_modules目录下的每一个包的下载信息,例如包的名字、版本号、下载地址等。示例代码:
1 | { |
工作建议
- 把
node_modules文件夹,添加到git的.gitignore忽略文件中。
对于git-clone得到的新项目,通过npm install重新安装配置文件中的所有包。 - 不建议手动修改
node_modules或package-lock.json文件中的任何代码。
如果需要卸载包,通过命令,npm uninstall 【包】。
全局包
在npm中,安装包的作用范围,可以分为两类包。
- 项目包
- 全局包
被安装到项目的node_modules目录中的包,都是项目包。上文我们讨论的,都是项目包。
在执行npm install命令时,如果提供了-g参数,则会把包安装为全局包。
通过命令npm root -g,可以查看全局包的安装路径。
一般只有工具性质的包(如npm),才有全局安装的必要性。
切换源
镜像源
下包的地址,就是源。
因为npm的官方源,在某些网络环境下,下包会很慢,甚至连不上。所以可以考虑国内的一些镜像源。
例如:
- 腾讯源
http://mirrors.cloud.tencent.com/npm/ - 淘宝源
https://registry.npmmirror.com - 华为源
https://mirrors.huaweicloud.com/repository/npm/
查看当前源
示例代码:
1 | npm config get registry |
运行结果:
1 | https://registry.npmjs.org/ |
切换源
示例代码:
1 | npm config set registry https://registry.npmmirror.com |
发布包
初始化包
- 新建文件夹,作为包的目录。
- 执行
npm init,进行初始化。生成package.json(包管理配置文件) - 在根目录创建
index.js,作为包的入口文件。 - 在根目录创建
README.md,作为包的说明文档。
编写代码
我们以一个"获取当前时间"这个功能为例,代码结构如下。
可以只在index.js中定义方法,作为一个例子,本文选择了"模块化"。
s.js,示例代码:
1 | function now(){ |
index.js,示例代码:
1 | const now = require('./scripts/s.js') |
发布
注册npm账号
访问:https://www.npmjs.com
注册账号。
登录npm账号
执行命令npm login命令,进行登录。
需要注意的是,在执行npm login之前,需要先源切换为npm的官方源,否则登录的是镜像源。
如,淘宝源。
切换回官方源:
1 | npm config set registry https://registry.npmjs.org |
发布到npm上
在包的根目录,执行npm publish,发布。
试一下
我们可以试一下,先执行npm install kaka-package-test,安装。
示例代码:
1 | const kaka = require('kaka-package-test') |
运行结果:
1 | 2023-05-05T09:44:11.750Z |
删除已发布的包
npm unpublish 【包】 --force,即可从npm删除已发布的包。
注意:
npm unpublish,只能删除72小时以内发布的包。npm unpublish,删除的包,在24小时内不允许重复发布。
图床
npm命令有一个神奇的用法,图床。虽然这个属于 滥用 。
所有的操作都一样,只是我们在包里面放了图片。
访问方法:
- 使用版本号访问
- 不使用版本号,默认最新版本
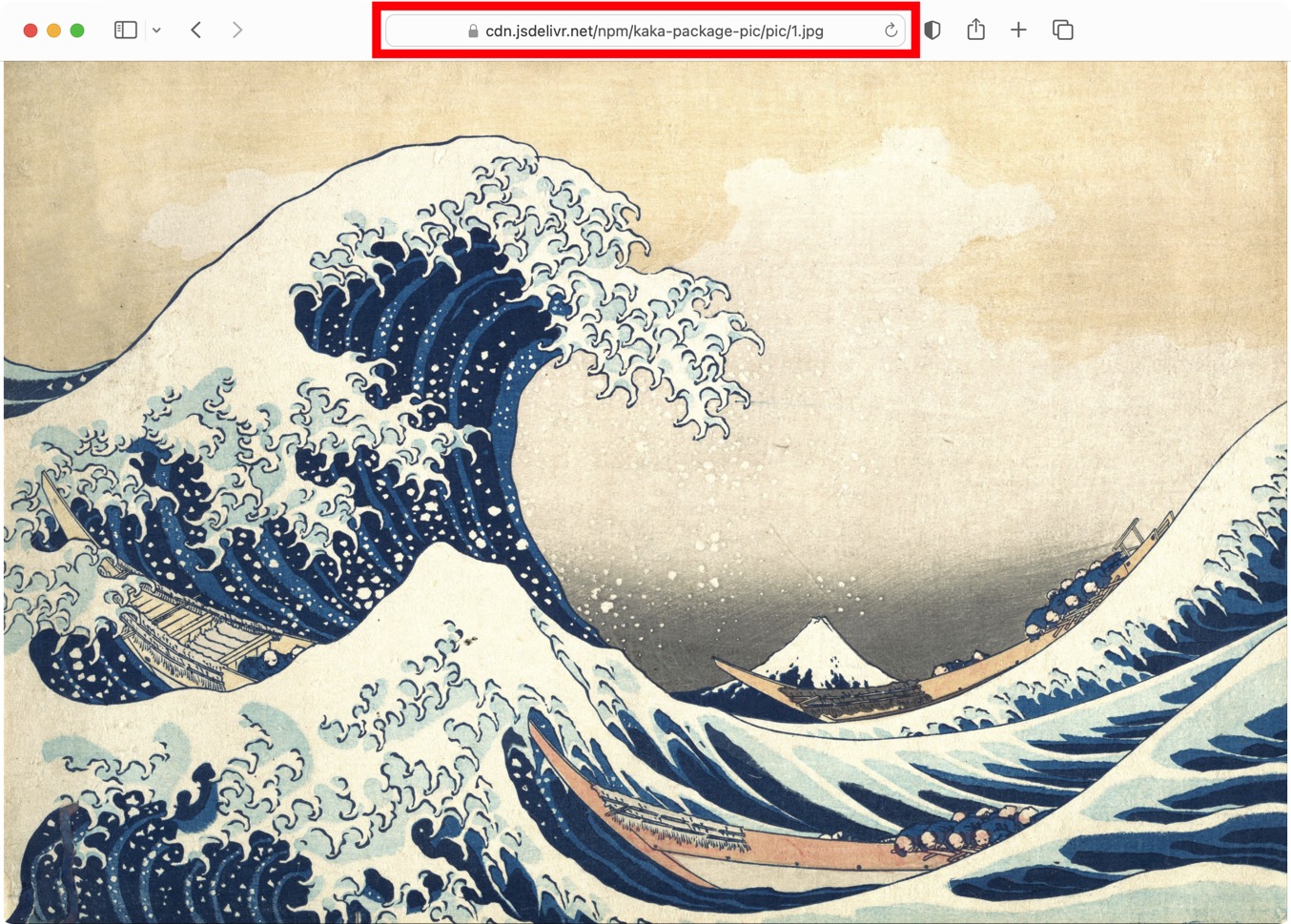
https://cdn.jsdelivr.net/npm/包名/图片路径
例如,在本例中,地址为:https://cdn.jsdelivr.net/npm/kaka-package-pic/pic/1.jpg
模块加载机制
优先从缓存中加载
模块在第一次加载后会被缓存,不论是内置模块、用户自定义模块、还是第三方模块,它们都会优先从缓存中加载。
这也意味着多次调用require()不会导致模块的代码被执行多次。
我们可以试一下,假设存在1.js,示例代码:
1 | console.log('1') |
2.js,示例代码:
1 | const m1 = require('./1.js') |
运行结果:
1 | 1 |
内置模块优先级最高
内置模块的加载优先级最高。
例如,fs是node的一个内置模块。假如说,在node_modules目录下有名字相同的包也叫做fs,require('fs')加载的也是内置的fs模块。
会发现只运行了一次。
自定义模块的加载机制
使用require()加载自定义模块时,必须指定以./、../或/开头的路径标识符。如果没有指定,则node会把它当作内置模块或第三方模块进行加载。
使用require()导入自定义模块时,如果省略了文件的扩展名,则Node.js会按顺序分别尝试加载以下的文件:
- 按照确切的文件名进行加载
- 补全
.js扩展名进行加载 - 补全
.json扩展名进行加载 - 补全
.node扩展名进行加载 - 加载失败,终端报错
有些资料说,对于用户自定义模块的加载,必须是./或../开头的相对路径,这个是不对的。
在我实际测试中,绝对路径也可以,应该是以./、../或/开头的路径。
第三方模块的加载机制
如果传递给require()的模块标识符不是一个内置模块,也没有以./、../或/开头,则Node.js会从当前模块的父目录开始,尝试从/node_modules文件夹中加载第三方模块。
如果没有找到对应的第三方模块,则移动到再上一层父目录中,进行加载,直到文件系统的根目录。
例如,假设在C:\Users\kaka\project\foo.js文件里require('tools'),则Node.js会按以下顺序查找:
C:\Users\kaka\project\node_modules\toolsC:\Users\kaka\node_modules\toolsC:\Users\node_modules\toolsC:\node_modules\tools
目录作为模块
如果把目录作为模块标识符,传递给require()进行加载,按照如下步骤加载
- 在被加载的目录下查找一个叫做
package.json的文件,并寻找main属性,将main属性定义的文件,作为require()加载的入口。 - 如果目录里没有
package.json文件,或者main入口不存在,或者main入口无法解析,则Node.js将会试图加载目录下的index.js文件。 - 如果以上两步都失败了,则Node.js会在终端打印错误消息,报告模块的缺失:
Error: Cannot find module 'xxx'。
假设代码结构如下。
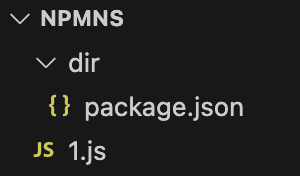
package.json:
1 | { |
在1.js中require('/dir')。示例代码:
1 | const d = require('/dir') |
运行结果:
1 | internal/modules/cjs/loader.js:818 |
mysql
安装
mysql,一个第三方的模块,提供了在Node.js中连接和操作MySQL数据库的能力。
安装命令:npm install mysql。
配置
createPool
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | ER_NOT_SUPPORTED_AUTH_MODE: Client does not support authentication protocol requested by server; consider upgrading MySQL client |
上述报错了,这个报错的原因,我们在《MySQL从入门到实践:1.概述和工具准备》的"MySQL安装与配置"的"连接异常的处理"也讨论过。
原因是:MySQL8.0默认采用caching_sha2_password的加密方式,但是有些第三方客户端不支持这种加密方式。解决方法是
1 | ALTER USER'root'@'%' IDENTIFIED WITH mysql_native_password BY 'MySQL@2023'; |
如果运行成功,结果为:
1 | [ RowDataPacket { '1': 1 } ] |
createConnection
在上文,我们用的是mysql.createPool(),还有一个方法是mysql.createConnection()。
mysql.createPool(),建立连接池。
mysql.createConnection(),建立连接。
关于连接和连接池,可以参考《基于Java的后端开发入门:10.JDBC》。
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | [ RowDataPacket { '1': 1 } ] |
在mysql.createConnection()中,我们可以执行db.end(),主动释放连接。但是在mysql.createPool(),不要执行db.end()。
查询
查询user表中所有的数据。示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | [ |
插入
一般方法
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | 插入成功 |
快捷方法
如果对象的每个属性和数据表的字段一一对应,可以通过INSERT INTO SET的方式快速插入数据。
1 | INSERT INTO user SET ? |
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | 插入成功 |
更新
一般方法
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | 更新成功 |
快捷方法
如果我们需要更新多个字段,这种方法会很效率很高。
1 | UPDATE user SET ? WHERE username = ? |
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | 更新成功 |
删除
示例代码:
1 | const mysql = require('mysql') |
运行结果:
1 | 删除成功 |
express
概述
Express,基于Node.js的Web开发框架。
安装
npm i express
基本操作
创建Web服务器
示例代码:
1 | const express = require('express') |
监听GET请求
通过app.get()方法,可以监听客户端发出的GET请求。
示例代码:
1 | app.get('/get',function(req,res){ |
- 参数一:客户端请求的URL地址
- 参数二:请求对应的处理函数
req:请求对象(包含了与请求相关的属性与方法)res:响应对象(包含了与响应相关的属性与方法)
监听POST请求
通过app.post()方法,可以监听客户端发出的POST请求。
示例代码:
1 | app.post('/post',function(req,res){ |
- 参数一:客户端请求的URL地址
- 参数二:请求对应的处理函数
req:请求对象(包含了与请求相关的属性与方法)res:响应对象(包含了与响应相关的属性与方法)
发送响应
通过res.send()方法,发送响应。
示例代码:
1 | app.get('/get',function(req,res){ |
参数处理
获取Get请求中的参数
客户端通过?name=姓名&age=22这种形式传输参数。
服务端通过req.query.name和req.query.age的形式接收参数。
示例代码:
1 | const express = require('express') |
1 | curl --location --request GET 'http://localhost:8080/get?name=姓名&age=22' |
运行结果:
1 | 姓名 |
获取RESTful中的参数
服务端通过/user/:id的形式定义要接收的参数,并通过req.params获取。
示例代码:
1 | const express = require('express') |
1 | curl --location --request GET 'http://localhost:8080/user/1' |
运行结果:
1 | { id: '1' } |
获取POST请求的表单参数
通过req.body接收,注意其中一行,app.use(express.urlencoded());。示例代码:
1 | const express = require('express') |
1 | curl --location --request POST 'http://localhost:8080/user' \ |
运行结果:
1 | { h1: '抽烟', h2: '喝酒', h3: '烫头' } |
获取POST请求的JSON参数
也是通过req.body接收,注意其中一行app.use(express.json());。示例代码:
1 | const express = require('express') |
1 | curl --location --request POST 'http://localhost:8080/user' \ |
运行结果:
1 | { u1: 1, u2: 2 } |
获取POST请求上传的文件
首先,需要安装multer。
然后,配置上传文件临时存储位置:
1 | const upload=multer({dest:"uploads/"}); |
最后,通过req.file获取单个文件,对于多个文件,通过req.files获取。示例代码:
1 | const express = require('express') |
注意,upload.single('cover')。
- 上传单个文件:
upload.single('myfile'); - 上传多个文件:
upload.array('myfile'); - 传多个文件 限制文件的个数:
upload.array('myfile',1);
upload.fields([name:'myfile',maxCount:2,{name:'myfile2'}]);
我们可以通过Postman发送文件进行测试,发送方法参考《基于Java的后端开发入门:17.SpringMVC》的"接收请求参数"的"文件"部分。
body-parser
还有一种方法是依赖中间件body-parser,这种方法实际上已经被废弃了,我们不讨论。
静态资源
express.static()
通过app.use(express.static(【指定目录】)),可以非常方便地创建一个静态资源服务器,然后可以将指定目录下的图片、CSS文件、JavaScript文件等对外开放。
示例代码:
代码结构如下,public和app.js位于同一层级
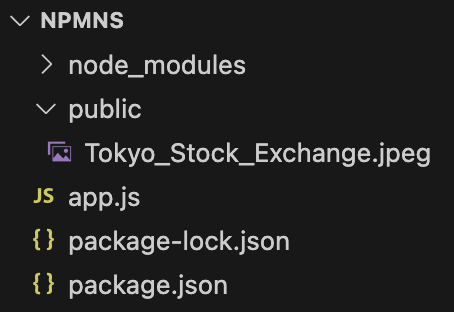
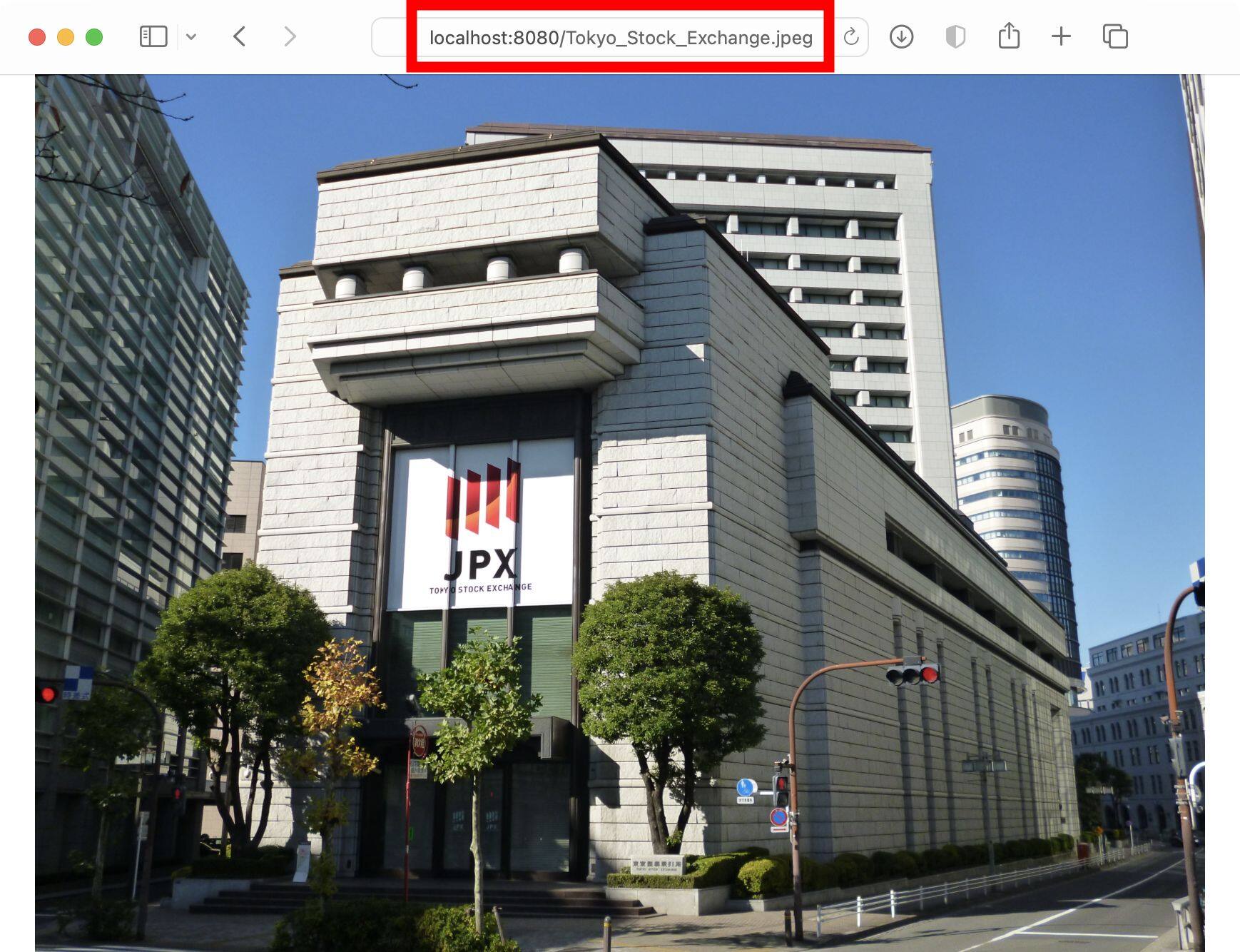
1 | app.use(express.static('public')) |
访问地址为:http://localhost:8080/Tokyo_Stock_Exchange.jpeg
多个静态资源目录
如果我们有多个静态资源目录,只需要多次调用express.static()函数即可。
示例代码:
1 | app.use(express.static('public')) |
路径前缀
如果希望在静态资源访问路径上加上前缀,可以通过如下的方式。
示例代码:
1 | app.use('/img',express.static('public')) |
此时,访问地址为:http://localhost:8080/img/Tokyo_Stock_Exchange.jpeg
路由
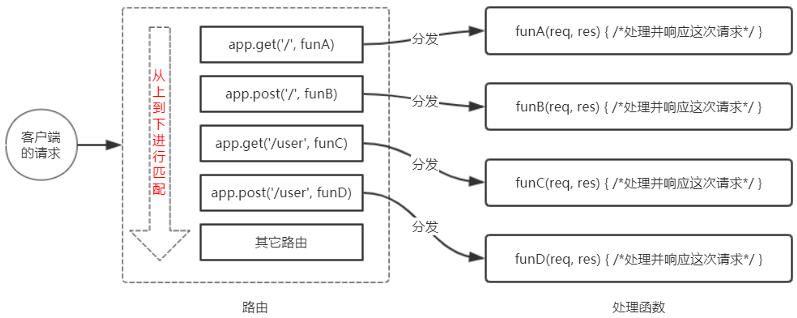
什么是路由
Express中的路由,指的是,我以某种方式请求某个路径,最终会交给哪个函数处理。
格式如下:
1 | app.METHOD(PATH,HANDLER) |
我们上文的get和post的例子,其实就是路由。
1 | app.get('/get',function(req,res){ |
路由匹配
在Express中,当一个请求到达服务器之后,先经过路由的匹配,只有匹配成功之后,才会调用对应的处理函数。
在匹配时,会按照路由注册的顺序进行匹配,如果请求方式和请求的URL同时匹配成功,则Express会将这次请求,转交给对应的函数进行处理。
模块化路由
为了方便对路由进行模块化的管理,我们推荐将路由抽离为单独的模块。
代码结构:
第一步:
- 创建路由模块对应的
.js文件。 - 调用
express.Router()函数创建路由对象。 - 向路由对象上挂载具体的路由。
- 使用
module.exports向外共享路由对象。
示例代码:
1 | // 调用`express.Router()`函数创建路由对象 |
第二步:使用app.use()函数注册路由模块。
1 | const express = require('express') |
中间件
概述
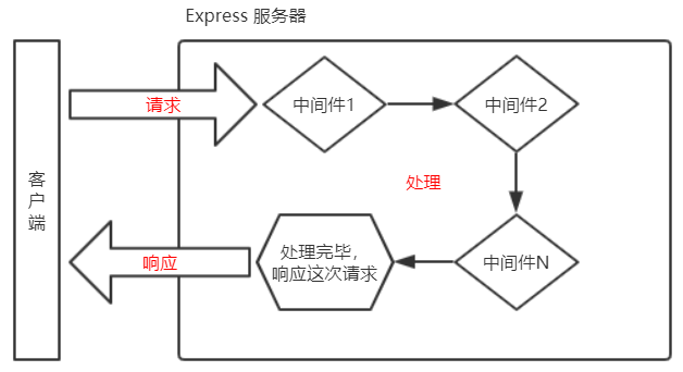
中间件,Middleware,当一个请求到达Express的服务器之后,可以连续调用多个中间件,从而对这次请求进行预处理。
这个概念也不陌生,类似的有
- 过滤器
我们在《基于Java的后端开发入门:13.Servlet、Filter和Listener》,有过讨论。 - 拦截器
我们在《基于Java的后端开发入门:17.SpringMVC》,有过讨论。
中间件的本质,就是一个函数。

- 在中间件函数的形参列表中,包含
next参数。但是,在路由处理函数中只包含req和res。 next()这一行,表示把流转关系转交给下一个中间件或路由。
定义中间件
示例代码:
1 | const mw = function(req,res,next){ |
全局生效的中间价
app.use(中间件函数)
客户端发起的任何请求,到达服务器之后,都会触发的中间件,叫做全局生效的中间件。
通过调用app.use(中间件函数),即可定义一个全局生效的中间件。
示例代码:
1 | const express = require('express') |
我们在上文的app.use(express.urlencoded())和app.use(express.json()),就是全局生效的中间件。
快捷方法
还有一种方法,这个是不是中间件?
1 | app.use(function (req,res,next){ |
也是中间件,中间件的本质就是一个函数。
多个中间件的顺序
可以使用app.use()定义多个全局中间件。
客户端请求到达服务器之后,会按照中间件定义的先后顺序依次进行调用。
示例代码:
1 | const express = require('express') |
运行结果:
1 | 这是一个中间件函数 |
局部生效的中间件
不使用app.use()定义的中间件,叫做局部生效的中间件。
比如我们在上文的POST接收文件定义的中间件。
1 | app.post("/postfile", upload.single('cover'), function (req, res) { |
定义多个局部中间件,有两种方式,是等价的。
方式一:app.get('/' , mwi, mw2, (req, res) => {res.send('Home page.')})
方式二:app.get('/', [mw1, mw2], (req, res) => {res.send('Home page.')})
五类中间件
Express中的间件可以分成5类:
- 应用级别的中间件
- 路由级别的中间件
- 错误级别的中间件
- Express内置的中间件
- 第三方的中间件
应用级别的中间件
通过app.use()或app.get()或app.post()等,绑定到app实例上的中间件,叫做应用级别的中间件。
我们上文的定义的所有中间件,都属于应用级别的中间件。
路由级别的中间件
绑定到express.Router()实例上的中间件,叫做路由级别的中间件。
其作用和应用级别中间件没有任何区别。
只不过,应用级别中间件是绑定到app实例上,路由级别中间件绑定到router实例上。
示例代码:
1 | router.use(function(req,res,next){ |
错误级别的中间件
专门用来捕获整个项目中发生的异常错误。
在错误级别中间件的处理函数中,必须有4个形参,形参顺序从前到后,分别是err、req、res和next。
示例代码:
1 | const express = require('express') |
运行结果:
1 | 发生了:制造错误 |
注意:错误级别的中间件,必须注册在所有路由之后!
我们来看一个没有定义在路由之后的现象。示例代码:
1 | const express = require('express') |
运行结果:
1 | Error: 制造错误 |
Express内置的中间件
Express内置了3个常用的中间件,这3个常用的中间件,我们在上文都讨论过。
express.static
快速托管静态资源的内置中间件。express.json
解析JSON格式的请求体数据,仅在4.16.0以上的版本中可用。express.urlencoded
解析URL-encoded格式的请求体数据,仅在4.16.0以上的版本中可用。
第三方的中间件
上文提到的body-parser,就是第三方的中间件。
在下文,我们还会提到好几个第三方的中间件。
注意事项
- 除了,错误级别的中间件,其他中间件一定要在路由之前注册
因为请求在到达后,按照从上到下进行匹配。如果对于其他中间件,如果路由之后注册中间件,会先匹配到路由,不会先进入中间件。 - 执行完中间件的业务代码之后,不要忘记调用
next()函数。 - 为了防止代码逻辑混乱,调用
next()函数后不要再写额外的代码。
跨域
现象
我们通过Chrome浏览器访问https://kakawanyifan.com/,进入开发者模式,调用http://127.0.0.1:8080/。
示例代码:
1 | var xhr = new XMLHttpRequest(); |
运行结果:
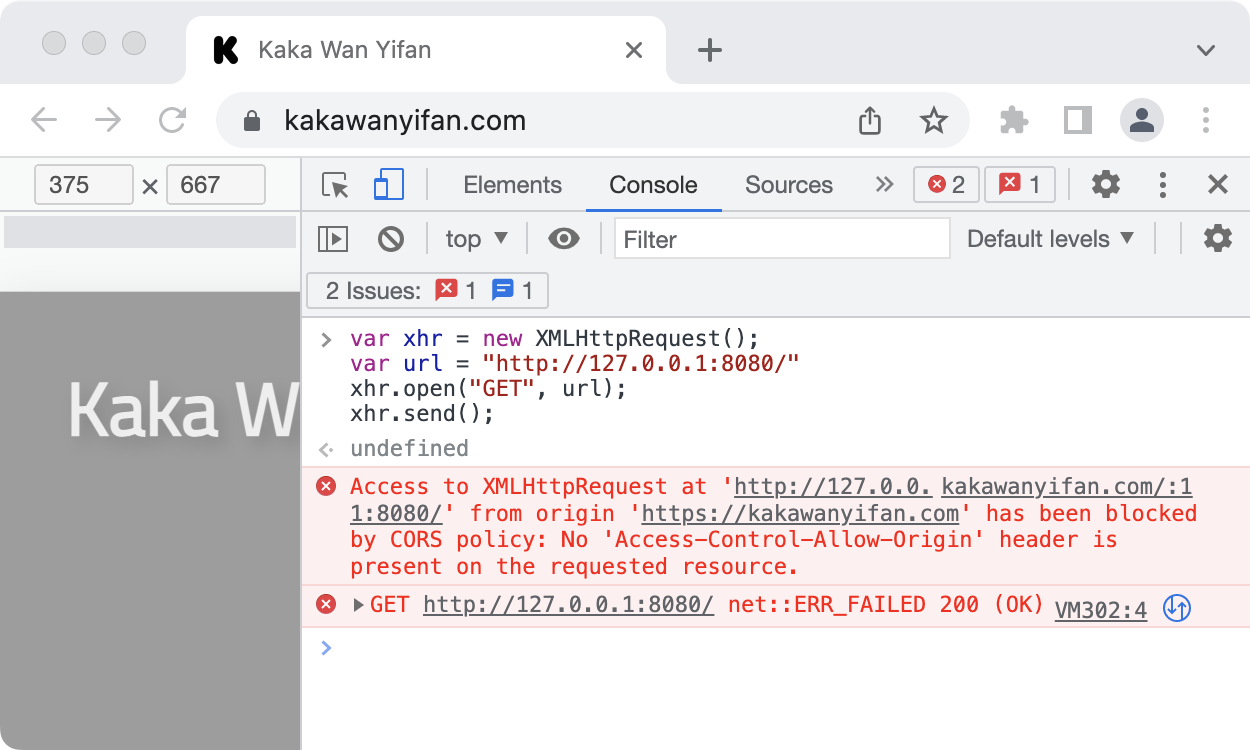
跨域了!
cors中间件
在Express中可以使用cors中间件解决跨域。
- 运行
npm install cors安装中间件。 - 使用
const cors = require('cors')导入中间件。 - 在路由之前调用
app.use(cors())配置中间件。
那么,为什么这样就可以了?
因为在app.use(cors())后,响应头多如下红框标示的一行。
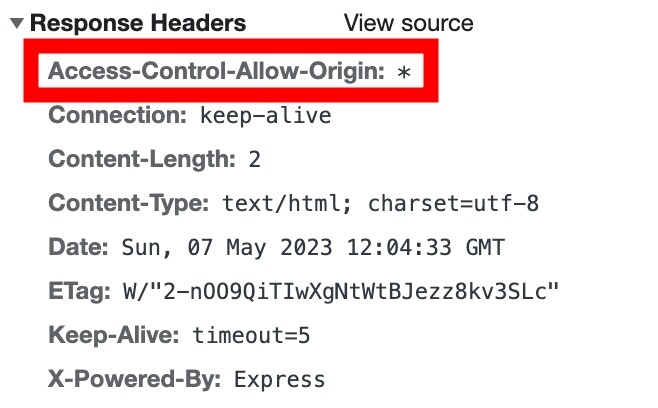
即,这种方法,是被请求的一方主动允许跨域。
那么,如果我们只想允许指定的域名可以跨域呢?
示例代码:
1 | const corsOptions = { |
关于cors中间件的更多用法,可以参考:https://expressjs.com/en/resources/middleware/cors.html
身份认证
身份认证有两种方式:
- Session
- JWT
Session
什么是Session
关于什么是Session,可以参考《基于Java的后端开发入门:13.Servlet、Filter和Listener》的"Session"部分。
配置express-session中间件
在Express项目中,可以通过express-session中间件,在项目中使用Session认证。
安装:npm install express-session。
使用,示例代码:
1 | const session = require('express-session') |
secret:密钥,可以为任意字符串。resave: false和saveUninitialized: true,是固定写法。
访问Session对象
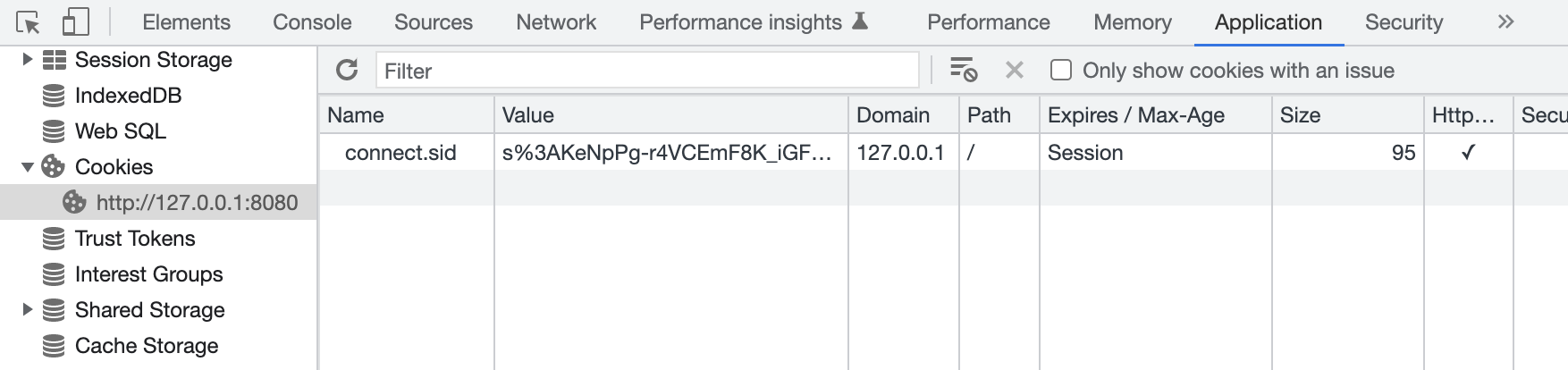
通过req.session来访问Session对象,通过req.session.destroy(),清空服务器保存的Session信息。
代码结构:

app.js:
1 | const express = require('express') |
访问http://127.0.0.1:8080/login.html,登录后,会看到如下内容。
JWT
工作原理
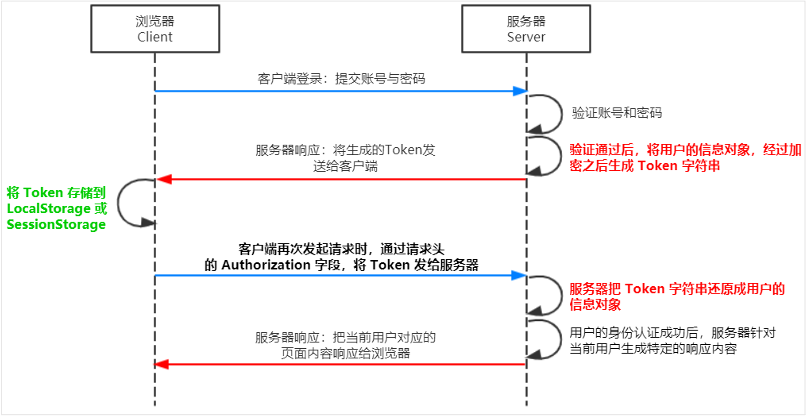
JWT,JSON Web Token,跨域认证解决方案。
用户的信息通过Token字符串的形式,保存在客户端浏览器中,服务器通过还原Token字符串的形式来认证用户的身份。
具体工作原理如下:
组成部分
JWT由三部分组成,分别是:
- Header,头部
- Payload,有效荷载
- Signature,签名
其中Payload是用户信息经过加密之后生成的字符串。Header和Signature是安全性相关的部分,用以保证Token的安全性。
三者之间使用英文的.分隔。
例如,这就是一个JWT:
1 | eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzUxMiJ9 |
使用方式
客户端收到服务器返回的JWT之后,会将其保存在本地(localStorage、sessionStorage或者cookie)。
此后,客户端每次与服务器通信,都要带上JWT的字符串,进行身份认证。
推荐的做法是把JWT放在HTTP请求头的Authorization字段中,形式如下:
1 | Authorization: Bearer <token> |
在Express中使用JWT
Serverless
Serverless,需要依赖云服务商的函数计算功能。
例如,阿里云的:https://www.aliyun.com/product/fc
安装插件@serverless-devs/s,在部署方面会更便捷。
安装
安装命令:
1 | npm install @serverless-devs/s -g |
安装完成后,可以通过s -v查看是否安装成功。示例代码:
1 | s -v |
运行结果:
1 | @serverless-devs/s: 2.1.14, s-home: /Users/kaka/.s, darwin-x64, node-v12.22.12 |
注意,如果在安装的时候,没有-g,无法通过s -v查看是否安装成功。
配置
配置密钥
通过s config add,选择云服务厂商。示例代码:
1 | s config add |
运行结果:
1 | ? Please select a provider: (Use arrow keys) |
通过上下方向键选择云服务厂商,回车键确认。
然后安装提示配置密钥等,在配置过程会,提示配置别名,默认是default。
查看密钥
1 | s config get -a default |
-a或--access,指定别名名称。
如果不加上-a或--access,即查看所有。
删除密钥
1 | s config delete -a aliasName |
初始化
1 | s init devsapp/start-express -d start-express |
-d,指定项目名称。
部署
1 | s deploy |